強化學習在資源優化領域的應用
2021-09-22 02:00:44王金予魏欣然石文磊張佳
大數據 2021年5期
王金予,魏欣然,石文磊,張佳
微軟亞洲研究院,北京 100080
1 引言
資源優化關心如何更有效地管理與利用資源以提高整體的收益。資源優化問題無處不在,大到國與國之間的貿易往來,小到每個人的衣食住行,整個人類的經濟、生產、生活活動都是圍繞著資源運行的。一直以來,傳統的運籌學方法,如組合優化、線性規劃、非凸優化等技術被廣泛地應用于海運優化[1-4]、出租車派單[5-6]、供應鏈管理[7-9]、貨物裝箱[10-11]等資源優化場景,并且成果斐然。
雖然基于運籌學的方法對解決上述資源優化問題提供了很大幫助,但實際中仍然存在的很多挑戰嚴重地降低了運籌學方法的求解效果。這些挑戰主要來自以下3個方面。
● 求解空間非常巨大。很多實際場景涉及的資源節點眾多、依賴關系復雜、待求解周期長,導致構造的運籌學模型動輒幾十萬變量、上百萬約束,使得求解速度緩慢、計算成本高昂,造成運籌學模型很難應用于一些時效性要求高的場景,如出租車派單。
● 不確定性強。資源優化問題通常是針對未來的情況的,例如海運公司需要根據未來的供需情況進行集裝箱的平衡調度,出租車派單中需要根據未來的訂單情況進行匹配,供應鏈中需要考慮未來各環節的產能與倉儲能力以及最終的客戶需求進而決定供給方案。在這種情況下使用基于運籌學的方式進行求解就需要對未來的情況進行顯式的預測,并且基于這些預測建立模型。但是預測的精度總是有限的,尤其需要較長時間的預測時,準確度更加難以保證。這就導致求解質量不高、優化效率低,甚至得到的解無法執行。
● 場景邏輯復雜、多變。在實際問題中,由于業務邏輯復雜,存在很多用運籌學中的約束無法有效刻畫的邏輯,如跨國貿易中的一些政策、法規要求,供應鏈中未滿足客戶需求而產生的名譽、客戶流失等潛在成本。在這種情況下,運籌模型的建立需要進行人工設計,近似地刻畫這些約束,這不可避免地使模型具備了主觀性。與此同時,場景的業務邏輯(如業務模式、法規要求等)會隨時間發生改變,一旦發生變化,又需要大量的人力重新調整模型以適應新的變化,導致人工成本高昂,而且模型的穩定性難以保證。
上述挑戰超出了傳統運籌學方法的范疇,需要引入全新的解決方案。事實上,隨著信息技術的不斷發展以及存儲設備的價格越來越低,各行各業積累了大量的歷史數據,如海運領域的航線變化、船舶離港到港事件、供需關系數據,出租車領域的車輛軌跡、訂單需求數據,快遞領域的包裹尺寸、目的地分布數據等。這些寶貴的數據中包含了業務的復雜變化與各種事件的不確定性,隱式地體現了問題的運行邏輯。如何充分地利用這些數據,從中發現規律、學習策略是解決資源優化問題面臨的重要挑戰,也是重大機遇。顯然,這些數據在傳統的運籌學方法中很難發揮出最大價值。
隨著強化學習在圍棋[12]、游戲[13]等序列化決策領域大放異彩、在多智能體協作等領域取得較好表現[14],它的一些優秀特性也得到了資源優化領域的關注。首先,基于強化學習的解決方案決策非常高效。雖然強化學習策略的訓練非常耗時,但是這些訓練工作可以離線進行,實際中只需要利用訓練好的模型進行推理,因而在絕大部分情況下可以做到近似實時決策。其次,使用強化學習的方法并不需要顯式地對未來進行預測,模型可以從交互經驗、海量數據中發現規律、學習策略,從而幫助做出合適的決策。最后,在強化學習中,模型不需要對業務邏輯進行建模,可以完全把業務邏輯當成一個黑盒,避免了對復雜業務邏輯的刻畫工作和刻畫主觀性問題。當業務環境發生變化時,智能體能夠及時地利用數據中蘊含的變化信號,從而更加迅速和敏銳地通過與業務環境的交互重新找到合適的優化方案。鑒于這些特點,近年來強化學習算法結合行業大數據的解決方案在資源優化領域得到越來越多的應用,并取得了一系列優秀的成果。
基于這種行業趨勢,本文針對強化學習算法在資源優化領域的應用展開調研,幫助讀者了解該領域最新的進展,學習如何利用數據驅動的方式解決資源優化問題。鑒于資源優化問題場景眾多、設定繁雜,劃分出3類應用廣泛的資源優化問題,即資源平衡問題、資源分配問題、裝箱問題,集中進行調研。在每個領域闡述問題的特性,并根據具體的問題特性進行細分,然后以場景為中心進行具體工作的闡述,并重點從問題的建模、特征設計、獎勵設計、策略學習等方面展開具體介紹。
2 基本知識
2.1 強化學習的基本概念
強化學習以馬爾可夫決策過程(Markov decision process,MDP)為基礎構造模型[15]。一個典型的馬爾可夫決策過程可以表示為五元組分別表示狀態空間、動作空間、狀態轉換概率函數、獎勵方程和衰減因子。狀態空間,表示當前環境的全部狀態的集合;動作空間,表示當前環境中各個狀態下可采取的動作集合,特別地,對于一個給定的狀態s,有效的動作空間表示為,且有;狀態轉換概率函 數描述了在狀態s下采取動作a,環境跳轉到狀態s′的概率;獎勵方程R可以定義為表示在狀態s下完成動作a后從環境中得到的獎勵;衰減因子γ用來對長期獎勵進行建模,用于描述每個動作a的作用效果隨時間推移的衰減程度,即環境給的單步獎勵rt+1對前序動作at的衰減程度,獎勵接收時間與動作執行時間離得越遠,衰減程度越大。
強化學習中的兩大主體分別是智能體和環境。強化學習智能體通過不斷地與環境進行交互來收集經驗,并從經驗中進行學習。對于一個給定的狀態s,智能體采取動作a后,環境將跳轉到下一個狀態s′,并返回一個獎勵r,這樣就得到了一條經驗數據。智能體與環境交互過程中的全部狀態、動作序列共同構成了此次交互的一條軌跡。一條軌跡對應的全部獎勵值之和被稱為這條軌跡對應的回報值,用表示,
2.2 強化學習算法基礎
根據智能體在與環境交互過程中具體學習的內容,可以把無須對環境進行建模(即model-free)的強化學習算法分為兩大類:直接學習動作執行策略的策略優化算法(如REINFORCE[16])和通過學習一個值函數進而做出動作執行決策的值優化算法(如Q-learning[17])。
在策略優化這類算法中,主要學習對象是動作執行策略πθ,其中,θ表示當前策略的全部參數。策略πθ負責完成從狀態s到動作a的映射,具體分為確定性策略和隨機性策略。確定性策略將給定的狀態s映射到確定的動作a,即;對于給定的狀態s,隨機性策略將給出動作a的概率 分布,即。樸素 的REINFORCE算法又被稱為樸素的策略梯度(vanilla policy gradient,VPG)算法,是一種隨機性策略算法,更新的規則是以梯度上升的方式更新參數θ,從而提升與環境交互所獲得的軌跡的對應回報值,即策略更新的目標函數為:
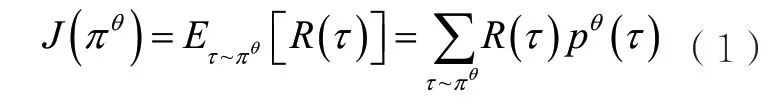
進一步可以得到對應的梯度:
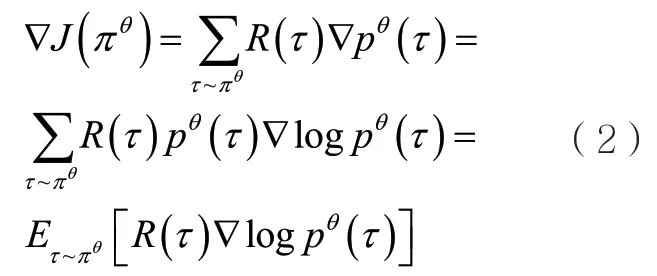
從而可以通過抽取一定量的經驗數據實現策略的更新梯度計算,這里把抽取的經驗數據的數量定為N:
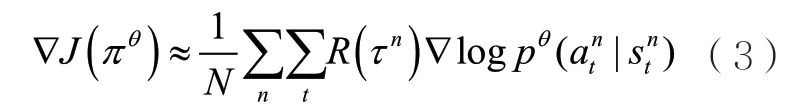
除了REINFORCE算法,策略優化算法還包括信賴域策略優化(trust region policy optimization,TRPO)算法[18]、近端策略優化(proximal policy optimization,PPO)算法[19-20]、優勢動作評價(advanced actor-critic,A2C)算法[21]、異步優勢動作評價(asynchronous advantage actorcritic,A3C)算法[21]等。
值優化算法的典型代表是深度Q網絡(deep Q network,DQN)[13],DQN主要學習的是一個動作-價值函數類似地,這里的θ指的是當前動作-價值函數的全部參數,而則表示基于參數θ,在狀態s下采取動作a對應的價值的估計值,也可以理解為在狀態s下采取動作a后仍基于參數θ與環境交互、預計能從環境中獲得的所有獎勵值的和的期望。最終,依據動作-價值函數,根據值最大化的原則,DQN算法選取的動作是。當智能體與環境進行交互并收集到一定數量的經驗數據后,即得到狀態s與狀態s′之間實際相差的獎勵值r后,考慮到Q函數應當具備的自洽性,可以根據最小化與的估計誤差的原則來更新動作-價值函數,則損失函數為:
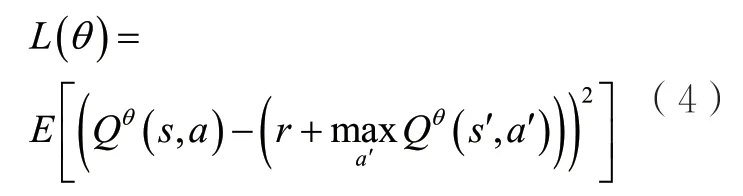
3 資源平衡問題
資源平衡問題指研究資源有限系統中分散資源點間的資源調度策略,以優化資源需求與資源消耗在時空分布上的一致性。根據平衡問題的觸發與作用機制的不同,資源平衡問題可以劃分為被動平衡問題、主動平衡問題和基于市場機制的平衡問題。
3.1 被動平衡問題
現實場景中的資源平衡問題往往會受到諸多現實因素的制約,如路線、成本等,因此調度策略往往需要遵循現實世界的既定規則,即調度動作只能由現實事件觸發。以交通場景為例,觸發事件可以是負責運載資源的交通工具抵達資源點。在固定路線的約束下,典型的資源網絡可以定義為G=(P,R,V),其中,P、R、V分別表示資源點、交通路線、交通工具的集合。每個端點Pi∈P表示一個資源點,將Pi處的初始庫存資源表示為,用和分別表示不同時刻的庫存數量、資源需求數量和資源供應數量。每條路線Ri∈R表示物流網絡中的一條通路,由一系列連續的資 源點組成,表示這條路線上的資源點總數。每條路線Ri上都有一隊固定的車輛,且每一輛運載工具Vj∈VRi都有其固定的運行時刻表及容量上限Cj,同時,不同的路線之間可能在任意資源點相交。當運載工具到達資源點時,它可以從資源點裝載資源,也可以向資源點卸載資源。空集裝箱重定位就是比較典型的被動平衡場景,下面將對這一場景的相關算法進行介紹。
空集裝箱重定位問題:空集裝箱是航運中用來裝載貨物的核心資源,而世界各國和地區之間的進出口貿易存在很大的貿易不對等,這導致空集裝箱的供需極度不平衡。空集裝箱重定位問題是在運輸貨物的同時合理運輸適量的空集裝箱,以達到優化貨物運輸效率的目標。作為交通網絡中的資源平衡問題,這一問題受到了運籌優化領域的廣泛關注[1-4]。
1997年,Crainic T G等人[1]總結了在貨運運輸規劃和執行中的主要問題,并以計算機技術為基礎,提出了相應的策略模型和方法。隨后,Epstein R等人[2]針對空集裝箱重定位問題進行了更加細致的研究,設計了物流優化系統來管理資源不平衡的問題,并提出了基于供需預測和庫存控制的多商品網絡流量模型。參考文獻[22]將環境的不確定性引入空集裝箱重定位系統中,建立了一個針對隨機供需、隨機船舶容量的兩階段隨機規劃模型,得到了良好的效果。Song D P等人[23]對基于運籌學的資源平衡解決方案進行了詳細的回顧,這些方法通常是多階段的,即先預測每個資源點未來的供需情況,再采用組合優化的方法求解每個資源點的最優策略,最后通過裁剪模型輸出的原始策略來生成可行解。然而,上述傳統的運籌學方法受限于供需的不確定性、復雜的非凸業務約束以及交通網絡的高度復雜性,難以在真實場景中得到令人滿意的調度策略。
為了解決上述挑戰,Li X H等人[24]將這一問題建模為一個由事件驅動的多智能體強化學習問題。具體地,每條船對應一個智能體,當船舶Vi到達港口Pj時,會觸發相應的智能體做出決策,且其動作空間表示將部分資源從車上卸下,時則相反。同時,這些操作始終受到船舶的容量Ci的限制。在狀態S和獎勵函數R的設計上,研究根據各智能體間合作范圍的不同,提出自我意識、領土意識和外交意識3種模式。在自我意識中,智能體是自私且短視的,因此狀態SI可以僅由當前船只和當前港口的特征來描述,即,而獎勵函數rI是只與當前船只的庫存與空箱短缺數量相關的函數。領土意識則具有更廣闊的視野,它關注當前船只Vi即將路過的多個港口,以及當前港口Pj的后續接駁的多個船只,此時狀態可以表示為,這一模式使得智能體可以基于航線的信息做出更全面的決策。進一步地,外交意識在領土意識的狀態ST上增加了當前港口Pj所在的所有路線的信息,其獎勵函數表示為,其中,α表示自我獎勵rI的權重,即外交獎勵是自我獎勵rI與相鄰路線的獎勵rc的加權均值,從而實現智能體與交叉航線的合作,使得資源可以在航線間進行再平衡。此外,將船只作為智能體,是考慮到沿著同一路線行駛的多個船只通常共享相似的環境,因此它們可以共享相同的策略,從而顯著降低模型的復雜度。同時,船只的航行過程也是其信息視野的自然放大過程,因此將其作為智能體能夠獲得更好的全局策略。
本質上,合作多智能體系統通過對多個分散智能體求取全局最優解,建模智能體間的合作行為。因此,在實際問題中,要想建模智能體與環境實體之間復雜的協作關系,要充分了解每個智能體及與它相關的智能體和環境實體的狀態信息。為此,Jiang J C等人[25]提出了使用交互圖對整個環境進行建模的方法。其中,頂點表示智能體或環境實體,當兩個頂點相互作用時,便存在邊。這一研究方法在多智能體強化學習(multi-agent reinforcement learning,MARL)框架下,利用圖神經網絡(graph neural network,GNN)在連通的智能體間傳遞合作信號,并在各種小游戲中取得了不錯的表現。但是,現實場景往往要比游戲更復雜。簡單的GNN模型通常使用比較簡單的池函數作為聚合函數,并在信息傳播的過程中始終假設交互圖中的所有頂點是同構的。然而,實際問題中的頂點大多是異構的,異構頂點之間不同的特征空間阻礙了有效的信息傳遞。同時,簡單的聚合函數也可能造成信息的丟失或過平滑問題。
因此,Shi W L等人[26]提出了一種新的合作策略學習框架,使用預訓練的方法學習異構的表征,并在真實場景上的大量實驗中證明了其優越性。該方法將多智能體系統表示為一個異構的交互圖,并提出了一種新的多智能體強化學習框架。框架由兩部分組成:基于編碼器-解碼器的圖注意模塊(EncGAT)和使用actor-critic的預訓練流程(PreLAC)。其中,EncGAT模型學習交互圖中的信息表示,然后將這些信息輸入actor-critic網絡中,以幫助它學習到更好的合作策略。然而,在A2C算法中引入EncGAT模型后,這一復雜結構會使得多智能體系統的學習過程變得更加困難。為了提高學習效率和學習策略的有效性,研究人員首先使用局部獎勵訓練EncGAT模型,得到多個執行自私策略的actor和critic,即它們都只關心自己獲得的局部獎勵是否最大;然后使用預先訓練好的EncGAT網絡參數初始化actor和critic;最后使用全局的獎勵函數進行微調。
3.2 主動平衡問題
不同于被動平衡問題,在主動平衡問題中,資源調度的動作成本往往不高,且存在專用于資源調度的運輸工具可供調配,因此調度動作可以由資源點根據自身情況主動、靈活地觸發,不再受限于環境事件。
以基于人工的共享自行車重定位為例進行說明。近年來,作為連接城市“最后一公里”的解決方案,共享自行車系統為人們提供了新式的公共交通工具。同樣地,由于自行車使用在空間和時間領域的不平衡,在共享自行車的站點可能出現車輛堆積和車輛不足的情況。由于共享自行車站點往往數量龐大、路線龐雜,對共享自行車系統的研究不僅集中在自行車重定位策略上,同時也涉及系統設計、供需預測、行程建議等多個方面。自行車的重定位方法一般被分為基于人工的重定位方法[27-33]和基于用戶的重定位方法[34-38]。
基于人工的重定位方法使用多輛三輪車在車站周圍移動,在不同的車站間裝卸自行車。與空集裝箱重定位不同的是,由于自行車重定位場景的站點較多且分布密集,三輪車不設置固定路線,而是根據車站的調度需求進行隨機移動。重定位可以以靜態或動態的方式進行,靜態重定位指當系統不運行或在夜間時,工作人員將自行車重新按需分配到系統中。這一問題的解決方案大多基于優化模型[23],并將最小化總行程作為優化的目標。動態重定位問題[28-40]也采用優化模型,但模型往往過于復雜,無法建模策略的長期影響并應對真實環境中存在的諸多不確定性。
為了解決這一問題,Li Y X等人[31]提出了一種基于時空注意力的強化學習模型。為了更好地定義這一問題,并降低大規模共享自行車系統內的問題復雜性,他們提出了一種名為IIIB的兩步聚類算法。上述聚類算法首先根據某一時段內站點的空間聚集程度和軌跡分布將其劃分為不同的區域,再將各個區域聚類成內部平衡且相互獨立的簇。簇Ci內部各區域sj間的平衡性可以表示為,Ci和Cj之間的獨立性定義為,其中o、r分別表示借、還的車數,f表示區域和間的軌跡。該方法將每個卡車作為一個智能體,為每個區域分配一定數量的卡車,它們在區域內部不斷地更新目的地,完成自行車重定位任務。觀測狀態S由一個2ni+1維的向量表示,包含系統狀態(容量、供需等)、其他卡車狀態(目的地和卸載量)和當前車站的狀態,ni表示當前簇中的區域數量。智能體的動作由一個ni維的one-hot向量和1位表示卸載量的數字表示。基于以上設定,上述研究設計了一個時空強化學習模型,使用深度神經網絡估計其值函數,為每個區域訓練其重定位策略,并在訓練中巧妙地通過剪枝規則進一步降低模型的訓練復雜度。
3.3 基于市場機制的平衡問題
基于市場機制的平衡問題指不使用運輸工具或調度工具直接在資源點間轉移資源,而使用定價、獎懲等機制來影響系統中的供需情況或運行機制,從而間接提高資源需求與資源消耗在時空分布上的一致性。
以基于用戶的共享自行車重定位為例進行說明。以人工為基礎的定位方法利用多輛卡車或自行車拖車,通過在不同區域裝卸自行車實現重新定位。然而,其再平衡效果在很大程度上取決于需求預測的準確性。此外,由于運輸工具的行程、維護、人工成本較高,基于人工的方法往往需要大量的預算。相比之下,以用戶為基礎的方式通過向用戶發放折扣、獎勵的途徑,鼓勵用戶選擇特定的取車或落車地點,是一種更加經濟和靈活的重新平衡系統的方式。
Contardo C等人[27]首次提出了動態的公共自行車共享平衡問題,對這一問題進行了詳細的定義,從運籌學角度給出了這一問題在中大型系統中的解決方案,并將定價策略作為平衡系統中的一個子問題。隨后,Chemla D等人[34]提出了一種定價策略,使得不依賴人工移動自行車的平衡策略成為可能。該方法依據現實經驗將空間分為多個獨立區域,在真實用戶的行為基礎上開發了多功能模擬器,并在其上對定價策略進行了實驗。進一步地,Singla A等人[37]提出了一種眾包機制,通過現金獎勵的方式激勵用戶在特定的區域取車或換車,從而實現自行車的重定位。他們模擬了用戶進行自行車租賃的完整過程,并為之設計了一個完整的激勵體系,通過用戶模型評估是否為用戶提供建議路線和相應的獎勵,同時采用動態定價機制,在給定的預算約束下,實現自行車使用效率的最大化。他們在模擬器上驗證了該方法的性能,并首次將動態激勵系統的自行車重定位系統部署在現實世界的自行車共享系統中。
然而,上述基于用戶的方法往往沒有將空間信息(如自行車和用戶的空間分布)和用戶的信息(如步行所需時間)作為定價政策的影響因素。Pan L等人[36]將這一問題視為共享自行車服務經營者與環境之間的相互作用,并將其描述為MDP。在這個MDP中,每個地區的狀態都由自行車的供應量、需求量、到達量和其他相關信息組成,動作可以表示為當前地區ri在總預 算B限制下的 一 種定價 策略這一策略通過價值為的獎勵,激 勵用戶步行前往距當前地區ri距離為x的附近區域借還第k輛車。使用函數表示用戶接受定價動作建議所需代價,當當前區域無車可用且時,會發生流單。這一任務的優化目標即最小化流單率。這一設置產生了一個連續的高維行動空間,且該空間維數隨著指數增長。為了解決這一問題,Pan L等人[36]提出了一種名為分層強化定價(hierarchical reinforcement pricing,HRP)的深度強化學習算法。HRP算法建立在深度確定性策略梯度(deep deterministic policy gradient,DDPG)算法[41]的基礎上,并使用了層次化的強化學習框架。這一算法的核心思想是將整個目標區域的Q值分解為多個較小區域的子Q值,其中,分別表示子區域rj在時間t的狀態和動作,uj表示模型參數。該分解方法解決了高維輸入中空間和時間依賴導致的復雜性問題,同時在分解過程中引入了一定誤差。因此,HRP算法通過一個本地化模塊fj(·)引入空間依賴性,從而糾正由于 子狀態 和子動作之間的相互關聯和分解而引入的Q函數估計偏差,因此可以表示為,以獲得更小的輸入空間,減小訓練誤差。該研究證明了HRP算法對收斂性的改進效果,并在摩拜單車數據集上證明了其性能優于現有算法。
4 資源分配問題
資源分配問題主要研究如何在多種資源與多個使用者之間建立合理、有效的分配,以優化整體的資源使用效率。根據問題中資源與使用者的匹配復雜程度,可以將資源分配問題劃分為單段分配問題(如出租車派單、廣告分配)和多段分配問題(如供應鏈管理)。經典的離線分配問題本身并不難以求解,通常可以采用匈牙利算法或網絡流的方式獲得最優的分配方案。但在實際應用中,由于分配中的一方或雙方具有動態性,通常沒有辦法獲取求解所需的所有信息。例如在出租車派單問題中,某個區域的空閑車輛是動態變化的,同時乘客的出現也是具有不確定性的。在這種動態性下,快速地建立高效的匹配來降低司機空載時間及乘客等待時間是非常具有挑戰性的。下面分別針對單段分配和多段分配對相關文獻進行梳理。
4.1 單段分配問題
在單段分配問題中,資源與使用者之間的匹配關系是一次性的。針對單段分配問題的強化學習研究主要集中在出租車派單、在線廣告分配等問題中。下面從這兩大類場景出發,介紹相關的典型研究。
(1)出租車派單問題
派單問題主要指如何滿足實時出現的乘客需求,使得用戶等待時間和司機空載時間盡可能短。一直以來,派單問題在交通優化問題上都有廣泛的研究[5-6,42-43]。2009年,Alshamsi A等人[44]開始使用多智能體技術解決派單問題,沒有使用強化學習的機制解決這個問題,而是使用事先制定好的規則指導各個智能體的行為,顯而易見,這種情況下智能體的適應能力是受限的。
自從網約車興起,由于場景本身的復雜性,越來越多的工作開始關注如何使用強化學習技術進一步改善派單效果。2018年滴滴出行科技有限公司聯合密歇根州立大學的研究人員提出使用強化學習方法對出租車進行調度,平衡各個區域的供需關系[45]。在他們的模型中,整個城市被劃分為由面積相等的六邊形構成的若干網格,并將一天拆分成144個時間片。在每一個時間片內產生的訂單,首先使用網格內的車輛進行匹配,若無法得到滿足,再使用鄰居網格中的可用車輛進行匹配。在具體建模中,每個車輛被建模成一個智能體,智能體能夠觀察到的狀態為,其中,st表示t時刻的全局信息,gi表示該智能體對應的網格。智能體的動作空間iA包含7個動作,表示下一時刻能夠到達的網格,其中,前6個動作表示移動到當前所在網格的6個鄰居網格,最后一個表示留在當前網格。每個智能體i都有一個獎勵函數Ri,具體來說,設智能體i在t時刻采取動作為該動作獲得的獎勵是在該智能體所處的網格中包括它自己在內的所有智能體在t+1時刻接收的訂單收益的平均值。這樣設計獎勵函數的好處有兩點:一是鼓勵車輛自發地從供給多的網格流向供給少的網格;二是避免所有車輛都為了追求利益而集中到熱點區域。在策略學習方面,參考文獻[45]提出了兩種帶有上下文信息的學習算法:上下文深度Q網絡(contextual DQN,cDQN)算法和上下文多智能體動作-評價算法(contextual multi-agent actorcritic algorithm,cA2C)。在cDQN算法中,作者利用全局信息共享以及每個網格內的獎勵平均分配這兩個特性,將對每一個智能體每個動作的Q值的計算轉化為僅對當前狀態下每一個網格的Q值的計算,即僅計算,其中,gd表 示 動作中指定的目的地。基于這一點,所有智能體可以共享一個全局的Q值。而上下文信息主要體現在兩個方面:地理上下文信息和協作上下文信息。地理上下文信息主要根據地理位置,對有效的區域進行編碼;協作上下文信息主要在可行的動作上進行限制,避免有車輛從A地到B地的同時還有車輛從B地到A地。除此之外的部分就是一個標準的DQN算法。cA2C算法中也有類似的處理,這里不再贅述。在結果方面,通過在滴滴出行提供的數據上進行模擬,可以發現基于cDQN和cA2C的方法在總收益和訂單的接受率上都有顯著提高。
上述方法主要存在兩個問題。首先,作者只使用強化學習的技術平衡了各個網格中的供需關系,但是最終車輛到乘客的匹配是通過規則實現的,因此整體上是一個兩段式的解決方案。其次,所有的智能體共享一個全局的Q函數,是一個中心化的解決方案,在擴展性和復雜性上都存在一些瓶頸。2019年,Li M等人[46]提出了一種新的端到端的解決方案。與之前的工作相比,該工作主要有以下幾點不同。首先在狀態方面,每個智能體i可以基于一個觀測函數,從全局信息獲取一個自己獨有的狀態oi。全局狀態包括訂單分布、司機分布、全局時間信息、交通信息以及天氣信息等。這些信息都能幫助智能體更好地進行決策。然后在動作方面,智能體i需要從oi包含的未分配訂單中選擇并進行匹配。接著在獎勵方面,作者綜合考慮了每個智能體實際接單的收益和訂單目的地的潛在收益,很明顯,后者是由環境以及所有智能體的行為決定的。這樣做的目的是鼓勵智能體之間更好地合作。最后在策略學習方面,作者提出了一種合作派單(cooperative order dispatching,COD)算法。該算法主要的創新是引入了平均場強化學習(meaning field reinforcement learning,MFRL)[47],即在決策的時候每個智能體單獨進行決策并獲取動作,而在訓練的過程中,根據平均動作更新評價網絡,進而影響動作網絡。具體來講,針對每一個動作ai,COD算法會為其計算一個平均動作,即完成動作ai后,將所在區域中其他司機的數量除以可接收訂單的數量。這個平均動作會作為額外的信息被引入評價網絡的更新當中。
關于派單問題,還有很多優秀的工作,例如上海交通大學與滴滴團隊提出的一種完全分散化的多智能體強化學習策略[48],以及香港科技大學聯合滴滴團隊提出的一種組合優化與強化學習相結合的兩段式解決方案[49]。限于篇幅,本文不再展開介紹,感興趣的讀者可以閱讀原始論文獲取更多細節。
(2)在線廣告分配問題
同派單問題相比,在線廣告分配的問題場景更清晰。對于廣告平臺,每天有大量的客戶訪問平臺。平臺通過向這些用戶展示廣告,從廣告主處獲取收益。目前主流的廣告展示策略有兩種,第一種是傳統的合約廣告,即平臺與廣告主簽訂合約,在一定時間內向一定數量、符合條件的用戶展示該廣告主的廣告。合約達成后,平臺會獲取收益,反之,平臺需要承擔違約的懲罰。這種廣告方式在在線廣告的早期非常流行,但是近些年來,其市場份額逐漸被新興的實時競價(real-time bidding,RTB)方式占據。實時競價最早在搜索廣告中出現,當用戶查詢一個關鍵詞時,廣告主針對這個查詢發起競拍并向平臺報價,平臺根據報價選擇廣告進行展示。后來這種方式擴展到展示廣告中,競拍的依據也從查詢變成用戶屬性。雖然近些年實時競價的市場在不斷擴大,但是合約廣告仍然占據大量的市場份額。
在在線廣告領域,一個典型的使用強化學習進行分配的工作是阿里巴巴團隊于2018年提出的一種融合合約廣告與實時競價的解決方案[50]。假設有n個用戶展示需要分配給m個合約。對于每一個展示,都有一組實時出價價格,對此展示平臺可以選擇分配給某一個合約廣告或分配給出價最高的競價廣告。最終的優化目標是最大化合約廣告和實時競價的整體收益以及整體合約廣告的質量。作者提出了一種比較新穎的方式,即為每個合約模擬實時競價行為,并為每一次競價展示出一個價格。然后平臺像普通的實時競價系統那樣按照第二價格的方式進行廣告分配展示。作者在假設所有展示信息和實時出價已知的情況下,建立了最優分配的線性規劃,并根據互補松弛定理證明,只要合約對應的出價滿足式(5),最終的分配策略就是最優的①具體證明過程參見參考文獻[50]。:?
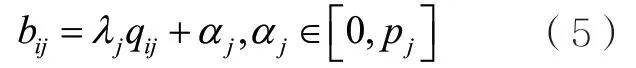
其中,bij、λj、qij、pj分別表示合約j對展示i的出價、合約j的質量權重、展示i相對于合約j的質量,以及違反合約j的懲罰。因此,問題的關鍵轉化為求解合適的αj。但是在在線廣告中,展示機會到來的情況和對應的出價難以預測,因此難以利用傳統優化方法求解。為了解決這一問題,作者提出了一種多智能體強化學習的方法,即為每個合約分配一個智能體,讓智能體動態地決定當前展示的出價。具體來說,智能體j在第t步決策的狀態st包括時間信息(用于告訴智能體分配處于什么階段)、合約當前的滿足狀態(多少比例已經滿足,還有多少沒有滿足)以及在 1t?~t步之間智能體獲取的收益rt?1。動作表示αj的調整因子,滿足:
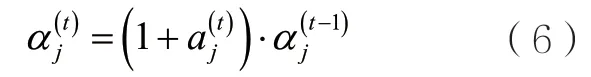
獎勵的設計比較關鍵,作者首先定義原始即時獎勵為t到t+1時刻平臺整體的廣告收益。在此基礎上進一步定義:
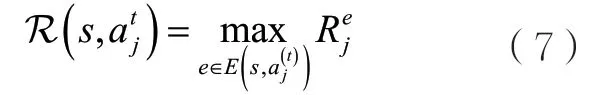
除了上述工作,還有更多的工作研究如何使用機器學習技術解決廣告展示以及推薦系統中的問題,如參考文獻[51-53],感興趣的讀者可以進一步研究這些工作。
4.2 多段分配問題
在單段分配問題中,只需要建立資源與使用者之間的關系即可,但是在多段分配問題中,面臨的情況會更復雜。通常資源的流通會形成一個軌跡,需要優化流通中的每一步從而獲得更好的分配效果,其典型的場景就是供應鏈問題。在供應鏈問題中,從原材料的生產、加工到銷售通常需要多個步驟,而每一步的資源分配都會影響最終的收益,因而更考驗分配算法的性能。下面對供應鏈的一些典型工作進行介紹。
供應鏈管理是一個傳統的優化問題,但是其中供需關系的動態性使得傳統的優化方法難以解決。隨著強化學習的興起,出現了大量使用強化學習解決供應鏈問題的工作,如參考文獻[54-55],但是這些工作都使用了非常簡單的供應鏈網絡(網絡只有兩層,或者網絡是一條鏈式的供應鏈)。Alves J C等人[56]在2020年改進了這些工作,他們將強化學習技術應用于一個更實際的場 景。在這個工作中,作者考慮了一個4層(供應商、工廠、批發商、零售商)的供應鏈網絡,每一層都有兩個參與者。供應商提供原材料,工廠加工成產品,然后再依次交給批發商、零售商進行售賣,其中原材料的供應是有一定容量的,鏈路中的每一個節點都有自己的庫存容量,同時零售商還需要負責應對需求不確定性。整個供應鏈采取統一的控制方案,并且優化目標是在一個時間段內滿足用戶的商品需求,同時最小化運營成本。這里的運營成本包括4個方面:原材料的生產成本、工廠加工成本、各環節運輸成本和倉儲成本。
在MDP建模方面,i時刻的狀態包括以下部分:(i+1)時刻各個零售商面臨的需求數量、每一個節點當前的庫存情況和(i+1)時刻的預計供給情況、當前時刻距離本次算法迭代終止剩余可執行動作的步數。智能體需要在每個時刻決定所有的原材料生 產數量和資源流通情況,具體包括兩部分。第一部分是每個供應商需要生產的原材料數量。為了便于模型學習,所有動作都用比例表示,例如供給節點j生產原材料的動作aj表示生產cjaj個原料,其中,cj表示節點j的最大產量。第二部分是每個上游節點對下游節點供應的數量。如節點i對節點j的供應動作表 示有的庫存需要從節點i運出,其中,,Si表示節點i的庫存量。這樣設計的目的是保證總輸出量不超過庫存量,同時剩余量將作為庫存繼續保留。在獎勵設計部分,為了保證最終能夠學習到全局最優的策略,作者將所有的成本都考慮到獎勵設計中,即整個獎勵包括生產、運輸、加工、存儲、原料廢棄以及沒有滿足客戶需求帶來的懲罰等部分。考慮到問題的動作空間很大,作者采用一種基于PPO的專用于GPU并行加速的PPO2算法進行策略學習。通過訓練并同主流的基于線性規劃的算法進行對比,發現PPO2算法能夠降低約87.4%的未滿足需求,同時成本有約1.3%的下降。
5 裝箱問題
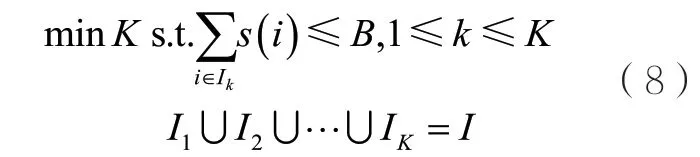
裝箱問題是一個NP完全問題,早在20世紀70年代中期,Johnson D S等人[57]就證實了對于現有主流的兩種近似算法(降序首次適應(first-fit decreasing,FFD)算法和降序最佳適應(best-fit decreasing,BFD)算法)都能在時間復雜度的條件下達 到的近似性能保證。這兩種方法都先將待裝箱的物件按其大小進行降序排序。不同的是,對于一個給定的物件i,FFD算法將依次遍歷箱子序列,并從中選擇第一個能裝下當前物件i(即剩余空間大于s(i))的箱子;BFD會從所有能裝下當前物件i的箱子中選擇剩余空間最小的箱子,即剩余空間大于s(i)且最接近s(i)的箱子。
在實際應用領域,產業界真實面對的不是上述最基礎的裝箱問題,而是裝箱問題的多種變體,如二維裝箱問題、三維裝箱問題,或需要考慮不同裝箱表面、箱子重量、箱子高度等信息的更復雜的裝箱問題。根據實際情景中是否能提前知悉全部的物件信息,本文將裝箱問題分為離線裝箱問題和在線裝箱問題,前者不僅可以知悉全部的物件信息,甚至可以根據策略決定裝箱順序;后者面對的是未知的物件序列,只能在物件到來時做出實時響應,執行裝箱動作。
5.1 離線裝箱問題
基礎的離線裝箱問題一般使用FFD和BFD這樣的近似算法或簡單的線性規劃算法取得不錯的結果。當面對的是更加復雜的實際裝箱問題時,這些方法往往需要更加復雜的問題建模,耗費更長的計算時間。學術界和產業界都在裝箱問題上進行過許多嘗試,來自菜鳥物流的Hu H Y等人[58]將強化學習應用到裝箱問題上。不同于使用固定大小的箱子的經典裝箱問題,考慮到在真實物流問題上可以使用軟材料來打包物件,而打包成本又與材料的表面積相關,這份工作針對的是經典裝箱問題的一個變體:如何使用最少的包裝材料把所有的三維物件打包好。具體來說,他們使用強化學習智能體來決定物件的打包順序,而打包時物件具體的擺放位置和方向則由一套固定的常規的啟發式規則來決定。強化學習智能體面對的狀態空間由需要打包的所有物件的大小組成,表示為,其中,li、wi、hi分別表示物件的長、寬、高。他們從指針網絡(pointer network)[59]中獲得啟發,將所有物件的大小信息依次輸入一個長短期記憶(long short-term memory,LSTM)編碼器中,再由一個LSTM解碼器依次輸出物件的打包順序,即將物件的打包順序作為智能體的動作空間。由LSTM編碼器和LSTM解碼器構成的神經網絡指示的隨機策略可以表示為p(o|s),而智能體的動作則用打包物件的表面積進行評估,表示為SA(o|s)。他們使用樸素的REINFORCE算法對策略進行更新。緊接著,Hu H Y等人[60]在上述工作[58]的基礎上進一步利用多任務的形式,結合使用強化學習和監督學習,使智能體同時決定物件打包的順序和擺放的方向。物件的打包順序仍舊基于指針網絡實現,不同的是在策略的更新算法上使用了PPO算法。而物件的擺放方向則由一個分類器決定,該分類器是使用目前所得最佳方案中的擺放方向作為標簽訓練得到的。該工作在實驗部分使用了真實的數據集,實驗結果表明,相比于之前廣泛使用的啟發式規則方法和Hu H Y等人[58]提出的強化學習方案,這樣的智能體能取得更好的結果。同時,這一方法在真實生產環境中的應用也展示出,相比原生產線之前使用的貪心算法,該方法更能節省生產線成本。
不同于Hu H Y等人[58,60]采用類似于seq2seq(sequence-to-sequence)的建模方法,來自InstaDeep公司的Laterre A等人[61]把三維裝箱問題建模成一個馬爾可夫決策過程,并使用基于神經網絡的蒙特卡洛樹搜索算法來解決三維裝箱問題。與前面的工作類似,強化學習智能體的狀態空間由待打包物件的大小組成,即。不同的是,智能體的動作空間不只包含選擇的物件編號,還包含其左下角的 擺 放位 置 坐標(xi,yi,zi)、物 件 擺放時的旋轉方向oi,oi∈ {0 ,1,2,3,4,5}對應長方體的6種旋轉結果,即完整的動作可以表 示為(i,xi,yi,zi,oi)。在該工作的解決方 案中,Laterre A等人[61]把三維裝箱問題建模成一個單人游戲,為了進一步提升智能體的決策表現,他們還添加了一個獎勵排名機制——動作的獎勵值通過對最近的裝箱操作的相對表現進行重塑得到。具體而言,智能體最近的性能表現會被存入一個緩沖區,對于設定的閾值α∈ ( 0,100%),僅當動作的性能表現超過緩沖區中α的記錄時,智能體才能獲得一個正向的獎勵值。這樣的獎勵排名機制使得單個智能體在多次探索中得到類似雙人游戲中與對手博弈的激勵作用。實驗采用的數據集由隨機將原始箱子切成多個物件創建得來,相比于傳統的蒙特卡洛樹搜索算法、啟發式算法和整數規劃算法,該方法顯示出更好的性能。
Li D D等人[62]認為使用啟發式規則來決定物件的擺放方向和放置位置或通過切割原始箱子的方式來獲取物件集合是這些方法的局限性,他們使用注意力機制來決定物件的擺放順序、擺放方向和擺放位置。在Li D D等人[62]的建模中,狀態空間由各個物件的信息組成,即其中表 示當前 物件 是 否已打包的0-1因子,表 示物件的長、寬、高,表示物件i當前的坐標,分別為相對于箱子前端、左端、下端的距離;動作空間的定義與Laterre A等人[61]的類似,由物件編號i、擺放方向oi和擺放位 置共同 構成;動作的獎 勵 值 函數則是一個增量函數,獎勵值由當前箱子里的物件的體積計算得到。智能體的訓練使用了A2C算法,與Hu H Y等人[60]提出的方法和一個遺傳算法進行對比,實驗結果表明,這一方法具有更小的箱子間隙比率(bin gap ratio),其中,W、L、H分別表示箱子的寬度、長度和高度。
Cai Q P等人[63]提出了一種基于強化學習算法初始化的啟發式算法優化框架RLHO(reinforcement learning heuristic optimization),并結合使用PPO算法和模擬退火算法來解決一維裝箱問題。在這兩種算法的結合中,PPO的輸出方案被當作模擬退火算法的初始狀態;而模擬退火算法則在有限次的迭代中尋找一個更好的解決方案,并基于最終找到的解決方案給PPO算法提供一個折扣未來獎勵(discount future reward),從而指導PPO算法獲取更優的初始狀態。在智能體的設計方面,狀態空間被定義為待裝箱物件的一個全排列;動作空間則是這個全排列中任意兩個物件的排序交換;并以受當前動作影響,待裝箱物件的全排列對應的裝箱成本的變化值作為智能體的即時獎勵。這一工作的實驗結果表明,基于RLHO框架,將PPO算法和模擬退火算法結合的方式能夠取得比僅使用PPO算法或僅使用基于隨機初始化的模擬退火算法更好的結果。
5.2 在線裝箱問題
與離線裝箱問題不同的是,在線裝箱問題無法得知未來到達物件的信息,因而只能通過動態策略求解,不存在靜態裝箱解,相比之下,在線裝箱問題要取得一個好的全局解更加困難。
與以往把箱子和待裝箱物件的大小編碼作為輸入的方式不同,Kundu O等人[64]結合使用計算機視覺的技術,把箱子的實時狀態和待裝箱物件都表示為一個W×H的0-1矩陣(被物件占據的位置用0表示,可放置物件的位置用1表示)。這兩個W×H的矩陣被拼接在一起,共同組成一個形狀為W×2H的輸入狀態s。在強化學習智能體的動作空間的設計上,Kundu O等人[64]考慮的是待裝箱物件的左上角的擺放位置,因而對于一個橫截面為W×H的箱子而言,有W×H個可行的動作,再加上一個不將當前物件裝入當前箱子的動作,共同夠成了大小為W×H+1的動作空間。在獎勵值函數的設計上,對于實際無法擺放物件的無效動作,給予一個負反饋;對于有效動作,則將物件擺放后的連通區域大小和擺放緊密度的乘積作為動作的獎勵值。這里的連通區域大小指的是緊鄰新物件4條邊的區域數,可以對那些把新物件緊鄰舊物件擺放的動作起到一定正向激勵作用;而擺放緊密度則表示連通區域的大小占包含該連通區域的最小長方形的比值,用于鼓勵使得連通的物件的形狀更接近于長方形的擺放動作。實驗結果表明,這種基于計算機視覺和強化學習的在線裝箱方法能夠取得比現有在線裝箱方法更優的性能表現。
Verma R等人[65]在在線裝箱問題的狀態空間的建模上使用了和Kundu O等人[64]相似的思路——用一個二維矩陣表示箱子自上而下的投影。不同的是,由于研究問題從二維裝箱轉換到三維裝箱,僅用0、1表示投影點的狀態遠不足夠,因而每個投影點又進一步地使用一個值表示當前碼垛物件的高度。此外,為了避免動作空間過大帶來的探索效率過低的問題,也為了有效利用人為總結出來的有效規律(如把物件緊鄰已有物件擺放會更高效),Verma R等人[65]使用一種兩階段決策的模式:首先基于一些基礎規則篩選出物件擺放方向和位置的合法可行解,這些可行解主要包含將物件擺放在箱子的四角和緊鄰已擺放物件的四角的擺放方式;其次,基于DQN算法的價值函數,從中選擇一個擺放方案。在獎勵值函數的設定方面,作者認為在三維裝箱問題上沒有顯式的單步獎勵,他們通過將裝箱序列的最終獎勵值定義為整個裝箱序列最終的裝箱比率,并結合一個指數衰減函數來反推得到每步的單步獎勵值的方式,推進這一強化學習智能體的訓練學習。
來自國防科學技術大學的Zhao H等人[66]使用了A2C的算法,其利用傳感器獲取箱子當前的狀態信息,得到一個自上而下視角的碼垛高度的投影矩陣H,假定大小為L×W。與此同時,待擺放物件i的長li、寬wi、高hi信息也被分別填充進3個L×W的矩陣中,構成形狀為L×W×3的待擺放物件i的大小信息Di。而智能體的狀態空間則由把H和Di拼接得到的L×W×4的信息輸入一層狀態卷積網絡得到。同樣,為了避免探索過程中的無效動作過多(這里的無效動作指的是無法擺放物件的動作),Zhao H等人[66]引入了一個可行動作空間掩碼的預測器,而智能體僅在actor的輸出中選取未被可行動作掩碼預測器篩除的有效動作。掩碼預測器的監督學習機制使得智能體的交互學習過程以更快的效率收斂。對于獎勵值的設計部分,直接使用每一步動作帶來的箱子空間占用率的提升量作為單步獎勵,實驗結果表明,這種單步獎勵的設定方法要優于將最終箱子空間占用率作為最終獎勵值的方法。
6 結束語
資源優化問題無處不在,更好的資源優化方案會帶來更好的經濟、社會效益。本文調研了強化學習在資源優化領域的最新應用,并針對3類重要的優化問題,即資源平衡問題、資源分配問題和裝箱問題,就各個問題的特性、各個解決方案的問題建模和算法設計展開了詳細介紹,以期能幫助讀者更好地理解各領域。
雖然強化學習在解決實際資源優化問題方面取得了很多重要突破,但是目前仍存在一些問題亟待解決。首先,訓練強化學習算法需要建立模擬環境或大量的歷史數據,這提高了部署強化學習的方案門檻,很多小規模的優化場景很難應用。其次,訓練算法需要大量計算資源,同時為了應對實際問題中的動態變化,需要定期地更新模型。這些都代表著巨大的計算成本。最后,大部分強化學習方案不具備普適性,需要根據具體的業務場景進行定制。這就需要大量強化學習專家的參與,難以形成規模效應。鑒于這些問題,研究者期待數據依賴更小、計算成本更低并且具有普適性的強化學習解決方案的出現。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
