基于生成對抗網(wǎng)絡(luò)增強惡意代碼的方法
2021-11-20 01:56:52朱曉慧錢麗萍
計算機工程與設(shè)計 2021年11期
朱曉慧,錢麗萍,傅 偉
(1.北京建筑大學(xué) 電氣與信息工程學(xué)院,北京 100044;2.北京建筑大學(xué) 建筑大數(shù)據(jù)智能處理方法研究北京市重點實驗室,北京 100044)
0 引 言
互聯(lián)網(wǎng)給信息交換與共享帶來極大便利的同時,也為惡意代碼的廣泛傳播提供了有利環(huán)境[1]。因此探究有效防護的分類檢測方法成為近年來許多專家學(xué)者的關(guān)注熱點,且迄今為止,已從多方面提出很多不同類型的分類檢測方法。其中較為新穎和重要的一類是以惡意代碼可視化圖像為研究對象提取特征,并結(jié)合機器學(xué)習或深度學(xué)習算法的分類檢測方法,文獻[2-6]均在該方向上有所研究。這些研究既很好解決了傳統(tǒng)分類檢測方法難以應(yīng)對反追蹤和代碼混淆策略的不足,又表明采用圖像處理方法具備有效性和可行性,為惡意代碼處理提供新視角。但隨著研究的深入,學(xué)術(shù)界公開可用的惡意代碼數(shù)據(jù)量不足且類別不均衡的問題越來越明顯,成為限制性能提升的關(guān)鍵問題之一,故亟需加強對惡意代碼數(shù)據(jù)增強技術(shù)的探究。
已有傳統(tǒng)惡意代碼增強技術(shù),如代碼復(fù)用或自動化技術(shù)均能夠?qū)崿F(xiàn)惡意代碼數(shù)據(jù)生成,一定程度上實現(xiàn)數(shù)據(jù)集擴增,但因其存在耗時費力、缺乏多樣性以及實現(xiàn)難度較大等不足,已不能很好滿足如今對增強方法可操作性以及高性能的要求,所以結(jié)合新興技術(shù)探究高效可行的惡意代碼數(shù)據(jù)增強方法顯得更加重要。
因此,本文借鑒分類檢測中結(jié)合圖像的處理方式,提出一種基于惡意代碼圖像并結(jié)合生成對抗網(wǎng)絡(luò)的惡意代碼數(shù)據(jù)增強方法,緩解現(xiàn)存數(shù)據(jù)集規(guī)模小、類別不均衡問題,輔助提高分類器性能。主要貢獻如下:①將圖像處理技術(shù)應(yīng)用于惡意代碼數(shù)據(jù)增強,一方面創(chuàng)新性地采用有別于直接增強惡意代碼可執(zhí)行文件的方法,既克服了文本增強難操作、特征復(fù)雜難以學(xué)習以及生成樣本缺乏多樣性等問題,使特征保留更加完整直觀,又為惡意代碼增強方法提供新思路;另一方面能夠迎合目前以惡意代碼圖像為對象的分類檢測方法,使其有更好的應(yīng)用。②將轉(zhuǎn)換后圖像經(jīng)由縮放操作表示,解決惡意代碼文件長度不一情況下全部隱含特征的高概率保持問題,使其后續(xù)作為輸入數(shù)據(jù)可操作,更有利于發(fā)揮生成對抗網(wǎng)絡(luò)性能。③引入生成對抗網(wǎng)絡(luò)模型架構(gòu),使用Wasserstein距離代替JS散度描述模型生成樣本與真實樣本之間的分布距離,并使用梯度懲罰項解決惡意代碼圖像訓(xùn)練過程中參數(shù)極端和梯度消失問題,構(gòu)建較穩(wěn)定的WGAN-GP模型。④結(jié)合圖像質(zhì)量評價指標SSIM和多種基礎(chǔ)分類器準確率對惡意代碼生成數(shù)據(jù)相似性及有效性進行綜合評估。
1 相關(guān)工作
基于機器學(xué)習或深度學(xué)習的檢測算法大多為數(shù)據(jù)驅(qū)動,故在已有惡意代碼數(shù)據(jù)不滿足需求的情況下,需要采用一些數(shù)據(jù)增強技術(shù)擴增數(shù)據(jù)集,提高網(wǎng)絡(luò)模型性能,緩解過擬合問題。本節(jié)從傳統(tǒng)惡意代碼生成技術(shù)和基于生成對抗網(wǎng)絡(luò)生成技術(shù)兩方面介紹研究狀況。
傳統(tǒng)惡意代碼生成技術(shù)主要包括代碼復(fù)用和自動化生成,其中代碼復(fù)用技術(shù)通過人工拷貝或修改源代碼的方式重新編譯生成新的不同執(zhí)行體,這些執(zhí)行體中保留個體大部分公用代碼和復(fù)用歷史,具有相似的功能特征但外形相差甚大。文獻[7]中提到惡意代碼具有復(fù)用性,采用代碼復(fù)用技術(shù)可以在不修改或稍許改動已有惡意代碼的基礎(chǔ)上生成新的惡意代碼行為。
然而代碼復(fù)用技術(shù)主要依賴人工操作,費時費力且結(jié)構(gòu)單一,已經(jīng)逐漸為惡意代碼制造者摒棄。而自動化生成技術(shù)是通過自動化生產(chǎn)引擎生成組合惡意代碼,較于代碼復(fù)用技術(shù)更具隨機性和多樣性,目前加密、多態(tài)和變形都是較為成熟的自動化生產(chǎn)引擎技術(shù)。文獻[8,9]中均涉及對運用多態(tài)、變形等技術(shù)手段生成各種攻擊行為相近惡意代碼的描述。這些技術(shù)已相對成熟,但還是存在生成數(shù)據(jù)模塊較固定且實現(xiàn)難度較大等問題。故上述兩種傳統(tǒng)生成技術(shù)均難以應(yīng)對機器學(xué)習或深度學(xué)習檢測方法對數(shù)據(jù)質(zhì)量和數(shù)量提出的更高要求。
而隨著深度學(xué)習技術(shù)的發(fā)展,具有強大學(xué)習和生成能力的生成對抗網(wǎng)絡(luò)(GAN)[10]已成為惡意代碼數(shù)據(jù)集增強的新選擇。Hu Wei等提出一種基于生成對抗網(wǎng)絡(luò)的算法-MalGAN,用來生成對抗惡意軟件示例,由其生成的示例樣本能夠成功繞過基于黑盒機器學(xué)習的檢測模型[11]。Hu Wei等針對基于機器學(xué)習的惡意軟件檢測算法在對抗性示例攻擊下很脆弱問題提出一種新穎的生成算法,能夠生成順序?qū)剐允纠齕12]。Kim等為檢測帶有混淆的惡意軟件,提出一種潛在語義控制生成對抗網(wǎng)絡(luò)(LSC-GAN)方法[13]。Burks等采用生成對抗網(wǎng)絡(luò)擴增惡意軟件數(shù)據(jù),并討論其優(yōu)劣之處[14]。曹啟云等采用生成對抗網(wǎng)絡(luò)生成惡意JavaScript代碼樣本,增強數(shù)據(jù)集[15]。基于GAN的新方法均取得較好效果,值得進一步探究。
綜上所述,人們對惡意代碼數(shù)據(jù)集增強的工作一直沒有停歇,不斷結(jié)合新興技術(shù)提高數(shù)據(jù)質(zhì)量與操作可行性。生成對抗網(wǎng)絡(luò)的引入很好彌補了傳統(tǒng)惡意代碼增強方法在實現(xiàn)簡易度以及生成樣本質(zhì)量上的不足,更好實現(xiàn)了惡意代碼增強。然而已有相關(guān)研究大多從惡意代碼對抗樣本角度或代碼文本角度出發(fā)生成惡意代碼數(shù)據(jù),沒能充分發(fā)揮生成對抗網(wǎng)絡(luò)模型處理連續(xù)型數(shù)據(jù)的優(yōu)勢,且最終僅采用在分類檢測中的應(yīng)用作為驗證方法有效性的評估指標。而本文將加強對使用生成對抗網(wǎng)絡(luò)模型增強惡意代碼數(shù)據(jù)的研究,重視惡意代碼數(shù)據(jù)本身重要性,結(jié)合圖像處理方法突破生成對抗網(wǎng)絡(luò)處理惡意代碼離散數(shù)據(jù)的局限,自動化生成新數(shù)據(jù)擴充數(shù)據(jù)集,并采用圖像評估指標及分類檢測應(yīng)用進行綜合驗證。
2 基于生成對抗網(wǎng)絡(luò)的惡意代碼生成
2.1 數(shù)據(jù)表示
本節(jié)從惡意代碼文件可視化及惡意代碼圖像處理兩方面闡述對樣本數(shù)據(jù)進行的有效表示:
(1)惡意代碼文件可視化
對惡意代碼可視化方法的研究,國內(nèi)外都已取得一定成果,可將其分為直接轉(zhuǎn)化法和操作碼轉(zhuǎn)化法兩類。其中直接轉(zhuǎn)化法以HAN等提出的基于Nataraj方法將惡意軟件可執(zhí)行文件轉(zhuǎn)換成對應(yīng)的灰度紋理圖方法為代表[16],這類方法主要是由惡意代碼PE文件二進制碼直接轉(zhuǎn)化生成灰度或彩色圖像;而操作碼轉(zhuǎn)換法則以Andrew等提出的基于反匯編文件進行矢量化的方法為代表[17],該類方法側(cè)重于對惡意代碼文件操作碼的選取轉(zhuǎn)換。目前,這兩種轉(zhuǎn)換方法在對BIG2015數(shù)據(jù)集的研究中均有涉及,文獻[5,6]以及Kaggle競賽冠軍均采用操作碼轉(zhuǎn)化法選取不同操作碼進行圖像轉(zhuǎn)化,而文獻[3]中則采用直接轉(zhuǎn)換法進行可視化操作,都取得了理想的效果。本文鑒于對可視化操作可行性以及各類別轉(zhuǎn)換后特征表現(xiàn)度和差異度的綜合考慮,最終選擇.bytes文件作為研究對象,采用直接轉(zhuǎn)化法將其轉(zhuǎn)化為惡意代碼圖像,具體步驟為:首先將.bytes文件中存放的十六進制代碼(一次為兩個代碼的集合)轉(zhuǎn)換為一組十進制代碼,當遇到不規(guī)則符號如“??”時統(tǒng)一分配一個十進制數(shù)-1,然后將所得十進制數(shù)以固定寬度組成二維數(shù)組,最后對應(yīng)像素值轉(zhuǎn)換為灰度圖像。
(2)惡意代碼圖像處理
不同惡意代碼樣本文件結(jié)構(gòu)、功能的差異性導(dǎo)致其大小不一,故在將其完整轉(zhuǎn)化為惡意代碼圖像后的尺寸也有所不同。本文為了兼顧惡意代碼內(nèi)容相對完整性,使其后續(xù)作為生成對抗網(wǎng)絡(luò)輸入可操作、有意義,并且減少計算量,將圖片尺寸調(diào)整統(tǒng)一為64*64大小。以第一、第八家族惡意代碼為例,最終生成灰度圖像分別如圖1、圖2所示;并在實驗輸入時通過歸一化操作,將圖像像素值由[0,255]限定在[-1,1],促進在后續(xù)實驗過程中網(wǎng)絡(luò)結(jié)構(gòu)對數(shù)據(jù)的處理,加快收斂速度和反向傳播。

圖1 第一類(Ramnit)惡意代碼灰度

圖2 第八類(Obfuscator.ACY)惡意代碼灰度
易觀察發(fā)現(xiàn),同一家族的惡意代碼圖像在紋理、色澤及結(jié)構(gòu)等特征方面具有明顯的相似之處,而不同家族之間存在顯著的差別。
2.2 基于GAN的惡意代碼數(shù)據(jù)增強
2.2.1 網(wǎng)絡(luò)結(jié)構(gòu)及參數(shù)選擇
生成對抗網(wǎng)絡(luò)(GAN)是由Ian Goodfellow等提出,是一種無監(jiān)督學(xué)習的生成式模型[10]。GAN思想的誕生啟發(fā)于博弈論中的二人零和博弈,通過兩個參與者的對抗互相提升,所以相較于自動編碼器和變分自編碼器等傳統(tǒng)的生成模型,GAN中包含兩個網(wǎng)絡(luò),其一是生成網(wǎng)絡(luò)G,另一個是判別網(wǎng)絡(luò)D,網(wǎng)絡(luò)模型結(jié)構(gòu)如圖3所示。

圖3 生成對抗網(wǎng)絡(luò)模型
然而傳統(tǒng)GAN在實際應(yīng)用中存在網(wǎng)絡(luò)難訓(xùn)練、梯度不穩(wěn)定以及訓(xùn)練進度無衡量指標等問題,因此本文采用其改進衍生的WGAN-GP模型來訓(xùn)練生成,對該模型生成網(wǎng)絡(luò)與判別網(wǎng)絡(luò)均選用深度卷積網(wǎng)絡(luò),充分學(xué)習惡意代碼圖像特征。
其中生成網(wǎng)絡(luò)由輸入層、隱含層和輸出層組成,模型結(jié)構(gòu)如圖4所示。該網(wǎng)絡(luò)以符合正太分布、維度為100的隨機噪聲為輸入,通過全連接和reshape等操作后送入隱含層;考慮惡意代碼圖像為灰度形式,且經(jīng)處理后尺寸較小,故為避免因卷積架構(gòu)過大而導(dǎo)致擬合困難、生成質(zhì)量差等問題,在隱含層僅設(shè)置4個轉(zhuǎn)置卷積層,使隨機噪聲經(jīng)過轉(zhuǎn)置卷積層進行空間上采樣,實現(xiàn)輸入數(shù)據(jù)通道數(shù)減半而圖像尺寸加倍,又為兼顧惡意代碼特征基本覆蓋和降低計算難度,將每層卷積核大小設(shè)為5*5,步幅為2,同時為解決梯度消失問題,并加快模型收斂,在隱含層(除最后一層轉(zhuǎn)置卷積層)中均使用ReLU作為激活函數(shù),并加入Batch Normalization層進行批標準化處理;最后由于惡意代碼數(shù)據(jù)經(jīng)處理后取值范圍在[-1,1],故輸出層采用Tanh激活函數(shù)進行激活返回。
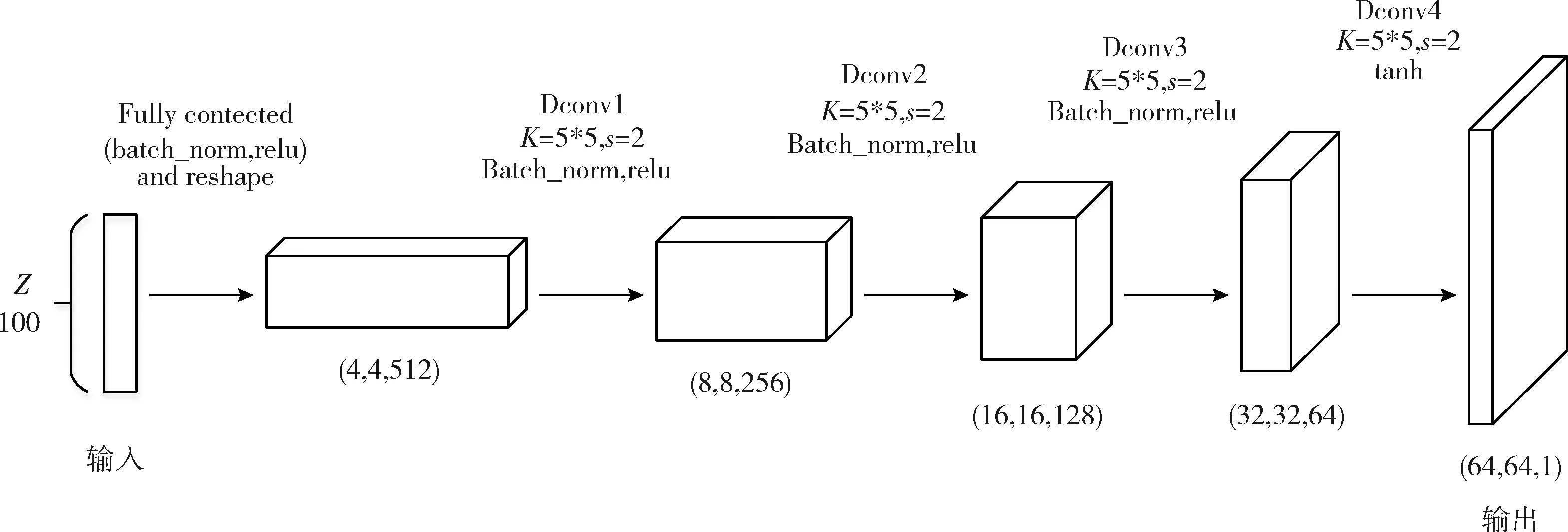
圖4 生成模型網(wǎng)絡(luò)結(jié)構(gòu)
判別網(wǎng)絡(luò)同樣由輸入層、隱含層和輸出層組成,如圖5所示。與生成網(wǎng)絡(luò)輸入不同,判別網(wǎng)絡(luò)的輸入來源包括兩部分:其一是真實惡意代碼圖像樣本,其二則是由生成器生成的假樣本,尺寸均為64*64*1;而為充分提取惡意代碼圖像中的復(fù)雜特征,故采用4個卷積層構(gòu)建隱含層,又考慮對惡意代碼數(shù)據(jù)的利用率及計算頻次故將卷積核選取與生成網(wǎng)絡(luò)相同的5*5大小,步幅均為2,又為在卷積降維操作中避免惡意代碼數(shù)據(jù)信息丟失而使用Leaky RELU激活函數(shù)激活,并在除第一層卷積層外其它隱含層中添加Layer Normalization進行處理;最后為達擬合真實與生成惡意代碼數(shù)據(jù)分布之間距離的目的,在輸出層不使用sigmoid函數(shù)激活,而通過全連接層直接將結(jié)果返回。
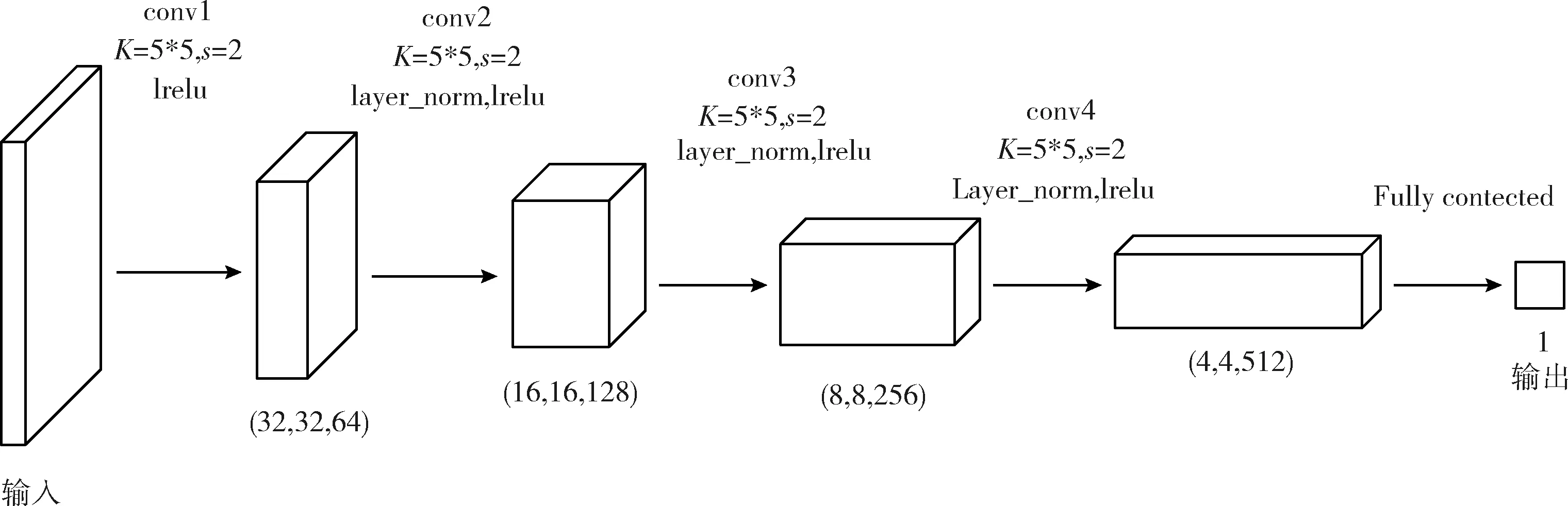
圖5 判別模型網(wǎng)絡(luò)結(jié)構(gòu)
并使用wassertein距離取代傳統(tǒng)GAN中JS散度衡量生成數(shù)據(jù)分布和真實數(shù)據(jù)分布之間的距離,解決傳統(tǒng)GAN因無重疊概率分布情況下概率無法衡量問題,使訓(xùn)練過程更加穩(wěn)定;還通過在目標函數(shù)中增加懲罰梯度來實現(xiàn)對Lipschitz系數(shù)的限制,由此避免參數(shù)極端和梯度消失或爆炸問題。使判別器優(yōu)化目標由真實惡意代碼數(shù)據(jù)和生成偽惡意代碼數(shù)據(jù)的原始誤差式(1)以及懲罰梯度項損失式(2)兩部分組成,最終損失函數(shù)如式(3)所示
(1)
(2)
L(D)=Lorigin_loss+Lgp
(3)
而生成器采用式(4)作為損失函數(shù)
(4)
2.2.2 模型訓(xùn)練
在對惡意代碼數(shù)據(jù)集經(jīng)過圖像處理之后,開始模型訓(xùn)練。為保證訓(xùn)練過程中判別器性能優(yōu)于當前生成器生成能力,能夠指導(dǎo)生成器朝更好的方向?qū)W習,故本文借鑒大多實驗中采用的訓(xùn)練次數(shù)比,設(shè)置每更新5次判別網(wǎng)絡(luò)后更新1次生成網(wǎng)絡(luò);將學(xué)習率初始值設(shè)為較小的0.0002,且為避免學(xué)習率過大無法收斂,過小訓(xùn)練太慢等問題采用指數(shù)衰減學(xué)習率,適時調(diào)整學(xué)習率配合訓(xùn)練。具體訓(xùn)練過程如下:
(1)隨機生成符合正態(tài)分布的噪聲z,并由生成器得到生成惡意代碼圖像Pg;
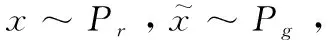
//訓(xùn)練判別器
(3)將真實惡意代碼圖像和生成惡意代碼圖像輸入判別器分別計算誤差,并如式(1)所示求得原始誤差損失Lorigin_loss,再由懲罰項采集樣本按式(2)計算懲罰梯度損失Lgp;
(4)計算得式(3)所示判別器誤差L(D);
(5)固定生成器參數(shù),依據(jù)式(3)所示誤差公式,采用Adam優(yōu)化器更新判別器參數(shù);
(6)判別器每更新5次,執(zhí)行以下步驟;
//訓(xùn)練生成器
(7)執(zhí)行步驟(1),并從生成的惡意代碼樣本Pg中采樣送入判別器;
(8)依據(jù)式(4)計算生成器對應(yīng)誤差損失L(G);
(9)固定判別器參數(shù),采用Adam優(yōu)化器更新生成器參數(shù)。
不斷迭代兩個過程,當判別器和生成器均收斂,達到納什平衡時結(jié)束訓(xùn)練。訓(xùn)練完成后,只需要將訓(xùn)練完善的生成器提取出來就可以作為惡意代碼數(shù)據(jù)集擴增的工具,通過給予其大量的隨機噪聲就能夠獲取足夠多的惡意代碼數(shù)據(jù)樣本,從而解決數(shù)據(jù)集數(shù)量缺乏及不均衡問題。
2.3 數(shù)據(jù)質(zhì)量評估
鑒于本研究最終為了生成與真實數(shù)據(jù)分布相似的新數(shù)據(jù),因此對其生成質(zhì)量和相似度的衡量指標也成為值得研究的問題。本文將從兩方面對生成數(shù)據(jù)進行評價:其一、采用圖像生成數(shù)據(jù)評價指標,由理論公式計算相應(yīng)分數(shù)來評估生成質(zhì)量與相似度;其二、將生成數(shù)據(jù)添加至原始數(shù)據(jù)用于分類檢測,通過比較分類檢測準確度衡量生成有效性。以下分別對兩個方面進行闡釋。
(1)本文采用生成對抗網(wǎng)絡(luò)將惡意代碼數(shù)據(jù)以惡意代碼圖像形式生成新的圖像樣本,則可以采用圖像評估的指標評價生成樣本質(zhì)量以及與原始樣本的相似度,故選擇灰度圖像評價常用指標之一——結(jié)構(gòu)相似性(SSIM)來驗證生成數(shù)據(jù)質(zhì)量。
結(jié)構(gòu)相似性(SSIM)是一種符合人類直覺的圖像質(zhì)量評價標準,從圖像亮度、對比度以及結(jié)構(gòu)三方面進行比較計算。該指標數(shù)值范圍在[0,1],數(shù)值越高說明生成圖像質(zhì)量越好,與原始數(shù)據(jù)結(jié)構(gòu)越相似。具體計算如式(5)所示
(5)
其中,x為原始惡意代碼圖像,y為本文模型生成結(jié)果,μx和μy分別代表x,y的平均值,σx和σy分別代表x,y的標準差,σxy代表x,y的協(xié)方差,c1、c2均為常數(shù)。
(2)對于數(shù)據(jù)增強研究的重要目的之一是生成數(shù)據(jù)能夠有效應(yīng)用,通常會將生成數(shù)據(jù)樣本進行分類檢測實驗驗證,透過分類檢測準確率來反映增強數(shù)據(jù)在實踐中的意義。因此,分類準確率也成為最終評價度量的標準之一。本文將采用決策樹、KNN以及隨機森林3種分類算法進行分類準確率驗證,分析比較增強效果。
3 實 驗
3.1 實驗數(shù)據(jù)集
目前對于惡意代碼數(shù)據(jù)集,開源的Kaggle平臺成為重要的獲取途徑之一,由其提供的數(shù)據(jù)集內(nèi)容全面且信服力高。本實驗選取由微軟在Kaggle平臺上發(fā)起的惡意代碼分類比賽所提供的數(shù)據(jù)集BIG2015[18],其主要包含表1所示的4部分文件。
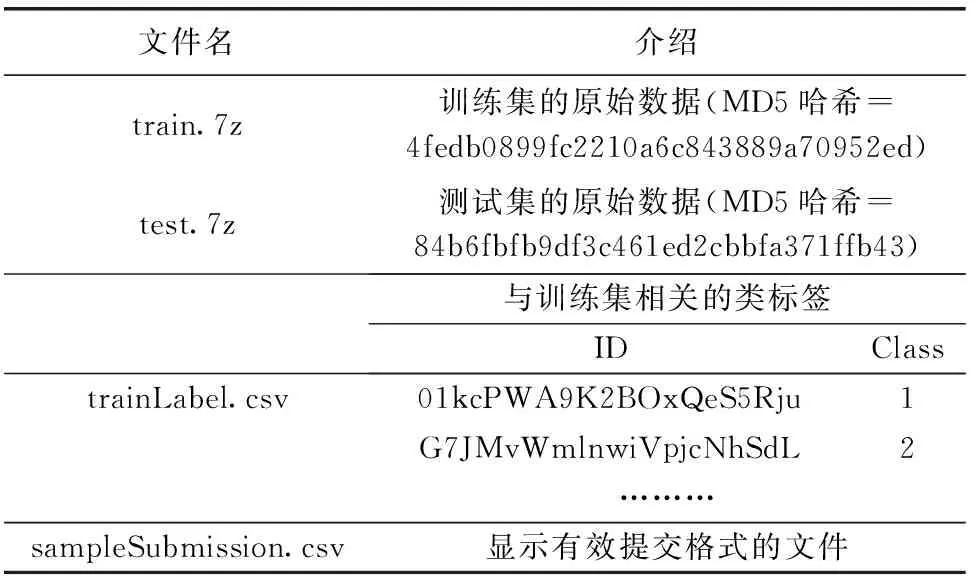
表1 數(shù)據(jù)集所包含文件
訓(xùn)練和測試樣本庫中所使用的9類惡意代碼家族為:Ramnit、Lollipop、Kelihos_ver3、Vundo、Simda、Tracur、Kelihos_ver1、Obfuscator.ACY、Gatak。在訓(xùn)練集中每個惡意代碼文件都有一個唯一標識該文件的20字符哈希值ID和一個Class(類別),其中Class標記為1-9分別對應(yīng)上述9種類別,且每個惡意代碼均對應(yīng)一個十六進制表示的.bytes文件和一個利用IDA反匯編工具生成的.asm文件。各類別數(shù)據(jù)數(shù)量情況見表2。

表2 數(shù)據(jù)集9類家族介紹
3.2 實驗環(huán)境
本文中的實驗環(huán)境主要包括實驗平臺和環(huán)境配置,具體信息見表3。

表3 實驗平臺及配置
3.3 實驗結(jié)果與分析
本文對所提生成對抗網(wǎng)絡(luò)模型依據(jù)上述進行實驗,并采用2.3章節(jié)的評價指標進行客觀分析,驗證有效性。
3.3.1 模型有效性驗證-生成數(shù)據(jù)與原始數(shù)據(jù)結(jié)構(gòu)相似性對比
為顯示本文所用方法的有效性及優(yōu)勢,本節(jié)中將使用已在圖像生成領(lǐng)域應(yīng)用廣泛且生成、判別網(wǎng)絡(luò)架構(gòu)與本文模型相似的深度卷積生成對抗網(wǎng)絡(luò)(DCGAN),同樣訓(xùn)練生成一定規(guī)模的各類別惡意代碼數(shù)據(jù)樣本[19],并計算對應(yīng)SSIM值與本文方法作比較。結(jié)果見表4。

表4 各類別SSIM值
由表4可得以下折線圖6,更加直觀比較兩種模型生成各類別數(shù)據(jù)與原始數(shù)據(jù)結(jié)構(gòu)相似性的實驗效果。
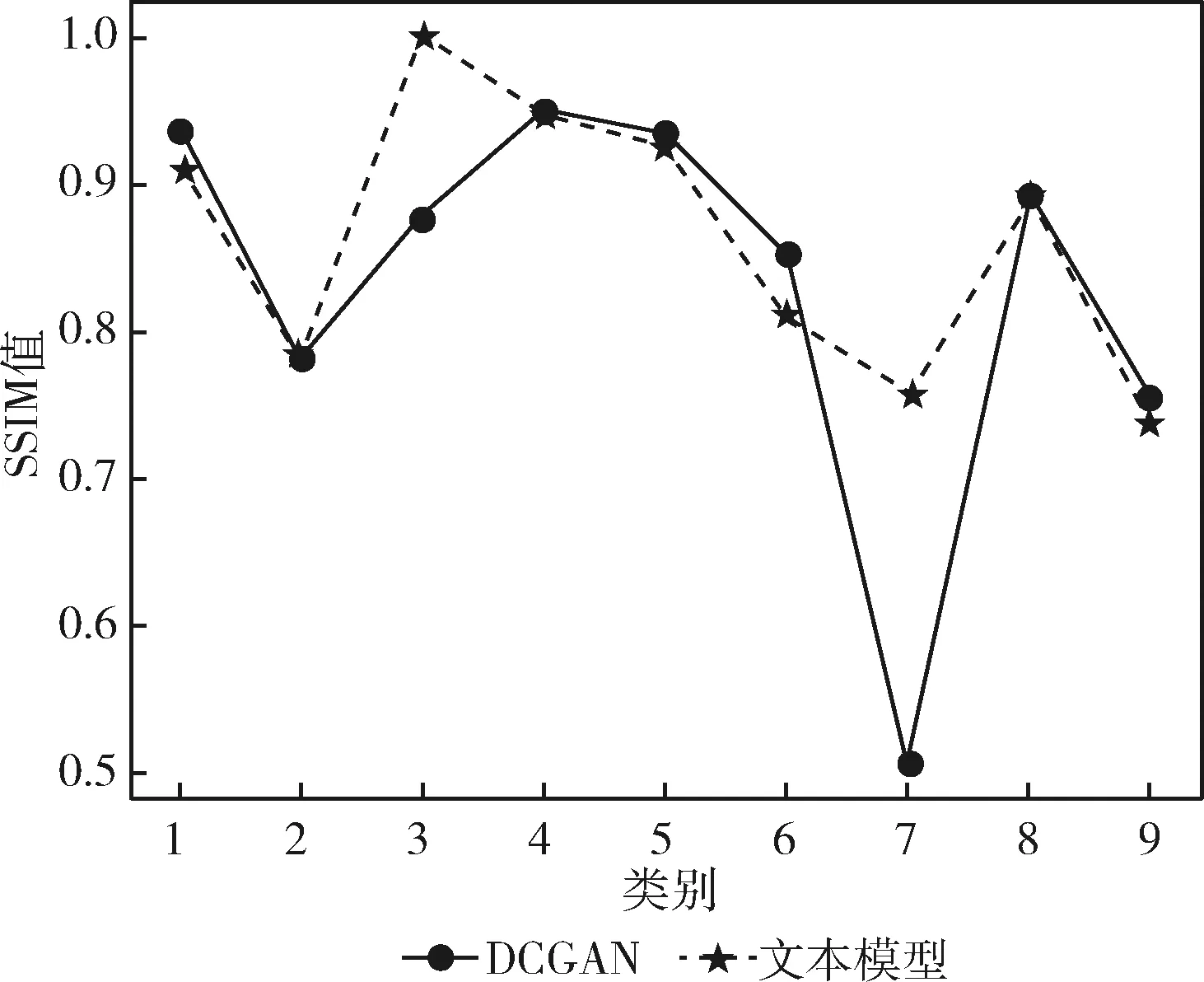
圖6 各類數(shù)據(jù)SSIM值
其中橫軸表示惡意代碼數(shù)據(jù)類別,縱軸為各類別與真實數(shù)據(jù)之間的SSIM值。由圖表可知:兩種模型在大多數(shù)類別惡意代碼數(shù)據(jù)生成中都有較好表現(xiàn),與原始數(shù)據(jù)的結(jié)構(gòu)相似性值都較高,這表明采用生成對抗網(wǎng)絡(luò)學(xué)習生成惡意代碼的方法切實可行。而與本文模型相比DCGAN模型所得曲線波動較大,不夠平穩(wěn),對于個別類型惡意代碼生成效果較差,雖有部分數(shù)值高于本文模型,但二者數(shù)值也相差甚微。由此體現(xiàn)本文模型性能更加穩(wěn)定,能夠更好處理各類別惡意代碼數(shù)據(jù)特點。所以總體來說,本文所用模型效果優(yōu)于DCGAN模型,是一種相對較好的惡意代碼數(shù)據(jù)生成模型。
3.3.2 模型有效性驗證-生成數(shù)據(jù)在分類中的應(yīng)用對比
為從分類結(jié)果角度進一步驗證本文數(shù)據(jù)增強方法的有效性,本節(jié)中以提取的灰度圖像矩陣為特征,采用決策樹、KNN以及隨機森林等傳統(tǒng)機器學(xué)習分類方法,分別在小規(guī)模均衡原始數(shù)據(jù)集與生成數(shù)據(jù)集、小規(guī)模不均衡原始數(shù)據(jù)集與增強數(shù)據(jù)集以及大規(guī)模原始數(shù)據(jù)集與增強數(shù)據(jù)集中進行分類驗證和分析。并且為避免按一定比例劃分數(shù)據(jù)集而受不同數(shù)據(jù)分布影響導(dǎo)致分類結(jié)果存在不確定性問題,提高最終結(jié)果穩(wěn)定性和說服力,以下分類結(jié)果均是采用十折交叉驗證方法計算而來。
首先對小規(guī)模均衡原始數(shù)據(jù)集和生成數(shù)據(jù)集進行實驗比較,即選取各類均衡且數(shù)量相同的原始數(shù)據(jù)和生成數(shù)據(jù),采用3種機器學(xué)習分類算法進行分類。分類結(jié)果見表5。

表5 各分類算法實驗結(jié)果(識別率/%)
由表5中數(shù)據(jù)可得:通過提取灰度圖像矩陣后對惡意代碼數(shù)據(jù)進行分類,在兩個數(shù)據(jù)集中均能取得一定的識別率,故選用的分類特征具備有效性,且采用隨機森林方法的表現(xiàn)相較于其它兩種機器學(xué)習方法最優(yōu)。此外,生成數(shù)據(jù)集采用3種機器學(xué)習分類方法取得的總體分類準確率在原始數(shù)據(jù)結(jié)果基準范圍之內(nèi),且略高于其結(jié)果,這表明由生成對抗網(wǎng)絡(luò)生成的新樣本有效學(xué)習到了各類別數(shù)據(jù)特征,且不僅能夠具有原始數(shù)據(jù)基本結(jié)構(gòu),還使得分類特征更加鮮明突出,具備較強的區(qū)分性。從而說明生成數(shù)據(jù)真實有效,可以用于原始數(shù)據(jù)增強。
以分類效果較優(yōu)的隨機森林分類器為例,表6詳細記錄了其對各類別數(shù)據(jù)的分類結(jié)果。
由表6可知,原始數(shù)據(jù)集均衡情況下對各類別的分類結(jié)果也較為均衡,生成數(shù)據(jù)集在各類別分類精確度、召回率和F1值上的表現(xiàn)都符合原數(shù)據(jù)集的分布情況,結(jié)果表明生成的各類數(shù)據(jù)特征與原數(shù)據(jù)特征分布都較為相似,可以很好的將各類區(qū)分開來。
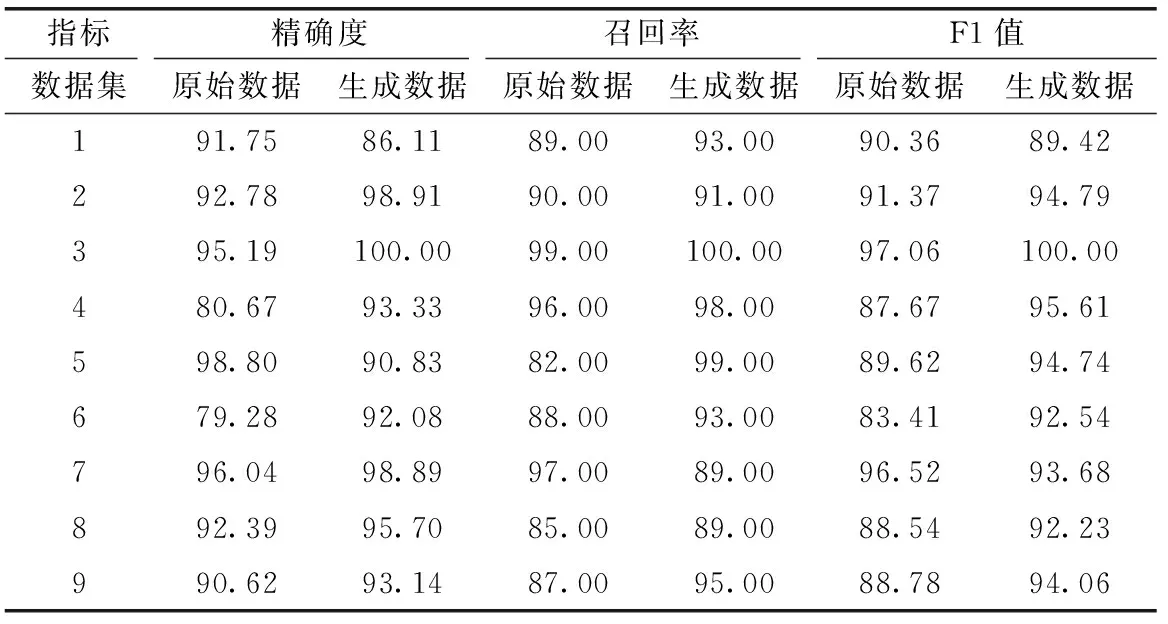
表6 隨機森林對各類別數(shù)據(jù)分類結(jié)果/%
上述分類驗證所選用數(shù)據(jù)集通過選取使各類別數(shù)量相同,旨在驗證各類生成數(shù)據(jù)能夠具備原始數(shù)據(jù)特征。下面從數(shù)據(jù)不均衡角度出發(fā),驗證本文生成樣本能夠有效緩解該問題。以下實驗對小規(guī)模不均衡原始數(shù)據(jù)集和增強數(shù)據(jù)集進行實驗,即選取10%原始不均衡數(shù)據(jù)集以及添加本文方法新生成數(shù)據(jù)后的較均衡數(shù)據(jù)集,采用上述特征提取方法提取相同特征后分別在分類器中進行實驗。表7展示了兩個數(shù)據(jù)集各類別惡意代碼樣本的數(shù)據(jù)量。

表7 惡意代碼訓(xùn)練集數(shù)據(jù)量
由表7可以發(fā)現(xiàn)原始數(shù)據(jù)集存在嚴重的數(shù)據(jù)不平衡現(xiàn)象,有些類別數(shù)據(jù)數(shù)量特別少如第五類和第七類惡意代碼數(shù)據(jù),而在使用本文方法生成數(shù)據(jù)一定的擴充下,各類別數(shù)據(jù)相對均衡。而采用不同分類器的具體分類結(jié)果見表8。

表8 各分類算法實驗結(jié)果(識別率/%)
由表8可得:3種分類方法中隨機森林表現(xiàn)最好,而當加入生成數(shù)據(jù)增大訓(xùn)練數(shù)量后,對3種分類方法的總體識別率均有不同程度的提升,結(jié)果表明采用本文增強數(shù)據(jù)集方法對于分類器性能的改善有一定的積極作用。
同樣以隨機森林為例,表9展示了各類別數(shù)據(jù)增強前后的分類結(jié)果,由此可以看出在原始數(shù)據(jù)集中數(shù)量較少的類別識別率都較小,受不均衡影響較為嚴重,而對其進行增強后各類別的識別率都有改變,其中在數(shù)據(jù)量較少的第四類和第五類等惡意代碼數(shù)據(jù)上表現(xiàn)顯著。從而可以驗證本文方法生成數(shù)據(jù)具備有效性,能夠在一定程度上緩解數(shù)據(jù)量少和不均衡等問題,用于輔助分類器訓(xùn)練。
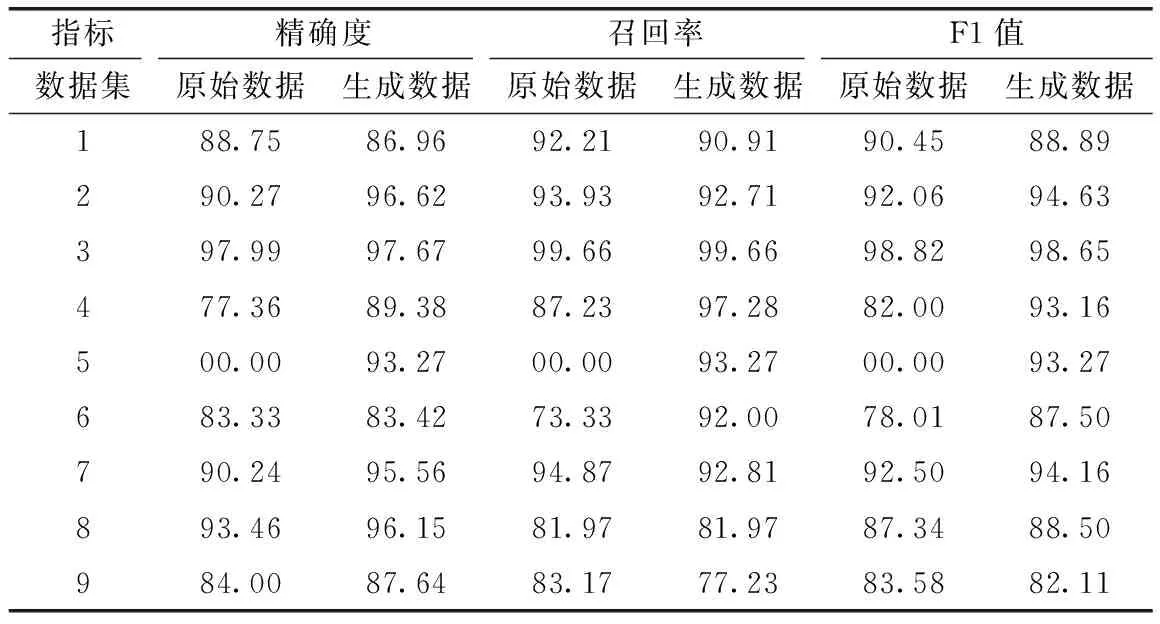
表9 隨機森林對各類別數(shù)據(jù)分類結(jié)果/%
最后對大規(guī)模不均衡原始數(shù)據(jù)集和增強后較均衡數(shù)據(jù)集進行實驗,即采用原始數(shù)據(jù)集中全部訓(xùn)練數(shù)據(jù)和添加生成數(shù)據(jù)后的較均衡數(shù)據(jù)集,利用3種分類方法分類。兩個數(shù)據(jù)集各類別惡意代碼樣本的數(shù)據(jù)量和具體分類結(jié)果分別見表10、表11。

表10 惡意代碼訓(xùn)練集數(shù)據(jù)量

表11 各分類算法實驗結(jié)果(識別率/%)
由表11可發(fā)現(xiàn):當數(shù)據(jù)量顯著增多后,采用決策樹、KNN和隨機森林的分類準確率也都明顯提升,說明數(shù)據(jù)量對識別率存在較大影響,而在有針對性的添加生成數(shù)據(jù),擴增數(shù)據(jù)集后,各方法又有一定提升,整體結(jié)果表明該生成數(shù)據(jù)能夠用于分類器的訓(xùn)練,且有一定的積極作用。而對各類別具體分類結(jié)果見表12,可以發(fā)現(xiàn)雖然原始數(shù)據(jù)各類的識別精確度已具有較好結(jié)果,但通過本文方法增強,對于原始數(shù)據(jù)量少的4、5、6、7類數(shù)據(jù)的識別率還是有明顯提升,一定程度上緩解了數(shù)據(jù)不均衡而帶來的損失。
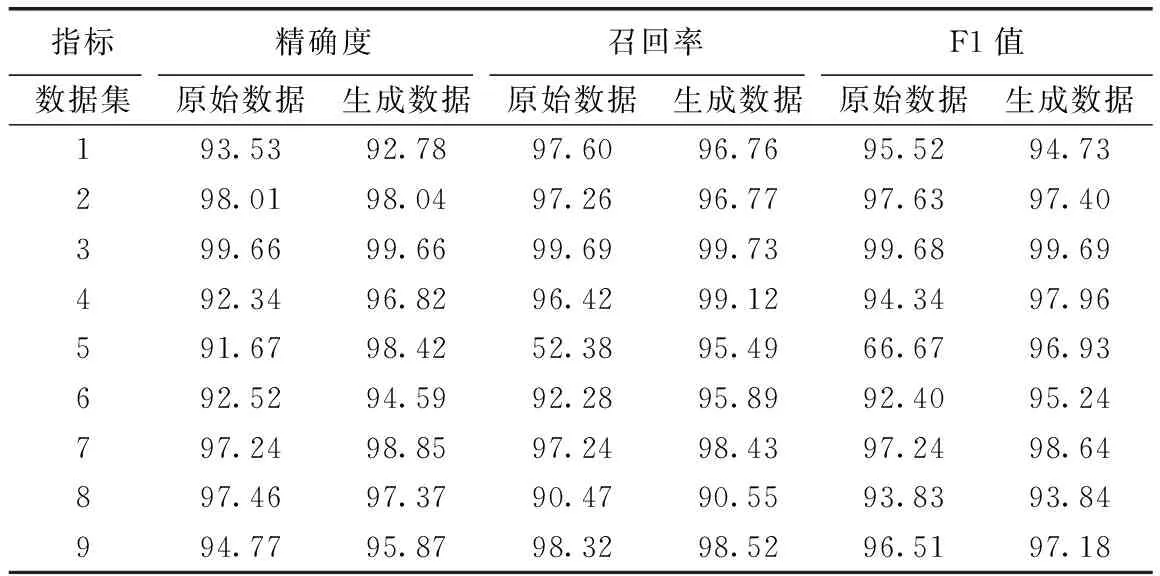
表12 隨機森林對各類別數(shù)據(jù)分類結(jié)果/%
綜合分析上述三方面實驗結(jié)果可得:①由表5、表8和表11中原始數(shù)據(jù)集結(jié)果可知數(shù)據(jù)集數(shù)量對惡意代碼分類影響較大,數(shù)據(jù)量越多分類識別率越高,從一方面驗證數(shù)據(jù)的重要性,凸顯本研究的意義;②由表8、表11各自對比結(jié)果可知,采用本文數(shù)據(jù)增強對提升分類器性能有積極作用;③通過表9、表12中各類別數(shù)據(jù)分類結(jié)果展示可知,不均衡數(shù)據(jù)也是影響分類性能的重要因素,而使用本文增強方法能夠有效緩解該問題。總之,本文方法所生成數(shù)據(jù)能夠從數(shù)據(jù)量和均衡性兩方面較好解決性能提升限制問題,具有可行性。
上述實驗已經(jīng)驗證了本文增強方法的有效性,本小節(jié)最后進一步與其它分類方法在該數(shù)據(jù)集上所得結(jié)果作比較,見表13。本文利用在大規(guī)模原始數(shù)據(jù)集中增強后,以隨機森林作為分類器所得結(jié)果與相關(guān)研究進行比較。本文方法所得結(jié)果比文獻[6]所達結(jié)果略低,主要原因在于文獻[6]采用卷積神經(jīng)網(wǎng)絡(luò)模型對轉(zhuǎn)換后的惡意代碼圖像進行特征提取和分類,其層層變換與提取對識別結(jié)果有一定的提高;而相較于文獻[5]和文獻[3]結(jié)果均有所提高。由此可知通過生成對抗網(wǎng)絡(luò)進行數(shù)據(jù)增強對于分類識別具有積極的作用。
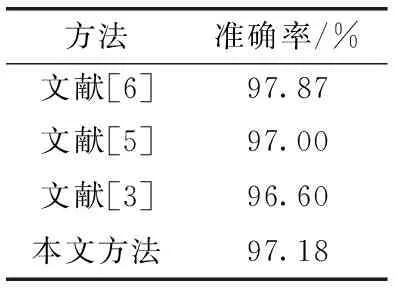
表13 相關(guān)研究比較
3.3.3 小結(jié)
綜上所述,本節(jié)不僅從圖像角度選取SSIM值作為評價指標衡量了本文方法生成圖像的質(zhì)量以及與原始數(shù)據(jù)的相似性,體現(xiàn)本文方法相較于DCGAN生成數(shù)據(jù)的優(yōu)勢,對擴充較高質(zhì)量惡意代碼數(shù)據(jù)具有一定的可行性;還通過多種分類器模型識別率的比較,表明本文方法擴增的數(shù)據(jù)樣本有利于提高分類器性能,能夠緩解原數(shù)據(jù)集各類別數(shù)據(jù)量不均衡等問題,具備有效性。
4 結(jié)束語
惡意代碼數(shù)據(jù)集的采集獲取是惡意代碼分類檢測任務(wù)中的關(guān)鍵一環(huán),本文將生成對抗網(wǎng)絡(luò)應(yīng)用于網(wǎng)絡(luò)惡意代碼數(shù)據(jù)的生成,很好地解決了現(xiàn)存數(shù)據(jù)集難獲取、不均衡等問題,為此環(huán)節(jié)提供了保障。本文創(chuàng)新性地將惡意代碼可視化技術(shù)融入其中,結(jié)合生成對抗網(wǎng)絡(luò)在圖像領(lǐng)域的優(yōu)良應(yīng)用,實現(xiàn)了惡意代碼數(shù)據(jù)集擴增。從整體來說,本文方法在數(shù)據(jù)集擴增實驗中表現(xiàn)良好,能夠達到預(yù)期期望。實驗比較結(jié)果表明,惡意代碼生成數(shù)據(jù)具備有效性,符合用于惡意代碼檢測任務(wù)訓(xùn)練的目標。本文下一步計劃深入探究惡意代碼可視化表示方法,使其更多包含、更好表現(xiàn)惡意代碼數(shù)據(jù)特性,從保持惡意代碼攻擊性的角度探究生成更具關(guān)聯(lián)性新樣本的方法,并評估其質(zhì)量和有效性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
