面向方志類古籍的多類型命名實體聯合自動識別模型構建*
2021-12-15 12:32:42李娜
圖書館論壇 2021年12期
關鍵詞:模型
李 娜
0 引言
方志即地方志,是在一定體例范疇中,系統記載特定時空下自然、社會、政治、經濟、文化等各個方面情況的專門文獻,被譽為“一方之全史”[1],以起源早、類型全、數量多等特征而聞名[2]。我國保存至今的宋至民國的方志就有8,264種,11萬余卷,成為重要的文化遺產寶庫[3]。地方志承擔著傳承中華文明、延續歷史智慧的使命,“要了解中國文化,必須先了解中國的地方志”[4];它也是一座強大的遠期數據庫,擔負起決策信息支持任務[5-6],整理和利用地方志是我國的優秀傳統。1950年代著名農史學家萬國鼎組織力量,從40多個大中型城市、100多個文史單位的7,200余部地方志中手工整理摘抄物產專題資料,涉及宋至民國期間近900年全國范圍內的物產品種、種植與飼養方法、利用技術等農業生產的各個方面,是農史學界著名的紅本子,曾接待國內外眾多學者前來查詢[7]。
命名實體(Named Entities)是指文本中人名、地名、機構名、時間、數量等具有特定意義的實體,是正確理解文本的基礎。方志類古籍中的命名實體類型多、數量大,蘊含著豐富的關聯關系和隱性知識;通過命名實體識別技術對多類型命名實體及其之間的關聯關系進行分析,能最大化挖掘和發揮方志類古籍的價值。數字人文為方志類古籍文本內容的深度知識組織提供了技術支持[8]。作為學科融合的代表領域,數字人文跨越計算機科學、語言學、歷史學、文學等學科[9],拓展了人文學科研究的廣度和深度[10]。本文以《方志物產》山西分卷為研究語料,探索條件隨機場模型在方志類古籍命名實體識別中的性能和前景。《方志物產》山西分卷共13本,約43萬字,記載了明成化21 年(1485)至民國29 年(1940)間山西境內的物產及相關信息,共收錄51,545條物產信息,涉及植物、動物和貨物3個類別。在人工標注語料基礎上,引入命名實體識別技術中的條件隨機場模型,通過自動識別模型和人機交互系統的構建,實現物產文本信息中別名、地名、人名、引用名、用途名等五類命名實體的一體化自動抽取,形成物產相關的命名實體專題數據庫,建立關聯數據集,為知識發現打下基礎。
1 中文古籍命名實體識別研究綜述
命名實體識別作為文本信息抽取任務中關鍵而實用的一項技術,主要從電子文本中識別出人們感興趣的命名實體,在多種語言和領域有著廣泛的應用,其中英語語料由于詞匯含義的單一性和文本結構的規則性,取得了良好的識別效果。中文字詞含義的多樣性和行文結構的連續性成為中文命名實體識別的障礙,尤其是中文古籍使用繁體字以及無句讀等特點,更是為中文古籍命名實體識別帶來了更大困難。在中文古籍整理領域,命名實體識別的相關研究成果主要集中在國內,從早期基于規則的研究發展到基于條件隨機場的研究,再到深度學習技術的應用,逐步積累了一系列學術成果。
基于規則的研究主要采用詞表和注疏等方式開展。徐潤華等以《左傳》為研究對象,在文獻和注疏自動對齊的基礎上,提出利用古籍注疏分詞的新方法,F值達89%[11];留金騰等采用自動分詞與詞性標注,并結合人工校正的方法,實現《淮南子》語料庫的構建[12];王嘉靈以中古史傳文獻《漢書》為例,利用地名表、人名表、注疏詞表來提高《漢書》的自動分詞效果[13];朱鎖玲以廣東、福建、臺灣三省《方志物產》為語料,通過整理文中地名出現的規則,構建規則庫,與文本內容進行匹配,實現地名識別,準確率為63.38%,召回率為82.89%[14];衡中青以《方志物產》廣東分卷為例,基于規則的方法分別識別文中的引書和別名,其中引書識別的召回率和正確率分別為84.95%和72.88%,別名的召回率為88.6%、正確率為71.6%[15]。
基于條件隨機場的研究是命名實體識別領域比較成熟的方法,取得了較好的識別效果。肖磊[16]、汪青青[17]、李章超等[18]分別針對《左傳》中的地名、人名、戰爭事件結構的特點,基于CRF模型,分別實現地名、人名和戰爭事件的自動識別;梁社會等對比條件隨機場和注疏文獻在先秦文獻《孟子》自動分詞實驗中的效果,發現二者均達到較高的水平[19];朱曉等選擇編年體題材的《明史》作為研究語料,用交叉驗證法對比了條件隨機場的無邊圖、完全圖以及嵌套圖等3種模型的性能[20];黃水清等基于先秦語料庫,分別使用條件隨機場和最大熵模型對地名進行了識別研究,結果表明條件隨機場的識別效果優于最大熵模型[21];李秀英設計了綜合算法,完成了對《史記》漢英對照的術語抽取,實現了漢英典籍平行語料庫的構建[22];黃水清等基于《漢學引得叢刊》中的《春秋經傳注疏引書引得》制定詞匯表,通過條件隨機場模型,結合統計和人工內省方法確定的特征模板,完成對先秦典籍進行自動分詞的探究,最好的調和平均值達到97.47%[23];王錚將條件隨機場模型應用到《三國演義》的地名識別中,準確率為99.16%[24]。葉輝等通過融合多特征的CRF模型提升中醫古籍《金匱要略》中蘊含的癥狀藥物實體的識別效果[25];王東波等構建基于先秦語料庫的CRF模型,自動抽取其中蘊含的歷史事件,構成實體信息[26];袁悅等對比不同詞性標記集在《左轉》《國語》兩部典籍命名實體識別效果的差異性,為先秦古文獻實體抽取與詞性標注提供借鑒[27]。
近年深度學習技術得到快速發展,并在相關領域逐步開展實驗研究,呈現出較好的應用前景。謝韜基于Apriori算法和LSTM神經網絡對宋詞和《史記》語料進行新詞發現實驗,取得較好效果[28];李成名運用深度學習中的LSTM-CRF模型對《左傳》中的人名、地名進行了自動抽取實驗,識別率達82%以上[29];李煥基于BERTBiLSTM-CRF模型對中醫古籍文本中的中醫術語進行識別,明顯提升了識別效率[30];徐晨飛等對比Bi- RNN、 Bi- LSTM、 Bi- LSTM- CRF、BERT等深度學習模型在《方志物產》云南卷中對人名、別名、引書和地名等實體的識別效果,驗證了深度學習方法在方志類古籍實體識別中的可行性[31];杜悅等運用7種深度學習模型從25本經過分詞和人工標注的典籍語料中抽取歷史事件相關實體,驗證了深度學習模型對大規模中文古籍文本挖掘的可行性[32];劉忠寶等在BERT 和LSTM-CRF 模型的基礎上,提出了面向《史記》歷史事件及其組成元素的抽取方法,F1值分別達82.3%和76.0%[33];崔競烽等利用深度學習模型對菊花古典詩詞中的時間、地點、季節、花名、花色、人物、節日等命名實體進行標注和識別,得出BERT 模型識別效果較為顯著的結伭[34]。上述研究成果表明,在中文古籍整理方面,命名實體識別得到廣泛應用,取得了良好的識別效果。隨著技術進步,基于規則的方法逐步被基于CRF的方法和深度學習的方法替代。其中,條件隨機場模型由于突破了隱馬爾科夫模型的嚴格獨立性假設限制,優化了最大熵模型的歸一化處理,解決了標注偏差的問題,可以靈活融合上下文的多種特征,基于條件概率處理序列標注問題,且具有成熟的開源工具,在中文古籍分詞領域有著良好的性能和廣泛的應用;而深度學習模型正處于快速發展的階段,穩定性和適用性都在逐步增強,擁有良好的應用前景。本研究選擇將相對穩定成熟的CRF技術應用于方志類古籍的實體識別,綜合對別名、地名、引用名、用途名、人名等五類命名實體進行一體化識別,并與其他基于規則和深度學習的實驗結果形成對比。
2 識別模型構建
本研究過程主要分為3個部分:一是語料篩選和標注,即從《方志物產》山西分卷中選出備注信息不為空的物產信息,指定語料的標注原則,人工對物產的備注信息進行標注;二是機器學習和模型構建,將人工標注的語料打亂順序后,平均分為10份,每次取其中9份作為訓練語料,讓計算機進行學習,分析并提取標注對象的內外部特征,形成特征模板,根據特征模板完成基于條件隨機場的識別模型構建;三是模型測試,將訓練語料以外的另一份語料作為測試語料,對基于條件隨機場的識別模型進行測試,用召回率R、正確率P和加權平均值F作為測評指標,分析測評結果,評估模型性能。具體的技術路線如圖1所示。本節主要探討語料預處理、特征分析和模型構建的內容。

圖1 研究的技術路線
2.1 語料篩選和標注
(1)語料篩選。首先,根據物產名稱進行語料篩選。在流傳過程中,由于文字變遷、抄寫錯誤、字跡不清等,《方志物產》記載的物產名稱不盡完備。《方志物產》山西分卷中共記載51,545條物產信息,部分物產的名稱中除可識別的漢字外,還包括特殊符號,如 “+、□、(、?)”“鸂□、鷰(鳥衣)、(艸+旹)蘿、??”,代表該處為“缺字” 或“造字” 等情況。物產名稱不完整的數據共273條,約占總語料規模0.53%。為保證數據的原始性和完整性,況且物產名稱不完整并不影響命名實體識別,所以仍保留相關語料,嘗試通過數據對比和關聯等方式完善這部分物產名稱的數據。其次,就文本結構而言,方志類文獻中物產記載方式不一,物產備注信息存在缺失現象。圖2所示是從《方志物產》山西分卷全文數據庫中隨機選取的10條物產信息,可見備注信息空缺的現象。本研究的目的是從物產的解釋信息中抽取別名、地名、人名、引用名和用途名等5類實體信息,因此,語料庫中沒有解釋信息的物產記錄不是本研究的有效語料。《方志物產》 山西分卷記載的51,545條物產信息中,含解釋信息的共9,085條,約占總物產量17.63%。
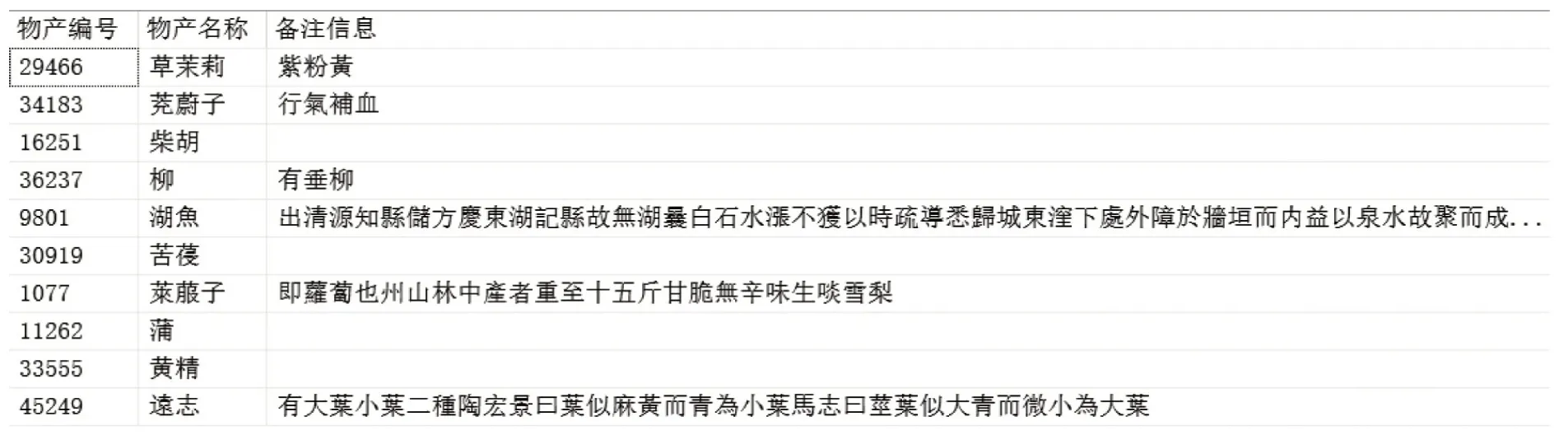
圖2 隨機選取的10條物產名稱及其備注信息樣例
(2)語料標注。為提升機器學習效果,對部分語料進行人工標注。在對物產的備注信息進行標注時,用英文單詞表示對應的命名實體類別,標注時選用大寫首字母表示,以“【”“】” 表示命名實體的左右邊界,具體見表1。標注完成后,9,085條備注信息不為空的物產信息中含別名的有2,522條,含地名的1,308條,含人名的624條,含引用名的1,307條,含用途名的823條,共計6,584條,這是本文進行命名實體識別研究的最終語料。

表1 命名實體標注說明
2.2 標注集生成
在人工標注語料的基礎上,對訓練語料進行一定的標記,用于抽取語料特征。通過計算標注實體的加權長度,明確標注集的長度,生成標注集運用式,如下:
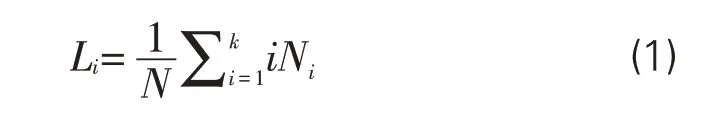
其中,Li表示i≤k當時,命名實體平均加權詞長,Ni表示語料庫中詞長為i的命名實體出現次數,k和i為語料庫中命名實體的最大詞長和最小詞長,N為語料庫中命名實體出現次數總和。例如,L2就表示在k=2時,整個語料庫的中命名實體的平均加權詞長。通過反復計算和實驗測試,本研究確定在《方志物產》的命名實體自動抽取中,使用4 詞位的標注集,即P={B,M,E,S}。其中,B表示命名實體的起始詞,M表示命名實體的中間詞,E表示命名實體的結束詞,S表示非命名實體詞的標記。經過手工標記的語句,如 “旨鹝草 州境出草如綬亦名【A 文章草】”“蝙蝠 其矢名夜明砂【F治目翳障癥】”“蟾酥 出【L 代州】【L 太原】【L 定襄】【L 五臺】【L崞縣】”“太谷蒲桃 見【P高青邱】 詩集今不可得”“虎【C 格物論】 云虎山獸之長”等,標注集的生成結果(樣例)如表2所示。通過生成標注集,將訓練語料處理成一串具有特定標識符的單字,為精確定位命名實體的左右邊界詞及分析邊界詞特征提供便利。命名實體的左右邊界詞是特征模板的重要內容,其分布特征影響實體抽取模型的功能優化和識別效果。
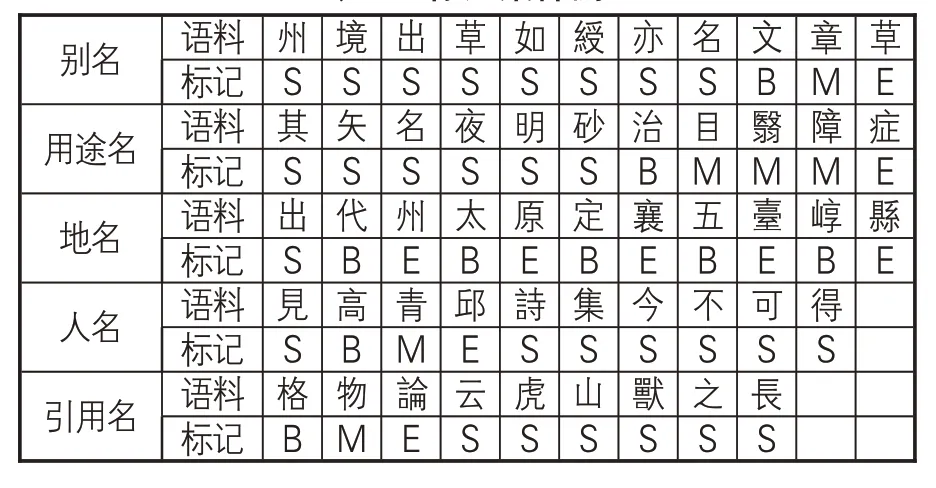
表2 標注集樣例
2.3 內外部特征分析
基于人工標注語料和實體標注集,統計總結命名實體的內外部結構特征,作為核心要素應用到模型構建中。其中,內部特征是指命名實體的詞長及其頻次分布規律,外部特征是指命名實體的左右一元邊界詞及其頻次分布規律。
(1)內部特征分析。命名實體的詞長是指構成命名實體的字數。根據詞長的統計分析結果,可以協助確定及識別序列的跨度。標注語料中共提取出人工標注的別名3,458個、地名2,287個、人名846 個、引用名1,944 個、用途名1,191個。從長度和頻次統計結果看,5種類型命名實體的長度特征如表3所示。從表3可見,除了引用名稍長以外,別名、地名、人名、用途名的長度均集中在1、2、3上,高頻長度能夠涵蓋絕大多數命名實體。詞長的統計分析結果有助于提高模型對實體長度判斷的準確性。
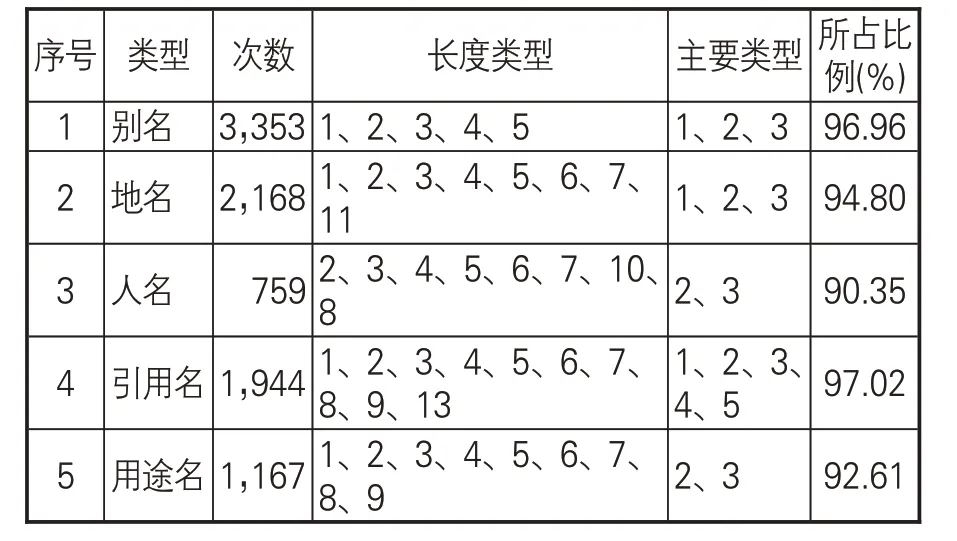
表3 命名實體長度特征統計表
(2)外部特征分析。根據已有標注集,對命名實體的左右一元邊界詞進行統計分析。假設把一條語料表示成 “SLn,…,SLi,…SL1,【R,R1,…,Rn】,SR1,…,SRj,…,SRn”,其中,【R,R1,…,Rn】 代表標注集,SLi代表標注集的左邊界詞,SLj代表標注集的右邊界詞,即可以判定標注集的左右一元邊界詞,即SL1和SR1,其分布狀況運用式如下:
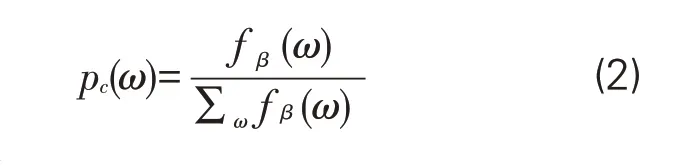
其中,pc(ω)為ω在語料中作為一元邊界詞的頻率,fβ(ω)為ω作為一元邊界詞出現的次數,∑ωfβ(ω)為在語料中出現的總次數。表4所示為各類命名實體的高頻左右一元邊界詞,括號中為該邊界詞出現的頻率。可見,別名、用途名的左一元邊界詞聚集程度較高,最高頻次均達到70%以上;地名的左右一元邊界詞都相對集中,最高頻次均超過70%;人名和引用名的右一元邊界詞較左一元邊界詞更為集中,最高頻次為100%。
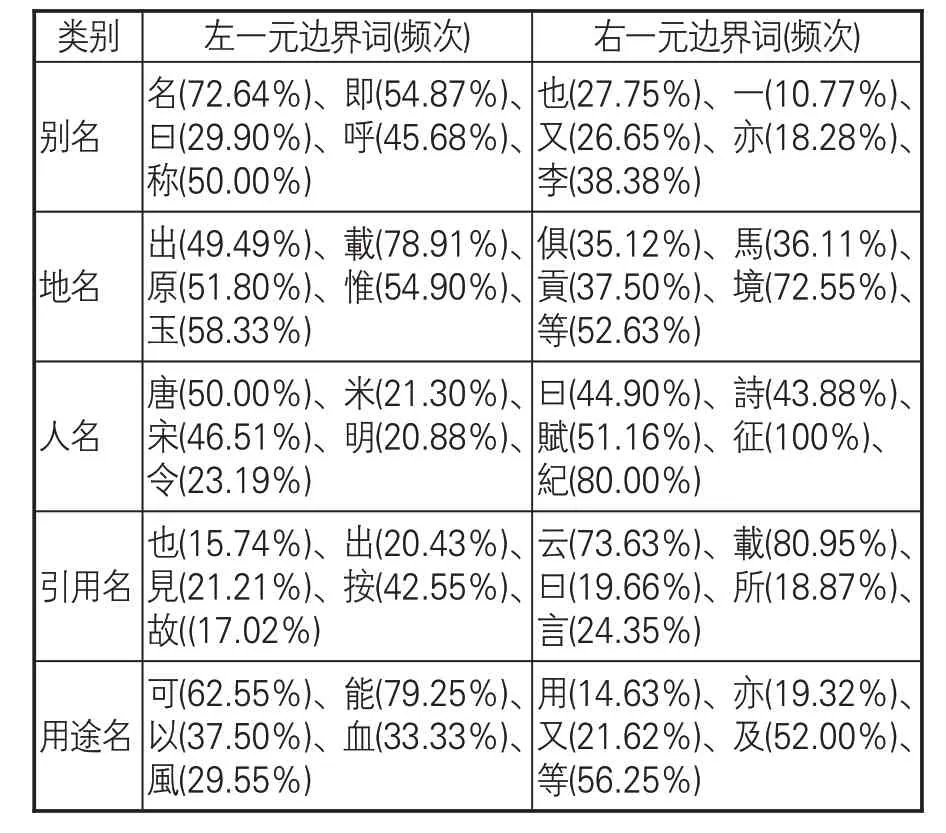
表4 高頻左、右一元邊界詞
2.4 特征模板構建
條件隨機場[35](Conditional Random Fields,CRF)是判別式概率模型,常用于標注或分析序列資料,自然語言是其分析對象之一。設圖G=(V,E)是一個無向圖,Y為已標注序列,Y={Yv|v∈V},X為待標注序列,令X={x1,x2,…,xn},Y={y1,y2,…,yn},如果Yv服從馬爾科夫屬性,則(X,Y)構成一個條件隨機場,滿足p(Yv|X,Yu,u≠v,v,{u,v}∈V)=p(Yv|X,Yu,u~v,{u,v}∈E),u~v表示u是v相鄰的節點。為最大限度地提升模型的識別性能,在基于CRF構建識別模型時,應充分考慮標注語料中上下文結構特征。本模型構建中綜合融入了訓練語料命名實體的內部和外部特征,即上文所分析的實體長度、出現頻次、左右邊界詞等。
(1)實體長度。《方志物產》語料中,最常見的別名長度為2,如 “虞美人 俗稱【A 芙蓉】 ”;最常見的地名長度為2,如 “萆麻子【L平魯】【L朔州】【L馬邑】 有”;最常見的人名長度為3,如“玉簪【P漢武帝】 寵【P李夫人】取玉簪搔頭後宮人皆效之玉簪花之名始此明【P徐文長】 詩曰小院秋深墜碧茵花間猶見李夫人搔頭可綴誰能綴一夜西風夢裏神”;最常見的引用名長度為2,如“艾【C爾雅】 曰水臺王安石【C字說】 曰艾可乂疾久而彌善故字從乂師曠曰歲欲病病草先生艾也”;最常見的用途名長度為2,如“蜂密 一名石蜜以白如膏者良【F潤燥】【F滑腸】【F補中】【F清熱】”。實體長度用阿拉伯數字表示,是識別模型的一個重要特征。
(2)一元邊界詞。命名實體抽取過程中,左右一元邊界詞是識別模型的重要參數。一旦確定了實體的左右一元邊界詞,就鎖定了實體的具體位置,從而抽取出目標實體。在利用訓練語料進行模型構建時,根據人工標注實體的位置標出左右一元邊界詞,用L代表左一元邊界詞,用R代表右一元邊界詞,用N代表非一元邊界詞。語料訓練結果樣例見表5。
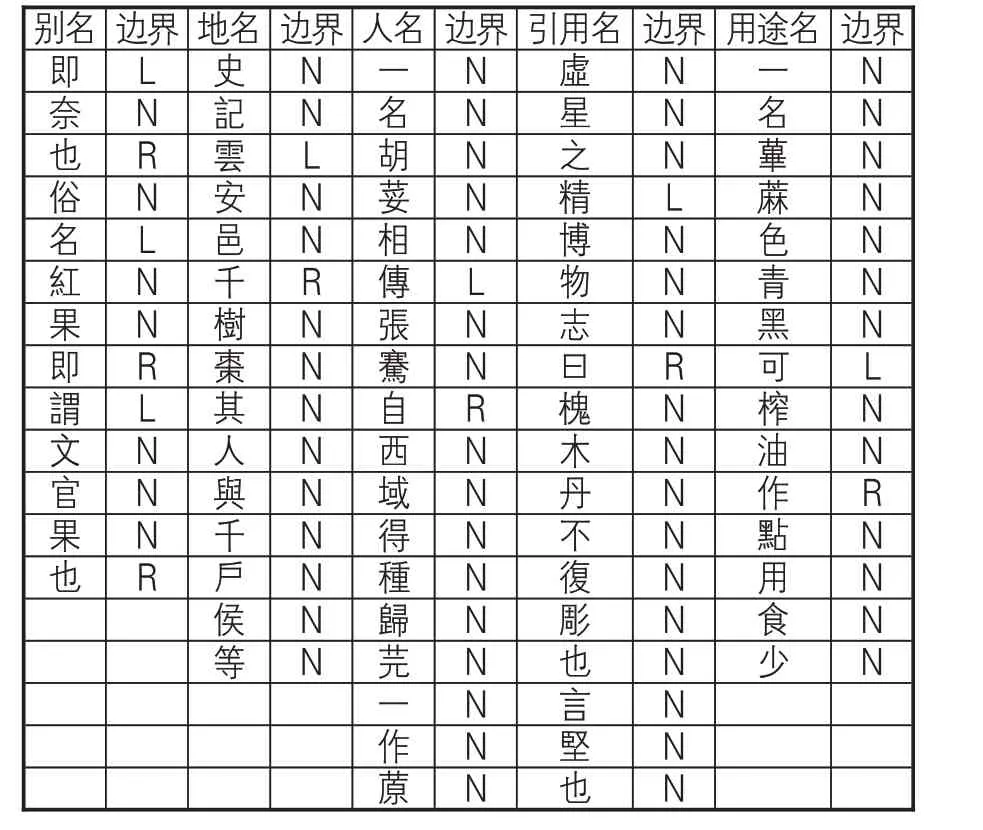
表5 五類命名實體的左右一元邊界詞標注樣例
3 模型測試與結果分析
3.1 模型測試
本研究采用正確率P、召回率R和調和平均數F[36]對基于CRF的命名實體識別模型的識別效果進行綜合評價,用以衡量其在方志類古籍文獻整理中的適用性和應用前景。

其中,correct是模型識別結果中正確的命名實體數量,incorrect是模型識別結果中錯誤的命名實體數量,unrecognized是人工標注出來但模型沒能識別的命名實體數量。
為合理優化和提升模型識別效果,本研究使用十次交叉法驗證不同訓練語料和測試語料下的模型性能。首先,將所有語料隨機亂序排列,并平均分成10等份;其次,每次驗證選取10份中的任意9份作為訓練語料,用于構建命名實體自動抽取模型,將剩余的1份語料作為測試語料,評估模型的性能,共進行10次評估實驗,從而獲得最優模型。五類命名實體測試的最優結果如圖3所示。從最優模型識別結果看,面向《方志物產》 命名實體自動抽取模型的識別效果中,效率最高的是正確率,其次是調和平均數,而召回率相對較低。即,模型識別出的實體中正確的比例較高,但是占全部應識別出的實體比例稍低。五類命名實體中,別名、地名、引用名的效果較好, 最高正確率均達到了95.48%,人名和用途名的識別效果稍差,正確率為70%~80%。
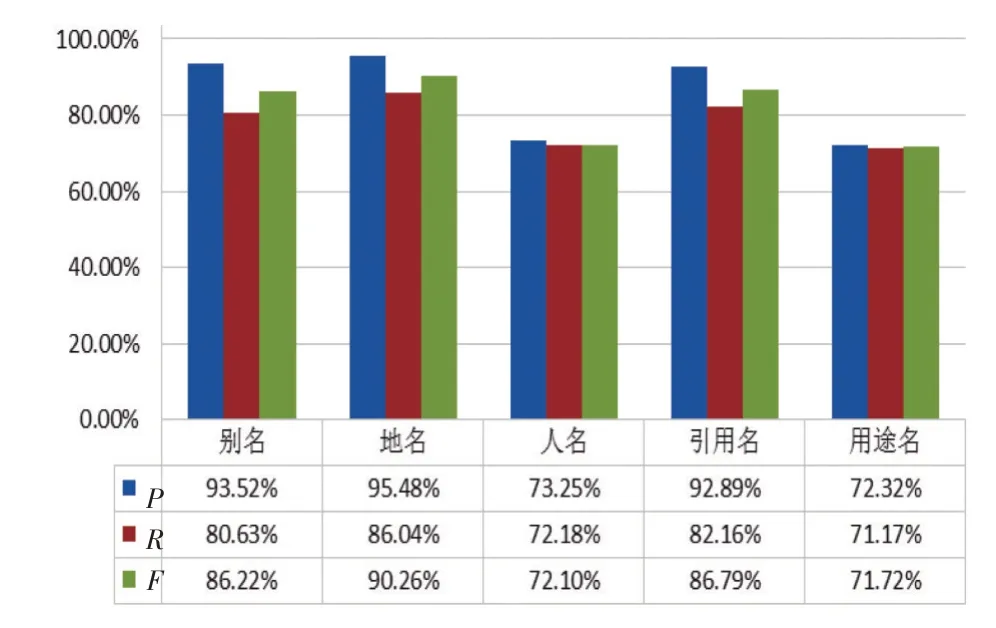
圖3 最優模型的測試結果
3.2 對比分析
近期有學者運用Bi-RNN、Bi-LSTM、Bi-LSTM-CRF、BERT等深度學習模型對《方志物產》云南分卷語料中的別名、人名、地名、引用名進行了一體化識別[31]。其中,Bi-RNN是一種雙向循環神經網絡模型,加入了時間序列的變化,分別從起點和末尾兩端對文本序列進行學習,獲取句子中詞之間的語義關系;Bi-LSTM為雙向長短時記憶模型,引入遺忘門、輸入門和輸出門,更加全面地捕獲文本序列信息,解決語料長距離依賴問題;Bi-LSTM-CRF 模型將雙向長短時記憶模型與CRF模型相結合,既考慮到文本前后序列的關聯性,又解決標記偏置的問題,是較為主流的方法;BERT模型摒棄了RNN循環式神經網絡結構,通過自注意力機制進行建模,采用雙向語言模型提取上下文語義關系,有效解決長期依賴問題,在自然語言處理領域具有突破性表現。本文將基于條件隨機場模型與基于Bi- RNN、 Bi- LSTM、 Bi-LSTM-CRF、BERT 等深度學習模型識別效果中的F1 值進行比較,結果見表6。基于條件隨機場的模型對別名和地名兩類實體的識別效果較顯著,而深度學習在人名識別方面的效果優于條件隨機場模型,二者在引用名的識別效果上基本持平。另外,本研究將命名實體技術首先應用于《方志物產》 中用途名的實體識別,尚未有其他模型的對比數據。
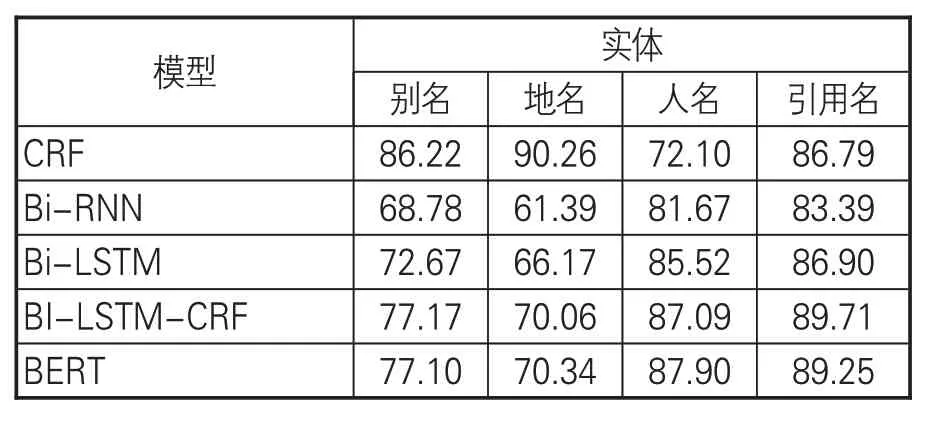
表6 CRF與深度學習模型識別效果F1值比較(單位:%)
3.3 結果分析
分析基于CRF的命名實體識別模型正確率分布,以及對比人工標注與機器識別結果可發現:
(1)識別效果最好的實體類型依次是地名、別名、引用名。這是因為在《方志物產》的編纂過程中,地名、別名和引用名的表述較為規范,且聚集程度高,無伭是在時間線上還是在空間域上,這三類實體重復出現的幾率大,詞長和邊界詞等文本特征相對明顯,在一定程度上提升了模型的識別性能。這三類實體識別錯誤的情況主要集中在以下幾個方面。就地名而言,一種情況是實體不是一個具體的地名,而是一個范圍或者指代性的名詞,導致機器無法根據特征進行精確判別,如語料 “訓峪後溝等十數村” 不是一個確切的常規地名,導致機器識別的結果表現為實體字段識別不全;另一種情況是實體并列出現,如語料 “太原平陽潞安三府及汾澤二州俱出” 中 “汾澤” 二州就因為并列出現而被漏識別。就別名而言,主要存在實體類型判斷錯誤情況,即模型實體抽取是正確的,但是由于多類型命名實體的混合以及語言表達規則的相似性,導致在實體類型劃分時出現了錯誤,如 “赭石” 的語料 “生河東山中別錄曰出代郡者名代赭李時珍曰赭赤色也代即雁門也俗呼土朱鐵”,識別結果為“代赭、雁門、土朱鐵”,顯而易見,“雁門” 并非物產“赭石” 的別名,而是地點“代” 表示的地名,只是因為二者的語言規則相似而被誤判。就引用名而言,主要原因是實體嵌套導致的實體名稱過長,如語料“細莖叢生花豓藍色既開如墜花落結子他邑所無附宋司馬光晉陽三月未有春色詩天心均煦嫗物態異芬芳上國花應爛邊城柳未黃清明空改火元已漫浮觴仍説秋寒早年年八月霜” 中“宋司馬光晉陽三月未有春色詩”,就存在時間、人名、地名、引用名的連續嵌套,導致機器判別出錯。
(2)人名和用途名的識別效果存在著較大的提升空間。其中,人名識別方面,古人除了本名以外,還有字、號、官職、尊稱、謚號等多種別名,實體的長短、出現的頻率等缺乏規律性,機器判別難度大;此外,不同類型的實體嵌套或者混淆的情況較為常見,如“河南王孝瑜” 為地名與人名的嵌套、“白香山” 為地名與人名的混淆、“魏武衛將軍奚康生” 為官職名與人名混淆,“唐段成式” 為朝代名與人名混淆等。而用途名的識別方面,主要立足傳統中草藥的功效角度進行描述,表達方式多樣,不同時代、不同地區或不同志書對同一物產同一功效的描述也不盡相同,且數種功效經常并列出現,如物產 “青蒿” 的語料“處處生之春夏採莖葉同童便煎退骨蒸勞熱生搗絞汁卻心疼熱秋黃冬採根實實須炒治風疹疥瘙虗煩盜汗開胃明目辟邪殺蟲” 中就有“風疹、疥瘙、虗煩、盜汗、開胃、明目、辟邪、殺蟲” 等多種用途名稱的并列使用,成為機器識別精度提升的阻礙。
本文總結的問題與經驗,可以為方志類古籍大規模語料標注和實體識別研究提供借鑒。其中,增強領域專家的介入程度和提高標注人員的語言素養,有助于提升訓練語料人工標注的精度;適當擴大訓練語料的規模,有利于更全面地收集異質性較強的實體類型的特征信息;積極借助現有的數據集和標注標準,有益于排除標注過程中出現的分歧問題,從而提升實體識別模型的總體效果。
3.4 基于實體識別結果的應用
以“菠薐” 和“貫衆” 兩條物產的解釋信息“一名波斯菜詢芻錄云南人呼菠菜北人呼赤根菜劉禹錫嘉話錄本自頗陵國流入中國語訛耳能觧酒毒” 和“出遼州一名鳳尾草李時珍曰葉莖如鳳尾一本而眾枝貫之故草名鳳尾根名貫眾廣雅謂之貫節” 為例,CRF模型對別名、地名、人名、引用名、用途名的識別結果分別為 “‘波斯菜、菠菜、赤根菜’、‘劉禹錫’、‘詢芻錄、嘉話錄’、‘觧酒毒’” 和 “‘鳳尾草、貫節’、‘遼州’、‘李時珍’、‘廣雅’”。根據物產名與命名實體識別的人名、地名、別名、引用名、用途名五類命名實體之間的對應關系,以及物產名所屬的記載時間和地區、物產分類信息等要素,建立起關聯關系(如表7所示),并以此為基礎,開展數據挖掘和知識發現研究。
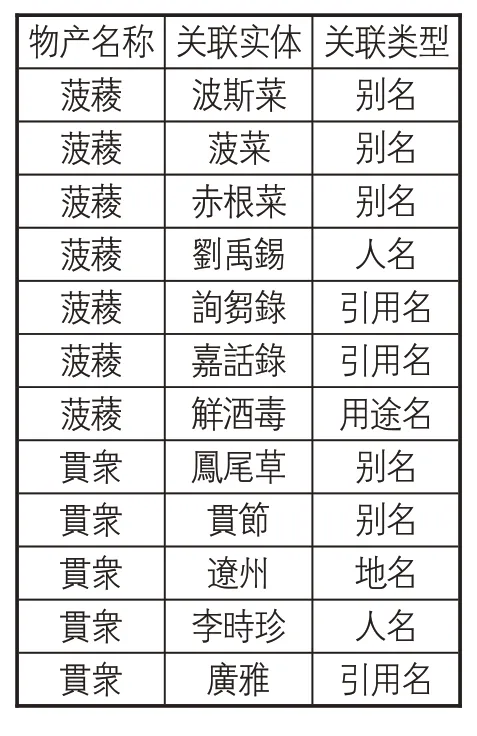
表7 關聯數據識別結果樣例
通過物產與別名的關聯關系,可以挖掘指定物產的別名信息,還可以發現哪些物產擁有相同的別名,為分析別名的來源提供了資料支撐;通過物產與人名的關聯關系,可以挖掘物產在傳播的過程中,受到哪些歷史人物的影響,是在哪些方面產生了影響,如命名方面、文學方面、種植技術方面等;通過物產與時空的關聯關系,不僅可以挖掘物產橫向地域上的變遷,還可以挖掘物產在縱向時間上的消長,將物產與社會變遷、生態環境等緊密聯系起來;通過物產與引用名之間的關系,可以了解具體物產在哪些古籍文獻或詩詞歌賦或民間諺語中記載或流傳,為資料查找提供重要線索;通過物產與用途之間的關聯關系,可以挖掘物產在生活、民俗、藥用等方面的價值,為進一步深度利用打下了基礎。例如,圖4為依據物產與人名之間關聯關系而生成的知識圖譜,可以根據不同的需求開展不同緯度、不同角度的深度剖析;圖5是來源志書在時空范圍的分布圖,呈現了不同朝代山西境內不同地區的志書修撰情況,這從側面反應了物產記載的詳略程度;圖6是物產與時空之間關聯關系的分布圖,展示了棉花在山西引種和傳播的進程。
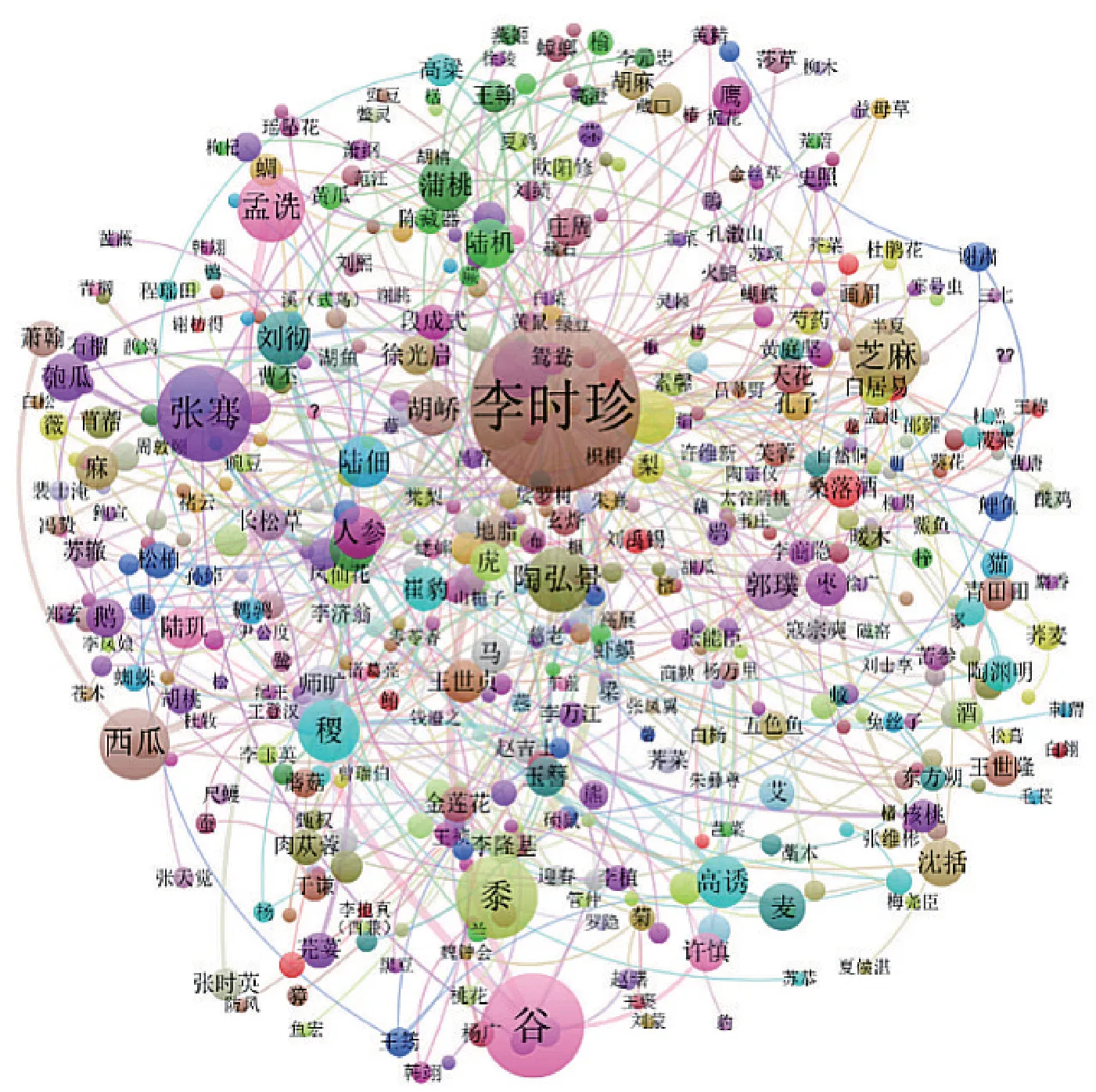
圖4 物產與人名之間的關聯關系可視化圖
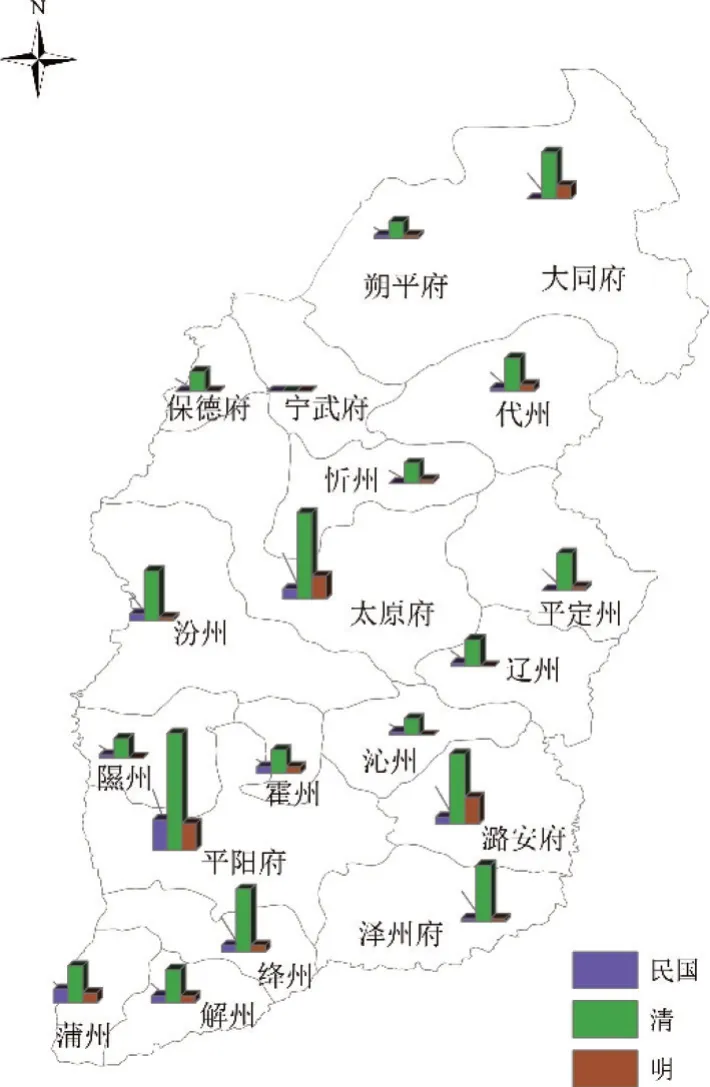
圖5 志書的空間分布圖
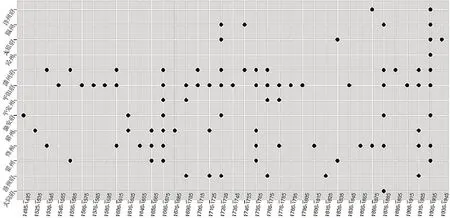
圖6 物產“棉” 的時空傳播分布圖
4 結語
本文以《方志物產》山西分卷為研究語料,基于條件隨機場構建多類型命名實體復雜識別模型,實現了文本中別名、地名、人名、引用名和用途名五類命名實體的自動抽取,并應用十次交叉法對模型識別性能進行測評,取得了較好的實驗結果。本研究驗證了在方志類古籍的知識挖掘中,條件隨機場模型能發揮較好的效果,具有較高的可行性和較好的應用前景,為大規模方志古籍以及其他類古籍的挖掘利用研究提供借鑒。
但是,本研究仍然存在有待進一步提升的空間:語料規模小,僅以山西一省物產資料為研究對象,占全國語料1%左右,規模偏小;標注精度低,人工標注者的農史底蘊薄弱,導致人工標注不夠完善;模型特征少,模型構建中僅采納了長度、頻率、左右一元邊界詞作為特征,沒有全面覆蓋所有特征信息。
在未來研究中,需要逐步擴大語料規模,從一個省份擴展到多個省份,直至全國;引入農史專業學者對語料進行深度標注、提升標注程度,構建標注標準體系,以便在更大范圍內推廣;獲取更多語料特征,豐富特征模板,完善識別模型的功能,提升識別效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
