用于體質量估測的黃羽雞姿態關鍵幀識別與分析
2022-02-08 13:07:16張小敏張延寧朱逸航饒秀勤
農業機械學報 2022年12期
張小敏 徐 濤 張延寧 高 源 朱逸航 饒秀勤
(1.浙江大學生物系統工程與食品科學學院, 杭州 310058; 2.浙江省農業智能裝備與機器人重點實驗室, 杭州 310058)
0 引言
體質量是家禽的重要生長指標之一,也是種雞選育的重要參考依據。家禽的體質量與經濟效益直接相關,體質量信息可用于判斷家禽最佳出欄時間、指導日常飼喂、判斷是否患病等[1-2]。目前家禽體質量測量可分為人工測量法、稱量裝置測量法和機器視覺監測法。傳統的人工測量法耗時、費力,易造成家禽的應激反應,且獲得的體質量信息不全,不具有時間連續性[3]。稱量裝置測量法不會引起家禽的應激反應,但此類傳感器存在安裝復雜、維護困難等問題,且在養殖后期,體質量較大的肉雞相比其他肉雞,上秤頻次低,造成體質量低估[4]。相比而言,機器視覺監測法具有實時客觀、非侵擾性、可維護性強等優點,可以提高測量效率。
基于機器視覺技術的畜禽體質量估測已取得了一定的進展[5-10],但目前主要依靠人工選取家禽理想姿態幀,主觀性強且耗時費力,難以在家禽體質量自動估測中應用。因此,研究用于家禽體質量估測的理想姿態識別算法具有重要意義。
在動物個體姿態識別方面,LEROY等[11]通過點分布模型擬合蛋雞圖像,描述蛋雞的姿勢信息,能夠自動識別母雞的站立、行走和抓撓行為。POURSABERI等[12]通過分析牛的背部姿態來識別跛行,通過檢測背部輪廓的弧度并通過脊椎線上的選定點擬合圓來檢測背部姿態。勞鳳丹等[13]基于10個特征量使用貝葉斯分類法對蛋雞行為進行識別,能夠識別單只蛋雞的拍翅膀、修飾、休息、探索、抖動和舉翅膀等行為。勞鳳丹等[14]基于深度圖像對蛋雞行為識別進行了研究,結果表明算法對蛋雞的采食、躺、站和坐的識別準確率分別為90.3%、91.5%、87.5%和56.2%。司永勝等[15]提出了一種基于Kinect的豬體理想姿態檢測算法以提高圖像利用率和體尺測量效率,算法利用投影法和差分法識別頭部和尾部位置,利用骨骼化算法結合霍夫變換算法檢測豬體頭部是否歪斜,對于52 016幀圖像檢測出理想姿態2 592幀、漏報432幀、誤報0幀。
隨著深度學習技術的發展,卷積神經網絡技術在動物個體姿態識別領域得到了較多應用[16-18]。文獻[19-20]提出了采用單幅圖像識別豬只立臥姿態的方法,利用建立的豬只識別模型和頭尾識別方法,將待測豬圖像調整到水平狀態,構建了豬只立臥姿態識別模型,精度達到了95%。LUO等[21]提出了一種輕量級的通道注意力模型,用于實時識別豬只的站立、趴臥、側臥、坐姿和攀爬5種姿勢,該算法對上述5種姿勢的平均識別精度分別為97.7%、95.2%、95.7%、87.5%和84.1%,單幅圖像的推理速度約為63 ms。薛月菊等[22]提出了一種融合2D-3D卷積特征的哺乳母豬姿態轉換識別算法,模型姿態轉換識別準確率為97.95%,召回率為91.67%,測試速度為14.39 f/s。FANG等[23]利用多部位目標檢測方法對單只肉雞的側面圖像進行姿態估計,利用ResNet50和特征金字塔(FPN)結構[24]構建特征提取器,算法對單個肉雞姿態估計的準確率和召回率分別為91.9%和86.5%。
基于機器視覺的家禽姿態識別相關研究已取得一定進展,但目前依舊存在以下問題:當雞只處于低頭、展翅、梳理羽毛或坐姿等姿態時,雞只寬度、體積、背高等特征參數的提取會受到影響,易造成體質量預測的誤差較大;而家禽處于站立姿態時,身體直立無多余動作,這樣的姿態對于特征的提取更加穩定,因此站立姿態可認為是家禽體質量估計時的最理想姿態[5,7-8],但目前適用于家禽體質量估計的站立姿態識別方法缺乏,且由于家禽為非合作對象,適于體質量估計的理想姿態在視頻中出現較少,樣本不均衡問題突出,研究者難以獲得較好的理想姿態識別精度。
針對上述問題,本文以882黃雞為試驗對象,提出SE-ResNet18+fLoss網絡,從視頻中篩選符合體質量估計的姿態關鍵幀,模型融合注意力機制SE模塊和殘差結構,并改進損失函數,通過Focal Loss監督信號來解決樣本不平衡問題,同時引入梯度加權類激活圖(Gradient-weighted class activation mapping,Grad-CAM)[25]對末端分類規則的合理性進行解釋,反映每一類姿態所關注的重點區域。在連續視頻上進行模型的驗證與黃羽雞姿態特性的分析,為家禽行為研究提供參考依據。通過試驗驗證本文提出的姿態關鍵幀識別模型對于提升黃羽雞體質量估測精度的有效性。
1 試驗材料
1.1 數據采集
試驗數據采集于浙江省湖州市,共采集4個批次,采集時間分別為2019年12月5—6日、2020年8月22—24日、2022年6月4日和2022年6月11日。將4個批次的數據分別標記為D1、D2、D3和D4,具體數據集如表1所示。其中,D1為單只雞連續24 h視頻片段;D2為20只雞視頻片段,其中有18只雞平均采集1.5 h,采集時間為08:00—17:00,其余2只平均采集15 h,采集時間為17:00—08:00;D3和D4為同一批20只雞的2周次視頻片段,每只雞采集10 min,采集時間為08:00—12:00,采集視頻的同時,利用電子秤獲得其實際體質量,電子秤為大紅鷹無線款32 cm×42 cm,精度為0.05 kg。本文的試驗對象為882黃雞,平養于4.50 m×2.50 m的空地區域,內側配有料槽和飲水器,雞只可自由采食和飲水。當采集數據時,將待測雞只轉移至試驗籠中,試驗籠尺寸為1.45 m×0.97 m×1.30 m,光照時間段為08:00—17:00。

表1 試驗數據集Tab.1 Datasets of experiment
如圖1所示,試驗籠主要由攝像機、網線、硬盤錄像機、飲水器、腳墊、飼料槽和糞槽組成。籠子正上方架設了一臺海康威視雙光譜攝像機(DS-2TD2636-10型),攝像機機芯距離腳墊的高度為1.45 m,攝像機通過網線連到硬盤錄像機(DS-8616N-I8型),以4 f/s的速度拍攝彩色視頻圖像,單次采集僅拍攝一只雞,圖像分辨率為1 920像素×1 080像素,并將采集到的視頻數據以avi格式存儲至硬盤錄像機中,之后導入本地計算機進行視頻分析,為了方便后續處理,所有視頻都將解碼為jpg格式的圖像。

圖1 視頻采集示意圖Fig.1 Sketch of video acquisition1.攝像機 2.網線 3.硬盤錄像機 4.籠子 5.腳墊 6.糞槽 7.飲水器 8.飼料槽 9.雞只
1.2 黃羽雞姿態關鍵幀定義
按照家禽的行為特征,可將黃羽雞姿態分為站立、低頭、展翅、梳理羽毛和坐姿。其中,坐姿的定義包含了腹臥情況。此外,當雞只被遮擋時也無法進行體尺參數提取,故將遮擋情況也加入數據集進行識別,共6種姿態情況,表2為每種姿態情況定義的詳細說明。本文提出只有當雞只處于站立姿態時,當前幀才被認為是姿態關鍵幀,方可進行后續的體尺參數提取與體質量估測研究。
1.3 數據集準備
D1、D2兩批次采集的視頻文件共68個,單個文件時長為80 min左右。將所有視頻解碼為圖像后,從D2批次中挑選4 295幅圖像作為數據集,覆蓋每一只雞。最終得到站立、低頭、展翅、梳理羽毛、坐姿和遮擋情況的姿態圖像數量分別為1 017、968、74、802、507、927幅,圖像分辨率均為1 920像素×1 080像素。將所有圖像人工標注姿態類別,每個類別按照7∶2∶1的比例劃分為訓練集、驗證集和測試集,訓練集總計3 002幅,驗證集861幅,測試集432幅。數據集中各個姿態類別的數量如表3所示,觀察表3可知,數據集中6種姿態類別數量相差較大,會帶來數據分布不均衡問題。此外,D1批次視頻數據也作為測試集以分析雞姿態分布特性,視頻采樣間隔為1 min/幅,共得到1 935幅圖像。D3和D4批次視頻數據作為4.5節中不同姿態下體質量估測結果分析的數據集,分別從D3和D4批次視頻數據中截取3 min進行采樣,采樣間隔為1 s/幅,共得到7 200 幅圖像,用于后續體質量估測研究。

表2 黃羽雞姿態情況定義Tab.2 Definition of yellow-feathered chicken posture conditions
2 雞只姿態關鍵幀識別模型
2.1 模型網絡結構
建立SE-ResNet18+fLoss模型,將SE模塊[26]與ResNet18[27]進行融合,并改進損失函數,通過Focal Loss[28]監督信號來解決樣本不平衡問題,網絡結構如圖2所示。SE模塊的核心思想是通過網絡根據損失函數去學習特征權重,使得有效的特征圖權重大,而無效或效果不顯著的特征圖權重小,篩選出針對通道的注意力,通過引入SE模塊,模型能夠從網絡特征通道層面進一步提升網絡性能。

表3 數據集中各個姿態類別圖像數量

圖2 SE-ResNet18+fLoss網絡結構圖Fig.2 Network architecture of SE-ResNet18+fLoss

在連續的雞只視頻數據中,6類姿態的數量分布差異較大,尤其是展翅姿態,數量較少。針對樣本類別不平衡問題,本文通過Focal Loss損失函數減少易分類樣本的權重,使得模型在訓練時更專注于難分類的樣本。Focal Loss損失是基于標準交叉熵損失的基礎上修改得到的,對于二分類問題,交叉熵損失函數可以表示為
CE(pt)=-lnpt
(1)

(2)
式中pt——預測為真實類別的概率
CE——交叉熵損失函數
p——模型對于類別y=1所得到的預測概率
為了解決類不平衡問題,Focal Loss首先添加權重因子αt,其次,在交叉熵前添加權重因子(1-pt)γ,以減少置信度很高的樣本損失在總損失中的比重,最終得到Focal Loss為
LF(pt)=-αt(1-pt)γlnpt
(3)
式中αt——權重因子,用于抑制正負樣本的數量失衡,αt∈[0,1]
LF——Focal Loss損失函數
γ——調制因子,用于增加難分樣本的損失比例,γ≥0
2.2 模型可解釋性
由于本文的模型為圖像分類網絡,無法像目標檢測網絡那樣給出目標邊界框,為了對姿態識別結果進行可視化解釋,采用Grad-CAM來解釋網絡進行分類時重點關注的區域。Grad-CAM相比于CAM更具一般性,其利用網絡反向傳播的梯度計算出特征圖每一個通道的權重從而得到熱力圖,因此Grad-CAM可以直接用于各種卷積神經網絡,無需重新訓練網絡。

(4)
式中Z——特征圖的像素個數
yc——網絡針對類別c預測的得分,這里沒有經過softmax激活
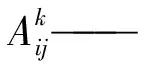
(5)
式中Ak——特征層A的第k通道
2.3 模型訓練環境
模型訓練平臺為超威服務器,CPU為Intel(R) Xeon(R) Gold 6147M 2.50 GHz,GPU為 NVIDIA TITAN RTX,內存256 GB,操作系統為Ubuntu 18.04.1,深度學習框架為Pytorch,CUDA 版本為10.0。
2.4 模型評價指標
采用精確率(Precision,P)、召回率(Recall,R)、F1值和識別速度4個指標來評價模型的識別性能。精確率表示正確預測為正樣本占全部預測為正樣本的比例,召回率表示正確預測為正樣本占全部實際為正樣本的比例,F1值為精確率和召回率的調和平均值,識別速度為每秒內處理的圖像幀數。考慮到每個類別樣本數量不均衡,最終模型的總體評價指標均采用加權平均值(weighted avg)。
3 體質量估測方法
3.1 圖像特征提取
為了驗證本文提出的姿態關鍵幀對于提升黃羽雞體質量估測精度的有效性,進一步設計了稱量試驗,對D3和D4批次視頻數據采樣得到的數據集進行分析,比較不同姿態下黃羽雞體質量估測的精度。
首先采用Unet網絡[29]對D3和D4批次視頻數據采樣得到的7 200幅數據進行分割,Unet模型采用D1和D2兩批次數據中采樣得到的1 000幅圖像按照7∶2∶1的比例劃分訓練集、驗證集和測試集進行訓練得到,對原始雞只彩色圖進行分割后的圖像如圖3b所示。接著對分割后的圖像進行一維和二維特征提取,用于后續黃羽雞體質量估測模型的建立。參照文獻[6-9],本文提取的一維特征包括周齡O,二維特征包括投影面積A、周長P、寬度D、長度L、最大內切圓半徑R和偏心率E,二維特征提取的示意圖如圖3c所示。其中,投影面積A為分割前景的像素面積,周長P為分割前景的輪廓像素數,寬度D和長度L分別為分割前景的最小外接矩形的寬度和長度,最大內切圓半徑R為分割前景的最大內切圓半徑,偏心率E為橢圓擬合分割前景的偏心率。

圖3 圖像分割與二維特征提取示意圖Fig.3 Schematics of image segmentation and two-dimensional feature extraction
3.2 體質量估測模型建立
體質量估測模型采用隨機森林(Random forest,RF)[30]算法進行建立,RF是一種集成學習方法,在以決策樹為基學習器構建Bagging集成的基礎上,進一步引入了隨機屬性選擇,算法簡單、高效且計算開銷小。RF回歸算法的具體步驟為:①從原始數據集中隨機有放回地抽取n個訓練樣本,重復T次。②對于T個子數據集,分別訓練一個CART回歸樹模型。在訓練過程中,每個結點的劃分規則是先隨機從所有特征中選取k個特征,再從k個特征中選擇最優屬性用于劃分。③將生成的T棵決策樹組成隨機森林,隨機森林最終的預測結果為所有T棵CART回歸樹預測結果的均值。
將3.1節得到的特征參數(周齡O、投影面積A、周長P、寬度D、長度L、最大內切圓半徑R和偏心率E)作為輸入,實際體質量作為真實標簽,建立基于隨機森林的黃羽雞體質量估測模型。數據集按照7∶3的比例劃分訓練集和測試集,并采用均方根誤差(RMSE)以及相對誤差(MRE)對測試集中不同姿態下體質量估測的效果進行評價。
4 結果與分析
4.1 模型訓練與參數優化
本文采用小批量的隨機梯度下降法,對SE-ResNet18+fLoss模型進行訓練。訓練過程中,迭代次數(Epochs)設置為200次,最小批處理大小(MiniBatch size)為16。學習率初始化為0.01,并采用學習率衰減訓練策略調整學習率,學習率調整如表4所示。
為了解決數據分布不平衡的問題,使用Focal Loss損失函數提升分類精度,訓練過程中SE-ResNet18+fLoss模型的損失函數曲線和驗證集準確率曲線如圖4所示。由圖4可以看出,訓練集的損失函數隨迭代次數的增加而下降,而準確率隨迭代次數的增加而逐漸增加,當迭代次數達到100次左右時,模型基本收斂,訓練損失函數曲線和準確率曲線都趨于平穩。

表4 學習率調整策略Tab.4 Learning rate adjustment strategy

圖4 模型訓練損失函數曲線和驗證集上準確率曲線Fig.4 Model training loss function curve and accuracy curve
Focal Loss損失函數最重要的兩個參數是調制因子γ和權重因子αt,本文對于調制因子γ和權重因子αt的選取進行討論。圖5a為調制因子γ分別取0、0.5、1.0、2.0、5.0時模型的訓練損失函數曲線,圖5b為不同調制因子對應測試集F1值,當γ=0時,Focal Loss等于標準交叉熵函數,可以發現隨著γ的增大,損失曲線收斂更快,且越趨近于0,通過圖5b發現,當γ=2.0時,F1值最高,故模型取γ=2.0。圖5c為不同權重因子αt對應在測試集上測試得到的F1值,固定調制因子γ=2.0,對于站立、低頭、梳理羽毛、展翅、坐姿和遮擋情況6種類別的權重比例分別設置為:α1為1∶1∶1∶1∶1∶1,α2為1∶1∶1∶2∶1∶1,α3為1∶1∶1∶5∶2∶1,α4為1∶1∶1∶10∶2∶1,α5為1∶1∶1∶15∶3∶1,α6為1∶1∶1∶20∶4∶1,由于展翅和坐姿姿態的圖像數量明顯較少,本文將展翅和坐姿兩種姿態的權重進行了增大,當權重因子為α1時,表示未對正負樣本的數量進行平衡。從圖5c中可以發現,當各姿態類別的權重因子比例設置為α4,即根據樣本的分布進行設置時,F1值最高,將比值歸一化到[0,1],可得αt=(0.062 5, 0.062 5, 0.062 5, 0.625, 0.125, 0.062 5)時模型最優。此外,還可發現相比于α1,其他權重因子對應在測試集上的F1值都有顯著提高,說明Focal Loss損失函數對模型分類效果有明顯提升。

圖5 不同調制因子γ和權重因子αt的模型性能Fig.5 Model performance with different modulation factors γ and weighting factors αt
4.2 模型姿態識別結果分析
圖6為SE-ResNet18+fLoss模型在432幅測試集圖像上測試結果的混淆矩陣,表5為各姿態情況分類的精確率、召回率及F1值。結果表明模型對于站立、低頭、展翅、梳理羽毛、坐姿和遮擋情況6種類別識別的F1值分別為94.34%、91.98%、76.92%、93.75%、100%和93.68%,6類姿態的加權平均F1值達到93.90%,具有較高的識別精度和較強的魯棒性,模型對于夜間昏暗光線場景下的雞只姿態也能進行很好的識別。進一步發現,模型對于坐姿的識別效果最好,主要是由于雞只坐姿通常發生在晚上,光照與白天有明顯不同,而對于展翅姿態的識別性能有待提高,這可能與展翅數據本身數量較少且展翅幅度不定有關。

圖6 SE-ResNet18+fLoss模型對雞只姿態情況 分類的混淆矩陣Fig.6 Confusion matrix of chicken classification based on SE-ResNet18+fLoss model

表5 SE-ResNet+fLoss模型對雞只不同姿態分類結果Tab.5 Classification results of SE-ResNet+fLoss model for different postures of chickens %
由于本文最終旨在識別出姿態關鍵幀(站立姿態)用于后續體質量估測,故將非站立姿態看作一類,可得到表6所示模型對于姿態關鍵幀的識別性能,可以看出若僅識別是否為姿態關鍵幀,模型的識別精度為97.38%、召回率為97.22%、F1值為97.26%,識別效果較優。

表6 SE-ResNet+fLoss模型對于雞只姿態關鍵幀 的識別結果Tab.6 Detection results of SE-ResNet+fLoss model for the posture key frame of chicken %
為了更好地解釋本文提出的SE-ResNet+fLoss模型,對模型的最后一層卷積層的特征圖利用Grad-CAM進行可視化,獲得6種姿態的類激活圖如圖7所示,每一類姿態包括第1行的原始RGB圖像和第2行的Grad-CAM可視化效果。通過可視化結果可以看出,不同姿態下模型的類激活圖存在差異,反映了每一類所關注的重點區域不一致。其中,站立姿態重點關注于雞頭部位,而低頭姿態關注于雞的尾部和頸部,梳理羽毛姿態更關注于扭頭時雞的頭部與身體部分,展翅姿態關注于身體翅膀展開部分,坐姿重點關注于雞坐立時突出的側面部分,遮擋情況則更關注于雞在視場內的身體部分,此部分通常處于圖像的邊緣。

圖7 黃羽雞不同姿態下分類的類激活圖Fig.7 Class activation maps for classification of yellow-feathered chickens in different postures
通過Grad-CAM可以很好地解釋本文方法分類的依據,即使不采用目標檢測網絡,模型亦能準確定位雞的位置,尤其是正常姿態下,如圖8所示,Guided Grad-CAM表現了細粒度的重要性,可以看出類激活圖更關注于雞頭部位,這也為弱監督的目標檢測提供了參考。

圖8 站立姿態下雞只姿態識別的類激活圖Fig.8 Class activation maps for posture detection of chicken in ‘stand’ pose
4.3 不同方法比較
本文將SE-ResNet18+fLoss與ResNet18、MobileNet V2、SE-ResNet18進行了姿態識別對比試驗。其中,MobileNet V2[31]是2018年Google團隊提出的輕量級網絡。不同模型均采用相同的試驗訓練參數,并在相同測試集上驗證模型的性能,識別速度是在批處理大小為16的情況下進行推理得到的,試驗結果如表7所示。從表7可以看出,SE-ResNet+Focal Loss在基礎網絡中加入了注意力機制SE模塊和Focal Loss,模型在精確率、召回率和F1值方面相比其他網絡均最優,在識別速度方面ResNet18模型最優,但SE-ResNet+fLoss的識別速度與其相差不大。從結果可以看出本文改進的SE-ResNet能較為理想地兼顧識別性能與識別速度。
為了進一步說明不同方法姿態識別的結果,本文可視化ResNet18、MobileNet V2、SE-ResNet18和SE-ResNet18+fLoss在2 h的視頻段上的測試結果,如圖9所示,視頻采樣間隔為1 min/幅。從圖9可以看出,ResNet18和MobileNet V2有較多圖像將其他姿態誤判為站立姿態,這對于本文進行姿態關鍵幀識別是不利的,因為這種誤判將直接導致后續體質量預測的誤差較大。與其他3種方法相比,SE-ResNet18+fLoss對于姿態的識別更加準確,能夠較為全面地覆蓋姿態轉換發生的時間區間。

表7 不同方法結果比較Tab.7 Comparison of results using different methods

圖9 不同方法部分測試結果可視化Fig.9 Visualization of some test results of different methods
4.4 模型測試
圖10為SE-ResNet18+fLoss在連續24 h視頻段上(2019年12月5日08:00—2019年12月6日08:00)的姿態自動識別結果。從圖10可以看出,黃羽雞白天多為站立姿態,而夜間多為坐姿,白天姿態轉換頻率顯著高于夜間姿態轉換頻率。此外,2019年12月5日08:00—16:00期間光照較為明亮,有利于提取雞只的顏色和紋理特征,通過統計SE-ResNet18+fLoss在2019年12月5日08:00—16:00視頻段上的姿態占比結果(圖11),發現白天視頻段中有超過40%的時間雞只處于站立姿態,這意味著有相當一部分視頻數據是姿態關鍵幀,可以用于體質量預測。

圖10 SE-ResNet18+fLoss在連續24 h視頻段上的 姿態自動識別結果Fig.10 Automatic recognition result of posture on 24 h continuous video by SE-ResNet18+fLoss model

圖11 SE-ResNet18+fLoss在2019年12月5日08:00— 16:00時間段的姿態占比統計結果Fig.11 Share statistics results of posture at December 5, 2019, 08:00—16:00 by SE-ResNet18+fLoss model
4.5 不同姿態下黃羽雞體質量估測結果
表8為不同姿態下黃羽雞的體質量估測結果,可以發現當使用全部數據集時,均方根誤差為0.128 kg,平均相對誤差為7.481%,而經過SE-ResNet18+fLoss模型對黃羽雞姿態關鍵幀(站立姿態)進行篩選后,均方根誤差和平均相對誤差均有明顯降低,均方根誤差為0.059 kg,平均相對誤差為3.725%,且站立姿態相比于其他姿態的體質量估測精度更高,這也證明了SE-ResNet18+fLoss模型對于雞只姿態關鍵幀識別的有效性,能夠最終提高體質量估測的精度。由于本文僅提取一維特征和二維特征進行體質量估測模型的建立,若在此基礎上,融合三維特征,將會進一步提高雞只體質量估測的精度。

表8 不同姿態下黃羽雞體質量估測結果比較Tab.8 Comparison of yellow-feathered chicken weight estimation results in different postures
5 結束語
本研究提出一種用于平養黃羽雞體質量估測的姿態關鍵幀識別模型SE-ResNet18+fLoss,模型融合了注意力機制SE模塊和殘差結構,并改進了損失函數,通過Focal Loss監督信號來解決樣本不平衡問題,同時引入梯度加權類激活圖對末端分類規則的合理性進行解釋。模型在測試集上對于黃羽雞的站立、低頭、展翅、梳理羽毛、坐姿和遮擋6類姿態情況識別的F1值分別為94.34%、91.98%、76.92%、93.75%、100%和93.68%;若僅識別是否為雞只姿態關鍵幀,識別精確率為97.38%、召回率為97.22%、F1值為97.26%、識別速度為19.84 f/s,其識別精確率、召回率和F1值均優于ResNet18、MobileNet V2和SE-ResNet18網絡。結果發現通過Grad-CAM可以很好地解釋本文方法分類的依據,反映了每一類所關注的重點區域,其中,站立姿態重點關注于雞頭部位。其次,在連續視頻上進行了模型的驗證與雞姿態特性的分析,發現白天有較多時刻黃羽雞被識別為姿態關鍵幀,可用于后續體質量估測分析。進一步通過試驗驗證了SE-ResNet18+fLoss模型對于黃羽雞姿態關鍵幀識別的有效性,能夠提高體質量估測的精度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2019年2期)2019-08-23 08:12:08
產品可靠性報告(2017年7期)2017-09-05 09:49:12
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車觀察(2016年3期)2016-02-28 13:16:26
核科學與工程(2015年4期)2015-09-26 11:59:03
