基于通道注意力雙路徑架構網絡分割視網膜血管
2021-10-28 11:01:38鄧小波何柯辰全美霖劉艷麗
中國醫學影像技術 2021年10期
關鍵詞:特征
鄧小波,劉 奇,陳 曦,何柯辰,全美霖,劉艷麗
(1.四川大學電氣工程學院,2.生物醫學工程學院,四川 成都 610065;3.承德醫學院生物醫學工程系,河北 承德 067000)
分割及定位視網膜血管對診斷視網膜病變、青光眼、糖尿病及高血壓眼病等具有重要意義。利用眼底照相機和光學相干斷層成像可觀察視網膜及其內部區域,包括血管樹、中央凹及視盤等[1],進一步分段血管樹并提取血管的長度、寬度、分支及角度等形態屬性,可用于診斷眼科疾病;但是,人工分割受主觀因素影響較大,且耗時、費力[2-3]。傳統機器學習依賴人工構造圖像特征,而深度學習(deep learning,DL)可自動提取并選擇特征。采用U-Net算法或全卷積網絡(fully convolutional networks,FCN)的DL方法可實現分割視網膜血管。以現有DL算法分割血管雖可達到較高精度,但網絡設計多采用單個路徑提取特征,且為獲取更多纖薄血管,多使用跳層結構,融合高層語義信息及低層特征信息,而忽略了中間層特征圖。本研究觀察基于通道注意力的雙路徑架構網絡(dual path-based channel attention network,DPCA-Net)算法分割視網膜血管的效果。
1 數據與方法
1.1 數據集 數據來源于公開DRIVE數據集[4]和CHASE_DB1數據集[5]。DRIVE數據集包含40幅彩色視網膜圖像及經過標注的視網膜血管掩碼圖像,每幅原始圖像的尺寸為565×584,以其中20幅為訓練樣本、另20幅為測試樣本。CHASE_DB1數據集包含28幅分辨率為999×960的彩色視網膜圖像,將前10組共20幅左眼、右眼圖像作為訓練樣本,其余8幅作為測試樣本。自DRIVE訓練集中隨機抽取19萬塊大小為48×48的圖像塊,自CHASE_DB1訓練集中隨機抽取12萬塊64×64圖像塊,用以增加樣本數量[6]。
1.2 圖像預處理 基于訓練集(其中10%為驗證集),將眼底彩色圖轉換為灰度圖;對其行標準化處理,將每幅圖的灰度減去20幅訓練集圖像灰度的均值后除以標準差,以對比度受限自適應直方圖均衡[7]和Gamma校正[8]調整圖像對比度。
1.3 網絡結構 DPCA-Net算法由次路徑及主路徑組成,以通道注意力模塊連接兩個路徑(圖1)。路徑網絡主要由卷積層、殘差塊、激活層、池化層及上采樣層組成。于每個殘差卷積模塊前加入一個卷積層,該卷積層的輸出特征通道數提高2倍,使用ReLU激活函數[9]對卷積后的特征添加非線性因素,殘差塊為非共權殘差塊[6];于殘差塊后引入池化層,提取主要特征并降低特征圖的分辨率,上采樣層通過反卷積操作增加特征圖分辨率。次路徑與主路徑網絡之間僅卷積核大小不同,次路徑采用1×1的卷積核,主路徑采用3×3的卷積核。通道數為64和128的卷積層在每次下采樣前及上采樣后均引入通道注意力模塊。特征融合前添加殘差塊和卷積層,以獲得不同尺度特征信息,將2個路徑提取的特征相加,經過ReLU函數計算后,采用1×1卷積核,以輸出通道為2的卷積層作為網絡輸出。以交叉熵損失作為損失函數(Lossce)對每個像素進行分類[10],公式如下:

圖1 DPCA-Net算法網絡結構
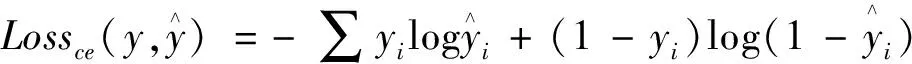
(1)
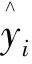
同時構建未采用通道注意力模塊的雙路徑架構網絡(dual path architecture network,DP-Net)算法。
1.4 通道注意力機制 選擇2個特征圖Ft∈RC×H×W和Fc∈RC×H×W,其中C表示輸入特征圖的通道數,H和W分別表示特征圖的高度和寬度;分別通過全局平均池化層(AvgPool)和全局最大池化層(MaxPool)壓縮特征圖的通道信息,對壓縮后的特征逐元素相加,得到特征Ftc∈RC×1×1。通過一個多層感知機模型生成通道注意力權重圖Mtc∈RC×1×1。為得到更為有效的特征,將隱藏層的大小設置為RC/r×1×1,其中r為縮減比率。最后對生成的特征圖進行特征映射,使其大小與原始輸入特征圖相同,再與其逐元素相乘,得到輸出特征圖FTout∈RC×H×W和FCout∈RC×H×W,見圖2。具體公式如下:
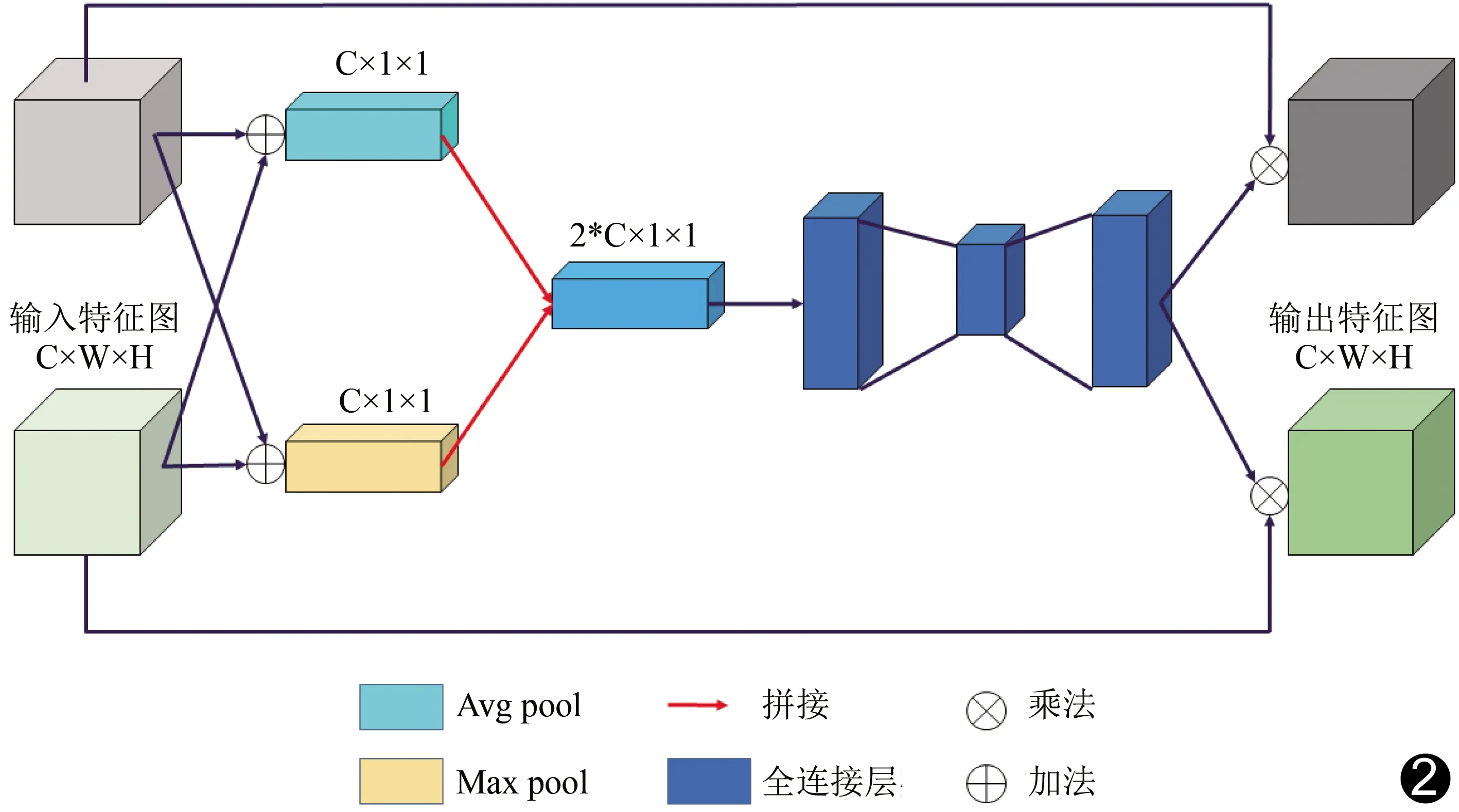
圖2 通道注意力模塊
Ftc=AvgPool(Ft+Fc)+MaxPool(Ft+Fc)
(2)
Mtc=σ[W1×δ(W0×Ftc)]
FTout=Ft×Fscale(Mtc)
FCout=Fc×Fscale(Mtc)
其中,σ表示Sigmoid激活函數,δ為ReLU激活函數,W0∈RC/r×C為多層感知機的第一層權重(長為C,寬為C/r的實數域矩陣),W1∈RC×C/r為第二次權重(長為C/r,寬為C的實數域矩陣)。Fscale表示將通道注意力權重圖映射成H×W的特征圖。
1.5 網絡訓練 采用Adam優化算法[11],將初始學習率設置為0.001,指數衰減率設置為0.9和0.999。當驗證集損失在訓練10個epoch不下降時,學習率變為原有數值之半,重復進行訓練,直至學習率下降至10-7以下。進行模型Xavier初始化[12],批量大小為512,丟失率為0.25。模擬平臺為Pycharm,采用PyTorch框架。計算機配置:Inter(R)Xeon(R)CPU E5-2630 V3@2.40 GHz處理器:Nvidia Geforce GTX 1080 Ti顯卡:64位Windows10操作系統。
1.6 算法評估 基于測試集統計血管像素被正確分類的真陽性(true positive,TP)數目、血管像素被錯誤分類為非血管像素的假陰性(false negative,FN)數目、非血管像素被正確分類的真陰性(true negative,TN)數目及非血管像素被錯誤分類為血管像素的假陽性(false positive,FP)數目。計算準確率(accuracy,ACC)、敏感度(sensitivity,SE)、特異度(specificity,SP)和F1值,評價DPCA-Net算法與DP-Net算法分割視網膜血管的效果。ACC=(TP+TN)/總數;SE=TP/(TP+FN);SP=TN/(TN+FP);精確度(precision,PR)=TP/(TP+FP),F1值=2×PR×SE/(PR+SE)。
2 結果
DPCA-Net算法可正確識別中央血管反射區中同時存在的微血管、無中央反射的血管和有中央反射的血管。采用DPCA-Net算法,亮斑區中的大部分血管被識別;背景干擾區中僅小部分背景被認為是血管;黑斑區中,形狀類似血管的黑斑被認為是血管,其他形狀被認為是非血管(圖3、4)。DPCA-Net算法分割DRIVE/CHASE_DB1數據集中視網膜血管的ACC為95.58%/96.34%,SE為80.37%/77.70%,SP為97.80%/98.22%,F1值為82.24%/79.55%,除針對DRIVE數據集的SE(80.63%)低于DP-Net外,其針對CHASE_DB1數據集的SE(76.06%)、分割DRIVE/CHASE_DB1數據集中視網膜血管的ACC(95.51%/96.15%)、SP(97.68%/98.18%)及F1值(82.06%/78.38%)均高于DP-Net。
圖3 DPCA-Net算法分割CHASE_DB1數據集視網膜血管結果 A、B.原始圖像;C、D.數據集標準分割結果;E、F.DPCA-Net算法分割結果 (藍框為中央血管反射區;紅框處為亮斑區)
3 討論
分割血管多基于U-Net架構并采用FCN方法。U-Net網絡利用跳層結構融合解碼器和編碼器特征,FCN則使計算更為高效。ALOM等[13]采用基于U-Net的遞歸神經網絡及遞歸殘差卷積神經網絡(convolutional neural network,CNN)的算法分割視網膜血管;LUO等[14]提出一種尺寸不變、可利用連續卷積層和池化層提取血管特征的FCN算法;FENG等[15]利用網絡主路徑與次路徑間的交叉連接融合多層次特征構建CNN算法;FU等[16]采用多尺度注意機制CNN算法,使網絡更加關注血管像素,并引入具有不同擴張率的阿托羅斯可分離卷積,以獲得更多血管特征。本研究將雙路徑FCN與通道注意力機制相結合,以充分發揮其優點,次路徑的引入豐富了血管特征,注意力機制不僅代替了跳層結構,且提高了特征層的利用率,使得DPCA-Net算法分割DRIVE/CHASE_DB1數據集中視網膜血管的效果均較好。
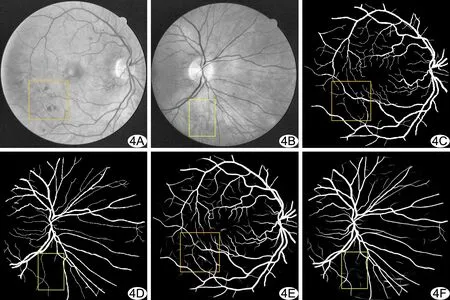
圖4 DPCA-Net算法分割DRIVE數據集視網膜血管結果 A、B.原始圖像;C、D.數據集標準分割結果;E、F.DPCA-Net算法分割結果 (橙框為黑斑區;黃框為背景干擾區)
與既往研究[13,15-19]相比,DPCA-Net分割的血管具有更好的連通性,且能分割出更多微血管,其對DRIVE、CHASE_DB1數據集的定量結果ACC均優于其他算法,分別達到95.58%/96.34%,SE、SP及F1值也達到較高水平(表1、2),提示引入通道注意力機制可通過利用網絡中間特征層進一步提升網絡性能。與DP-Net相比,DPCA-Net在2個數據集上的多項效能指標更優;但其針對DRIVE數據集的SE低于DP-Net,可能原因在于引入通道注意力機制使網絡更加注意微血管而將部分微小非血管元素分類為血管元素。
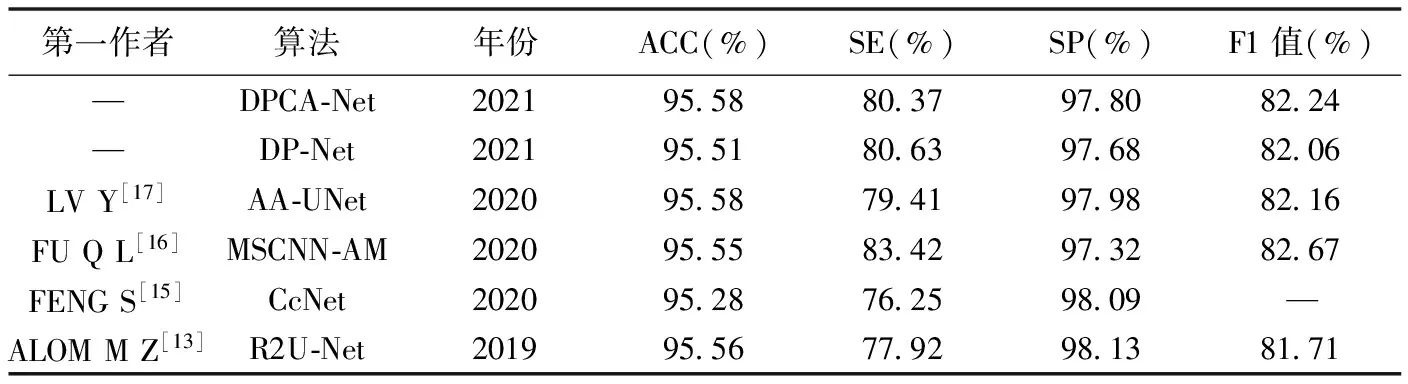
表1 不同算法針對DRIVE數據集的效能比較
綜上,本研究提出的DPCA-Net FCN視網膜血管分割方法可避開傳統跳層結構,將雙路徑網絡提取的特征經通道與注意力機制相融合,使網絡更加注意血管特征,降低病變區域度算法的影響,有利于改進分割視網膜血管的效果。
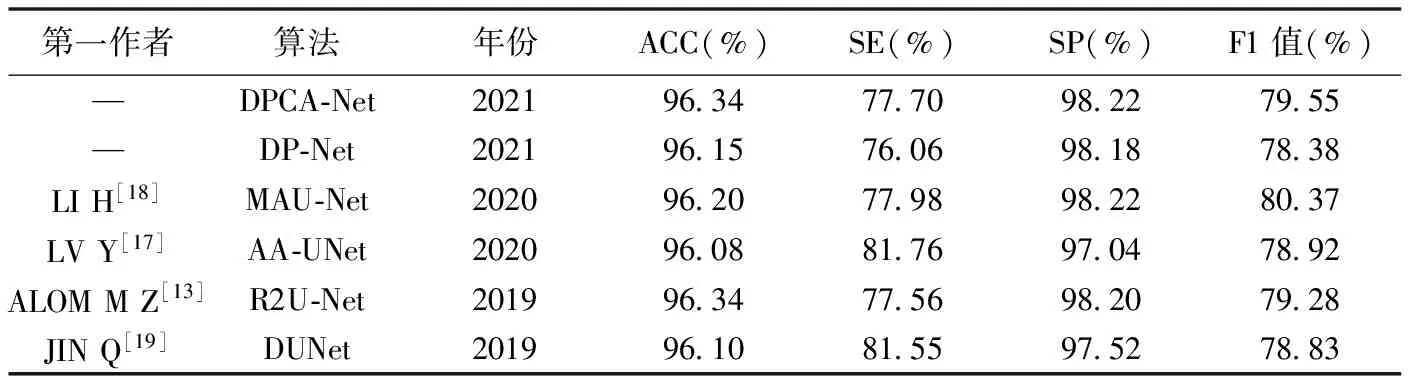
表2 不同算法針對CHASE_DB1數據集的效能比較
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
