基于聯合低秩稀疏分解的紅外與可見光圖像融合
2021-09-29 02:25:22王文卿
信號處理 2021年9期
王文卿 馬 笑 劉 涵
(1. 西安理工大學自動化與信息工程學院, 陜西西安 710048; 2. 西安理工大學陜西省復雜系統控制與智能信息處理重點實驗室, 陜西西安 710048)
1 引言
由于不同類型傳感器的成像機理存在較大差異,多傳感器可以為同一場景提供不同的圖像數據。例如,紅外傳感器基于目標產生的熱輻射成像,在全天時和全天候條件下具有良好的目標發現能力。然而,紅外圖像分辨率通常較低,缺少紋理、邊緣等細節信息。可見光傳感器是基于外觀信息豐富的反射光成像,可見光圖像具有清楚的細節紋理信息和較高的分辨率。然而,場景中的目標由于隱藏在黑暗、叢林或者煙霧中卻無法清晰成像。因此將紅外與可見光圖像融合可互補兩種圖像的特性,得到一幅細節信息豐富的融合圖像。目前,紅外與可見光圖像融合技術在目標識別、檢測和視頻監視等領域中得到廣泛應用[1-3]。
像素級圖像融合直接作用于原始輸入圖像,能夠保留原始圖像中豐富的細節信息,提取圖像的重要信息并將獲取信息以最小的失真或損失轉化為融合圖像是像素級圖像融合的關鍵。近幾十年來,人們已經提出了眾多有效的紅外與可見光圖像融合方法,歸納起來可分為四類:基于多尺度變換的融合方法,基于稀疏表示的融合方法,基于神經網絡的融合方法和基于顯著性的融合方法[4]。
基于多尺度變換的圖像融合方法是目前紅外和可見光圖像融合領域的研究熱點[5]。多尺度變換可以實現源圖像由細到粗不同尺度的分解,且許多研究證明多尺度變換與人們的視覺感知一致,可使得融合圖像具有良好的視覺效果。基于多尺度變換的融合方法主要包括三個步驟。首先,將紅外和可見光源圖像分別分解成不同尺度的若干層。然后根據規定的融合規則對多尺度系數進行融合;最后進行多尺度逆變換可獲得最終融合圖像。多尺度變換方法的選擇和融合規則的設計是實現該類方法的兩個關鍵步驟。紅外與可見光圖像融合中常用的多尺度變換有金字塔變換、小波變換、輪廓波變換、剪切波變換、邊緣保持濾波器等[6-10]。盡管變換系數可以合理地表示圖像的重要特征,但是每種變換都有自己的優缺點,因此選擇一種最優的多尺度變換由具體場景信息決定。
稀疏表示理論以其良好的表征人類視覺系統能力,在計算機視覺、機器學習、信息融合等不同領域得到了廣泛應用。稀疏表示遵循輸入信號可以近似地由過完備字典中的原子稀疏線性組合表示。文獻[11]首次利用稀疏表示模型解決圖像融合問題。首先,采用滑動窗口策略將每幅源圖像分解為若干個重疊的圖像塊。其次,通過正交匹配算法對每一個圖像塊進行稀疏編碼獲得稀疏系數。然后,采用稀疏系數向量的范數作為活躍級度量對稀疏系數進行融合。最后,利用融合稀疏系數和過完備字典重構最終融合圖像。構造過完備字典和稀疏編碼是基于稀疏表示圖像融合的兩個關鍵問題。文獻[12]采用了同時正交匹配算法進行稀疏編碼,保證相同位置的源圖像塊可以由字典中相同的原子子集表示。此外還采用K-SVD算法從大量自然圖像塊中學習得到字典,代替了離散余弦變換基構造的字典。文獻[13]采用形態學分量分析模型獲得源圖像的卡通和紋理分量的稀疏表示,根據不同分量的特性設計合適的融合策略。文獻[14]提出了自適應稀疏表示的圖像融合方法,其通過學習訓練樣本的不同梯度方向信息構建字典,根據圖像塊的梯度信息在字典集中自適應選擇合適的字典進行稀疏編碼。為了克服傳統稀疏表示采用基于圖像塊編碼存在細節保持能力有限和對誤配準的敏感性高的不足,文獻[15]提出了基于卷積稀疏表示的圖像融合方法。基于稀疏表示的方法取得很好的融合結果,但由于稀疏求解過程復雜,使得計算復雜度很高。
近年來深度學習方法也逐漸地被用到圖像融合領域。文獻[16]提出基于卷積神經網絡的紅外與可見光圖像融合方法,在拉普拉斯金字塔結構上使用卷積神經網絡來提取圖像特征并構造權重圖。文獻[17]構建并訓練了一個端到端的生成對抗性網絡模型來融合紅外和可見光圖像。文獻[18]提出了一種端到端的聚合殘差密集網絡結構,充分利用了殘差網絡的密集結構優勢,實現了紅外與可見光圖像的有效融合。
基于顯著性的融合方法作為紅外與可見光融合的代表性框架之一,可保持顯著性目標區域的完整性,提高融合圖像的視覺質量。權重計算和顯著目標提取是兩種不同的實現方法。前者通常和多尺度方法相結合,將紅外與可見光源圖像分解成基礎層和細節層,然后對基礎層或細節層采用顯著性提取模型獲得顯著圖并計算得到權重圖,根據權重圖實現基礎層和細節層圖像的融合,最后通過融合的基礎層和細節層重構融合圖像。文獻[19]提出基于多尺度邊緣保存濾波和引導濾波的紅外與可見光圖像融合方法,采用相位一致性來獲取基礎層和細節層的顯著圖,然后對顯著圖進行引導濾波獲得權重圖。后者通常采用顯著性模型提取紅外圖像的顯著性區域,使得融合圖像具有良好的視覺效果。文獻[20]采用基于超像素的顯著性模型獲得紅外圖像的顯著性區域,很好地保留了紅外圖像的目標信息。
為了更好地提取紅外圖像的顯著目標,且考慮到紅外與可見光圖像的相關性,本文提出了一種基于聯合低秩稀疏(Joint Low-rank and Sparse, JLRS)分解的紅外與可見光圖像融合方法。與傳統低秩稀疏分解不同,該方法假設紅外與可見光圖像具有共有的低秩分量,將源圖像聯合分解成共有低秩分量,特有低秩分量和特有稀疏分量三部分。針對特有低秩分量和特有稀疏分量的不同特點,采用基于非下采樣Shearlet變換(Non-Subsampled Shearlet Transform, NSST)和區域能量的融合方法分別對特有低秩分量和特有稀疏分量進行融合。最后將融合的特有低秩分量和特有稀疏分量與共有低秩分量合并重構最終的融合圖像。實驗結果表明本文算法能夠有效地提取紅外圖像中的目標信息和保留可見光圖像的背景信息,提高目標顯著性,并且在主觀視覺和客觀評價指標方面都明顯優于對比算法。
2 聯合低秩稀疏分解
低秩稀疏分解是一種有效的圖像表示模型,在圖像分類、圖像去噪、圖像對齊等研究中表現出良好性能[21]。對于一幅數字圖像,為了利用高維數據中的低秩低維結構,可將圖像矩陣分解成高度相關的低秩部分和近似噪聲或野點的稀疏部分。設輸入圖像矩陣為X=[x1,x2,…,xn]∈Rm×n,則有:
(1)
其中:L和S分別代表低秩分量和稀疏分量,rank(L)表示L的秩,||S||0表示矩陣S的0范數。然而,上述求解過程是NP-hard問題。為了得到最優解,通常將(1)轉化為凸優化問題,如(2)所示:
(2)
其中:||L||*表示矩陣L的核范數,||S||1表示矩陣S的1范數。
針對多幅圖像分解,原始低秩分解方法是逐一對源圖像進行單獨分解。然而,此方法忽略了多幅源圖像之間的相關性。因此,文獻[22]提出了一種聯合低秩稀疏分解模型。該模型假設數據矩陣由三部分組成:共有低秩部分、特有低秩部分和特有稀疏部分。假設Xq=[xq,1,xq,2,…,xq,n]∈Rm×n(q=1,2,…,Q)表示第q幅輸入圖像,Q為輸入圖像的總個數。因此,Xq可以被寫成以下三個分量之和:
Xq=Lc+Lq+Sq
(3)
其中:Lc表示共有低秩分量,Lq和Sq分別表示第q幅圖像的特有低秩部分和特有稀疏部分。通過求如下解優化問題(4),可以恢復出分解后的三部分分量。
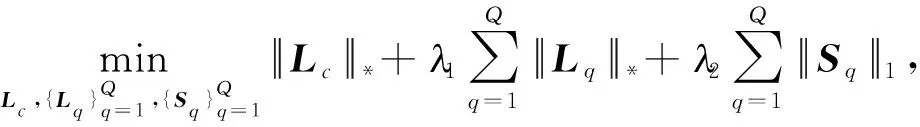
(4)
其中:λ1和λ2表示正則化參數。増廣拉格朗日乘子法可以求解凸優化問題。公式(4)的増廣拉格朗日函數為:
(5)
然后使用交替方法乘子法(Alternating Direction Method of Multipliers,ADMM) 求解以下最小化問題可以獲得最優解。
(6)
3 本文算法
本文提出了一種基于聯合低秩稀疏分解的紅外與可見光圖像融合算法,其算法流程如圖1所示。本方法主要包含以下四個步驟:源圖像聯合低秩稀疏分解、特有低秩分量融合、特有稀疏分量融合與融合圖像重構。具體實現步驟如下。
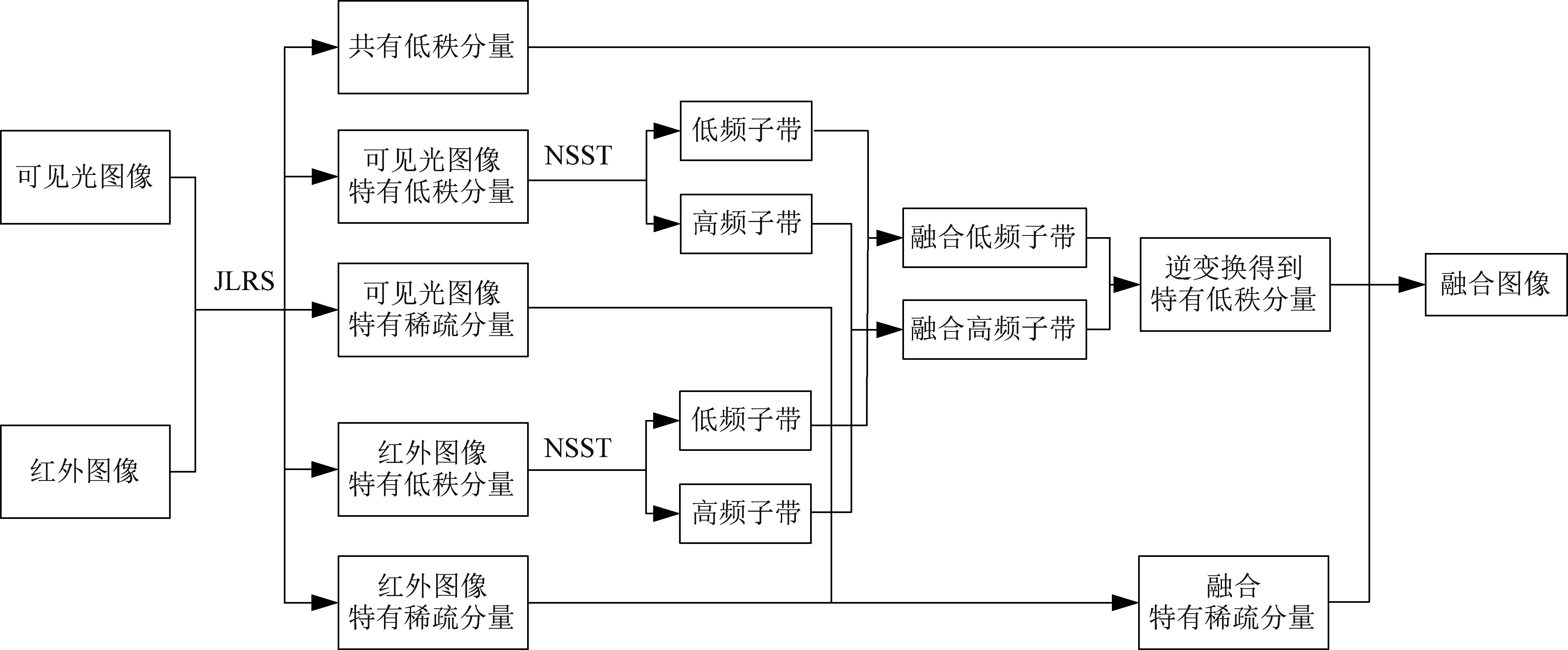
圖1 算法框架Fig.1 Algorithm framework
3.1 聯合低秩稀疏分解
利用聯合低秩稀疏分解模型將紅外圖像IA和可見光圖像IB聯合分解成共有低秩分量、特有低秩分量和特有稀疏分量。分解過程如式(7)所示:
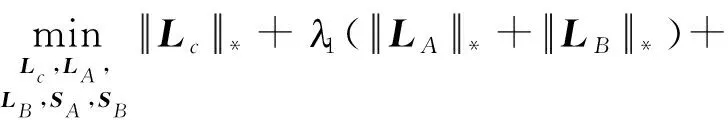
(7)
其中:Lc表示紅外與可見光圖像的共有低秩分量,LA和LB分別表示紅外與可見光圖像的特有低秩分量,SA和SB分別表示紅外與可見光圖像的特有稀疏分量。圖2所示為一組紅外與可見光圖像的聯合低秩稀疏分解結果。圖2(a)和(b)分別表示紅外圖像與可見光圖像。紅外圖像中行人目標溫度較高則可以清晰地發現,但圖像的背景信息清晰度很低,分辨率明顯低于可見光圖像。可見光圖像中細節紋理明顯清晰,但隱藏在叢林中的人物目標無法被觀察到。圖2(c)表示共有低秩分量。從圖中可以看到,其保留了兩幅圖像的共有輪廓信息。圖2(d)和(e)分別表示紅外和可見光圖像的特有低秩分量。從圖中可以看到,兩幅圖分別包含了紅外圖像和可見光圖像各自特有的背景信息,其中蘊含著源圖像的部分紋理細節信息。特有稀疏分量如圖(f)和圖(g)所示,包含著源圖像的顯著目標信息。針對特有低秩分量與特有稀疏分量,分別構建了不同融合策略。

圖2 紅外與可見光圖像聯合低秩稀疏分解Fig.2 Joint low-rank and sparse decomposition of infrared and visible images
3.2 特有低秩分量融合策略
3.2.1低頻子帶融合
低頻子帶蘊含特有低秩分量的絕大部分信息。為了更好地保留有效信息,去除冗余信息,本文采用基于稀疏表示的融合策略對特有低秩分量的低頻子帶進行融合。具體實現步驟如下:
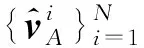
2)利用稀疏表示模型對每一個圖像塊進行稀疏分解,獲得每一個圖像塊的稀疏系數。
(8)
(9)
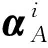
(10)
(11)
(12)
將所有融合后的圖像塊向量轉換成為圖像塊,對重疊區域進行平均可得到低頻子帶融合圖像FL。
3.2.2高頻子帶融合
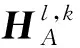
2)對初始決策圖采用一致性檢驗得到最終決策圖,如式(13)所示。
(13)
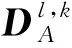
(14)
3.3 特有稀疏分量融合策略
特有稀疏分量主要包含源圖像中亮度較大的目標信息。能量常用來描述圖像的亮度特征,為了減少能量的損失,保留圖像中的顯著目標,本文采用區域能量取大的融合策略對特有稀疏分量進行融合。
紅外圖像特有稀疏分量SA和可見光圖像特有稀疏分量SB的區域能量計算如下:
(15)
(16)
其中:W表示一個(2r+1)×(2r+1)的權重矩陣,其根據四鄰域離中心位置的距離設定如下。
(17)
因此,融合特有稀疏分量可通過以下規則得到。
(18)
3.4 融合圖像重構
通過上述步驟,可獲得融合后的特有低秩分量和特有稀疏分量。最終融合圖像可通過式(19)獲得。
If=Lc+Lf+Sf
(19)
4 實驗結果與分析
本文在Bristol Eden Project1、Nato-camp和TNO2公共數據集中選取一些嚴格配準的紅外與可見光圖像進行測試。實驗環境平臺為:Intel(R) core(TM) i7-9700 @3.00 GHz,RAM 16.0 GB,MATLAB 2018b。
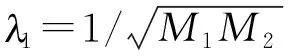
客觀評價指標可以定量地評估圖像的質量。本文采用熵(Entropy, EN)、互信息(Mutual Information, MI)、標準差(Standard Deviation, SD)、視覺信息保真度(Visual Information Fidelity, VIF)、差異相關系數之和(The Sum of the Correlations of Differences, SCD)和QY作為客觀評價指標對融合算法性能進行評估[27]。EN反映了融合圖像中包含信息量的多少。MI衡量了從源圖像到融合圖像傳輸的信息量。SD反映了融合圖像的灰度與圖像平均值之間的差異。VIF反應融合圖像的信息保真度。SCD計算源圖像與融合圖像的差分圖像之間的相關性,QY衡量融合圖像保存結構信息的能力。六種客觀評價指標數值越大,融合圖像質量越高。
第一組測試數據選用Nato-camp圖像序列,包含32幀大小為270×360的紅外圖像和可見光圖像。圖3(a)和(b)所示為其中一幀紅外與可見光源圖像。圖3(c)~(l)表示對比方法與本文方法的融合結果。從圖中可以看出,GTF方法的融合圖像視覺質量較差,細節信息模糊不清。LP、DTCWT、NSCT、NSST和CSR方法能夠保留可見光圖像中樹木的紋理信息,但是融合結果中人物目標偏暗且周圍存在黑洞,對比度偏低。GF較好地保存了紅外圖像中的顯著目標,但是融合圖像背景不清晰。LATLRR方法的融合結果整體比較模糊且分辨率較低。CNN方法的融合結果整體比較清晰,但建筑旁邊的樹木邊緣輪廓不理想。本文方法的融合結果相對于比較方法,目標清晰,對比度高,具有較好的視覺效果。
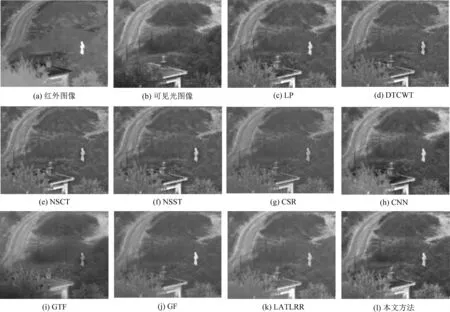
圖3 Nato-camp圖像融合結果Fig.3 Fusion results of Nato-camp images
圖4所示為十種融合方法在Nato-camp 32幀測試圖像序列上的六種客觀評價指標結果曲線圖,其中帶有星號的曲線代表本文融合算法。從圖中可以看到,本文方法的32幅融合圖像具有最優的VIF,SCD和QY數值結果,并且大多數融合結果具有最優的MI值。在EN和SD指標上,本文方法的數值結果均低于GTF方法的數值結果,但與CNN方法的數值結果不相伯仲。綜上所述,面對Nato-camp 32幀圖像序列,本文方法在主觀視覺和客觀評價上表現出優越的融合性能。
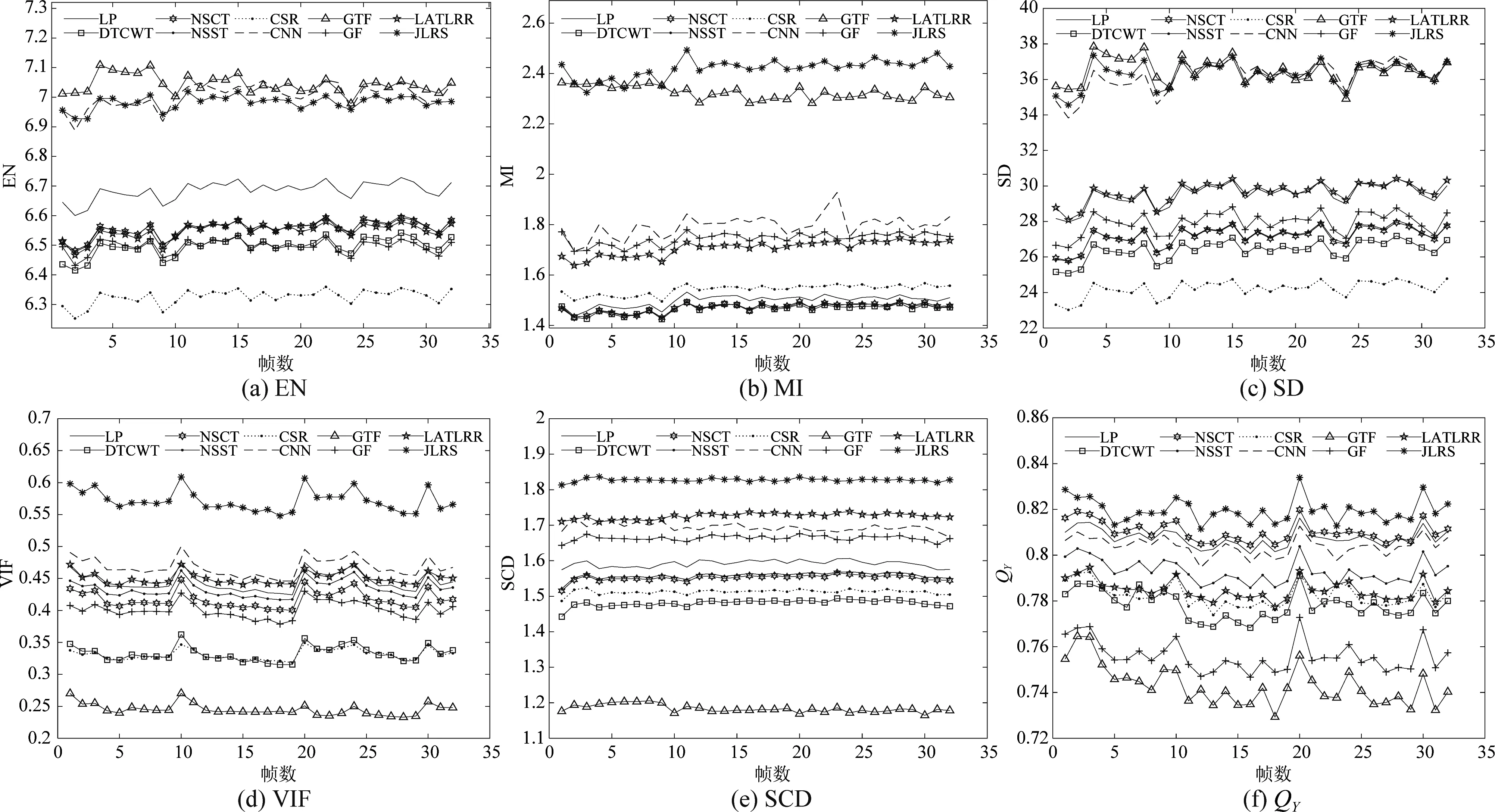
圖4 不同融合方法的客觀評價指標結果 (Nato-camp)Fig.4 Objective evaluation results of different fusion methods (Nato-camp)
圖5所示為Bristol Eden Project圖像序列中某幀源圖像和對比算法的融合結果。圖5(a)和(b)分別表示紅外和可見光源圖像。圖5(c)~(l)分別表示對比算法和本文算法的融合結果。從圖中可以看到,DTCWT、NSCT和NSST方法的融合結果中人物目標和背景都比較暗淡,對比度較低。CSR、GTF、GF和LATLRR方法的融合結果存在背景細節信息丟失問題,LP和CNN方法的融合圖像中人物目標周圍背景信息有一定程度丟失。本文方法的融合結果具有層次感,亮度高,人物目標非常清晰,具有更好的人類視覺效果。

圖5 Bristol Eden Project圖像融合結果Fig.5 Fusion results of Bristol Eden Project
圖6為十種融合方法在Bristol Eden Project 32幀測試圖像序列上的六種客觀評價指標結果曲線圖,圖中帶有星號的曲線代表本文融合算法。本文方法的32幅融合圖像具有最優的MI,VIF和SCD指標值,從EN值結果曲線中可以看出本文方法遠高于其他對比方法的熵值,SD值結果曲線中本文方法僅有一部分圖像幀融合結果未達到最優。總之,本文方法對Bristol Eden Project 32幀圖像序列在主觀視覺和客觀評價上均表現出一定的優勢。

圖6 不同融合方法的客觀評價指標結果 (Bristol Eden Project)Fig.6 Objective evaluation results of different fusion methods (Bristol Eden Project)
第三組測試圖像為Kaptein圖像,如圖7(a)和(b)所示。圖7(c)~(l)為對比方法和本文方法的融合結果。從主觀視覺來看,LP、DTCWT、NSCT、NSST、CSR、CNN和LATLRR方法的融合結果人物目標暗淡,對比度較差。GTF、GF和CNN方法能夠有效地保留清晰的人物目標。然而,GTF方法的融合結果背景模糊,GF方法的融合結果中庭院過度光滑,細節紋理不清晰。本文方法既保留紅外圖像中顯著的人物目標和屋頂的煙囪,又保留了可見光圖像中充足的背景信息,圖像整體視覺效果較好。為了進一步客觀評價融合算法的性能,表1列出了Kaptein圖像融合結果的客觀評價指標數值結果。從表中可以看出本文方法的EN、MI、SD、SCD和QY五項指標值都高于其他對比算法。
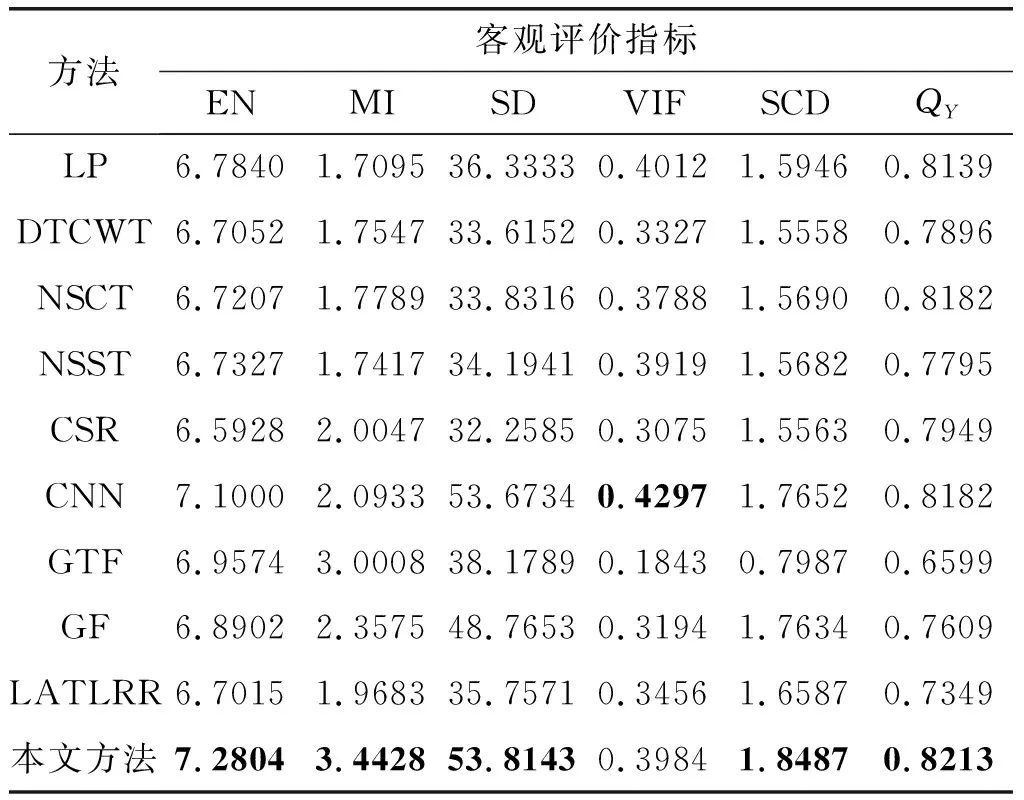
表1 Kaptein圖像的客觀評價指標
表2列出了不同融合方法在3組數據集上的運行時間。對于Nato-camp和Bristol Eden Project數據集,表2所列為不同融合方法在32幅圖像數據上的平均計算時間。對于Nato-camp數據集,LP、DTCWT、GTF與GF方法的計算時間均小于1 s,NSCT與NSST方法的計算時間略大于1 s,CSR、CNN、LATLLR與本文方法的計算時間遠大于1 s。對于Bristol Eden Project和Kaptein數據集,LP、DTCWT與GF方法的計算時間均小于1 s,NSCT、NSST和GTF方法的計算時間略大于3 s,CSR、CNN、LATLLR與本文方法的計算時間遠大于3 s。總之,相比于多尺度融合方法,如LP、DTCWT、NSCT、NSST、GTF和GF,本文方法的計算復雜度更高。然而,相較于CSR、CNN和LATLRR等方法,本文方法的計算復雜度較低。

表2 不同融合方法的運行時間 (s)
5 結論
針對傳統紅外與可見光圖像融合算法在融合圖像中細節信息丟失、顯著目標不清晰和對比度低等問題,充分考慮紅外與可見光圖像的相關性,提出了一種基于聯合低秩稀疏分解的紅外與可見光圖像融合方法。通過聯合低秩稀疏分解可以有效地將圖像目標與背景分離。設計合適融合規則實現了特有低秩分量和特有稀疏分量的有效融合。實驗結果表明本文方法獲得的融合圖像目標清晰,細節豐富,在主觀視覺和客觀評價指標上都優于對比方法。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
家庭影院技術(2020年10期)2020-12-14 07:53:50
現代出版(2020年3期)2020-06-20 07:10:34
小學生優秀作文(低年級)(2018年10期)2018-10-13 01:56:50
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2016年10期)2016-11-29 19:59:58
中外會展(2014年4期)2014-11-27 07:46:46
現代青年·細節版(2006年1期)2006-05-24 18:11:28
