資源匱乏多語言的語種辨識技術研究
2022-02-09 02:05:04毛雪麗米吉提阿不里米提艾斯卡爾艾木都拉
計算機仿真 2022年12期
毛雪麗,米吉提·阿不里米提,艾斯卡爾·艾木都拉
(新疆大學信息科學與工程學院,新疆 烏魯木齊 830046)
1 引言
語種識別,是通過計算機對給定的語音信號進行分析處理、自動識別其所屬語言種類的過程[1]。作為語音識別及相關領域的一個前端技術,語種識別也被稱為語言辨識。隨著全球化的發展,跨國語言交流日益增多,導致多語言共生的現象頻繁出現,許多領域對語種識別及相關技術的需求也愈加迫切,進而推動了語種識別在多語言語音處理方面的發展。國際上和國內的眾多研究機構,如MIT林肯實驗室,卡耐基梅隆大學,國內的中科院自動化所、中科院聲學所、中科大等,對語種識別技術進行了廣泛的研究[2]。但國內外的研究主要集中在英語,法語,西班牙語、德語、阿拉伯語等通用語言上,而對資源匱乏語言的研究相對較少,尤其是資源匱乏的同語系語言的語種識別。一是由于語料資源的缺少,主要表現在語音數據、文本數據、音素集、發音詞典等方面。二是由于語言的復雜性和個異性較強,使得不同語言在語音和語法層次有較大的差異性,使得該類語言的語種識別研究面臨極大的挑戰。
2 相關工作
早期的語種識別屬于傳統方法,主要是基于音素特征和基于聲學特征的語種識別等。基于音素特征的語種識別利用不同語種的音素搭配關系作為差異特征。利用音素識別器,得到語音信號的最優音素序列,根據這個序列為每個語種建立N-Gram模型。基于聲學特征的語種識別,通過提取語音信號的聲學特征,采用概率統計對其進行建模。常用的聲學特征有梅爾頻率倒譜系數(Mel-Frequency Cepstral Coefficient,MFCC)[3]、感知線性預測系數(Perceptual Linear Predictive,PLP)[4]、移位差分倒譜系數(Shifted Delta Cepstrum,SDC)[5]等。主流的語種識別系統主要有高斯混合模型-全局背景模型(Gaussian Mixture Model-Universal Background Model,GMM-UBM)[6]、高斯超向量-支持向量機(GMM SuperVector-SupportVector Machines,GSV-SVM)[7]和基于全差異空間(Total Tariability,TV)[8]的i-vector 系統等。
近年來,深度神經網絡(Deep Neural Networks,DNNs)[9]模型被應用于語種識別,并取得了良好的發展。一方面是從特征提取出發,文獻[10]利用DNN提取了深度瓶頸特征(Deep Bottleneck Feature,DBF);另一方面是從模型出發,文獻[11]提出了基于深度神經網絡的全差異空間(Total Varaibility,TV)建模方法 進行了語種識別。此外,也出現了深度學習端到端語種識別系統。2014年Google的研究人員將特征提取、特征變換和分類結合到一個神經網絡模型中,這是端到端系統首次應用于語種識別任務中[12]。在這之后,研究者開始采用不同的神經網絡進行語種識別的研究,包括時延神經網絡(Time-Delay Neural Network,TDNN)[13],長短時記憶遞歸神經網絡(Long Short Term Memory-Recurrent Neural Network,LSTM-RNN)[14]等。2016年,Geng等人[15]將注意力機制模型(Attention-based model)引入到語種識別系統中。2017年,Bartz等人[16]利用混合卷積遞歸神經網絡(CRNN)進行語種識別。
在文獻[16]的工作基礎上,本文利用CNN-BiGRU模型對同語系(阿爾泰語系的哈薩克語和維吾爾語、漢藏語系的漢語和藏語)和跨語系(哈薩克語、維吾爾語、漢語和藏語)語言進行了研究。首先將語音數據轉化為相應的灰度語譜圖,其次利用CNN提取語譜圖的空間特征,之后運用BiGRU提取語譜圖的時間序列信息,最終輸出語種的分類結果。本文結構安排如下:第三部分介紹采用的的方法,第四部分介紹實驗設置,第五部分描述實驗并分析結果,第六部分進行總結。
3 本文方法
3.1 語譜圖生成
語譜圖是語音信號在圖像域的一種表示方法,它能夠表示語音信號不同頻段的強度,可以通過傅里葉變換從語音信號中產生。語譜圖的橫坐標表示時間,縱坐標表示頻率,同時語譜圖中顯示了大量與語音特性有關的重要信息。圖1為語音波形及語譜圖示例。其中(a)、(b)分別為維吾爾語(Uyghur)的語音波形和語譜圖;(c)、(d)分別為哈薩克語(Kazakh)的語音波形和語譜圖。語音信號的語譜圖特征的提取流程如圖2所示。
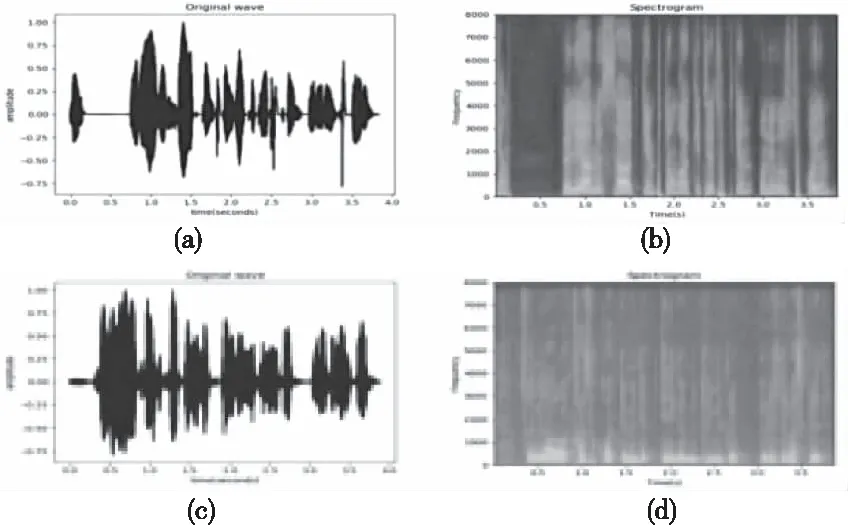
圖1 語音波形及語譜圖示例
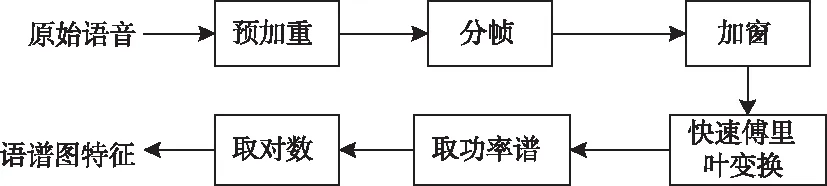
圖2 語譜圖特征的提取流程
在提取特征之前,通常要對語音信號進行預處理,預處理包括預加重、分幀和加窗。語譜圖特征提取的具體步驟如下所示:
1)預加重:將原始語音通過一個高通濾波器,其濾波器函數如式(1)所示。
H(Z)=1-μ/z
(1)
其中,μ值通常介于0.9-1之間,一般選μ值為0.97。
2)分幀:語音信號具有短時平穩性。因此,要進行短時分析,需要進行分幀。分幀時,相鄰兩幀之間存在重疊部分,是幀移,可以使得相鄰兩幀可以平滑過渡。常用的幀長為25ms,幀移為10ms。
3)加窗:為了避免頻譜的混疊。常見的窗函數有漢明窗(Hamming)、漢寧窗(Hanning)等。漢明窗函數如式(2)所示。
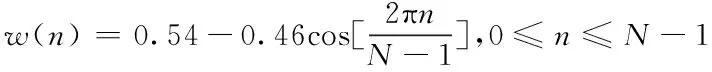
(2)
4)快速傅里葉變換:語音信號完成預處理后,采用快速傅里葉變換(fast Fourier transform,FFT)將語音信號從時域轉換到頻域,計算過程如式(3)所示
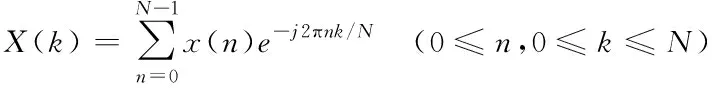
(3)
其中,x(n)是離散時域的語音信號,X(k)是頻域的語音信號,N表示傅里葉變換的點數,N=0,1,…,n-1。
5)取功率譜:將語音信號的頻譜取模的平方,得到語音信號的功率譜。
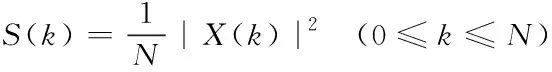
(4)
其中,X(k)是頻域的語音信號,S(k)是語音信號的功率譜,N表示傅里葉變換的點數。
6)取對數:對功率譜進行取對數運算,得到語譜圖特征。
3.2 雙向門控循環單元
卷積網絡對圖像進行處理時,是把圖像整體送入網絡,進行一層一層的卷積運算,因而卷積網絡對圖片的分類有較好的效果。但是,對于與時間序列相關的任務,卷積網絡的表現會相對遜色一些。因此,采用了循環網絡,它可以很好的處理時間序列任務。Cho等人[17]提出門控循環單元(Gated Recurrent Units,GRU),雙向門控循環單元(Bidirectional GRU,BiGRU)是由前向和后向的GRU構成,是一種雙向的網絡結構。其中,前向GRU學習當前時刻之前的信息,而后向GRU學習當前時刻以后的信息,因此該網絡能夠學習到時間上下文信息,從而彌補卷積網絡的不足。BiGRU網絡由輸入層、前向GRU和后向GRU以及輸出層等四部分組成,其網絡結構如圖3所示。
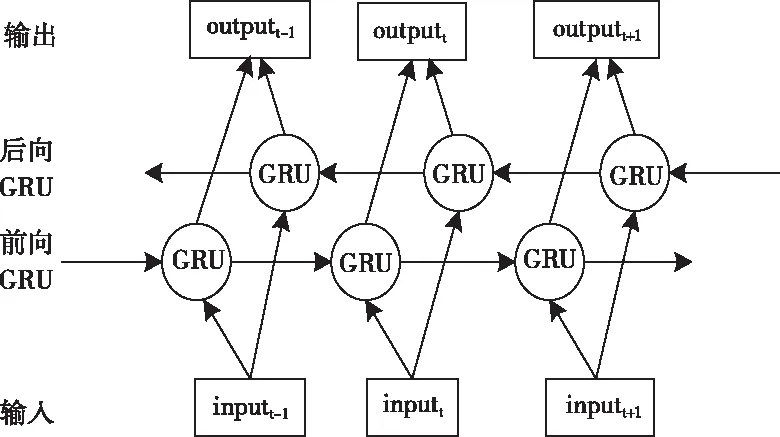
圖3 BiGRU網絡結構
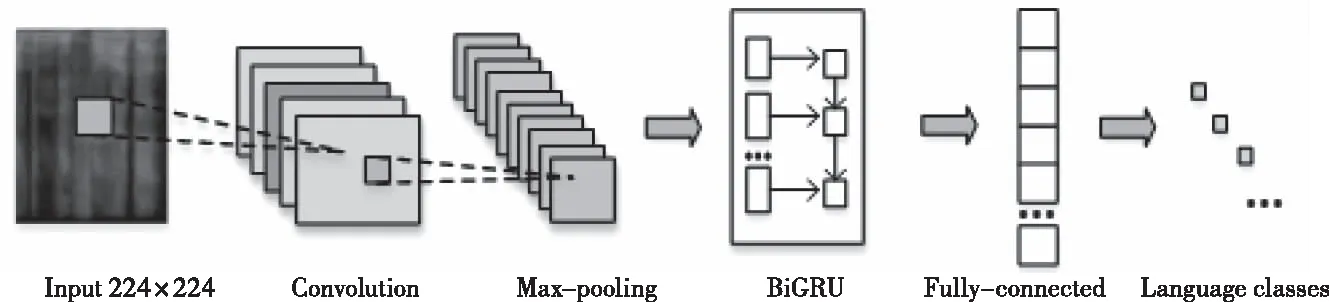
圖5 基于CNN-BiGRU的語種識別網絡結構
其中,inputt-1、inputt、inputt+1分別表示t-1、t、t+1時刻所對應的輸入,outputt-1、outputt、outputt+1分別表示t-1、t、t+1時刻對應的輸出。前向GRU,是指沿著時刻的正向順序,計算其輸出。后向GRU,指沿著時刻的反向順序,計算其輸出,最后在相應的時刻將二者的輸出一起作為最后的輸出。與LSTM相比,GRU少了存儲單元的設置,它通過隱藏狀態來信息傳遞,從而使其網絡中的學習參數量減少。GRU有更新門和重置門,其中,更新門能夠抑制被遺忘的信息和被添加的新信息;重置門可以反映了對先前信息的遺忘程度。通過更新門和重置門,GRU可以實現對輸入值、記憶值和輸出值的控制,GRU的結構如圖4所示。
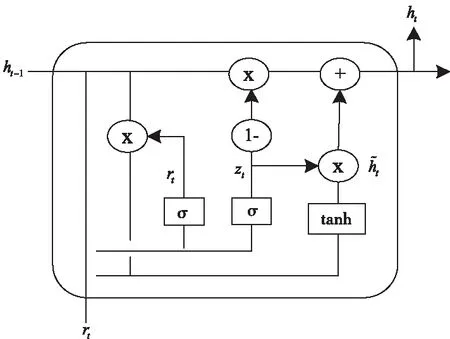
圖4 GRU網絡結構
在t時刻,GRU更新的過程如以下的計算公式所示
rt=σ(Wr·[ht-1,xt])
(5)
zt=σ(Wz·[ht-1,xt])
(6)
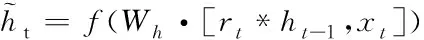
(7)

(8)
3.3 基于CNN-BiGRU的語種識別模型
本文采用CNN-BiGRU網絡進行語種識別,該網絡主要包括兩個部分。第一部分為卷積網絡,能夠提取語譜圖的局部特征;第二部分是雙向門控循環單元網絡,可以更好地捕捉語譜圖中的時序信息。卷積網絡使用4個卷積層和4個最大池化層。其中,卷積層中卷積核的大小和數目分別為(7*7,16),(5*5,32),(3*3,32),(3*3,32)。每個最大池化層中卷積核的大小為3*3,步長為2。BiGRU中含有1024個神經元(前向和后向的GRU各有512個神經元),之后送入全連接層,實現分類。基于CNN-BiGRU的語種識別網絡結構如圖5所示,該網絡各層的參數信息如表1所示。
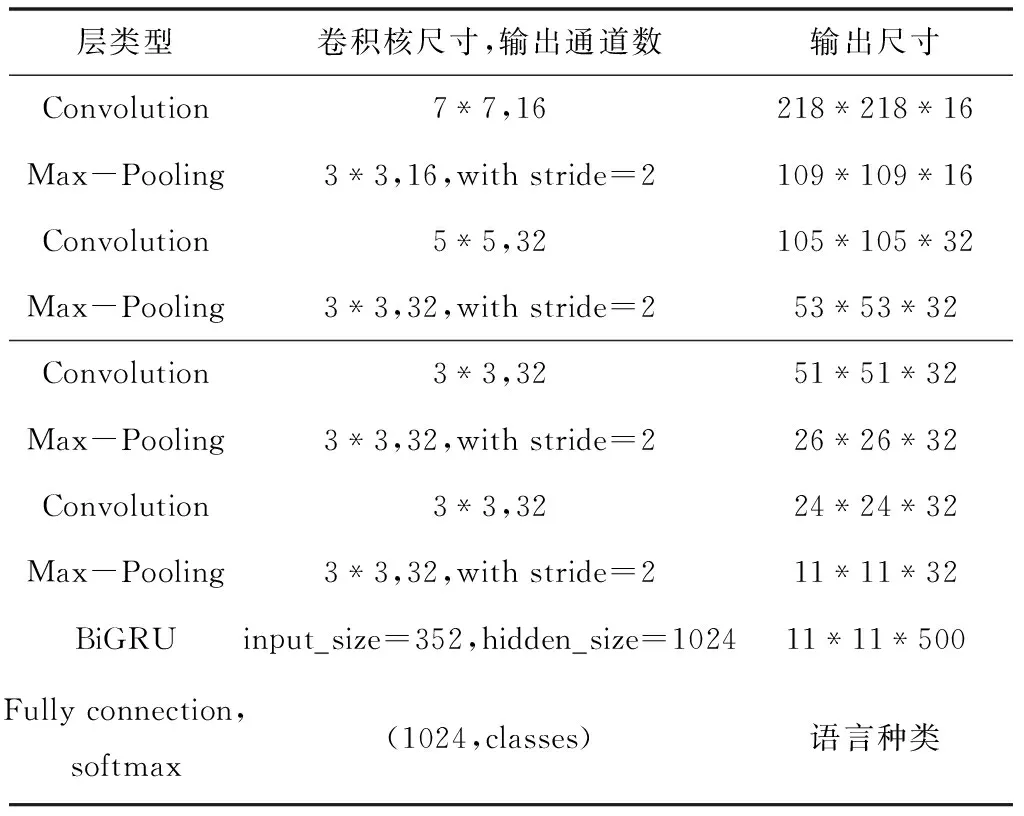
表1 CNN-BiGRU網絡各層的參數信息
4 實驗
4.1 實驗數據集
東方語種識別比賽(AP17 Oriental Language Recognition)的任務是識別漢語、粵語、維吾爾語、哈薩克語等東方語言[18]。本文在該比賽提供的數據集上進行實驗,該數據集包含由M2ASR NSFC[19]項目提供的維吾爾語,哈薩克語和藏語三種少數民族語言。本文從東方語種數據集中抽取維吾爾語、哈薩克語、漢語、藏語等4種語言,每種語言各1800條語音數據,按照70% (訓練集)、20% (驗證集)、10% (測試集)的比例進行劃分,數據集結構如表2所示。
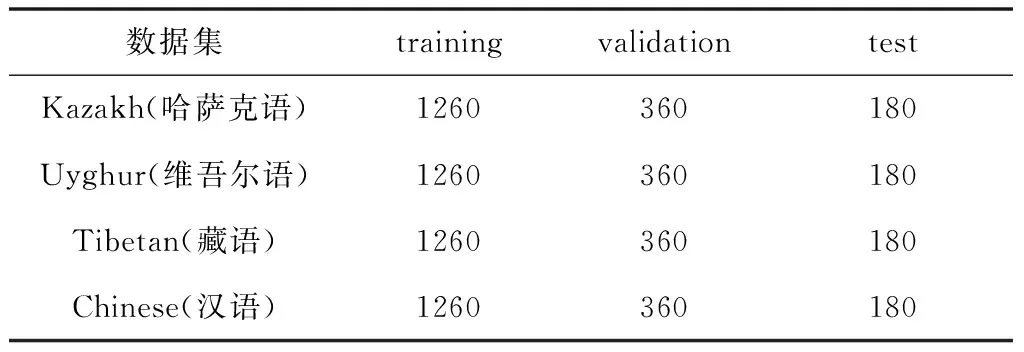
表2 數據集結構
4.2 實驗設置
本文利用pytorch框架,在NVIDIA GeForce GTX 1080GPU上搭建語種識別模型進行實驗。將語音數據經過預處理和特征提取后輸入到語種識別模型,訓練和驗證網絡模型時,其輸入為224*224的灰度語譜圖,批量大小為32*32(batch size),采用Adam優化器,學習率為0.002,損失函數采用交叉熵函數。采用的性能評估指標有精確率、召回率、準確率和F1值。精確率(Precision,P)是指模型預測正確的正例數占預測為正例總樣本的比例。召回率(Recall,R)是指模型預測正確的正例數占真正的正例樣本的比例。準確率指(Accuracy,acc)是指模型正確分類的樣本占總樣本的比例,F1是一個綜合評價指標,是精確率和召回率的調和平均值。準確率和F1值越高,則表明模型的識別效果越好。
5 實驗結果分析
本文實驗分為兩部分,第一部分是采用本文研究的模型(CNN-BiGRU)對不同的語音特征進行實驗,第二部分是采用不同的模型對最好的特征進行實驗。使用相同的數據集,不斷訓練學習,調整參數優化結果,選取最優的結果進行對比。
5.1 不同特征對比實驗
選取語譜圖特征、FBank特征、MFCC特征等三種不同的特征提取方式,使用本文研究的模型分別對同語系語言(阿爾泰語系的維吾爾語和哈薩克語、漢藏語系的漢語和藏語)以及跨語系語言(維吾爾語、哈薩克語、漢語和藏語)進行實驗,分析模型CNN-BiGRU在不同特征下的效果。實驗結果如表3、4、5所示。
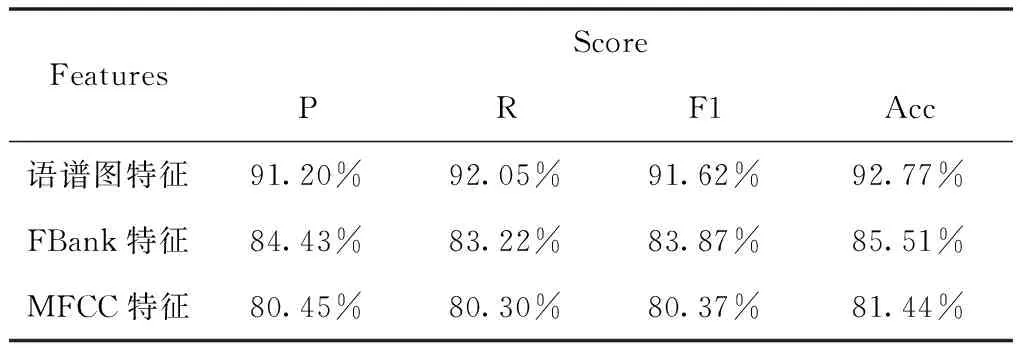
表3 特征對比實驗結果(維吾爾語和哈薩克語數據集)
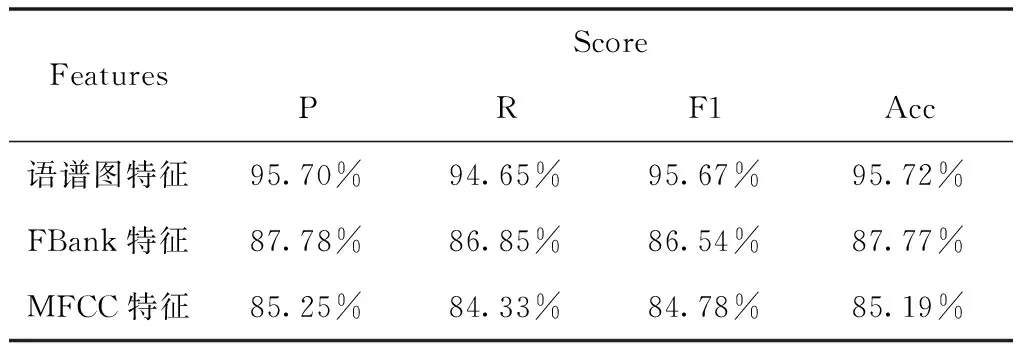
表4 特征對比實驗(漢語和藏語數據集)
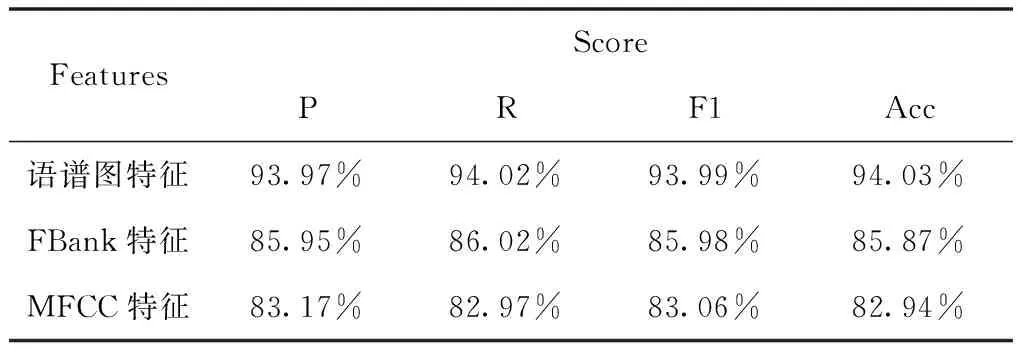
表5 特征對比實驗結果(維吾爾語、哈薩克語、漢語和藏語數據集)
從表3、4、5中可以看出,在語譜圖特征、FBank特征、MFCC特征等三種特征之中,使用語譜圖特征進行實驗的效果最好,而使用MFCC特征進行實驗的效果最差,這是由于語譜圖特征是語音數據的頻域表示,包含的語音信息最為豐富,而FBank、MFCC特征是在語譜圖基礎上進行一系列變換生成的,會導致部分語音信息丟失,從而影響實驗效果。同時可以看出在同語系(阿爾泰語系、漢藏語系)語種識別中,漢藏語系的漢語和藏語的識別效果要優于阿爾泰語系的維語和哈薩克語,這是由于漢語和藏語之間的發音差異遠比維吾爾語和哈薩克語大,使得網絡提取和學習特征更容易,識別效果更好。
5.2 不同模型對照實驗
設置CNN、GRU、LSTM、CNN-BiLSTM、CNN-BiGRU等五種模型作為對照實驗,分別對同語系語言 (阿爾泰語系的維吾爾語和哈薩克語、漢藏語系的漢語和藏語) 以及跨語系語言 (維吾爾語、哈薩克語、漢語和藏語) 的語譜圖特征進行實驗,分析不同模型在語譜圖特征下的性能。實驗結果如表6、7、8所示。
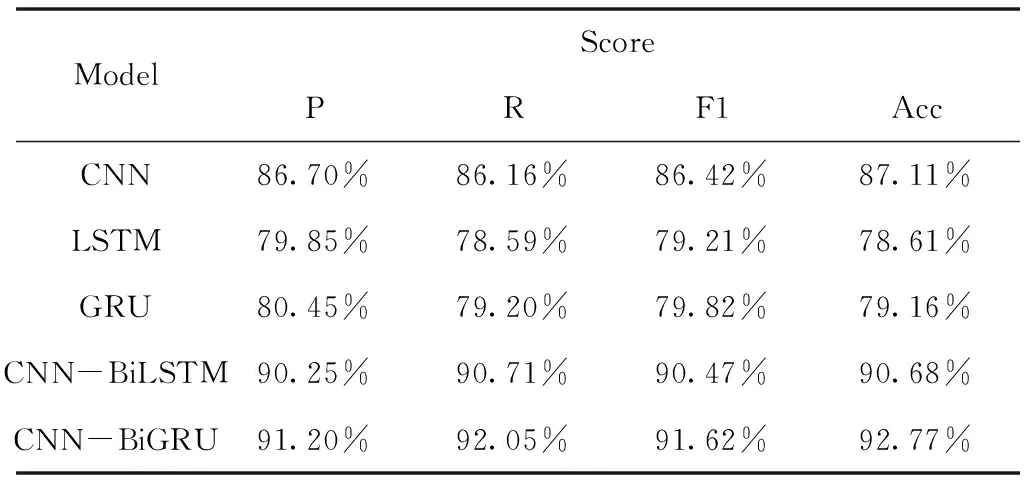
表6 模型對比實驗結果(維吾爾語和哈薩克語數據集)
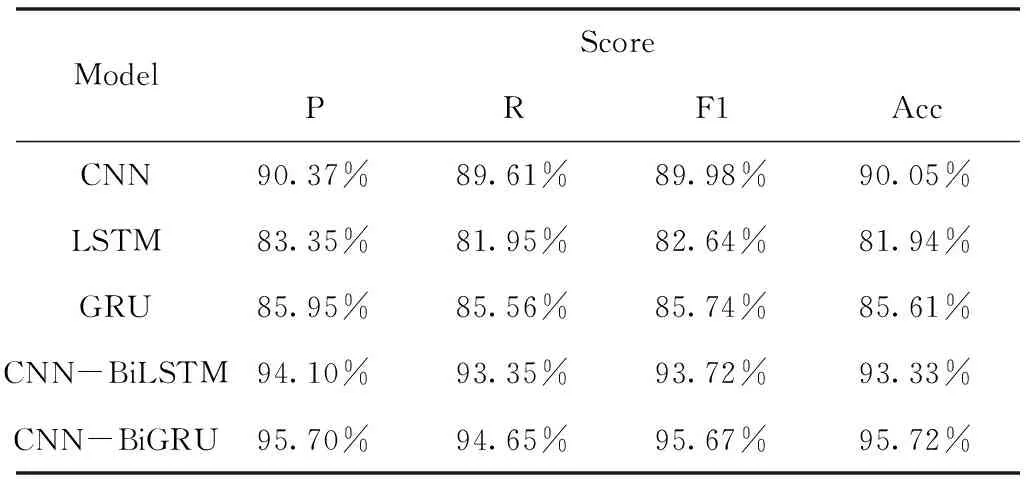
表7 模型對比實驗結果(漢語和藏語數據集)
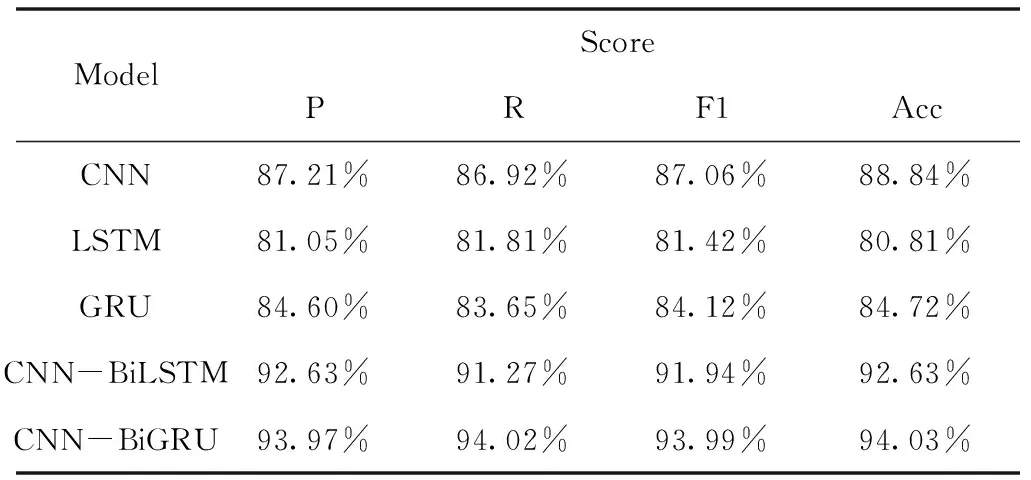
表8 模型對比實驗結果(維吾爾語、哈薩克語、漢語和藏語數據集)
從表6-8可看出,LSTM模型的的F1和Acc均為幾種模型中最低的,這是由于LSTM主要關注的是時序信息,無法像卷積網絡一樣很好地捕捉到語譜圖的圖像特征。對比幾種不同的循環神經網絡模型,可以看出,GRU模型作為LSTM模型的優化,兩者的性能非常接近,但是GRU模型的性能比LSTM模型略好。同時CNN與GRU/LSTM兩種模型融合后的網絡性能均優于CNN、GRU和LSTM模型。其中CNN-BiGRU的準確率相對CNN、GRU有所提升,CNN-BiLSTM的準確率相對CNN、LSTM亦是如此,說明融合后的網絡能夠更好地利用語譜圖圖像特征和時序信息,從而提升語種識別的準確率和F1值,獲得較好的結果。
6 總結
本文構建了CNN-BiGRU網絡語種識別模型,對兩個同語系語言(阿爾泰語系的維吾爾語、哈薩克語,漢藏語系的漢語和藏語)和跨語系語言(維吾爾語、哈薩克語、漢語和藏語)進行了語種識別。通過提取不同的特征和設置不同模型的比較實驗,進行了結果分析。實驗發現,最有效的特征是語譜圖特征,表現最好的模型是CNN-BiGRU網絡。實驗提取語音數據的有效特征,并提取語譜圖的視覺特征和時序信息特征,將其送入神經網絡模型訓練學習,最終分類輸出語言類別。通過實驗可以表明,本文提出的方法在同語系語言及跨語系語言的語種識別上都取得了較好的結果,但是本文涉及的語種較少,語料數據也比較少。在接下來的工作中,將會繼續在較大語料以及其它語種、方言上進行語種識別的探索,進一步開展相關研究。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
文苑(2020年4期)2020-05-30 12:35:30
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
