基于改進膠囊網(wǎng)絡(luò)的文本細(xì)粒度情感分類方法
2021-11-19 11:16:12李清霞李啟明
計算機仿真 2021年10期
江 濤,李清霞,李啟明
(1.廣東理工學(xué)院信息技術(shù)學(xué)院,廣東肇慶 526100;2.廣東工業(yè)大學(xué)網(wǎng)絡(luò)信息中心,廣東廣州510006)
1 引言
文本情感分析屬于信息檢索、自然語言處理、人工智能領(lǐng)域的交叉問題,可明確文本描述的情感內(nèi)容[1]。以往的情感分析大多是對篇章結(jié)構(gòu)、段落結(jié)構(gòu)的句子實施分析,而伴隨用戶需求日益顯著,此類層級的情感分析粗糙度顯著,一個段落或一句話僅表達一種情感態(tài)度,不能高精度描述用戶想了解的內(nèi)容。
目前已有研究人員對文本情感分類問題進行專題研究,文獻[2]提出了基于細(xì)粒度多通道卷積神經(jīng)網(wǎng)絡(luò)的文本情感分析方法,該方法可深入挖掘文本深層次的語義信息,實現(xiàn)文本情感分析,但是該方法不適用于文本樣本數(shù)較多的情況。文獻[3]提出融合注意力機制的多語言文本情感分析方法,該方法的優(yōu)勢在于可實現(xiàn)多語言文本情感分析,但對具有歧義的文本情感的分類精度有待優(yōu)化。
針對上述問題,以文本細(xì)粒度情感分析為主,細(xì)粒度情感可以在指定的角度分析文本的情感態(tài)度,提出基于改進膠囊網(wǎng)絡(luò)的文本細(xì)粒度情感分類方法,以期實現(xiàn)文本細(xì)粒度情感分類。
2 基于改進膠囊網(wǎng)絡(luò)的文本細(xì)粒度情感分類方法
2.1 基于信息增益改進貝葉斯模型的文本詞義消歧方法
文本歧義詞語對文本細(xì)粒度情感分類效果存在直接影響,例如,對汽車性能評價語句中,常常存在“不錯”、“還可以”此類評價,此種文本給人的直觀情感存在判斷模糊不清的情況,這對文本細(xì)粒度情感分類精度存在負(fù)面干擾[4]。為此,在實施文本細(xì)粒度情感分類之前,使用基于信息增益改進貝葉斯模型的文本詞義消歧方法,實現(xiàn)文本詞義消歧。
2.1.1 基于信息增益最大原則的改進思想
引入文本特征詞語的位置信息,以此優(yōu)化貝葉斯模型的詞語分辨性能。文本特征詞語位置信息能夠使用信息增益最大原則對文本特征集實施優(yōu)化,提高對歧義詞語判斷共享最顯著的上下文詞語權(quán)重,以此凸顯它們對詞義判斷的價值[5-6]。分析文本特征詞語位置信息與詞義判斷問題的聯(lián)系,得到位置權(quán)重,實現(xiàn)文本詞義優(yōu)化。
使用熵的方法能夠計算貝葉斯模型引入文本新信息前后的不確定性,按照不確定性的變化能夠計算文本詞義信息的增益度。先把上下文里各個詞納為一個種類,運算整個上下文環(huán)境的統(tǒng)計不確定性,簡稱為熵G(Context)。整個上下文環(huán)境的不確定性,簡稱為條件熵G(Context|Up),Up代表文本詞語集合。熵的運算方法是
G(Context)=-W(Context)×logW(Context)
(1)
其中,W(Up)是文本詞語Up在訓(xùn)練語料里出現(xiàn)的頻率。
(2)
其中,文本中全部詞語出現(xiàn)的頻度是θ;θ(Up)是Up出現(xiàn)的頻度。
條件熵的運算方法是:
(3)
其中,O(Up)是詞語Up在某指定位置出現(xiàn)的概率。
熵與條件熵之差可描述上下文環(huán)境的信息的增益量,信息增益量JK是:
JK=G(Context)-G(Context|Up)
(4)
將信息增益熵設(shè)成上下文詞語權(quán)重,導(dǎo)入改進貝葉斯模型的文本詞義消歧模型中,實現(xiàn)文本詞語消歧。
2.1.2 改進貝葉斯模型的文本詞義消歧模型
使用改進貝葉斯模型的文本詞義消歧模型實現(xiàn)文本詞語消歧的方法是:
(5)
其中,D0、W依次是文本中歧義詞、詞語出現(xiàn)概率;Dstar是消歧后文本。
2.2 基于改進稠密膠囊網(wǎng)絡(luò)模型的文本細(xì)粒度情感分類方法
基于改進稠密膠囊網(wǎng)絡(luò)模型的文本細(xì)粒度情感分類方法的改進之處主要在于引入自主力機制,增大需識別文本深層次特征的特征權(quán)值,提高文本細(xì)粒度情感分類精度。自注意力模型借鑒全局依賴學(xué)習(xí)的原理,建立非局部塊,對文本特征中深層次特征實施加權(quán),實現(xiàn)文本特征間全局依賴學(xué)習(xí)[7]。自注意力模型能夠協(xié)助網(wǎng)絡(luò)模型在膠囊網(wǎng)絡(luò)訓(xùn)練學(xué)習(xí)時著重分析文本深層次特征間的相關(guān)性,提取細(xì)粒度情感,并且可以在小樣本條件下優(yōu)化文本細(xì)粒度情感分類效果[8-10]。
此外,傳統(tǒng)膠囊網(wǎng)絡(luò)使用的動態(tài)路由算法在優(yōu)化分類準(zhǔn)確率之時,因為算法自身使用子膠囊和父膠囊間的全連接結(jié)構(gòu),網(wǎng)絡(luò)參數(shù)運算量將隨著文本特征的增多而增多,致使特征運算負(fù)載變大,所以,傳統(tǒng)膠囊網(wǎng)絡(luò)僅適用于小規(guī)模文本細(xì)粒度情感分類問題。基于改進稠密膠囊網(wǎng)絡(luò)模型的文本細(xì)粒度情感分類方法中,還使用局部約束動態(tài)路由算法,完成局部范圍中膠囊路由選取與變換矩陣共享,則子膠囊僅可以在一個提前設(shè)置的本地窗口路由與父膠囊聯(lián)系,且膠囊網(wǎng)絡(luò)里相同種類的膠囊變換矩陣具有共享性。
2.2.1 自注意力模型
1)特征相似度與注意力掩模運算
設(shè)置1×1卷積核是a(y)、b(y)、c(y),使用此卷積核完成文本細(xì)粒度情感特征跨通道信息融合
a(y)=Vay
(6)
b(y)=Vby
(7)
c(y)=Vcy
(8)
其中,Va、Vb、Vc屬于膠囊網(wǎng)絡(luò)參數(shù);a(y)、b(y)可運算文本細(xì)粒度情感特征相似度,可用來建立注意力掩模,c(y)用來構(gòu)建被掩模特征圖;y屬于文本細(xì)粒度情感特征值。相似度rij運算方法與注意力掩模δij運算方法是
rij=a(yi)b(yi)
(9)
(10)
其中,M是文本細(xì)粒度特征數(shù)量;yi屬于文本細(xì)粒度情感特征中索引是i的特征值。i、j代表特征索引值;rij可運算文本細(xì)粒度情感特征中索引位置j特征值對應(yīng)于索引i位置特征值的相似度;將δij實施歸一化,運算索引j位置特征值的全局相似度響應(yīng)值,以此建立注意力掩模矩陣。
2)文本細(xì)粒度情感自注意力特征運算
文本細(xì)粒度情感自注意力特征的運算公式是
(11)
xj=βzj+yi
(12)
其中,zj是掩模特征索引j位置中,文本細(xì)粒度情感的自注意力特征值;權(quán)重參數(shù)是β;xj是文本細(xì)粒度情感的自注意力特征;索引i位置文本細(xì)粒度情感自注意力特征值是yi。
2.2.2 局部約束動態(tài)路由算法



(13)
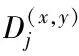
(14)
(15)
2.2.3 損失函數(shù)
使用改進稠密膠囊網(wǎng)絡(luò)模型損失函數(shù)KLost在原間隔損失函數(shù)中引入重構(gòu)損失項
KLost=KC+εKR
(16)
其中,間隔損失函數(shù)、重構(gòu)損失函數(shù)、誤差平衡系數(shù)依次是KC、KR、ε。間隔損失項可以優(yōu)化膠囊網(wǎng)絡(luò)模型對文本細(xì)粒度情感的分類精度,重構(gòu)損失項可判斷膠囊網(wǎng)絡(luò)特征重構(gòu)誤差[12]。
2.2.4 分類步驟
輸入:需細(xì)粒度情感分類的文本樣本Dstar
輸出:文本細(xì)粒度情感分類結(jié)果Dout
1)建立自注意力特征模型,提取文本細(xì)粒度情感特征;
2)建立膠囊層,此層分為2層主膠囊層與分類膠囊層,2層主膠囊層中具有32個膠囊,各個膠囊包含16個卷積核,各個膠囊輸出16維激活向量。分類膠囊層輸出激活向量Dout,激活向量可描述文本細(xì)粒度情感分類結(jié)果;
3)重構(gòu)輸入的需細(xì)粒度情感分類文本樣本,把第2個主膠囊層設(shè)成輸入,依次連接卷積層,將文本細(xì)粒度情感特征維度卷積核步長是1的反卷積層與重構(gòu)輸入樣本的卷積層進行擴充,輸出重構(gòu)樣本;
4)計算重構(gòu)樣本特征與原始樣本特征的損失函數(shù),選取合適的訓(xùn)練輪數(shù),優(yōu)化網(wǎng)絡(luò)模型對文本細(xì)粒度情感的分類精度。通過上述步驟,實現(xiàn)文本細(xì)粒度情感分類。
3 實驗分析
3.1 實驗環(huán)境設(shè)置
實驗硬件環(huán)境設(shè)置為Win10+Ubuntu1604雙系統(tǒng),16GB內(nèi)存,GTX1080顯卡,Intel Core i7 CPU,1T硬盤,并在MATLAB仿真軟件中,采用Python2.7編程語言以及Java工具包自然語言處理工具進行對比實驗。
將所提方法的膠囊網(wǎng)絡(luò)每步訓(xùn)練時間設(shè)成10ms,各輪文本特征訓(xùn)練時間是400ms,所提方法的損失函數(shù)曲線如圖1所示。
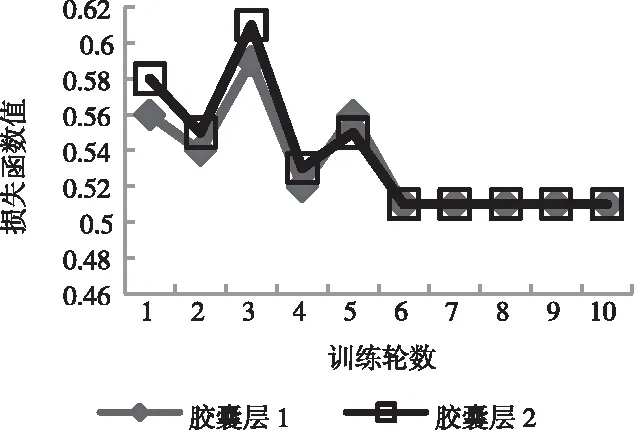
圖1 所提方法損失函數(shù)曲線圖
由圖1可知,所提方法兩個膠囊層的損失函數(shù)值在第6輪訓(xùn)練中趨于穩(wěn)定,且最小,此時分類性能最佳。為此,在所提方法應(yīng)用效果測試中,將所提方法訓(xùn)練輪數(shù)設(shè)成6次。
3.2 文本細(xì)粒度情感分類效果
3.2.1 多種文本細(xì)粒度情感分類效果評價
為測試所提方法對多種文本細(xì)粒度情感分類效果,使用國際上常用的查準(zhǔn)率、召回率、F1三個指標(biāo)判斷。查準(zhǔn)率(Precision ratio)、召回率(Recall)、F1(F-measure)三個指標(biāo)的數(shù)學(xué)公式是:
(17)
(18)
(19)
對某聊天系統(tǒng)里文本細(xì)粒度情感實施分類,文本細(xì)粒度情感類型依次是喜悅、悲傷、驚奇、憤怒、恐懼、厭惡。在MATLAB軟件中導(dǎo)入此聊天系統(tǒng)中聊天記錄,聊天記錄六種文本細(xì)粒度情感的聊天記錄為3000條,每種情感文本是500個,詳細(xì)設(shè)置如表1所示。

表1 實驗文本設(shè)置
使用所提方法、文獻[2]方法、文獻[3]方法同時進行文本細(xì)粒度情感分類,三種方法對聊天記錄六種文本細(xì)粒度情感的分類效果如圖2、圖3、圖4所示。
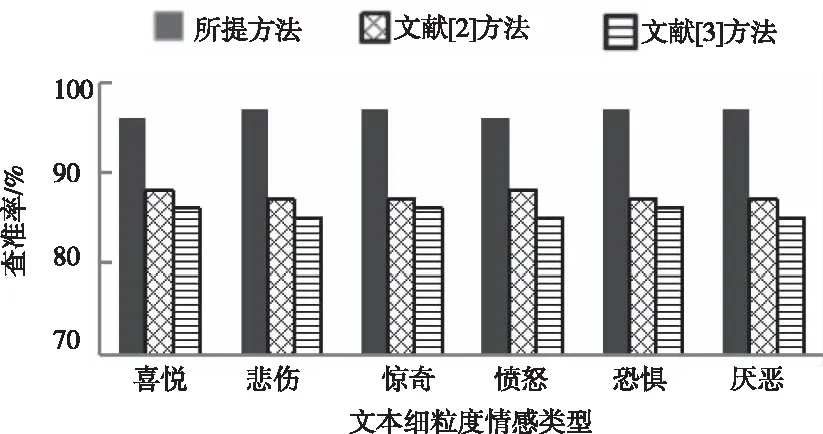
圖2 查準(zhǔn)率對比結(jié)果
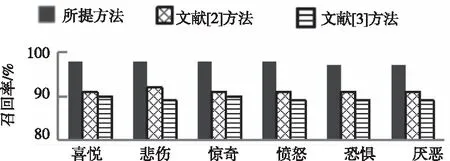
圖3 召回率對比結(jié)果
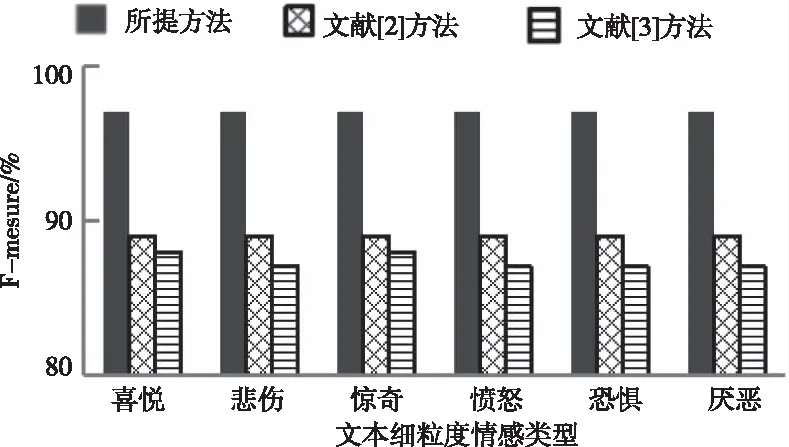
圖4 F-measure對比結(jié)果
由圖2、圖3、圖4可知,所提方法、文獻[2]方法、文獻[3]方法對表1中文本進行細(xì)粒度情感分類后,所提方法分類結(jié)果的查準(zhǔn)率、召回率、F1值均大于95%;文獻[2]方法、文獻[3]方法分類結(jié)果的查準(zhǔn)率、召回率、F1值均低于95%,由此可知,相比文獻[2]方法和文獻[3]方法,所提方法對多種文本細(xì)粒度情感分類效果較好。
3.2.2 具有歧義的文本細(xì)粒度情感分類精度評價
使用所提方法、文獻[2]方法、文獻[3]方法對存在詞語歧義的文本進行文本細(xì)粒度情感分類。存在詞語歧義的文本如表2所示。

表2 存在詞語歧義的文本
使用Kappa系數(shù)檢驗三種方法對具有歧義文本細(xì)粒度情感的分類精度,Kappa系數(shù)檢驗的公式是
(20)
其中,p1、p2依次是具有歧義文本細(xì)粒度情感分類結(jié)果與實際情感的實際一致率、期望一致率。Kappa系數(shù)越接近1,表示具有歧義文本細(xì)粒度情感的分類結(jié)果與實際情感一致性較高;Kappa系數(shù)越接近0,表示具有歧義文本細(xì)粒度情感的分類結(jié)果與實際情感一致性較低。
所提方法、文獻[2]方法、文獻[3]方法對四種存在歧義文本細(xì)粒度情感分類結(jié)果的Kappa系數(shù)測試結(jié)果依次如表3所示。
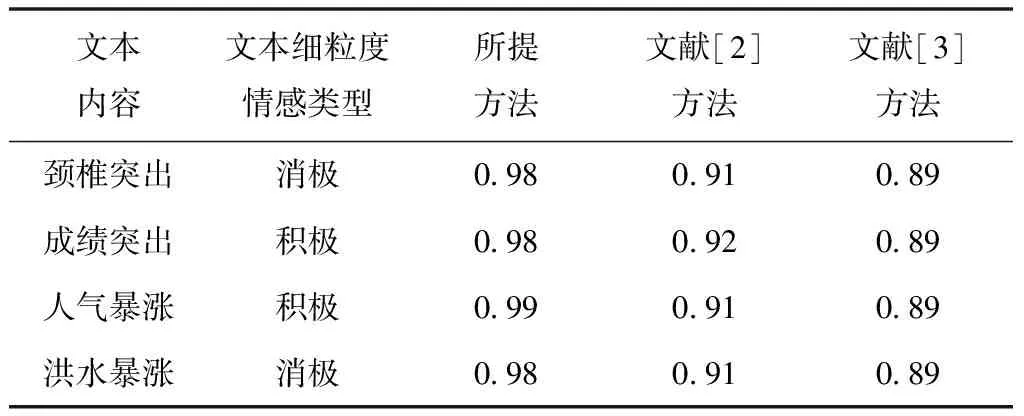
表3 三種方法Kappa系數(shù)測試結(jié)果
由表3可知,三種方法對四種存在歧義文本細(xì)粒度情感分類結(jié)果的Kappa系數(shù)差異較為明顯。所提方法對四種存在歧義文本細(xì)粒度情感分類結(jié)果的Kappa系數(shù)最大值為0.99,所提方法對具有歧義文本細(xì)粒度情感的分類結(jié)果與實際情感一致性較高;文獻[2]方法、文獻[3]方法對四種存在歧義文本細(xì)粒度情感分類結(jié)果的Kappa系數(shù)均小于所提方法。由此可知,所提方法對具有歧義文本細(xì)粒度情感的分類精度較高,原因是所提方法使用了基于信息增益改進貝葉斯模型的文本詞義消歧方法,有效去除文本詞義歧義,提升文本細(xì)粒度情感分類精度。
4 結(jié)論
膠囊網(wǎng)絡(luò)屬于一種新型網(wǎng)絡(luò)結(jié)構(gòu),與卷積神經(jīng)網(wǎng)絡(luò)的標(biāo)量輸入與輸出模式相比,膠囊網(wǎng)絡(luò)使用向量描述文本特征,能夠合理兼顧文本深度層次的語義信息。提出基于改進膠囊網(wǎng)絡(luò)的文本細(xì)粒度情感分類方法,可優(yōu)化文本細(xì)粒度情感分類效果,存在一定使用價值。具體應(yīng)用價值體現(xiàn)如下:
1)對某聊天系統(tǒng)里的文本細(xì)粒度情感實施分類后,當(dāng)文本細(xì)粒度情感類型依次是喜悅、悲傷、驚奇、憤怒、恐懼、厭惡時,所提方法分類結(jié)果的查準(zhǔn)率、召回率、F1值均大于95%,對多種文本細(xì)粒度情感分類效果較好;
2)所提方法對四種存在歧義文本細(xì)粒度情感分類結(jié)果的Kappa系數(shù)最大值為0.99,與1十分接近,所提方法對具有歧義文本細(xì)粒度情感的分類結(jié)果與實際情感一致性較高,能夠有效提升文本細(xì)粒度情感分類精度。
猜你喜歡
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
