基于改進遺傳算法的回歸測試用例優先級排序
2021-11-17 04:31:50劉音
計算機仿真 2021年2期
劉 音
(北京交通大學海濱學院,河北 黃驊 061199)
1 引言
各種程序系統飛速發展,而其中的回歸測試是修改舊代碼后,重新測試以確保修改沒有引入新的錯誤或者是致使其它代碼出現錯誤[1]。此過程是軟件生命周期內的一個重要組成部分,在整個軟件的測試過程內,占有比較大的工作量比重,在進行軟件開發的各個階段都要完成多次回歸測試。在以快速迭代的開發之中,新版本的連續發布致使回歸測試非常頻繁,在終端的編程方法內,更是要求每天都采用若干次的回歸測試[2]。所以,為了在給定的進度以及預算下,最大程度上執行效率和有效的回歸測試,要利用測試用例進行維護,且選擇一定策略對應回歸測試包[3]。但是,現階段傳統方法在進行回歸測試用例優先級排序時,測試效果較差,且執行效率低,不能夠滿足實際要求,所以該項技術一直是國內外研究學者的重要挑戰。
為此本文提出一種基于改進遺傳算法的回歸測試用例優先級排序方法,該方法是在傳統的遺傳算法上引入禁忌算法,通過禁忌方法的記憶能力強優點,在可控范圍內擇優選取,淘汰劣質個體,同時基于改進遺傳算法具有較強的搜索能力,能夠有效甄別優質活劣質個體,然后將擇優選取的個體代替劣質個體。在回歸測試用例優先級排序中,考慮時間和測試成本因素,通常將多元化目標函數運用到用例優先的排序結果評價中,通過時間以及覆蓋的角度進行考察,利用有效執行時間以及平均分支覆蓋率兩個目標來函數評價,該方法執行時間短,平均分支的覆蓋率大,所以該序列優良。
2 改進遺傳算法分析
2.1 遺傳算法原理
通過自然選擇與遺傳理論作為基本條件,結合群體中染色體任意信息交換機制和生物進化過程內適者生存規則,誕生的搜索方法[4]。
算法具體過程如圖1所示。

圖1 遺傳方法流程圖
2.2 改進的遺傳方法
在該方法內交配是隨機的,不過該隨機化雜交方法主要是在初始階段的尋優方面,需要保持多樣化狀態,但是在后期的進化方面,大量的個體集中在某一極點上,很容易導致近親繁衍,致使個體的差異性出現類似的情況,通常獲取最佳的局部解所產生的測試用例不能夠達到滿意的覆蓋率。
所以,若使用其它方法來對該情況完成改進。因此本文加入禁忌搜索,利用該方法的較強記憶能力,在規定范圍內用優質個體替代劣質個體,完成個體最優轉化。遺傳方法就有了禁忌方法局部的超強搜索能力,增強了生成最佳解的概率,具體流程如下所示[5]:
步驟一:初始化的參數;種群Pop、禁忌表的長度L、種群大小PopSize。
步驟二:選擇操作種群內的個體。
步驟三:利用自適應的變異和自適應交叉來操作種群內的個體。
步驟四:大范圍轉移VB已經淘汰的個體,且利用生成的新個體來替代被淘汰的個體。
步驟五:生成新一代種群,然后轉移到步驟二中。
2.3 禁忌搜索的模塊設計
兩個個體之間的相似度利用S代表,具體公式如下

(1)
式(1)中,ai表示禁忌搜索中最優點值,aj表示禁忌搜索中參考值。以任意一點當成中心球體,然后以球體內非中心點的任意一點稱其鄰居[6]。
將禁忌搜索方法加入遺傳方法內,使那些利用禁忌檢測的個體,被稱之為新個體進行接收,同時導致那些有效的基因缺失,不過適應度低于父代個體,就會被禁忌掉。此外,導致那些有效的基因、不過適應度低的個體,具有更多機會參加變異與交叉,以此來避免或者是延緩收斂的情況,
1)選擇方式與鄰域解集合的大小,對算法的參數性能有很大的影響,目前解領域內將會做最佳選擇,如果選擇過大,那么計算量也比較大,反之,如果選擇過少,那么出現優質解概率,則會變小。因此生成領域的方式,主要是以目前解x來作為中心,然后在利用R來作為半徑,生成鄰域,具體公式為:
Φ={xx′-x≤R}
(2)
式(2)中:x′代表目前解x任意產生的離散化鄰域解。
2)在進行遺傳方法的進化過程內,每代完成變異或者較差以后[8],將低于γ的水平個體進行淘汰,把這些淘汰個體設置成ai{ai,a2,…,an},采用禁忌搜索方法完成替代搜索,然后在其鄰域附近搜素,其步驟如下所示:
步驟一:對一個解Φnow=ai以及禁忌表進行數據預處理。
步驟二:在β內選擇最優的個體Best,且f(Best)>(fΦnow)同時S>ε時,Φnow=Best,Best加入禁忌表L,反之,如果Best?L,Φnow=Best,要修改禁忌表L。
步驟三:如果滿足條件,則終止搜索,反之,需要轉移至步驟二中。
2.4 遺傳模塊設計
具體的改進遺傳方法3個基本算子,加入精英保留形式,改進算子具體方法如下所示[9]:
1)算子選取
對適者生存規則進行選擇操作,保證種群內個體的分布。采用每一個個體的適應值對群體內最差的個體適應度值相減,將此值作為選擇個體的標準。
該方法要優于傳統輪盤賭的方式,致使最佳個體被選擇之后,顯著增加變異和交叉的概率,這樣最差的個體,會失去遺傳機會,以及整體的收斂速度也會快速增加,具體的概率計算選取方式如下
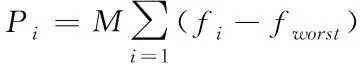
(3)
式(3)中:fi代表被選擇的個體適應度,fworst代表最差個體的適應度。
2)交叉與變異
遺傳算法交叉率以及變異率是固定不變的,主要是作為隨機性的搜索,存在特定的盲目性,很有可能導致存在比較高的適應度個體遭到損壞,因此,需要對損壞的個體進行修復,利用自適應算子,調整個體動態,檢查變異的交叉概率是否有效,將以存在的缺陷克服。此具有指導性的進化,存在全局最優解與效率以及更好的魯棒性,具體的交叉率Pc、變異率Pm,公式如下所示

(4)
式(4)中:fmax代表群體內的最大適應度,favg代表所有群體的平均適應度,f′代表需要交叉的個體內較大適應度,fc1代表需要變異個體適應度值。
3)保存精英方式
把種群內最佳個體,復制到下一代的種群內,成為下一代種群的新個體[10]。
3 回歸測試用例優先級排序
3.1 回歸多目標測試用例優先排序模型構建
在進行回歸多目標測試用例優先排序過程內,時間和測試成本的存在,通常利用多元素目標函數,測試用例有先的排序結果好壞進行評價,在測試用例優先的排序問題內,其通常狀況中,在評價指標眾多的情況下,要求能達到單一目標的最優解是很困難的,這就要求求解問題的非支配解,具體兩個優化目標的非主導解,回歸多目標測試用例優先排序模型構建具體如下所示:
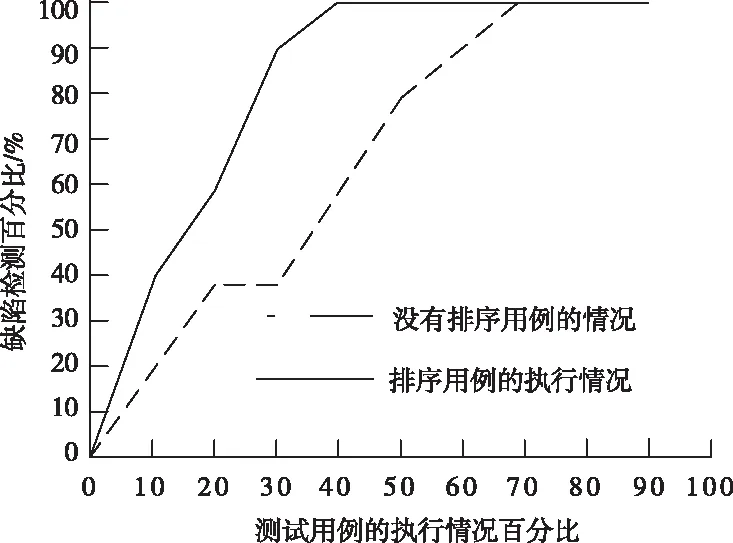
1)如果測試用例的優先排序是排列目標函數f1、f2以上的值都越大越好,則在f1(T1)>f1(T2)且f2(T2)>f2(T1)時,亦或者f1(T1) 2)決定一個測試用例集合中所有測試用例的編號組成了一個全排列,然后在這個測試的用例序列中,用例的上位部分,主要是根據這個全排列形成上面的第一個測試用例段。在測試用例結束時,將所有的測試用例按順序組成測試用例段,使其達到最大適應值。 不同測試情況用例覆蓋不同語句的情況測試用例的序列A-B-C-D相應APSC值如圖2所示: 圖2 測試用例的序列A-B-C-D相應APSC值 圖2是測試用例A、B、C、D對于程序內的APSC值對應情況,測試用例A、B、C、D是在執行期間以A-B-C-D為執行順序的,隨著測試用例逐個執行,它所覆蓋的語句的數目也在不斷增加,測試使用例C執行結束后,語句的覆蓋率可能會達到100%,當測試用例D執行的時,語句的覆蓋量不會在增加了,在這種情況下,測試用例A、B、C按順序形成的有序測試用例,稱為上位測試用例段,由此完成回歸多目標測試用例優先排序模型構建。 從時間和覆蓋角度出發,將有效執行時間和平均分支覆蓋率這兩個指標作為評價函數,主要用于衡量一個測試用例的優先次序好壞,用C表示平均分支的覆蓋率,具體一個測試用例的優先排序序列平均分支覆蓋率公式如下所示 (5) 上式(5)中:n代表測試用例個數,m代表被測程序內的分支個數,cm表示首要覆蓋程序中的第i個分支測試用例在該測試用例優先順序,有效時間利用T代表,一個測試用例的優先排序序列有效執行時間,利用以下公式表示 T=t1+t2+t3+…+tn (6) 式(6)中:tn表示執行測試用例的優先次序中的第i個測試用例所花的時間,由此證明這個序列具有一定層次,其原因是一個測試用例序的優先順序C越大,T順序越小[12]。 為證明本文方法的有效性,首先選擇某一個文件的傳輸軟件Ti(i=1,2,3,4,5,6,7,8,9,10)來進行分析和實驗,該軟件的要求,需要設計10個測試用例Fi(i=1,2,3,4,5,6,7,8,9,10)。在進行第一次測試發現,該軟件內的測試用例檢測錯誤如表1所示。 表1 測試用例的檢測軟件錯誤狀況 表1中的CT是代表用例的執行時間。 該軟件的錯誤級別以及類型量化值如表2所示。 表2 軟件內錯誤等級以及類型的量化值 表2中,fd代表錯誤等級所相應的量化值,fs代表錯誤類型所對應的量化值。 通過以上表1和表2內的錯誤類型以及等級的量化值。在進行回歸測試的時,第一次測試所執行的是沒有排序測試的用例,而第二次是通過本文方法進行排序測試用例之后在執行的,利用算法TRG,獲得回歸測試用例的優先排序集{T5,T9,T8,T4,T6,T2,T1,T10,T3},沒有排序測試的例集APFD如圖3所示。 圖3 沒有排序測試的用例序列APFD 排序之后的測試用例集APFD,如圖4所示。 圖4 排序之后的測試用例序列的APFD 測試用例沒有排序與排序之后的錯誤檢測,如圖5所示。 圖5 測試用例沒有排序與排序后的錯誤檢測情況圖像 通過以上實驗分析能夠看出: 1)沒有排序的測試用例集APFD數值是0.68,而排序之后的測試用例集APFD數值是0.84。其排序之后的測試用例值大于沒有排列測試用例的值,以此可以說明,排序之后的測試用例錯誤檢測速度要遠快于沒有排序測試的用例檢測錯誤速度。 2)通過以上測試用例的沒有排序與排序之后的錯誤檢測圖像能夠看出,排序之后的回歸測試用例在執行40%用例時,就能夠檢測出軟件內所有所有錯誤。而沒有排序回歸的測試用例,在執行70%用例才達到相同測試效果。 以此可以證明,本文方法具有很好的測試有效性,且測試效率較高。 1)對于一個軟件開發項目來說,項目的測試組在進行測試過程內,會把開發的測試用例保存至測試用例庫內,且對其進行維護與管理。采用正確的回歸測試來對回歸測試效率以及有效性進行選擇,回歸測試要用到人力、經費以及時間來進行管理、實施與計劃。 2)本文方法在傳統的遺傳算法上,加入的禁忌算法進行改進,使其具有禁忌方法的局部超強搜索能力優點。 3)在利用多個目標函數對回歸測試用例優先級排序評價,經過時間以及覆蓋的角度考察,執行時間較短,平均分支較大,說明該序列優良。 4)本文方法的測試效果較好,執行效率高。
3.2 多目標回歸測試用例的優先排序評價標準
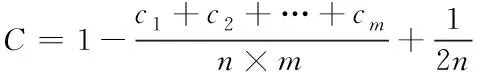
4 實驗分析




5 結束語
猜你喜歡
兒童時代·幸福寶寶(2022年12期)2022-12-09 11:24:14
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
兒童故事畫報(2019年5期)2019-05-26 14:26:14
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
