基于優化反饋的組合在線學習
2021-09-22 01:58:32孔芳楊悅然陳衛李帥
大數據 2021年5期
孔芳,楊悅然,陳衛,李帥
1. 上海交通大學約翰·霍普克羅夫特計算機科學中心,上海 200240;2. 微軟亞洲研究院,北京 100080
1 引言
隨著數據時代的來臨,傳統離線學習方法已難以快速處理模型訓練所需的爆發式增長的數據量及特征數量,這促進了在線學習模式的發展。在線學習方法接收實時數據流,定義累積懊悔(cumulative regret)取代損失函數作為新的優化函數,利用實時反饋不斷迭代調整算法,從而減少離線訓練所需的數據量,并提高處理效率。在許多實際問題中,最優解往往不是簡單的單個目標,而是多個目標的組合形式,這推進了對組合在線學習問題的研究。組合在線學習問題,即組合多臂老虎機(combinatorial multi-armed bandits,CMAB)問題,結合了在線學習與組合優化,研究如何在與環境交互的過程中自主學習未知參數,逐步找到最優的目標組合,其應用包括社交網絡中的廣告投放、搜索、推薦等問題。
2 組合在線學習問題
2.1 多臂老虎機問題
多臂老虎機(multi-armed bandits)問題是一個經典的機器學習問題,該問題最初由賭場的老虎機情景演變而來,被建模為玩家與環境之間的T輪在線游戲。老虎機共有m個臂(arm),m個臂的集合即玩家 的 動 作 集 合,記 為每個臂i∈[m]都有各自未知的獎勵分布,該分布的期望記作μi。玩家在每一輪游戲t∈[T]拉動其中一個臂,環境將從該臂的獎勵分布中采樣一個隨機變 量XAt,t,作為玩家拉動該臂的獎勵值。該獎勵值將幫助玩家更新對臂的獎勵分布的了解,進而更新其后續選擇臂的策略。玩家的目標是最大化T輪的累積期望收益,即最小化與最優臂之間的累積期望收益的距離。令表示最高期望收益,則玩家的目標為最小化累積期望懊悔:
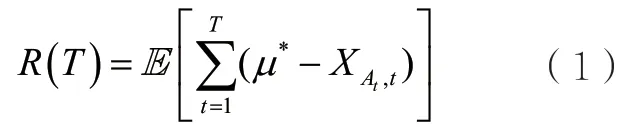
其中,期望取自獎勵值產生的隨機性及玩家策略的隨機性。
有時,玩家在每一輪收到的反饋不僅僅是其本輪拉動臂的獎勵(即強盜反饋(bandit feedback)),還可能觀察到所有臂的輸出,該反饋類型被稱為全反饋(full feedback)。玩家收到的反饋信息可用一個反饋圖(feedback graph)來表示,圖中每個節點表示一個臂,每條有向邊(i,j)表示當玩家拉動臂i時可觀察到臂j的輸出。全反饋類型的反饋圖可由完全圖表示,即每個節點有指向所有節點(包含自身)的邊;強盜反饋類型可用自環圖表示,即每個節點僅有指向自身的邊。反饋圖可進一步泛化,用于表示更復雜的反饋關系[1-2]。除有向圖外,矩陣也可用于描述反饋關系。部分監控(partial monitoring)[3]問題就使用反饋矩陣H來描述玩家可獲得的反饋信息,并使用損失矩陣L來刻畫玩家在游戲中的損失。若玩家在某一輪選擇臂i,環境本輪選擇臂i的輸出為j,則玩家將付出損失Li,j,并觀察到反饋Hi,j,通過設計不同的反饋矩陣,Hi,j可給出關于真實輸出j的部分或全部有效信息。
通過與環境的多輪交互,玩家將收集到對各個臂的獎勵分布的觀察。在接下來的游戲中,玩家一方面希望選取歷史觀察中表現最好的臂,以獲取相對較高的收益(開發(exploit));另一方面希望嘗試一些尚未受到足夠觀察的臂,以獲取潛在較高的收益(探索(explore))。過度開發可能導致玩家錯過最優臂,過度探索則將導致玩家付出過多的學習代價,如何平衡開發與探索是多臂老虎機算法需要考慮的核心問題。
置信區間上界(upper confidence bound,UCB)[4]和湯姆森采樣(Thompson sampling,TS)[5]類型的算法是解決此類多臂老虎機問題的經典方法。UCB類型的算法為每個臂i維持一個置信上界,該上界為過往觀察的經驗均值與置信半徑之和,置信半徑將隨著被觀察到的次數的增多而減小。當一個臂被觀察到的次數足夠小時,置信半徑很大,促使置信上界足夠大,算法將傾向于選擇這些臂,這體現了探索的思想。當臂被觀察到足夠多的次數時,置信半徑變小,置信上界的值趨近于經驗均值,進而趨近于真實的期望值,算法將傾向于選擇經驗均值高的臂,這體現了開發的思想。TS類型的算法則為每個臂維持一個關于其獎勵值的先驗分布,初始時算法對臂的收益尚未了解,該分布趨近于一個均勻分布,體現了探索的思想;隨著收集到的觀察的增多,該分布逐漸集中于經驗均值附近,方差變小,這體現了開發的思想。
上述策略均以最大化累積期望獎勵/最小化累積期望懊悔為目標,然而考慮這樣的應用場景,在疫情期間,醫學研究人員有多種藥物的配置方式及一些可供測試藥物效果的小鼠,研究人員希望在小鼠身上實驗后為人類找到最有效的藥物配置方式,該目標與小鼠本身的獎勵無關。這種問題被稱為純探索(pure exploration)問題,玩家有一定的預算輪數,在這段時間內可以拉動不同的臂,并觀察其輸出,預算輪數終止后,需要給出最終的推薦,即拉動不同臂的概率分布。簡單懊悔(simple regret)是用來衡量解決此類問題策略的標準,其被定義為最優臂的期望獎勵與最終推薦的期望獎勵之差[6]。當玩家的最終目標是經過探索后識別出最優的臂時,該問題被稱為最佳手臂識別(best arm identification)問題,是純探索問題的一種變體[7]。該問題也有兩種目標,當探索預算固定時,玩家需要最大化識別出最優臂的概率[8];當返回最優臂的概率固定時,玩家的目標為最小化探索所需付出的代價[9]。
此外,在有些應用場景中,玩家有額外的探索限制,如商家希望在每一輪廣告投放時,都能保證一定值的收益,即保守型探索(conservative exploration),服從保守型探索限制的問題被稱為保守型老虎機(conservative bandits)問題[10]。給定一個基準臂A0,保守型探索限制玩家每一輪游戲t選 擇 的 臂At滿 足,其中α用于衡量玩家的保守程度,α越小,意味著玩家越保守。
在上述場景中,每個臂的獎勵值服從一個固定的概率分布,此時稱反饋類型為靜態反饋(stationary feedback);當每個臂獎勵值服從的概率分布隨時間發生變化時,稱反饋類型為非靜態反饋(nonstationary feedback);當每一輪的信息不在這一輪實時反饋給玩家,而是會有一定延遲的時候,稱此反饋為延遲反饋(delayed feedback)。此外,多臂老虎機問題還有許多豐富的變種。當每個臂的獎勵值不再服從一個確定的概率分布,而是一系列的確定值時,該問題將變為對抗老虎機(adversarial bandit)問題,Exp3算法[11]是解決此類多臂老虎機問題的經典算法。若每個臂的期望收益與玩家所獲得的環境特征相關,則稱為情境式老虎機(contextual bandit)問題。在情境式老虎機問題中,若臂的期望收益是情境信息向量的線性加權形式,則稱為線性老虎機(linear bandit)問題,LinUCB算法[12]是解決此問題的經典算法;若每一輪玩家拉動的不再是單獨的臂,而是多個臂的組合,則該問題變為組合多臂老虎機問題,即組合在線學習問題。
2.2 組合多臂老虎機問題
在許多應用場景中,玩家拉動的不是單獨的一個臂,而是多個臂的組合。如出行推薦平臺需要向用戶推薦的通常是機票、酒店與景區門票的組合,這時便需要組合多臂老虎機的研究框架來解決。
Gai Y等人[13]最早將多用戶信道分配問題建模為一個組合多臂老虎機模型,在該模型中,每個臂包含多個組件的組合,拉動同一個臂的獎勵隨時間相互獨立,但是不同臂之間的獎勵會由于一些共享的部件而產生依賴關系。之后,該框架又被進一步泛化,并被系統地闡釋[14-17]。
組合在線學習同樣被建模為玩家與環境之間的T輪在線游戲。該問題包含m個基礎臂(base arm),所有基礎臂組成的集合被記為。每 個 基 礎臂維持其各自的獎勵分布,獎勵的期望記為μi。第t輪基礎臂i的輸出記為Xi,t,為環境從該臂的獎勵分布中采樣出的隨機變量,且是相互獨立的。記所有基礎臂的獎勵期望為,所有基礎 臂在第t輪 的 輸出為玩家可選擇的動作是所有m個基礎臂可能的組合,稱之為超級臂(super arm),記S為動作集合,則。在每一輪中,玩家拉動超級臂,隨后獲取本輪的獎勵,并觀察環境的反饋信息。玩家收到的獎勵值將與拉動超級臂中包含的所有基礎臂的輸出相關。若該值為每個基礎臂的輸出(加權)之和,則稱獎勵為線性形式[17]。但在實際應用場景中,拉動超級臂的獎勵形式可能更加復雜,如在推薦場景中用戶的點擊情況可能不直接線性依賴于平臺推薦的每一個項目的吸引力,此時獎勵被稱為非線性形式[14-16]。玩家收集到的反饋信息也將根據不同的應用場景有所不同,可分為以下3類。
● 全信息反饋:該反饋類型假設玩家在拉動一個超級臂之后,能夠觀察到所有基礎臂的輸出,而與該基礎臂是否被包含在被拉動的超級臂中無關。這是一種非常理想化的設定,現實中往往難以遇到該場景。
● 半強盜反饋:全信息反饋的設定較為理想,現實中更常見的模式是玩家只能觀察到其選擇的超級臂包含的基礎臂的反饋信息,也就是半強盜反饋。例如,在搜索排序場景中,平臺可以獲取用戶對所列舉項目的滿意程度。
● 強盜反饋:該反饋類型假設玩家只能觀察到拉動超級臂所獲得的總的獎勵,而不能看到任何基礎臂的信息。以推薦場景為例,用戶的點擊意味著對所推薦商品組合的認可,平臺往往無法獲知用戶對具體某個產品的滿意程度。
類似多臂老虎機問題,組合多臂老虎機的反饋類型也可分為靜態反饋、非靜態反饋、延遲反饋等。根據每一輪收集到的反饋信息,玩家將進一步更新自己的策略。
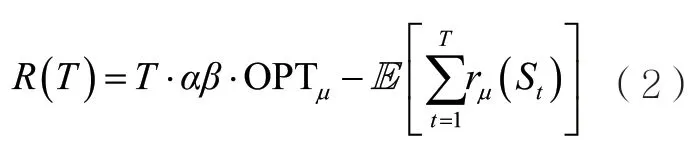
受到一些應用場景的啟發,玩家在拉動一個超級臂St∈S后,除St中包含的基礎臂外,更多的基礎臂可能會被St隨機觸發,對玩家最終的收益產生影響。該問題被建模為帶概率觸發臂的組合多臂老虎機(CMAB with probabilistically triggered arms,CMAB-T)模型[15,18],得到了較多的關注。
注意到在情境式線性老虎機模型中,學習者在每一輪拉動一個由向量表示的動作,并收到與該動作向量線性相關的獎勵值,線性函數的參數即學習者需要學習的未知參數向量。故線性多臂老虎機模型也可被視為基于線性獎勵形式、強盜反饋類型的組合多臂老虎機問題。研究者通常通過采用為未知參數向量構造置信橢球(confidence ellipsoid)的方法來解決此類問題[19-21]。
此外,多臂老虎機問題還可與組合數學中的擬陣結構相結合,即擬陣老虎機(matriod bandit)模型。該模型最早由Kveton B等人[22]提出,擬陣可由二元組表示,其中是由m個物品組成的集合,稱為基礎集(ground set);I是由E的子集組成的集合,稱為獨立集(independent set),且需要滿足以下3點性質:①?∈I;②I中每個元素的子集是獨立的;③增加屬性(augmentation property)。加權擬陣老虎機假設擬陣會關聯一個權重向量,其中w(e)表示元素e∈E的權重,玩家每次拉動的動作A∈I的收益為。該問題假設擬陣是已知的,權重w(e)將隨機從某未知的分布P中采樣得到。對應到組合多臂老虎機模型,E中的每個物品可被看作一個基礎臂,I中的每個元素可被看作一個超級臂。玩家的目標是尋找最優的超級臂,最小化T輪游戲拉動超級臂所獲期望收益與最優期望收益之間的差,即累積期望懊悔值。
純探索問題在組合場景下也得到了進一步的研究。Chen S等人[23]首先提出了多臂老虎機的組合純探索(combinatorial pure exploration of multi-armed bandits)問題。在該問題中,玩家在每一輪選擇一個基礎臂,并觀察到隨機獎勵,在探索階段結束后,推薦出其認為擁有最高期望獎勵的超級臂,其中超級臂的期望獎勵為其包含基礎臂的期望獎勵之和。Gabillon V等人[24]在相同的模型下研究了具有更低學習復雜度的算法。由于允許玩家直接觀察到其選擇的基礎臂的輸出這一假設在實際應用場景中過于理想化,上述模型隨后被進一步泛化。Kuroki Y等人[25]研究了玩家在每一輪選擇一個超級臂并僅能觀察到該超級臂包含基礎臂隨機獎勵之和的情況,即全強盜線性反饋的組合純探索(combinatorial pure exploration with full-bandit linear feedback)問題,并提出了非自適應性的算法來解決此問題。之后,Rejwan I等人[26]提出了自適應性的組合相繼接受與拒絕(combinatorial successive accepts and rejects,CSAR)算法來解決此類問題中返回前K個最優基礎臂的情況。Huang W R等人[27]泛化了線性獎勵形式,研究了具有連續和可分離獎勵函數的場景,并設計了自適應的一致最佳置信區間(consistently optimal confidence interval,COCI)算法。Chen W等人[28]提出了一種新的泛化模型——帶有部分線性反饋的組合純探索(combinatorial pure exploration with partial linear feedback,CPE-PL)問題,涵蓋了上述全強盜線性反饋以及半強盜反饋、部分反饋、非線性獎勵形式等場景,并給出了解決此模型的首個多項式時間復雜度的算法。在實際應用場景中,玩家可能無法觀察到某個臂的準確反饋,而是多個臂之間的相對信息,即競爭老虎機(dueling bandit)模型。Chen W等人[29]研究了競爭老虎機的組合純探索(combinatorial pure exploration for dueling bandits)問題,并設計了算法解決不同最優解定義的問題場景。
當每個基礎臂的收益值不再服從特定的概率分布,而是一系列的確定值時,上述問題將變成對抗組合多臂老虎機(adversarial CMAB)問題,相關研究工作將在下一節中基于強盜反饋的CMAB算法部分一并介紹。
3 基于優化反饋的組合在線學習算法
Gai Y 等人[17]最早考慮了組合多臂老虎機中獎勵形式為線性的情況,提出了線性獎勵學習(learning with linear reward,LLR)算法解決此問題,具體如下。
算法1:LLR算法
初始化:L為每個超級臂包含基礎臂的個數,t=0
Fori=1 tom
t=t+1
選擇有基礎臂i的超級臂
更新基礎臂i的獎勵估計以及基礎臂i被選擇的次數Ti,t
End for
While True do
t=t+1
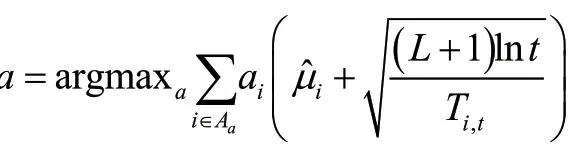
對于 ?i∈Aa,更新基礎臂i的收益估計以及基礎臂i被選擇次數Ti,t
End while
L LR算法使用UCB的思想平衡開發與探索的關系。在該算法中,學習者每輪可選擇的超級臂中至多包含L個基礎臂,其中L為超參數。每個超級臂Aa被表示為所有基礎臂的加權組合,權重向量由m維的向量a表示,ai≥ 0表示基礎臂i在超級臂中的權重,Aa將包含所有滿足ai≠ 0的基礎臂i。超級臂的置信上界是其包含的基礎臂的置信上界的加權和,算法在每一輪選擇置信上界最大的超級臂。該算法框架有豐富的應用場景,如尋找最大匹配、計算最短路徑及最小生成樹等。
隨后,Chen W等人[14-16]泛化了獎勵的形式,考慮到非線性形式的獎勵,且受到一些實際應用場景(如影響力最大化等)的啟發,提出了帶概率觸發機制的組合多臂老虎機(CMAB with probabilistically triggered arms,CMAB-T)模型,并設計組合置信區間上界(combinatorial upper confidence bound,CUCB)算法來解決此類問題,具體如下。
算法2:CUCB算法
輸入:基礎臂集合[m],離線神諭Oracle
While True do
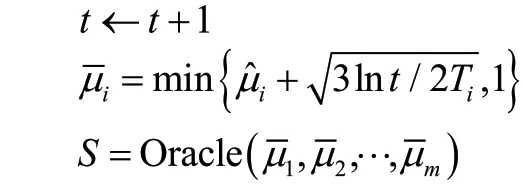
執行動作S,觀察到所有被觸發的基礎臂i,更新Ti和
End while
與LLR算法類似,CUCB算法同樣在每一輪為所有基礎臂計算其置信上界,不同之處在于選擇超級臂的方法不同。CUCB算法考慮了更多的應用場景,定義了一個更廣泛的求解超級臂的方法。算法獲取一個離線神諭作為輸入,將根據輸入的每個基礎臂的置信上界,輸出該參數下最優(或近似最優)的超級臂,算法進而執行此超級臂,并觀察相應的信息。由于許多非線性獎勵形式的離線組合優化問題通常為NP難問題,該算法允許借助近似的離線神諭來幫助每一輪中超級臂的選取,且使用近似累積懊悔上界指標來衡量算法的性能。
通過為具體的CMAB-T問題實例尋找合適的受觸發概率調制的有界平滑性條件(triggering probability modulated condition,TPM條件),CUCB算法可以達到的累積懊悔上界[15],其中B為TPM條件的參數,K為所有超級臂中可隨機觸發的基礎臂的最大個數。TPM條件的具體內容見條件1。
條件1(TPM條件):若存在有界平滑常數,使得對于任意兩個基礎臂分布(期望分別記為μ和μ′),任意超級臂S,滿足,則稱該CMAB-T問題實例滿足1范數TPM條件。其中,為超級臂S成功觸發基礎臂i的概率。
概括來說,TPM條件通過所有基礎臂在不同環境中的期望獎勵之差的加權和約束了同一個超級臂在對應獎勵分布下的獎勵差異,每個基礎臂的權重就是其在該超臂下被成功觸發進而對超級臂獎勵產生影響的概率。尋找合適的TPM條件對于該類問題的理論分析有重要的作用,如在線影響力最大化、基于特定點擊模型的搜索排序問題等。
之后,Combes R等人[30]嘗試了與LLR和CUCB不同的計算置信上界的方法,自然推廣KL-UCB[31]中的指標(index),利用KL散度來確定置信區間,并提出了ESCB(efficient sampling for combinatorial bandits)算法解決線性獎勵形式的CMAB問題。但由于超級臂數量隨著基礎臂數量的增加呈指數增長,該算法每一輪需要付出指數時間計算所有超級臂的置信上界。最近,Cuvelier T等人[32]提出了一個近似ESCB算法,算法能達到和ESCB一樣的累積懊悔上界,但實現了多項式時間復雜度O(Tpoly(m))。
此外,上述CMAB問題還可拓展至與情境相關的情況,即每輪玩家都會收到當前的情境信息,每個基礎臂的期望獎勵值會與該情境信息相關,該問題被稱為情境式CMAB(contextual CMAB)問題,由Qin L J等人[33]最早提出。在該工作中,每個基礎臂i的期望獎勵值都會與此輪的情境信息線性相關,其中xt(i)是描述情境信息的向量, 是噪聲項,而超級臂的獎勵值與超級臂中包含的基礎臂的獎勵值有關,可以是簡單的加權和,也可以是非線性關系。參考文獻[33]針對這樣的問題框架提出了C2UCB算法,在UCB算法的基礎上,加入了對參數θ的擬合過程,達到了階的累積懊悔上界,其中d是情境信息向量的維數。Chen L X等人[34]推廣了上述框架,考慮了玩家可選的基礎臂集合會隨時間發生變化的情況,并提出了CC-MAB算法來解決此類問題。隨后Zuo J H等人[35]提出了另一種廣義情境式CMAB-T(context CMAB-T)的框架——C2MAB-T。該框架考慮了給定情境信息之后,玩家可選的動作會受到該情境信息的限制。具體來說,在每一輪環境會先提供一個可選超級臂集,而玩家這一輪可選擇的超級臂就被限制在該集合中,其選擇的超級臂會隨機觸發更多的基礎臂,玩家最終觀察到所有觸發臂的反饋。參考文獻[35]提出了C2-UCB、C2-OFU算法來解決此類問題,并證明了在近似離線神諭下,累積懊悔上界均為,其中m是基礎臂的數量,K是所有超級臂可觸發基礎臂的最大數量。
總體來說,上述研究工作均基于UCB類型的算法處理開發與平衡的關系。除此之外,也有一系列基于TS的方法解決CMAB問題。
Komiyama J等人[36]研究用TS算法解決組合多臂老虎機中超級臂的獎勵為所包含基礎臂的輸出之和且超級臂的大小固定為K的問題,提出了多動作湯姆森采樣(multiple-play Thompson sampling,MP-TS)算法。該工作考慮了基礎臂的輸出為伯努利隨機變量的場景,算法為每個基礎 臂維 持 一 個貝塔 分布在每一輪將為每個基礎臂i從其分布中采樣一個隨機變量θi,并對所有基礎臂根據該隨機變量從高到低排序,從中選擇前K個基礎臂組成本輪要選擇的超級臂,隨后根據這些基礎臂的輸出再次更新其對應的貝塔分布。MP-TS算法達到了的累積懊悔上界,其中為任意非最優基礎臂i與最優臂K期望獎勵的KL距離,該懊悔值上界也與此類問題的最優懊悔值相匹配。
之后,Wang S W等人[37]研究如何用TS算法解決廣義獎勵形式的組合多臂老虎機問題,提出了組合湯姆森采樣(combinatorial Thompson sampling, CTS)算法,具體見算法3。
算法3:CTS算法
While True do
t←t+1
對于每個基礎臂i,從貝塔分布隨機 采樣
計算S=Oracle(θ(t))
執行動作S,得到觀察
End while
與CUCB算法相同,CTS算法同樣借助離線神諭產生給定參數下的最優超級臂,但該算法要求能夠產生最優解,不像CUCB算法那樣允許使用近似解。與MP-TS相比,CTS算法將基礎臂的輸出由伯努利類型的隨機變量放寬到[0,1]區間,且允許超級臂的獎勵是關于基礎臂輸出更為廣泛的形式,而不再是簡單的線性相加。當超級臂的期望獎勵值與基礎臂的獎勵期望滿足利普希茨連續性條件(Lipschitz continuity)時,該工作給出了基于TS策略解決廣泛獎勵形式的CMAB問題的首個與具體問題相關的累積懊悔上 界,其 中K為所 有 超 級臂中包含基礎臂的最大個數,?min為最優解和次優解之間的最小差。該懊悔值上界也與基于同樣條件獲得的UCB類型的策略(CUCB算法)的理論分析相匹配[14]。當獎勵形式滿足線性關系時,該算法的累積懊悔上界可被提升至[38]。
此外,Hüyük A等人[39-40]同樣基于確定的離線神諭Oracle,考慮到帶概率觸發的基礎臂,研究用CTS策略解決CMAB-T問題。當超級臂的期望獎勵與基礎臂的獎勵期望滿足利普希茨連續性條件時,該工作證明CTS算法在該問題場景下可以達到的累積懊悔上界,其中pi為基礎臂i被所有超級臂隨機觸發的最小概率。該結果也與基于同樣條件的UCB類型的策略(CUCB算法)的理論分析相匹配[14]。
具體到擬陣老虎機問題,Kveton B等人[22]充分挖掘擬陣結構,提出了樂觀擬陣最大化(optimistic matriod maximization,OMM)算法來解決此問題。該算法利用UCB的思想,每輪選取最大置信上界的超級臂,并且通過反饋進行參數更新,優化目標是令累積懊悔最小化。該文獻分別給出了OMM算法與具體問題相關的遺憾值上界和與具體問題無關的累積懊悔上界,其中K為最優超級臂A*的大小,是非最優基礎臂e和第Ke個最優基礎臂的權重期望之差,Ke為滿足大于0的元素個數。通過分析,擬陣多臂老虎機問題可達到的累積懊悔值下界為,該結果也與OMM算法可達到的累積懊悔上界相匹配。Chen W等人[41]也給出了利用CTS算法解決擬陣多臂老虎機問題的理論分析,該算法的累積懊悔上界也可匹配擬陣多臂老虎機問題的累積懊悔下界。
當每個臂的獎勵值服從的概率分布隨時間發生變化時,問題將變為非靜態組合多臂老虎機。Zhou H Z等人[42]最早研究了非靜態反饋的CMAB問題,并在問題設定中添加了限制——基礎臂的獎勵分布變化總次數S是。文中提出了基于廣義似然比檢驗的CUCB(CUCB with generalized likelihood ratio test,GLR-CUCB)算法,在合適的參數下,若總基礎臂數量m已知,則累積懊悔上界為;若m未知,則累積懊悔上界為,其中 C1、 C2為與具 體問 題相關的常數。而后Chen W等人[43]推廣了設定,即忽略上述對S大小的假設,引入變量衡量概率分布變化的方差,在S或者V中存在一個已知時,提出了基于滑動窗口的CUCB(sliding window CUCB,CUCBSW)算法,其累積懊悔上界為或者;在S和V都未知時,提出了基于兩層嵌套老虎機的CUCB(CUCB with bandit-over-bandit,CUCB-BoB)算法,在特定情況下,該算法累積懊悔上界為T的次線性數量級。
此外,CMAB問題也可以拓展至保守探索模式。Zhang X J 等人[44]最早將Wu Y F等人[10]提出的保守型多臂老虎機問題衍生到CMAB問題框架中,即第t輪用戶選擇的超級臂的獎勵值μt和默認超級臂的獎勵值μ0的關系服從限制,其中α用于 衡 量 用戶的保守程度,α越小意味著用戶越保守。該文獻基于UCB的思想提出了情境式組合保守UCB(contextual combinatorial conservative UCB,CCConUCB)算法,同時針對保守選擇的默認超臂的獎勵值0μ是否已知,分別提出了具體算法。當保守選擇的獎勵值已知時,算法的累積懊悔為,其 中d為基礎臂的特征維數,K為超級臂中最多能包含的基礎臂的數量。
上述CMAB研究工作均基于半強盜反饋,即超級臂中包含的(及觸發的)所有基礎臂的輸出都可以被玩家觀察到,也有部分工作研究了基于強盜反饋的CMAB算法。這類算法多考慮對抗組合多臂老虎機問題(adversarial CMAB),即每個基礎臂的輸出不再服從一個概率分布,而是一系列的確定值。Cersa-Bianchi N 等人[45]首先提出了COMBAND算法來解決此問題,該工作使用來體現組合關系,其中表示由基 礎臂組成的超級臂,當P的最小特征值滿足一定條件時,算法可達到的累積懊悔上界。Bubeck S等人[46]提出了基于約翰探索的EXP2(EXP2 with John’s exploration)算法,該算法也可達到的累積懊悔上界。Combes R等人[30]考慮通過將KL散度投影到概率空間計算基礎臂權重的近似概率分布的方法來減少計算復雜度,提出了更有效的COMBEXP算法,該算法對于多數問題也可達到相同的累積懊悔上界。Sakaue S等人[47]進一步考慮了更加復雜的超級臂集合的情況,設計了引入權重修改的COMBAND(COMBAND with weight modification,COMBWM)算法,該算法對于解決基于網絡結構的對抗組合多臂老虎機問題尤其有效。
當玩家需要拉動的動作為多個臂的組合時,其獲得的反饋也會隨實際應用場景變得更加復雜,部分監控問題在此場景下得到了進一步的研究,即組合部分監控(combinatorial partial monintoring)。Lin T等人[48]最早結合組合多臂老虎機與部分監控問題,提出了組合部分監控模型,以同時解決有限反饋信息、指數大的動作空間以及無限大的輸出空間的問題,并提出了全局置信上界(global confidence bound,GCB)算法來解決線性獎勵的場景,分別達到了與具體問題獨立的和與具體問題相關的的累積懊悔上界。GCB算法依賴于兩個分別的離線神諭,且其與具體問題相關的的累積懊悔 上界需要 保證問題最優解的唯一性,Chaudhuri S等人[49]放寬了這些限制,提出了基于貪心開發的階段性探索(phased exploration with greedy exploitation,PEGE)算法來解決同樣的問題,達到了與具體問題獨立的和與具體問題相關的的累積懊悔上界。
在一些應用場景中,如推薦系統等,隨著時間推移,系統將收集到越來越多的用戶私人信息,這引起了人們對數據隱私的關注,故CMAB算法還可以與差分隱私(differential privacy)相結合,用于消除實際應用對數據隱私的依賴性。Chen X Y等人[50]研究了在差分隱私和局部差分隱私(local differential privacy)場景下帶半強盜反饋的組合多臂老虎機問題,該工作證明了當具體CMAB問題的獎勵函數滿足某種有界平滑條件時,算法可以保護差分隱私,并給出了在兩種場景下的新算法及其累積懊悔上界。
4 應用方面
組合多臂老虎機問題框架有非常豐富的實際應用,本文著重介紹在線排序學習和在線影響力最大化兩類問題。
4.1 在線排序學習問題
排序學習問題主要研究如何根據目標的特征對目標進行排序,是機器學習算法在信息檢索領域的一個應用。該問題有一個目標物品集L,學習者每次需要根據某種打分標準對整個目標集進行打分,并且將打分進行排序,推薦出前K(通常L?K)個分數最高的目標物品。該問題有豐富的應用場景,如搜索、推薦、廣告點擊等。
在許多真實的應用場景中,如廣告推薦、搜索引擎排序等,總商品集的數量遠遠大于需要推薦的商品數量,使得離線排序學習模型所需訓練數據巨大,學習任務更加艱巨,這推動了對在線排序學習(online learning to rank)的研究。在線排序學習問題不再需要大量的歷史數據來構建排序模型,學習者將在與用戶的T輪交互過程中不斷更新對目標物品的評估。由于學習者需要推薦多個目標的組合,該問題屬于組合多臂老虎機的研究范疇,每個目標物品對應一個基礎臂,而推薦的物品組合對應一個超級臂。
在線排序學習算法早期多由經典的多臂老虎機問題算法改進而來,例如Li L H等人[12]改進了LinUCB(linear UCB)算法,考慮了項目的特征的加權組合,并通過計算置信上界來解決排序問題,Chen Y W等人[51]改進了LinUCB算法,在探索時引入貪心算法,優化了在線排序學習算法。
近年來,在線排序學習的研究工作多基于點擊模型。以商品推薦問題為例,商家考慮如何向用戶推薦商品,在與用戶的T輪交互過程中,學習商品的特征與用戶的喜好之間的關系,使用戶在輪推薦中盡可能多地點擊其推薦的商品。商家每次向用戶推薦的商品數量有限,推薦形式通常為列表。在每一輪推薦之后,商家可獲取用戶的點擊反饋,通常來說,若用戶點擊了其推薦的某個商品,則反饋為1,否則反饋為0。
上述點擊模型可分為3個部分:用戶是否瀏覽某個商品、商品對用戶的吸引程度以及用戶最終的點擊情況。用戶的瀏覽行為和商品對用戶的吸引力共同決定了用戶最終是否點擊。根據用戶的點擊行為,點擊模型可進一步分為級聯模型(cascade model)、依賴點擊模型(dependent click model)、基于位置的模型(position-based model)等。
級聯模型假設用戶至多點擊一次被推薦的商品列表(大小為K),即用戶會從列表的第一個商品開始,依次向后瀏覽,一旦點擊某個商品,用戶將停止繼續瀏覽。Kveton B等人[52]首先提出了析取目標(disjunctive objective)形式的級聯模型,即被推薦的商品列表中只要有一個“好”的商品,獎勵值為1,且考慮了所有可推薦的商品列表形成均勻擬陣的情況,并提出了CascadeKL-UCB算法解決該問題。該算法達到了的累積懊悔上界,其中Δ表示最優點擊期望和次優點擊期望之間的差的最小值。而后Kveton B等人[53]推廣了問題框架,提出了組合級聯模型,在該框架下推薦的商品列表只需滿足某些組合限制即可。該工作研究了合取目標(conjunctive objective),即只有所有商品都是“好”商品時,獎勵值才為1。作者提出了CombCascade算法解決此問題,達 到了的累積懊悔上界,f*是最優超級臂的收益。Li S等人[54]進一步考慮了商品的情境信息(contextual information),并提出了C3-UCB算法,算法的累積懊悔上界為,d為刻畫情境信息的特征維數。
依賴點擊模型放寬了級聯模型對用戶點擊次數的限制,允許用戶在每次點擊之后仍以λ的概率選擇繼續瀏覽,即最終的點擊數量可以大于1。在λ=1時,Katariya S等人[55]基于此模型結合KL-UCB算法[31]設計了dcmKL-UCB算法,取得了的累積懊悔上界。Cao J Y等人[56]推廣了問題設定,考慮了λ不一定為1的情況,并且考慮了用戶疲勞的情況(即用戶瀏覽越多,商品對用戶的吸引能力越弱),在疲勞折損因子已知的情況下提出了FA-DCM-P算法,算法的累積懊悔上界是;若疲勞折損因子未知,作者提出了FA-DCM算法,算法累積懊悔上界為
相較于前兩個點擊模型,基于位置的模型考慮了用戶對不同位置商品的瀏覽概率的變化,即用戶對商品的瀏覽概率將隨著該商品在推薦列表中順序的后移而逐漸變小。Li C等人[57]基于冒泡排序算法的思想設計了BubbleRank算法,該算法可同時適用于級聯模型和基于位置的模型。Zoghi M等人[58]引入了KL標度引理,設計了BatchRank算法。該算法也可同時應用于級聯模型和基于位置的模型。
Zhu Z A等人[59]不再考慮某特定的模型假設,而是根據實際推薦點擊場景提出了更通用的廣義點擊模型,上述3種模型均可涵蓋在內。廣義點擊模型假設用戶瀏覽每個商品的概率隨著商品在推薦列表中位置的后移而減小。用戶點擊某商品的概率與該商品的吸引力相關,且用戶繼續往后瀏覽的概率與其對當前商品的點擊與否相關。用戶對商品列表整體的瀏覽及點擊情況可由如圖1所示的貝葉斯網絡結構來闡釋。圖1中Ai表示用戶點擊第i個商品后繼續向下瀏覽,Bi表示用戶沒有點擊第i個商品并繼續向下瀏覽,Ei表示用戶瀏覽第i個商品,Ci表示用戶點擊第i個商品,Ri表示第i個商品的相關程度/吸引力,即用戶的瀏覽行為與商品的吸引力共同決定了用戶對該商品的點擊行為,而用戶瀏覽第i+1個商品的可能性與用戶對第i個商品采取行為的概率分布相關。
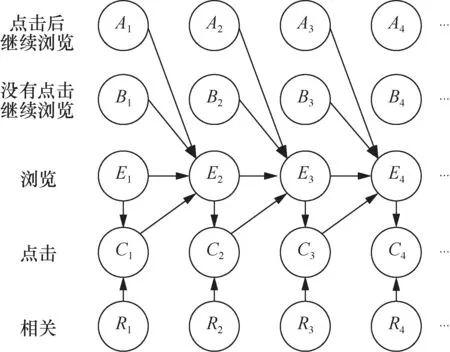
圖1 廣義點擊模型的貝葉斯網絡結構
針對上述廣義模型,Li S等人[60]考慮到廣義模型中每次反饋可能有噪聲影響,且假設點擊概率和瀏覽每個商品的概率獨立,同時與每個商品的吸引力也獨立,提出了RecurRank算法。該算法利用遞歸的思想,考慮將排序分為若干階段,每個階段都采用分段排序,下一個階段再對已經分得的段繼續分段排序,直至最后排序完成,算法的懊悔上界為,其中d為商品的特征維數;Lattimore T等人[61]基于BatchRank的結果提出了TopRank算法,該算法學習商品之間吸引力大小的相對關系,從而完成排序任務。相比于BatchRank,該算法應用更加廣泛,計算更加簡便且懊悔上界更小。
此外,線性次模多臂老虎機(linear submodular MAB)模型是應用于在線排序學習領域的另一經典 老虎機模型。該模型最早由Yue Y S等人[62]提出,將次模信息覆蓋模型引入組合多臂老虎機框架,并應用于排序學習領域。次模信息覆蓋模型假設信息的邊際效益遞減。該模型假設任意商品a都可被d個基本 覆蓋函數F1,…,Fd表示,其中基本 覆 蓋函數F1,… ,Fd表 示此文檔對d個特征的覆蓋率,且為已知的滿足次模性質的函數。同理,每個商品對應組合多臂老虎機模型的基礎臂,需要推薦的有序商品組合為超級臂,超級臂的覆蓋函數是基礎臂覆蓋函數的加權和。Yue Y S等人[62]提出了LSBGreedy算法來解決此問題,并證明其累積懊悔上界為其中L是超級臂中包含的基礎臂的數量,S是與權衡期望收益和噪聲的參數相關的常數。然而問題原始定義是將所有商品都進行排序輸出,即最終得到的超級臂是,這并不符合多數排序學習問題的實際情況,此后Yu B S 等人[63]引入了背包限制(即每個文檔有成本函數,需要考慮推薦的文檔的成本總和不能超過某個限制值),并提出了兩種貪心算法(MCSGreedy和CGreedy)來求解此類問題。Chen L等人[64]把原始線性次模問題推廣到無限維,考慮了邊際收益函數是屬于再生核希爾伯特空間的具有有限模的元素,并提出了SM-UCB算法。Takemori S等人[65]考慮了雙重限制下的次模多臂老虎機問題,即背包限制以及k-系統限制,沿用改進UCB的思想,提出了AFSM-UCB算法,相比于LSBGreedy[62]和CGreedy[63],該算法在實際應用效率方面有一定程度的提升。
4.2 在線影響力最大化
在線影響力最大化(online influence maximization,OIM)問題研究在社交網絡中影響概率未知的情況下,如何選取一組種子節點集合(用戶集合),使得其最終影響的用戶數量最大[66]。該問題有豐富的應用場景,如病毒營銷、推薦系統等。由于學習者選擇的動作是多個節點的組合,動作的數量會隨著網絡中節點個數的增長出現組合爆炸的問題,故在線影響力最大化也屬于組合在線學習的研究范疇。
獨立級聯(independent cascade,IC)模型與線性閾值(linear threshold,LT)模型是描述信息在社交網絡中傳播的兩個主流模型[67]。在IC模型中,信息在每條邊上的傳播被假設為相互獨立,當某一時刻節點被成功激活時,它會嘗試激活所有的出鄰居v一次,激活成功的概率即邊的權重,該激活嘗試與其他所有的激活嘗試都是相互獨立的。LT模型拋棄了IC模型所有傳播相互獨立的假設,考慮了社交網絡中常見的從眾行為。在LT模型中,每個節點v會關聯一個閾值θv表示該節點受影響的傾向,當來自活躍入鄰居的權重之和超過θv時,節點v將被激活。已有的在線影響力最大化工作主要專注于IC模型和LT模型。
Chen W等人[14-15]首先將IC模型下的在線影響力最大化問題建模為帶觸發機制的組合多臂老虎機問題(CMAB with probabilistically triggered arms,CMAB-T)。在該模型中,社交網絡中的每條邊被視為一個基礎臂,每次選擇的種子節點集合為學習者選擇的動作,種子節點集合的全部出邊的集合被視為超級臂。基礎臂的獎勵的期望即該邊的權重。隨著信息在網絡中的傳播,越來越多的邊被隨機觸發,其上的權重也可以被觀察到。基于此模型,CUCB算法[14-15]即可被用于解決該問題。通過證得IC模型上的在線影響力最大化問題滿足受觸發概率調制的有界平滑性條件(triggering probability modulated condition),CUCB算法可以達到的累積懊悔上界,其中n、m分別表示網絡中節點和邊的數量[15]。
后續又有一些研究者對此工作進行了改進。Wen Z等人[68]考慮到社交網絡中龐大的邊的數量可能會導致學習效率變低,引入了線性泛化的結構,提出了IMLinUCB算法,該算法適用于大型的社交網絡。該算法能達到的累積懊悔上界,其中d為引入線性泛化后特征的維數。Wu Q Y等人[69]考慮到網絡分類的性質,將每條邊的概率分解為起點的影響因子和終點的接收因子,通過此分解,問題的復雜度大大降低。該文獻中提出的IMFB算法可以達到的累積懊悔上界。
上述研究工作均基于半強盜反饋,即只有被觸發的基礎臂的輸出可以被學習者觀察到。具體到在線影響力最大化問題,該反饋也被稱為邊層面的反饋,即所有活躍節點的每條出邊的權重均可以被觀察到。由于在實際應用場景中,公司往往無法獲知具體哪個鄰居影響到某用戶購買商品,故該反饋是一種較為理想化的情況。節點層面的反饋是在線影響力最大化問題的另一種反饋模型,該反饋模型僅允許學習者觀察到每個節點的激活狀態。Vaswani S等人[70]研究了IC模型下節點層面反饋的情況,該工作分析了利用節點層面反饋估計每條邊的權重與直接利用邊層面反饋得到的估計值的差異,盡管兩種估計的差值可以被約束,但該工作并沒有給出對算法累積懊悔值的理論分析。
LT模型考慮了信息傳播中的相關性,這給在線影響力最大化問題的理論分析帶來了更大的挑戰。直到2020年,Li S等人[71]研究了LT模型下的在線影響力最大化問題,并給出了首個理論分析結果。該工作假設節點層面的反饋信息,即傳播過程每一步中每個節點的激活情況可以被觀察到,并基于此設計了LT-LinUCB算 法,該 算 法 可 以 達 到的累積懊悔上界。此外,Li S等人還提出了OIM-ETC(OIM-explore then commit)算法,該算法可以同時解決IC模型和LT模型下的在線影響力最大化問題,達到了的累積懊悔上界。Vaswani S等人[72]還考慮了一種新的反饋類型,即信息在任意兩點間的可達情況,并基于此反饋信息設計了DILinUCB(diffusionindependent LinUCB)算法。該算法同時適用于IC模型和LT模型,但其替換后的近似目標函數并不能保證嚴格的理論結果。
5 未來研究方向
組合在線學習問題仍有很多方面可以進一步研究和探索,具體如下。
● 設計適用于具體應用場景的有效算法。以在線影響力最大化問題為例,目前的研究工作多為通用的算法,基于TPM條件得到算法的累積懊悔上界。但實際應用場景中通常涉及更多值得關注的細節,如在線學習排序問題中用戶的點擊習慣、用戶疲勞等現象,在線影響力最大化問題中信息傳播的規律等。通用的算法往往難以全面考慮這些細節從而貼合具體的問題場景,因此針對具體問題場景設計出有效的算法,以及為這些問題證明其累積懊悔下界等仍然是值得研究的問題。
● 將組合在線學習與強化學習結合。MAB問題是強化學習的一種特例,CMAB是組合優化與MAB的結合,更進一步的問題是能否將這種結合推廣到廣義的強化學習領域,探索更廣泛通用的組合在線學習框架,以涵蓋更多的真實應用場景。
● 研究具有延遲反饋和批處理反饋的組合在線學習算法。實際應用場景中往往有更復雜的反饋情況,如在線排序學習問題中用戶可能沒有立即對感興趣的項目進行訪問,導致玩家行動與反饋之間有一定的時間差,即延遲反饋;有時廣告供應商每隔一段時間才集中收集一次數據,即批處理反饋。在MAB問題中,針對這兩種反饋方式的算法研究已取得一定的進展,在CMAB問題中,考慮這些復雜反饋形式的算法仍需繼續探索。
● 深入研究分布式CMAB(distributed CMAB)。考慮多個玩家同時以相同目標選擇超級臂的場景,玩家之間可以進行交流,但是每一輪每個玩家能共享的信息有限,玩家最終根據自己觀察到的信息做出選擇,并得到對應的獨立的獎勵值,最終每個玩家都會選擇自己認為最優的超級臂。分布式探索的方法在MAB問題中已經有所應用和突破,但在CMAB場景中仍然需要更多的深入研究。
● 尋找更多的實際應用場景,以及在真實數據集上進行實驗。已有算法可應用的數據集仍然有限,目前的研究工作多在人工數據集上進行實驗,如何將算法應用到更多的真實數據集中并解決更多的實際問題,是具有重要實際意義的研究方向。
6 結束語
本文首先介紹了組合在線學習問題的定義及其基本框架——組合多臂老虎機問題,而后概括了此框架下的組合在線學習模型及經典算法。該問題有豐富的應用場景,本文重點介紹了在線排序學習和在線影響力最大化,詳述了這兩個應用場景下的研究進展。組合在線學習仍有許多值得深入探索的問題,本文最后對其未來研究方向做了進一步展望。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
