基于2,1范數(shù)和神經(jīng)網(wǎng)絡(luò)的非線性特征選擇方法
2021-09-29 02:25:38范馨予徐雪遠(yuǎn)
信號(hào)處理 2021年9期
范馨予 徐雪遠(yuǎn) 鄔 霞
(北京師范大學(xué)人工智能學(xué)院, 北京 100875)
1 引言
隨著機(jī)器學(xué)習(xí)的發(fā)展,學(xué)習(xí)任務(wù)的特征維度不斷增加[1-3]。而在高維特征數(shù)據(jù)中,與任務(wù)不相關(guān)的特征數(shù)據(jù)或噪聲特征數(shù)據(jù)存在的規(guī)模也不斷增加[4]。這些特征數(shù)據(jù)不僅會(huì)降低學(xué)習(xí)任務(wù)的性能和效率,還會(huì)給結(jié)果的解釋增加困難性。為了解決上述問題,特征選擇和特征壓縮變換常被用來(lái)降低特征的規(guī)模[5]。相較于特征壓縮變換,特征選擇能夠不改變?cè)继卣鞯奈锢韺傩约皵?shù)據(jù)結(jié)構(gòu),更加有利于保留學(xué)習(xí)任務(wù)的可解釋性[6]。
按照特征選擇模型和學(xué)習(xí)任務(wù)模型的關(guān)系來(lái)說(shuō),特征選擇算法可分為過濾式(filter)特征選擇算法、包裹式(wrapped)特征選擇算法以及嵌入式(embedded)特征選擇算法[7]。過濾式特征選擇算法通過某一種法則計(jì)算所有特征的權(quán)值,并根據(jù)權(quán)值大小排列挑選出重要的特征,例如ReliefF,拉普拉斯分?jǐn)?shù)(Laplacian Score, LS)[8]和最小冗余最大相關(guān)算法(Minimum Redundancy Maximum Relevance, mRMR)[9];包裹式特征選擇算法將所有特征分成不同的子集,用分類器對(duì)所有子集進(jìn)行評(píng)價(jià),挑選分類性能最好的特征子集作為最終的特征選擇結(jié)果,例如序列特征選擇(Sequential Feature Selection, SFS)算法[10]和遺傳算法(Genetic Algorithm, GA)[11];嵌入式特征選擇算法則是將特征選擇的過程和學(xué)習(xí)的過程結(jié)合在一起,在模型訓(xùn)練的過程中篩選出與任務(wù)相關(guān)的重要特征,例如線性判別分析(Linear Discriminant Analysis, LDA)[12],最小二乘法(Least Square Method, LSM)[13],和隨機(jī)森林(Random Forests, RF)[14]。對(duì)于這三類特征選擇算法來(lái)說(shuō),過濾式算法的特征選擇過程與分類學(xué)習(xí)過程相互獨(dú)立,挑選的特征子集往往不是最佳的特征子集;包裹式特征選擇算法由于依賴分類器來(lái)評(píng)價(jià)所有特征子集的性能,因此計(jì)算復(fù)雜度較高。而嵌入式特征選擇算法將特征選擇的過程融入分類模型的構(gòu)建中,能夠挑選出分類準(zhǔn)確率較高的子集。
通常,正則化嵌入式特征選擇算法在目標(biāo)函數(shù)中加入懲罰項(xiàng)進(jìn)行約束,來(lái)對(duì)目標(biāo)函數(shù)的求解加以引導(dǎo)[5]。在目標(biāo)函數(shù)構(gòu)建中挑選符合學(xué)習(xí)任務(wù)的懲罰項(xiàng),能夠?qū)ψ罱K的分類結(jié)果帶來(lái)積極的影響。其中,最常使用的約束項(xiàng)p范數(shù),因此對(duì)于p范數(shù)的正則化是當(dāng)前研究熱點(diǎn)。例如,Hoerl等人提出了基于2范數(shù)的有偏估計(jì)嶺回歸,其中的2范數(shù)對(duì)所有系數(shù)計(jì)算平方和根,因此該方法對(duì)于誤差較大的離群值十分敏感[15]。但對(duì)于結(jié)構(gòu)相似的特征子集,2范數(shù)無(wú)法收縮系數(shù)得到稀疏解。為解決該問題,Tibshirani等人提出了基于1范數(shù)的最小絕對(duì)值收斂和選擇算子(LASSO)算法[16]。1范數(shù)采用正則化系數(shù)的絕對(duì)值進(jìn)行求和,能夠?qū)⒋蟛糠值南禂?shù)收縮至零[17]。因此,基于1范數(shù)的模型能得到稀疏解。而1范數(shù)的模型只能解決單個(gè)任務(wù)的特征選擇問題,并且對(duì)噪聲數(shù)據(jù)十分敏感。G.Obozinski等人針對(duì)該問題提出了一種將1范數(shù)和2范數(shù)結(jié)合的聯(lián)合2,1范數(shù)[18]。隨后,Lai等人提出了一種魯棒的局部判別分析方法,用2,1范數(shù)代替2范數(shù)構(gòu)造類間散布矩陣。同時(shí),他們?cè)谕队熬仃嚿鲜┘恿?,1范數(shù),以保證聯(lián)合稀疏性和魯棒性[19]。Yang等人提出了一種將LDA和2,1范數(shù)正則化相結(jié)合的特征選擇方法來(lái)實(shí)現(xiàn)特征選擇。在這種方法中,他們使用2,1范數(shù)項(xiàng)對(duì)變換矩陣的行施加稀疏約束[20]。2,1范數(shù)利用組內(nèi)和組間的聯(lián)合關(guān)系,在全局的范圍內(nèi)使關(guān)聯(lián)特征之間的系數(shù)為零,保證了系數(shù)的稀疏性和可解釋性。因此,2,1范數(shù)在特征選擇領(lǐng)域得到了廣泛的應(yīng)用[21]。
為了將重點(diǎn)落在原理的實(shí)現(xiàn)上,我們選擇了最基礎(chǔ)的后向傳播神經(jīng)網(wǎng)絡(luò)(Back Propagation,BP)結(jié)構(gòu),且只使用了一層隱藏層。因此,神經(jīng)網(wǎng)絡(luò)的模型只由輸入層,隱藏層和輸出層構(gòu)成。本章節(jié)使用的各參數(shù)定義如表1所示。

表1 各參數(shù)定義
一般來(lái)說(shuō),BP神經(jīng)網(wǎng)絡(luò)的正向傳播過程的輸出如公式(1)所示:
(1)
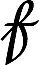
(2)
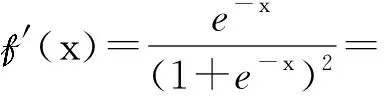
(3)
為了使模型更適合多分類任務(wù),且避免概率分值不平衡,我們采用交叉熵?fù)p失函數(shù)作為神經(jīng)網(wǎng)絡(luò)的損失函數(shù),將最大概率輸出為輸出。交叉熵?fù)p失定義函數(shù)為:
(4)
同時(shí),輸出層的激活函數(shù)配合使用softmax函數(shù):
(5)
(6)
其中,λ為正則化參數(shù),防止過擬合。且2,1范數(shù)表示為:
(7)
其中,a為w的總列數(shù),b為w的總行數(shù)。因此,最終的求解問題表示為:
(8)
對(duì)于||W||2,1矩陣的偏導(dǎo)數(shù)的求解過程可表示為:
(9)
經(jīng)過每一次前向傳播和后向傳播的迭代,輸出與真實(shí)標(biāo)簽之間的誤差會(huì)越來(lái)越小,此時(shí)設(shè)定迭代收斂的最小閾值來(lái)終止學(xué)習(xí)過程。為了直觀地反映特征選擇的結(jié)果,最后計(jì)算了權(quán)重矩陣W的2范數(shù)。綜上所述,我們將本文提出的方法命名為BPFS。
3 實(shí)驗(yàn)及結(jié)果分析
3.1 實(shí)驗(yàn)過程
為了評(píng)估BPFS的性能,我們將BPFS特征選擇方法與六種具有代表性的特征選擇方法進(jìn)行了比較,其中包括相關(guān)系數(shù)(Correlation Coefficient,CC)、ReliefF、mRMR經(jīng)典的特征選擇算法,以及通過線性方法優(yōu)化范數(shù)的RFS[23]、SDFS[26]和L21-RLDA[27]特征選擇算法。此外,選取公開的UCI數(shù)據(jù)集中的8個(gè)數(shù)據(jù)集對(duì)這些方法進(jìn)行了驗(yàn)證,八個(gè)數(shù)據(jù)集分別為Binalpha[28],Control[29],Corel5k[28],Crowdsowrced[30],Isolet[31],Movementlibras[32],Segment[28],Sensorless[33]。表2顯示了關(guān)于這些數(shù)據(jù)集的詳細(xì)信息。
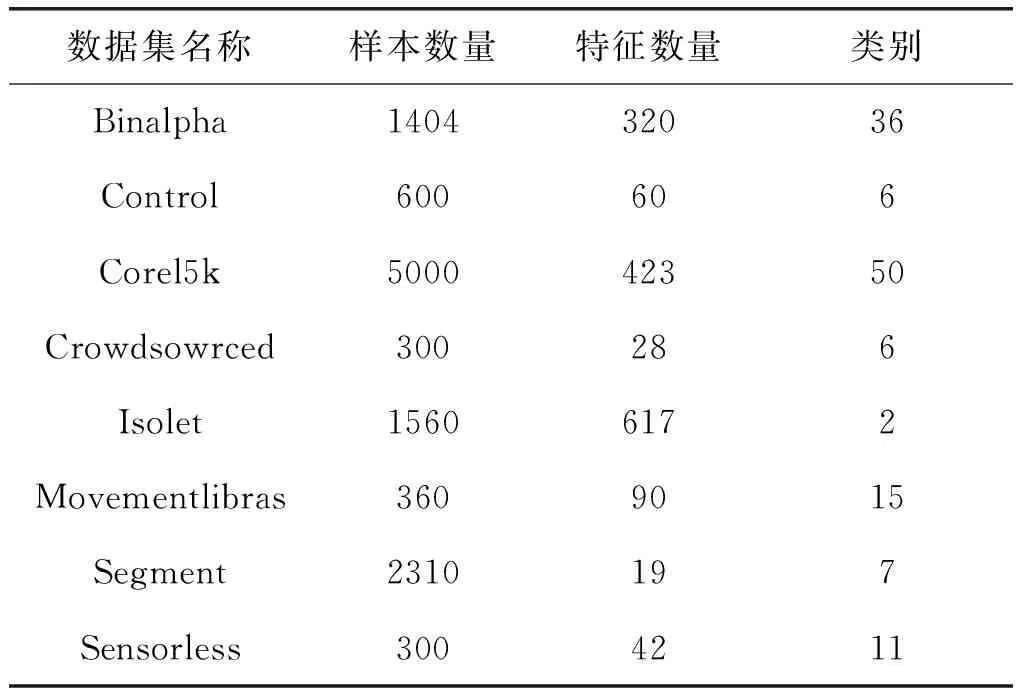
表2 各數(shù)據(jù)集信息
首先,我們使用七種特征選擇方法選擇不同數(shù)量下的特征。然后使用線性的支持向量機(jī)分類器(Support Vector Machine, SVM)和非線性的隨機(jī)森林(Random Forest,RF)分類器分別對(duì)各結(jié)果進(jìn)行分類,并且每次按照取百分之七十的數(shù)據(jù)作為訓(xùn)練集,剩下的數(shù)據(jù)作為測(cè)試集,重復(fù)多次取平均值作為分類準(zhǔn)確度。為了提高效率,直接將數(shù)據(jù)集的所有樣本和特征構(gòu)成的矩陣作為輸入傳入輸入層。需要注意的是,所有數(shù)據(jù)集都被零均值標(biāo)準(zhǔn)化。對(duì)于每次的分類結(jié)果,計(jì)算并記錄平均準(zhǔn)確度以及收斂性來(lái)檢驗(yàn)所提出方法的性能。所有代碼均在MATLAB上實(shí)現(xiàn),其中SVM分類器是由LIBSVM工具箱實(shí)現(xiàn)的,RF分類器是使用內(nèi)置函數(shù)實(shí)現(xiàn)。
3.2 實(shí)驗(yàn)結(jié)果及分析
算法的收斂速度能力一定程度反應(yīng)了算法的效率和穩(wěn)定性。為了加快計(jì)算速度和方便比較,將BP神經(jīng)網(wǎng)絡(luò)特征選擇過程的迭代次數(shù)設(shè)為常數(shù)2500,各數(shù)據(jù)集收斂情況如圖1所示。
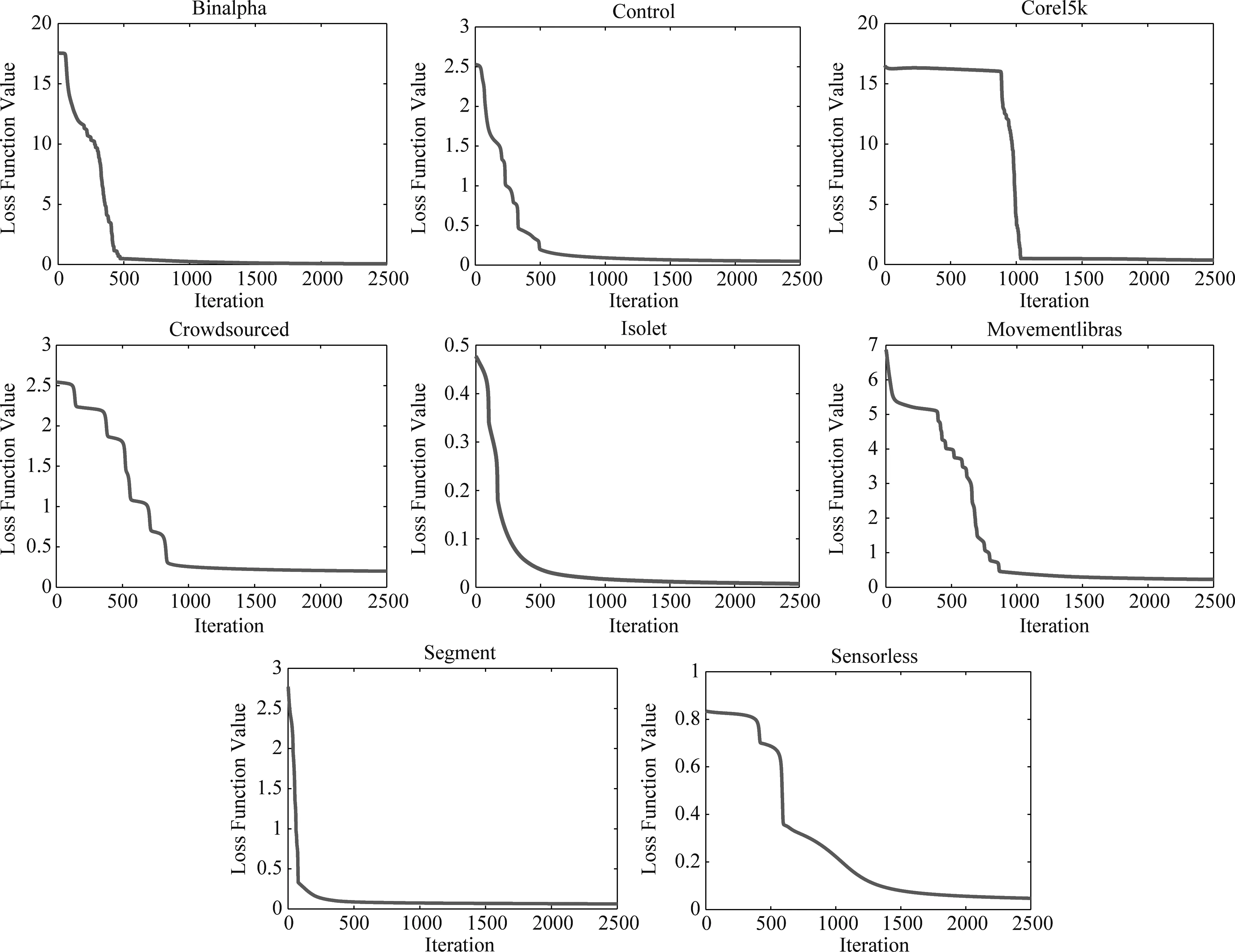
圖1 BPFS在各數(shù)據(jù)集中的收斂結(jié)果Fig.1 Iteration results of BPFS in all dataset
可以看到,在迭代2500的時(shí)候,所有數(shù)據(jù)集都很好的實(shí)現(xiàn)了收斂。大部分的數(shù)據(jù)在迭代次數(shù)為500至1000左右時(shí)實(shí)現(xiàn)了收斂,其中收斂效果最好的是Segment數(shù)據(jù)集,在迭代次數(shù)不到500時(shí)實(shí)現(xiàn)收斂。而Sensorless數(shù)據(jù)集收斂稍慢些,到近2000次迭代才收斂。因此,BPFS具備達(dá)到局部極小值的可能性。
圖2和表3展示了SVM分類器下的7種算法在各數(shù)據(jù)集上的不同維度的分類準(zhǔn)確度和所有維度下的平均分類準(zhǔn)確度。
從圖2可以看到,不同數(shù)據(jù)集各算法的分類準(zhǔn)確度結(jié)果,每種方法的精度隨著選擇的特征數(shù)量增加變得更加精確。在SVM的結(jié)果中,BPFS算法在部分?jǐn)?shù)據(jù)集中得到的分類結(jié)果相較其他算法具有一定的優(yōu)勢(shì),并且在很多數(shù)據(jù)集結(jié)果中都是最先趨于平滑,快速地調(diào)整誤差并選擇有更具有代表的特征。不過需要注意的是,在Control,Crowdsourced和Movementlibras數(shù)據(jù)集中,BPFS算法并未取得明顯的優(yōu)勢(shì),尤其在Control和Crowdsourced數(shù)據(jù)集中提取的特征數(shù)量增長(zhǎng)中后期。可能因?yàn)楸疚倪M(jìn)行實(shí)驗(yàn)的BPFS使用的是簡(jiǎn)單基礎(chǔ)的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),對(duì)于特征量龐大的數(shù)據(jù)集需要更深的網(wǎng)絡(luò)來(lái)實(shí)現(xiàn)更好的擬合。另外,結(jié)合表3所有維度平均分類準(zhǔn)確度中的方差來(lái)看,BPFS算法在所有數(shù)據(jù)集中都取得了十分小的方差,因此,BPFS算法相較于其他算法具有更好的穩(wěn)定性。
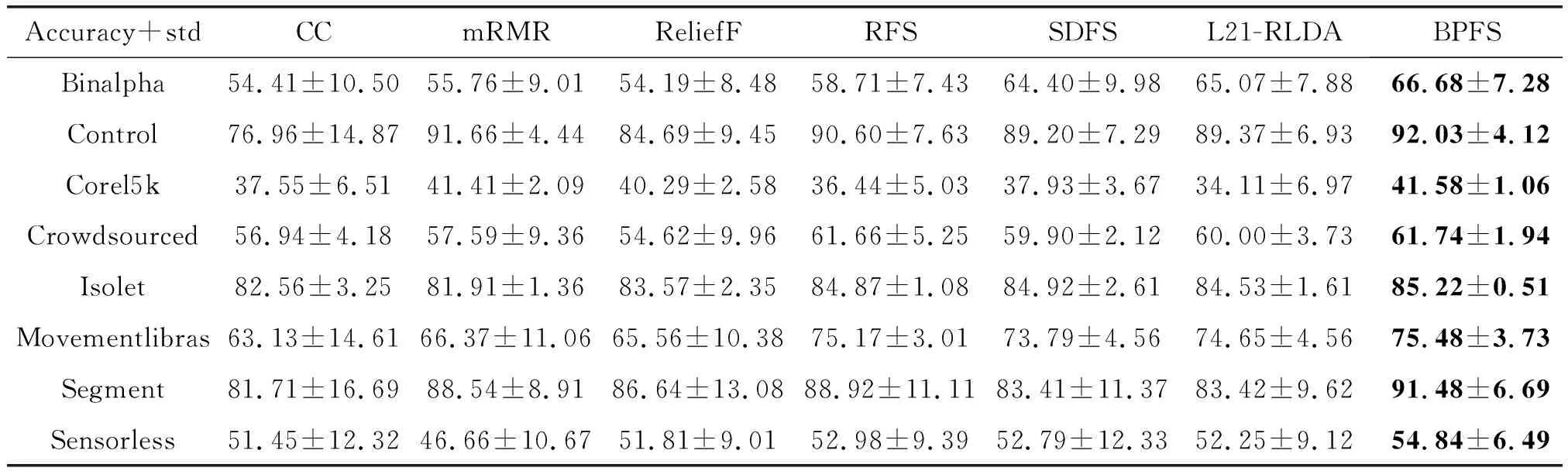
表3 七種特征選擇方法在SVM分類器下的平均分類準(zhǔn)確率和方差(%),其中加粗的是該數(shù)據(jù)集下準(zhǔn)確率最高的方法
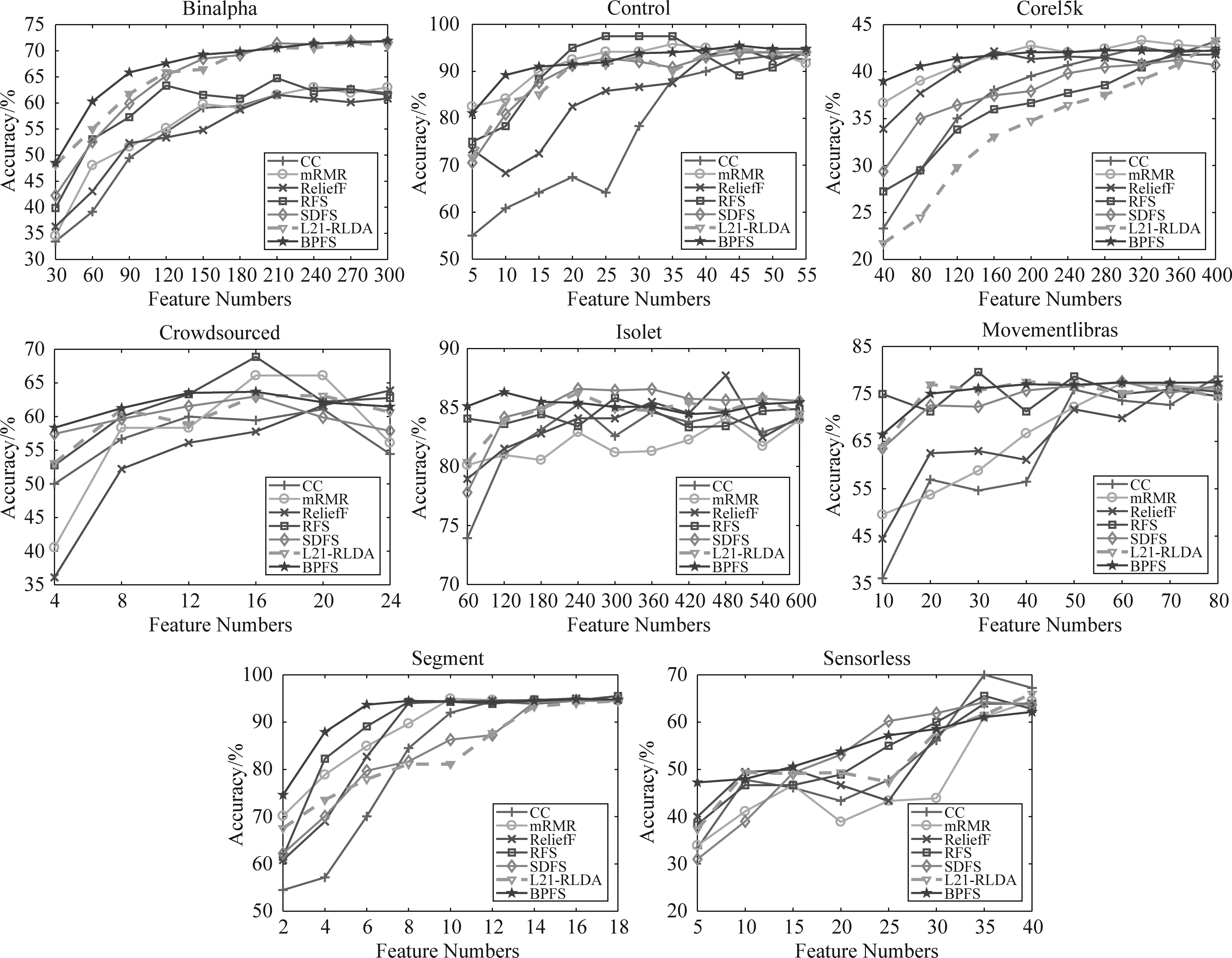
圖2 7種算法在SVM分類器下各數(shù)據(jù)集上的分類準(zhǔn)確度Fig.2 Accuracy result of seven algorithm in SVM
同理,我們可以得到在RF分類器下的7種算法在各數(shù)據(jù)集上的不同維度的分類準(zhǔn)確度和所有維度下的平均分類準(zhǔn)確度,如圖3和表4所示。
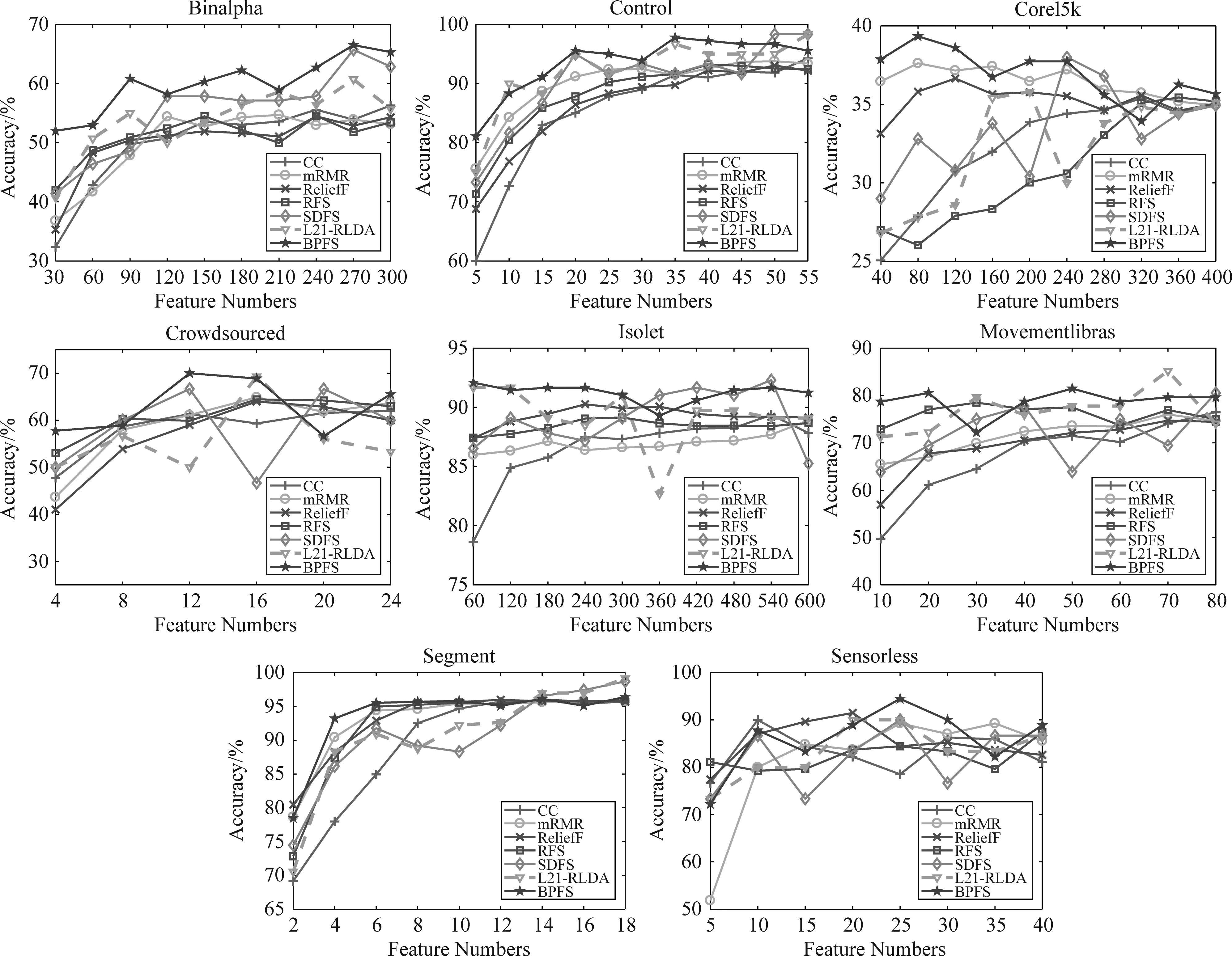
圖3 7種算法在RF分類器下各數(shù)據(jù)集上的分類準(zhǔn)確度Fig.3 Accuracy result of seven algorithm in RF
在圖3中可以看到BPFS算法在大部分的數(shù)據(jù)集中取了不錯(cuò)的結(jié)果,而在表4中可以看到BPFS算法在所有的數(shù)據(jù)集中得到了最高的平均分類準(zhǔn)確度。因此,基于非線性結(jié)構(gòu)的BPFS在不同的數(shù)據(jù)集中能夠發(fā)揮較好的作用,在神經(jīng)網(wǎng)絡(luò)的協(xié)助下選擇出更重要的特征。
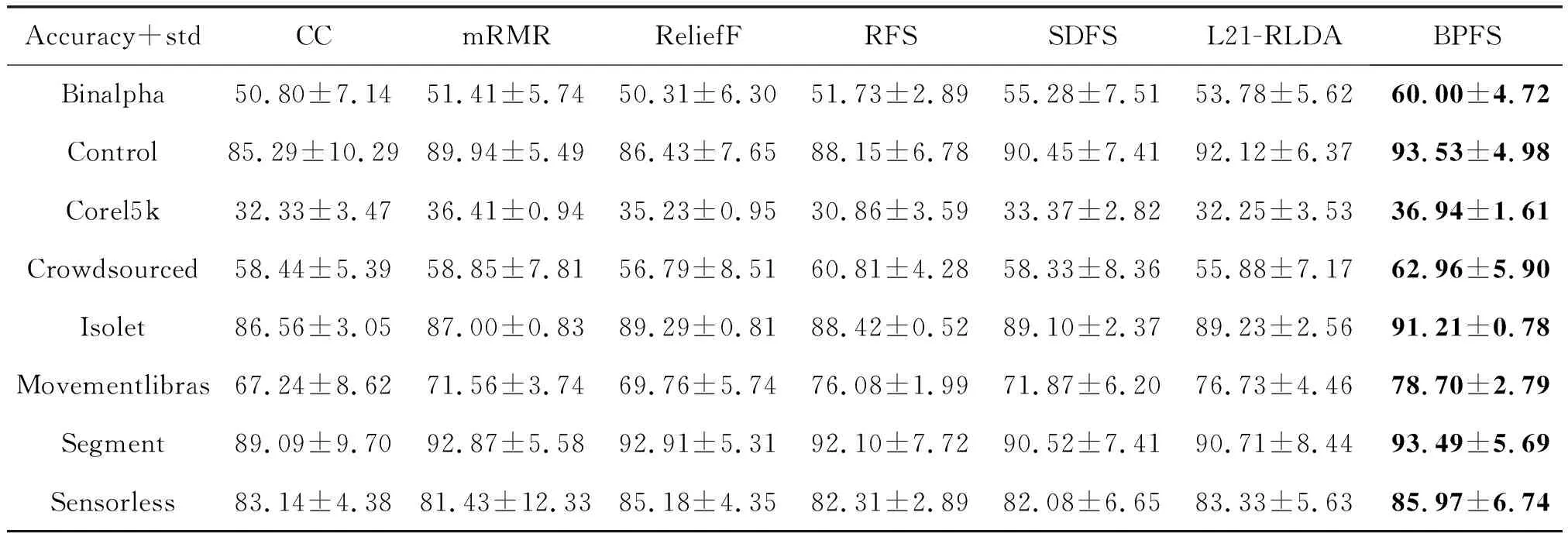
表4 七種特征選擇方法在RF分類器下的平均分類準(zhǔn)確率和方差(%),其中加粗的是該數(shù)據(jù)集下準(zhǔn)確率最高的方法
結(jié)合表3和表4分析BPFS算法在SVM分類器和RF分類器下的結(jié)果可以得到,RF分類器下BPFS的結(jié)果在大部分?jǐn)?shù)據(jù)集上比SVM分類器下BPFS的結(jié)果高,只有在Corel5k數(shù)據(jù)集上低于SVM分類器。這可能因?yàn)镃orel5k數(shù)據(jù)集中的相關(guān)聯(lián)的特征較多,線性的SVM分類器能夠更好地處理這些線性特征。同理,在Sensorless數(shù)據(jù)集的結(jié)果中可以看到,RF分類器下所有算法的平均分類準(zhǔn)確度都要遠(yuǎn)遠(yuǎn)高于SVM分類器下所有算法的平均分類準(zhǔn)確度。這兩個(gè)數(shù)據(jù)集在SVM分類器和RF分類器下造成的差異的原因可能是因?yàn)镾ensorless數(shù)據(jù)集中的特征結(jié)構(gòu)是非線性的結(jié)構(gòu),且冗余特征較多,因此在RF分類器中都取得了不錯(cuò)的表現(xiàn)。
4 結(jié)論
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
意林原創(chuàng)版(2016年10期)2016-11-25 10:28:30
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
