基于混合蜻蜓優(yōu)化多核模糊聚類和特征子集選取的在線齒輪故障識別
2022-01-27 15:22:44馬泳濤
機械設(shè)計與制造 2022年1期
梁 穎,馬泳濤
(1.中原工學院機電學院,河南 鄭州 450007;2.鄭州大學機械與動力工程學院,河南 鄭州 450001)
1 引言
齒輪傳動系統(tǒng)是機械傳動系統(tǒng)關(guān)鍵環(huán)節(jié)之一,決定了整個機械系統(tǒng)的運轉(zhuǎn)狀態(tài)[1]。隨著裝備機械部件的不斷增多、監(jiān)測采樣頻率的不斷提高,齒輪故障識別已經(jīng)進入大數(shù)據(jù)分析時代[2]。面對復雜多樣、高維非線性的海量齒輪故障監(jiān)測數(shù)據(jù),如何準確、高效、便捷的識別故障成為故障模式診斷面臨的新課題[3]。故障原理分析、故障信號特征提取和故障模式識別是齒輪系統(tǒng)故障診斷研究核心內(nèi)容,學者們重點圍繞3個方面展開了系列研究,文獻[4]采用時頻分析技術(shù)對行星齒輪箱瞬時轉(zhuǎn)速精確提取問題進行研究,提出了一種時頻脊融合特征提取方法;文獻[5]研究了基于振動信號的時域、頻域等特征的齒輪故障識別問題。此外,文獻[6-8]分別從不同角度對齒輪故障信號特征進行了研究,相應(yīng)的提出了特征提取方法,這些研究對大數(shù)據(jù)背景下的齒輪故障診斷具有重要借鑒意義,但是,上述特征選取方法更側(cè)重于故障信號產(chǎn)生機理,忽視了特征選取體量對系統(tǒng)復雜程度的影響,即使采用了特征降維處理技術(shù),但是篩選的特征子集不一定最優(yōu)。因此,研究基于多變量度量的特征子集選取具有重要意義,文獻[9-10]通過設(shè)計融合多個評價指標的度量標準,有效實現(xiàn)了對特征子集的選取,但是,大多數(shù)多變量度量特征子集選取方法通常采用劃分多階段選取特征子集的形式,導致很難滿足實時性要求。支持向量機、深度學習[2]、聚類分析[10]等是故障模式識別常采用的辨識模型,由于齒輪正常和故障信息具有邊界模糊的特性,因此,模糊聚類方法在故障識別、入侵檢測等應(yīng)用領(lǐng)域得到了廣泛應(yīng)用,模糊C-均值聚類算法(FCM)作為經(jīng)典的模糊聚類算法之一[11],有效克服FCM聚類問題魯棒性差、聚類個數(shù)事先確定、對初始聚類中心敏感的缺陷是當前研究熱點,文獻[12-14]針對上述一個或幾個缺陷進行研究,分別提出了改進算法,但是,如何平衡算法復雜度和聚類精度似乎還找到更好的辦法。
鑒于此,為提高復雜高維大體量齒輪故障識別的效率,提出一種融合模糊聚類、特征子集選取和智能優(yōu)化技術(shù)的在線齒輪故障識別方法,所做主要工作有:
(1)對FCM算法進行改進,引入多核距離度量函數(shù)和貪婪聚類中心初始化策略,以提高FCM的聚類魯棒性。提出特征子集選取機制,在保持高分辨能力的同時,最大限度降低數(shù)據(jù)維度。
(2)引入混合蜻蜓優(yōu)化算法,利用算法全局尋優(yōu)能力,通過蜻蜓種群迭代進化,以實現(xiàn)多核函數(shù)確定、最佳特征子集選取和數(shù)據(jù)聚類分析。
(3)構(gòu)建齒輪故障識別模型,利用訓練樣本集對改進FCM進行參數(shù)訓練,得到最佳模糊聚類個數(shù)等參數(shù),獲取多核函數(shù)、特征子集選取信息,并應(yīng)用于齒輪故障線上識別。
2 模糊聚類與特征子集選取
2.1 模糊C-均值聚類算法(FCM)
FCM作為目前最為廣泛應(yīng)用的聚類算法之一,其利用隸屬度矩陣U=[μik]C×n度量樣本點xk(xk∈X,X為樣本集合)與C個聚類中心V={v1,…,vC}的隸屬關(guān)系,通過迭代求解聚類目標函數(shù)J(U,V),實現(xiàn)樣本聚類劃分。
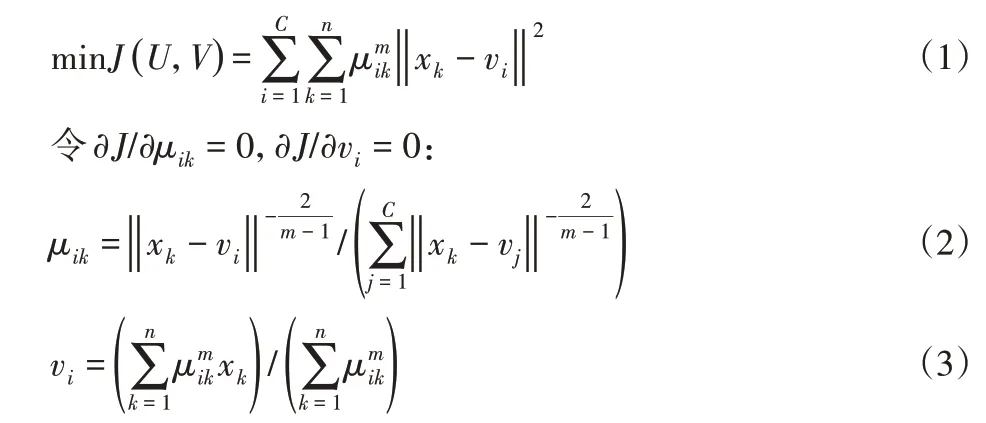
式中:m—模糊加權(quán)指數(shù)。研究表明,采用歐式距離衡量數(shù)據(jù)間差異性的FCM,不適用于孤點、復雜高維數(shù)據(jù)聚類分析,為此,利用高維空間映射函數(shù)Φ(xk)處理xk,此時J(U,V)表示為:
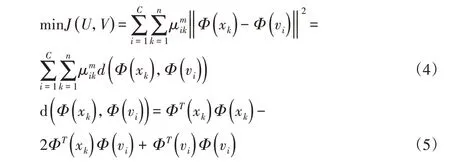
定義Θ(x,v)=ΦT(x)Φ(v),相關(guān)文獻指出,當Θ(x,v)滿足Mercer條件時[15],則不需要知道Φ(xk)的具體形式,并且稱Θ(x,v)為核函數(shù)。此時令?J/?μik=0,?J/?vi=0,有:
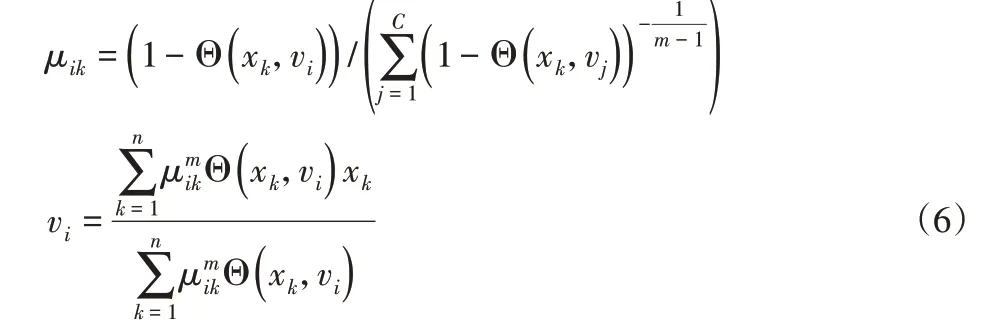
2.2 特征子集選取

從式(7)可以看出,只需要確定R=(χ1,…,χm)具體形式,就可以實現(xiàn)數(shù)據(jù)集的特征子集選取。
3 改進FCM
針對FCM對初始聚類中心敏感、復雜數(shù)據(jù)聚類魯棒性差、聚類個數(shù)事先確定的缺陷,分別提出改進策略,以提高改進FCM(IFCM)的聚類性能。
3.1 多核距離度量函數(shù)
采用核函數(shù)替代傳統(tǒng)歐式距離度量,提高了FCM處理復雜數(shù)據(jù)問題的能力,然而單一的核函數(shù)更適用于特定的數(shù)據(jù)聚類分析問題,為此,設(shè)計映射矩陣Φd×d:

定義核函數(shù)Θk(xi,xi)=Ak(xi)T Ak(xi),當選取d個滿足Mercer條件的Θk(xi,xi)時,就可以實現(xiàn)聚類分析。從式(9)~式(12)可以看出,多個核函數(shù)的引入,能夠更好的體現(xiàn)數(shù)據(jù)樣本間的差異性,進一步提高了聚類結(jié)果的魯棒性。
3.2 貪婪聚類中心初始化
傳統(tǒng)FCM采用隨機初始化的方式生成初始聚類中心,具有很強的不確定性,而且,得到的初始聚類中心并不是數(shù)據(jù)集內(nèi)個體,為此,提出貪婪聚類中心初始化聚類策略:
(1)確定v1,star。根據(jù)下式計算每個數(shù)據(jù)點的密度值τ(xk),選取密度值最大的點xk為第一個初始聚類中心v1,stɑr。
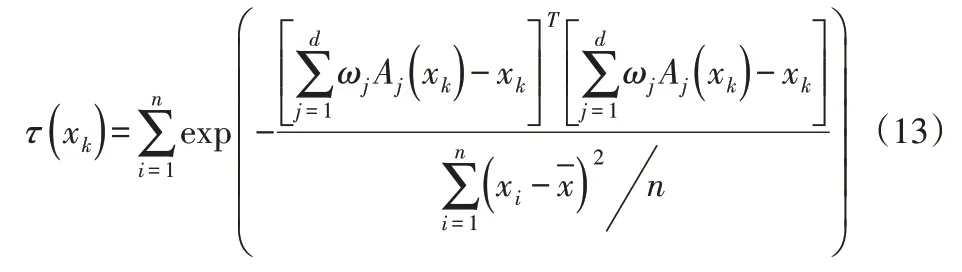
(2)確定v2,star。從X剩余數(shù)據(jù)點內(nèi),以概率P2選取xl為v2,star,c←3。
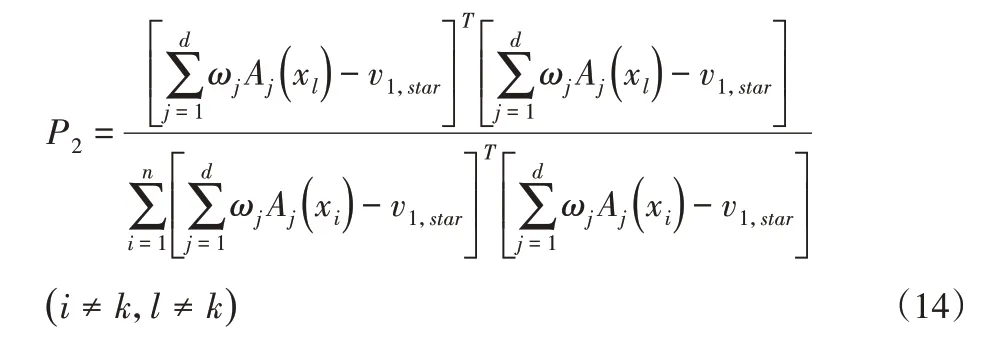
(3)確定vc,star。從X剩余數(shù)據(jù)點內(nèi),以概率Pc選取xc為vc,star。
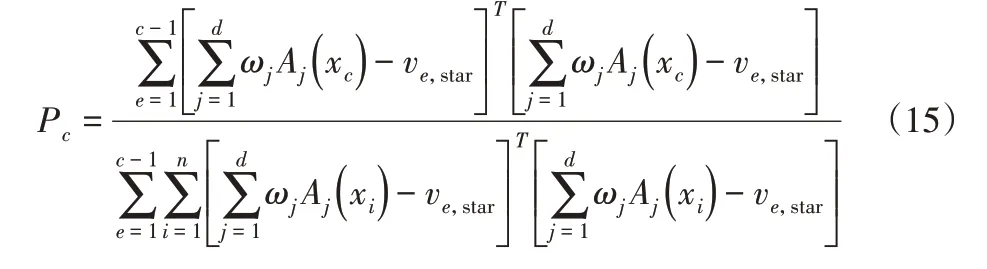
(4)終止條件判定。若c>C,則終止迭代,輸出初始化聚類中心;否則,c←c+1,返回“(3)”。
從貪婪聚類中心初始化策略可以看出,初始聚類中心相互之間的空間距離度量較大,增強了算法搜索空間,具有很強的針對性。
3.3 FDMFCM算法
蜻蜓算法(Dragonfly Algorithm,DA)是2016年才被提出的新型群智能優(yōu)化技術(shù)[16]。DA通過模擬蜻蜓群體行為,設(shè)置捕食和遷徙2個種群模態(tài),賦予個體Xi(t)具有避撞(Si(t))、結(jié)隊(Ai(t))、聚集(Ci(t))、覓食(Fi(t))、避敵(Ei(t))5種行為,并按照式(16)進行更新。
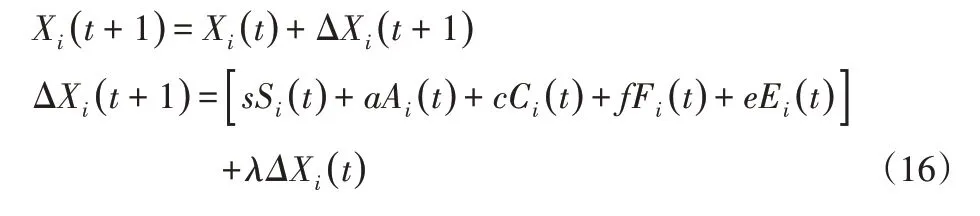
研究成果表明,DA兼具全局搜索和局部搜索,具有較強的優(yōu)化能力(DA基本原理見相關(guān)文獻)。為了方便問題描述,將特征子集選取作為改進FCM的前提,提出基于特征子集選取和混合蜻蜓優(yōu)化多核模糊聚類算法(FDMFCM),即改進FCM在特征子集選取的基礎(chǔ)上,實現(xiàn)對數(shù)據(jù)集的聚類分析。為了評價聚類結(jié)果的好壞,定義聚類結(jié)果評定指標CREI:
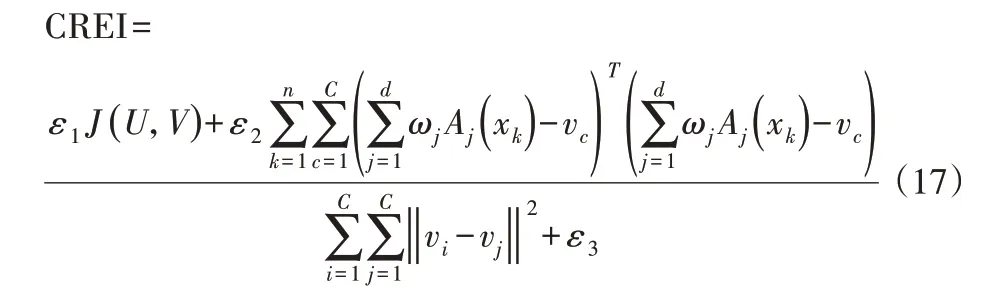
式中:ε1、ε2、ε3—比例系數(shù)。
從式(17)可以看出,CREI的分子反映了分類內(nèi)部的緊致度,分母反映了類間的分離度,CREI取值越小,表明聚類結(jié)果越好。
DA編碼:對于多核函數(shù)確定、最佳特征子集選取和聚類中心迭代計算問題,定義個體編碼Xi(t)為:
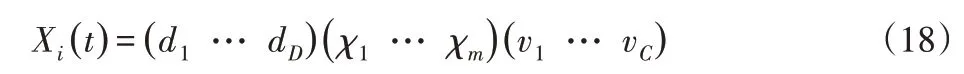
式中:(d1,…,d i,…,d D)—D個候選核函數(shù),若di=1,則表示選取第i個核函數(shù),否則di=0,且有=d。DA編碼示意圖,如圖1所示。
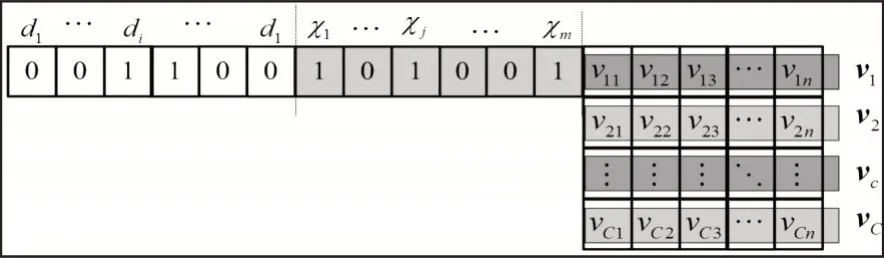
圖1 DA編碼示意圖Fig.1 Schematic Diagram of DA Coding
混合迭代進化:從DA編碼定義可以看出,Xi(t)既包含離散和連續(xù)兩種編碼位形式,對于連續(xù)編碼位可以直接采用式(16)進行迭代更新,對于離散編碼位,給出取反Re、替換Su、交換Ex3種離散迭代進化策略,其中Re(Xi(t))定義為選取自身G1個編碼位進行取反操作,且:
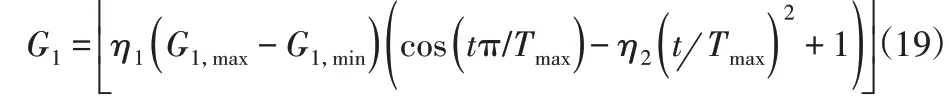
式中:G1,max、G1,min—G1最大值和最小值。Su(Xi(t)←Xj(t))定義為選取Xj(t)內(nèi)不同于Xi(t)的G2個編碼位替換,且:
人性化護理是將“人文關(guān)懷”和“以患者為中心”的思想結(jié)合日常護理,為患者提供細節(jié)、全面、人性化的護理服務(wù)[7]。常規(guī)護理方式通常將重點放在患者住院期間疾病的變化過程和生命體征、檢驗報告數(shù)據(jù)中,對于患者的在住院期間的心理變化、文化影響等缺乏關(guān)注。樂小麗等[8-9]人在研究中對宮頸炎患者采取人性化護理干預后有效改善患者焦慮、煩躁的不良情緒、提高了患者滿意度[10-11]。本研究中對患者實施人性化護理干預后,患者用藥依從性得到了顯著提高,從而有效促進了治療效果提高。
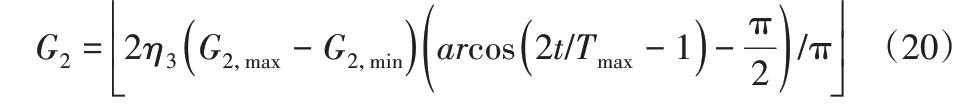
式中:G2,max、G2,min—G2最大值和最小值,顯然,對于不同Xi(t),G2,max取值是不同的。定義Ex((Xi(t)←Xk(t)))為Xi(t)隨機選取Xk(t)內(nèi)對應(yīng)的G3個編碼位進行交換,3種離散迭代進化策略示意圖,如圖2所示。
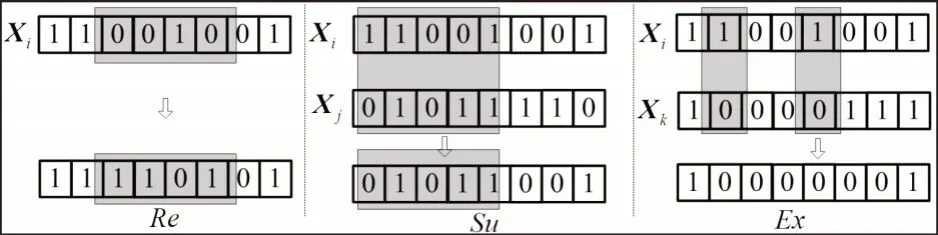
圖2 離散迭代進化策略示意圖Fig.2 Schematic Diagram of Discrete Iterative Evolution Strategy
目標函數(shù):對于模糊聚類優(yōu)化問題,定義混合蜻蜓算法目標函數(shù)f(X):
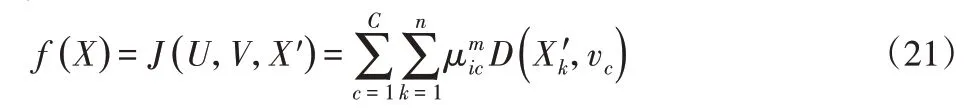
式中:X′—X的編碼子集,且X′=(v1…vC)。
FDMFCM實現(xiàn):采用混合蜻蜓算法對改進FCM進行優(yōu)化。在每次迭代過程中,首先,對Xi(t)的離散編碼子集(d1…d D)、(χ1…χm)執(zhí)行離散進化操作,并在此基礎(chǔ)上,確定核函數(shù)和特征子集。然后,對Xi(t)的連續(xù)編碼子集執(zhí)行次進化操作,得到Xi(t)對用的聚類中心VXi(t)和聚類結(jié)果評定指標CREI(Xi(t)),并據(jù)此更新種群個體信息。如此往復,直到算法結(jié)束,最終得到最佳(d1…d D)best、(χ1…χm)best和聚類中心Vbest。基于混合蜻蜓優(yōu)化的改進FCM實現(xiàn)流程圖,如圖3所示。
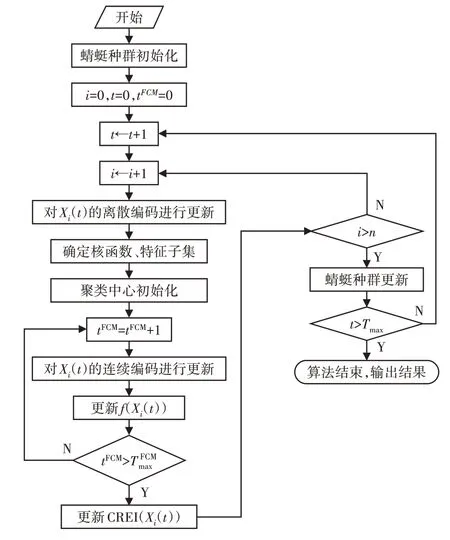
圖3 FDMFCM實現(xiàn)流程圖Fig.3 Flow Chart of FDMFCM Implementation
算法計算復雜度:從FDMFCM實現(xiàn)過程可以看出,對于具有P個個體的蜻蜓種群,種群初始化復雜度為O(P×(n+d+m)),每次迭代離散編碼子集更新復雜度為O(P×(d+m)),連續(xù)編碼子集更新復雜度為種群更新復雜度為O(P×(n+d+m)),故算法計算復雜度為:
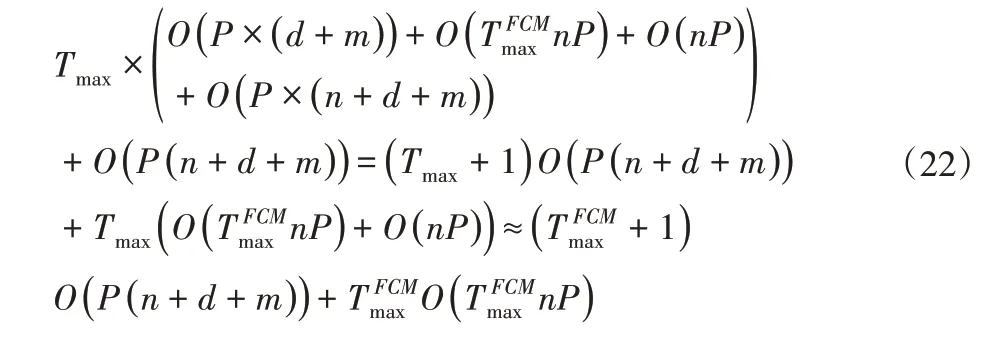
4 在線齒輪故障識別
利用FDMFCM算法進行齒輪故障識別,采取線下訓練和線上識別兩個階段。線下階段,由于聚類數(shù)C未知,提出多線程策略:設(shè)定線下共有(Cmax-1)個線程,每個線程按照聚類數(shù)c(c=2,…,…Cmax)執(zhí)行FDMFCM操作,得到該聚類數(shù)下的CREI(c),選取CREI(c)取值最小的聚類數(shù)為最佳聚類數(shù)Cbest,并將其對應(yīng)的(d1…d D)、(χ1…χm)以及其他參數(shù)作為線上識別參數(shù)輸入。線上階段,由于核函數(shù)、聚類個數(shù)、特征子集選取向量已經(jīng)確定,因此,在執(zhí)行模糊聚類操作時,只需要執(zhí)行Xi(t)連續(xù)編碼位更新操作,使得算法計算復雜度下降到TmaxO(nP)級別,大大提升了線上齒輪故障識別效率。在線齒輪故障識別示意圖,如圖4所示。
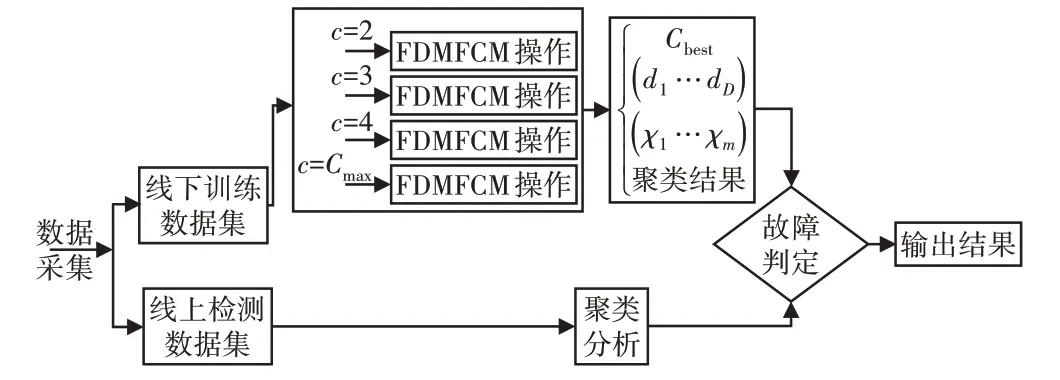
圖4 在線齒輪故障識別示意圖Fig.4 Schematic Diagram of On-Line Gear Fault Identification
5 仿真實驗
采用監(jiān)測實驗平臺對所提方案進行驗證,監(jiān)測實驗平臺包括轉(zhuǎn)速傳感器、電機、齒輪箱、制動器等模塊。實驗平臺能夠模擬齒輪點蝕、剝落、斷齒、正常等4種健康狀況。
5.1 改進FCM性能驗證
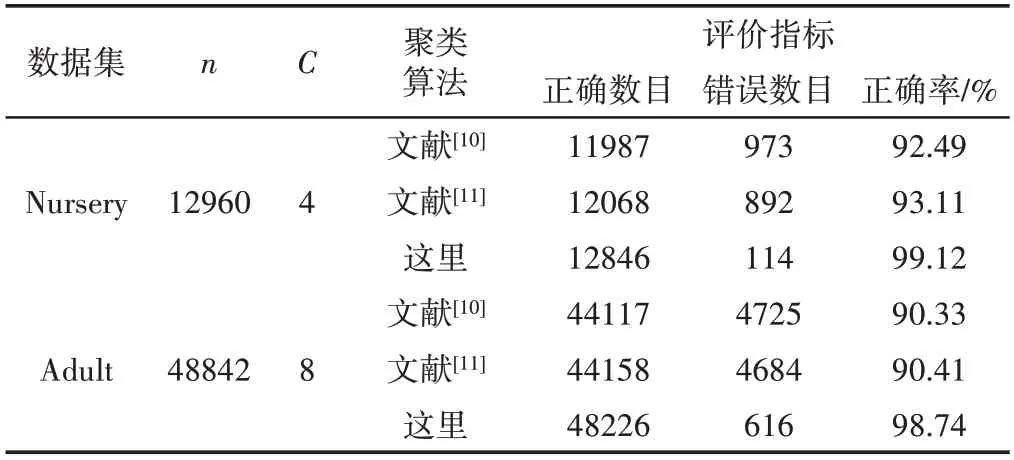
表1 UCI數(shù)據(jù)集聚類對比結(jié)果Tab.1 Clustering Comparison Results of UCI Dataset
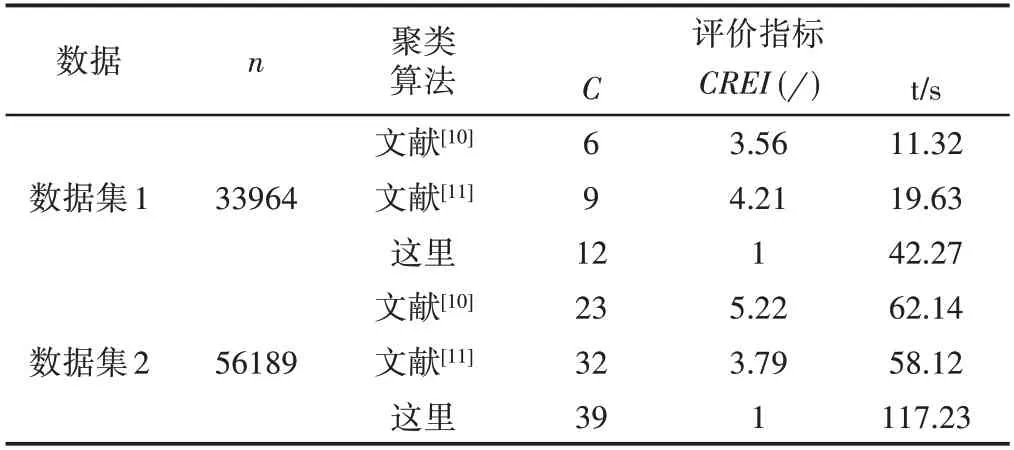
表2 人工數(shù)據(jù)集聚類對比結(jié)果Tab.2 Clustering Comparison Results of Artificial Data Sets
5.2 齒輪故障識別驗證
試驗設(shè)置3種不同轉(zhuǎn)速,信號采樣頻率設(shè)定為1000Hz,每種工況分別采集300個樣本點,其中260個樣本點組成訓練集,其余組成測試集。對于特征集,參考文獻[6]提出的時域與頻域聯(lián)合特征提取方法,每個樣本由50個特征描述,4種工況下數(shù)據(jù)情況,如表3所示。

表3 數(shù)據(jù)集Tab.3 Data Sets
5.2.1 特征子集選取對故障識別正確率的影響實驗
對于每種工況,依次增加特征子集選取規(guī)模,并采用基于多核距離度量函數(shù)和貪婪聚類中心初始化策略的改進FCM進行聚類分析,不同特征子集規(guī)模下故障識別正確率對比曲線圖,如圖5所示。運算時間對比曲線圖,如圖6所示。
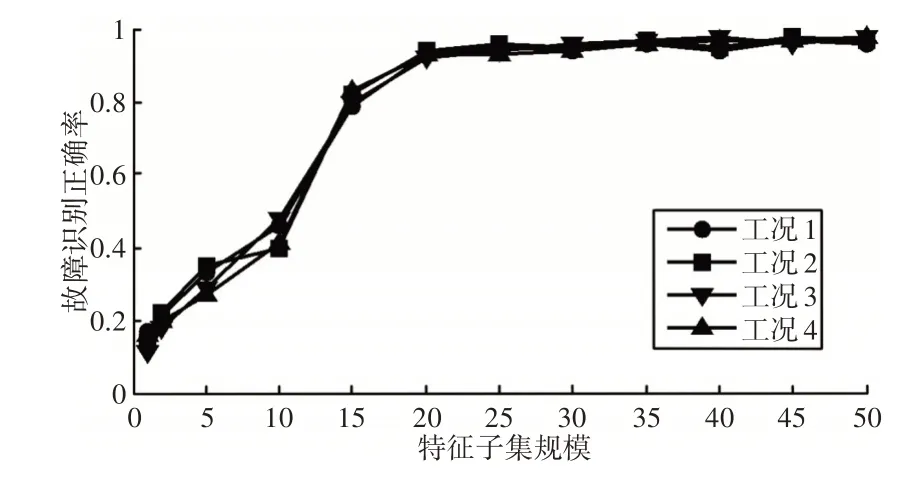
圖5 不同特征子集規(guī)模下故障識別正確率Fig.5 Fault Recognition Accuracy under Different Feature Subset Sizes
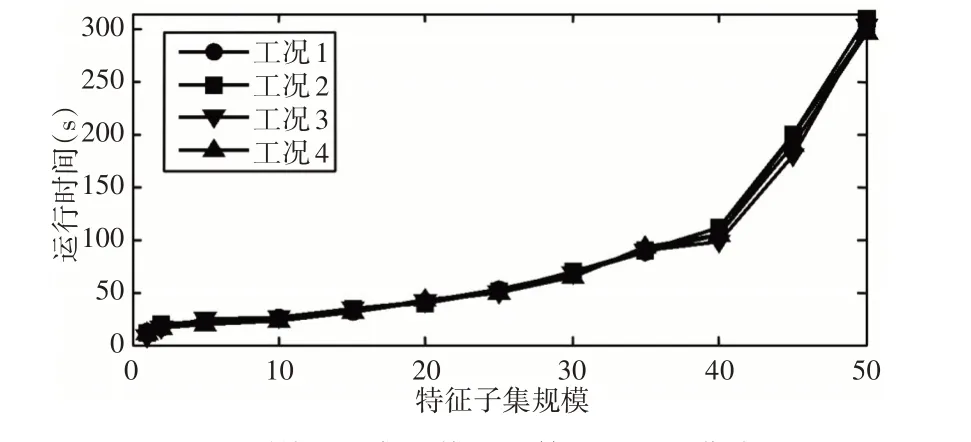
圖6 不同特征子集規(guī)模下運算時間對比曲線圖Fig.6 Comparison Curve of Operation Time under Different Feature Subset Sizes
5.2.2 齒輪故障識別驗證實驗
將4種工況的訓練樣本、測試樣本分別組成訓練集和測試集,采用FDMFCM算法進行訓練,檢測時,隨機選取測試集中的樣本進行實驗,每次實驗獨立運行50次,實驗結(jié)果取均值。某次實驗線上識別階段混合蜻蜓算法收斂曲線,如圖7所示。不同實驗下故障識別正確率,如圖8所示。
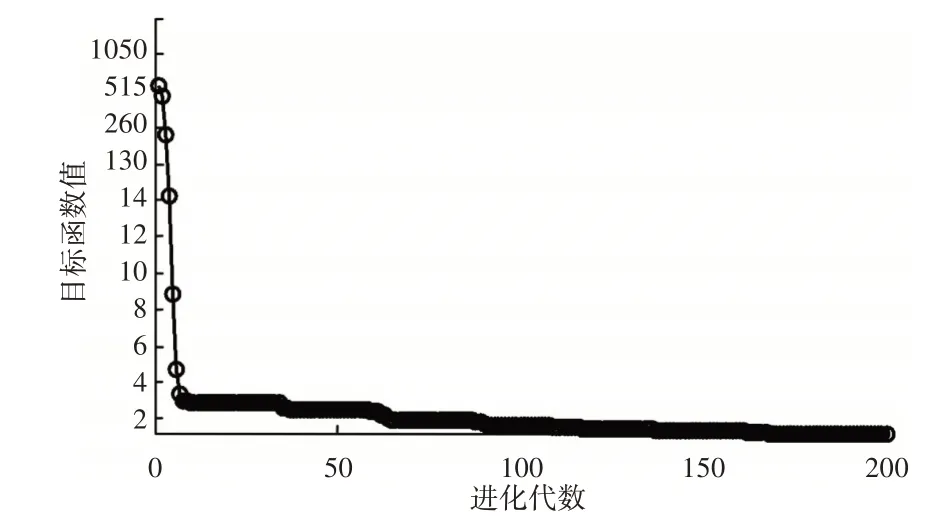
圖7 混合蜻蜓算法收斂曲線Fig.7 Convergence Curve of Hybrid Dragonfly Algorithm
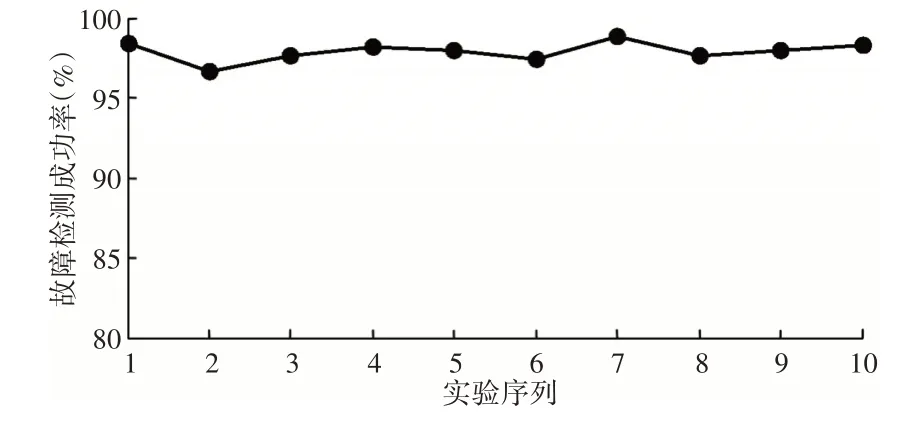
圖8 不同實驗下齒輪故障識別正確率Fig.8 Correct Rate of Gear Fault Recognition under Different Experiments
5.2.3 不同方法對比實驗
為了進一步分析這里方案性能,基于同樣的數(shù)據(jù)集,分別選取文獻[5]提出的齒輪局部故障識別方法、文獻[7]提出的齒輪箱故障診斷方法和文獻[10]提出的齒輪故障模式識別方法進行對比實驗,這幾種方法的核心都是在特征子集選取的基礎(chǔ)上,利用不同的識別分類技術(shù)進行故障識別。不同實驗下,4種方法故障識別正確率對比,如圖9所示。
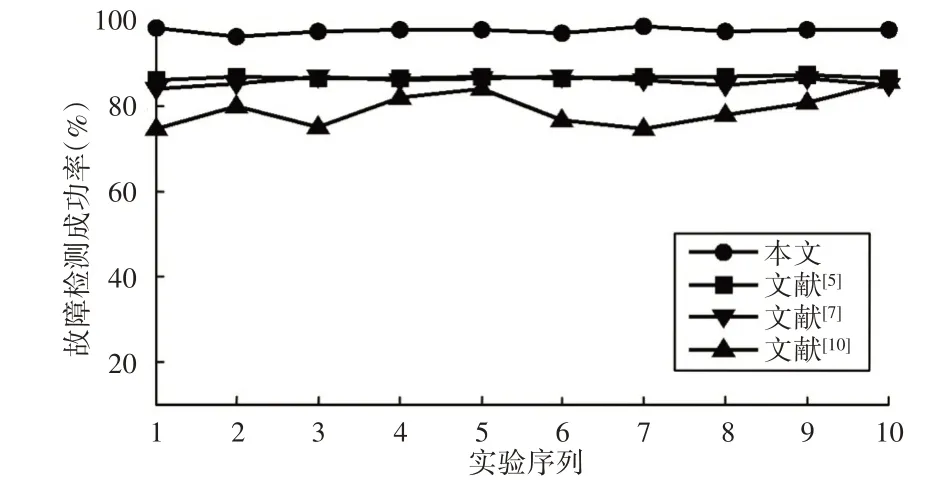
圖9 4種方法故障識別正確率對比Fig.9 Comparison of Fault Identification Accuracy of Four Methods
5.3 結(jié)論分析
(1)提出的改進FCM(IFCM)具有更好的聚類性能。從表1可以看出,對于經(jīng)典測試數(shù)據(jù),3種聚類算法都取得了不錯的聚類效果,聚類正確率都達到了90%以上,特別的,相比其他兩種算法,IFCM聚類正確率提高了約(6.5~9.3)%。從表2可以看出,對于人工數(shù)據(jù),由于聚類數(shù)事先未知,且人為增加數(shù)據(jù)復雜度,導致其他兩種算法的聚類效果不佳,聚類評價指標CREI是IFCM的4倍左右,但是,由于采用兩重循環(huán)迭代,IFCM在運算時間上要高于其他兩種算法。之所以IFCM聚類效果更優(yōu),是因為多核距離度量函數(shù)的引入,提高了算法對復雜數(shù)據(jù)問題的適應(yīng)性,貪婪聚類中心初始化的提出,提高了聚類迭代的針對性和確定性,使得算法具有更佳的聚類性能。對于IFCM運算效率較慢的問題,后期采用線下訓練和線上識別兩個階段,有效避開了線下訓練階段消耗時間較多的缺陷。
(2)合理選取特征子集對提高故障識別效率具有重要影響。從圖5、圖6可以看出,在一定范圍內(nèi),隨著特征子集規(guī)模的不斷增加,故障識別正確率不斷提高,特別的,當特征子集規(guī)模在20左右時,識別正確率可以達到90%以上。此后,故障識別正確率隨特征子集規(guī)模變化不大,但是,算法運行時間在迅速增加,因此,合理選取特征子集可以保持較高的故障識別正確效率,而且能夠大幅度降低算法運算時間。
(3)提出的在線齒輪故障識別方法具有更好的識別效果。從圖7、圖8可以看出,在線上識別階段,混合蜻蜓算法能夠快速收斂全局最優(yōu)解,而且識別正確率很高,這表明,提出的在線齒輪故障識別方法能夠快速準確識別出齒輪故障。從圖9可以看出,相比于其他故障識別方法,這里算法具有更好的識別正確率,而且更加穩(wěn)定,識別正確率提高了約(11.1~31.7)%。
6 結(jié)束語
對在線齒輪故障識別進行了研究,提出了一種基于混合蜻蜓優(yōu)化多核模糊聚類和特征子集選取的在線齒輪故障識別方法。該方法以模糊聚類算法為核心,具有線下訓練和在線識別兩階段結(jié)構(gòu),通過提出改進策略以提升模糊聚類算法復雜問題聚類性能,提高了在線齒輪故障識別正確率,實驗仿真結(jié)果也驗證了所提方法的有效性。下一步將圍繞小樣本故障檢測成功率進行研究。
猜你喜歡
數(shù)學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
汽車維修與保養(yǎng)(2019年7期)2020-01-06 03:30:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
汽車維護與修理(2016年10期)2016-07-10 08:17:41
汽車維修與保養(yǎng)(2015年12期)2015-04-18 07:51:49
汽車維修與保養(yǎng)(2015年6期)2015-04-17 03:31:50
汽車維修與保養(yǎng)(2015年2期)2015-04-17 01:30:34
