基于DP-SAMQ行為樹的智能體決策模型研究
2021-11-17 07:11:06陳妙云丁治強
計算機仿真 2021年2期
陳妙云,王 雷,丁治強
(中國科學技術大學信息科技學院,安徽 合肥 230031)
1 引言
多智能體仿真是當前仿真的主流研究方法,應用在軍事,交通,社會安全娛樂游戲等廣泛領域[1]。在多智能體仿真的過程中,智能體需要對不同場景下的不同事件進行決策,能否合理決策是判斷仿真成功與否的重要依據。基于有限狀態機的決策模型具有決策過程較為僵化的缺點[2],而模糊狀態機[3]的優點在于隨機性較好,但是其場景適應性差。行為樹決策模型是當前智能體研究中重要的行為模型,廣泛應用于仿真領域[4]。其優點在于提供了豐富的流程控制方法,可以更加直觀的看到狀態的改變,還具有擴展性好,易于編輯的特點。但目前基于行為樹決策模型的多智能體仿真研究還有如下不足:
● 行為樹的設計需要對不同的狀態進行判斷[5],涉及到大量的條件節點。當人物的行為邏輯較為復雜時,行為樹會非常龐大,需要進行大量的調試工作,極大的加大了開發難度;
● 需要對單個物體或人物的行為樹進行設計,大大降低了開發效率;
● 不合理的行為樹設計會導致仿真時出現異常。
本文通過引入Q-Learning算法來解決行為樹的上述不足。Q-Learning具有優秀的自學習和自適應能力[6],可以用于實現行為樹的自動化設計。但是傳統的ε貪心Q-learning[7]為了避免陷入局部最優的陷阱,需要對次優的動作進行探索,隨著智能體學習經驗的不斷增加會產生大量的無效計算,存在難以收斂的問題。
基于以上問題,本文提出了一種新的人群仿真多智能體決策模型,該模型對傳統的ε貪心Q-learning算法進行了改進,并引入了行為樹,使得模型能夠對行為樹節點進行自動重排,實現自動化調試。
2 多步Q-Learning
傳統ε貪心Q-Learning算法[8]是一種單步時序差分算法,在估計狀態動作價值時只考慮下一步的信息,而忽略了未來決策對當前的影響,因此具有低預見性的缺點。Q(λ)學習算法[9]是一種新的強化學習算法,它在估計狀態動作價值時考慮了將來的所有狀態獎勵,極大的提高了算法的預見能力。但當狀態-動作空間規模較大時,該算法的計算復雜度過高。基于該缺點,Nachum[10]提出了一種多步Q-Learning算法,它在更新Q值時考慮了將來n步的信息,極大的降低了算法的計算復雜度,加快收斂;同時又增強了智能體的預見能力,使其決策更加合理。
其算法描述如算法1所示:

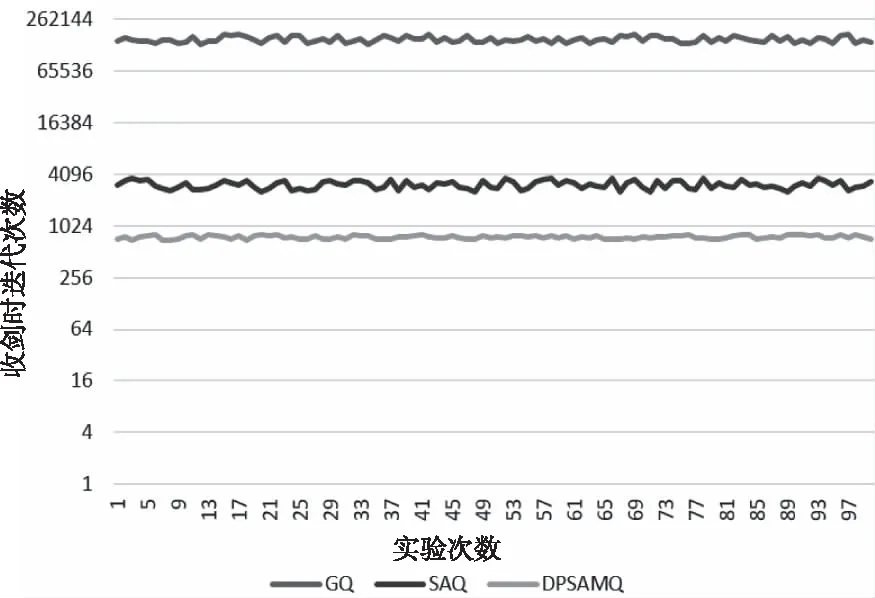
輸入:初始 Q表,S[m],A[m],E[m],E'[m]輸出:收斂的Q值表For each episodet=1, 初始化 siFor each step of episode采取動作at, 得到收益rt,st→st+1;et'=rt+γ·Vt(st+1)-Qt(st,at)et=rt+γ·Vt(st+1)-Vt(st)Update Array S,A,E,E' if(t 在算法1中,輸入數組的長度用m來表示,m個步驟的狀態、動作、e和e′ 分別用數組S[m],A[m],E[m]和E′[m]來存儲。當t 多步Q-Learning算法的動作選擇是基于ε貪心策略,會有一定的概率選擇非最優動作,而這概率保持不變會使得在算法學習后期產生許多無效的計算,導致算法收斂速度變慢,性能下降。 除此之外,其值函數更新策略也會降低算法的收斂速度。當采取動作從環境中得到收益之后,算法只是對當前狀態-動作對的Q值進行更新。在學習過程中,該狀態動作對會重復進行更新。 針對當前多步Q-learning難以收斂的問題,本文使用模擬退火算法中的Metropolis準則改進了多步Q-learning算法的動作選擇策略,使用動態規劃改進了值函數的更新策略,提出了一種改進的多步Q-learning算法。 在傳統的Q-Learning算法中使用ε貪心策略進行動作選擇,會以ε的概率選擇次優動作。但是當智能體學習到足夠多的經驗后,ε的值仍然不發生改變,導致產生許多無效的計算,降低算法的收斂速度。 基于以上分析,本算法改進了ε貪心動作選擇策略,隨著學習過程的不斷迭代,ε值會逐漸降低。在學習初期,智能體經驗不足,因此選擇較大的ε值對環境進行探索。隨著智能體的經驗不斷增加,ε值逐漸減小,智能體更趨于利用而非探索。而模擬退火算法[14]通過降溫策略來改變轉移概率,可以逐漸降低選擇次優動作的概率。因此本文將Metropolis準則應用到動作選擇策略中。 Peng[15]將Metropolis準則應用到傳統的單步Q-Learning算法中,有效的平衡了探索和利用的問題。 本文采用模擬退火動作算法來改進多步Q-learning算法中的動作選擇策略,動作選擇概率如式(3)所示: p(ap→ar)= (3) 式中,ar和ap分別表示隨機選擇策略和貪婪選擇策略對應的動作,當Q(s,ar)≤Q(s,ap)時,選擇ar動作進行探索,通過探索非最優動作提升算法的性能,當Q(s,ar)>Q(s,ap)時,以exp[(Q(s,ap)-Q(s,ar))/T]的概率探索非最優動作,T是溫度控制參數,即T值較大時,探索的概率會比較大,當T值趨向于0時,不在探索非最優動作。T值的選取借鑒了模擬退火算法中的溫度降溫策略,其公式如(4)所示 T(N)=T0exp(-AN1/M) (4) T0,N,A,M分別表示初始的溫度,算法迭代的次數,指定的常數和待反演參數的個數。上式也可表示為: T(N)=T0aN1/M (5) 其中α∈(0.7,1),1/M通常取為1或0.5。在算法的起始階段,T一般取較大的值,依據式(3)可得p(ap=ar)較大,此時選擇隨機動作的概率較大。隨著不斷迭代,依據式(4)T值會逐漸降低,即會進行降溫處理,使得p(ap=ar)變小,則選擇非最優動作的概率變小,有利于在Q-Learning算法的后期更傾向于選擇最優動作,隨著迭代的進行,模型不斷逼近收斂狀態,T值也逐漸接近0。此時模型的動作選擇策略退化為貪心策略,即不再進行探索,每次動作選擇只選最優動作。通過上述分析可以看到,使用模擬退火動作選擇策略可以較好的實現ε值的自適應變化,加速了Q-Learning算法的收斂。 基于Metropolis準則的動作選擇策略流程圖如圖1所示。 圖1 基于Metropolis準則的動作選擇流程 在多步Q-Learning算法的學習過程中,智能體根據自身狀態以及動作選擇策略選擇動作,并加以執行,從環境中得到收益。但是每一步只能在Q值表中更新當前狀態-動作對的Q值。當Q值表沒有收斂到最優時,每個狀態下同一個動作會反復執行,這也造成了多步Q-learning算法的難以收斂。Shilova[16]等提出了逆序的思想對傳統的單步Q-learning算法進行了改進,可以加快收斂。原因在于對學習到的狀態動作對進行逆序更新避免了相同狀態動作對的重復執行。智能體根據自身狀態選擇動作加以執行并從環境中得到收益,更新Q值。動態規劃也是基于逆序的思想,本文中用動態規劃來對Q值進行更新。 本文算法使用鄰接鏈表來存儲到達不同狀態前的狀態動作對,以達到降低時間復雜度的效果。當智能體采取動作進入到下一狀態后,鄰接鏈表進行相應的更新,比如智能體經過(s1,a1), (s2,a2)之后到達狀態s3,那么此時在鄰接鏈表中s3對應的就是{(s1,a1), (s2,a2)}。同時對鄰接鏈表的狀態進行逆序更新。更新步驟如圖2所示。智能體根據當前狀態選擇動作并執行從環境中得到獎勵后,根據Q值更新公式更新當前狀態動作對的Q值,判斷當前狀態動作對的Q值是否為該狀態下所有動作的最大Q值,如果是,就對鄰接表中當前狀態下的狀態動作集的Q值進行逆序更新。 圖2 動態規劃逆序更新Q值 本算法將Metropolis準則和動態規劃分別應用到動作選擇策略和值更新策略中,提出了改進的多步Q-Learning算法。本算法在每一episode的開始時初始化參數和Q值表,建立鄰接鏈表。在每一step中,智能體根據當前狀態 st和基于Metropolis準則的動作選擇策略選擇動作at并且執行,從環境中得到相應的獎勵r,轉移到st+1狀態,然后根據基于動態規劃思想的值更新策略對Q值表以及鄰接鏈表進行更新。當到達終止狀態時結束當前episode的學習。重新開始下一episode的學習。 本算法流程如圖3所示。 圖3 改進的多步Q-Learning算法 其中存儲狀態,動作,e和e′的四個數組分別是S[k],A[k],E[k]和E′[k] 本系統模型描述如下: Step1:初始化行為樹,動作空間,狀態空間,狀態轉移表,獎勵表和Q值表。 Step2:應用上述介紹的改進的多步Q-learning算法學習得到最終收斂的Q值表。然后根據不同的動作將收斂的Q值表劃分成不同的狀態允許子表,如圖4所示。 Step3:將得到的不同動作的狀態允許子表替換行為樹的條件節點,并輸出不同動作下獲得的最大Q值; Step4:根據不同動作節點得到的最大Q值對行為樹進行重排; Step5:輸出重排后的Q-learning行為樹。 步驟1是初始化行為樹,其中動作節點代表智能體可以采取的動作,條件節點對智能體所處狀態進行判斷。狀態空間,動作空間,狀態轉移表和獎勵表都是人為給定的。 系統輸入是一棵普通的行為樹,輸出是自動重排后的Q-Learning行為樹。該系統首先應用上述介紹的改進的多步Q-learning算法得到最終收斂的Q值表。然后對初始行為樹進行dfs搜索找到所有的動作集合,根據動作集合的動作將Q值表分割成不同的狀態Q值集合,并將其替換掉行為樹中的條件節點,并將最大的Q值填入動作節點對應的順序節點中。從而行為樹在選擇動作的時候就不需要進行復雜的條件判斷,只需判斷當前狀態是否存在動作節點對應的狀態允許列表中即可,如果存在,就采取該動作。改造的Q-Learning行為樹如圖4所示。得到了含有Q值和狀態允許列表的行為樹后,根據動作節點對應的狀態集合中的最大Q值對行為樹進行重排序,得到的行為樹即為系統輸出。 以下內容將對step2,3,4分別進行具體描述。 應用本文提出的改進的多步Q-learning算法學習到收斂的Q值表之后,根據不同的動作將得到的Q值表分割成狀態-Q值集合,對每一個集合中的狀態根據Q值從大到小排序,根據實驗情況保留一定比例的高Q值狀態,命名為狀態允許列表,用得到的不同動作對應的狀態允許列表替換行為樹中的條件節點,如圖4所示。 圖4 將Q值信息整合到行為樹 狀態允許列表中去掉Q值小于0的狀態,并保留一定比例的高Q值狀態。 算法2是選取最大Q值的偽代碼: 輸入:動作集合A,狀態集合S,Q值表輸出:輸出動作-最大Q值for each a in Afor each s in Sq=Q.getQ(s,a)if q > 0 act_states[a].insert(s)sort(act_states[a]) in reverse orderact_states.remove[size*(1-x):]res[a]=act_states[0] 得到含有Q值的行為樹后,根據Q值大小對行為樹進行重排序。Q行為樹中節點的Q值自上而下自左而右依次減小,如算法3所示。 算法3是行為樹重排的偽代碼 輸入:初始Q-tree輸出:已重排Q-treefor each node in bottom layerif node.value > fa_node.value swap(node, fa_node) down(node)sort(node.childs) 圖5為具體的重排過程。行為樹對應節點的Q值從上往下,從左往右依次減少。重排后得到決策更加合理的行為樹 圖5 根據Q 值重排行為樹 本文將改進的多步Q-Learning算法命名為DP-SAMQ(Dynamic Programming Simulated Annealing Multi-step Q-learning)算法。本文的實驗環境基于手動搭建的人群仿真場景,場景中部署了一定的監控設備。 在Unity 3D中仿照真實人物構造了相應的3d模型,并導入相應的運動動畫,使其顯示更加逼真。 實驗的場景基于城市中的一座廣場,其中重要人物正在視察,安保人員的任務是保護重要人物的安全,嫌疑人的任務是找到攻擊重要人物。 本實驗選擇基于模擬退火的單步Q-Learning算法(SAMQ)以及采用ε貪心策略的(GQ)算法與本文的DP-SAMQ算法進行對比實驗。實驗中的參數設置如下:折扣因子γ設置為0.9,權重參數λ設置為0.85,學習率α設置為0.4,初始溫度T0設置為500。 Q-Learning算法涉及智能體的狀態,動作,狀態轉移,獎勵,之后Q-Learning算法才能開始具體的學習。所以接下來將詳細介紹嫌疑人和安保人員的狀態空間,動作空間,狀態轉移和獎勵的設計。 5.1.1 狀態空間 安保人員的狀態空間:(生命值lv,與嫌疑人距離dis_em, 與同伴距離dis_pt, 是否被攻擊hited) 生命值lv(0-1000):高(500-1000),中 (200-500),低(0-200),死亡(0); 是否被攻擊(hited):T/F; 與嫌疑人距離(dis_em):近(0-50),中 (50-100),遠(>100); 與同伴距離(dis_pt):近(0-50),中(50-100),遠(>100); 為了避免維數災難,對距離和健康值進行了離散化,模糊化處理。 危險分子的狀態空間: (生命值lv,發現重要人物fl, 被安保人員發現fd,發現安保人員fp,與安保人員距離dis_pl)。 生命值lv(0-1000):高(500-1000),中 (200-500),低(0-200),死亡(0); 發現重要人物(fl): T/F; 是否被安保人員發現(fd): T/F; 發現安保人員(fp): T/F; 與安保人員距離(dis_pl):近(0-50),中(50-100),遠(>100); 5.1.2 行為空間 安保人員的行為空間:(追擊/pa,逃跑/ma,巡視/sa,尋找伙伴/fc,尋找嫌疑人/fe)。 危險分子的行為空間:(自首/sr,逃跑/ma,攻擊重要人物/al,尋找重要人物/fl,攻擊安保人員/ap) 5.1.3 動作選擇策略 采用如上介紹的基于Metropolis準則的動作選擇策略。 5.1.4 獎勵表 表1 安保人員的獎勵表 表2 危險分子的獎勵表 除表1中給出的狀態-動作對有獎勵值之外,其它狀態-動作對獎勵值均設置為0。 5.1.5 行為樹 圖6 安保人員初始行為樹 圖7 嫌疑人初始行為樹 圖8 基于DP-SAMQ的行為樹模型得到的安保人員的行為樹 圖9 基于DP-SAMQ的行為樹模型得到的嫌疑人行為樹 本實驗中安保人員和嫌疑人的行為樹設計如上。重排后行為樹由多棵子樹組成,從上到下從左到右Q值逐漸降低,輸入狀態,輸出具有最大Q值的動作。嫌疑人初始行為樹中存在的不合理地方在于當危險分子的健康值小于200且與安保人員的距離大于100時,應該優先逃跑而不是繼續攻擊安保人員。經過DP-SAMQ算法重排后的嫌疑人行為樹則有較好的表現。 接下來的實驗需要找到改進后多步Q-learning的最優n值。本文接下來的實驗分成兩組。第一組是測試不同n值下算法的收斂速度,找到最佳n值,第二組驗證應用了本文算法的行為樹的合理性。 從算法1中可以看出該算法的時間復雜度為O(Episode_num*step_num)。 n值決定了智能體的預見能力,n值越大,預見能力越高,但是計算復雜度同時也加大,n值越小,雖然計算復雜度降低,但是預見能力也越低。因此需要權衡n的取值。 實驗過程中采取了不同的n值進行實驗,分別取了n=10,20,..,100,在實驗中發現當n>20的時候,算法的收斂速度明顯下降,因此本文只給出n為10,20時算法的收斂曲線。每次實驗運行1000個Episode。橫坐標為episode_num/40,縱坐標為40個episode的steps_num的平均值。 圖10 不同n值下DP-SAMQ算法的收斂曲線 從圖中可以看出,當n=10的時候,算法收斂速度更快,最終steps_num收斂為17,而n=20時,steps_num最終收斂為28。因此n值最終取10。 下圖是GQ/SAQ與本文算法(DPSAMQ)的對比效果圖,縱坐標為log(steps_num),表示最終算法收斂時的步驟數。橫坐標為實驗的次數,總共是100次實驗。 圖11 GQ/SAQ/DPSAMQ對比實驗 從圖中可看出本文DP-SAMQ算法收斂所需迭代次數相較GQ和SAQ算法有非常明顯的下降,算法性能顯著提高。 從圖12/13的對比可看出,基于本文算法(DP-SAMQ)訓練出來的嫌疑人在面臨安保人員攻擊時更傾向于逃跑,這是符合嫌疑人的行為邏輯的。而且行為樹在選擇動作時是基于dfs算法搜索的,從上到下從左到右的動作優先級逐漸降低,因此當嫌疑人被安保人員發現時優先選擇逃跑而不是主動攻擊。 初始行為樹仿真結果如圖12所示。 圖12 初始行為樹仿真結果 可以發現實驗中嫌疑人被安保人員發現時選擇進一步接近并攻擊安保人員。 基于DP-SAMQ算法學習得到的行為樹仿真結果如圖13所示。 圖13 基于DP-SAMQ的行為樹模型仿真結果 從圖中可看出,當嫌疑人被安保人員發現時,優先選擇逃跑。從以上對比實驗可看出,基于DP-SAMQ訓練得到的行為樹決策模型更加合理,證明了該算法的合理性 針對目前傳統的單步Q-learning算法預見性低,難以收斂以及Q(λ)算法計算復雜度過大等缺點,本文引入了模擬退火算法中Metropolis準則對多步Q-learning算法中的動作選擇策略進行改進,使得算法能夠隨著學習過程自適應改變次優動作的選擇概率。并且本文還引入了動態規劃來改進了Q值函數的更新策略,極大地加快了算法的收斂;并且本文還針對目前基于行為樹的智能體決策模型存在人工開發效率低的缺點,將改進的多步Q-leaning算法應用到行為樹決策模型中,實現了行為樹的自動化設計和優化;通過實驗也證明了本文算法(DP-SAMQ)的合理性與有效性。但是本文實驗仍是基于單智能體,現實生活中更多是多智能體場景,因此在進一步的工作中會考慮引入多智能體。3 改進的多步Q-Learning算法設計
3.1 動作選擇策略的設計


3.2 值函數更新策略

3.3 改進的多步Q-Learning算法

4 人群仿真系統設計與實現
4.1 模型概述
4.2 行為樹改造

4.3 選取最大Q值

4.4 行為樹拓撲重排序


5 實驗設計與仿真分析
5.1 實驗設計






5.2 n值的確定

5.3 實驗一
5.4 實驗二


6 結語
猜你喜歡
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10文苑(2018年23期)2018-12-14 01:06:06文苑(2018年19期)2018-11-09 01:30:14文苑(2018年17期)2018-11-09 01:29:26文苑(2018年21期)2018-11-09 01:22:32小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35數學大世界(2018年1期)2018-04-12 05:39:14少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
