基于改進用戶畫像的協同過濾推薦算法
2022-02-09 02:21:46姜久雷李盛慶
計算機仿真 2022年12期
凌 坤,姜久雷,李盛慶
(1. 北方民族大學計算機科學與工程學院,寧夏 銀川 750021;2. 常熟理工學院計算機科學與工程學院,江蘇 蘇州 215500)
1 引言
隨著Internet技術的發展,網絡數據逐年增加[1]。為了更好地解決客戶的復雜需求和海量信息之間的矛盾,誕生了個性化推薦系統[2],該系統可運用到很多領域中,例如,產品推薦[3],電影推薦[4],音樂推薦[5],社交網絡推薦[6]和許多其它行業。個性化推薦技術[7]會根據客戶在科學研究中的興趣和偏好,強烈推薦客戶所需的各種資源。在許多強烈推薦的技術中,協作過濾算法現在是更流行的技術。與傳統的基于內容過濾的強推薦方法不同,協作過濾算法通過分析客戶的興趣和偏好,在消費者群體中尋找與目標客戶相似的客戶,并為不同的新客戶提供相似的客戶評級。對于新項目,對該最新項目的目標客戶的偏好水平進行了預測分析,并根據相反方向的排名得分獲得了強烈的推薦結果。
根據用戶喜好將相應的作品推送給用戶的算法,即協同過濾算法。實際上,它們可以分為三類:基于用戶的[8,9],基于新項目的[10,11]和基于物理模型的[12]。協同過濾算法。協同過濾算法可以過濾這些復雜的敘事內容,可以解決不能完全自動化的信息過濾問題,并且具有強烈推薦新信息的功能。但該算法并不是完美的。在信息量持續擴大的情況下,它存在評分矩陣稀疏的問題[13]。
關于傳統強烈推薦算法的稀缺性問題,來自世界各地的許多學者介紹了與用戶畫像有關的算法,并從不同角度進行了科學研究。Bertani等[14]處理了傳統的強推薦算法不能合理利用用戶信息的問題,并明確提出了一種基于用戶資料的用戶肖像強推薦算法。該算法通過學習用戶的個人信息并整合對象的新穎性和時尚性來開發智能推薦。經過實驗研究后發現,與其它算法相比,該算法獲得的效果更為理想。姚等[15]明確提出了一種基于愛好識別和個人行為的智能推薦算法。該算法基于用戶的愛好標識和歷史時間訪問記錄來構建用戶肖像,并強烈推薦用戶感興趣的電影。Hu等[16]經過研究后,以肖像特征為基礎,提出相應的推薦算法。該算法使用酒店餐廳的消費者信息和房間總數來構造用戶畫像,以開發針對酒店房間及其酒店餐廳服務項目的智能推薦。Abri等[17]明確提出了一種基于主題風格用戶畫像的智能推薦實體模型。實體模型使用K-means聚類算法為用戶執行聚類算法,并在每種主題樣式中使用普遍的方法來考慮用戶之間的相似性,提高最終用戶得分排名,并解決用戶的冷啟動問題。黃等[18]明確提出了一種針對人性化廣告的強力推薦算法。該算法根據每個用戶的歷史瀏覽記錄建立用戶肖像,并直觀地表達用戶的廣告偏好。對于這些不常見的廣告,請使用廣告的特征和用戶頭像來提出強烈的建議。楊等[19]結合馬爾科夫鏈,設計出智能推薦算法。該算法使用馬爾可夫鏈獲得用戶之間的相似度,并根據用戶分數開發相關信息。Ahmadian等[20]以信任為基礎提出的推計算法將信任度分數與社交媒體中的信任度緊密集成在一起,并通過增加用戶之間的信任度來改善強推薦功能。上述研究表明,在用戶肖像協同過濾方面已經取得了一些研究成果,但仍存在數據稀缺,強推薦精度低的問題[13]。
針對目前還存在的用戶評分矩陣稀疏性問題,本文提出了一種基于用戶畫像的協同過濾推薦算法(CPCF),該算法將用戶評分矩陣轉化為用戶特征矩陣,采用用戶畫像產生的特征權重與傳統相似度相結合,計算得到CPsim相似度公式,最后利用改進的權重聚合公式(DFM)得到評分矩陣,有效填充了評分矩陣中的缺失值,部分解決協同過濾算法在相似度計算階段由于用戶評分數據稀疏性引起的推薦準確率不高的問題。經在movieslens和數據集上與UBCF等推薦算法進行對比分析,實驗結果表明,相比UBCF等算法平均絕對誤差(MAE)降低了13%,精確率、召回率和F1-Score分別提高了11%、3%和4%。
2 傳統協同過濾推薦模型
2.1 基于奇異值的相似性推薦算法
2012年Bobadilla等人[21]提出了一種SM(similarity measure based on singularity)相似度量模型。其分析用戶相關性,根據分析來獲得實際相似度。根據相關性把所有內容分為兩部分:正相關、負相關,若相關性過低,則屬于負相關,可定義為與用戶喜好相反的項目,在實際操作時,盡可能減少該類項目的推薦。分析相關性時,可利用評分的方法來表示分析結果。對每個項目均進行一次評分,最高為5分,最低為1分,若分值低于3(含3分),則可將該項目歸類到負相關。該過程中,得到的所有正相關項目存放到Zi集合內,負相關存放至Fi集合,則奇異值的計算公式

(1)

(2)


以下通過三步來計算目標用戶對項目的評分。
首先利用MSD(Mean Squared Differences)進行相似度計算,見式(3)

(3)
Iu和Iu′表示用戶u和用戶u′的項目,rui為用戶u對于項目i的評分。
對式(3)進行改進,將之前計算的奇異值加入MSD公式,得到了SM相似度量模型,見式(4)

(4)
rui為用戶u對于項目i的評分,ruj為用戶u對于項目j的評分。
隨后結合上述表達式,設定閾值為k,若計算結果高于該值,則可將該項目設置為鄰居用戶。確定所有鄰居用戶后,分析其與目標用戶間的相似性,從而得到該項目的最終分值預估值。這里利用改進的權重聚合公式進行評分預測,見式(5)
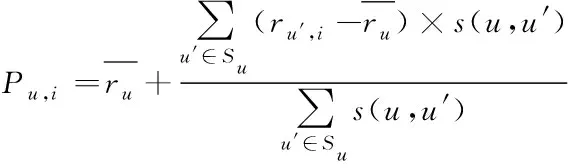
(5)
以上表達式內,各參數涵義如下:s(u,u′)——目標用戶及u的相似度;rui——u對項目評分值;ru——u平均分值。
根據以上計算的最終分值,確定該項目奇異值,并融合其與評分矩陣后,計算后得到的結果即為相似度,通過這種方法可避免矩陣中存在數據稀疏的問題。但是SM算法的不足之處在于用戶評分矩陣奇異值稀疏問題,導致計算結果不準確并且影響相似度結果,最終影響推薦的性能。
2.2 基于用戶協同過濾推薦算法
在許多推薦算法方法中,基于用戶協同過濾的強推薦算法是第一個問世。用戶協同過濾算法是在1992年明確提出的,并用于電子郵件過濾設備[22]。兩年后出現了有關該算法使用的相關報道。到2000年,該算法已成為業界最知名的算法。
實際上人們不管是在購物還是做其它事情,都會無意識根據自己的喜好來選擇,如在商場內購物時,通常都是基于自己的喜好或結合朋友推薦來購物。而本文中提出的協同過濾算法,就是以該思想為基礎而設計的,其首先采集用戶信息,判斷該用戶的喜好,再根據該結果搜索到喜好較為相似的鄰居用戶,結合鄰居用戶評分值,來預估目標用戶對該項目的評分,并根據該評估結果,給用戶推薦相應的Top-N項目。將其運算過程用結構圖描述出來,如下圖,項目a、b、d都為用戶A的喜好,而B僅喜好c,用戶C則喜好a、d,由此,項目a、d都為用戶A、C的喜好,表明兩用戶喜好較為接近,根據算法思想,可得項目b可能為用戶C的喜好,因此可將該項目推薦給C,這就是該算法的基本原理。

圖1 基于用戶協同過濾算法原理
該算法雖然具有較高的準確率,但其也有一定的缺陷。隨著用戶的增加,相似度測量和得分矩陣的成本非常高,導致矩陣的稀缺性增加。另外,由于新用戶在歷史上的個人行為較少,因此在協作過濾強推薦算法中仍然存在無法立即對新用戶進行智能推薦的問題。
針對算法中存在的該問題,人們經過不斷研究后也提出了相應的解決方法。用戶畫像可以準確提供用戶的偏好信息,根據偏好信息構建用戶畫像并填充稀疏矩陣,部分改進傳統協同過濾算法具有的數據稀疏問題,可以提升推薦性能,所以本文重點研究基于用戶畫像的協同過濾推薦[23]。人像的定義[24]首先是人機交互的發起者艾倫·庫珀(Alan Cooper)明確提出的。用戶肖像指的是基于用戶的相關特征,偏好,生活方式,個人行為和其它信息的帶有標簽的抽象用戶實體模型。本文使用用戶的性別,年齡和工作特征來構建用戶肖像,并使用改進的CPsim來衡量用戶的相似性。即采集用戶的相關信息,如職業、性別等,利用這些信息得到對應的用戶畫像。
3 基于改進的用戶畫像協同過濾算法
3.1 生成用戶特征
Bobadilla在基于奇異值的相似性模型中提出的SM模型[21],根據用戶-項目評分矩陣,計算奇異值權重,從而獲得對應的畫像。本章基于SM模型進行用戶特征權重的計算。對于不同的用戶信息進行分類,并且計算每一類別相應的特征系數與特征權重,從而生成用戶畫像進行推薦。用戶的基本信息包括性別、年齡和職業,以用戶性別信息為例,將用戶評分矩陣轉換為用戶性別矩陣,計算性別系數以及性別權重,得到用戶性別矩陣,見表1。

表1 用戶性別矩陣
M=男性特征
W=女性特征
其中,M、W分別為男、女性特征。如U1與I1對應的用戶性別矩陣中為M,則表示對項目I1感興趣的用戶U1為男性用戶。如果一個項目中的某一性別的用戶越多,則該項目更加受這一性別人群的喜愛。
計算用戶的特征系數,通過用戶性別矩陣選取相應的性別特征集合。該系數中包含男性、女性兩部分,計算公式如下:

(8)
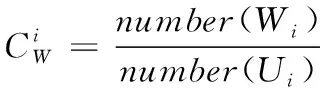
(9)

結合以上得到的計算值,獲得相應的性別權重,進而確定性別特征。用戶特征反應了某一性別的用戶對于該項目的偏好程度,性別特征計算見式(10)(11):

(10)

(11)

上述即為性別特征的分析方法。根據性別系數來判斷權重值,從而獲得對應的特征。其它的用戶特征計算方法與用戶性別特征計算方法相類似,年齡、職業等特征不再具體描述。
3.2 用戶畫像生成
2.1節以用戶性別特征為例介紹了用戶特征計算方法,本節將用戶的信息進行明確的劃分并計算信息特征,然后通過信息特征權重構建用戶畫像。
對于用戶的年齡和職業信息來說,信息的種類比較復雜,無法直接利用公式進行計算。因此在計算前,需把職業、年齡分為兩個不同的特征。比如,將用戶的年齡信息按照不同的年齡階段分為青少年、青年、中年、老年,將用戶的職業信息按照不同的職業種類分為技術人員、學術人員、事務人員、經管人員及其他人員。
將用戶的信息分類完成,利用之前的分類結果設立相應的特征系數及特征標簽,具體標簽見表2。

表2 用戶特征含義
對用戶的基本信息設立相應的標簽,然后對用戶的標簽進行數值化,將相應的年齡段以及職業轉化為數值形式。具體的年齡轉化方法為:1:0-18歲,18:18-24歲,25:25-34歲,35:35-44歲,45:45-49歲,50:50-55歲,56:56歲以上。具體的職業轉化方法為:0-20:未知,老師,藝術者,行政,學生,服務人員,醫生,管理人員,農民,家庭主婦,青少年,律師,IT人員,退休人員,銷售者,科學家,個體戶,工程師,技術人員,待業人員,作家。其特征標簽如表3所示。

表3 特征標簽
下面通過分類產生新的用戶信息表,將用戶項目評分矩陣轉換為項目特征矩陣,具體轉換方法如式(12)所示。根據得到的矩陣,結合評分矩陣,即可獲得對應的特征矩陣,轉換公式如下

(12)

(13)

4 CPCF推薦算法
為解決傳統推薦算法用戶評分矩陣稀疏、推薦精度不足、無法有效利用用戶信息問題,本文采用改進的權重聚合方法(DFM)進行評分,提出基于用戶畫像的協同過濾推薦算法,。本文算法以用戶-特征矩陣作為原始數據,把整個推薦過程分為改進用戶項目評分矩陣、改進的相似性計算方法和評分并產生推薦結果三部分。
4.1 改進用戶-項目評分矩陣
根據上文中提出的矩陣轉換公式,采集到用戶基本信息后,利用生成的矩陣融合特征,即可獲得對應的特征矩陣,這就是評分矩陣的優化方法。用戶特征矩陣即為用戶畫像,通過用戶畫像中每一個特征對應的權重值可以觀察出該項目受哪些用戶的喜愛。
4.2 改進的相似性計算方法
通常情況下,可利用余弦相似度、Pearson相關系數兩種方法,對用戶相似度展開計算。1994年,Resnick明確提出應用Pearson相關系數[25](PCC)來測量用戶之間的相似度,請參見式(14)

(14)
相關參數含義如下:Iu——u進行過評分的全部項目集合;i——評分項目;ru——u的評分均值。
余弦相似度[26],即判斷空間中任意2向量角度的余弦值,根據該值來分析兩者差異。若兩者計算得到的余弦值與1相差越小,表明兩向量存在的差異非常小,相似度極大。將其運用到推薦算法內,可將向量設置為用戶針對該項目給出的評分值,以此來計算相似度

(15)
下面分三步得到CPsim相似度公式。
首先將用戶畫像融入皮爾遜相關系數公式得到改進的皮爾遜相似度(PCCstrsim),見式(16)所示。在該公式中加入畫像權重后,得到的表達式為(17),即余弦相似度。將完善后的兩個相似度結合,即可獲得CPsim相似度,即表達式(18)。這里將用戶畫像融入皮爾遜以及余弦相似度公式,可以利用用戶的特征信息代替傳統相似度的評分,通過用戶準確的畫像信息獲取相似度可以更加準確的觀察用戶之間的相似程度。最后將兩種改進的相似度公式進行加權,從兩種不同角度統一去判定用戶間的相似程度,有效提高了推薦的準確性。

(16)

(17)

(18)

4.3 評分并進行推薦
結合實際情況,利用實驗的方法尋找最實用的評分法,本次設計中對比WS、DFM兩種算法下獲得的MAE值來選擇相應的評分法,最終確定使用DFM法來獲得相應的評分值。結合表達式(16),對相似度展開計算,獲得鄰居用戶。隨后通過下表達式來預估用戶對該項目的評分值

(19)
以上內容介紹了CPCF推薦的三個主要步驟,具體的推薦流程如圖2所示。

圖2 CPCF推薦算法流程
首先根據數據集提供的用戶評分矩陣,利用性別系數、職業系數以及年齡系數計算公式計算每一個用戶的特征系數,從而獲得項目特征矩陣。獲得特征矩陣后,即可獲得該用戶的畫像。下面將用戶畫像融入PCC相似度和COS相似度,獲得改進的PCCstrsim相似度以及COSstrsim相似度,并對兩種相似度加權求和生成CPsim相似度。其次利用CPsim相似度和改進的權重聚合評分公式獲取用戶評分。以降序的方式,將得到的所有分值進行排列,并把排列在前k的用戶提取出來。
算法描述:

Algorithm 1 Recommendation based on user profile INPUT: Train_User_Item_Rating_MatrixTest_User_Item_Rating_MatrixUser_Profile_Matrix,Label_setOUTPUT: Scoring_Matrix1) for every user in Train_User_Profile_Matrix:2) for every label in Label_set:3) Use improved similarity formula4) Generate user similarity_matrix5) for every user in Test_User_Item_Rating_Matrix:6) for every item in Test_User_Item_Rating_Matrix:7) find the nearest neighbor8) use dfm score prediction formula 9) generate user_item score matrix Return Scoring_Matrix
5 實驗結果分析
本次實驗中獲得的所有數據通過MoviesLens-1M進行收集。在這兩個數據集通過與UBCF等算法進行對比實驗分析,驗證所提推薦算法的性能。在Windows10系統、8G內存、Intel Core i5-4570@2.20GHz處理器條件下完成所有操作。將F1-Score、召回率、MAE、精確率設置為評價指標。
5.1 數據集
本文中所進行的實驗通過MoviesLens-1M、Book-Crossing數據集完成,前者中包含評分、電影、用戶三部分,而實驗中所研究到的職業、年齡、性別等均屬于用戶信息。而評分文件內,評分次數達到一百萬次,總用戶數為6040,電影數量3952,表明該文件中,每位用戶評分過的電影最少有20部。而Book-Crossing數據集由Cai-Nicolas Ziegler在經過4周的爬取,在人類系統 首席技術官Ron Hornbaker的允許下,從Book-Crossing社區中收集。其中包含了278858個用戶對271379個項目的1149780次評分,其中包括用戶信息、書目信息和評分信息。

表4 數據集
5.2 評價指標
為了更好地考慮所提出方法的特性,本文將平均絕對誤差(MAE),精度,均方誤差和F1-Score用作評估指標值。MAE指標值表示預測分析與特定值之間的平均偏差。若獲得的該指標值相對較小,表明該算法推薦的精準率越高。若{ac1,ac2,…,acn}表示為真實評分集合,{pr1,pr2,…,prn}表示為預估分值,則可利用以下表達式來計算MAE

(20)
在所有推薦的項目中,用戶實際喜歡的項目占總推薦項目的比例,即為精確率,因此可根據該指標值的大小,來判斷系統給出的推薦是否精確。而推薦準確的項目數、測試集內所有項目的比值,即為召回率,根據召回率大小可判斷系統所使用的算法是否合適,從而判斷其推薦精度。通常在計算這兩個指標的時候,首先需要根據評分值,把測試集內的項目劃分為正相關、負相關,分值較高的部分,為正相關;而評分后項目集合內,也需要劃分為推薦、不推薦項目。精確率是針對預測結果而言,表示為被推薦的相關項目數量與被推薦的項目總數之比,具體見式(21)所示

(21)
與精確率不同,召回率針對的是原來的樣本,表示為被推薦的相關項目數量與所有相關項目的總數量,具體見式(22)所示
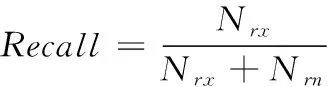
(22)
其中,Nrx——相關項目中,被推薦數;Nbx——不相關項目中,被推薦數;Nrn——相關項目中,未推薦數。
利用算法設計推薦系統時,為提高推薦精度,不僅要分析其精確率,還需要對召回率展開計算,通常可根據兩者加權調和后得到的均值來結合分析,即計算F1-Score值。當得到的值較高時,表明該系統推薦的項目較為準確。其計算公式為
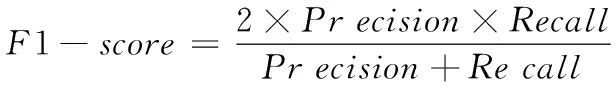
(23)
5.3 實驗結果分析
將操作中采集到的全部數據劃分為5類,其中測試集占比20%,剩余為訓練集。為了增強結果的穩定性,本文使用不同的劃分進行多輪交叉驗證,并把每次的結果取平均值,本文實驗進行了五重交叉驗證。
本文選取鄰居數為5到195,依次遞增10,分別對UBCF算法、SM算法以及本文所提算法的MAE進行比較,比較結果如圖3所示。

圖3 三種算法在不同k值的MAE
圖3中對比了兩個數據集中三種算法的MAE值,從圖中MAE的變化趨勢可以看出,3種算法的MAE都會隨著鄰居數量的變化而變化。當鄰居數量選取較少時,由于只參考了少數人的意見,導致預測評分受個人因素影響較大,CPCF和SM算法中不能給出準確的預測,所以MAE偏高,但是UPCF算法基于用戶進行評分,所以當用戶數較少時也可以給出準確的預測,MAE低于另兩個算法;當鄰居數量逐漸增多時,由于融入更多用戶的參考意見,會有效的改進預測效果,導致MAE有所降低,并且隨著鄰居數量達到峰值,MAE值達到最低。但是由于MoviesLens數據集的數據相較于Book-Crossing數據更加稀疏,導致用戶對于同一項目的評分過多,真實評分的數量降低,所以Book-Crossing上的MAE值要低于MoviesLens。從以上分析來看,本文提出的CPCF算法的MAE值較UBCF等算法最多降低了13%,在推薦性能方面要優于其它兩種算法。
對比不同算法下獲得的召回率、準確率,結果如下圖,前者為橫軸,圖中的點為推薦數值。推薦數值越高,表明該算法下獲得的兩指標值越大。從圖中可以看出,兩個數據集上CPCF均在SM的上方,而SM在UBCF的上方,綜合看來,CPCF算法的準確率與召回率較其它兩種算法依次提高了11%和3%,推薦準確性有所提升。
精確率與召回率在某種程度上是相互矛盾的,如果精確率很高,那么相應的召回率就會很低。兩種評價指標對于算法性能的評價還有所弊端,所以這里利用F1-score綜合兩種評價指標的優缺點,更全面的評價三種算法的性能。對不同算法下計算的F1-score值展開對比分析。
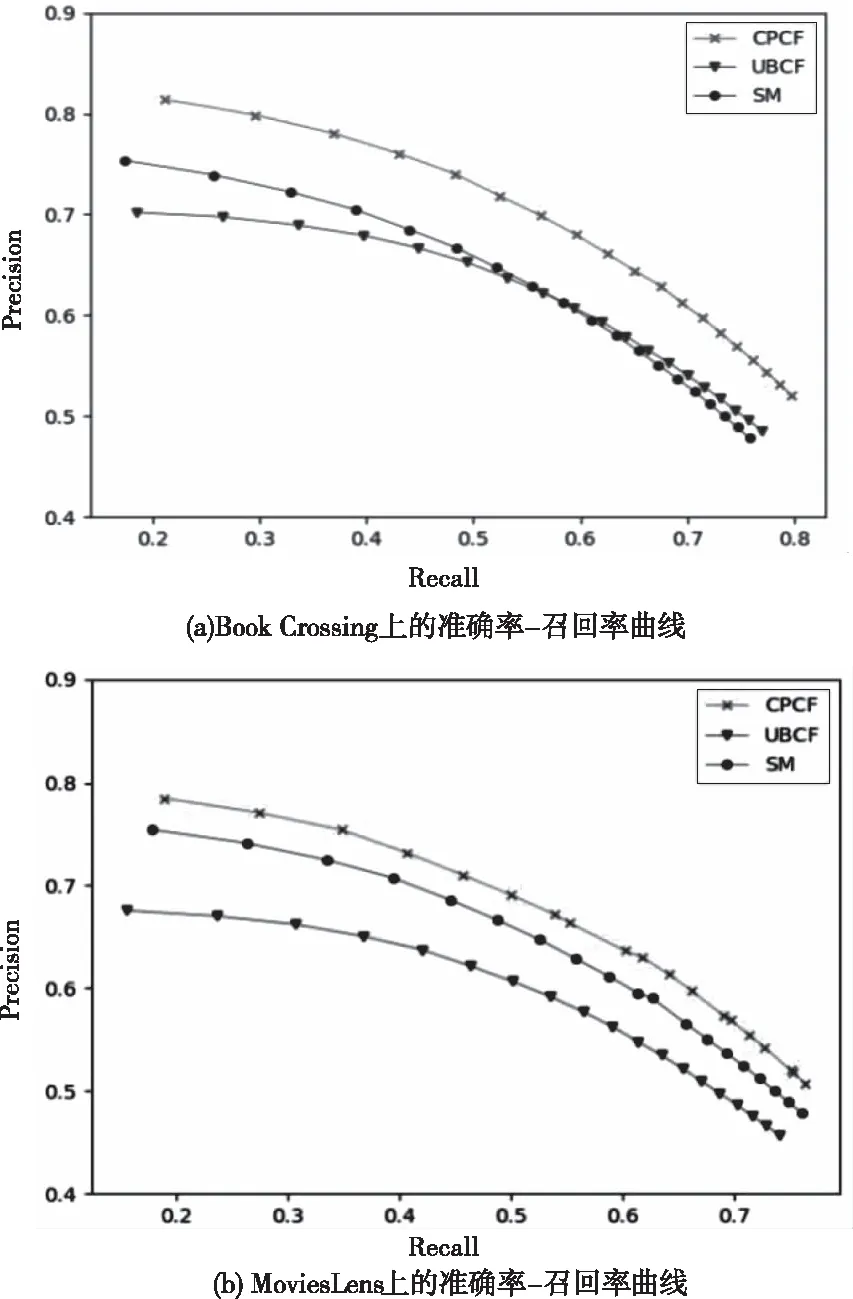
圖4 三種算法在不同k值的準確率-召回率

圖5 三種算法在不同k值的F1-Score
從圖5可以看出,在兩個數據集上隨著k值的增加,三種算法的F1-score均逐漸上升,k為9時F1-score達到最高點。兩個數據集的CPCF與SM的F1-score差異很小,但是都要優于UBCF算法,說明隨著鄰居數量的增加,UBCF算法整體性能較差。但是MoviesLens數據集更加稀疏,所以Book-Crossing的F1-score要優于MoviesLens。Book-Crossing中CPCF性能最優,較UBCF等算法提高了4%,表明該算法在整體性能方面要優于其它兩種算法。
6 結語
本文針對傳統協同過濾推薦算法面對稀疏數據計算相似度不準確,導致推薦效果不佳的問題,利用用戶的年齡、性別、職業三種基本信息,將用戶特征進行數值化,計算用戶特征系數。根據相應的公式計算特征系數,進而獲得相應的用戶特征,該特征即可作為用戶畫像輸入到系統內。然后將用戶畫像融入改進的皮爾遜相關系數和改進的余弦相似度中,進行線性加權得到CPsim相似度。最終利用改進的權重聚合公式(DFM)進行評分得到推薦結果。
在兩個數據集上的實驗表明,該算法較UBCF等算法平均絕對誤差降低13%,精確率提高11%、召回率和F1-score分別提高了3%和4%,有效改善了推薦性能。在現實生活中用戶特征會隨時間的推移有所變化,導致推薦結果受到一定影響,因此在后續工作中考慮將時間特征信息中的數據融入CPCF算法,進一步提高推薦效果。除此之外本文構建信息標簽時只考慮了用戶性別、年齡和職業信息,未考慮其它重要特征,今后的研究中可以考慮加入家庭住址、興趣愛好、學歷以及有無配偶等信息,豐富用戶畫像,從而改善推薦性能。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
