面向數字人文的辭書關聯數據知識組織*
2021-12-15 12:32:44張志美錢智勇
圖書館論壇 2021年12期
關鍵詞:關聯
張志美,陳 濤,錢智勇,何 書
0 引言
辭書古代又稱 “字書”,是記錄語言和語言文化的載體,用來解釋字形、讀音和釋義,是館藏重要文獻資源和人文研究的重要工具。古代辭書知識涉及文字、音韻、語法、修辭、詞匯、校勘、句讀、句段、篇章等內容。先秦時代的《爾雅》是世界上第一部按同義和百科分類的義類綜合性語文辭書,爾雅以古代中原地區規范通用的語言訓釋上古典籍中的難字和百科異名,反映了先秦時代的社會生活,是人類寶貴的文化遺產[1]。漢代以來的《爾雅》注疏文獻是研究典籍文獻及先秦語言和文化的知識寶庫[2],也是大數據時代重要的知識組織工具。利用現代技術研究古代經典辭書,使非結構化的古代語言知識成為互聯網的結構化的開放互聯數據,通過網絡傳承中國優秀傳統文化,是通過推動中華優秀傳統文化創造性轉化和創新性發展,讓收藏在博物館里的文物、陳列在廣闊大地上遺產、書寫在古籍里的文字都活起來的重要手段[3]。以元數據為基礎的關聯數據已經成為通用的語義互聯的標準規范,利用關聯數據對辭書知識組織,以三元組存儲詞匯知識庫,是典籍數字人文的基礎建設。網上已發布的詞表中包括了大量現代語言同義詞和語義概念關系,大量的詞表本體研究與實踐,為爾雅詞表本體構建提供了可以復用的數據和結構。構建爾雅詞表本體可以實現爾雅詞匯知識的跨語言知識檢索與共享復用,將對外國留學生及其他讀者檢索中文古籍詞匯提供幫助;通過詞表本體學習、本體進化等技術,爾雅詞表本體也將成為自然語言處理、搜索引擎智能檢索、典籍標注和數字人文研究的重要知識組織工具。
1 關聯數據知識組織與數字人文的關系
1.1 關聯數據簡述
關聯數據(Linked data) 最早是Berners-Lee[4]提出的概念,初衷是將WEB中沒有進行關聯的數據鏈接起來,構建可被機器理解的包含語義關系的數據網絡。關聯數據有4個基本原則[4]:用URI來為任何事物標識名稱;通過HTTP協議便于用戶可以查找到這些名稱;以RDF 和SPARQL的形式提供原始數據;盡可能提供鏈接以發現更多信息資源。關聯數據的核心是資源描述框架(RDF),RDF 采用基于RDF/XML 的語法進行數據存儲與交換,使用三元組(主語—謂語—賓語)并通過URI標識網絡中的資源和元數據,資源的概念對應于主語,資源的屬性類型對應于謂語,資源的屬性值對應于賓語,主語與謂語使用唯一標識HTTP URI,賓語可以是字符串,也可以是其它對象實體,謂語反映了資源之間的關系。RDF定義的元數據描述方法不僅為各種類型資源的描述提供統一的數據模型,允許不同領域的用戶根據不同資源編制各自所需要的詞匯表描述領域元數據的語義,同時還提供不同元數據之間相互兼容,相互操作的平臺。關聯數據已經在大眾傳媒、圖書館、文化遺產、數字人文、政府電子政務、商業企業等領域廣泛應用。
1.2 關聯數據在數字人文中的作用
隨著數字媒介和網絡技術的快速發展,對不同載體文本進行保存、計算分析、編輯和內容建模等數字人文研究漸成趨勢。在數字人文過程中關聯數據的作用見圖1,數字人文研究過程包括對數字資源組織與保存、文本計算分析、圖像文本編輯和內容建模等方面。首先在數字資源的組織與保存方面,利用關聯數據我們把網上各種結構化、半結構化和非結構化數據資源,通過URI鏈接,以RDF/XML三元組語法描述,并以專門用來存取RDF數據的三元組數據庫保存各種數據。其次,在對文本的計算分析過程中,利用關聯數據、本體、描述邏輯語言對文獻進行字詞句關聯查詢、校勘分析、注釋內容比對分析、版本分析、概念關系抽取、作品作者時空分析等處理。第三,在數字人文的文本編輯階段,利用關聯數據技術與國際圖像互操作框架結合,對文本中的圖文聲像等開放數據進行基于不同時期作品的編輯,例如對一部典籍作品在歷史形成過程中出現的各種不同版本、修訂情況進行整合編輯,利用國際圖像互操作協議(IIIF)對各種版本的圖像文本進行圖像編輯并基于RDF的知識圖譜展示串聯成文獻版本發現證據鏈,這種時空維度下的圖像編輯將超越人文研究傳統文本記錄的界限。第四,在數字人文的內容建模階段,可以根據不同文本內容結構,利用關聯數據和已有本體模型結構對文本內容進行建模,在萬維網的數字環境中,遵循已有的關聯數據規范和推薦協議,完全可以為典籍文獻、文化遺產、歷史遺跡、考古等多維空間虛擬世界建立基于文本內容的仿真模型和研究場景。這些數字人文基礎建設與應用過程是以數字資源描述框架為基礎的關聯數據理伭和技術為支撐的。反過來數字人文中的文本數字化保存、計算分析、圖文編輯以及內容建模等過程也推進了以關聯數據為核心的語義技術架構的改進和發展。
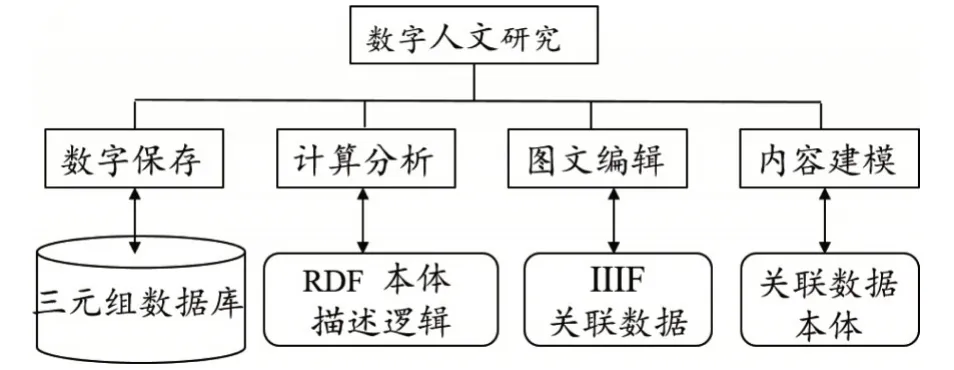
圖1 關聯數據在數字人文中的作用
1.3 圖書館關聯數據與辭書知識組織相關研究
圖書館關聯數據應用是以元數據和書目數據的轉換為基礎開始的。美國國會圖書館2017年將全部館藏和規范目錄從傳統的MARC書目轉換到BIBFRAME(書目描述框架)并推廣使用。已經建成可供參考的重要本體詞表包括元數據集(DCMI)、關聯數據集詞表、古籍書目本體等。國內采用關聯數據技術研究構建特定領域敘詞表應用成為趨勢,近年國內館藏文獻資源關聯數據知識組織相關研究有:夏翠娟等[5]基于關聯數據四原則和語義技術框架設計和發布上海圖書館的家譜本體詞表;白林林等[6]利用Drupal平臺研究中文古籍書目關聯數據發布過程;陳濤等[7]提出書目數據在BIBFRAME中的知識關聯框架;侯西龍等[8]基于關聯數據技術研究非遺知識組織與關聯數據集構建的過程;王曉光等[9]研究敦煌壁畫敘詞表關聯數據;徐晨飛等[10]研究方志物產史料關聯數據構建與知識庫應用。
在辭書語義知識組織研究方面有:《同義詞詞林》[11]及其編碼系統將漢語詞匯按語義分為大類、中類和小類,類下再以同義主題歸集;知網概念關系詞表(HowNet)揭示漢、英詞語概念以及屬性之間的關系;中英雙語知識本體詞網(ECTEC)是結合詞網、知識本體與領域標記的詞匯知識庫;WordNet以同義詞集合表示語義概念;FrameNet使用“框架元素” 進行詞匯含義描述。已有的研究在關聯數據標準規范、中文名稱規范語義描述、本體構建、詞匯語義相似度計算和詞匯語義分類等方面的研究與實踐成果為本文的研究提供了理伭指導和方法借鑒。辭書是人文研究的重要工具,利用關聯數據對中國古代辭書中詞匯語義進行知識組織是數字人文基礎建設的重要內容。本文以《爾雅》詞表構建、本體模型設計與關聯數據發布為例,探索辭書關聯數據知識組織理伭方法與實現過程,以期推進古代辭書典籍的知識組織與數字人文研究。
2 爾雅詞表構建與本體設計
2.1 爾雅詞表構建概述
《爾雅》是中國第一部按詞義和分類編排的綜合性語文辭書。《爾雅》原有20篇,現存19篇按內容分為普通語詞和百科名詞兩個部分[1]。普通語詞即生活中常用的一般詞語,包括“釋詁”“釋言”“釋訓” 三篇。《爾雅》百科名詞共分16個大類,其中有解釋古代親屬關系的 “釋親”,有解釋和反映上古人類日常生活的“釋宮”“釋器”“釋樂”,有解釋古代天象稱謂的 “釋天”,還有解釋古代動物稱謂的 “釋蟲”“釋魚”“釋鳥”“釋獸”“釋畜” 等,每個類篇目下細分小的分類。這些分類反映了戰國至秦漢時代人們的衣食住行等社會生活和文化知識結構,爾雅訓詁資料也成為后人通釋經書和典籍文獻的參考工具。課題以實現辭書典籍語義知識檢索與輔助數字人文研究為目標,研究爾雅多語詞表構建。選取上海古籍出版社2004 年出版的簡體本《爾雅譯注》(胡奇光,方環海著),該書是上海古籍出版社邀請名家歷經10年完成的簡體中文《十三經譯注》之一,可幫助讀者最大程度讀通和理解原著;爾雅注釋還參照南開大學出版社1987年出版的《爾雅今注》(徐朝華著),該書是當代第一次使用語體文為爾雅作注的著作[2]。上述書中的注釋原句引用參考郭璞《爾雅注》、邢昺《爾雅疏》、郝懿行《爾雅義疏》、邵晉涵《爾雅正義》、孫炎《爾雅音義》、黃侃《爾雅音訓》、阮元《爾雅注疏校勘記》,釋義例句參考許慎《說文解字》、劉熙《釋名》、楊雄《方言》、顧野王《玉篇》、司馬光《類篇》、陳彭年等《廣韻》、陸德明《經典釋文》等典籍。爾雅詞表中的詞匯結構由訓釋詞語、被訓釋詞語、例證三部分組成。
爾雅中的訓釋詞語包括類義編碼和釋義兩個部分。對每個被訓釋詞語給出唯一的類義編碼,詞語編碼參考《同義詞詞林》的分類編碼規則,以英文字母大寫的A-S表示《爾雅》中的十九個大類,以英文字母小寫的a-y表示大類之下的2級小類,小寫字母z表示0,以001-999位數字代表概念同義詞集。訓釋詞語或百科名詞稱謂包括中文、英文、日文、韓文,分別以語種標簽cn、en、ja、ko區分語種標記。
被訓釋詞語內容包括漢語拼音、注音、古今字、異體字、通假字,釋義(中文、英文、日文、韓文)、典籍中注釋原句(加雙引號)、注釋者(注者名、字、朝代、籍貫),注釋句典籍出處、典籍中注疏原句和注疏者(名、字、朝代、籍貫)。
例證包括典籍中的例句、例句出處、例句作者(名、字、朝代、籍貫)、例句注釋語句、例句注釋者(名、字、朝代、籍貫)、例句注釋出處、例句注疏語句、例句注疏者(名、字、朝代、籍貫)、例句注疏語句、例句注疏出處、例句注箋句、例句注箋者(名、字、朝代、籍貫)和例句注箋出處。
爾雅詞表全面反映了被訓釋語詞的讀音、字形變化、多語種釋義、分類、例證及其注、疏、箋等內容。比如“釋器” 中的被訓釋詞語“罍”的完整標注如下:
罍/léi/ㄌㄟ'/壺形青銅酒器/Ff003/(cn)古代壺形酒器,與壺相似,用來盛酒或水,多用青銅鑄造,亦有陶制的/(en)Ancient pot shaped wine vessels/(ja)古代の壷形酒器/(ko)?????????/“罍,酒尊也。”/陸德明(名元朗,字德明)/唐/蘇州吳縣(今江蘇省蘇州市)人/《經典釋文》/“罍者,尊之大者也。”/邢昺(字叔明)/北宋/曹州濟陰郡(今山東省菏澤市曹縣北) 人/《爾雅疏》/“我姑酌彼金罍,維以不永懷。”/《詩經·周南·卷耳》/“罍,酒器,刻為云雷之象,以黃金飾之。”/朱熹(字元晦,又字仲晦,號晦庵)/南宋/南劍州尤溪(今屬福建三明市尤溪縣)人/《詩經集傳》
這段標注中被訓釋詞 “罍” 的類義編碼Ff003中,F表示大類“釋器”,f表示小類“酒器”,003表示小類“酒器” 中的壺形青銅酒器,通過Ff003就將不同語種的“罍” 的解釋映射出來,從而實現語義關聯和跨語言檢索。由語言學老師與多名古漢語、英語、日語、韓語研究生,根據《爾雅譯注》中詞語的簡體中文釋義,借助翻譯詞典進行詞語釋義的手工翻譯、標注和校對工作,我們完成了爾雅簡體字版本共3584個被訓釋詞語和百科名詞稱謂,以及2219個訓釋詞語和百科名稱的多語種釋義。爾雅詞表的標注為爾雅本體設計完成了數據準備。
2.2 爾雅詞表本體設計
2.2.1 爾雅詞表本體的定義與設計原則
本體在牛津詞典中解釋為:本體是關于某個主題領域中的概念和類別并顯示它們之間的關系的列表。在知識工程領域,Neches最早給本體的定義為[12]:特定主題領域詞表基本術語及關系,再結合這些術語及關系定義詞表的外延規則。湯姆·格魯伯給本體定義為[13]:一個共享的概念化模型的明確規范說明。張曉林認為[14]:本體就是概念集,是特定領域內公認的關于該領域的對象及其關系的概念化表示,包括對象類等級體系、類屬性及取值約束、對象類之間邏輯關系、對象類及關系的推理規則。根據上述本體概念的解釋,結合爾雅詞表的內容結構,給爾雅詞表本體定義為:爾雅詞表本體是利用本體語言和規范描述爾雅詞表中的被訓釋詞語及百科名詞釋義并給出詞間關系的可視化的語義詞表。用ERYA表示爾雅詞表本體,公式表示為:ERYA={C,P,I,O},公式右邊括號中的C為概念,在爾雅詞表中包括全部訓釋詞語和類義編碼;P為屬性,包括對象屬性和數據屬性;I為實例;O為公理,表示概念的永真斷言,用于被訓釋詞語之間隱含關系推理。與關系型數據詞表相比,爾雅詞表本體的最大作用是實現基于爾雅訓釋詞語概念的分類檢索和詞表的關聯數據開放服務,便于與其他詞表互操作,實現爾雅知識共享和復用;可用于字人文中典籍文本的語義標注,使隱含在文本中的隱性知識顯式化。
爾雅詞表本體設計遵循三個基本原則:首先盡量利用現有的本體數據模型,找到相似本體的類、屬性和關系,在它們的基礎上添加、修改、創建本體;其次最大限度的重用已經發布使用的詞匯表和術語以便于以后的關聯,在此基礎上創建新的術語類及其屬性,盡量給新建詞匯添加注釋信息,如使用rdfs:label屬性定義詞匯標簽;最后要為詞表給出命名空間聲明并賦予一個穩定、永久的URI,為本體本身添加注釋,說明本體的版本及版本兼容信息,以利于爾雅詞表的共享和重用。
2.2.2 爾雅詞表本體設計步驟
爾雅詞表本體模型設計采用自上向下與自下向上相結合的方法,爾雅詞表總體設計采用自上而下的元數據分析方法,參考國家圖書館的《基于元數據的本體構建規范與應用指南》[15],本體模型設計采用自下而上的方法,通過對詞表進行內容分析,制定本體設計流程和步驟。將爾雅詞表本體的設計流程概括為三個步驟。
(1)定義爾雅詞表概念類。通過對爾雅詞表標注字段及內容的分析,定義爾雅本體的實體具名類。類是具有共同屬性特征的個體或對象的集合,所謂具名類就是由設計者在創建本體時直接定義并賦予明確名稱標識的類。
在定義具名類時,共定義5個類(見表1)。從爾雅詞表的元數據中看出,一條完整的被訓釋詞主要涉及到對爾雅被訓釋詞的解釋(erya:Concept)、被訓釋詞所屬分類(erya:Category)、被訓釋詞所在原始例句(erya:Sentence)以及例句的典籍出處(bibo:Book)幾大信息塊,其他的具體信息都可以歸納到這幾大信息塊中,為后續可以和更多的人物知識庫關聯,在典籍出處中又單獨抽出人物類。考慮可以復用現有本體包括國會圖書館bibo 書目本體和foaf 本體的人物類(foaf:Person),首先定義一個表示爾雅概念的類,我們定義一個“Concept” 類表示詞表實體對象的概念集合。爾雅詞表中的詞語釋義和例證來自典籍文獻,把典籍實體抽取出來定義一個表示所有注釋和例證出處的類,這里復用bibo本體中“bibo:Book” 類。爾雅詞表中的訓釋詞語都有唯一的類義編碼,根據爾雅的分類編碼定義一個“Category”(分類)類。爾雅詞表中的詞語釋義包括中英日韓多語釋義句子,還包括例句及其注、疏、箋句,為集中表示句子概念實體,定義了一個“Sentence”(句子)類。爾雅詞表中的人包括作者、注者、注疏者、注箋者等,關于人的實體,有成熟的本體類,復用foaf 本體中的“foaf:Person” 類。這樣就完成爾雅詞表本體5個實體類的構建。爾雅詞表本體類構建代碼如下:
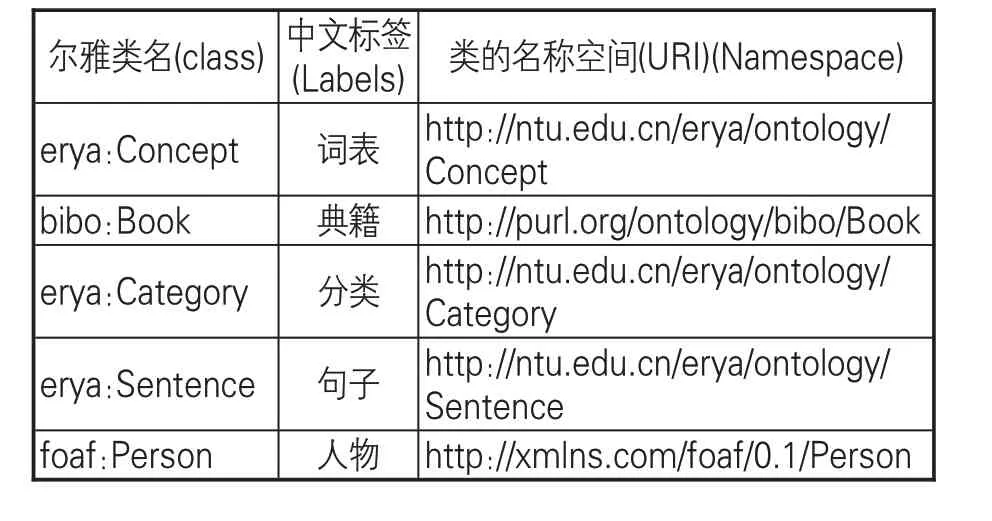
表1 爾雅詞表本體類


(2)定義詞表本體類的屬性及其屬性約束,完成爾雅詞表本體模型(見圖2)構建。詞表本體中屬性的作用是描述類的主要特征以及類和類、類和實例之間的關系。屬性主要有兩種,一種是對象屬性,描述的對象是實體類,另一種是數據類型屬性,描述的對象是字符串、數字、日期等數值型數據。每個屬性都有定義域(領域)和值域,定義域是指屬性的應用范圍(領域中的哪些類),值域是指屬性的取值范圍,對于對象屬性,其值域是某個類,對于數值屬性,其值域就是不同數據類型。爾雅詞表本體類的對象屬性見表2,詞表本體的數據屬性見表3。
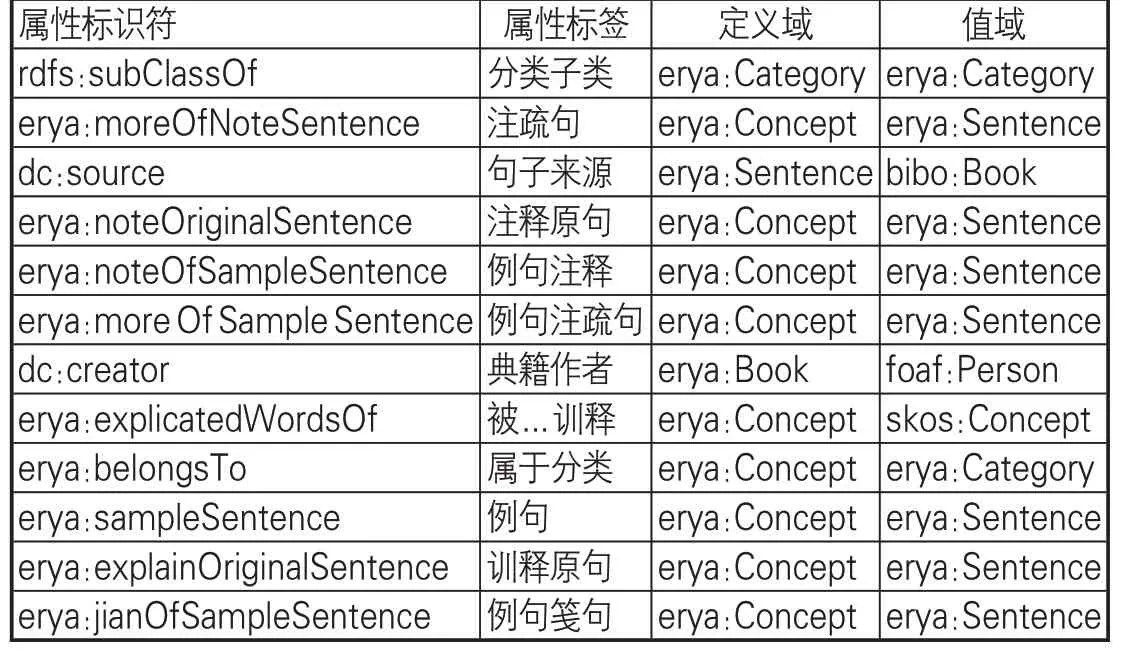
表2 爾雅詞表本體的對象屬性
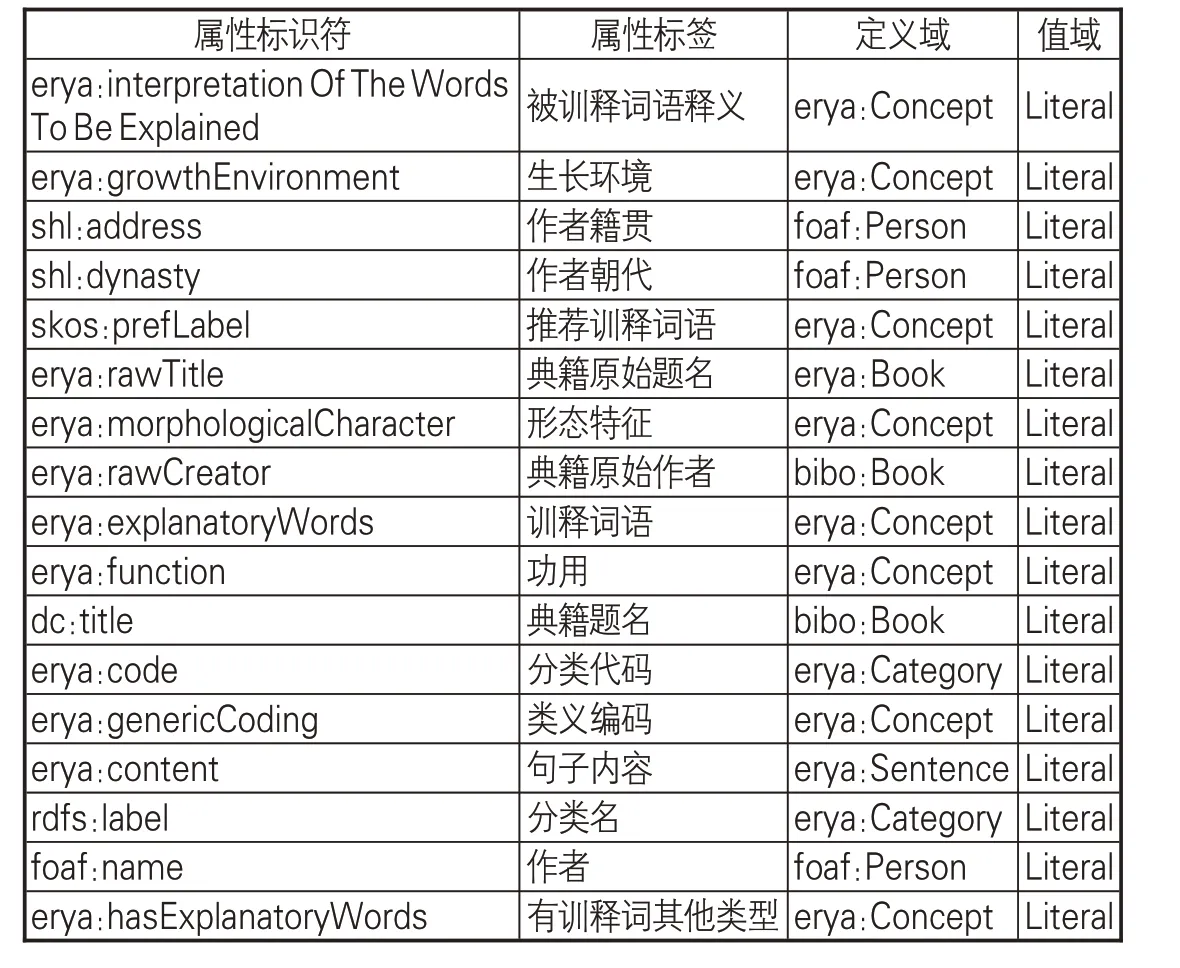
表3 爾雅詞表本體的數據屬性
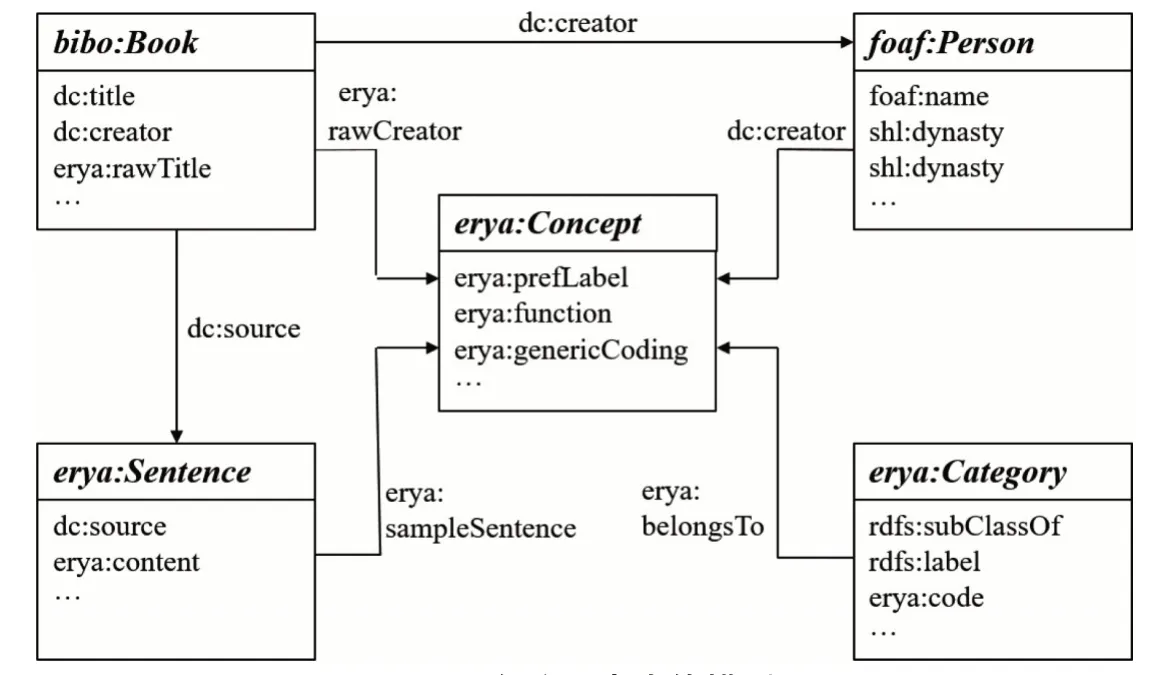
圖2 爾雅詞表本體模型
通過概念抽取程序完成爾雅詞表本體2,219個訓釋詞語概念,3,584個被訓釋詞語和百科名詞異名的術語實例,其中釋詁被訓釋詞語1,029個,釋言詞語653個,釋訓詞語249個,百科詞語1,650個。通過12個對象屬性和17個數據屬性及其約束實現了基于訓釋詞語概念的多維度語義關聯。圖3可視化展示了爾雅詞表本體的概念類及屬性關系。
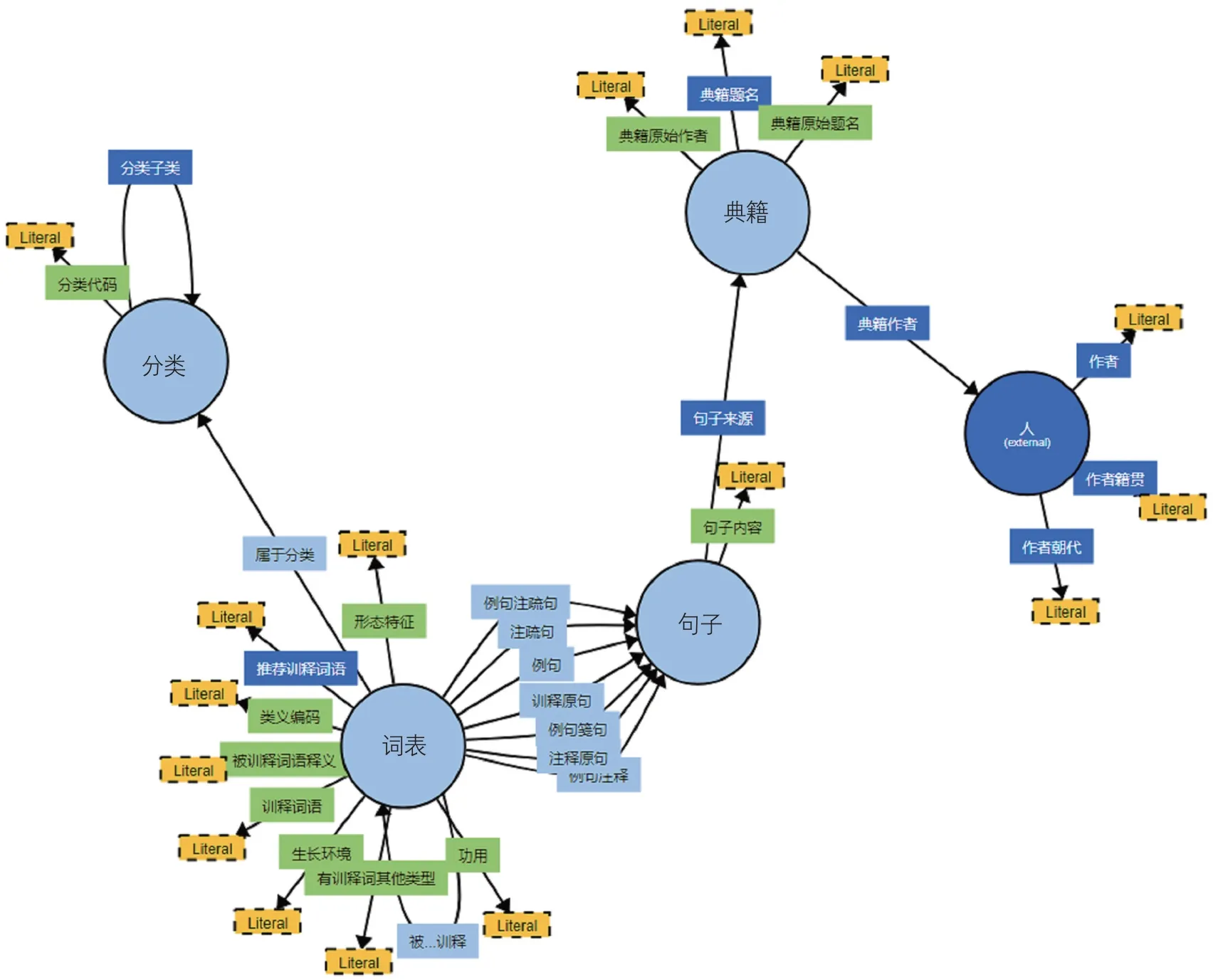
圖3 爾雅詞表本體可視化
(3)為本體本身添加注釋屬性并完成本體的測試、修改和完善。為本體自身添加注釋屬性包括版本信息及名稱空間聲明,版本信息包括版本號、URI、發布機構以及版本兼容信息等,以利于本體的共享和重用。本體的測試采用上海圖書館本體服務中心校驗系統對爾雅詞表數據的正確性和一致性進行數據檢驗,并根據檢測結果對爾雅詞表本體文檔進行糾錯和優化,保證了爾雅詞表本體數據的正確。
3 爾雅詞表本體關聯數據發布與檢索
3.1 關聯數據發布規范與步驟
關聯數據發布是依據關聯數據基本原則對結構化、半結構化和非結構化數據作了規范和限定之后,通過一定技術步驟發布出來以供檢索與數據開放共享的過程。國外圖書館書目數據、敘詞表、元數據相關標準等較早發布為關聯數據本體[16-17]。隨著關聯數據發布實踐的逐漸增多,近年來國內圖書館領域對關聯數據構建的研究水平有很大提高。王忠義等[18]研究將分布式人類計算(DHC)應用于數字圖書館的深層關聯數據發布架構;牛永骎等[19]通過開源軟件D2R發布圖書情報領域學者的關聯數據集,探索實體URI定義、作者重名、專著與網絡學術記錄難以采全等問題;陳濤等[20]以關聯數據七星模型為基礎,結合國外和國內諸多關聯數據發布平臺實施的實例,深入分析關聯數據創建與發布過程中存在的問題和對策思考,提出了關聯數據發布的十個常用規范和建議。這些研究與實踐為爾雅詞表關聯數據的發布提供了指導和借鑒。根據爾雅詞表本體的內容性質與特點,我們提出爾雅詞表關聯數據發布的六個基本步驟(見圖4)和遵循的規范。
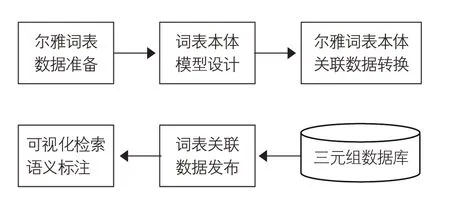
圖4 本體詞表關聯數據發布流程
(1)詞表數據準備。設計爾雅詞表URI時,考慮爾雅URI 除作為爾雅詞表本體的標識名稱之外,還考慮到在爾雅詞表發布后,方便領域人員通過HTTP訪問爾雅詞表資源,設置URI采用了機構域名http://ww.ntu.edu.cn/erya/ontology/,這樣便于今后永久訪問爾雅詞表資源同時利于復用和與其他詞表的關聯。
(2)詞表本體設計。抽取爾雅詞表的數據結構,按照知識組織的標準規范設計爾雅詞表本體,盡量復用已有本體,復用和擴展本體屬性時,區分對象屬性與數據屬性,爾雅本體設計過程中復用了dc、bibo、foaf等詞表規范。
(3)詞表關聯數據轉換。依據本體將爾雅詞表中的數據轉換為RDF格式,從爾雅文本的結構化表格轉換為關聯數據。除了提供SPARQL端口形式以訪問爾雅詞表數據之外,還提供爾雅詞表資源的內容協商獲取方式,支持機器可讀和復用。
(4)詞表的數據存儲。將轉換好的關聯數據存儲到數據庫,采用三元組數據庫存儲爾雅詞表的RDF數據,選用適合爾雅詞表的圖模式進行詞表的數據存儲并與爾雅詞表的關系型數據庫及詞表索引庫共存。
(5)詞表的發布。按照關聯數據四個基本原則與開放數據的七星標準,發布爾雅詞表本體和詞語訓釋實例數據。描述爾雅資源時嚴格區分爾雅本體的類與屬性,在發布爾雅詞表數據集的同時,以高可讀性形式發布爾雅詞表數據集對應的爾雅詞表本體,并加注本體的元數據信息。
(6)詞表本體可視化檢索與應用。提供的數據服務包括爾雅詞表的檢索,提供爾雅數據集的數據狀態,詞表檢索結果的可視化,通過本體對齊,爾雅詞表與外部詞表的鏈接,支持典籍語義標注研究。爾雅詞表按照這樣標準化的步驟和規范發布出來,所有的詞匯都是實體,可以元數據注釋自解釋,爾雅詞表不僅被機器可讀,而且被任意鏈接復用,爾雅詞表中的詞語概念、關系都可以被重用,實現更大范圍的詞表資源互操作。
3.2 爾雅詞表關聯數據轉換與發布
爾雅詞表是基于Excel 的數據表,使用Excel2RDF數據映射轉換完成三元組數據發布。Excel2RDF映射過程見圖5。例如,爾雅原始詞表中的被訓釋詞“俶” 的內容結構見表4-5。
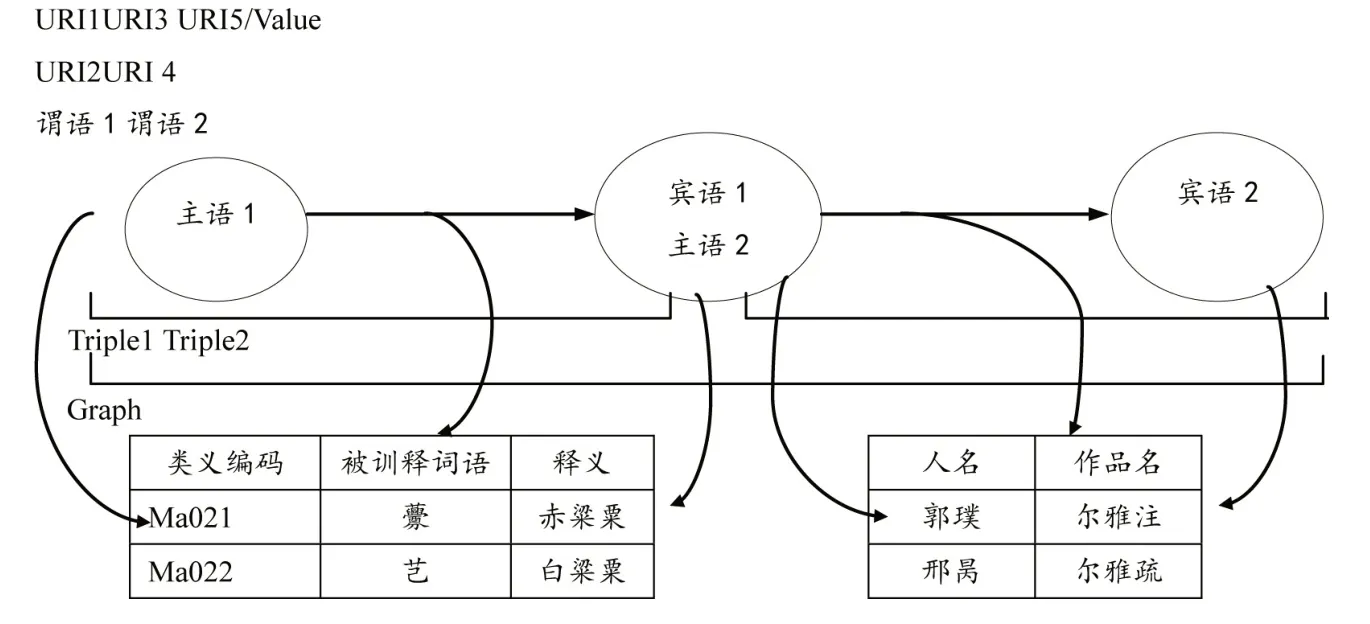
圖5 爾雅詞表Excel2RDF映射過程

表4 “俶” 的訓釋詞語類義編碼

表5 “俶” 的音、形、義標注
第一層是類義編碼層,類義編碼 “A”,表示“訓詁” 類,給出“類義編碼” 的隨機碼URI作主語,取值“A” 作賓語。第二層是訓釋詞語層,訓釋詞語“始也(開始)” 的“類義編碼” 是“Az001”,“訓釋詞語”(ch、en、ja、ko)分別作謂語,表中對應不同列(不同語種的“始也”)作賓語。第三層是有關被訓釋詞語 “初” 的所有列(表中節選了部分),表中的列還包括“俶” 的讀音、注音、古今字、異體字、通假字、釋義、注釋原句、注釋出處、注者、注疏句、注疏出處、疏者、例句、例句出處、例句作者、例句注、疏、箋等,行的主鍵值 “俶” 作主語,表中的這些列都被作為謂語抽取,行的句子數據取值被作為賓語抽取。通過這樣的三層代碼轉換,完成爾雅本體詞表從Excel到RDF的映射。被訓釋詞語 “俶” 的RDF映射轉換代碼如下:

詞表本體簡單的存儲方法是以文件方式保存,適用于數據量小的靜態文件,如已歸檔的本體文件。對動態的數據庫和表格數據的存儲以圖數據庫為主流。爾雅詞表本體是動態表格數據,選擇三元組數據庫存儲(Triplestore),優點包括:模式靈活,可對RDF存儲進行相當于模式更改的實時操作,無需任何停機或重新設計;使用輕便,RDF存儲通常通過HTTP進行查詢,易放入服務架構;語言標準,使用RDF和SPARQL實現的標準化水平遠高于SQL,在系統之間移動數據易,因為語言統一;表達方便,在RDF中對復雜數據建模要比在SQL 中容易,查詢語言SPARQL的操作更容易;蹤跡可尋,SPARQL允許用戶跟蹤每一條信息的來源,并存儲關于它的元數據,輕松完成復雜的查詢。爾雅詞表本體選擇使用OpenLink Virtuoso進行存儲,OpenLink Virtuoso支持關系數據、對象-關系數據、RDF數據、XML數據和文本數據的統一管理,支持sparql1.1語法查詢,支持W3C的關聯數據系列協議,可以把三元組數據直接存儲在數據庫表中,定義了RDF_QUAD表,每個三元組存儲為RDF_QUAD中的一行,表的列分別代表圖、主語、謂語和賓語。RDF_DATATYPE表,保存賓語的類型名和2個字節值的映射。
3.3 爾雅詞表本體的檢索與利用
3.3.1 爾雅詞表本體的SPARQL檢索
爾雅詞表本體存儲到OpenLink Virtuoso后,可以通過SPARQL直接檢索爾雅詞表中的詞語,SPARQL是W3C制定并推薦的在RDF數據庫中查詢和操縱RDF數據的語言和協議,可根據需要通過SPARQL語句描述爾雅詞表中的變量及其關系,構成帶有變量的圖模式查詢表達式,例如查詢爾雅被訓釋詞語“元” 的所有釋義,構造SPARQL表達式查詢見下,SPARQL查詢結果如表6。通過SPARQL 的Restful API 接口,外部系統可以查詢和關聯到爾雅詞表,并獲取相關詞在爾雅詞表中的所有關聯信息。
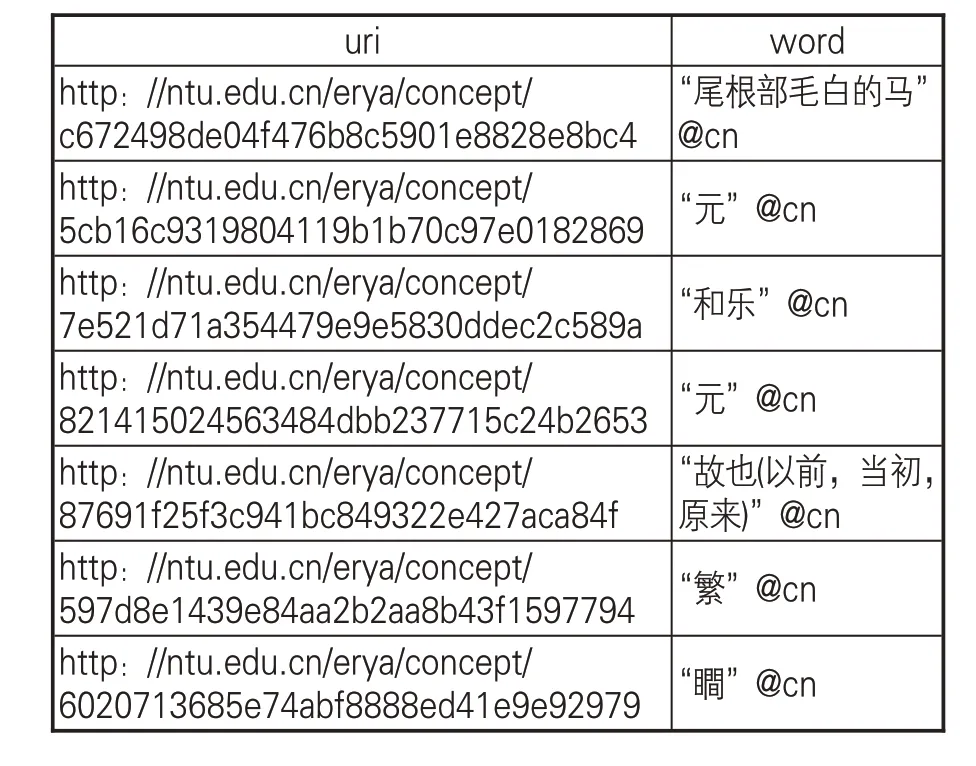
表6 爾雅詞表SPARQL檢索結果

3.3.2 爾雅詞表本體可視化檢索系統
爾雅本體詞表檢索通過可視化檢索平臺SOOOPA,可以檢索爾雅詞表中全部被訓釋詞語及實體類、屬性關聯,并可視化顯示每個實體類及其個體詞語的三元組。比如,查詢 “馬”,如圖6列表顯示爾雅詞表中“釋畜” 類下馬屬子類的全部97 個馬的訓釋詞語以及被訓釋詞語不同馬的稱謂及中、英、日、韓語釋義,注釋出處,例句等三元組數據。圖7可視化顯示 “釋畜” 類 “馬屬”“骃” 字的關聯數據知識圖譜,圖中展示古代一種被稱作 “骃” 的馬的中、英、日、韓文釋義、屬種、注釋原句、注釋出處、詩經中的例句及注釋,也關聯與“骃” 相關的其他馬的稱謂及其解釋,這種圖像化的詞匯知識便于讀者研究和學習古代語言,同時多語言釋義也方便了外語讀者和留學生學習中國古代漢語時作為檢索工具。后續將爾雅詞表本體與圖書館古籍書目本體關聯,可以擴充檢索爾雅注釋館藏出處和版本信息。
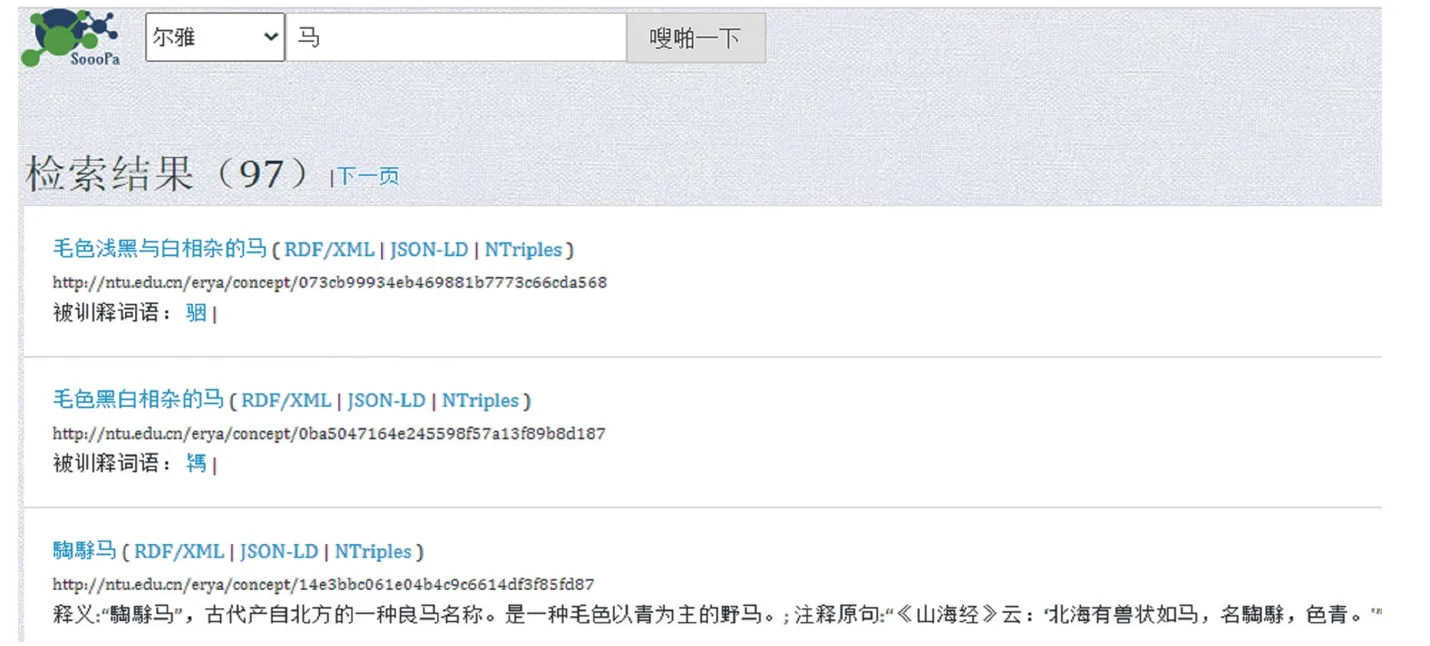
圖6 爾雅詞表本體概念檢索“馬”
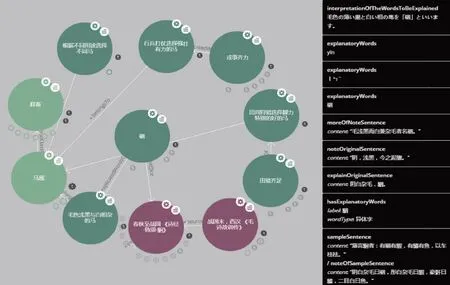
圖7 爾雅詞表中“骃” 字關聯數據知識圖譜
4 結語
為實現古代經典辭書語義知識組織和數字人文研究,通過對辭書爾雅內容的分析,以簡體本的《爾雅譯注》為基礎,構建含有中、英、日、韓文釋義的爾雅詞表,基于此探索以詞表、典籍、句子、分類和人物為實體類的爾雅詞表領域知識本體構建,并定義概念屬性關系,完成爾雅詞匯的實例抽取;再依據本體,對爾雅詞表進行關聯數據映射轉換與存儲發布,實現爾雅詞表本體知識的跨語言關聯檢索與可視化呈現,為典籍數字人文提供了可以復用的辭書多語語義詞典。不足之處在于爾雅詞表本體構建基本以手工方式為主,詞匯內容僅選取的簡體中文版的爾雅注釋,詞匯英文、日文、韓文釋義是參照《爾雅譯注》 中的簡體中文釋義手工翻譯,難免有對古文釋義的深度翻譯不到位的地方,此外還需要豐富不同版本館藏古籍注釋中的詞匯釋義。可以通過辭書典籍標注的眾包平臺,由更多的人文學者參與辭書標注與校對,并研究利用機器學習和自然語言處理的中文分詞和語義標注技術,對典籍注釋進行半自動標注,并在詞表中添加爾雅圖像的內容和注釋,豐富詞表的語言和知識。未來通過研究詞表本體對齊和本體映射技術,可以將爾雅詞表與wordnet 英、日、韓文等多語詞表進行映射關聯,實現詞表詞語更大范圍的在線關聯檢索。此外,還可以利用爾雅詞表構建《詩經》《國語》等典籍知識圖譜,再與機器深度學習技術相結合,對中國典籍文獻進行跨學科機器翻譯、智慧學習等數字人文應用,通過預測典籍知識單元之間的各種關系,包括概念之間的生成關系、上下文關系、同義關系等,從關聯的辭書和典籍資源中發現新概念和屬性關系,并應用于在線學習平臺,支持讀者和外國留學生碎片化閱讀和自助學習。通過對不同時間和地點不同作者的詞匯釋義聚合、比對、推理分析計算,輔助人文學者進行典籍文本挖掘與知識發現研究。
猜你喜歡
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:30
當代陜西(2021年17期)2021-11-06 03:21:36
原道(2020年2期)2020-12-21 05:47:06
當代陜西(2019年15期)2019-09-02 01:52:00
中國非營利評論(2018年2期)2018-06-18 10:48:50
學苑創造·A版(2018年11期)2018-02-01 06:29:20
自動化學報(2017年1期)2017-03-11 17:31:17
讀者(2017年5期)2017-02-15 18:04:18
西藏科技(2016年5期)2016-09-26 12:16:39
振動工程學報(2015年1期)2015-03-01 01:15:42
