面向國產加速器的CFD核心算法并行優化
2021-09-17 09:43:26曹義魁陸忠華張鑒劉夏真袁武梁姍
數據與計算發展前沿 2021年4期
曹義魁,陸忠華,張鑒,劉夏真,袁武,梁姍
1.中國科學院計算機網絡信息中心,北京 100190
2.中國科學院大學,北京 100049
引言
計算流體動力學(Computational Fluid Dynamics,CFD)是一門新興的交叉型學科,它結合數學中的離散方法,利用計算機強大的算力對流體力學中復雜的微分方程進行求解,在科研和工程領域都發揮著巨大的作用。目前的CFD 商業軟件、開源CFD軟件等,大多數是基于CPU 開發的。但隨著計算規模的不斷擴大,CPU 的計算、訪存及通信性能已經不能滿足人們的需要[1],所以尋求新的方法實現對大規模數據進行并行處理已經成為國產CFD 軟件發展的必要條件。
CPU+加速器異構架構的出現,為人們解決復雜的大規模計算提供了新的方法,它充分集合了CPU 和加速器的各自優勢特點,將具有并行性的計算密集部分放到加速器上進行加速,極大的提高了程序的運行速度,這也成為了目前高性能計算的主流方法[2]。為了能夠充分利用加速器的性能,需要針對程序中的算法特點設計具有高并行度、高訪存帶寬的并行方法。國內外已有較多將CFD 應用移植到CPU+加速器異構平臺并進行優化的相關研究。
Corrigan 等[3]基于CPU/GPU 異構平臺對流體力學中的格子玻爾茲曼方法實現了并行加速,并采用多種方法實現了簡單高效的數據訪存模式,使全局訪存帶寬利用率達到了86%,相應程序也得到33.6 倍的加速效果。Jespersen[4]設計并實現了基于對稱逐次超松弛方法的CFD 軟件的GPU 并行方案,并對其中的Jacobi 迭代部分進行了并行加速,單GPU 卡相對于單CPU 核心實現了大約3 倍的加速效果。李大力等[5]針對高階精度加權緊致非線性格式的CFD 軟件,實現并優化了Jacobi 解法器的 GPU 并行計算,與單CPU 核心相比運行時間加速了9.8 倍。董廷星等人[6]利用GPU 加速計算流體力學中經典的N-S(Navier-Stokes)方程和歐拉(Euler)方程的求解,并采用3 個測試算例進行實驗,單GPU 卡相對于單CPU 核心最高能得到33.2 倍的加速效果。鄧亮等人[7]基于ADI 解法器的有限體積CFD 應用,設計了兩種GPU并行方案,并討論了若干性能優化方法,使整個CFD 應用得到了17.3 倍的加速效果。V.Emelyanov[8]在GPU 上開發了基于有限體積法的非定常可壓縮的歐拉方程和N-S 方程求解器,并利用精簡計算、訪存優化等方法對GPU 程序進行優化,最終得到20 ~50 倍的加速效果。此外,他們還在GPU上對不同聲速下的翼型外流場進行了數值模擬[9]。Lai 等[10]基于CPU/GPU 異構平臺,利用雷諾數為118 的雙橢球繞流問題驗證了可壓縮NS 方程求解器的計算能力,并從數據傳輸方面對程序進行了優化。隨后,他們又設計了高效的多GPU 并行算法對高超聲速流場進行了研究,當使用4 張GPU 加速卡時,可以獲得147 倍的加速[11]。黨冠麟等[12]基于CPU/GPU 異構系統,利用自主開發的高精度有限差分CFD 求解器,對鈍錐邊界層轉捩問題進行了數值模擬,并對核函數進行了細致的優化,單GPU 卡相對單CPU 核心獲得了60 倍的加速。
以上工作都是在CPU+GPU 的異構系統上完成。為了打破高性能行業的技術封鎖,近年來國家高度重視國產高性能計算機的發展,并取得了突出成就,多次斬獲超級計算TOP500 榜單首名,并且我國在E 級超級計算機系統的研發上也處于世界領先地位。使用國產加速器替代GPU 等加速器已經成為一種必然趨勢[13]。本文利用CPU+國產加速器的異構系統對國產自主CFD 軟件進行加速,國產加速器采用類GPU體系架構,相關資料尚未被授權公開,此處對其架構不展開介紹。國產加速器可以完全兼容運行在GPU上的CUDA 程序,其優化思路也大致和GPU 相同。
1 CFD 軟件介紹
1.1 CFD 軟件計算流程
本文中用于移植的CFD 軟件的初始版本是CCFD V3.0,此軟件全部用Fortran 語言編寫。CCFD系列軟件是國家“863 計劃”“十一五”和“十二五”連續支持的面向大型飛機設計的大規模流場數值模擬軟件[14],也是“863 計劃”中我國集中科研資源重點發展的高性能計算軟件之一[15]。課題組在CCFD V1.0 和V2.0 的基礎上,瞄準國產高性能計算平臺發展V3.0 版本,并在神威-太湖之光等平臺上開展了相關研究。CCFD V3.0 軟件的計算流程主要包括三個階段,如下圖1所示:
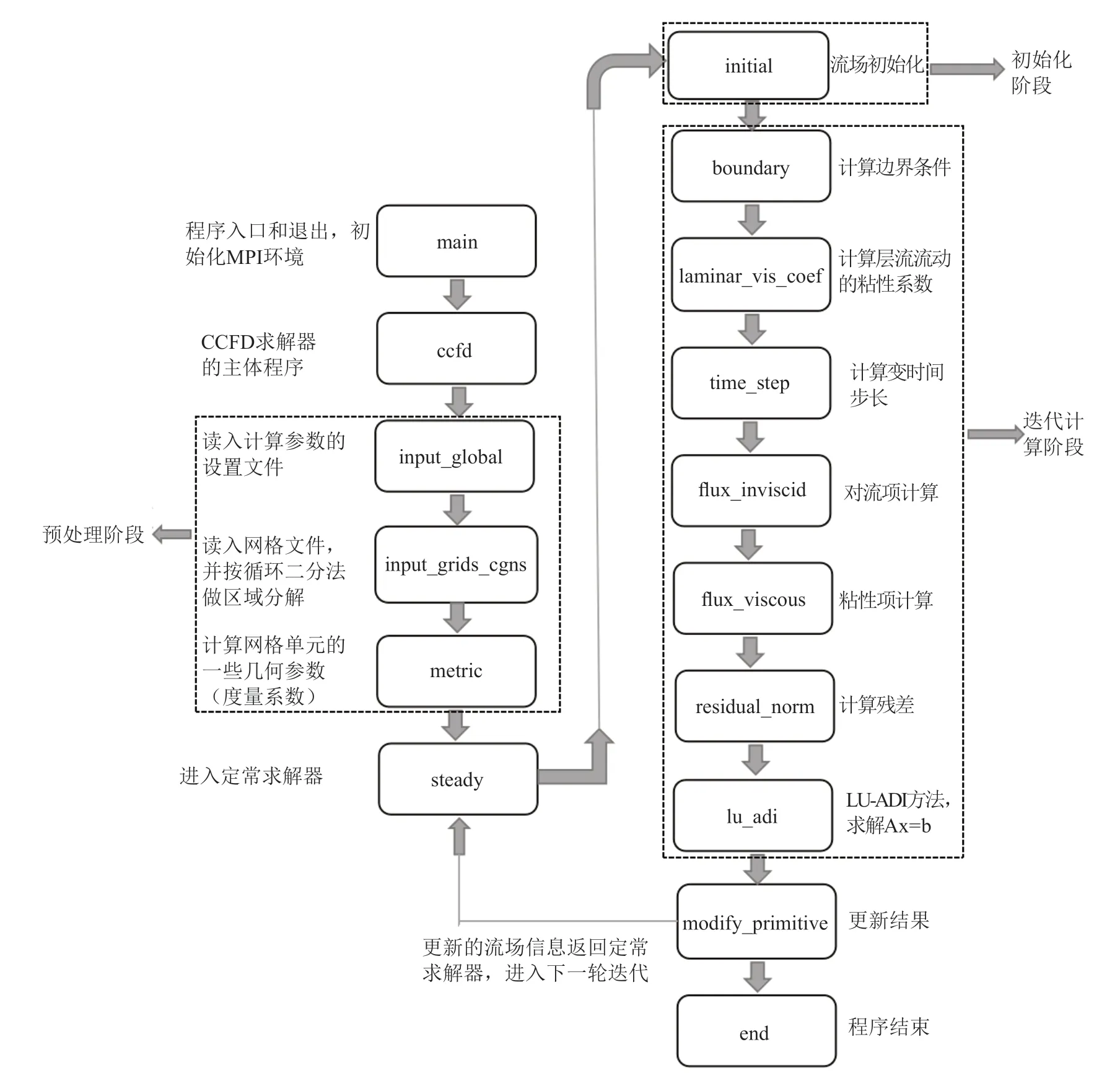
圖1 CCFD V3.0 軟件定常計算流程圖Fig.1 CCFD V3.0 software steady state calculation flow chart
(1)預處理階段。主要進行網格劃分,設置計算參數,進行度量系數的計算。
(2)初始化階段。進行流場信息的初始化,處理初始邊界條件。
(3)迭代計算階段。包括邊界更新、時間推進、對流項的計算、方程求解等模塊。
1.2 CFD 核心算法
根據程序特點,本文對CCFD V3.0 的定常求解器steady 部分做了移植。經過測試發現,flux 函數部分和lu_adi 函數部分約占整個程序運行時間的90%,所以本文主要介紹有關對流項計算的flux 函數部分以及使用LU_ADI 算法求解的lu_adi 函數部分,這兩部分也是整個CFD 求解器的核心部分。
對流項的空間離散方法在CFD 計算中至關重要,它不僅會影響計算的穩定性,對計算結果在精度上也會有很大影響。CCFD V3.0 軟件集成了多種國際上評價較高的上風格式(Roe’s FDS[16]、Van Leer’s FVS[17]、AUSM+[18])和Jameson 中心格式[19]。其中,本文研究是Roe’s FDS 格式,它是基于黎曼解的通量差分分裂格式,是目前使用最廣泛、評價最高的迎風格式之一。
時間推進方法上,工程CFD 軟件普遍采用隱式算法,典型的隱式算法有對角化方法、交替隱式追趕方法(ADI)[20]和LU-SGS[21]方法等。其中,交替方向隱式追趕方法(ADI)對通過系數矩陣在三個方向上作近似因子(AF)分解,并基于LU 分裂將方程求解分為上下三角的兩個子過程,穩定性好且計算效率高,在不要求時間精度的定常計算中應用廣泛。
flux 函數的對流項計算部分是典型的模版計算,lu_adi 函數中的LU_ADI 算法是典型的數據依賴方法,這兩部分是CFD 軟件基礎算法的主要部分。由于推導過程會占據大量篇幅,所以此處不再贅述,本文只在下文相應章節處給出具體的相應代碼,詳細的公式推導及具體算法介紹見參考文獻18。
2 核心算法并行方案
國產加速器架構類似于GPU,都是通過將數據分散到成千上萬個小的計算核心實現并行加速。本文的移植方案先將軟件移植到CPU+GPU 異構系統得到基礎版本,之后再移植到國產加速器上進行優化。
GPU 使用CUDA 編程模型[22],線程按照線程格(Grid)、線程塊(Block)、線程(Thread)的多層次模型進行組織。其中,Block 以三維的形式組織在同一個Grid 內,Thread 以三維的形式組織在同一個Block 內,并分別通過內置變量blockIdx(x,y,z)和threadIdx(x,y,z)進行標識,從而可以對每個線程進行索引。
下面將分別介紹flux 函數和lu_adi 函數兩部分在GPU 上的并行方案。
2.1 flux 函數的GPU 并行方案
對流通量項計算函數(flux 函數)是一個典型的模版計算函數,每個網格數據點的計算都是獨立進行的,僅需要將相應網格點的數據映射到GPU 上的單個線程,可以實現高效的三維并行,具體的映射關系如圖2所示。根據flux 函數的計算流程,將每個方向的計算都拆分成了4 個核函數,分別命名為flux_kernel1-flux_kernel4,拆分的作用是為了實現對內點和邊界點的分別計算以及數據計算的最大并行。
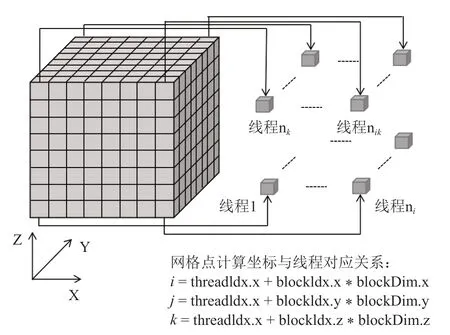
圖2 右端項計算的線程映射Fig.2 Thread mapping of right end item calculation
2.2 lu_adi 函數的GPU 并行方案
在CPU 版本中,lu_adi 函數分別在X、Y、Z三個方向利用LU_ADI 方法求解三維定常可壓縮N-S 方程。該算法最大的特點是在每個計算方向上都存在強數據依賴性,網格中任一內點的更新都需要自身點和同一條網格線上鄰點參與計算,且需要往返各更新一次,具體的計算方式如下圖3所示。
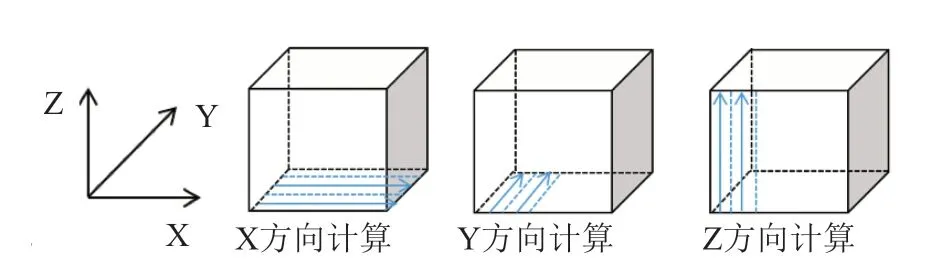
圖3 ADI 迭代計算Fig.3 ADI iterative computation
針對上述ADI 算法特點,對lu_adi 函數中沒有數據依賴的計算部分仍采用三維并行,網格數據與線程的映射和圖3 相同。而對lu_adi 函數中具有強數據依賴性的計算部分,只能在沒有數據依賴的另外兩個方向上實現兩維并行,有數據依賴的方向使用循環串行執行,每個線程負責控制一條網格線上相關點的計算,具體的網格數據與線程的映射關系如圖4所示。本文根據lu_adi 函數特點,將每個方向的計算都拆分成了5 個核函數,分別命名為ADI_kernel1-ADI_kernel5,拆分的目的是為了實現數據計算的最大并行化。
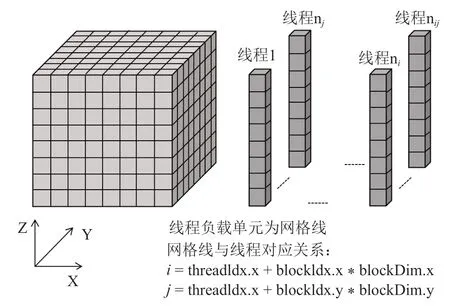
圖4 LU_ADI 迭代計算的線程映射Fig.4 Thread mapping of LU_ ADI iterative calculation
3 基于國產加速器的性能優化策略
利用上述并行方案實現了GPU 的加速版本后,再通過國產加速器自帶的轉碼工具將程序移植到國產加速器,得到了移植后的基礎版本。使用128 立方的三維網格進行測試,單加速卡相對于單CPU 核心,移植前后flux 函數部分的運行時間從2231.21s 降為16.9s,加速了132 倍,lu_adi 函數部分的運行實踐從1641.93s 降到83.1s,加速了19.7 倍。但此基礎版本仍有很大的優化空間,后續本文會基于國產加速器架構特點,充分利用國產加速器上寄存器、共享內存等內存資源,采用核函數合并與分解、訪存合并、調整塊大小等方法對移植后的程序進行優化。
3.1 核函數的分解與合并
在對核函數進行優化時,應充分利用寄存器資源進行計算。但是寄存器資源非常稀少,所以當核函數過大,中間變量過多時,可以采用拆分核函數的方法,減少同一個核函數內寄存器的使用數量,從而增大線程塊并發的數量。當核函數規模較小,中間變量較少,可以將相關核函數進行合并,在保證線程塊具有較高并行性的情況下,充分利用寄存器資源。本課題中對lu_adi 函數進行了相關優化,lu_adi 函數共由五個核函數組成,前兩個核函數ADI_kernel1 和ADI_kernel2 的計算中有大量中間數組的重復使用。針對此特點,可以將這些使用到的中間數組數據用寄存器存儲起來,之后的相關計算也都在寄存器上進行。此外,ADI_kernel2 核函數中的一些計算可以合并到ADI_kernel1 核函數中,并且不會對程序結果產生影響。通過測試發現,將這兩種優化方法結合起來使用,這兩個核函數的總時間從16.54 秒降到10.95 秒,速度提升了33.8%。
3.2 全局訪存的合并與對齊
通常情況下,計算數據都是存儲在加速器的全局內存(Global Memory)上,并且內存帶寬往往是影響程序性能的主要因素。因此,設計較好的訪存模式實現較高的訪存帶寬對程序的優化至關重要。在GPU 上核函數的內存訪問是在物理設備內存和片上內存間以128 字節或32 字節內存事物來實現的,在國產加速器上的訪存機制與GPU 類似。為了最大化帶寬利用率,我們可以對程序的訪存模式進行設計,將設備內存事務的首地址設置為128 字節的偶數倍,并讓同一線程束內連續的線程獲取連續的內存數據,從而實現訪存的合并與對齊,提高核函數的運行速度。在我們的程序中,以ADI_kernel3_i 核函數為例,原程序中對殘差數組三個維度的計算都從第三個點開始,其對數據的訪問是非對齊的。為了實現合并對齊訪問,我們對x 方向的計算仍從第三個點開始,另外兩個方向的計算都從第一個點開始,這樣既不會影響程序的正確性,又可以實現對全局內存的合并對齊訪問。經過這樣的優化后,ADI_kernel3_i 核函數的運行時間從1.86s 降為1.58s,性能提升了15%。
3.3 共享內存的使用
共享內存是國產加速器上的一塊具有固定大小的可編程緩存,與全局內存相比,它具有較低的訪存延遲和較高的內存帶寬。存儲在共享內存上的數據可以被同一個線程塊內的線程共享。國產加速器的一個計算卡上有64kB 的共享內存,當數據是雙精度浮點類型時,一個核函數使用的共享內存數組大小不能超過8192。根據程序特點,使用共享內存存儲全局內存數據,可以減少對Global Memory 不必要的頻繁訪問,提升程序的整體性能。特別是一些具有數據依賴的計算,使用共享內存進行優化是優先選擇。但是使用共享內存時還要注意避免bank 沖突,通常解決bank 沖突的方法是對數據進行內存填充,改變數據到共享內存存儲體的映射。此外,還可以利用共享內存對內存訪問模式進行設計,以便實現訪存的合并。
3.3.1 對lu_adi 函數使用共享內存優化
在本課題中,lu_adi 函數的數據依賴部分主要集中在第四個核函數ADI_kernel4,并且對i 方向數據的訪問是非合并的,具體的計算形式如下所示。

Specific Code:do k = 2 ,kdim do j = 2 ,jdim do i = 3 ,idim res(i,j,k)=(res(i,j,k)- flmp(i,j,k)* res(i-1,j,k))/diag(i,j,k)end do do i = idim-1 ,2 res(i,j,k)= res(i,j,k)- flmn(i,j,k)* res(i+1,j,k)end do end do end do
針對i 方向訪存不連續的問題,本文使用共享內存設計了一種實現合并的內存訪問模式。由于一個核函數的共享內存大小不能超過64kB,所以沿i正向計算時使用三個大小為4*32*17 的共享內存數組,分別存放res、flmp和diag數組,并且控制連續的16 個線程訪問連續的16 個全局內存數據,將其存儲到共享內存數組中,這樣便實現了合并訪存。i方向的每一條網格線分成n 次來計算,n 的大小由網格大小確定。每次循環沿i 方向取16 個數據,并且在進行下次計算之前將需要用到的數據提前存放到共享內存數組中,這也是將共享內存數組的最后一個維度聲明為17 的原因。n 次循環之后,一個線程實際負責了一條網格線上數據點的計算,反向計算原理相同。此外,n 次循環中,每次取數據之后要進行同步,計算之后也要進行同步,否則可能會出現未知錯誤,同步的方法是使用syncthreads()函數,此函數的作用是同步同一線程塊內的線程操作。設計的具體訪存模式如圖5所示。
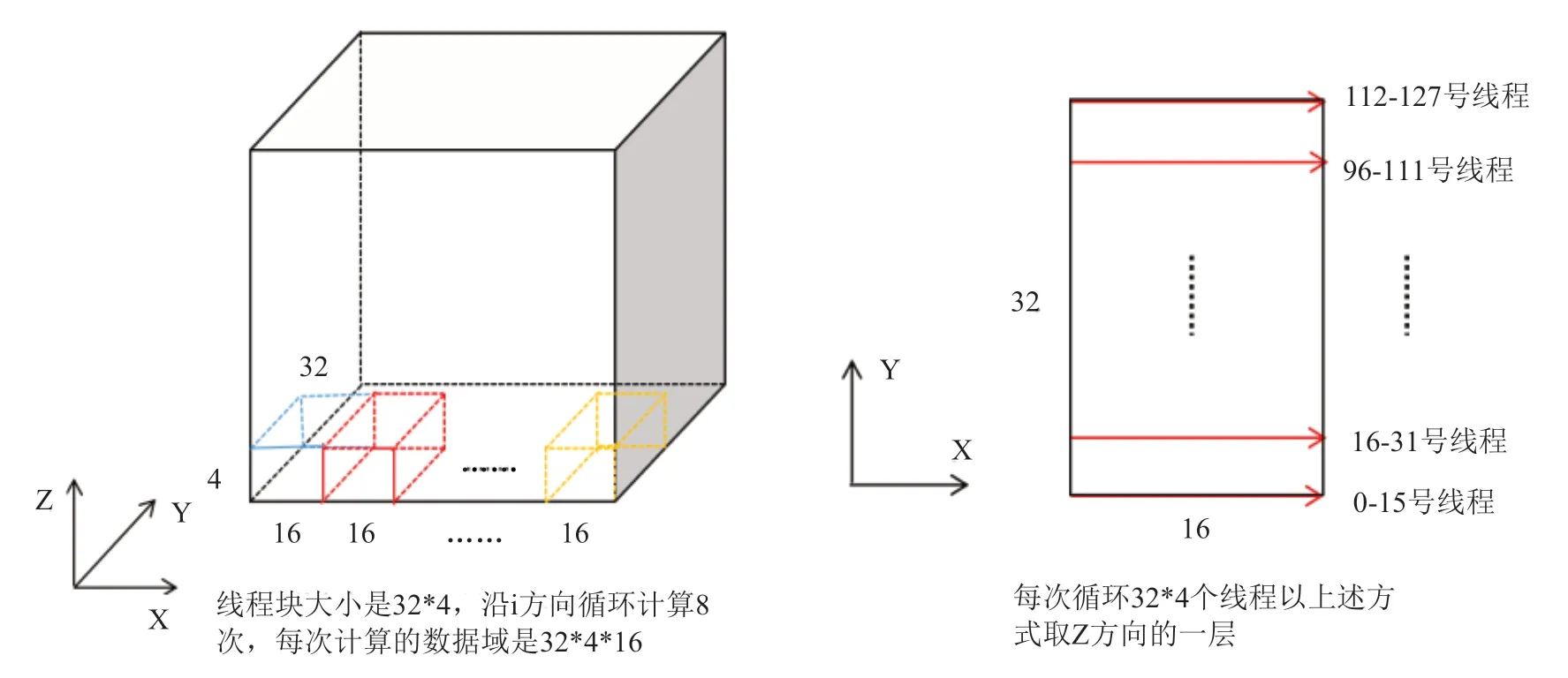
圖5 ADI_kernel4 核函數i 方向訪存模式Fig.5 ADI_ Kernel4 kernel function i-direction memory access mode
而對于j、k 方向數據的訪存本就是合并的,使用共享內存僅僅只能減少對全局內存的訪存次數,而使用寄存器可以達到同樣的效果,并且比共享內存更加方便,所以對j、k 方向使用寄存器進行計算,每次沿相應方向連續更新計算一條網格線上的所有點。使用此方法進行優化后,ADI_kernel4 部分實現了5.4 倍的加速。
3.3.2 對flux 函數使用共享內存優化
flux 函數中的第一個核函數flux_kernel1 的計算需要用到相同數組的相鄰兩點,具體計算形式如下所示。

Specific Code:do k = 2 ,kdim do j = 2 ,jdim do i = 3 ,idim du(i,j,k)= u(i,j,k)- u(i-1,j,k)end do end do end do
并且數據的訪問已經實現了合并與對齊,利用共享內存可以減少對全局內存的訪問次數,從而減少程序的運行時間。具體方案和對ADI_kernel4 的優化思路大致相同,不同之處在于使用的共享內存數組大小為4*8*33,并且沒有循環過程,也沒有數據依賴。使用共享內存進行優化后,flux_kernel1 部分相比原來的版本實現了28%的加速。
3.4 調整線程塊的大小
線程塊大小會影響每個線程所能分配的內核資源,從而影響整個程序的并發性。調整線程塊大小是比較基礎的優化方法,當已經使用了其他優化方法或者找不到更好的優化方法時,對線程塊大小進行調整通常可以取到一定的效果。本課題對lu_adi 函數中有關i 方向計算的兩個比較簡單的核函數ADI_kernel1_i 和ADI_kernel5_i 采用此方法進行優化,并取得了一定的加速效果。具體的線程塊配置如表1所示。
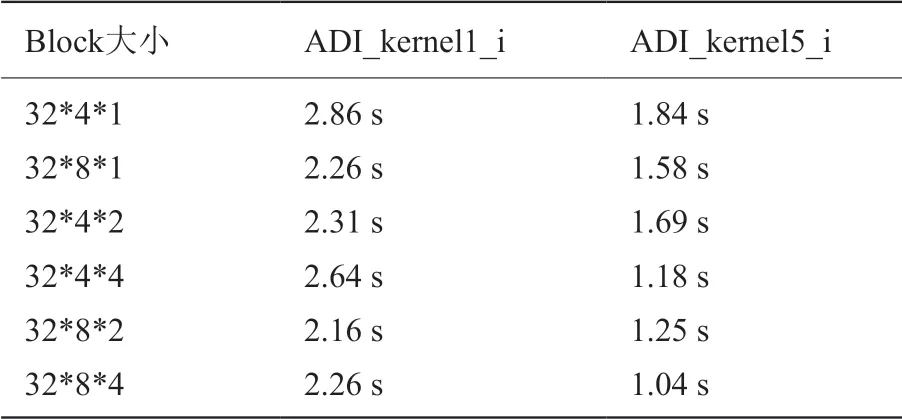
表1 ADI_kernel1_i 和ADI_kernel5_i 在不同線程塊大小下的運行時間Table 1 The running time of ADI_kernel1_i and ADI_kernel5_i under different thread block sizes
從圖中可以看到,相同的線程塊大小配置對于不同的核函數影響是不同的。ADI_kernel1_i 核函數中計算操作較多,用到了較多的寄存器,使用32*8*2 的線程網格大小既可以增大每個線程分配的寄存器的資源,又可以得到最大的并行性,所以其加速效果也最好。而ADI_kernel3_i 核函數中計算較少,主要是讀寫內存操作,使用32*8*4 的線程網格可以保證其最大并行性。所以,對每個核函數應根據自身特點,合理設計線程塊大小,設計相應核函數的最佳線程塊配置,而不應該采用統一的線程網格大小。
4 實驗結果與分析
4.1 實驗平臺
在CPU+國產加速器異構平臺進行測試,系統環境配置:國產x86 處理器(32 核心),內存容量為128GB DDR4,國產加速器具有16GB HBM2 顯存,帶寬1TB/s。本文采用Intel 編譯器編譯Fortran 程序,使用國產加速器自帶的編譯器編譯移植后的程序,并且使用“-O2”優化,最終將編譯后的文件用ifort 命令進行鏈接生成可執行文件。在CPU 上所進行的運算只使用單核,國產加速器上使用單張加速卡進行加速。
4.2 正確性驗證
本文的算例是求解三維方腔流問題,使用了128*128*128 和256*256*128 兩種規模的網格模型進行測試,其中網格的最外面兩層為虛網格點,其作用是用來更新內點,網格數據全部為雙精度,設置定常迭代步數為2000。通過打印輸出原CPU 程序和移植優化后的最終全部流場信息,驗證移植與優化的正確性。兩種測試結果表明,移植前后全部流場信息的絕對誤差的最大值都控制在小數點后15 位,完全滿足工程上的精度要求。
4.3 實驗結果
本文采用兩套不同網格規模進行測試,圖6 和圖7 給出了兩種網格移植前后CCFD V3.0 程序各部分的運行時間對比。通過對測試結果的初步分析,發現128 立方大小的網格和256*256*128 大小的網格的優化效果基本一致。限于篇幅,本文只給出128 立方大小網格詳細的優化結果。表2 是對ADI_kernel1 和ADI_kernel2 采用核函數的合并與分解方法的具體優化效果,表3、表4 分別是對ADI_kernel4、flux_kernel1 核函數使用共享內存方法優化的三個方向優化效果。圖8 和圖9 分別給出了移植的初始版本和綜合使用上述幾種優化方法后,flux 函數和lu_adi 函數各個方向計算的最終時間對比。
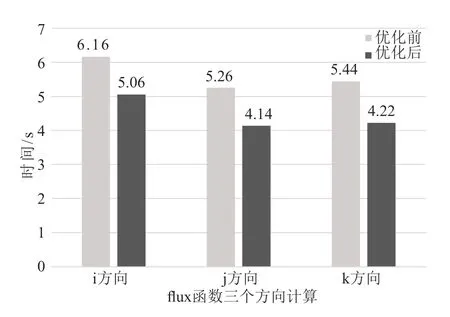
圖8 flux 函數優化前后時間對比Fig.8 Comparison of time before and after optimization of flux function

圖9 lu_adi 函數優化前后時間對比Fig.9 Comparison of time before and after optimization of lu_adi function
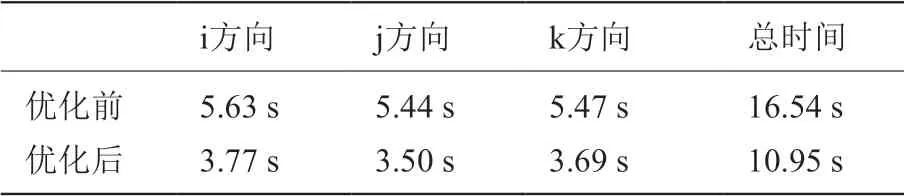
表2 ADI_kernel1 和ADI_kernel2 優化效果Table 2 The optimization effect of ADI_ Kernel1 and ADI_kernel2
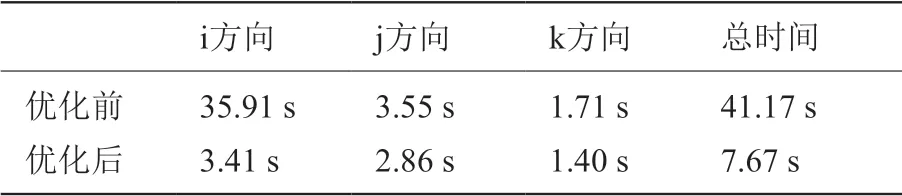
表3 ADI_kernel4 核函數三個方向優化效果Table 3 The optimization effect of ADI_kernel4 kernel function in three directions

表4 flux_kernel1 核函數三個方向優化效果Table 4 The optimization effect of flux_kernel1 kernel function in three directions
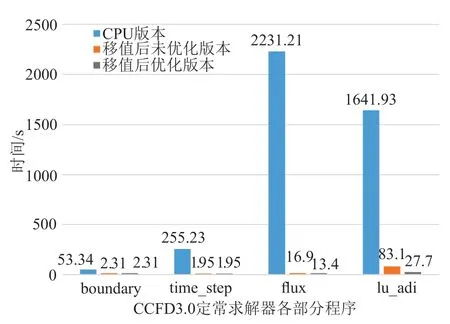
圖6 CCFD V3.0 三個版本程序時間對比,網格規模:128*128*128Fig.6 Time comparison of three versions of CCFD V3.0,grid size:128*128*128
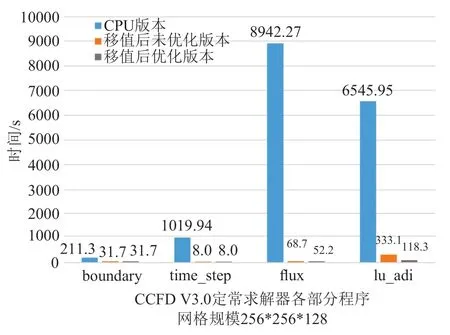
圖7 CCFD V3.0 三個版本程序時間對比,網格規模:256*256*128Fig.7 Time comparison of three versions of CCFD V3.0,grid size:256*256*128
從上述圖表可以看出將移植到國產異構系統可以對程序的性能有明顯的提升,并且采用上述優化方法進行優化后,程序性能會進一步得到提升。其中,對lu_adi 函數i 方向的相關計算在優化后的性能提升最明顯,這是因為i 方向的數據在初步移植后的訪存是非合并的,優化后實現了訪存的合并,性能得到了很好的提升。
5 實驗結果與分析
本文將CCFD V3.0 軟件的定常求解器部分移植到國產異構平臺,并針對CFD 軟件的主要核心算法,對flux 函數部分和lu_adi 函數部分實現了在國產異構平臺上的并行優化。根據異構平臺特點,使用了寄存器、共享內存、對核函數進行合并與分解、實現訪存的合并與對齊、調整線程塊大小等優化方法,對移植后的程序進行優化,最終取得了很好的加速效果,flux 函數部分實現了166 倍的加速,lu_adi 函數部分實現了59 倍的加速,整個CCFD V3.0 程序實現了90 倍的加速(國產加速器上的單個加速卡相對于單個CPU 核心)。
下一步將整個CCFD V3.0 程序移植到CPU+國產加速器的異構平臺,并將上述優化方法應用到軟件的其它模塊中,從而對整個CCFD V3.0 應用程序實現更好的加速效果。
利益沖突聲明
所有作者聲明不存在利益沖突關系。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
人大建設(2019年12期)2019-05-21 02:55:44
中山大學法律評論(2018年1期)2018-03-30 01:21:00
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
中國衛生(2015年3期)2015-11-19 02:53:32
