基于VFP的隨機數研究與應用
2021-10-18 06:23:46趙康
商丘職業技術學院學報 2021年4期
趙 康
(商丘職業技術學院,河南 商丘 476100)
引言
隨著科技的進步,隨機數的運用已經滲透社會的各行各業.學術界對隨機數的討論以及對隨機參數的選取也是眾說紛紜.隨機數最重要的特性是前后產生的兩個數沒有邏輯關系,即真正的隨機.但我們在日常工作和生活中,使用計算機接觸的隨機數只是某些工具根據一些參數在特定的計算方式下生成的具有隨機數某些特征的偽隨機數.VFP是一種集成了面向對象程序設計工具的小型數據庫管理系統[1],由于其結構簡單、功能強大、性能穩定等特點,因此,VFP在社會各行各業都有著廣泛的應用基礎[2].本文就VFP所提供的隨機函數RAND()在生成隨機數時出現的生成相同序列隨機數、生成隨機數重復率等問題進行探討.
1 隨機數的概述
隨機數產生于大量統計對象中選取的特殊樣本,這些樣本之間沒有固定的關聯關系.隨機數一般分為三類.
1)偽隨機數:它的判定基于統計學中所選定的特殊樣本各分類的占比大致相等.
2)密碼學安全的偽隨機數:在滿足第一類偽隨機數的基礎上,抽取部分樣本不能有效地演算出隨機樣本的剩余部分的信息.
3)真隨機數:在滿足第一類條件和第二類條件的基礎上,還必須滿足隨機樣本不可重復的條件.
生成隨機數的方法稱為隨機數發生器,隨機數發生器分為兩類[3].
1)物理性隨機數發生器:它以噪聲、溫度等物理信息獲取隨機數.
2)偽隨機數發生器:通過固定重復的計算得到具有隨機數統計特征的偽隨機數.
2 VFP中隨機函數RAND()的功能特點
VFP為用戶提供了300多種函數[4],用戶在使用這些函數處理實際問題時,一般都需要多個函數配合使用才能解決問題.
隨機函數RAND()的基本格式為:RAND([<隨機參數>]),調用函數返回一個0-1的數值型隨機數[5].在實際使用過程中,RAND()函數可以配合其他函數疊加使用,從而滿足用戶的需求.例如:生成0-999之間的隨機整數,只需要將RAND()的返回值乘上1000,然后再使用取整函數INT()對數據結果處理即可.即:INT(RAND()*1000);若要生成某個指定范圍內的隨機整數,可做如下變形:INT((n2-n1+1)*RAND()+ n1),其中,n2是隨機數范圍的上限,n1是隨機數范圍的下限.INT((999-100+1)*RAND()+100)就是生成三位整數的隨機數.
3 隨機函數RAND()使用過程中產生相同隨機序列的問題
在VFP中,函數的調用需要有輸出值和返回值,這相當于簡單的函數式:y=f(x),當x值確定后根據對應法則f,就會有確定的y值與之對應.但隨機函數RAND()可以通過循環語句反復被調用來生成一個隨機數列.我們以每組輸出10個隨機數的5組數據為例.因為,本例的設計是為了論證在隨機參數缺省時,無論代碼被運行幾次返回的數值都將會是同一個隨機數列,因此,省略了外層循環.運行程序生成的隨機數結果,如表1所示.
具體代碼如下:
CLEAR
SET TALK OFF
FOR i=1 TO 10
REPLACE 測試1 WITH RAND()
SKIP
ENDFOR
SET TALK ON
RETURN
由表1可知,5次程序運行的結果得到的5組隨機數數列是相同的,這和我們的預計結果是一致的.因為,當調用隨機函數所使用的隨機參數為省略,參數值將取默認缺省值100001.雖然隨機參數缺省隨機函數會返回序列中的下一個隨機數,但是,這段代碼中隨機參數的初值是固定的,因此,無論代碼被執行多少次總會返回相同的數列,這樣所產生的數列不能滿足我們的實際需求.為此,我們可以考慮,在進入輸出隨機數列循環體之前調用一次參數值為負數的隨機函數RAND(-1),其目的是將系統時鐘的當前秒數用作隨機數的隨機參數值,如此,運行程序的多次調用是有時間差的,反映到實驗結果上的隨機數列也必然不同.具體結果如表2所示.
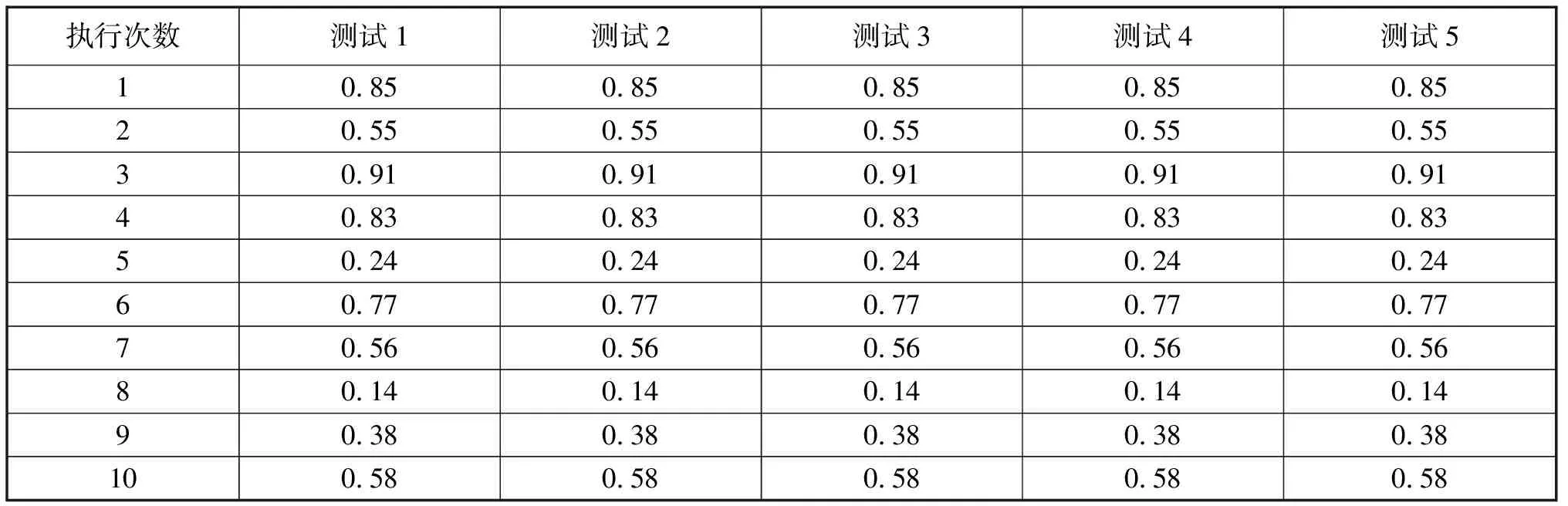
表1 運行程序生成的隨機數列結果
具體代碼修改如下:
CLEAR
SET TALK OFF
RAND(-1)
FOR i = 1 TO 10
REPLACE 測試1 WITH RAND()
SKIP
ENDFOR
SET TALK ON
RETURN
由表2可知,經過首先調用含有負參數的隨機函數RAND(-1)再使用RAND()生成的序列就是比較令人滿意的隨機數列了.
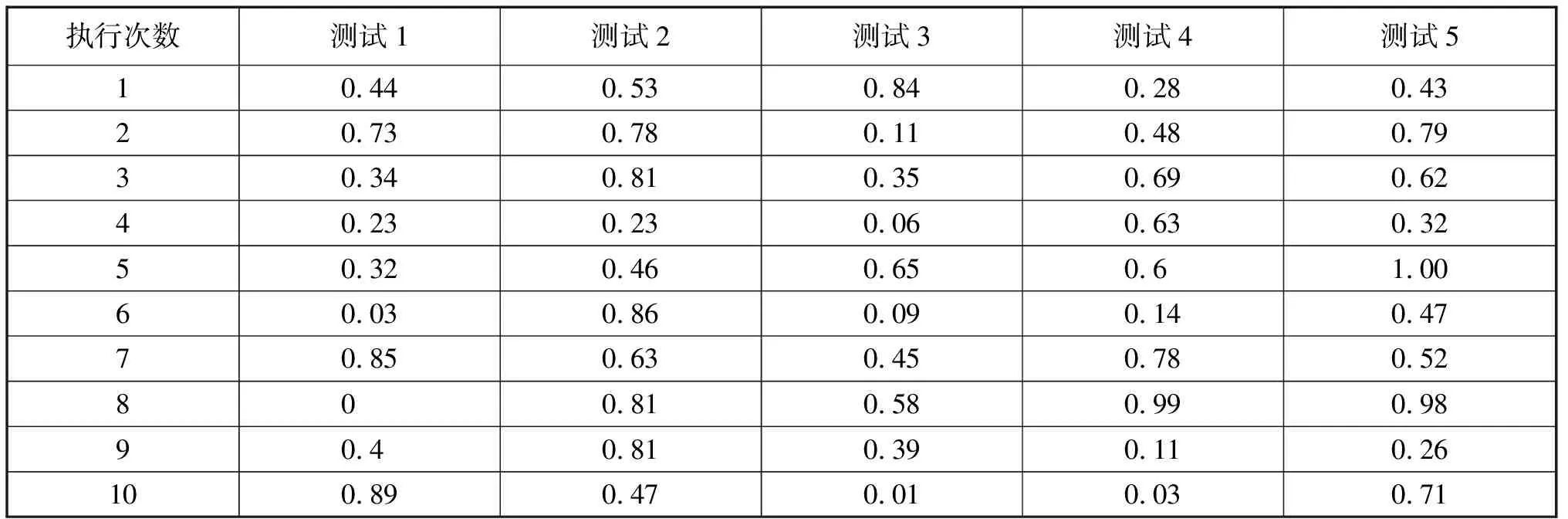
表2 運行修正后程序的隨機數列結果
4 隨機函數RAND()使用中產生隨機數的重復率問題
根據隨機數發生器的工作原理可知,在確定隨機參數初值后,每一次隨機函數的調用都會將上一個生成的隨機數作為下一次調用的隨機參數值.由于發生器在設計時對參數值精度的選定,因此,其結果必然會出現參數值相同的現象.這反映到隨機數列上就是在隨機數列中的重復值問題.為了探討隨機數在使用過程中的重復值現象,我們以追加每組50個數的10組3位隨機整數為例.
具體代碼如下:
CLEAR
SET TALK OFF
USE "測試"
RAND(-1)
FOR i=1 TO 50
REPLACE cs1 WITH INT((999-100+1)*RAND()+100)
SKIP
ENDFOR
SET TALK ON
RETURN
如表3所示,統計每50個數的3位隨機數的重復率達6%.目前,隨機數產生原理一般是線性同余法或平方取中法,線性同余法產生的隨機數會出現循環情況,但由于它的模為231,通過平方取中法產生的隨機數會逐漸趨向于0.因此,隨機值高重復率的根源在于實際問題本身.因為,我們要求是生成3位隨機整數,因此必須對隨機函數進行疊加才能實現“INT((999-100+1)*RAND()+100)”,但明顯這樣做就舍棄了小數點后的很多位,其解決重復數據的辦法是通過擴大位數的手段降低重復率.在數據量較小時,對于個別重復數據的手動微調可以降低重復率.但在實際工作中,如果數據量較大,那么對數據的查重和對數據的修改就很容易出錯,對隨機數的使用反而不如順序數來得直接高效.

表3 3位隨機數列出現重復值的統計結果
5 隨機函數RAND()在實際工作中的應用
5.1 追加大量隨機數時數值重復問題解決辦法
在某些工作中,我們會遇到為某些記錄追加固定長度的序號,并且出于保密角度的考慮,序號又不能使用連貫序號這一問題.下面筆者以給20 677條數據追加一個6位不重復的隨機數字段為例(由于一般情況下數據表的字段多為字符型,這里需要使用數值型轉字符型函數STR()和刪除字符串的首部和尾部連續空格函數ALLTRIM()).
具體代碼如下:
CLEAR
SET TALK OFF
USE "表名"
RAND(-1)
GO TOP
DO WHILE NOT EOF()
REPLACE ALL zp WITH ALLTRIM(STR(INT((999999-100000+1)*RAND()+100000)))
SKIP
ENDDO
SET TALK ON
RETURN
如表4所示,以20 677條記錄為基礎的6位的隨機數重復率在2%.這個結果相對于上述問題的每50個3位隨機數重復率達6%的重復率而言降低了不少,但手工調整重復值的方法依然是不可行的.根據實際工作需求,為了避免隨機數的重復率問題,筆者考慮為每一個隨機函數添加一個不同的參數來控制隨機數的重復率.由于每一張數據表中每條記錄的記錄號是唯一的,筆者將每條記錄的記錄號設為隨機函數參數“RAND(RECNO())”,經多次追加同一序列的隨機數進行測試發現(每條記錄的隨機數是同一個值),沒有重復值的6位隨機數.

表4 6位隨機數列出現重復值的統計結果
5.2 隨機抽取數據庫相關信息
在一些娛樂節目中,我們經常會看到抽取幸運數字或幸運身份證號碼等環節.以21 815條記錄的數據庫為例,利用隨機函數RAND()返回值是0-1的特點,在數據庫內隨機抽取記錄值并返回對應記錄的相關信息,結果如圖1所示.
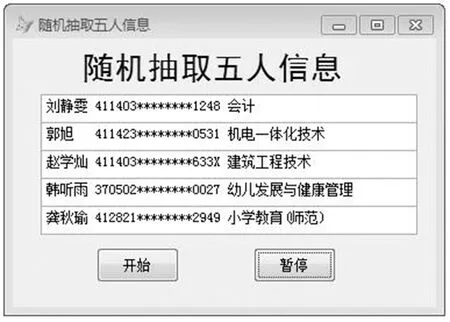
圖1 隨機抽取5人信息運行結果
在表單的Init事件中添加以下代碼:
IF ! USED("隨機排序表")
USE 隨機排序表
ENDIF
RAND(-1)
在timer1控件的Timer事件中添加以下代碼:
FOR i=1 TO 5
texti="text"+ALLTRIM(STR(i))
GO INT(RAND()*21815)
thisform.&texti..Value=IIF(LEN(ALLTRIM(xm))==4,ALLTRIM(xm)+" ",ALLTRIM(xm)+" ")
+LEFT(ALLTRIM(sfzh),6)+"********"+RIGHT(ALLTRIM(sfzh),4)+" "+ALLTRIM(zymc)
ENDFOR
在command1控件的Click事件中添加以下代碼:
thisform.timer1.Interval=270
在command2控件的Click事件中添加以下代碼:
thisform.timer1.Interval=0
上述代碼主要是針對在已有數據的基礎上實現范圍內信息隨機抽取的功能實現.由于這里輸出的信息是在一個文本框中進行的輸出,考慮到輸出的美觀和信息的隱私性,筆者做了如下處理.因為姓名的字數個數不同,所以需要通過追加空格以保證輸出信息的整齊“IIF(LEN(ALLTR IM(xm))==4,ALLTRIM(xm)+" ",ALLTRIM(xm)+" ")”(這里只以2個漢字或3個漢字進行處理,對于超過3個漢字的名字不做說明).對于身份證號等具有較強隱私性的信息需要對關鍵部分進行處理,這里筆者通過函數“LEFT(ALLTRIM(sfzh),6)+"********"+RIGHT(ALLTRIM(sfzh),4)”對身份證號碼中的出生年月日進行了替換顯示.這類問題在工作和生活中應用度很高,對于類似的問題只需要在本例的基礎上稍加調整即可實現.
5.3 將1-10的10個數字隨機排序
在工作和生活中,我們經常會碰到一些具體的人或物排序的問題.筆者以1-10這10個數字為例,對這10個具體數字實現隨機排序.
創建一個臨時表,具體代碼如下:
RAND(-1)
SELECT 0
CREATE CURSOR testt(x int, y N(6,4))
FOR ii = 1 TO 10
APPEND BLANK
ENDFOR
這段代碼首先為臨時表的兩個字段賦值,分別是記錄號和隨機數.臨時表的10條記錄對應1-10這10個數字,按照隨機數的大小進行排序并重寫臨時表,將重寫后的臨時表中的記錄號字段賦給一個變量并輸出這個變量.反復執行下述代碼,實現10個數字的隨機排序.
REPLACE ALL x WITH RECNO(),y WITH RAND()
SELECT * FROM testt ORDER BY y INTO CURSOR testt READWRITE
testi=''
SCAN ALL
testi=testi+','+TRANSFORM(x)
ENDSCAN
?SUBSTR(testi,2)
運行結果如圖2所示.

圖2 1-10隨機數排序運行結果
6 結論
隨機數研究與應用可以模擬、解決各活動領域中的一些實際問題.根據隨機數的特性和影響隨機數發生的隨機函數參數的選取來控制和影響隨機數的發生.從本質上看,在計算機系統中,無論任何計算機語言提供的隨機函數所生成的隨機數,都是通過一個參數在對應算法的基礎上產生的偽隨機數,這些由隨機函數產生的偽隨機數,基本符合隨機數的特性而且實用價值很高.本文探討了追加大量隨機數時,數值重復問題的解決辦法、隨機抽取數據庫中相關信息進行顯示的問題和將10個數字隨機排序這3個工作中經常出現的隨機數應用問題,并從實際問題出發闡明其具體的解決思路.
猜你喜歡
兒童時代·幸福寶寶(2022年12期)2022-12-09 11:24:14
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
幼兒智力世界(2004年3期)2004-04-29 00:00:00
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
