基于改進遺傳算法的軟件單元安全性測試仿真
2021-11-18 04:09:04龐先偉
計算機仿真 2021年1期
王 超,龐先偉
(西南財經大學,四川 成都 610074)
1 引言
目前,計算機軟件在各領域得到廣泛使用,已成為人們工作與生活的重要組成部分。軟件的安全問題會造成一定的財產與隱私風險。因此在軟件開發中安全檢測是關鍵環節。其主要目的是通過少量測試用例實現最大的檢測覆蓋面,保證及時發現軟件存在的安全隱患,進而改善軟件可靠性。但是計算機程序日益復雜,軟件漏洞查找難度逐漸增大。為解決該問題,相關專家已經得到了一些可應用的研究成果。
文獻[1]提出軟件安全檢測方法。利用安全控制結構,建立描述軟件過程的變量模型。綜合分析危險發生系統上下文信息,將其作為軟件安全性要求。設計控制系統軟件,采用模型檢驗技術對軟件安全性進行測試。文獻[2]在區塊鏈基礎上構建軟件安全檢測模型。當一個區塊鏈高于六個區塊后,此區塊的內容將不能被改變,認為其達到穩定狀態,威脅出現的概率有效降低,根據每個區塊到達穩定狀態的幾率來判斷軟件是否安全。
上述兩種傳統方法具有較好安全檢測性能,但是實際應用中出現了漏檢率偏高問題。為此本文利用改進的遺傳算法測試軟件單元安全性。在傳統遺傳算法基礎上,引入種群活力思想,綜合分析種群多樣性與鄰近種群之間相似度,利用并行機理改進變異操作過程。仿真結果表明,所提方法降低了漏檢率,對軟件可疑點測試更加全面,表現出了較高應用價值。
2 軟件威脅分類與異常特征分析
2.1 安全威脅分類
1)系統軟件安全威脅
操作系統屬于最關鍵的軟件之一,是智能終端的核心,若系統存在安全威脅,則用戶隱私信息可能暴露。現階段操作系統威脅分為:系統漏洞、系統底層API(Core Audio APls)濫用等。
系統漏洞[3]能夠對軟件安全造成毀滅性危害,例如iOS(Internet work Operating System)越獄行為就是通過存在的漏洞破壞系統,屬于主動破壞行為。一些漏洞問題會在網絡中公開,因此攻擊者能夠任意使用漏洞資源對軟件進行攻擊。
2)應用軟件安全威脅
此種威脅主要由惡意軟件[4]引起。在傳統互聯網中對惡意軟件研究起步較晚,缺乏對其識別的標準。為提高整體網絡安全環境,提出惡意軟件代碼描述規范。此規范中分類惡意元件,包括信息竊取、資費消耗、系統破壞等。
2.2 軟件異常特征分析
軟件安全問題體現在多個方面,比如:CPU占用量較大,表明軟件存在潛在風險,可優化其空間;電量大量消耗表明可能有惡意軟件正在資源消耗;內存快速減少說明內存遭到泄漏。結合上述的軟件安全分類結果,將軟件有關安全問題與系統性能特性指標一一對應,總結結果表1所示。
3 基于改進遺傳算法的軟件單元安全性測試
3.1 軟件安全性度量性選擇
遺傳方法是一種自適應搜索算法,與優勝略汰思想相同,存在自適應性與并行性,有助于處理海量復雜數據,可以解決軟件質量度量屬性選取問題[5]。此外,該方法還能對任意一個度量屬性做出優劣評判,而不局限于評價單一軟件安全性,確保選擇的度量屬性子集最優化,提高搜索效率,屬性選取過程如圖1所示。
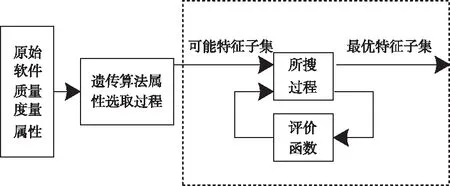
圖1 遺傳算法的軟件質量屬性選取過程
3.1.1 度量屬性編碼
編碼方式是遺傳算法的重要內容,表示全部軟件屬性子集的解空間。常用的編碼方式較多,由于軟件質量度量屬性僅有選中與不選兩種結果,因此本文利用二進制編碼。
例如某六個軟件安全性度量屬性表示為{y1y2y3y4y5y6},因此{111010}代表一個可能屬性子集合,其中1表示被選中,0表征未被選中。
3.1.2 初始種群選擇
在遺產算法中必須先確定一個潛在解,將其視為初始種群[6]。因為初始種群分布狀況會影響該算法全局收斂性,假設{X(n);n≥1}表示算法中種群馬爾科夫鏈,pm=0,X(0)=X0,因此可以得出:
1)針對Y∈L(X0),有n≥0的情況存在,所以P{Y∈X(n)/X(0)=X0}>0;
2)針對Y?L(X0),有n≥0的情況發生,因此P{Y∈X(n)/X(0)=X0}=0。
上述中,pm表示變異幾率,L(X0)代表初始種群最小規模,X(n)為第n代種群,Y是種群中任意一個個體。
通過上述分析可知,初始種群確定問題的本質是利用有限個體表示空間特征優化。因此種群規模不可隨意確定,只有將空間內最優個體作為初始種群,才可以很好的體現空間內部特性。因此在確定種群后需要自適應調整交叉變異概率。
3.1.3 變異概率自適應調整
本文改進傳統的AGA(Adaptive Genetic Algorithm)與PAGA(Prominent Adaptive Genetic Algorithm)自適應交叉變異概率調整方法。假定對第t代種群中第i個個體做交叉變異處理[7],則AGA方法中變異幾率計算公式如下
(1)

(2)
式中,f′t表示未交叉的個體中較高的適應度值,k1、k2、k3與k4是[0,1]區間的數,k3、k4高于k1、k2。在此種算法中,自適應度值越高,參與交叉變異的幾率就越低。因此有利于在進化過程中保存較多優質個體,但是其中一些優質個體無法參加遺傳操作,易產生早熟現象。
而在PAGA中,適應度值越高,參與交叉操作的可能性就越大,其交叉概率計算公式表示為

(3)
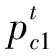
研究上述兩種算法,得出產生問題的主要原因是這兩種方法均沒有分析整個種群進化情況[8]。在進化初始時期,種群差異性較大,自適應值也相對較大,但為使優良模式傳播效果更好,對自適應度值較高的個體定義更大的交叉幾率。在進化后半段,交叉概率隨交叉效果的下降而下降,此時應該保存更多較優個體。
綜合上述分析,本文使用種群活力改進上述方法,提出一種新的自適應變化規則:
式(4)定義的是交叉概率變換準則,在進化初始階段,優質個體可以得到有效傳播,在進化后半段,能實現對優質個體的保護。式(5)描述變異幾率自適應變換準則,取值大小與種群活力程度相關。當種群活力程度較低時,變異幾率取值應較大,以此控制種群變壞。

(5)
式中,pc1、pc2、pc3、pm1、pm2分別表示原始設置的交叉變異機率;θ(t)代表第t代種群活力程度指標,kc1與kc2均屬于交叉調節系數,取值范圍分別是[1,5]與[5,10]。km使變異調節系數,取值為[1,5],γ的取值在[0.1,0.5]之間,σ∈[1,10]。
3.1.4 并行變異處理
經過上述變異概率自適應調整后在規定取值范圍內形成一個隨機數,以此替換初始數據。但此數據存在一定隨機性,得到的結果對收斂精度改善并不顯著,無法有效提高局部尋優能力。因此提出并行機理對變異操作進一步優化。
假設將對第t代任意個體x進行變異處理,則
x1=r(xmax-xmin)+xmin
(6)

(7)
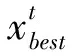

如果連續多代個體平均適應度差值低于設定的閾值時,則認為此種群已經沒有繼續計劃的趨勢,可終止算法,并選擇適應度最大的個體做并行解碼操作[9],此時即可獲得軟件安全性要求的最佳屬性結合,可將其當作下一步測試模型的輸入。
3.2 軟件安全性測試模型構建
在利用改進的遺傳方法進行軟件安全性度量性選擇后,構建安全測試模型。
當網絡環境為開放性時,利用一個四叉樹模型代表軟件的分布特性,通過三元組SC=(Ex′,En′,He′)代表軟件屬性數值特性。設定集合O為在n′維論域μ中的軟件指標參量,因此O的四叉樹可表示為

(8)
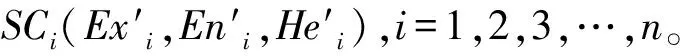

(9)

(10)

(11)
式中a為常數。
經過以上設計,完成軟件安全測試模型的構建,利用該模型能夠測試出軟件安全狀況。
4 實驗結果與分析
為證明本文提出的軟件安全性測試方法性能,從三個不同軟件中挑選1000個樣本當作仿真目標,其中可疑樣本數量為300,訓練數量為700,本文確定的安全性度量屬性如表2所示。

表2 安全性度量屬性表
利用改進的遺傳方法獲得種群多樣性與鄰近代迭代種群多樣性變換曲線分別如圖2與圖3所示。

圖2 種群多樣性

圖3 鄰近代種群間相似度
從圖2與圖3中可以看出,隨著迭代次數的不斷增加,種群多樣性趨勢下降,但是相鄰迭代種群之間相似度不斷提升,證明本文方法選取的安全性度量屬性較為合理。
將交叉與遺傳概率分別設置為0.8與0.3,初始迭代次數為60,最大迭代次數為600,在此環境下,利用本文方法、文獻[1]方法、文獻[2]方法測試軟件可疑點數量,并對測試錯誤率進行對比。
由表3可知,在相同網絡環境下,所提方法可發現更多軟件存在的可疑點。這是因為所提方法全面分析軟件異常特征,因此在測試過程中綜合考慮各種異常狀況,提高脆弱點發現幾率。

表3 不同方法可疑點測試結果對比表

圖4 不同方法軟件可疑點測試錯誤率
從圖4可以看出,在所有可疑點測試結果中,本文方法測試的錯誤率最低。這是因為所提方法在遺傳算法中引入并行機理,獲取安全性要求的最佳屬性結合,提高了算法變異能力,避免陷入局部最優,大幅度提升了測試的精準度。
5 結論
本文改進遺傳算法,利用并行變異處理,提高局部尋優能力,更全面發現軟件可疑點,提高測試精度,將軟件安全問題造成的損失降到最低。
猜你喜歡
現代儀器與醫療(2022年2期)2022-08-11 09:51:40
建材發展導向(2021年14期)2021-08-23 00:57:04
建材發展導向(2021年23期)2021-03-08 01:05:44
中華養生保健(2020年5期)2020-11-16 01:44:32
兒童故事畫報(2019年5期)2019-05-26 14:26:14
信息安全與通信保密(2016年3期)2016-08-23 01:23:46
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
