一種基于成詞率和譜聚類的電力文本領域詞發現方法*
2021-11-04 03:48:28尹春林李慧斌
電子技術應用 2021年10期
楊 政 ,尹春林 ,蔡 迪 ,李慧斌
(1.云南電網有限責任公司電力科學研究院,云南 昆明 650217;2.西安交通大學 數學與統計學院,陜西 西安 710049)
0 引言
針對特定領域的文本數據,領域詞的詞庫構建是最為關鍵的任務之一。傳統領域詞發現方法依賴互信息或鄰接熵得到候選詞集,進而利用word2vec 進行詞向量轉化、K-means 進行聚類[1],最終得到行業領域詞。傳統方法對詞語組合規律運用得不夠全面,因此這類方法篩選的候選詞集存在諸多不合理的詞語。領域詞發現分為候選詞集篩選與字符串過濾兩個步驟。
在候選詞集篩選方面,領域詞發現算法主要是基于詞語統計特性的無監督方法或序列模式機器學習的有監督算法。基于無監督的方法中,互信息和凝固度是最常見的用來篩選詞語的度量,劉偉童等[2]提出使用互信息初步篩選詞集,隨后用鄰接熵對詞集進行再過濾的方法。劉昱彤等[3]使用改進的類Apriori 算法,通過組合、統計頻率、過濾3 個步驟來篩選候選詞集。杜麗萍等[4]提出利用改進的互信息,同時結合一定的構詞規則篩選候選詞集。無監督算法泛化性優良,但缺少規則,會遺留有較多垃圾串與非領域詞。基于監督的機器學習詞集篩選方法有馬建紅等[5]提出的基于CNN 和LSTM 抽取詞特征,隨后使用半馬爾科夫條件隨機場(SCRF)來識別詞語邊界。Fu Guohong 等[6]在隱馬爾可夫模型(HMM)的框架下運用命名實體識別(NER)的思路,同時結合上下文篩選出候選詞集。陳飛等[7]提出運用條件隨機場來判斷分詞的詞匯邊界是否為候選詞邊界的方法。監督方法通常需要大量標注數據進行訓練,耗費高額的人工成本。此外,部分方法選擇基于純規則的構詞法[8-9](即漢語成詞規則)與一些領域先驗知識結合,進行候選詞集的篩選。這種方式雖然準確性相對較高,但是規則維護復雜,基本無跨域能力。
在得到候選詞集之后還需對垃圾字符串與非領域詞進行過濾。趙志濱等[10]定義了詞語相似度計算的Words-Avg 方法,通過與閾值對比來判斷候選詞集里的詞是否為領域詞。王鑫等[11]在使用word2vec 訓練候選詞向量時加入了詞類信息,進而得到化學領域詞。吉久明等[12]運用改進的GloVe 詞向量模型提取詞語向量,隨后進行K-means 聚類,最終得到領域詞。
1 本文方法
圖1 展示了本文提出的方法,共分為5 個步驟:文本預處理、候選詞篩選、文本切片算法、常用詞過濾以及譜聚類[13]。
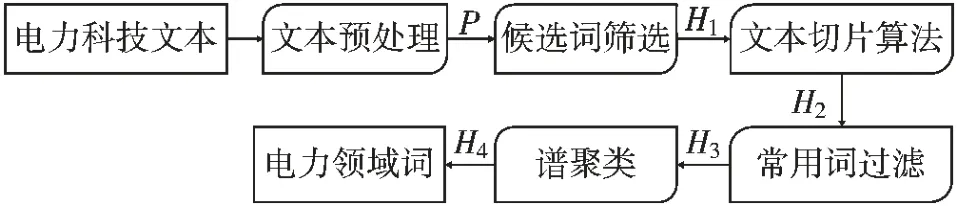
圖1 本文所提方法流程圖
1.1 文本預處理
在對文本進行候選詞集篩選前,需對電力科技文檔進行文本預處理,處理后得到文本記為P。具體處理步驟如下:
(1)篩選出電力科技文檔中目的和意義、項目研究內容與實施方案三部分,避免其他電力領域詞很少出現的部分干擾最終結果,同時提升算法運行效率;
(2)去除掉停用詞,即語氣助詞、副詞、介詞、連接詞(如“的”)以及標點符號。
1.2 候選詞篩選
在得到預處理后的文本P 后,本文提出了一種新的候選詞集篩選度量“成詞率(Suc)”,用以對文本P 中的詞語進行篩選,篩選后得到初步的詞集H1。其中設定最長詞語長度n 為4,候選詞篩選度量Suc 的閾值設定為0.62,成詞率由互信息(Mut)、左右熵(Adj)與構詞規律(Reg)構成。
(1)互信息(Mut):指一個隨機變量中包含的關于另一個隨機變量的信息量,即隨機變量間的聯系程度,包含的信息量越高,則變量間聯系程度越高,詞內凝固度越高,該字符串則越容易成詞。互信息Mut 的計算公式如式(1)~式(3)所示,分別表示2、3、4 字詞的互信息,其中,x、y、z 代表單個字符。

(2)左右熵(Adj):指候選詞的自由程度,左右熵表示詞語搭配的不確定性。左右熵越大,詞語搭配的不確定性越大,即候選的詞左右搭配越豐富,成詞概率越高,計算公式如式(4)、式(5)所示,Adjl、Adjr分別為左熵和右熵,w 為字符串,wr、wl為單前綴與單尾綴。

(3)構詞規律(Reg):通過對電力行業領域詞的觀察發現,絕大多數領域詞依然遵循構詞學基本原理[14]:名詞與名詞、動詞、形容詞結合非常頻繁,其他結合方式構成電力領域詞的比例約四分之一,本文定義了字符串結合成詞的構詞規律Reg,其中a、b 為搭配成詞的兩個字符串。

(4)成詞率(Suc):用來篩選候選詞集的度量,結合了上述3 個變量的優點。

其中,k1和k2將互信息與左右熵的值映射到相近的量級,k1取值為Mut 均值除以Adjl的均值,k2取值為Mut均值除以Adjr的均值;m 為歸一化常數。
1.3 文本切片算法
初步的詞集H1中仍有諸多未被篩選的電力領域詞,本文提出使用文本切片算法,算法步驟分為分詞和回溯,具體如下:
(1)分詞:在得到初步的詞集H1以后,本文選擇用H1對預處理后的文本P 進行切分,旨在得到更為合理的候選詞集。在對預處理后的文本P 進行分詞時,遵循的原則為“最準確切分原則”,例如:“各項目經理”這個字符串,很有可能“各項”、“項目”、“經理”、“項目經理”均在H1中,那么就選擇不對此字符串進行分詞,得到分詞后的候選詞集定義為H2。
(2)回溯:檢查候選詞集H2中的詞語,如果詞語長度小于n,則判斷該詞語是否在H1中,若不在H1中則從H2中刪除;如果詞語長度大于n,則判斷該詞語內部字符串是否有一半以上位于H1中,若沒有則從H2中刪除。例如:H2中有詞語“單相接地故障”,該詞語長度大于n,則判斷“單相”、“單項接”、“單項接地”……是否在H1中,若不在H1中的詞語個數小于其內部字符串組合情況總數的一半以上,則對該詞語予以刪除。
分詞回溯舉措中,分詞意在最大化候選集中詞語的準確性;回溯舉措目的是進一步確保候選詞集中的詞語是內部足夠“凝固”的,提高了候選詞語的準確性。
1.4 常用詞過濾
在得到的候選詞集H2中,需要進一步對非領域詞進行過濾。本文從中國知網中選擇經濟、哲學、化工3 個領域分別爬取50、50、40 篇非電力領域科技文本,對這140 篇文檔重復第1.1~1.3 小節步驟,得到詞集H21,同時將H2過濾掉H2與H21的交集,進而得到詞集H3,如式(8)所示。

1.5 譜聚類
此時得到的候選詞集H3除了電力行業領域詞外,還有其他領域詞以及不常用的非電力行業詞,諸如:“麥克斯韋方程”、“對抗樣本”、“池化層”等。因此,需要對H3中的詞語進行聚類處理,此處選擇BERT[15]算法對詞集中的詞語進行向量化處理,維度為512,最后運用譜聚類進行降維處理并聚類,最終得到電力領域詞集H4。
譜聚類:把所有數據看作空間中的點,這些點可以用邊連接起來,距離較遠的兩個點之間的邊權重值較低,距離較近則較高。通過對所有數據點組成的無向圖G=(V,E)進行切圖,讓切圖后不同的子圖間邊權重和盡可能低,子圖內的邊權重和盡可能高,從而達到聚類的目的。其中,圖頂點間權重集合為E={Ai,j},鄰接矩陣為W={Ai,j},定義度D 為與當前圖相連的所有圖的權重Ai,j之和。優化函數如式(9)所示:
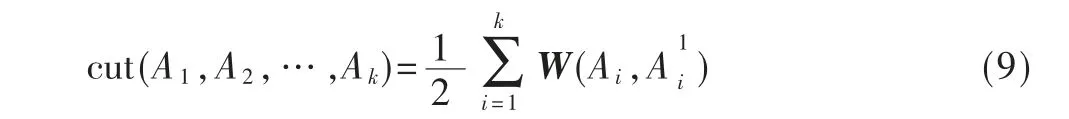

2 實驗
2.1 數據集及預處理
本文從中國南方電網有限公司云南電力科學研究院科技項目申報文檔數據庫中選取了140 篇項目可研申請書作為領域詞發現的語料庫,研究主題主要包括:高電壓與絕緣技術、電機與電氣以及電力系統及自動化,表1 給出了數據集的組成情況。其中語料中的電力領域詞總數為619 個,例如:高壓、絕緣、電路、相位、電阻、繼電器等。

表1 語料庫中各類文本的數量
實驗環境為:8 核16 線程CPU,Ubuntu20.04,Python3.6,TensorFlow-GPU 2.1.0,Nvidia 2070s 顯卡。
在得到語料庫后對每篇文檔做如下處理,處理前后文檔大小及本文所提算法運行時間如表2 所示:

表2 語料處理前后對比
(1)抽取出文檔中目的和意義、項目研究內容與實施方案兩部分。
(2)對抽取出的部分做正則化處理,包括去掉通用格式、數字等對中文領域詞發現無意義的字符。
(3)將每篇文檔被抽取出的部分拼接起來并存入JSON數據庫,形成需要的數據。
2.2 評價指標及參數設置
評價指標:本文選取的模型評價指標為準確率P′、召回率R 以及F 值,這些度量指標用來評判電力詞領域詞發現模型效果,計算公式如下:

其中,識別到的詞語總數為識別出的電力領域詞集;語料中的電力領域詞總數為人工篩選的電力領域詞集;識別正確的電力領域詞為識別出的電力領域詞集與人工篩選的電力領域詞集重合的部分。
參數設置:k1、k2由互信息(Mut)的均值與左右熵(Adj)權重來確定。對于成詞率閾值,本文選取貪心算法進行閾值的取值計算,設定成詞率Suc 閾值取值介于0~1 之間,步長為0.1,設定k1和k2取值介于100~500 之間,步長為1,m 為歸一化常數,n_clusters 與gamma 為譜聚類參數,具體設置如表3 所示。

表3 參數設置
2.3 實驗結果
首先,使用本文方法對140 篇電力科技文檔進行領域詞發現,同時將聚類效果進行可視化。如圖2 所示,圓點表示電力領域詞,五角星為非電力領域詞,可以發現,與預期的預測結果基本一致,譜聚類輸出結果中,電力領域詞基本被聚集在了一起。

圖2 譜聚類可視化效果
為了更加直觀展示本文提出的基于成詞率和譜聚類的領域詞發現方法的效果,進一步對聚類后的詞語做部分展示,如圖3 所示。

圖3 本文方法用于電力文本領域詞發現的效果展示(部分)
從圖3 中可以發現,篩選出的電力詞匯是具有一定可信度的,但領域詞中也有像“自動化”這種經常出現在電力科技文檔里的詞語,也有“電信網”這種帶“電”字樣卻不是電力行業領域詞的詞語;非領域詞中也有“相位”、“母線”這種個別被分錯的電力領域詞。
為了進一步驗證提出方法的有效性,本文做了4 個消融實驗,實驗結果如表4 與圖4 所示。可以發現,本文提出的成詞率相比傳統運用互信息和左右熵的方法有明顯優勢;使用文本切分算法后,各項指標也有明顯提升。譜聚類方法相比傳統K-menas 聚類方法也有明顯優勢。值得注意的是,聚類算法會使召回率與聚類前相比有所降低,主要原因在于聚類操作會使部分電力領域詞被錯分為非領域詞。

圖4 實驗結果展示

表4 實驗結果展示
3 結論
本文通過結合統計特征與語言規則,提出了成詞率這一新的過濾指標,并結合譜聚類實現無監督電力科技文本領域詞發現新方法。實驗結果表明,所提方法與現有傳統方法相比有效提升了候選詞集篩選的準確性,同時在詞語聚類時有效地解決了詞向量維數過高的問題。
后續研究將著眼于對成詞率指標的改進以及將詞嵌入過程與聚類過程更加有效的融合,使其能夠更準確地過濾非電力領域詞,進一步提升方法效率和精度。
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
兒童故事畫報(2019年5期)2019-05-26 14:26:14
電子制作(2018年18期)2018-11-14 01:48:06
意林原創版(2016年10期)2016-11-25 10:28:30
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
