基于新型特征融合的安全帽佩戴檢測方法
2021-11-20 01:57:08周敏新張方舟龔聲蓉
計算機工程與設計 2021年11期
周敏新,張方舟,龔聲蓉
(1.東北石油大學 計算機與信息技術學院,黑龍江 大慶 163000;2.常熟理工學院 計算機科學與工程學院,江蘇 蘇州 215500)
0 引 言
目前已經有學者對安全帽佩戴檢測做出了研究,現有的大多方法依賴人的臉部特征,一旦人背離攝像頭就無法檢測[1]。也有方法雖然可以在工作場所進行檢測,但是只對近處的工人有很好的檢測效果,遠處的工人檢測效果不佳[2-6]。這是因為工地監控攝像頭拍攝到的遠處工人僅占據圖像的小部分,特征難以識別,很難與復雜的背景區分開,并且工地的監控攝像頭大多安裝在高處,采集到的圖像中工人大部分都是小尺度的。基于這些原因,迫切需要一個能夠解決小尺度工人問題的自動安全帽佩戴檢測器。
本文提出在CenterNet[7]基礎上引入新型特征融合結構用于安全帽佩戴檢測,為了提高對小尺度工人檢測的有效性,首先引入一個U型結構的特征金字塔模塊(feature pyramid module,FPM),采用自頂向下的方式融合深層和淺層特征[8]。受PoolNet[9]啟發,深層語義信息在融合過程中容易被稀釋,因此引入全局引導模塊(global guidance module,GGM),即在特征金字塔結構的每一個橫向連接處添加深層語義信息。其次高倍數的上采樣會造成失真,采用特征整合模塊(feature aggregation module,FAM)使粗層次的語義信息在自頂向下過程中與精細特征更好融合[9]。
1 相關工作
目前關于安全帽佩戴檢測的研究主要分為基于傳感器的方法和基于視覺的方法[2]。基于傳感器的方法使用場景受限,一旦超過了信號范圍就無法檢測,并且設備需要定期充電,不利于長期使用。因此,使用普通相機進行實際應用比傳感器具有更重要的現實意義[2]。基于視覺的方法進一步分為基于手工設計特征的方法和目前主流的基于深度學習的方法。
1.1 基于手工設計特征的方法
Shrestha等[1]提取頭部區域的邊緣特征來判斷工人是否佩戴了安全帽。Park等[3]提出使用背景分離法從復雜的背景中檢測人體和安全帽,再分別提取人的身體部分和安全帽的HOG特征,最后根據它們的空間關系進行匹配。Li等[4]提出采用行人檢測算法檢測出行人,再利用頭部定位、顏色空間變化和顏色特征識別實現安全帽佩戴檢測。可以看出基于手工設計特征的方法大都需要進行多步驟檢測,首先從復雜的背景中提取行人,再提取目標的邊緣、顏色、形狀和其它具有判別性的特征,這些特征通常被編碼成低層次的視覺描述器,檢測速度慢[10]。還有方法依賴人的正臉特征,使用場景受限。此外,該類方法的特征描述符是基于低層次的視覺線索手工設計的,難以在復雜的上下文環境中捕獲具有代表性的語義信息[11]。
1.2 基于深度學習目標檢測的方法
隨著計算資源比如GPU的發展以及更多公開的數據集,和基于手工設計特征的方法相反,深度卷積神經網絡可以從大量訓練數據集中自動學習并將圖片的原始像素信息表示成高層次的語義信息,因此基于深度卷積神經網絡的目標檢測算法具有更強的特征表示能力[11]。基于這些特性,深度學習目標檢測算法逐漸成為主流。
目前已經有學者使用深度學習目標檢測算法進行安全帽佩戴檢測,但是仍處于起步階段[2]。直接將Faster R-CNN[14]用于安全帽佩戴檢測,結構復雜,不能達到實時的效果,并且僅在最后一層特征圖上進行預測,對小尺度目標檢測效果不佳。Wu F等[5]將YOLOv3[12]的骨干網絡DarkNet53替換成了DenseNet用于安全帽佩戴檢測,訓練簡單,并且該方法在多尺度特征映射圖上進行預測提高了對小尺度目標的檢測效果。Luo等[6]采用SSD[13]算法進行安全帽佩戴檢測,但是SSD[13]算法利用淺層特征預測小尺度目標,深層特征預測大尺度目標,沒有結合深層和淺層特征各自的優勢,因此對于小尺度的目標檢測效果依然不佳。
上述方法均采用了錨框機制,在設置錨框寬高比時麻煩,此外,還存在大量的冗余框導致正負樣本嚴重失衡。2018年~2019年期間出現了大量基于關鍵點的目標檢測方法,不需要預設錨框,直接根據關鍵點定位目標。CenterNet[7]僅使用中心點表示目標,邊界框的其它屬性通過中心點區域的特征映射圖進行回歸,每個目標只有一個中心點,因此不需要做極大值抑制后處理。在與YOLOv3[12]相同的檢測速度下,CenterNet的檢測精度要比YOLOv3[12]高3倍[7]。
為了全面考慮檢測的速度和精度,本文提出以CenterNet[7]為基礎的改進方法用于安全帽佩戴檢測。
2 CenterNet
CenterNet屬于無錨框目標檢測,圖1為CenterNet的無錨框機制與傳統的錨框機制對比,如圖1(a)所描述的,目標直接通過它的中心點來表示,圖1(b)表示的是傳統的基于錨框的目標檢測算法,每個位置都預設了固定尺度的錨框,每個錨框負責預測與真值框交并比大于某個閾值的目標[14]。
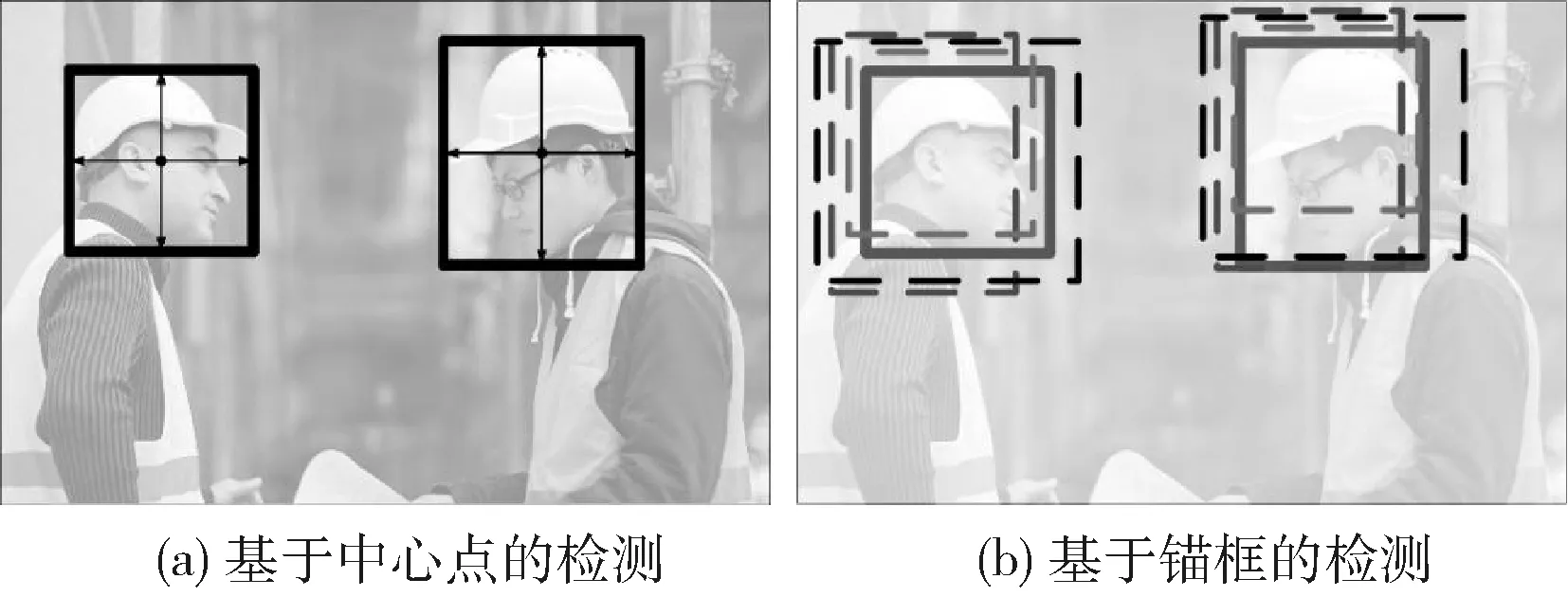
圖1 CenterNet與傳統的錨框機制對比
CenterNet網絡結構如圖2所示,僅在最后一層特征映射圖上進行預測,忽略了淺層特征的細節信息,導致對小尺度目標不敏感,在應用于安全帽佩戴檢測時仍然會存在漏檢、誤檢情況。本文采用新型特征融合方式充分融合深層和淺層特征,提高對小目標的檢測精度和召回率。

圖2 CenterNet網絡結構
3 改進的方法CenterNetFF
深層語義信息有助于分類,而淺層特征具有豐富的細節信息有利于定位[8],CenterNet僅通過最后一層特征進行預測,忽略了淺層特征的細節信息,導致在檢測小尺度目標時效果不佳。本文提出在CenterNet中引入一種新型特征融合方法,稱之為CenterNet-Feature-Fusion(CenterNetFF),利用3個模塊更好的融合深層和淺層特征,擴大了整體網絡的感受野,以便更精確捕捉目標的位置信息,提升對小尺度目標的檢測效果。
3.1 CenterNetFF總體網絡結構
如圖3所示,CenterNet作為基礎網絡,輸入512×512大小的圖片,經過骨干網絡得到最終的特征映射圖Conv_5。本文提出3個模塊更好融合深層和淺層特征,提高對小尺度目標的檢測效果。首先引入特征金字塔模塊采用自頂向下的方式融合深層特征與淺層特征,由于深層語義信息會在自頂向下融合過程中被稀釋[9],本文在特征金字塔模塊中插入全局引導模塊,由圖3中的金字塔池化模塊(pyramid pooling module,PPM)和全局引導流(global guidance flows,GGFs)組成。金字塔池化通過不同尺度的縮放Conv_5獲得全局引導信息,全局引導流負責在特征金字塔的每一個橫向連接處添加金字塔池化獲得的全局引導信息,彌補在自頂向下過程中逐漸被稀釋的深層語義信息。高倍數的上采樣容易引入雜質,造成混疊效應,引入特征整合模塊,也就是圖3中的A,對每一層融合特征映射圖進行處理,不僅減少了混疊效應,同時通過在不同尺度空間上查看上下文信息,進一步擴大了整個網絡的感受野。最后使用融合后的特征進行預測,分為3個分支用于生成關鍵點熱力圖、邊界框的尺度預測(Wi,Hi)以及關鍵點的偏差預測(ΔXi,ΔYi),均采用3×3和1×1的卷積。根據預測得到的中心點坐標(Xi,Yi),即關鍵點熱力圖中的峰值點、邊界框的尺度以及偏差值可以定位目標的位置 (Xi+ΔXi-Wi/2,Yi+ΔYi-Hi/2,Xi+ΔXi+Wi/2,Yi+ΔYi+Hi/2)。
3.2 特征金字塔模塊(FPM)
由于小尺度目標占據圖像的像素較小,在自底向上過程中隨著特征圖的分辨率越來越低,小尺度目標的像素信息逐漸丟失,僅通過最后一層特征層進行預測導致在檢測小尺度目標時存在不足。本文在CenterNet基礎上引入U型結構的特征金字塔模塊。第一步是自底向上的過程,也就是網絡的前向傳播過程,如圖3所示,Conv_2~Conv_5特征映射圖的大小隨著網絡層數的加深逐漸減小,分辨率也越來越低。Conv_1~Conv_3淺層特征包含豐富的目標邊緣等細節信息,但是缺乏語義信息,而深層特征Conv_4~Conv_5語義信息豐富,有利于目標的分類,但是缺乏淺層特征的細節信息,不利于定位。第二步,采用自頂向下的方式融合深層特征和淺層特征,如圖3中的F模塊,將上一層的特征映射圖進行2倍上采樣,下一層的特征映射圖采用1×1的卷積核減少通道數,與上采樣后的上一層特征

圖3 改進后的網絡CenterNetFF結構
進行融合。本文將骨干網絡的Conv_5,Conv_4,Conv_3這3層特征圖依次進行上采樣融合,融合后的特征圖既包含了淺層特征的細節信息,又包含了深層特征的語義信息,提高了對小尺度目標的敏感性,并且融合后的特征圖分辨率高,感受野與小尺度目標剛好匹配。
3.3 全局引導模塊(GGM)
特征金字塔是融合不同特征層的經典結構,但是在自頂向下過程中深層語義信息會逐漸被稀釋[15]。指出卷積神經網絡的實際感受野會比理論感受野要小,尤其是在深層特征映射圖上。因此整個網絡的感受野不足以捕獲輸入圖像的全局信息,導致目標容易被背景吞噬[9],本文引入全局引導模塊將深層語義信息更好融入到淺層特征層中。如圖3所示,全局引導模塊由兩個部分組成:金字塔池化模塊和全局引導流。金字塔池化模塊通過融合不同區域的上下文信息來捕獲全局信息,圖4是金字塔池化模塊結構。首先對Conv_5采用平均池化得到1×1、2×2、3×3和6×6不同大小的池化特征映射圖,再通過1×1的卷積核將池化特征映射圖的通道數變為原來的1/4,最后通過雙線性插值法將這些特征圖上采樣回原來大小,并與初始的Conv_5 進行拼接。為了將金字塔池化獲得的全局引導信息融入到特征金字塔的不同特征層上,引入全局引導流,如圖3所示,在特征金字塔模塊的每一次橫向連接處分別加入2倍、4倍、8倍上采樣后的全局引導信息,彌補了在自頂向下過程中被稀釋的深層語義信息,本文通過對引入全局引導流前后的特征進行可視化結果對比來驗證其有效性,具體分析結果將在實驗部分進行展示。

圖4 金字塔池化模塊
3.4 特征整合模塊(FAM)
上一節的全局引導模塊在自頂向下過程的每一個融合特征層中加入全局引導信息,增加了各層融合特征層的深層語義信息,但同時也帶來了一個問題。圖5為引入各模塊后的特征可視化結果,其中圖5(c)是在融合特征層中添加全局引導信息后的特征可視化圖,可以看出由于高倍數的上采樣引入了雜質,造成混疊效應。傳統的特征金字塔模塊對2倍上采樣融合后的特征采用3×3的卷積核進行卷積,消除了上采樣引起的混疊效應,但是全局引導流需要更大倍數的上采樣,比如4倍和8倍,因此需要有效消除全局引導流和不同尺度特征映射圖之間的差距[9]。特征整合模塊如圖6所示,包括4個分支,首先將融合特征通過平均池化進行2、4、8倍的下采樣,然后經過3×3的卷積操作再進行對應倍數的上采樣與初始的融合特征合并到一起,最后再做一個3×3的卷積。如圖3所示,本文首先對Conv_5進行特征整合模塊處理,之后對每一層融合的特征都進行了特征整合模塊處理,不僅中和了高倍數上采樣帶來的混疊效應,而且特征整合模塊通過在不同空間位置和不同尺度上觀察局部信息,整個網絡的感受野得到了擴展。

圖5 引入各模塊后的特征可視化結果

圖6 特征整合模塊
4 實驗結果與分析
4.1 實驗環境和訓練參數
實驗環境見表1,服務器包含4個GPU,每個容量為16 G,型號為Tesla P100。本文將CenterNetFF和原始的CenterNet以及其它先進的深度學習目標檢測器在SHWD數據集上使用表2相同的訓練參數進行訓練。學習率初始化為1.25e-4,批量大小為16。總共訓練200輪,由于在訓練初期學習率較大,所以損失值下降速度很快,但是在訓練后期模型逐漸收斂時,大的學習率會導致損失值下降的緩慢,在一個區域值內不停擺動,于是在第90輪和第120輪時對學習率進行一個衰減,這樣損失值又可以進一步下降一個坡度。
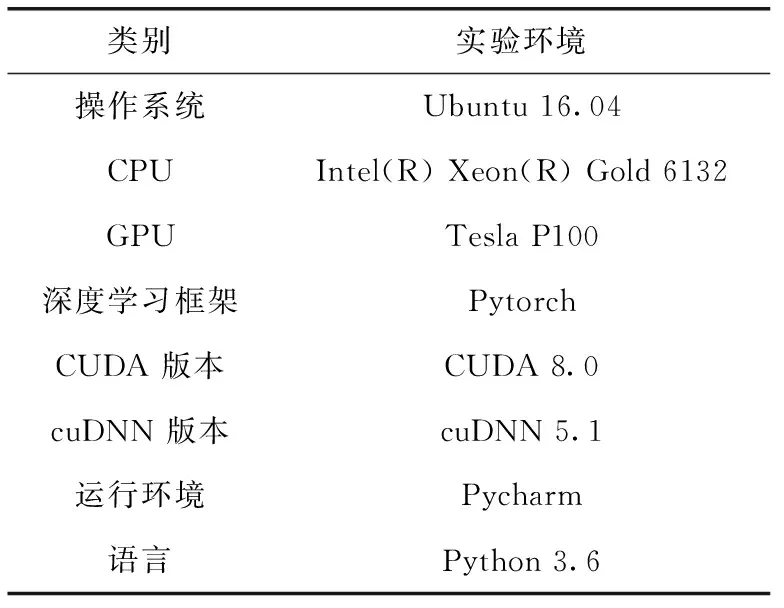
表1 實驗環境

表2 訓練參數
4.2 實驗數據和評價指標
本文采用的實驗數據是公開的安全帽數據集SHWD以及目標檢測數據集COCO。SHWD數據集被分為兩類:hat(佩戴安全帽的)和person(沒有佩戴安全帽的)。SHWD總共7581張圖片,包括9044個佩戴安全帽的正例和11 151個沒有佩戴安全帽的反例。本文將SHWD數據集按3∶1∶1的比例劃分為4548張訓練集、1516張驗證集和1517張測試集,部分樣本如圖7所示。為了驗證本文方法不僅僅只對安全帽數據集有很好的檢測效果,本文同時使用COCO數據集對CenterNetFF進行了訓練檢測。COCO數據集分為10個類別,總共包含20萬張圖像。評價指標采用的是平均檢測精度AP、平均召回率AR以及檢測速度幀每秒fps。

圖7 數據集樣本
4.3 消融實驗
為了驗證本文提出的每個模塊的有效性,我們進行了廣泛的消融實驗。
4.3.1 特征金字塔的有效性
骨干網絡的淺層特征映射圖包含清晰的目標邊緣細節,隨著網絡層數的不斷加深,語義信息越來越豐富。但是目標的細節信息逐漸模糊,分辨率越來越低,導致識別小尺度目標困難。將深層特征融入到淺層特征中可以彌補淺層特征缺乏的語義信息,最終的融合特征映射圖比原來的特征映射圖具有更高的分辨率,感受野又剛好與小尺度目標相匹配。融合后的特征圖不僅包含深層特征的語義信息,還包含了淺層特征的細節信息。表3的第2、6、10行展示了在不同的骨干網絡下添加了特征金字塔之后的檢測結果,可以看出平均檢測精度AP分別提高了1.4%、1.8%、0.4%,
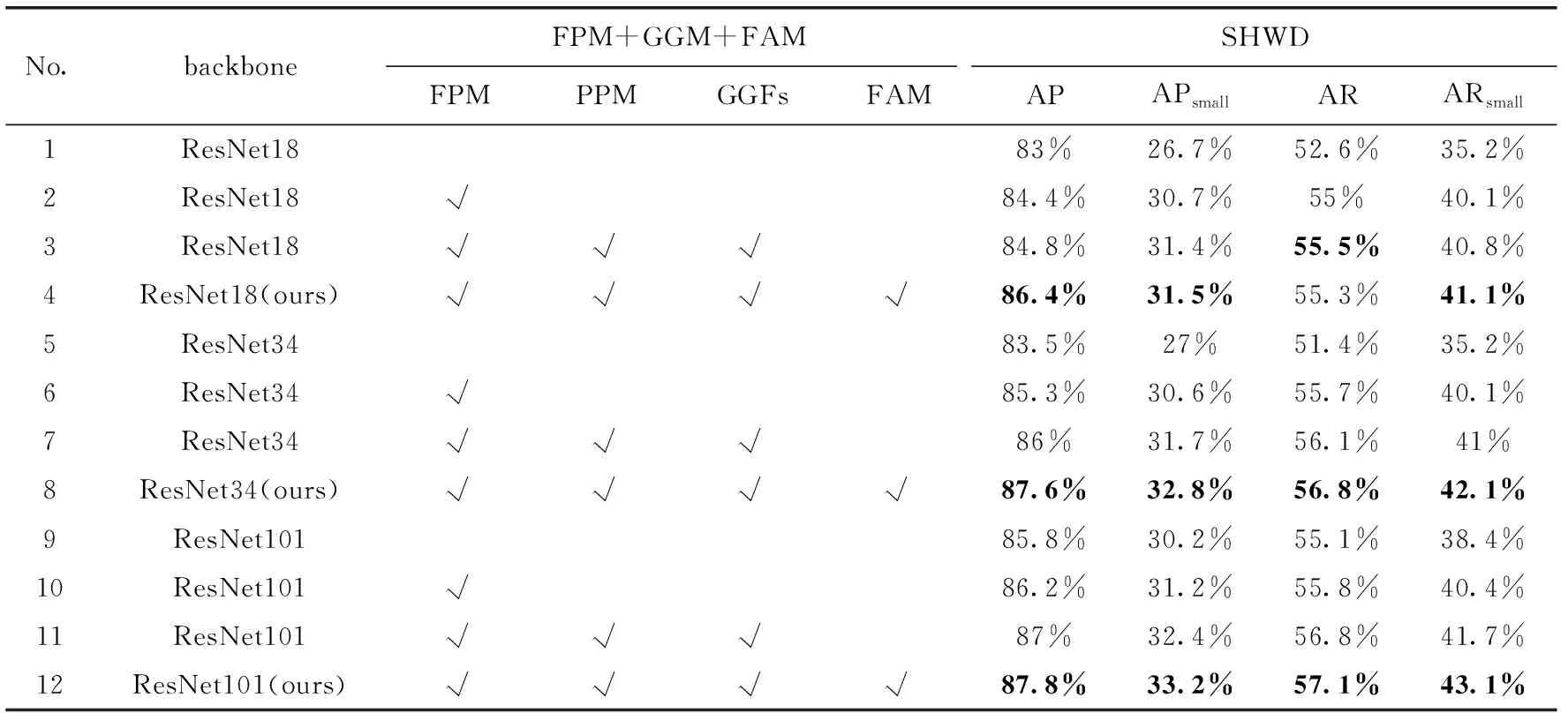
表3 在SHWD數據集上的測試結果對比
平均召回率AR分別提高了2.4%、4.3%、0.7%。同時,對于小尺度目標檢測效果也有了很大的提升,APsmall分別提高了4.0%、3.6%、1.0%,ARsmall分別提高了4.9%、4.9%、2.0%,特征金字塔的引入明顯提高了對小目標的敏感性。
4.3.2 全局引導模塊的有效性
圖5為引入各模塊后的特征可視化結果,其中圖5(b)是經過特征金字塔融合后的特征圖可視化結果,圖5(c)是引入全局引導模塊后的特征圖可視化結果。全局引導模塊在每一層融合特征層中添加了全局引導信息,可以看出圖5(c)的語義信息要更豐富一些,整個網絡更加關注目標的完整性。表3的第3、7、11行是引入全局引導模塊后的結果,平均檢測精度AP和平均召回率AR較上一步又有了進一步提升,其中AP分別提高了0.4%、0.7%、0.8%,AR分別提高了0.5%、0.4%、1.0%。
4.3.3 特征整合模塊的有效性
特征整合模塊將融合后的特征先通過平均池化進行下采樣,再用相同的倍數進行上采樣整合到一起,平均了高倍數上采樣而引入的雜質。在圖5的特征圖可視化結果圖中,圖5(d)是引入特征整合模塊后的特征圖可視化結果,可以看出減少了高倍上采樣帶來的混疊效應,更能準確捕捉目標的位置和細節信息。從表3的第4、8、12行可以看出經過特征整合模塊處理后網絡的檢測平均精度AP又分別提高了1.6%、1.6%、0.8%,小尺度目標的檢測平均精度APsmall分別提高了0.1%、1.1%、0.8%。最終本文的CenterNetFF算法AP達到了87.8%,AR達到了43.1%,并且對于小尺度目標的檢測APsmall達到33.2%,ARsmall達到43.1%,相較于原來的CenterNet的APsmall和ARsmall分別提高了3.0%以及4.7%,檢測速度可以達到21 fps,滿足工地上的實時檢測要求。
4.4 在COCO數據集上的實驗
為了充分驗證CenterNetFF的有效性,本文將CenterNetFF與原來的CenterNet在COCO數據集上進行了實驗。表4是實驗結果數據,在ResNet18上檢測AP達到29.2%,相較于原來的CenterNet提高了1.1%,小尺度目標的檢測AP提高了1.1%。在ResNet101上檢測AP達到35.9%,比原來的CenterNet檢測平均精度提高了1.3%。小尺度目標檢測AP達到24.6%。可以看出改進后的算法不僅提高了網絡整體的檢測平均精度,而且極大提高了對小尺度目標的檢測精度。

表4 COCO數據集上實驗數據對比/%
4.5 與其它先進的深度學習目標檢測算法對比
本文將CenterNetFF與Faster R-CNN[14]、YOLOv3[12]以及SSD[13]在SHWD數據集上進行了訓練對比。在相同的實驗環境下,結果如圖8所示,盡管Faster R-CNN[14]的檢測平均精度和CenterNetFF差不多,但是檢測速度只有4.92 fps,遠遠達不到實時的效果。由于復雜的網絡結構,

圖8 與目前先進的目標檢測算法對比
大量的計算成本,Faster R-CNN[14]在檢測速度方面不占優勢。另外,YOLOv3[12]和SSD[13]檢測速度快,可以達到實時的效果,但是檢測精度比本文的方法低,不能滿足復雜工況下安全帽佩戴檢測所需要達到的精度要求。由于不需要提前預設候選框,操作麻煩并且會存在大量的冗余框。另外YOLOv3[12]使用傳統的特征金字塔結構融合深層特征和淺層特征, 深層語義信息會在自頂向下過程中被稀釋,不能很好與淺層特征進行融合。SSD[13]在多尺度特征圖上進行預測,沒有結合深層和淺層特征各自的優勢,因此對于小尺度目標檢測效果仍然不好。相反,本文提出的CenterNetFF既結合了深層和淺層特征各自的優勢,又保證了深層語義信息不在融合過程中被稀釋。最終CenterNetFF的平均檢測精度達到87.8%,檢測速度21 fps,滿足實時性檢測要求。
4.6 對小尺度目標的檢測效果
本文選用多張小尺度工人的圖像測試CenterNetFF以及原來的CenterNet[7]。圖9為在CenterNet和本文改進的方法CenterNetFF上的檢測結果,圖9(a)和圖9(c)是原來的CenterNet檢測結果,圖9(b)和圖9(d)是CenterNetFF檢測結果。圖9(a)中遠離攝像頭的工人沒有被檢測出來,但是CenterNetFF檢測出這個工人佩戴了安全帽,并且檢測的置信度要更高。圖9(c)中有別的目標被誤檢成安全帽,可能是因為它的顏色和安全帽類似。CenterNetFF通過全局引導模塊的全局信息使得網絡更關心目標的完整性,減少了假陽性。另外我們看到圖9(c)中一個被起重機遮擋的工人在改進后的算法中仍然沒有被檢測出來,這是本文的方法還存在的問題。

圖9 CenterNet與CenterNetFF對小尺度目標的檢測效果
基于以上結果,本文改進后的算法CenterNetFF不僅減少了原來的CenterNet的誤檢和漏檢情況,還有效解決了小尺度工人的安全帽佩戴情況檢測問題。
基于上述實驗結果,可以發現和原來的CenterNet以及其它先進的深度學習目標檢測算法相比,本文改進后的算法CenterNetFF在真實工作場景下有更好的檢測性能,誤檢和漏檢情況都有所改善,在速度方面也能達到實時效果。
5 結束語
本文首先介紹了CenterNet基本原理,簡單、快速、精確、不需要做極大值抑制后處理。但是在復雜的工作場景下,檢測小尺度工人佩戴安全帽情況仍存在不足。本文提出一種特征融合方法,在CenterNet基礎上引入特征金字塔模塊、全局引導模塊以及特征整合模塊。從實驗結果可以看出,整體的平均檢測精度和平均召回率都有了不同程度的提升,尤其對于小尺度工人的誤檢情況得到了改善,而且檢測速度也基本滿足實時性。但是我們可以看到被建筑物遮擋的工人檢測效果不好。如何減輕遮擋的問題將是我們下一步的工作重點。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
