基于多維特征和候選項的易混手寫英文識別
2021-11-20 01:57:12付鵬斌宋冬雪楊惠榮
計算機工程與設計 2021年11期
付鵬斌,宋冬雪,楊惠榮
(北京工業大學 信息學部,北京 100124)
0 引 言
手寫英文字符識別是光學字符識別(optical character recognition,OCR)的一個重要分支,研究人員提出了多種方法[1-5]進行手寫英文字符的識別。近年來,為了提高易混手寫字符的識別準確率,現有的研究方法可以分為兩類:以特征提取[6-8]為中心,以神經網絡[9-11]為中心。以特征提取為中心的方法旨在通過找到字符高質量的特征并加強特征的表征能力來進行易混字符的區分。Inkeaw等[12]提出了一種利用潛在表征區域的梯度特征來增強圖像特征的識別方法。Jangid等[13]提出了一種基于由類間方差和類內方差之比定義的統計度量,增強字符的可分辨部分的特征元素以進行判定。這類方式雖然能夠對字符的形態特點進行直觀性描述,但是對于產生形變的字符識別準確率并不高,缺乏魯棒性。另一方面,以神經網絡為中心的方法專注于開發一個復雜且高度區分的分類器,以更好地區分易混字符。Shao等[14]提出了一種基于多實例學習的易混字符識別方法。Wang等[15]提出使用層次化結構的卷積神經網絡來區分易混字符。盡管這些研究中提出的識別分類器在易混字符識別方面表現良好,但由于分類器的復雜度較高,通常需要大量的樣本進行訓練,耗費較多時間。
本文通過分析易混字符相似區域的特點和字符間構成單詞的相關性,提出一種結合多維特征和候選項區分易混手寫英文字符的識別方法,進一步加強字符識別結果的可信度,有效提高了易混手寫英文字符的識別準確率。
1 基于CNN的字符識別
1.1 數據準備
本文基于已公開的NIST、Chars74k數據集上擴充收集了包含不同年齡段作者的手寫英文數據,并以此為基礎,經過腐蝕、膨脹、加噪等一系列圖像形變操作算法,形成了共38類包含大小寫的手寫英文字符數據集,其中將大小寫書寫形式相同的字符,合并成了同一類字符,這樣的字符為 {C/c,F/f,K/k,L/l,M/m,O/o,P/p,S/s,U/u,V/v,W/w,X/x,Y/y,Z/z}。 最終形成了每類手寫英文字符圖像約10 000張,共計373 352張的手寫英文字符數據集。
1.2 字符識別
文中所用的手寫英文字符識別網絡是基于CNN構建的網絡模型,網絡結構為兩個卷積層、兩個池化層和兩個全連接層。
本文采用的網絡模型如圖1所示,其中輸入的是28×28的圖像,C1和C3層代表卷積層,S2和S4是池化層,F5和F6 是全連接層。整個網絡第一層卷積設定有32個5×5大小的濾波器,從而得到32個28×28特征圖。第二層池化層設定池化的大小為2×2,經過這層池化操作后,圖像的長和寬都縮小一半,從28×28變到了14×14。再經過第三層的卷積操作,特征圖數量變成了64。經過第四層又一個2×2的池化層后得到了64個7×7大小的特征圖之后進入全連接層。選取了兩個全連接層,第一個全連接層設置的神經元的個數是1024個,相當于把7×7×64的特征圖轉化成一個1024的列向量,第二個全連接層的神經元個數是38,即文中確定的英文字符分類數。

圖1 CNN識別模型
1.3 實驗測試及分析
為驗證使用模型的有效性,實驗統計了該模型對手寫英文字符的識別準確率。將數據準備階段構建的手寫英文字符數據集,經過篩選、歸一化后,每類字符的數量按照4∶1的比例劃分為訓練集和測試集。實驗結果如圖2和圖3 所示,手寫英文字符識別在測試集上的平均識別準確率是96.52%。
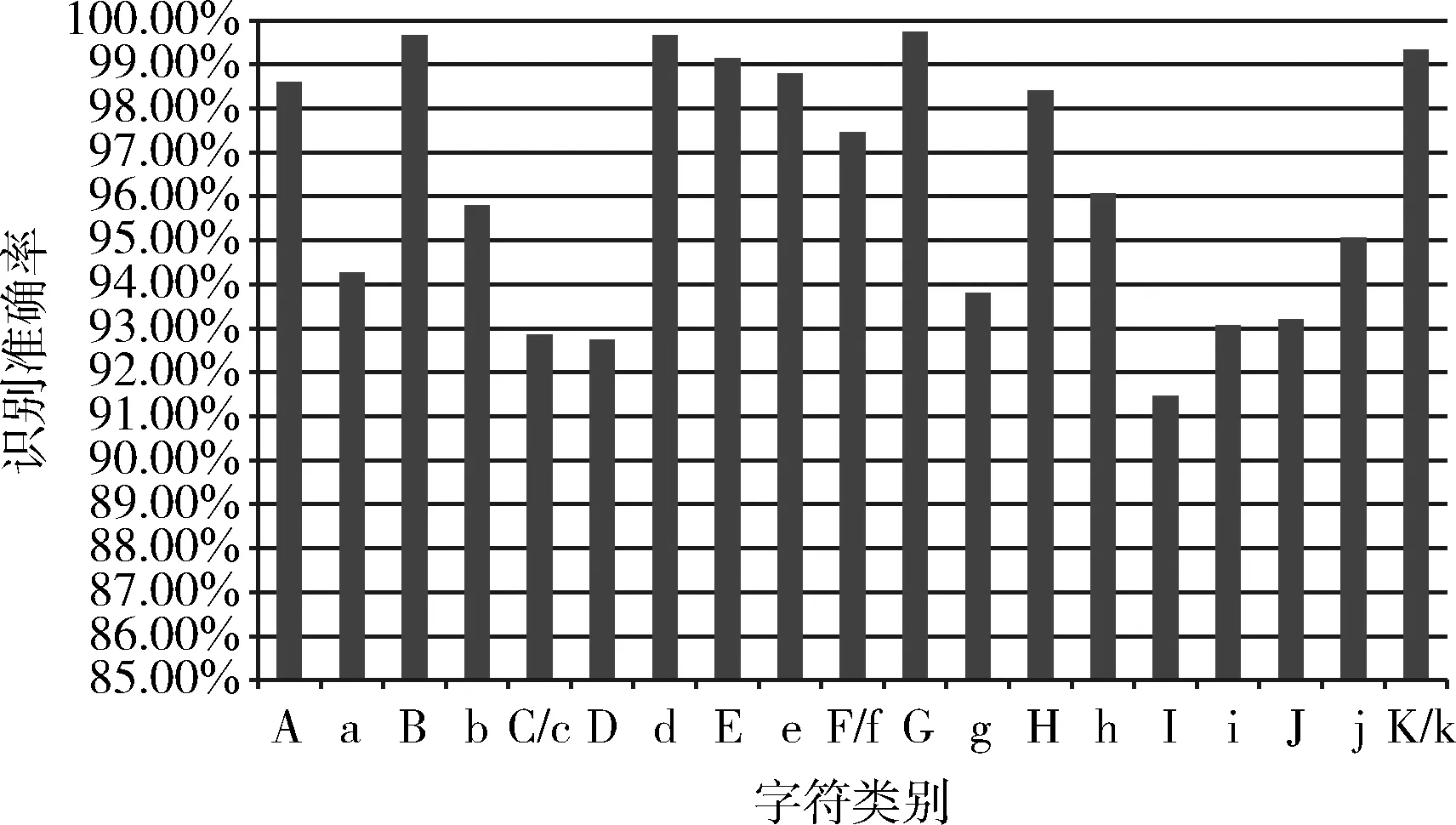
圖2 字符“A-K/k”的識別準確率
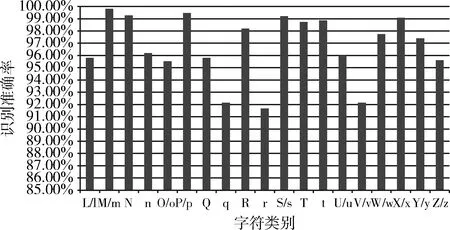
圖3 字符“L/l-Z/z”的識別準確率
由圖2和圖3可知,其中“a”,“C/c”、“D”、“g”、“I”、“q”、“r”、“V/v”等字符識別準確率均低于95%,并且“I”和“r”的識別準確率低于92%。與整體字符的平均識別準確率相比,存在一定的偏差。通過分析其識別結果發現,主要誤差造成的原因是易混字符的誤識。由于英文字符筆畫簡單,某些字符的字形相差不大,基于神經網絡的字符識別算法,字符的特征提取蘊含在模型訓練過程中,所以在初次識別時,由于易混字符的特征相似,會有較大概率出現分類錯誤的現象。因此,對于易混字符,有必要根據其相似區域找到差異性從而進行針對化的識別,彌補識別的不足。
2 易混字符的識別
2.1 易混字符類別劃分
通過卷積神經網絡得到的特征向量以SoftMax回歸的形式輸出手寫字符歸屬于每一類的概率大小。輸入一個手寫字符圖像,其輸出向量在每個類別的概率大小反映該樣本識別為該類別的置信度。一般置信度最大的字符就是識別結果。定義置信度最大的識別概率為第一識別概率pi,1, 依次類推,第二識別概率pi,2, 第三識別概率pi,3…pi,n。 設待識別字符圖像經過卷積神經網絡識別后輸出的第一識別概率pi,1代表的字符為初步識別結果Ri,待識別字符對應的正確識別結果為Ci,統計易混字符類別的算法如下:
步驟1 輸入:字符初步識別結果Ri,字符正確識別結果Ci;
步驟2 統計識別過程中與正確識別結果Ci比較,不等于Ci的Ri分別出現的次數,用F(Ci,Ri) 表示;
步驟3 計算混淆概率P(Ri|Ci)
(1)
F(Ci) 表示所有識別結果出現的次數;
步驟4 對所有混淆概率根據P(Ri|Ci) 的大小進行排序;
步驟5 取排序后的前N個Ri代表字符作為Ci的易混字符;
步驟6 統計各類字符中包含易混字符的公共部分,定義為同一類易混字符。
根據以上算法進行統計,將易混字符劃分為以下6類:
(1)a,Q,q,g
(2)b,D,o
(3)c,l
(4)I,l,i,J,j,z
(5)n,h
(6)u,v,r,y
通過分析造成字符易混的影響因素,又可將以上類別細分為表1所示的易混字符對。

表1 易混字符類別
2.2 易混字符的判定
對字符經過卷積神經網絡進行初步識別之后,設定判斷識別結果是否可信的條件如下
pi,1>α&&pi,2<β&&pi,3<γ
(2)
即需要同時滿足第一識別概率大于閾值α,第二識別概率小于閾值β,第三識別概率小于閾值γ的條件,這樣才認為該字符的識別結果可取。對大量手寫英文字符的識別結果進行分析,通過表2列出的部分因易混字符而造成的誤識和其識別概率也可以看出,一般因為易混字符而造成的識別錯誤,其正確識別結果出現在識別概率排名前三位的字符中。
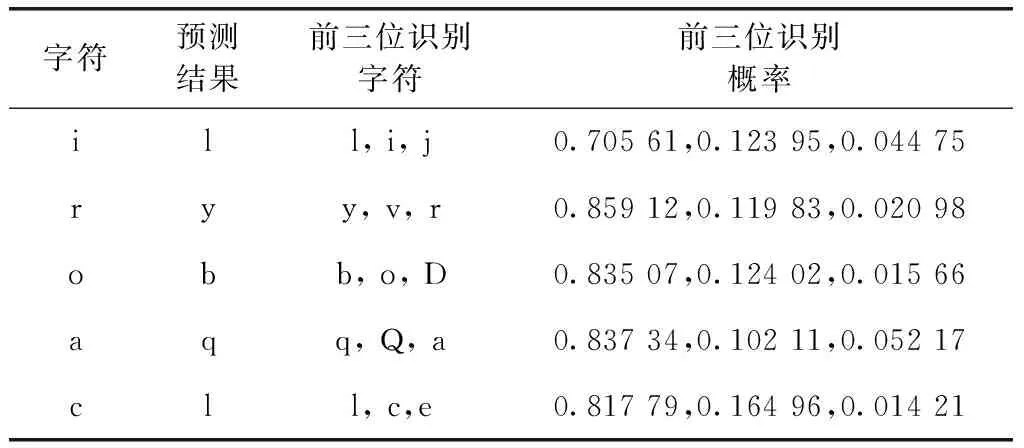
表2 部分因易混字符而造成的誤識結果和識別概率
因此對易混字符的判定可以表示為
pi,1<α&&pi,2>β&&pi,3>γ
(3)
通過實驗計算后得出,當α=0.9,β=0.1,γ=0.01時,若字符的識別概率滿足式(3),并且前三位識別字符中包含易混字符中的某一類,則認為該字符為易混字符。
2.3 多維特征提取
對于易混字符結合特征對其識別,關鍵在于提取穩定的、最能體現字符間差異的特征。因此,在確定是易混字符造成的誤識之后,首先需要確定易混字符的區分區域,在區分區域的基礎上進行多維特征的提取。通過對大量易混字符樣本進行觀察和分析,定義了以下字符的多維特征,具體定義如下:
定義1 鏈碼特征
鏈碼是通過給定單位長度的序列來描述圖像輪廓信息的一種特征,如圖4所示,本文所用是八方向鏈碼表示。對一個連通的像素序列來說,其輪廓曲線的鏈碼可以定義為 {a0…ai…an}, 其中ai∈{0,1,2,3,4,5,6,7},n表示圖像矩陣化后的點集數。如圖5(a)和5圖(b)所示,繪制字符“D”和“O”的外輪廓鏈碼圖,在圖中按照箭頭所指方向開始進行編碼。對于手寫字符“D”和“O”來說,其顯著的區別在于字符左側輪廓的變化趨勢,字符“D”的相對趨勢變化一直為第三象限的方向,而字符“O”則存在第三到第四象限的方向變化趨勢。
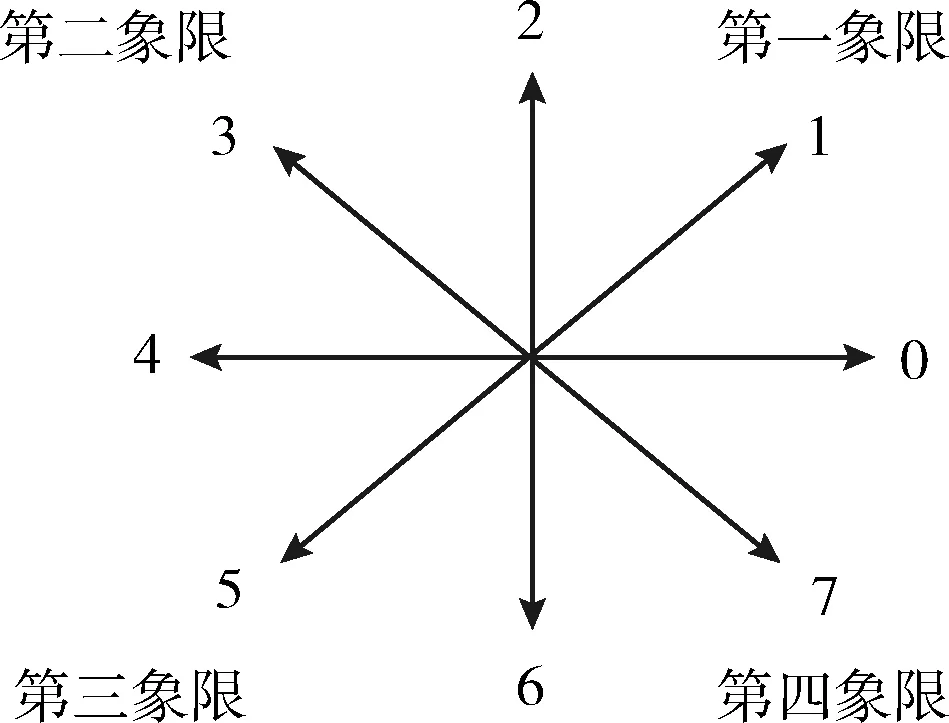
圖4 鏈碼方向碼表示
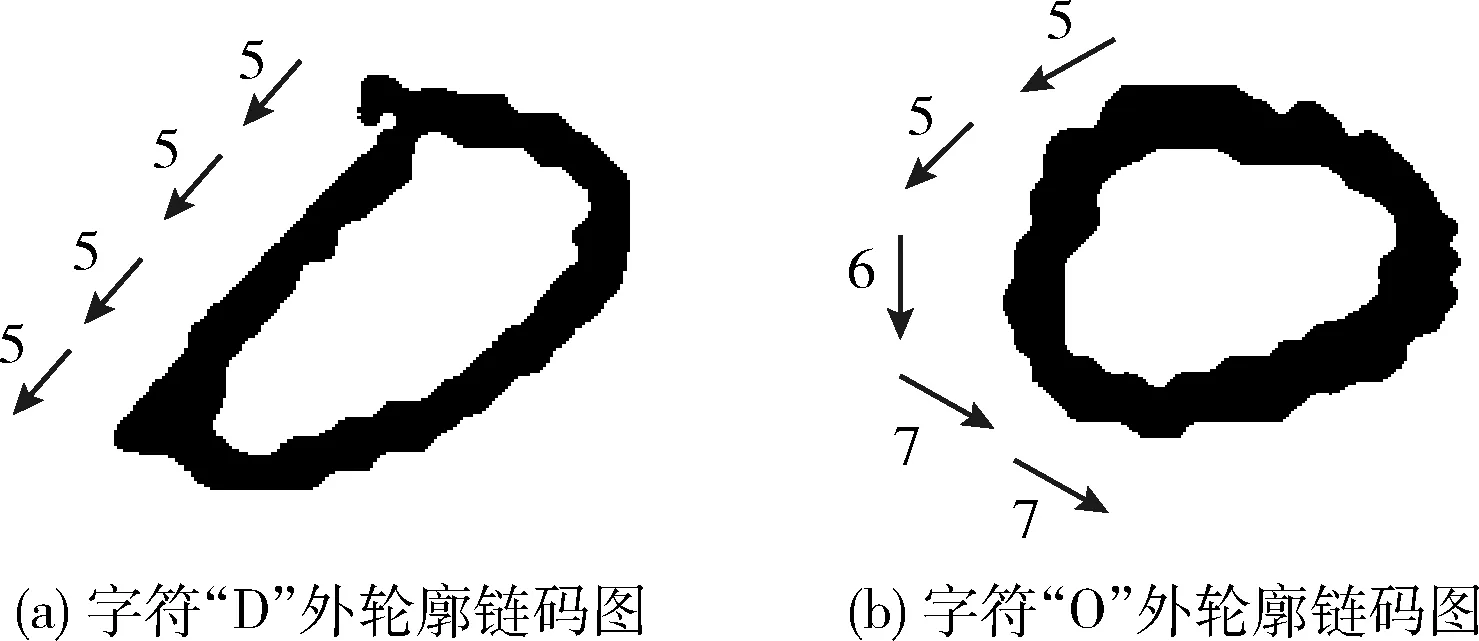
圖5 鏈碼特征
定義2 橫縱向交截數特征
在矩陣化的圖片上,通過在每一行插入水平射線和在每一列上插入垂直射線,射線上像素的黑白交替變化次數即為橫縱向交截數特征。從圖6可以觀察到,對不同手寫英文字符來說,在不同區域位置的橫縱向交截數會有所不同。例如字符“v”和“y”,從兩個字符的高度起點開始,從上往下到字符高度終點,每行進行水平射線穿插,字符“v”水平射線穿插出來的橫向交截數是2的行數占整個圖形總行數的比例一定大于字符“y”的比例。
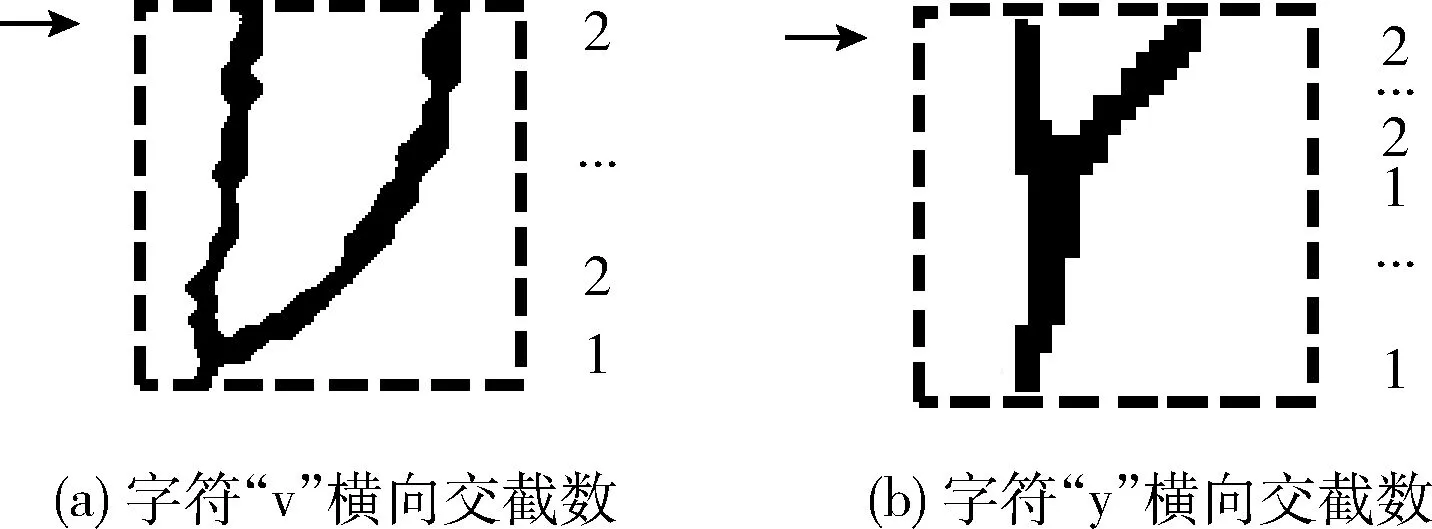
圖6 橫縱向交截特征
定義3 點特征
對于字符圖像來說,是否存在交叉點是字符結構中最基本、最易見的特征。由于英文字符是由筆畫連接或交叉而構成的,因此可以根據字符的連通性確定其點特征。通常點特征的計算需要依賴細化算法得到。
用式(4)逐個計算細化圖中各目標像素對應的t值
(4)
其中,Xi為當前像素P周圍8鄰域中的像素值,且P=X8,t為二值圖中相鄰兩元素值差的絕對值之和。當t的值分別為2、6、8時,則表明像素點P分別對應于細化二值圖的端點、三叉點、四叉點。結合字符本身來說,端點就是指筆畫(或筆段)的起點,三叉點是指從該點發出3條筆畫的點,四叉點是指從該點發出4條筆畫的點。手寫字符“a”只有端點和三叉點存在,而字符“Q”中則存在四叉點。
定義4 幾何特征
本文選取字符圖像的寬高比,連通域個數作為易混字符的幾何特征。寬高比即從字符最小外包矩形圖像中計算得到的字符的寬度和高度的比值。連通域個數為圖像中具有連通性的區域個數。圖像中如果兩個像素點鄰接,則這兩點彼此連通。所有彼此連通的點形成的一個區域,該區域為具有連通性的區域。
2.4 推薦候選項
在實際生活中,英文字符的出現形式是以單詞為基本構成形式而應用,某些易混字符單從個體形態來看具有的差異性較小,但根據其在構成的單詞之間則會有不同的組成。因此為了進一步提高識別結果的可信度,提出了一種結合字符合并形成候選項單詞的識別算法。具體流程如圖7所示。
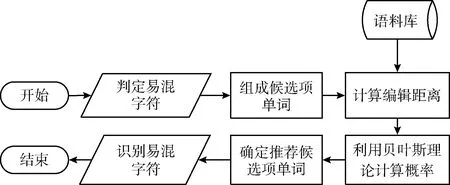
圖7 推薦候選項算法流程
為了研究單詞的使用情況及提取單詞中字符間的連接規律,本文主要針對高中階段學生的學習類型建立了英文語料庫。語料庫中包含1000余篇高中英語范文、中國英語學習者語料庫(CLEC)和英國國家語料庫,其中去除了語料庫中所有的標點符號。
確定易混字符后,它的前三位識別概率對應的字符表示為 {ri,1,ri,2,ri,3}, 將與該易混字符相連形成單詞的其它字符的識別結果表示為 {R1…Ri…Rn}, 結合單詞間字符的組成順序建立候選項單詞 {Word1…Wordi…Wordn},Wordi={R1,R2…r…Rn}, 其中r∈{ri,1,ri,2,ri,3}。
因為易混字符誤識的原因,往往會造成單詞的拼寫錯誤。為了找到離錯誤單詞相似程度最高的正確單詞,即字符正確識別結果。可以利用單詞的編輯距離來衡量候選項單詞與語料庫中單詞的相似程度,根據式(5)計算單詞間的編輯距離
dist(word,Tword)=sub(word,Tword)
(5)
其中,語料庫表示為V,語料庫中單詞為Tword,Tword∈V,word∈{Word1…Wordi…Wordn},dist(word,Tword) 代表候選項單詞與單詞語料庫中單詞的編輯距離,sub(word,Tword) 代表候選項單詞與單詞語料庫中單詞比較,進行替換操作所需代價。
計算編輯距離的偽代碼如下:
輸入:word[0…m],Tword[0…n]; 0…m和0…n代表組成單詞的字符
輸出:編輯距離dist
Begin
//dist[i,j] 表示word[0…i] 和Tword[0…j] 這兩個字串的編輯距離
Intdist[0…m,0…n]
Fori←0 TomDo:
dist[i,0]=i
Forj←0 TonDo
dist[0,j]=j
Fori←1 TomDo
Forj←1 TonDo
Intcost=(word[i]= =Tword[j]?0∶1)
dist[i,j]=min(dist[i-1,j-1]+cost)
Returndist[m,n]
通過已有研究發現,假設各個單詞的使用頻率相等,當兩個或兩個以上的字符被替換時單詞的成詞率很低。因此基于貝葉斯理論從概率的角度確定單詞的正確輸出,將需要計算概率的單詞集合限制在與候選單詞編輯距離為1的范圍內。
假設與候選項單詞word編輯距離為1范圍內單詞Tword構成的集合為S={S1…Si…Sn}, 求Si∈S使得P(Si|word) 最大,根據貝葉斯公式可得到式(6)
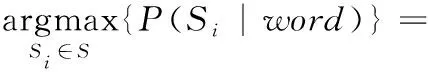
(6)
對于所有的Si∈S, 出現候選項單詞的概率都是一樣的,即P(word)都相等,因此近一步推導得式(7)
(7)
其中,P(Si) 表示語料庫中單詞Si出現概率,P(word|Si) 表示因為易混字符誤識成word的概率。將二者乘積最大的語料庫中單詞Si挑選出來作為推薦候選項單詞,將其中易混字符對應的字符作為識別結果。
2.5 結合多維特征和推薦候選項
對于待識別單詞中出現的易混字符,利用上文定義的多維特征去除圖像中的冗余屬性,得到了不同類別的易混字符的識別規則,分類器根據其類別信息,查找對應的算法,通過計算從而得到識別結果。再結合推薦候選項,進一步加強了易混字符的識別可信度。整體識別算法如下:
步驟1 輸入:易混字符圖像image
步驟2 利用CNN識別算法,得到字符識別概率 {pi,1,pi,2,pi,3} 以及前三位識別字符 {ri,1,ri,2,ri,3};
步驟3 根據識別概率和前三位識別字符通過2.2節的算法確定是否為易混字符和其所屬的易混字符類別;
步驟4 確定不同類別易混字符的區分區域 {xi,yi→xj,yj}, 進行記錄;
步驟5 根據造成易混字符的影響因素的不同,分別選擇字符的多維特征組;定義SFc表示特征組,FNc=(xi,yi→xj,yj) 表示為字符某段筆畫的鏈碼序列,LNc為橫向交截數,VNc為縱向交截數,Bc=(BCc,BPc) 代表交叉點的數目和位置,寬高比WH,連通域個數CON;
步驟6 計算image的多維特征,對標記的區域結合字符形態特征,進行識別;若屬于字符筆畫結構相似造成的易混字符,SFc=(LNc,VNc,FNc,WH); 若屬于筆畫位置不同,SFc=(Bc,FNc,CON); 若屬于筆畫長度不同,SFc=(WH,LNc,VNc); 若屬于筆畫交叉位置不同,SFc=(Bc); 根據SFc獲得識別結果Result1;否則拒識;
步驟7 對于字符結構相似字符,則還需要結合候選項單詞進行識別。根據2.4節算法動態計算出與單詞語料庫中單詞的編輯距離dist;若dist=0,則該候選項單詞為推薦候選項單詞,該推薦候選項單詞中對應的易混字符結果為識別結果Result2;若dist>0,根據貝葉斯理論計算概率乘積最大的推薦候選項單詞中的字符作為識別結果Result2;
步驟8 獲得易混字符最終識別結果Result;若通過多維特征和推薦候選項算法計算得到的結果Result1=Result2, 則Result=Result1=Result2; 若 (Result1!=Result2&&dist=0),Result=Result2; 若 (Result1!=Result2&&dist=1), 并且屬于由筆畫相似造成的不同,Result=Result2; 否則Result=Result1;
步驟9 輸出易混字符識別結果Result;
3 實驗與分析
通過對易混字符識別處理前后的性能進行實驗統計,并將字符的識別準確率作為性能評價指標,定義如下
(8)
其中,P為字符的識別準確率,CN為字符識別正確的總數,FN字符識別錯誤的總數。
在1.3節收集的實驗數據的基礎上,對單字符識別加上了本文算法再識別后,由圖8和圖9可以觀察到,手寫英文字符的平均識別準確率從96.52%提升到了98.67%,其中易混字符的識別準確率均有了明顯提升。
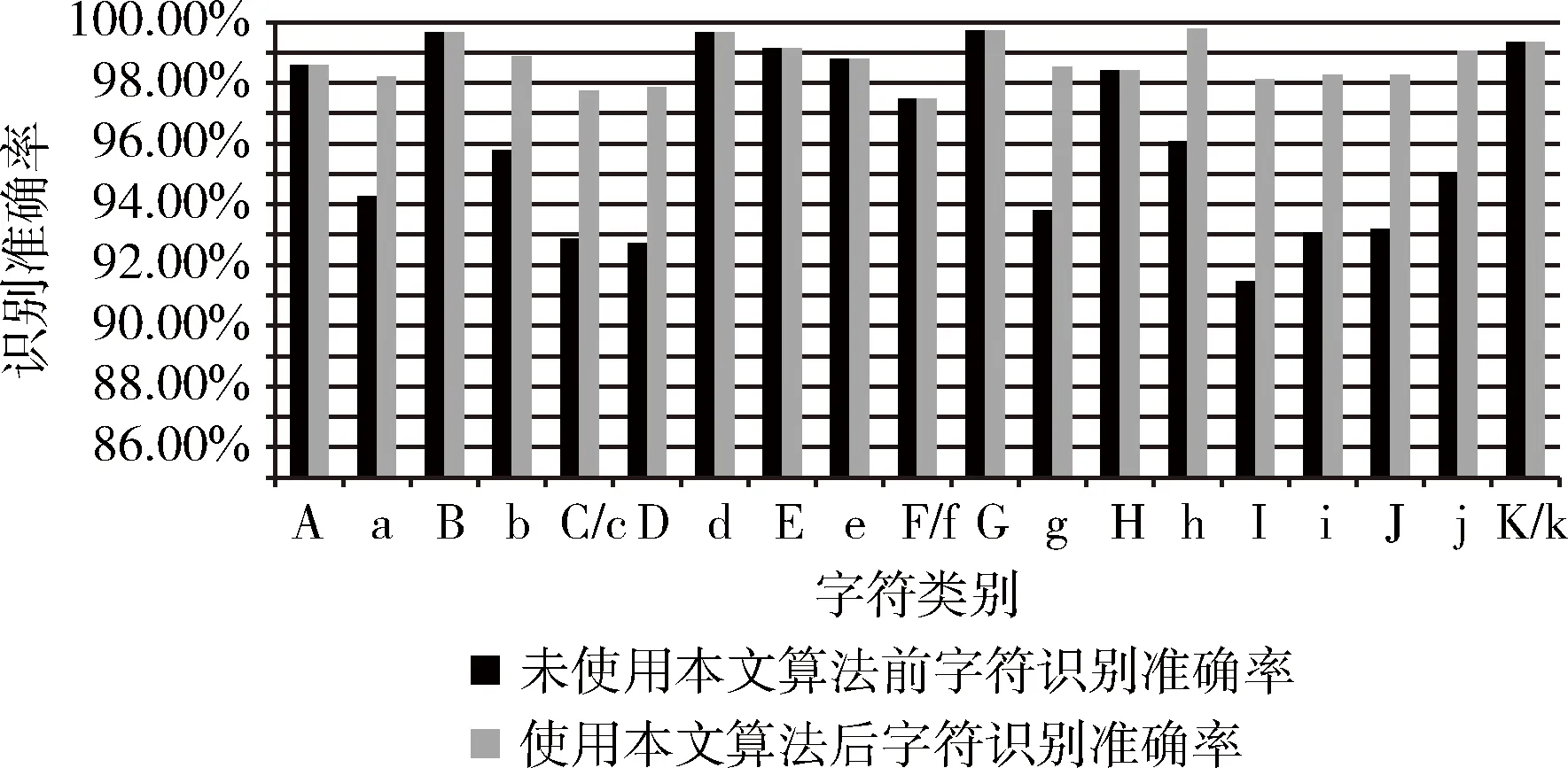
圖8 利用本文算法后字符“A-K/k”的識別準確率

圖9 利用本文算法后字符“L/l-Z/z”的識別準確率
為了驗證易混字符結合多維特征和候選項的識別準確率,收集了來自多名作者書寫的手寫英文單詞,這些單詞選擇了在不考慮圖像質量,單詞中每個字符均能裁切為完整且獨立字符的影響下,其中每個單詞包含至少一個因為易混字符而造成的誤識,合計600個單詞。在已確定易混字符所屬類別和其所屬單詞的情況下,進行實驗結果如圖10 所示:其中利用多維特征進行易混字符識別的平均準確率為70.85%,加上推薦候選項后平均準確率為78.03%。
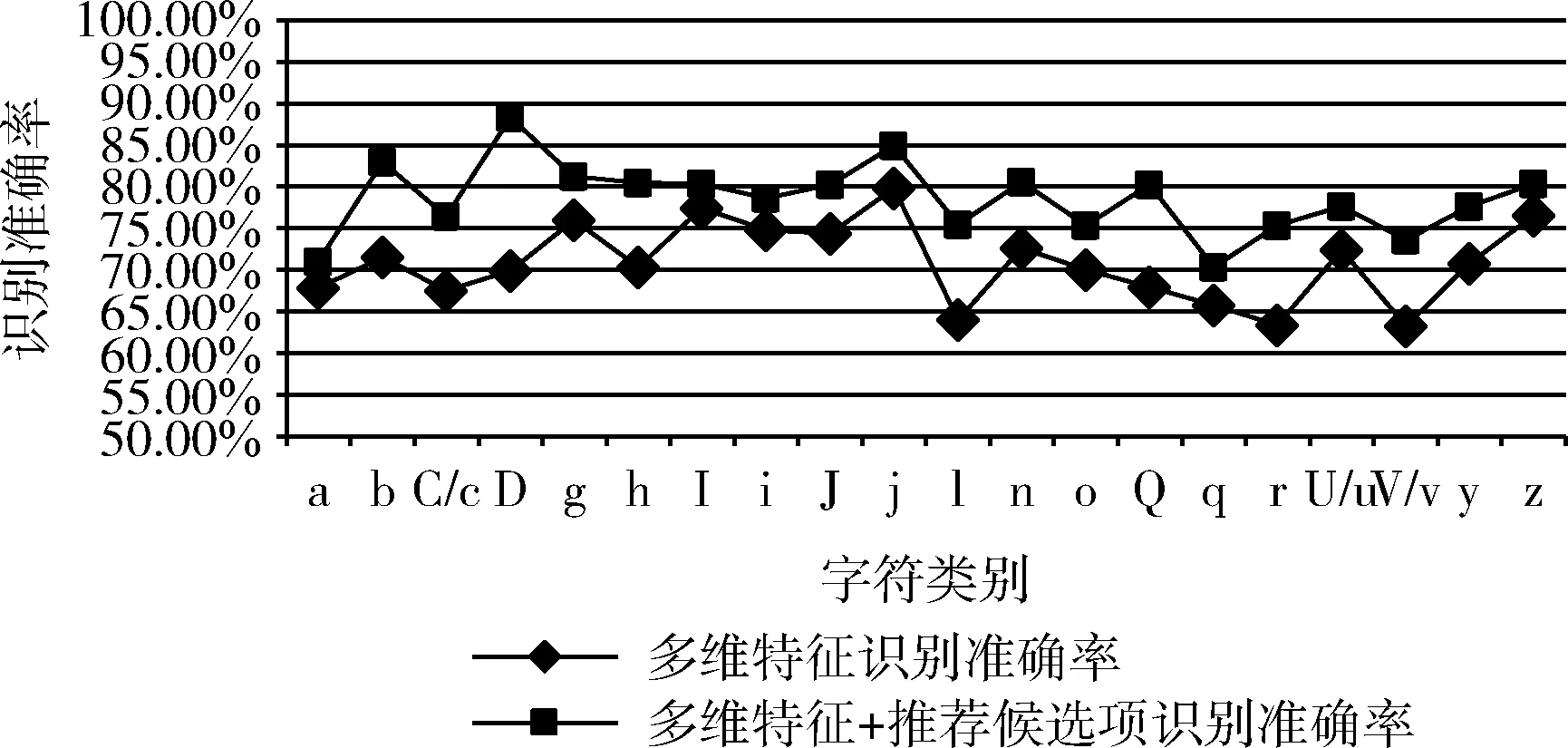
圖10 利用本文算法的易混字符識別準確率
4 結束語
針對手寫英文字符識別中易混字符造成的識別錯誤,在神經網絡初步識別的基礎上,提出了一種結合多維特征和候選項的識別算法。通過對大量易混字符進行識別實驗表明,該方法能夠較好地識別易混字符,并提高了手寫英文字符的整體識別準確率,從而驗證了該方法的可行性及正確性。根據易混字符在整體相似,局部差異的特點,對它們之間的細微差異信息進行精準識別,解決了采用特征輸入神經網絡時,由于選擇特征的局限性造成的誤識。同時為應用到其它語言的易混手寫字符識別提供了思路。
猜你喜歡
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
鄱陽湖學刊(2016年6期)2017-01-16 13:05:41
中國遠程教育(2016年6期)2016-12-07 10:07:02
財經(2016年19期)2016-08-11 08:17:03
中國遠程教育(2016年5期)2016-06-29 10:13:42
河南科技(2014年23期)2014-02-27 14:19:15
