基于多粒度信息的中醫(yī)文本關系抽取的研究
2021-11-08 13:12:09王亞文王培盧苗苗
電腦知識與技術 2021年27期
關鍵詞:深度學習
王亞文 王培 盧苗苗
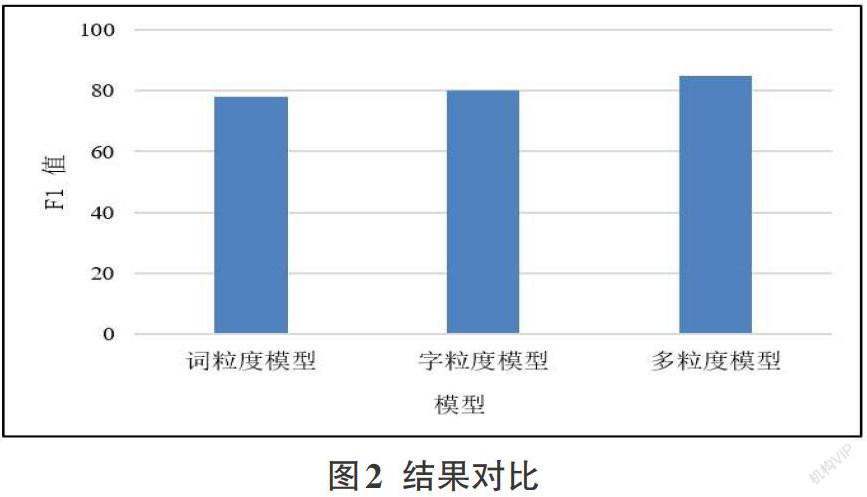
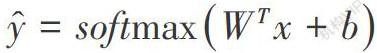

摘要:中醫(yī)領域知識主要是以文本的形式存在,具有無規(guī)律的語言特性,中醫(yī)知識的有效挖掘對充分利用文本中蘊藏的經驗知識具有重要作用,信息抽取任務是中醫(yī)知識管理的重要子任務,而關系抽取又是信息抽取任務中的重要環(huán)節(jié)。針對單粒度信息關系抽取方法中存在的句意傳遞錯誤和文本語義丟失的問題,提出將句子中的多粒度信息應用于中醫(yī)文本關系抽取任務,構建多粒度信息抽取模型,將詞語級信息整合到字符序列中,多種粒度的文本信息可以為模型提供更多的知識引導,更全面的挖掘語義特征。實驗結果證明,此方法能夠更加精確的抽取中醫(yī)文本關系,使模型具有更好的魯棒性,基本不受噪聲的影響。
關鍵詞:多粒度信息;關系抽取;深度學習;中醫(yī)文本
中圖分類號:TP3? ? ? ? 文獻標識碼:A
文章編號:1009-3044(2021)27-0015-02
1引言
中醫(yī)知識包含了中華民族千百年來在和疾病斗爭中總結的豐富診療經驗,在長期發(fā)展的過程中也形成了一種獨特的診療體系,留下了大量對現(xiàn)代疾病診斷具有重要指導價值的文獻資料。然而,中醫(yī)文本信息尚未得到有效利用,關系抽取[1]技術是有效利用中醫(yī)文本信息的關鍵技術之一,目的是提取中醫(yī)文本實體對之間的語義關系[2]。例如:“若兼有氣虛者,身倦乏力,少氣自汗宜加黃芪,并加以重用,以補氣行血”,這句中的“黃芪”和“氣虛”是“治療”的關系。
隨著深度學習[3]的不斷發(fā)展,以其自動提取特征的優(yōu)勢被更多地應用在關系抽取任務中[4]。目前大多數(shù)的關系抽取模型是基于字粒度或者基于詞粒度的單一粒度進行抽取。基于字符的關系抽取將每個輸入語句視為一個字符序列。這種方法不能充分利用詞語級信息,捕獲的句子特征較少,字符、語法和語義之間的關系較為松散,無法完整的表達出句子語義,比如“羌活”這個詞如果拆成字粒度就成了“羌”和“活”,這兩個字的單獨含義明顯與它們組合起來的詞的含義大相徑庭。所以利用字粒度信息捕獲的句子特征比較少,存在“文本語義丟失”的問題,完全依賴字符進行關系抽取效果不佳。基于詞粒度的關系抽取模型,首先要進行分詞,然后推導出單詞序列,再將每個詞語表示為詞向量,輸入到神經網(wǎng)絡模型中,利用詞粒度信息容易引入詞語分割錯誤帶來的“句意錯誤傳播”問題。例如給定中醫(yī)句子:“酒黃疸,心中懊或熱甚而痛,梔子大黃湯主之,蓋為實熱之邪立法也”。句中黃疸和大黃是治療關系,但是經過分詞操作之后“梔子大黃湯主之”被分為“梔子”“大”“黃湯”和“主之”,分完詞之后沒有得到“大黃”這個詞。
因此,基于單粒度信息的抽取方法會存在“文本語義丟失”和“句意傳遞錯誤”的問題。本文結合字符粒度信息與詞粒度信息的優(yōu)點,使用多粒度信息[5]對中醫(yī)文本進行特征學習,既利用了字粒度模型參數(shù)少和不依賴分詞算法的優(yōu)點,解決句意傳遞錯誤的問題,同時利用了詞語中包含的詞法、句法和語義等信息,捕獲更多的文本語義特征,解決文本語義丟失的問題。兩種粒度方法互為補充,提升了中醫(yī)文本關系抽取的效率。
2 多粒度關系抽取模型
對于基于字符級信息和詞語級信息訓練的模型存在文本實體分割錯誤問題,不能夠充分利用句子的語義特征,限制了模型挖掘深層語義特征的能力。本文利用多種文本粒度的,為模型提供更多的知識引導,從而獲取句子更充分地語義信息,模型具有更好的魯棒性,基本不受噪聲的影響。多粒度關系抽取模型是在基于字符的雙向長短期記憶網(wǎng)絡[6](Bidirectional long short-term memory network,Bi-LSTM)的結構基礎上增加了詞粒度信息流,利用門結構控制信息的嵌入。模型結構如圖1所示。
基于多粒度信息的中醫(yī)文本關系抽取模型分為四層,分別是嵌入層、編碼層、注意力層和分類層。
2.1嵌入層
由于神經網(wǎng)絡的輸入是數(shù)值類型數(shù)據(jù),所以在對文本編碼之前需要將中醫(yī)文本數(shù)據(jù)轉換為數(shù)值數(shù)據(jù)表示。本文的多粒度信息包括字粒度信息和詞粒度信息,同時利用位置信息,因此在嵌入層需要將字符、詞語和相對位置信息進行向量化表示。
(1)字詞嵌入
在通過神經網(wǎng)絡處理之前將預處理之后的中醫(yī)文本進行向量化表示,本文采用的是word2vec技術把文本中包含的字符和詞語分別映射成具有一定維度的實值向量,很好地表達了字和詞語的語義依賴關系。嵌入層中的[l]表示字符和[w]表示詞語分別映射為字向量[dl]和詞向量[dw]。
(2)位置嵌入
關系抽取是預測句子中兩個實體存在的關系,一般距離實體對越近的字隱含表達實體對的關系的貢獻越大。句子的每個字符都有兩個位置信息,分別代表與頭實體和尾實體的相對距離,例如給定中醫(yī)句子“若兼陽分氣虛,而脈微神困,懶言多汗者,必加人參”。此句子的頭實體是“脈微”,尾實體是“人參”,字“加”與頭實體的相對距離為10,與尾實體的相對距離是0。
2.2編碼層
本文使用基于網(wǎng)格結構的雙向長短時記憶網(wǎng)絡(Lattice BiLSTM)作為編碼器,該模型是基于字符的雙向長短期記憶神經網(wǎng)絡(BiLSTM),將字符作為直接輸入,即將每個輸入句子作為字符序列,不同點在于增加了詞粒度信息流,在字符輸入的同時嵌入詞語信息,利用句子中包含的多種粒度信息。模型編碼層中[x]表示編碼層的輸入,[h]表示正向隱藏層,[h]表示逆向隱藏層,[h]表示匯總隱藏層。隱藏層計算如下公式所示,[hci]表示第i個隱藏單元狀態(tài)。
2.3注意力層
在實際應用場景中,句子中有些字符對預測兩個實體關系具有更加重要的地位。例如給定中醫(yī)句子“黃疸腹?jié)M,小便不利而赤,自汗出,此為表和里實,當下之,宜大黃硝石湯”,在預測“黃疸”與“大黃”之間的關系時,字“宜”比其他字對關系預測的貢獻更大。為了使模型能夠獲得對關系抽取貢獻較大的特征,本文通過給句子中的每個字分配權重,增強句子的局部特征。
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現(xiàn)代商貿工業(yè)(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現(xiàn)代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
