基于主輔網絡特征融合的語音情感識別
2021-09-22 08:03:24胡德生張雪英李寶蕓
太原理工大學學報 2021年5期
胡德生,張雪英,張 靜,李寶蕓
(太原理工大學 信息與計算機學院,太原 030024)
語言是人類交流最方便、最快捷的方式,語言中包含的情感信息在交流時發揮著重要作用。讓機器像人一樣具備說話、思維和情感能力,是人工智能領域一直追求的目標。語音情感識別的研究,將推動這一目標的逐步實現。
典型的語音情感識別模型由語音情感數據庫、特征提取和識別3部分組成[1],提取有效情感特征是語音情感識別的關鍵。傳統的語音情感識別首先分幀提取Mel頻率倒譜系數(Mel frequency cepstral coefficients,MFCC)等聲學特征,然后提取所有幀的最大值、最小值、均值、方差等統計特征作為語音信號的全局特征[2-4]。由于全局特征是在句子級別上提取統計特征,所以其只能粗略反映語音情感隨時間變化的特性。針對這個問題,段特征的概念被提出,首先將語音信號分段,每段包含若干幀語音,對這若干幀語音各自提取聲學特征后,再計算這段語音的多個統計特征作為段特征。文獻[2]將段特征直接輸入基于注意力機制的長短時記憶單元(long short-term memory,LSTM)網絡提取深度特征并分類,與全局特征相比取得了較好的效果。
語譜圖是一維語音信號在二維時頻域的展開,能夠充分反映語音信號在時頻域大部分信息。卷積神經網絡(convolutional neural networks,CNN)由于其自動學習特征的能力和適用于二維圖像數據的特點,目前被廣泛用在語譜圖中提取特征,進一步提高語音情感識別性能[5-8]。如文獻[8]先將語譜圖輸入全卷積網絡(fully convolutional networks,FCN),并在最后一層卷積層使用注意力機制,最后進行情感識別,在IEMOCAP數據集上其WA(weighted accuracy)和UA(unweighted accuracy)分別達到70.4%,63.9%.
近年來,國內外學者提出多種混合網絡模型用于將不同類型的特征進行特征融合,提升了語音情感識別的性能[9-11]。文獻[9]提出HSF-CRNN模型,采用CRNN網絡對語譜圖提取深度特征,將全局特征輸入全連接層,最后將兩者拼接進行情感識別;文獻[10]提出Attention-BLSTM-FCN模型,在Mel語譜圖上分別應用Attention-BLSTM網絡和Attention-FCN網絡,然后將兩個網絡提取的深度情感特征以直接拼接的方式進行特征融合,最后輸入全連接層進行分類識別。雖然這些方法取得了一定的效果,但將不同類型的特征簡單拼接起來作為識別網絡的輸入,沒有考慮不同特征的量綱和維度的差異,以及各類型特征實際物理意義的不同,會對識別結果帶來不利影響。
針對上述問題,本文提出了通過主輔網絡方式將不同類別特征進行融合的方法。首先將段特征輸入BLSTM-Attention網絡作為主網絡,提取深度段特征;然后,把Mel語譜圖輸入CNN-GAP網絡作為輔助網絡,提取深度Mel語譜圖特征;最后,用深度Mel語譜圖特征輔助深度段特征,將兩者以主輔網絡方式進行特征融合。在IEMOCAP數據集上的實驗結果表明,使用主輔網絡深度特征融合的WA和UA分別達到74.45%、72.50%,比將特征直接拼接的WA和UA分別提高了1.24%、1.15%.
1 不同類別的特征提取
1.1 段特征提取
1) 語音信號采樣率為16 kHz,分幀處理時取窗長256,窗移128;
2) 使用截斷或補零的方式使所有語音長度為1 000幀;
3) 計算每一幀信號的平均過零率、能量、基音頻率、共振峰、MFCC,共18維聲學特征[12];
4) 每5幀組成一段[13],共200段。計算一段內聲學特征的最大值、最小值、平均值、中值和方差等統計特征,得到一段信號的18×5=90維特征;
5) 標準化處理,得到每一句情感語音信號的90×200的段特征,段內的聲學特征如表1所示。

表1 段內的聲學特征及其統計類型Table 1 Acoustic feature and statistical feature within a segment
1.2 Mel語譜圖生成
首先對語音信號進行STFT變換,使用漢明窗,窗長256,窗移128.
大量實驗表明人耳聽到的聲音高低和實際頻率(Hz)不呈線性關系,Mel頻率更加符合人耳的聽覺特性,Mel頻率fMel和Hz頻率f的關系如式(1)所示。
(1)
然后通過40階Mel濾波器組得到Hm(k),再將Hm(k)×|X(k)|2求和得到Mel語譜圖。
Mel濾波器組的輸出計算如式(2)所示,每個濾波器具有三角濾波特性,
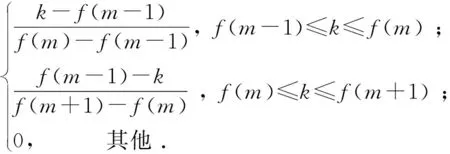
(2)
式中:f(m)為中心頻率,m表示Mel濾波器的階數;k表示FFT中點的編號。
Mel語譜圖計算如式(3)所示,
(3)
其中,|X(k)|2表示頻譜能量。
最后使用截斷補零的方式使所有Mel語譜圖大小對齊,得到大小為40×432的Mel語譜圖。
1.3 基于BLSTM-Attention的深度段特征提取
LSTM適合對序列問題進行建模,因此被廣泛應用在語音識別和語音情感識別中。BLSTM由正向LSTM和反向LSTM組成。BLSTM不僅可以考慮輸入數據以前的信息,還可以考慮輸入數據未來的信息,可以更好地對序列問題進行建模。采用BLSTM對段特征進行建模可以提取考慮上下文情感信息的深度情感特征。本文使用兩層BLSTM,隱藏神經元個數為300,為了減輕過擬合使用dropout,棄權率為0.5.
通過對BLSTM輸出應用注意力機制可以關注輸入的情感語音信號中更顯著的情感片段,增強BLSTM網絡提取顯著深度段特征的能力。更具體地說,以LSTM為核心的識別器在時間上展開的長度是T,則LSTM在每一時刻都對應一個輸出。相比于平均池化輸出和最后時刻輸出,注意力機制可以兼顧LSTM層每一時刻的輸出,其對LSTM網絡每一時刻的輸出分配不同的權重來考慮上下文情感信息的深層特征。注意力機制的具體計算如式(4)所示:
(4)
式中:st∈RD是輸入序列的某一元素;T表示LSTM的某一時刻;αt為加權系數。加權系數可以通過式(5)、(6)算出,并通過網絡訓練進行更新。
αt=softmax(βt) .
(5)
(6)
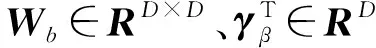
1.4 基于CNN-GAP的深度Mel語譜圖特征提取
由于CNN適合于二維圖像數據,而Mel語譜圖是一維語音信號在二維時頻域的展開,因此CNN可以用來在Mel語譜圖上提取深度特征。CNN由卷積層和池化層組成,卷積層用來提取特征,池化層用來降低網絡規模和過擬合,通常采用最大值池化或均值池化。
Mel語譜圖是一維語音信號在二維時頻域的展開,能夠充分反映語音信號在時頻域大部分信息。針對Mel語譜圖的這一特點,可以分別在時間軸和頻率軸設計較大的卷積核,提取Mel語譜圖的頻率和時間特性,進而提取顯著的情感特征。設計的卷積神經網絡結構如圖1所示。
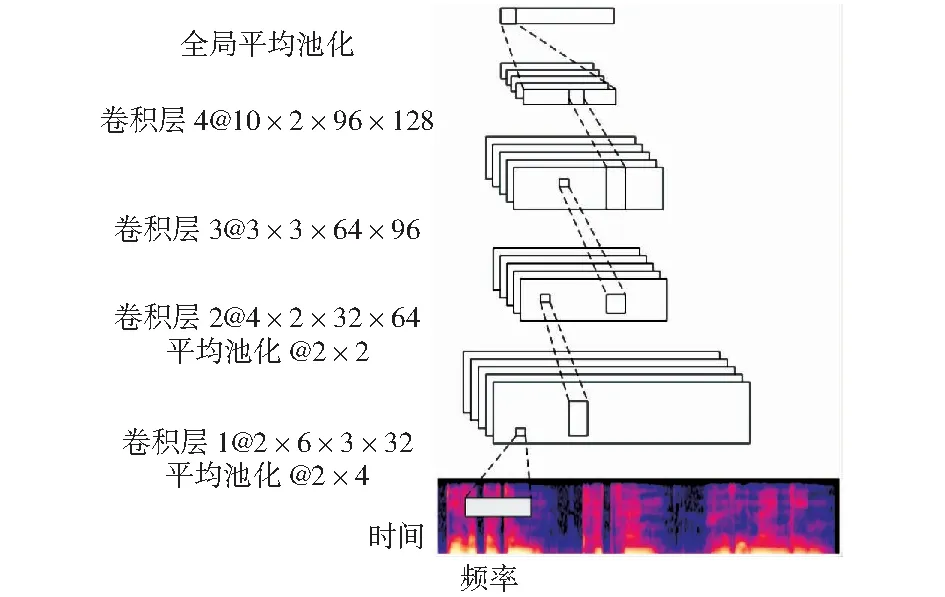
卷積核大小表示為長×寬×輸入通道×輸出通道,池化層大小表示為長×寬圖1 設計的卷積神經網絡結構Fig.1 Design of the convolutional neural network structure
第一層卷積層在時間軸上設計較大的卷積核,提取Mel語譜圖的時間特性;第二層卷積層在頻率軸上設計較大的卷積核,提取Mel語譜圖的頻率特性;第三層卷積層使用3×3卷積核;第四層卷積層在頻率軸上使用全卷積,最后再使用全局平均池化(global average pooling,GAP).用GAP代替全連接層可以減輕過擬合,使網絡易于訓練。每一層卷積層都使用了批歸一化(batch normalization,BN)以及Relu激活函數。具體網絡參數經過調參得到。
2 主輔網絡特征融合模型
2.1 主輔網絡特征融合的網絡結構
將段特征輸入BLSTM-Attention網絡提取了深度段特征,將Mel語譜圖輸入CNN-GAP網絡提取深度Mel語譜圖特征,通常將兩者以直接拼接的方式進行特征融合,但是沒有考慮不同特征的量綱和維度的差異,會對識別結果帶來不利影響。因此,本文提出基于主輔網絡特征融合的語音情感識別。
主輔網絡特征融合的網絡結構如圖2所示。傳統聲學特征以時域特征為主,具有明確的物理意義,因此將其作為主網絡輸入特征。主網絡是基于BLSTM-Attention的深度段特征提取模塊,輔助網絡是基于CNN-GAP的深度Mel語譜圖特征提取模塊,兩者以主輔網絡方式組成特征融合網絡。主網絡分為上、下兩部分,MU代表上半部分,由全連接層構成;MD代表下半部分,由BLSTM-Attention網絡構成。e0表示語音段特征,經標準化后作為主網絡的輸入;hl代表主網絡MD部分的輸出,是深度段特征,維度是600.輔助網絡由CNN-GAP網絡構成,v0表示Mel語譜圖,作為輔助網絡輸入,vM表示輔助網絡GPA的輸出,輔助網絡FC層的Wc是控制參數(為了簡化描述,省略了輔助網絡FC層偏置項),也是權重,維度是128×200.一方面在主網絡參數更新時可以控制輔助網絡參數不更新;另一方面是對vM進行特征變換。Concate表示hl與WcvM直接拼接,并輸入主網絡的MU上半部分,其中hl表示BLSTM-Attention網絡提取的深度段特征,vM表示CNN-GAP網絡提取的深度Mel語譜圖特征,Wc表示控制主輔網絡訓練的參數。然后將Concate拼接結果通過FC層做進一步特征融合,最后使用Softmax進行分類。
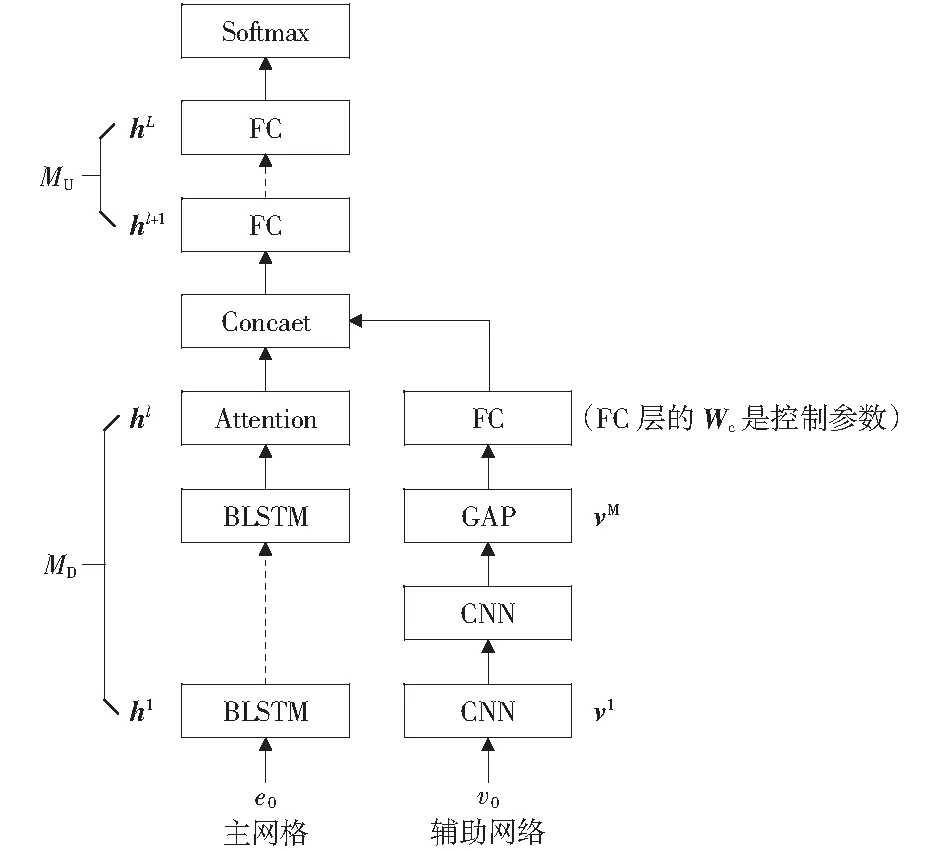
圖2 主輔網絡特征融合的結構模型Fig.2 A structural model of feature fusion of main-auxiliary networks
2.2 主輔網絡特征融合參數傳遞及更新
本文提出的基于主輔網絡特征融合的語音情感識別模型,最重要的是網絡訓練過程,也就是誤差反傳參數更新的過程,主輔網絡特征融合參數傳遞示意圖如圖3所示。
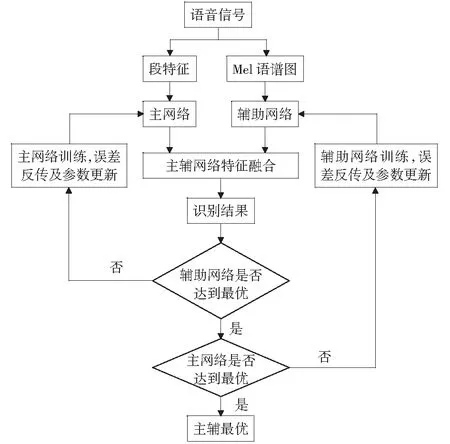
圖3 主輔網絡特征融合參數傳遞及更新Fig.3 Transfer and update of main-auxiliary network feature fusion parameters
由于輔助網絡的加入,網絡的訓練被分為三步:
1) 參數初始化。將語音段特征e0輸入主網絡,將Mel語譜圖v0輸入輔助網絡;然后將控制參數Wc初始化為0,主網絡和輔助網絡的權重和偏置通過截斷正太分布隨機初始化。
2) 主網絡訓練。首先通過控制Wc和網絡設置使輔助網絡不起作用,然后使用梯度下降算法和反向傳播算法訓練主網絡使主網絡MD和MU參數更新。
3) 輔助網絡訓練。首先將主網絡MD和MU的權重和偏置設置為不更新,將輔助網絡的權重、偏置和Wc設置為更新;使用梯度下降算法和反向傳播算法訓練輔助網絡使輔助網絡參數和Wc更新。
下面介紹輔助網絡的一些參數更新。主輔網絡最后一層輸出拼接向量為hl,具體的拼接公式如式(7)所示:
hl=hl+WcvM.
(7)
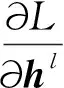
(8)
(9)
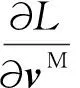
3 實驗及結果
3.1 實驗數據庫及網絡參數設置
本文使用美國南加州大學發布的英文情感數據集IEMOCAP(the interactive emotional dyadic motion capture database).該數據集由5個會話組成,每個會話由一對說話者(女性和男性)在預先設定的場景和即興場景中對話。本文使用即興場景對話中的語句,選取4種情感,分別是高興、悲傷、憤怒、中性,共2 046條語句。
本文使用tensorflow深度學習框架,以本文提出的網絡模型為例,通過多次實驗確定網絡參數如下:主網絡學習率為0.000 5,輔助網絡學習率為0.001;主網絡minibatch大小為96,輔助網絡minibatch大小為48;主輔網絡均使用Adam優化器。
3.2 實驗結果及分析
本文采用情感識別領域常見的兩種評價指標:加權準確率WA和非加權準確率UA.WA衡量了語音情感識別系統的總體性能,其計算方式為正確分類的樣本數量除以樣本總數;UA衡量所有類別的識別性能,其計算方式為各類的分類準確率再除以類別數。本文采用分層五折交叉方式驗證模型預測效果,使用樣本的80%進行訓練,20%進行測試,最后對5次預測結果取平均。為了評價本文所提算法的有效性,對5種識別模型在IEMOCAP數據集上進行了對比實驗,結果如表2所示。
下面對5種識別模型的輸入特征進行說明。
BLSTM:將段特征輸入BLSTM網絡進行特征提取,然后輸入Softmax分類器進行語音情感識別。
BLSTM-Attention:將段特征輸入BLSTM-Attention網絡進行特征提取,然后輸入Softmax分類器進行語音情感識別。
CNN-GAP:將Mel語譜圖輸入CNN-GAP網絡進行特征提取,然后輸入Softmax分類器進行語音情感識別。
Concate Network:將段特征輸入基于BLSTM-Attention網絡,將Mel語譜圖輸入CNN-GAP網絡,再將兩者以直接拼接的方式進行特征融合,最后輸入Softmax分類器進行語音情感識別。
Our Methods:本文提出的主輔網絡特征融合識別模型,先將段特征輸入基于BLSTM-Attention網絡,將Mel語譜圖輸入CNN-GAP網絡,再將兩者以主輔網絡特征融合的方式進行特征融合,最后輸入Softmax分類器進行語音情感識別。
由表2可知,Our Methods的WA和UA比BLSTM-Attention分別提高3.20%,3.08%;比CNN-GAP分別提高3.68%,4.02%;比Concate Network分別提高1.24%,1.15%.表明使用兩種特征融合比單獨使用一種特征更有效,且主輔網絡特征融合方式的識別結果比直接拼接方式特征融合的識別結果更有效。
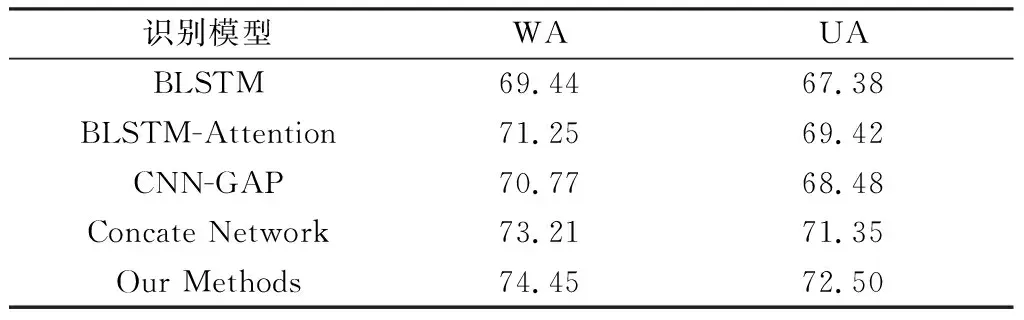
表2 5種識別模型在IEMOCAP數據集上的識別結果Table 2 Recognition results of the five recognition models on IEMOCAP dataset %
Our Methods的混淆矩陣如表3所示,中性、高興、悲傷、生氣情感的識別準確率分別為60.02%,78.15%,88.37%,63.51%,4種情感識別準確率均高于60%,進一步證明了Our Methods的有效性。
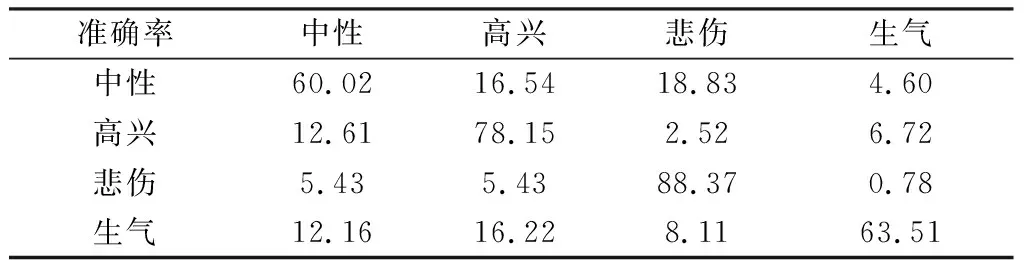
表3 Our Methods的混淆矩陣Table 3 Confusion matrix of Our Methods %
表4中列出了Our Methods和其他模型在 IEMOCAP數據集上研究的識別結果,識別模型均采用即興場景對話中的語句,選取了4種情感。從表4可以看出,Our Methods和其他模型相比取得了不錯的效果,比Attention-BLSTM-FCN模型[15]的WA和UA分別提高了6.35%和5.50%.
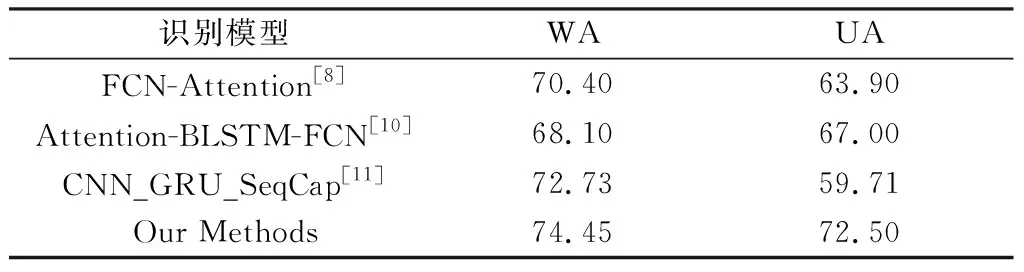
表4 Our methods和其他模型在IEMOCAP數據集上的識別結果Table 4 Recognition results of Our Methods and other models on IEMOCAP datasets %
4 結束語
情感的表達本身是一個很復雜的過程,涉及到心理以及生理方面的諸多因素,因此從語音信號中識別出情感信息是一個挑戰性的課題。本文將段特征輸入BLSTM-Attention網絡作為主網絡,把Mel語譜圖輸入CNN-GAP網絡作為輔助網絡,然后將兩個網絡提取的深度特征以主輔網絡方式進行特征融合,解決不同類型特征直接融合帶來的識別結果不理想的問題,并用實驗驗證了所提出模型的有效性。在今后的研究過程中,擬改進CNN-GAP網絡的最后一層的池化方式并將腦電信號作為輔助信號引入主輔網絡結構進行語音情感識別。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
