基于卷積神經網絡的解扭曲車牌檢測識別方法
2021-11-20 01:57:16王曉峰
計算機工程與設計 2021年11期
關鍵詞:檢測
王 昆,王曉峰,劉 軒,郝 瀟
(1.山西大學 物理電子工程學院,山西 太原 030006;2.國網山西省電力公司檢修分公司,山西 太原 030000)
0 引 言
自動車牌識別[1]是檢測識別技術的重要應用,該技術一般首先進行車輛和車牌檢測,然后通過光學字符識別[2](optical character recognition,OCR)識別出車牌號。雖然該技術已經取得了長足發展,但大部分車牌識別方法主要針對車輛和車牌的正前方視角,很少考慮更寬泛的圖像采集場景。研究非理想情況下的車牌識別具有更高意義和價值。
隨著前沿科學的發展(如深度學習),越來越多的車牌識別技術采用新技術以獲得高精度的快速識別。如Hsu等[3]基于YOLO網絡[4],通過輕微改動,擴大網絡輸出粒度以提升檢測數量,并為兩種類別(車牌和背景)設定了概率。Zhang等[5]根據車牌形態的結構化特點,改進Yolov2提取不同網絡深度的多級細粒度特征,但對于復雜清晰或較為模糊的情況下處理效果不佳,聚類方法有待提高。Xie等[6]對兩個基于YOLO的網絡進行了訓練,以檢測旋轉后的車牌。但該方法僅考慮平面上的旋轉,未考慮由于相機視角傾斜而造成的更復雜的形變。
另外,卷積神經網絡[7](convolution neural network,CNN)應用較為廣泛,如Dong等[8]提出了一個基于CNN的車牌字符識別。通過感興趣區域池化層對候選車牌區域所對應的特征圖進行裁剪。Selmi等[9]基于形態算子、高斯濾波、邊緣檢測等預處理方法,尋找車牌區域和字符。
為了適應更多不同類型和不同拍攝情況下的車牌檢測,本文提出了一種檢測解扭曲-卷積神經網絡(detection untwist-convolution neural network,DU-CNN),其主要工作總結如下:①采用了來自YOLOv3空間變換網絡理念,通過SPP模塊將不同分辨率的特征圖轉換為設計好的和全連接層相同維度的特征向量,避免了圖像的尺寸對于所提DU-CNN網絡的限制;②通過對仿射變化的系數進行回歸,將發生形變的車牌重新“解扭曲”為接近正前方視角的矩形,使車牌識別的適應性更好;③為了增強訓練數據集,由真實數據和人工合成數據組成混合數據集。實驗結果驗證了所提方法具有較好的魯棒性和識別精度。
1 提出的方法
本文提出的方法包括3個主要步驟:車輛檢測、車牌檢測和OCR。給定一張輸入圖像,第一個模塊檢測場景中的車輛。在每個檢測區域內,利用提出的檢測解扭曲-卷積神經網絡(DU-CNN),搜索車牌并對每個檢測進行一次仿射變換回歸,由此將車牌區域修正為接近正面視圖的矩形。將這些修正后的檢測輸入到OCR網絡中,以進行最終的字符識別。
1.1 車輛檢測
車輛檢測是很多經典檢測和識別的基礎,例如PASCAL-VOC[10]、ImageNet[11]等,因此,本文并未從頭進行檢測器的訓練,而是根據一些標準,選擇一個已知模型來進行車輛檢測。首先,要求具備較高的查全率,因為對任何一輛包含可見車牌車輛的漏檢,都會直接造成一次車牌完全漏檢。其次,還需要具備較高的查準率,以使運行時間較低。基于這些考量,本文使用YOLOv3網絡,其執行速度快(幀率約70 FPS),且在查準率和查全率之間有著較好的平衡。
YOLOv3是YOLO家族的第3個版本,在執行效率和檢測準確率方面都有所提升,對于一般YOLO系列的目標檢測方法,或者其它較為復雜的網絡等,檢測的準確性取決于最終的分類,而分類層由全連接層組成,由提取特征的數量確定。原始YOLOv3網絡的一個重要缺點是圖片尺寸必須是固定的,輸入到網絡的圖像尺寸必須是416×416像素,這在實際情況中很少遇到。
針對上述情況,很多時候將輸入的圖片(或視頻)進行一些預處理操作,例如圖像剪裁、拉伸和縮放等,這會造成圖像的有效信息的丟失,最終會導致圖像的檢測精度下降。因此,本文在原始YOLOv3網絡中添加空間金字塔池化(spatial pyramid pooling,SPP)模塊,SPP模塊結構如圖1所示,其由何愷明等[12]提出。引入SPP的原因就是為了避免圖像剪切、旋轉、縮放等操作造成的圖像信息失真,同時解決圖像特征的重復提取的問題,能在一定程度上降低計算成本,提高計算效率。使用SPP后,不同尺寸的圖片得到的池化特征是一樣長度,通過SPP模塊將任意分辨率的特征圖轉換為設計好的和全連接層相同維度的特征向量。這是因為SPP使用了多個池化窗口,對特征圖進行池化,將得到的結果合并之后作為輸出結果,保證了固定長度的輸出。因此,圖像的尺寸對于添加了SPP模塊的YOLOv3并沒有限制。

圖1 SPP的模塊結構
在輸入DU-CNN前,重新調整陽性檢測的尺寸。一般來說,較大的輸入圖像有助于較小目標的檢測,但會造成計算成本上升。在接近正前方(后方)的視圖中,車牌尺寸和車輛包圍框之間的比率較高。但該比率在傾斜(側面)視圖中會變得小得多,因為車輛的包圍框會變得更大和更長。因此,為保持車牌區域的可識別性,需要將傾斜視圖調整到比正面視圖更大的尺寸。雖然可以利用3D姿勢估計方法決定尺寸調整范圍,但為了高效快速,本文提出了一種基于車輛包圍框縱橫比的方法。當車輛尺寸與其包圍框之間的比率接近1時,可以使用較小的尺寸,隨著該比率變大則需要增加輸入圖像尺寸。具體來說,尺寸調整因子fsc給出如下
(1)
式中:Wv和Hv分別為車輛包圍框的寬度和高度。Dmin≤fscmin(Wv,Hv)≤Dmax, 因此Dmin和Dmax限定了重新調整后最小尺寸的包圍框的范圍。基于實驗并盡量在準確度和運行時間之間保持較好的平衡,選擇Dmin=288,Dmax=608。
1.2 車牌檢測和解扭曲
車牌本身是矩形的平面目標,附著在車輛上作為身份標識。為充分利用其形狀,本文提出了一種變型的卷積神經網絡DU-CNN。該網絡學習對發生各種不同形變的車牌進行檢測,并通過對仿射變化的系數進行回歸,將發生形變的車牌重新“解扭曲”為接近正前方視角的矩形。雖然在仿射變換之外也可使用平面透視投影,但透視變換中涉及到的觸發可能會生成很小的分母值,由此產生數值不穩定性。
本文在開發DU-CNN時采用了來自YOLOv3空間變換網絡[13]理念。DU-CNN的檢測過程如圖2所示。首先,將重新調整大小后的車輛檢測模塊的輸出饋送到該網絡。由此生成一個8信道特征圖,其對目標/非目標概率和仿射變化參數進行編碼。為提取扭曲車牌,首先考慮圍繞cell(m,n)中心的一個固定尺寸的虛構正方形。如果該單元格的目標概率超過某個給定的檢測閾值,則部分回歸參數用于構建仿射矩陣,將虛擬正方形轉換為車牌區域。由此可以輕易地將車牌解扭曲為水平對齊和垂直對齊的目標。

圖2 DU-CNN的檢測過程
1.2.1 網絡架構
提出的架構共包含17個卷積層,其中10層位于殘差區塊內,其架構如圖3所示。所有卷積濾波器的尺寸均固定為3×3。在除檢測區塊之外的整個網絡中均使用線性修正單元(rectified linear unit,ReLU)激活函數。網絡中包含4個尺寸為2×2的最大池化層,步長為2,以將輸入尺寸降低到原來的1/16。最后,檢測區塊包含兩個并行的卷積層:①一個卷積層用于推斷概率,由softmax函數激活;②另一個卷積層用于仿射參數的回歸,沒有激活函數(或等效地使用恒等式F(x)=x作為激活函數)。

圖3 提出的DU-CNN網絡架構
1.2.2 損失函數
設pi=[xi,yi]T,i=1,…,4, 表示帶注釋的車牌的4個角點,以順時針從左上角開始。同樣,設q1=[-0.5,-0.5]T,q2=[0.5,-0.5]T,q3=[0.5,0.5]T,q4=[-0.5,0.5]T表示以原點為中心的標準單位正方形的對應頂點。
對于一張高度為H,寬度為W的輸入圖像,網絡步長為Ns=24(4個最大池化層),則網絡輸出特征圖的大小為M×N×8,其中M=H/Ns,N=W/Ns。 對于特征圖中的每個點cell(m,n),均需要估計8個數值:前兩個數值(v1和v2)為目標/非目標的概率,后6個數值(v3至v8)被用于構建局部仿射變換Tmn
(2)
式中:采用v3和v6的最大值函數以確保對角為正(避免不必要的鏡像或過度旋轉)。
為匹配網絡輸出分辨率,通過網絡步長的倒數重新標定點pi, 并根據特征圖中的每個點(m,n)重新確定中心點。通過應用正則化函數來實現這一點
(3)
式中:α為度量常數,代表虛構正方形的邊。設α=7.75, 即增強訓練數據集內最大和最小車牌尺寸之間的中點除以網絡步長。
假定一個目標(車牌)位于cell(m,n)位置,損失函數首先考慮標準正方形的扭曲版本,和車牌的正則化注釋點之間的誤差,定義如下
(4)
其次,損失函數要估計目標是否位于(m,n)的概率。與SSD(single shot Multiplebox detector)檢測的置信損失[14]相似,損失函數基本上為兩個對數損失函數之和
fpr(m,n)=logloss(∏obj,v1)+logloss(1-∏obj,v2)
(5)
式中: ∏obj為目標指示函數,如果在點(m,n)存在一個目標,則返回1;如果在該點不存在目標,則返回0。 logloss(y,p)=-ylog(p)。 如果目標的矩形包圍框與以(m,n)為中心的另一個相同尺寸的包圍框之間的交并比(IoU)大于閾值γobj(根據經驗將該閾值設為0.3),則考慮該目標在點(m,n)內。
合并式(4)和式(5)中定義的項,最終的損失函數如下
(6)
1.2.3 訓練
為訓練提出的DU-CNN,本文創建了一個包含196張圖像的數據集,其中105張圖像來自于Cars數據集,40張圖像來自SSIG數據集(訓練子集),51張圖像來自AOLP數據集(學習子集)。由于減少了訓練數據集內注釋圖像的數量,因此數據增強的使用是至關重要的。本文使用了如下增強轉換:
(1)糾正:基于車牌注釋對整個圖像進行糾正,假定車牌位于一個平面上;
(2)縱橫比:在區間[2,4]內隨機設定車牌的縱橫比,以適應來自不同地區的車牌尺寸;
(3)居中:車牌的中心成為圖像中心;
(4)縮放:對車牌進行縮放,使其寬度匹配40像素至208像素之間的一個數值(基于車牌的可讀性,根據經驗設定)。使用這一范圍定義式(3)中α的數值;
(5)旋轉:以隨機選擇的角度執行3D旋轉,以涵蓋較大的相機范圍設置;
(6)鏡像:50%的幾率;
(7)平移:從圖像中心對車牌進行隨機平移,僅限于移動中心周圍208×208像素的一個正方形;
(8)裁剪:在平移之前考慮車牌中心,并圍繞該中心裁剪出一個208×208的區域;
(9)顏色空間:對HSV顏色空間進行較小修改;
(10)注釋:使用與增大輸入圖像時應用的相同空間變換來調整車牌4個角的位置。
通過以上選擇的轉換處理,可以從單個手動標注的樣本中得到具有非常明顯視覺特征的各種增強測試圖像。本文使用ADAM優化器,以mini-batch(批尺寸32)對網絡進行100 000次迭代訓練。學習率設為0.001,參數β1=0.9,β2=0.999。 通過從訓練集中隨機選擇并增廣樣本,生成mini-batches,由此在每次迭代后,可得到尺寸為32×208×208×3的新輸入張量。
1.3 光學字符識別
提出的系統使用修改后的YOLOv3網絡在經過校正的車牌上執行字符分割和識別,即,光學字符識別(optical character recognition,OCR),利用電子的方式從圖片中提取出文字信息,然后用于其它領域,如文字編輯、搜索和識別等。該網絡架構與文獻[15]相同。但本文研究利用合成和增強數據,極大擴展了訓練數據集。
人工創建的數據包括將一個字符串(7個字符)粘貼到有紋理的背景上,然后執行不同操作,例如旋轉、平移、噪聲和模糊等隨機變換。圖4描述了合成數據生成的流程,合成數據的使用能夠顯著提升網絡通用性,從而實現使用完全相同的網絡處理來自世界不同地區的車牌。

圖4 合成數據的流程
2 實驗與分析
實驗使用的硬件配置為一個Intel i7處理器,8 Gb RAM和一個NVIDIA Titan X GPU。上述配置能夠以8 FPS 的均值(針對到所有數據集)運行完整的ALPR系統。運行時間取決于輸入圖像中檢測到的車輛數量。因此,提高車輛檢測閾值將得到更高的FPS,但會降低查全率。開發環境為Python 3.5語言的PyCharm集成開發工具,原始YOLOv3由Keras框架提供。
2.1 數據集
本文的目標之一是開發在各種非約束場景下均性能良好的識別技術,因此,本文選擇了4個可用的在線數據集,即OpenALPR[16]、SSIG[17]和AOLP[17](路面巡邏),這些數據集覆蓋了大量不同的環境,見表1。本文考慮了3個不同的變量:車牌角度(正面和傾斜)、車輛與相機的距離(近、中、遠),以及圖片拍攝的地區。

表1 數據集介紹
在車牌失真方面,AOLP-RP子集是難度較大的數據集,其試圖模擬相機安裝在巡邏車輛上(或手持)時的情況。在車輛與相機距離這一方面,SSIG數據集的難度最大。該數據集由高分辨率圖像組成,即使車輛距離較遠,車牌依然具備可讀性。這些數據集均不包括同時展示多個車牌的情況。
這些數據集已經覆蓋了大量場景,但數據集依然缺少挑戰性圖像。因此,本文還手動注釋了包含120張圖像集合,該集合包含近、中、遠距離,車牌角度有很多是傾斜的,且車牌具有一定模糊,有國內和國外的車牌。一些示例圖像如圖5所示。

圖5 本文數據集示例圖像
2.2 結果分析
提出的方法的實施流程中包括3個網絡,根據經驗設定以下可接受閾值:車輛(YOLOv3)和車牌(DU-CNN)檢測的可接受閾值為0.50,字符檢測和識別的可接受閾值為0.45。實驗中,如果車牌的所有字符均被正確識別,且未檢測到額外字符,則視為一次正確識別。對所有數據集均應用了完全相同的網絡:對于給定類別的車牌(例如歐洲或中國),未使用任何特定訓練程序對網絡進行調整。僅針對數據集在系統流程中做出了微小改動。
圖6給出了使用本文方法獲得部分具有代表性的識別案例。由圖6可以看出,對于傾斜,甚至一定的遮擋等情況,本文方法依然可以準確識別出車牌的重要標識。

圖6 部分識別案例結果
為了進一步分析討論,本文使用了兩組訓練數據對提出的系統進行評價,以展示在訓練程序中納入全合成數據的收益:①第一組訓練數據包括真實增強數據,以及人工生成的增強數據;②第二組僅包括真實增強數據。兩者分別表示為“真實+合成”和“無合成”,見表2。從表2中可以觀察到,添加全合成數據提升了準確度(AOLP數據集的增益約為5%)。此外,為凸顯對檢測包圍盒進行校正的收益,還給出了使用普通未校正包圍盒的實驗結果,見表2“未校正”。與預期相符,當使用未校正包圍盒時,大部分正面視圖的數據集的結果變化較小(處理OpenALPR數據集時的性能甚至出現微小提升),但在包含難度較大的傾斜車牌數據集(AOLP和本文數據集)中,使用未校正包圍盒會顯著降低準確度。表2還給出了商用和學術系統的實驗結果比較,“/”表示沒有采用對應數據集。結果表明提出的系統在受控場景數據集(車牌大部分在正前方,包括OpenALPR和SSIG)中的識別率與商用系統大致相當或更優。

表2 不同數據集的準確率結果/%
值得一提,文獻[5,6,8]僅著眼于單個地區或數據集。性能比較驗證了所提方法具有很好的通用性。值得一提,在大部分較難的數據集(AOLP和本文數據集)中,使用所提方法的車牌識別率,大大高于直接對注釋后的矩形車牌包圍盒應用OCR模塊的識別率。該增益源自于DU-CNN所支持的解扭曲操作,該操作能夠極大提升車牌扭曲程度較強時的OCR性能。簡單來說,通過為每個檢測單元生成一個仿射變換矩陣,實現對扭曲車牌的檢測和解扭曲。這一步驟降低了OCR網絡的工作量,減少了后者需要處理的失真情況,增強了總體識別性能。
為了進行較差拍攝情況下的識別比較,本文遴選30幅較大傾斜或模糊情況下的所獲圖像,本文方法采用校準后的方式,與商用“森諾”車牌識別進行比較。由圖7可以看出基本上,在字符檢測和識別的可接受閾值在0.45左右,兩種方法均能差不多達到各自最佳準確率,但對于較差情況下的識別,本文方法更勝一籌,商用系統“森諾”的檢測識別算法較少考慮極端情況,因為商用系統的CCD相機拍攝角度固定,要求的車道也是固定的,基本不考慮極端情況。若遇到不按規矩行車的司機或新手司機,可能會造成無法識別的情況,LED顯示牌顯示“臨時車”,司機則不得不重新倒車再檢測。這間接驗證了所提方法的解扭曲操作的確可以提高OCR性能,增強系統的適應性。
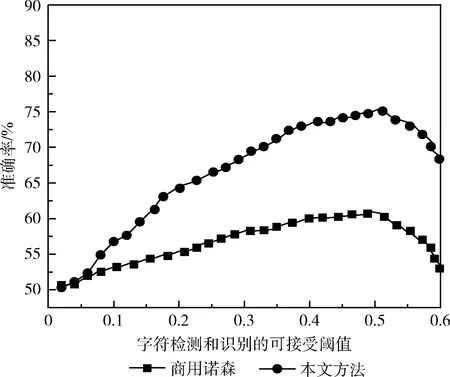
圖7 與商用系統在較差情況下識別性能比較
3 結束語
本文提出了一個用于非約束場景基于深度學習的車牌檢測識別系統。通過為每個檢測單元生成一個仿射變換矩陣,實現對扭曲車牌的檢測和解扭曲,這一步驟降低了OCR網絡的工作量,減少了后者需要處理的失真情況。通過在網絡中添加SPP模塊,避免了不同分辨率特征圖對識別結果的影響。結果表明,所提方法在困難數據集(其中車牌以較大傾斜角度拍攝)中的性能優于當前其它方法,且在受控數據集中也能夠取得較好結果。
未來,本文可能將解決方案擴展至摩托車的車牌檢測,其主要挑戰是摩托車或電瓶車車牌與汽車車牌有著不同的縱橫比和布局。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
