基于無監(jiān)督學(xué)習(xí)的可持續(xù)發(fā)展目標(biāo)數(shù)據(jù)分類
2021-09-17 09:43:30雷聲黎建輝張麗麗
數(shù)據(jù)與計(jì)算發(fā)展前沿 2021年4期
雷聲,黎建輝,張麗麗
1.中國(guó)科學(xué)院計(jì)算機(jī)網(wǎng)絡(luò)信息中心,北京 100190 2.中國(guó)科學(xué)院大學(xué),北京 100049
引言
聯(lián)合國(guó)可持續(xù)發(fā)展目標(biāo)(Sustainable Development Goals,SDGs)是聯(lián)合國(guó)在2015年9月制定的17 個(gè)全球發(fā)展目標(biāo),旨在從2015年—2030年間以綜合方式徹底解決社會(huì)、經(jīng)濟(jì)和環(huán)境三個(gè)維度的發(fā)展問題,從而轉(zhuǎn)向可持續(xù)發(fā)展道路[1]。SDGs 數(shù)據(jù)對(duì)可持續(xù)發(fā)展工作具有極為重要的指導(dǎo)意義,它對(duì)可持續(xù)發(fā)展給出了細(xì)致而全面的數(shù)據(jù)指標(biāo),涉及范圍極廣,值得研究的相關(guān)數(shù)據(jù)也極多。數(shù)據(jù)與計(jì)算技術(shù)飛速發(fā)展,在科學(xué)研究中能夠起到輔助與支撐的作用,甚至能夠驅(qū)動(dòng)和引領(lǐng)科學(xué)研究活動(dòng)[2]。截至目前,對(duì)SDGs 數(shù)據(jù)及工作進(jìn)行研究討論的中英文文獻(xiàn)數(shù)量已經(jīng)達(dá)到了數(shù)十萬篇。SDGs 所涉及的龐大數(shù)據(jù)量在為相關(guān)科研工作提供信息的同時(shí)也提高了科研人員的使用難度,要想在如此海量的數(shù)據(jù)中獲得與研究目標(biāo)相關(guān)的數(shù)據(jù),就必須將數(shù)據(jù)進(jìn)行合理的分類。機(jī)器學(xué)習(xí)時(shí)代的來臨實(shí)現(xiàn)了很多技術(shù)上的應(yīng)用[3]。聯(lián)合國(guó)為SDGs 中的每項(xiàng)指標(biāo)都提供了詳細(xì)的描述文檔,基于機(jī)器學(xué)習(xí)利用這些描述文檔為數(shù)據(jù)進(jìn)行分類可以更好地為從事SDGs 相關(guān)研究的科研人員提供便利。
現(xiàn)有的文本分類算法大多屬于有監(jiān)督模型,它需要大量人工標(biāo)注的文檔作為訓(xùn)練集,而聯(lián)合國(guó)官方能夠提供的標(biāo)記數(shù)據(jù)極少,利用有監(jiān)督甚至半監(jiān)督模型都難以得到令人滿意的效果。且聯(lián)合國(guó)為每個(gè)SDGs 指標(biāo)都制定了詳細(xì)的描述文檔,人工地根據(jù)這些文檔對(duì)數(shù)據(jù)進(jìn)行標(biāo)記會(huì)是一個(gè)復(fù)雜而耗時(shí)的工程。因此,使用無監(jiān)督算法來進(jìn)行實(shí)際分類是更為合適的選擇。本文基于數(shù)據(jù)描述無監(jiān)督地對(duì)科學(xué)數(shù)據(jù)進(jìn)行了SDGs 相關(guān)性分類,主要分為以下兩個(gè)階段:
(1)類別描述信息篩選。本文綜合textrank 和相對(duì)詞頻統(tǒng)計(jì)(Relative Frequency,RF)的方法,無監(jiān)督地從聯(lián)合國(guó)所提供指標(biāo)描述文檔中提取指標(biāo)關(guān)鍵詞集,以此作為類別描述信息。
(2)數(shù)據(jù)分類。本文將類別信息和數(shù)據(jù)描述信息投影到同一語(yǔ)義空間中,基于相似度匹配的自學(xué)習(xí)算法無監(jiān)督地對(duì)數(shù)據(jù)進(jìn)行了分類。
在聯(lián)合國(guó)官方所提供的官方數(shù)據(jù)集上的測(cè)試表明,我們對(duì)SDGs 科學(xué)數(shù)據(jù)的分類是有效的;且相對(duì)于目前主流的基于主題模型的無監(jiān)督文本分類算法而言,我們所提模型能夠取得更好的效果。
1 相關(guān)工作
1.1 無監(jiān)督文本關(guān)鍵詞提取
無監(jiān)督的文本關(guān)鍵詞提取方法種類繁多,但按其原理大致可以分為以下三類:基于統(tǒng)計(jì)的方法、基于圖結(jié)構(gòu)的方法以及基于語(yǔ)義的方法。
(1)基于統(tǒng)計(jì)的方法通常綜合統(tǒng)計(jì)TFIDF[4]、詞共現(xiàn)[5]、詞頻[6]、詞性[7]等一系列指標(biāo)信息,再根據(jù)這些指標(biāo)進(jìn)行排序。例如羅燕等人[6]通過齊普夫定律推導(dǎo)出文本中同頻詞數(shù)的計(jì)算公式,并綜合詞頻統(tǒng)計(jì)和TFIDF 進(jìn)行了關(guān)鍵詞提取;Barker 等人[7]通過詞頻及詞長(zhǎng)等特征選擇性提取名詞短語(yǔ)作為文本關(guān)鍵詞;Song 等人[4]綜合單詞詞性的語(yǔ)法信息和TFIDF 信息提出了一種新聞關(guān)鍵詞提取方法。這種方法簡(jiǎn)單易用,但需要大量文本進(jìn)行對(duì)比統(tǒng)計(jì),在文本數(shù)量較少的情況下效果不佳。
(2)基于圖結(jié)構(gòu)的方法將詞語(yǔ)視作圖中的節(jié)點(diǎn),按照特定的規(guī)則為節(jié)點(diǎn)之間進(jìn)行關(guān)聯(lián),據(jù)此迭代計(jì)算詞語(yǔ)的重要性。典型地,Mihalcea 等人[8]提出的textrank 模型基于google 所提Pagerank 的鏈接分析理論,通過迭代計(jì)算節(jié)點(diǎn)邊緣權(quán)重來計(jì)算詞語(yǔ)重要性;Bellaachia 等人[9]提出的NERank 模型在節(jié)點(diǎn)邊緣權(quán)重的基礎(chǔ)上,也考慮了單詞權(quán)重;Saroj 等人[10]綜合考慮詞語(yǔ)節(jié)點(diǎn)的中心程度、位置、詞頻、及鄰居頻數(shù)來考慮節(jié)點(diǎn)的重要性,從而提取關(guān)鍵詞。這種方法比較靈活,既可以僅利用文檔本身的信息來完成關(guān)鍵詞抽取,也可以很容易地融合外界權(quán)重、相似度等信息來綜合構(gòu)建詞圖網(wǎng)絡(luò)。
(3)基于語(yǔ)義的方法通常使用PLSA[11]、LDA[12]等主題模型或者word2vec[13]等語(yǔ)言模型對(duì)文本和詞匯進(jìn)行語(yǔ)義建模,進(jìn)而抽取關(guān)鍵詞。例如石晶等人[14]基于LDA 得到文本和詞匯的主題分布,通過比對(duì)詞與文檔的主題分布情況來獲取關(guān)鍵詞;劉嘯劍等人[15]利用文檔和詞語(yǔ)的主題信息并結(jié)合詞語(yǔ)的統(tǒng)計(jì)特征來為候選詞打分。這種方法能夠獲取語(yǔ)義相似性的關(guān)系,因此常常能夠獲得不錯(cuò)的效果。
本文綜合了相對(duì)詞頻和textrank 的方法從聯(lián)合國(guó)提供的SDGs 描述文檔中抽取關(guān)鍵詞,以得到SDGs 類別描述詞集。
1.2 無監(jiān)督文本分類
現(xiàn)有的無監(jiān)督文本分類研究按照其思想可被大致分為以下兩類:基于相似度匹配的方法和基于主題模型的方法。
(1)基于相似度匹配的方法通常通過計(jì)算、對(duì)比類別描述和文本之間的相似度來實(shí)現(xiàn)分類,它并不關(guān)注樣本本身,而是將文本和類別投影到同一語(yǔ)義空間中并直接對(duì)二者進(jìn)行比較,廣泛適用于各種數(shù)據(jù)集。例如Druck 等人[16]首先預(yù)定義一批類別關(guān)鍵詞,利用最大熵算法,最大化文檔的預(yù)期類別分布與類別中相應(yīng)關(guān)鍵詞的類別分布之間的相似度來優(yōu)化分類器參數(shù);Chang 等人[17]通過基于英文維基百科的顯示語(yǔ)義分析(Explicit Semantic Analysis,ESA)來計(jì)算文檔與類別描述之間的相似度,但這種方法需要準(zhǔn)確地用詞條描述來替換對(duì)應(yīng)詞條,難以推廣到概念描述不夠多的其他領(lǐng)域及數(shù)據(jù)集中;Song 等人[18]同樣利用ESA 來評(píng)估文檔-類別相似度,并通過對(duì)類別進(jìn)行分層來解決類別重合,獲得了良好的效果。
(2)基于主題模型的方法通常先學(xué)習(xí)文檔集得到聯(lián)合概率分布,再通過聯(lián)合概率分布得到條件概率分布實(shí)現(xiàn)分類,它基于數(shù)據(jù)集中的共現(xiàn)分布進(jìn)行推理,能夠很好地分析文本本身的特點(diǎn)且不依賴于外界知識(shí)庫(kù),是目前主流的無監(jiān)督文本分類方法。但由于主題模型的分布推理通常基于共現(xiàn)統(tǒng)計(jì),當(dāng)面對(duì)小規(guī)模數(shù)據(jù)集或短文本數(shù)據(jù)集時(shí),詞共現(xiàn)矩陣往往過于稀疏,因此在這些數(shù)據(jù)集上的應(yīng)用效果并不理想。Xia 等人[19]首先利用類別描述種子詞產(chǎn)生少量文本,通過LDA 推理得到類別的狄利克雷先驗(yàn)(主題-詞矩陣),再通過詞分布推斷具體文本的類別分布; Li 等人[20]直接利用類別描述種子詞集和主題模型進(jìn)行主題推斷,從而完成對(duì)文本種類標(biāo)簽的預(yù)測(cè);Yang 等人[21]為了解決短文本數(shù)據(jù)集共現(xiàn)矩陣稀疏的問題,將文本中的詞排列組合成二元詞組來構(gòu)建共現(xiàn)矩陣,但這種重復(fù)統(tǒng)計(jì)所帶來的提升非常有限,效果依然不夠理想。
由于基于主題模型的方法在短文本上應(yīng)用效果不佳,而SDGs 數(shù)據(jù)描述文本的長(zhǎng)度通常在10~100詞之間,屬于短文本。因此,本文主要采用了基于相似度匹配的方法,一方面,本文利用詞向量構(gòu)建通用語(yǔ)義空間,直接通過文本-類別間的距離度量來對(duì)文本進(jìn)行分類,以適應(yīng)不同類型的文本數(shù)據(jù);另一方面,也利用同類文本中詞匯的相似分布,通過自訓(xùn)練算法對(duì)分類器進(jìn)行迭代更新。
2 SDGs 數(shù)據(jù)分類方法設(shè)計(jì)
本文對(duì)SDGs 科學(xué)數(shù)據(jù)進(jìn)行分類的流程框架如圖1所示,主要包括數(shù)據(jù)提取和文本分類兩個(gè)部分。
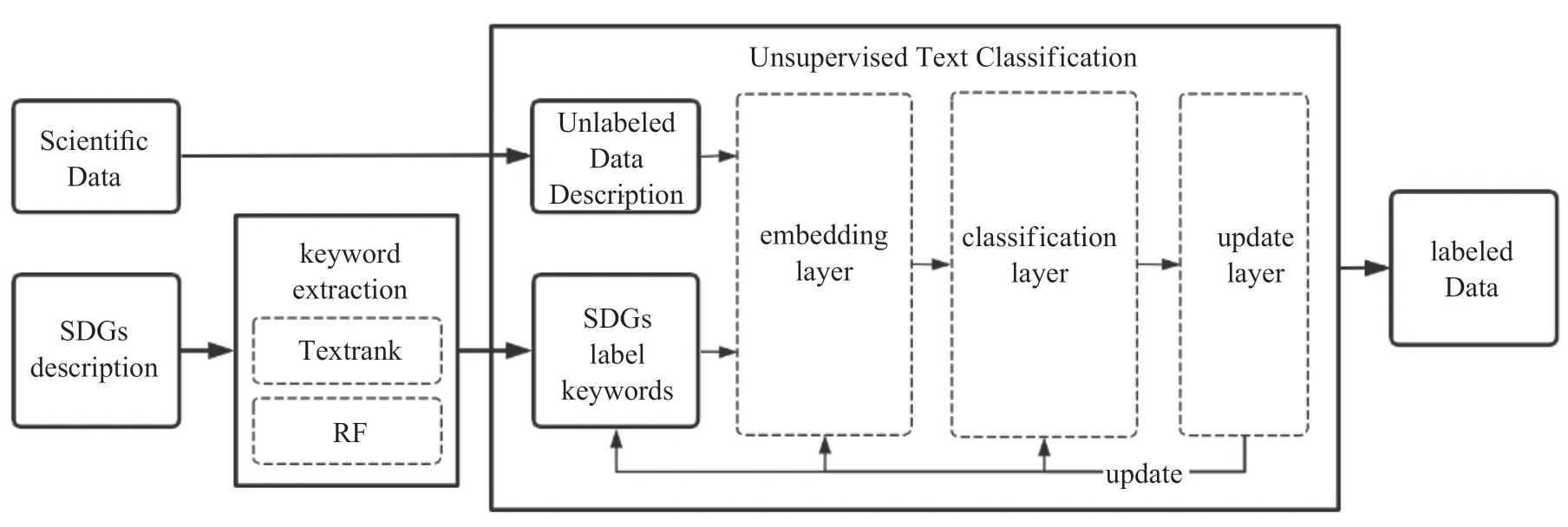
圖1 基于無監(jiān)督的SDGs 數(shù)據(jù)分類Fig.1 Unsupervised SDGs data classification
(1)數(shù)據(jù)提取。根據(jù)聯(lián)合國(guó)提供的指標(biāo)類別描述文檔,利用綜合textrank 和相對(duì)詞頻統(tǒng)計(jì)的關(guān)鍵詞抽取算法提取出SDGs 類別關(guān)鍵詞作為類別描述,提取待分類的科學(xué)數(shù)據(jù)中的標(biāo)題及描述信息得到數(shù)據(jù)描述文本。
(2)文本分類。通過一個(gè)基于無監(jiān)督的文本分類算法根據(jù)(1)中提取出的數(shù)據(jù)描述文本對(duì)科學(xué)數(shù)據(jù)進(jìn)行歸類。
2.1 SDGs 類別關(guān)鍵詞提取
由于本文提取類別關(guān)鍵詞來表征類別信息,這些關(guān)鍵詞應(yīng)當(dāng)具有兩個(gè)特點(diǎn):(1)能夠概括類別;(2)能夠與其他類別進(jìn)行區(qū)分。前者需要利用常規(guī)的關(guān)鍵詞抽取算法如TFIDF、textrank 等對(duì)官方所給描述文檔進(jìn)行精煉提取,后者需要關(guān)鍵詞為類別專屬詞或具有足夠的類別區(qū)分度。在本文中,我們首先采用textrank 初篩出類別關(guān)鍵詞,再根據(jù)詞頻計(jì)算詞語(yǔ)的相對(duì)詞頻,再次篩選得到具有區(qū)分度的詞語(yǔ)集合作為最終的類別描述。
首先,我們根據(jù)文本內(nèi)部之間的共現(xiàn)關(guān)系構(gòu)建詞圖,首先利用textrank 公式迭代計(jì)算各個(gè)詞語(yǔ)節(jié)點(diǎn)的重要度得分,初步篩選出較多的類別描述詞;然后,我們通過公式(1)來統(tǒng)計(jì)獲取類別i中候選詞w的相對(duì)詞頻RF(w,i),為每個(gè)類進(jìn)行再次篩選,得到少量具有類別區(qū)分度的最終類別關(guān)鍵詞。
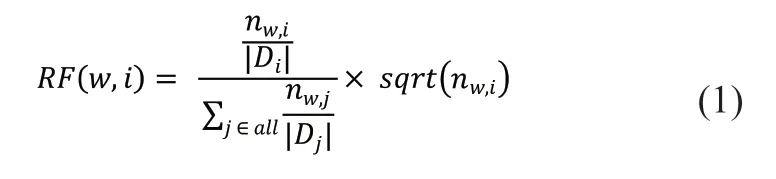
其中│Di│代表類別i中包含的文檔數(shù)量,nw,i則為詞語(yǔ)w在類別i中出現(xiàn)的次數(shù),TF(w,i)代表詞w在類別i中出現(xiàn)的頻率。SDGs 中每個(gè)類別中包含的文檔數(shù)量可能有較大差別,因此在計(jì)算類間相對(duì)性時(shí)需要排除這個(gè)因素影響。
2.2 基于無監(jiān)督的文本分類
本文所設(shè)計(jì)的基于詞向量的無監(jiān)督文本分類模型(Seedword and Embedding based Text Classification,SeedETC)以類別描述詞集和待分類數(shù)據(jù)描述文本集及對(duì)應(yīng)的初始化權(quán)重為輸入,利用詞向量將這些文本投影到同一語(yǔ)義空間,通過類EM 算法的自訓(xùn)練迭代算法[21]更新分類器模型的相關(guān)參數(shù),并輸出文本對(duì)應(yīng)的類別標(biāo)簽,主要包括以下四個(gè)步驟:
(1)詞向量編碼:利用已有詞向量模型對(duì)類別描述詞集及待分類文本進(jìn)行編碼,得到詞向量集;
(2)文本分類:根據(jù)詞向量及文本權(quán)重對(duì)待分類文檔進(jìn)行分類;
(3)模型更新:對(duì)分類結(jié)果進(jìn)行評(píng)估,更新部分樣本的類別標(biāo)記,更新類別描述詞、類別詞權(quán)重及文本權(quán)重。
(4)重復(fù)(1)、(2)、(3)步直到模型收斂。
2.2.1 詞向量編碼
詞向量使得詞之間存在“距離”概念,從而能夠表征詞之間的相似關(guān)系。使用詞向量進(jìn)行詞的向量化表示時(shí),能夠充分考慮到文本的局部和整體信息[22]。本層將文檔以及類別描述中的所有詞表征為向量的形式。目前,主流詞向量的表示方法有三種:一是基于詞頻統(tǒng)計(jì)的方式,比如使用全局矩陣分解的LSA[24]等,這種方式需要大量數(shù)據(jù)提供足夠的共現(xiàn)統(tǒng)計(jì)信息,不適用于本文任務(wù);第二種是基于局部上下文窗口的方式,如word2vec[25]、glove[26]等,能夠用于多種場(chǎng)景,計(jì)算代價(jià)低,效果也很好,是目前主流的詞向量表示方式;第三種則是基于預(yù)訓(xùn)練任務(wù)得到附屬詞向量產(chǎn)物的方式,如bert[27]等,這類模型相較于第二種效果更好,但其模型復(fù)雜,計(jì)算代價(jià)高,單純作為詞向量使用不夠靈活。因此,本文采用了拼接大規(guī)模語(yǔ)料和新領(lǐng)域語(yǔ)料的glove 詞向量來完成單詞的向量化編碼。
由于glove 是基于全局共現(xiàn)統(tǒng)計(jì)的算法,難以實(shí)現(xiàn)增量訓(xùn)練,而為了擬合數(shù)據(jù)集的分布,本文最終在經(jīng)過大規(guī)模語(yǔ)料D0預(yù)訓(xùn)練得到的glove 模型基礎(chǔ)上,額外使用待分類數(shù)據(jù)SDGs 元數(shù)據(jù)描述語(yǔ)料D1訓(xùn)練得到新數(shù)據(jù)分布的詞向量,將這兩種向量歸一化后進(jìn)行加權(quán)拼接,得到最終的詞向量,如公式(2)所示:
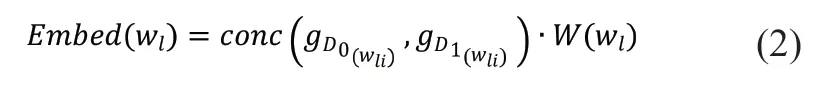
2.2.2 文本分類
在文本分類層,我們依據(jù)文檔詞與類別描述詞間的距離對(duì)文本進(jìn)行分類。與常見的先對(duì)詞向量進(jìn)行拼接或加權(quán)平均構(gòu)造文本向量,通過計(jì)算待分類文本與類別描述文本的向量間距來衡量文本與類別相似度的方法不同,本文使用詞作為一個(gè)獨(dú)立的單位,并不根據(jù)文檔對(duì)詞進(jìn)行整合。在分類時(shí),本層通過詞-詞、詞-類別、文本-類別3 個(gè)階段來計(jì)算文本與類別間的相似度,如算法1所示。

算法1:文本分類器輸入:待分類數(shù)據(jù)描述文本d的詞向量集,Ew,d;類別描述文本Li的詞向量集,Ew,Li;閾值窗口大小Cd;文本權(quán)重向量 Wd,l ;輸出:數(shù)據(jù)分類結(jié)果,prediction(d);文本d與各個(gè)類別的Li的相似度 ,sim(d,Li)Initialize:Wd,l=[1 for Li in Labels]For Li in labels do For wd in document d do For wLi in label Li descriptions do
其中,由于一篇文本中具有很多通用詞,在各個(gè)類別中分布都較為均勻,我們通過窗口Cd篩除掉這些對(duì)分類無意義的詞,只保留與分類有關(guān)詞的信息。
2.2.3 模型更新
本層的作用主要有以下兩個(gè)方面:一方面是更新文本標(biāo)記,利用改進(jìn)的輪廓系數(shù)指標(biāo)來評(píng)估分類結(jié)果,為被認(rèn)為正確分類的文本更新類別標(biāo)記;另一方面對(duì)分類器參數(shù)進(jìn)行更新,利用分類結(jié)果、文本與類別及數(shù)據(jù)集中其他文本的相似度,更新分類器中的類別描述詞及其權(quán)重、文本權(quán)重等參數(shù)。
(1)文本標(biāo)簽更新
本文通過改進(jìn)原用于評(píng)估聚類效果的輪廓系數(shù)(silhouettes)算法[28]來評(píng)估每個(gè)節(jié)點(diǎn)與類別的相對(duì)相關(guān)性。假定在分類層我們認(rèn)為文檔d屬于類別Li(d與類別Li的相似度最高),那么輪廓系數(shù)公式如式(3)所示。
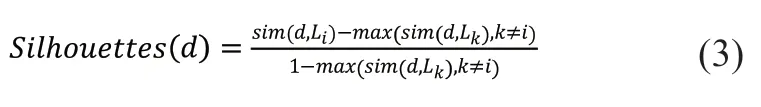
很容易發(fā)現(xiàn)silhouettes 公式的分母是為了除去相似度大小因素的影響而只關(guān)注距離的相對(duì)比例。但在實(shí)驗(yàn)中我們發(fā)現(xiàn),相似度本身數(shù)值大小也非常重要,因此我們?nèi)サ袅耸?3)中的分母,據(jù)此得到改進(jìn)的分類評(píng)估公式:
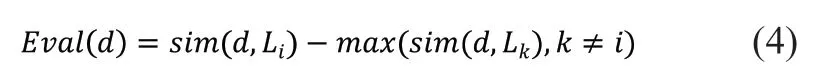
在每輪迭代時(shí),根據(jù)剩余待分類樣本數(shù)設(shè)定一個(gè)評(píng)估閾值,對(duì)所有分類評(píng)估分?jǐn)?shù)高于閾值的樣本更新其類別標(biāo)簽,剩余樣本則投入下一輪訓(xùn)練。
(2)分類器參數(shù)更新
對(duì)于分類器,主要需要更新以下3 種參數(shù):類別描述詞、類別描述詞權(quán)重和文本權(quán)重。
由于我們需要的類別描述詞需要滿足對(duì)類別的高區(qū)分度條件,因此本文通過相對(duì)詞頻統(tǒng)計(jì)來更新每個(gè)類別的描述詞。首先,從已更新標(biāo)簽的文本集中選出類別c 中的高頻詞作為該類別候選詞,并計(jì)算這些詞在當(dāng)前類與其他類別中的相對(duì)詞頻比例:
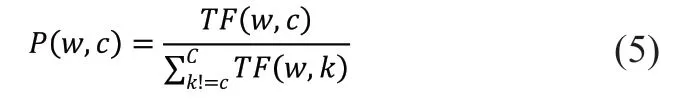
我們認(rèn)為高頻詞可以有效表征類別,而相對(duì)詞頻比越高,說明這個(gè)詞的類別區(qū)分度越高,最終篩選出相對(duì)詞頻比排名更高且滿足最低閾值的少量詞作為本輪分類器中更新的類別描述詞。
由于我們利用了相對(duì)詞頻比來獲取具有高區(qū)分度的關(guān)鍵詞,單純利用已更新標(biāo)簽的文本來更新其權(quán)重,將會(huì)導(dǎo)致權(quán)重偏高。為了獲取更真實(shí)的詞分布信息,我們借鑒了姜震等人[29]利用不精確的偽標(biāo)簽(Pseudo label)擴(kuò)充訓(xùn)練集的思想,利用了全體樣本來更新類別描述詞的權(quán)重。將所有樣本在當(dāng)前輪次中的預(yù)測(cè)結(jié)果作為偽標(biāo)簽,通過詞頻統(tǒng)計(jì)來更新詞權(quán)重。綜合以上考慮,最終確定類別描述詞權(quán)重W(w,c)更新公式如式(6)所示:

在本文中,文本與文本間的相似度完全由單詞計(jì)算得到,沒有利用到任何詞序信息,無法識(shí)別到長(zhǎng)詞組。因此,本文對(duì)待分類文本進(jìn)行了二元詞組統(tǒng)計(jì),并基于統(tǒng)計(jì)結(jié)果計(jì)算待分類文本間的相似度,通過相似度閾值篩選得到文檔d的近鄰文本集neighbord,并依據(jù)屬于類別Li的已標(biāo)記近鄰樣本提高該文檔對(duì)于類別Li的權(quán)重:
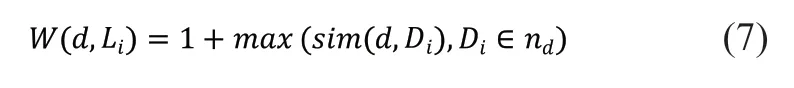
3 SDGs 數(shù)據(jù)分類實(shí)驗(yàn)
3.1 實(shí)驗(yàn)數(shù)據(jù)
本文在聯(lián)合國(guó)官方所提供的SDGs 指標(biāo)元數(shù)據(jù)集[30]上進(jìn)行了類別描述關(guān)鍵詞集的構(gòu)建,并以聯(lián)合國(guó)官方SDGs 數(shù)據(jù)庫(kù)[31]為實(shí)驗(yàn)數(shù)據(jù)集,驗(yàn)證了本文所提框架的有效性。
在數(shù)據(jù)集處理方面,對(duì)于聯(lián)合國(guó)所提供的257個(gè)SDGs 元數(shù)據(jù),我們僅僅保留每個(gè)文檔中的goal、target、indicator,computation method 和definition,concepts 字段,其他諸如Disaggregation、Collection process 等字段被過濾掉。對(duì)2 個(gè)數(shù)據(jù)集我們均采用了傳統(tǒng)的文本預(yù)處理流程來對(duì)這些數(shù)據(jù)集進(jìn)行簡(jiǎn)單預(yù)處理,利用nltk[32]來對(duì)文本進(jìn)行分詞、去掉停用詞、詞形還原并剔除詞向量模型中不包含的詞匯得到我們所使用的數(shù)據(jù)集,其基本信息如表1所示。由于SDGs 數(shù)據(jù)庫(kù)所包含的詞數(shù)較少,不作詞頻的限制,對(duì)于SDGs 指標(biāo)元數(shù)據(jù)集,我們額外篩除了詞頻低于5 的詞,以減少噪音的產(chǎn)生。在實(shí)驗(yàn)類別選擇方面,聯(lián)合國(guó)官方將SDGs 指標(biāo)統(tǒng)分為17 個(gè)可持續(xù)發(fā)展目標(biāo),并在這17 個(gè)一級(jí)目標(biāo)(goal)下逐級(jí)細(xì)分,得到169 個(gè)二級(jí)目標(biāo)(target)乃至257 個(gè)三級(jí)指標(biāo)(indicator)。本文按照17 個(gè)一級(jí)目標(biāo)劃分類別,并在此基礎(chǔ)上進(jìn)行分類實(shí)驗(yàn)。
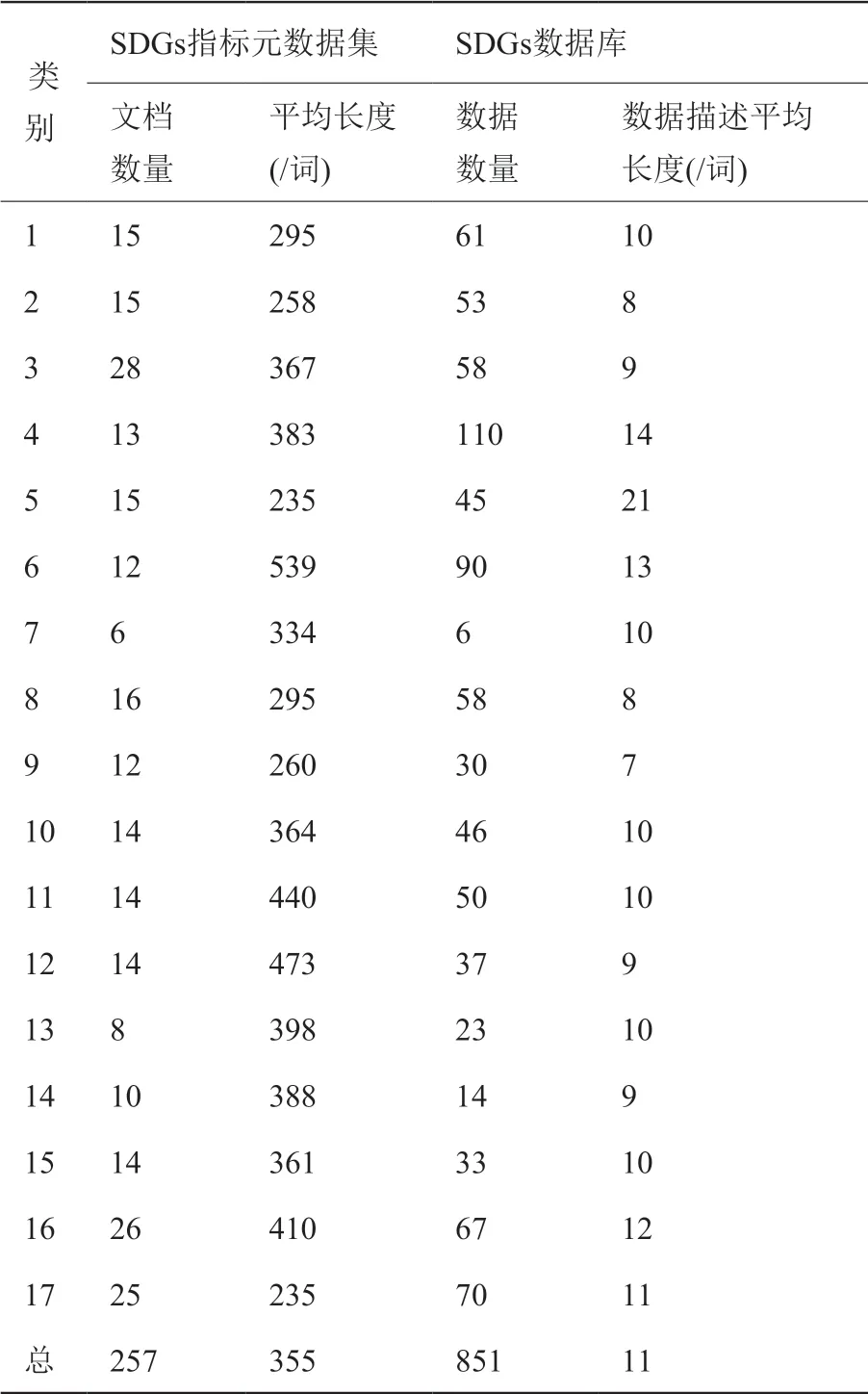
表1 SDGs 數(shù)據(jù)集信息Table 1 Information of SDGs datasets
3.2 實(shí)驗(yàn)相關(guān)參數(shù)
(1)關(guān)鍵詞提取:在textrank 算法中,我們?cè)O(shè)置其阻尼系數(shù)為0.85,窗口大小為5,邊和節(jié)點(diǎn)的權(quán)重都初始化為1。在抽取過程中,首先通過textrank獲取評(píng)分靠前的200 個(gè)候選詞,再篩出相對(duì)詞頻系數(shù)大于2 的少量關(guān)鍵詞作為當(dāng)前類別的描述詞集。
(2)文本分類層:由于數(shù)據(jù)描述通常較短(SDGs數(shù)據(jù)庫(kù)中的數(shù)據(jù)描述平均長(zhǎng)度僅為11 個(gè)單詞),本文將窗口Cn 固定為5。
(3)模型更新層:標(biāo)簽更新的閾值由每輪的更新樣本數(shù)量決定,按照實(shí)驗(yàn)數(shù)據(jù)集的具體規(guī)模,本文在實(shí)驗(yàn)中每輪更新200 個(gè)數(shù)據(jù)的標(biāo)簽;而對(duì)于類別描述詞的更新閾值,本文實(shí)驗(yàn)設(shè)置每輪每類關(guān)鍵詞更新數(shù)量不超過2 個(gè),且其詞頻比需滿足最低閾值0.8;對(duì)于類別描述權(quán)重,實(shí)驗(yàn)將公式(7)中的值設(shè)為0.5,值設(shè)為0.05,k 值設(shè)為1/17;對(duì)于近鄰樣本,規(guī)定相似度大于0.2 的樣本為近鄰樣本。
1)喘證急性加重期;2)排除間質(zhì)性肺病,肺癌等其他需要治療的慢性肺部疾病;合并嚴(yán)重的呼吸、循環(huán)、泌尿、血液、神經(jīng)和內(nèi)分泌系統(tǒng)等疾病、精神患者、惡性腫瘤、傳染病患者;妊娠期或哺乳期婦女;近半年內(nèi)已接受過中藥貼敷治療、刮痧、穴位拔罐的患者;3)貼敷穴位、刮痧部位有皮損或瘢痕體質(zhì)者,及對(duì)藥物或敷料特別敏感的患者;4)研究者認(rèn)為不適合參加本研究者。
3.3 實(shí)驗(yàn)結(jié)果分析
3.3.1 對(duì)比實(shí)驗(yàn)
(1)類別關(guān)鍵詞提取實(shí)驗(yàn)
為了驗(yàn)證我們所使用的關(guān)鍵詞提取算法的有效性,我們將以下兩種常規(guī)的文檔關(guān)鍵詞提取算法在SDGs 元數(shù)據(jù)集的提取結(jié)果也應(yīng)用于數(shù)據(jù)分類中,并根據(jù)最終的分類結(jié)果進(jìn)行對(duì)比。
①TFIDF[4]:首先將同類別的文檔拼接成一整篇類別描述文檔,再利用TFIDF 公式從類別描述文檔集中抽取得到類別關(guān)鍵詞集。
②textrank[8]:與TFIDF 實(shí)驗(yàn)類似,首先將同類別文檔進(jìn)行拼接,再對(duì)不同類別的描述文檔分別構(gòu)建圖網(wǎng)絡(luò),通過textrank 算法提取文檔關(guān)鍵詞,篩除類別重復(fù)詞,得到最終的關(guān)鍵詞集。
(2)數(shù)據(jù)分類實(shí)驗(yàn)
為了驗(yàn)證所提方法在無監(jiān)督文本分類任務(wù)上的有效性,我們選取了以下基準(zhǔn)模型,在textrank+RF方法提取得到的關(guān)鍵詞基礎(chǔ)上進(jìn)行了對(duì)比實(shí)驗(yàn)。
②STM[20]:使用人工設(shè)定的少量類別描述種子詞,利用主題模型對(duì)文本進(jìn)行分類,該方法在長(zhǎng)文本上獲得了很好的效果。
③SeedBTM[21]:使用詞向量擴(kuò)展得到更大的類別描述詞集合,對(duì)文本中的單詞進(jìn)行排列組合得到二元詞組,在這些詞組基礎(chǔ)上構(gòu)建二元主題模型,在短文本上獲得了比STM 更好的效果。
(3)詞向量模型對(duì)比實(shí)驗(yàn)
為了探討不同詞向量模型對(duì)實(shí)驗(yàn)結(jié)果的影響,我們?cè)诔S玫膅love、Bert 預(yù)訓(xùn)練模型所產(chǎn)生的詞向量上進(jìn)行了對(duì)比實(shí)驗(yàn)。
①glove[26]:由于glove 詞向量利用到了統(tǒng)計(jì)信息,難以進(jìn)行增量訓(xùn)練。我們采用了stanford 開源提供的100 維詞向量[33]作為外界語(yǔ)料詞向量,同時(shí)在SDGs 元數(shù)據(jù)集綜合SDGs 待分類數(shù)據(jù)集上進(jìn)行g(shù)love 訓(xùn)練得到的詞向量作為語(yǔ)料向量,并以1:2進(jìn)行加權(quán)組合。
②Bert[27]:本文以google 開源提供的預(yù)訓(xùn)練語(yǔ)言模型[34]作為基礎(chǔ),在SDGs 元數(shù)據(jù)集和待分類數(shù)據(jù)集上進(jìn)行增量訓(xùn)練,以最后一層的輸出作為最終使用的詞向量。
3.3.2 實(shí)驗(yàn)結(jié)果及分析
本文所采用的綜合textrank 和相對(duì)詞頻方法的關(guān)鍵詞提取結(jié)果如表2所示。

表2 SDGs 中g(shù)oal 層面的類別關(guān)鍵詞提取結(jié)果Table 2 Category keyword extraction results at the goal level in SDGs

類別關(guān)鍵詞集14fish,marine,fishery,ocean,sustainable,ph 15specie,wildlife,forest,biodiversity 16right,develop,victim,traffic,chamber 17development,least,worldwide,broadband,statistical,partnership
在將類別描述詞集應(yīng)用于分類算法時(shí),我們發(fā)現(xiàn),一方面類別描述并非越詳細(xì)越好,而應(yīng)該在能夠描述類別的基礎(chǔ)上盡量保證類別之間的差距足夠大,以得到一個(gè)盡量準(zhǔn)確的初始分類界面。當(dāng)類別關(guān)鍵詞集過大時(shí),詞集中往往擁有很多噪聲信息,初始分類界面不夠準(zhǔn)確,導(dǎo)致分類效果不佳;當(dāng)類別關(guān)鍵詞集過小時(shí),類別描述不夠充分,部分文檔無法分類,分類效果也不理想。
如圖2所示,在分類器第一輪迭代上的對(duì)比實(shí)驗(yàn)表明,當(dāng)相對(duì)詞頻篩選閾值不超過某個(gè)值時(shí)(閾值過高會(huì)使得描述詞集過小,只有2-3 個(gè)詞),相對(duì)詞頻分?jǐn)?shù)越低,分類的準(zhǔn)確度也會(huì)隨之降低。因此,我們最終所選相對(duì)詞頻分?jǐn)?shù)的閾值大小為2,以保證最終每個(gè)類別的描述詞集大小在5 左右。
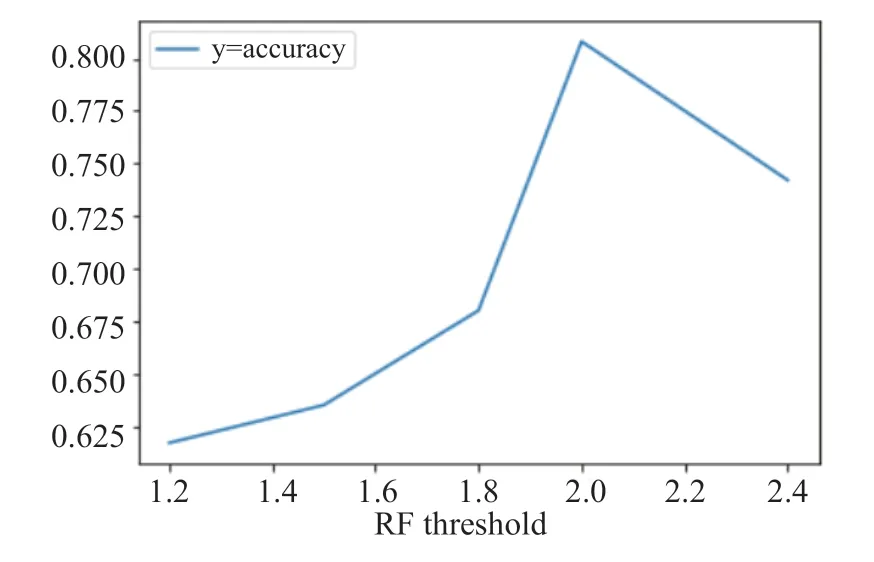
圖2 在不同相對(duì)詞頻閾值下的分類準(zhǔn)確度Fig.2 Classification accuracy of different relative word frequency thresholds
表3 展示了不同方法在SDGs 數(shù)據(jù)庫(kù)上實(shí)驗(yàn)得到的結(jié)果。可以看出,與當(dāng)前主流的基于主題模型的分類方法相比,我們的分類方法取得了更好的效果;而與基礎(chǔ)的TFIDF 等關(guān)鍵詞提取算法相比,我們所使用的關(guān)鍵詞提取方法得到的詞匯更適用于本文模型。
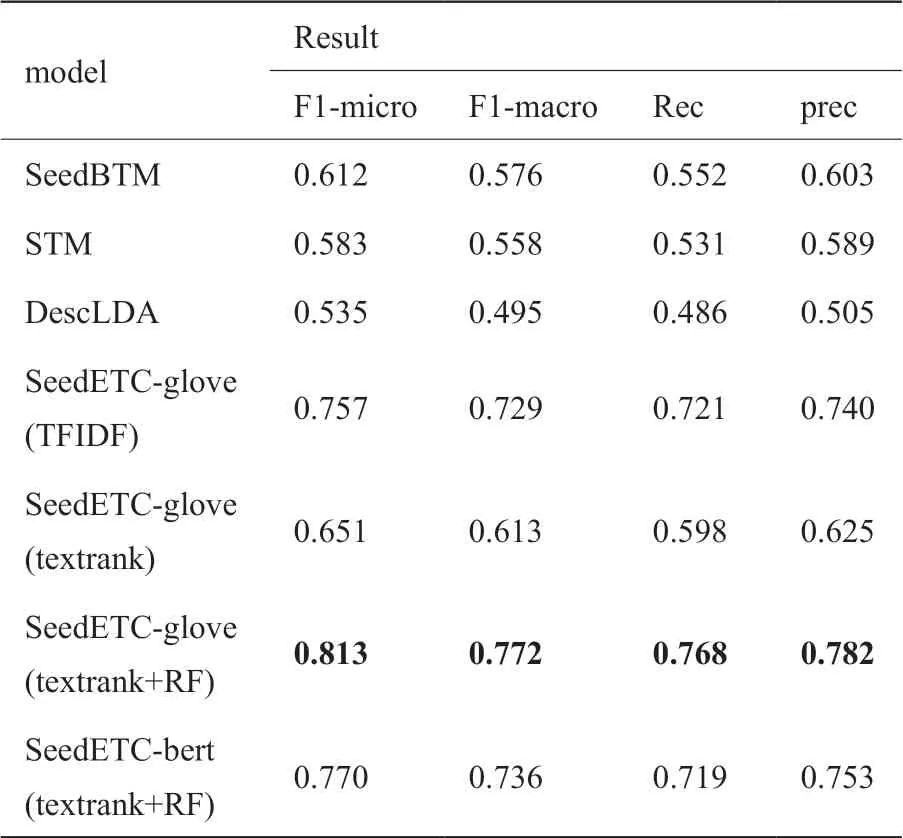
表3 文本分類實(shí)驗(yàn)結(jié)果比較Table 3 Comparison of text classification experiment results
更具體地,我們通過F1-micro 來對(duì)比評(píng)估SeedETC 的分類性能。由圖3 可以看出,我們所提SeedETC 方法對(duì)比SeedBTM 在F1-micro 指標(biāo)上提高了33%,而在不擅長(zhǎng)短文本分類的STM 及DescLDA 上分別提升了39%和 52%。這主要是由于主題模型往往需要足夠大的數(shù)據(jù)集以支撐其基于詞共現(xiàn)統(tǒng)計(jì)的主題分布建模,而SDGs 數(shù)據(jù)集數(shù)據(jù)量較少,難以提供足夠的信息,導(dǎo)致共現(xiàn)矩陣過于稀疏,而我們的方法利用了外界訓(xùn)練得到的詞向量,除了數(shù)據(jù)集內(nèi)部分布外也能捕捉外界信息,因此能夠獲得更好的效果。此外,由實(shí)驗(yàn)結(jié)果可以發(fā)現(xiàn),glove詞向量比經(jīng)過大規(guī)模預(yù)訓(xùn)練的bert 模型所得詞向量效果也要更好,初步推測(cè)這是由于數(shù)據(jù)集過小,bert詞向量受到外界噪聲信息影響較大,難以很好的表征SDGs 相關(guān)語(yǔ)料的分布造成的。Glove 詞向量直接對(duì)外界和SDGs 語(yǔ)料訓(xùn)練得到的詞向量進(jìn)行加權(quán)拼接,更能夠表征SDGs 數(shù)據(jù)集內(nèi)部的詞匯分布。
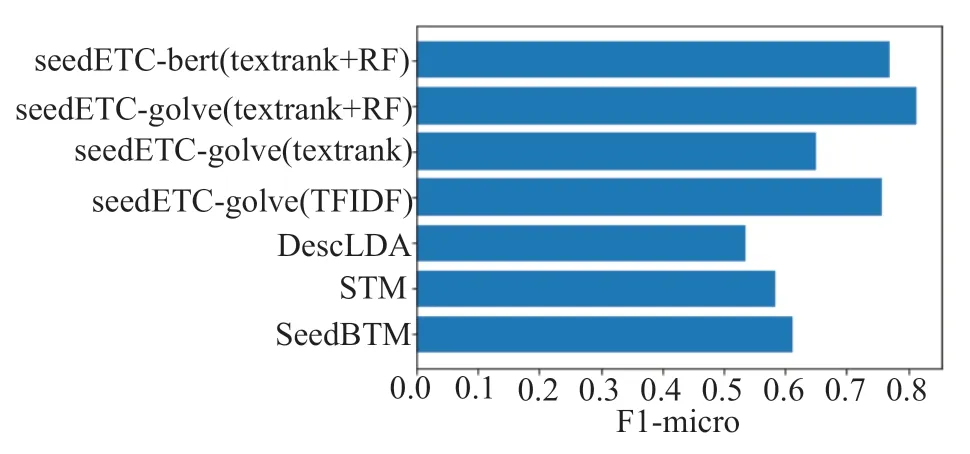
圖3 不同方法實(shí)驗(yàn)得到的F1-micro 分?jǐn)?shù)Fig.3 F1-micro scores obtained from experiments with different methods
而在關(guān)鍵詞提取算法中,相較于常規(guī)TFIDF 及textrank 關(guān)鍵詞提取方法得到的類別描述詞集而言,我們利用textrank+RF得到的關(guān)鍵詞也具有明顯優(yōu)勢(shì)。
由表3 可以看出,textrank+RF 方法所得關(guān)鍵詞在與TFIDF 的對(duì)比實(shí)驗(yàn)中,其F1-micro 指標(biāo)上提升了7%,而在與textrank 的對(duì)比實(shí)驗(yàn)中提升了25%。這主要是由于TFIDF 方法通過逆文檔頻率IDF,與其他類別文檔進(jìn)行了一定的區(qū)分;textrank 方法只考慮了文檔內(nèi)部的高頻詞,缺少與其他類別之間關(guān)鍵詞的區(qū)分;我們的方法主要關(guān)注的就是詞語(yǔ)在不同類別間的相對(duì)詞頻,能夠得到具有極高類別區(qū)分度的單詞作為類別描述詞。這也在一定程度上印證了我們?cè)谇拔闹刑岢龅念悇e描述不一定要足夠詳細(xì)但一定要有足夠的類別區(qū)分度的觀點(diǎn)。
4 結(jié)束語(yǔ)
本文以聯(lián)合國(guó)官網(wǎng)所提供的聯(lián)合國(guó)可持續(xù)發(fā)展目標(biāo)(SDGs)指標(biāo)數(shù)據(jù)集為例,設(shè)計(jì)了一種基于詞向量的無監(jiān)督文本分類方法(SeedETC)進(jìn)行數(shù)據(jù)分類。其中,無監(jiān)督文本分類方法往往需要一些關(guān)鍵詞來提供類別信息,本文又提出了基于textrank 和相對(duì)詞頻的關(guān)鍵詞提取方法,從SDGs 元數(shù)據(jù)描述文檔中提取得到了類別描述關(guān)鍵詞集用于文本分類模型。實(shí)驗(yàn)結(jié)果表明,我們的方法取得了較好的分類效果,取得了0.813 的micro-F1 score,且與其他無監(jiān)督文本分類方法對(duì)比,本文所提SeedETC 算法具有更好的性能。由于本文所使用算法高度依賴于詞向量,當(dāng)詞向量不能夠準(zhǔn)確表征數(shù)據(jù)分布時(shí)分類效果將會(huì)大幅下降,下一步工作中將會(huì)繼續(xù)探討更穩(wěn)定的詞向量改進(jìn)方式,并探索將本文所使用方法應(yīng)用于其他領(lǐng)域。
利益沖突聲明
所有作者聲明不存在利益沖突關(guān)系。
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
意林原創(chuàng)版(2016年10期)2016-11-25 10:28:30
Coco薇(2016年2期)2016-03-22 02:42:52
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
