熱門數字音頻預測技術綜述
2021-09-17 09:43:24張怡寧何洪波王閏強
數據與計算發展前沿 2021年4期
張怡寧,何洪波,王閏強
1.中國科學院計算機網絡信息中心,北京 100190
2.中國科學院大學,北京 100049
引言
數字媒體技術和互聯網的高速發展給傳統媒體帶來技術上的變革,也對其形態、傳播方式、傳播理念等都產生了重要的影響。基于互聯網的數字音頻內容,如在線音樂、移動電臺播客、有聲書等,受眾愈發廣泛。根據艾媒咨詢數據[1]顯示,2019年,全國在線音頻市場用戶規模已達4.9 億人,2020年,中國在線音頻用戶規模約達5.42 億人。而在世界范圍內,據德勤的調研報告[2]統計全球播客(podcast)市場在2020年增長30%,規模達到了11 億美元。種種跡象表明,基于互聯網的數字音頻傳媒形式正在經歷高速發展,并將憑借自身實力成長為一大重要市場。
李明揚[3]定義數字音頻是一種利用數字化手段對聲音進行錄制、存放、編輯、壓縮或播放的技術,它是隨著數字信號處理技術、計算機技術、多媒體技術的發展而形成的一種全新的聲音處理手段。數字音頻的主要應用領域是音樂后期制作和錄音。熱門數字音頻預測技術是指通過選擇和提取具有較強表示性的音頻特征,探索音頻熱門程度或流行程度與這些特征之間的關系,并訓練相應模型來預測新發布的音頻是否會成為熱門音頻(hits)。研究熱門數字音頻預測技術,將一步促進全球在線數字音頻行業的蓬勃發展——對于市場規模已然龐大的音樂行業和發展潛力更為巨大的移動電臺播客領域都將帶來深遠的影響。
近些年,全球已有不少學者對熱門音頻預測技術進行了探索,并在熱門音樂預測、熱門播客預測領域取得了可觀的成果。本文將從熱門指標定義、音頻特征選取、預測模型算法三方面綜述學術界在熱門數字音頻預測領域的相關研究成果,并對熱門數字音頻預測技術未來的發展趨勢和研究方向進行展望。
1 熱門指標定義
熱門數字音頻預測問題在大多數情況下都會被看作一個二分類問題,即通過音頻特征預測音頻屬于熱門/非熱門音頻。而對于“熱門”與否,學者們大多通過音頻排名、播放量或下載量等客觀數據劃定閾值進行指標的衡量。
在對于熱門音樂預測的研究中,大部分學者根據音樂排行榜上的音樂排名對熱門音樂和非熱門音樂進行區分,但在熱門指標衡量的嚴格程度上又可能有所不同。在一些文獻[4-6]中,作者定義熱門音樂為登上過美國公告牌(Billboard)年度歌曲排行榜前100 名的音樂,非熱門音樂為從未進入排行榜前100名的音樂。在另一些學者的研究中[7-11]中,進入相應歌曲排行榜前5、前10 或前20 名的音樂被看作熱門音樂。而Dhanaraj 等人[12]只將排行榜排名第一的音樂看作熱門音樂。也有學者認為由于時間變量的影響,單純的排行榜數據無法客觀反映一首歌的熱門程度,因此Lee 等人[13]基于音樂排行榜的排名自主定義了一首歌曲的多個流行度指標,以量化一首音樂的綜合熱度。
部分學者通過音樂播放量(play counts)對熱門音樂進行定義[14-16],通過設定較高的播放量閾值對熱門音樂進行劃分。還有少部分學者直接使用第三方API(Application Programming Interface,應用程序編程接口)定義的熱度指標對熱門音樂作出區分,如Pham 等人[17]使用the Echo Nest(原音樂網站應用數據平臺,現已被Spotify 收購并更名為Spotify Web API[18])定義的“hotttnesss”指標作為預測的熱門指標。
在熱門播客預測領域,研究成果尚不如熱門音樂預測領域豐富,基本上所有學者都是通過播客在相關平臺上的排名數據對熱門播客與非熱門播客進行區分[19-21]。
2 特征選取
音頻特征選擇與提取是熱門數字音頻預測研究中的重要環節,選取與熱門程度相關性更強的特征往往會取得更好的預測效果。熱門數字音頻預測的特征可以分為兩個主要類別:內部特征和外部特征[15,22]。內部特征指音頻及其本身相關內容的特征,外部特征通常包括與音頻有關的社交媒體事件、聽眾心理或社會影響等內容。由于外部特征更多的涉及社會科學方向,因此熱門數字音頻預測技術領域的研究通常都選取可以量化表示的內部特征進行建模。只有Bischoff等人[23]僅依靠外部特征,通過從音樂社交網絡挖掘的數據以及歌曲、藝術家和專輯之間的關系,使用機器學習的方法預測了歌曲成為熱門歌曲的潛力。本文主要對學者們在該預測領域所選取的內部特征進行總結和分析,主要可歸納為以下四個類別。表1 總結了常用的四種特征示例及其解釋。

表1 常見的四種特征示例及其解釋Table1 Examples and explanations of the four common features
在大多數熱門數字音頻預測的實驗研究中,學者們更多的選取音頻淺層特征和音頻深層特征作為輸入變量建立預測模型。單獨選取文本特征進行預測也會取得可觀的預測效果[4]。值得注意的是,在他們的實驗中,選取多種特征類型共同預測的效果往往最好,如Yang 等人[15]使用音頻淺層特征和元數據標簽特征的深度學習融合模型在所有實驗中取得了最好的預測效果,遠遠超過使用單一類型特征的預測結果。
2.1 音頻淺層特征
音頻淺層特征是指基于音頻信號本身的易于提取的特征,主要包括基于頻譜圖的MFCC(Mel Frequency Cepstral Coefficient,梅爾頻率倒譜系數)[12,15-16,24],通過the Echo Nest 或Spotify Web API獲取的簡單音樂特征如節奏、拍子記號、調式、音調等[5-11,14,17,25],基本音頻屬性如音頻片段的時長、響度等[6,14,25]。
2.2 音頻深層特征
與音頻淺層特征相對應的是音頻深層特征,手工特征(hand-craft features)也屬于深層特征。音頻深層特征由音頻淺層特征經過更為復雜的計算或人工標注而來,Porter 等人[26]認為音頻深層特征可以捕捉更為抽象的概念,如情緒類別等。The Echo Nest 或Spotify Web API 獲取的深層音頻特征包括音樂的可舞蹈性(Danceability)、能量(Energy)、口語性(Speechness)、現場性(Liveness)等。
在一些研究中,學者們還經常使用自定義的深層特征進行熱門數字音頻的預測。如Lee 等人[24]利用音樂和聲、節奏、音色以及響度等特征隨時間的變化情況計算得出的音樂復雜度(Complexity)特征,Yang 等人[20]通過對播客的音頻特征利用基于逆向學習的建模方法提出的播客表示方法ALPR(Adversarial Learning-based Podcast Representation,基于對抗學習的播客表示),以及Tsagkias 等人[27]提出的播客分析框架PodCred 中的大部分特征也屬于音頻的深層特征。
2.3 文本特征
數字音頻的文本特征主要包括音樂的歌詞以及播客的口播文本內容。Dhanaraj 和Logan[12]利用潛在語義分析的方法將每首歌的歌詞轉換為特征向量,Singhi 等[4]使用Rhyme Analyser[28]和CMU Pronunciation Dictionary[29]提取歌詞的韻律和音節特征,對熱門歌曲進行預測。Joshi 等[21]基于詞法分析采用了一種三元組訓練方法,學習了基于文本的播客特征表示,并將其應用于熱門播客的預測任務。
2.4 元數據特征
元數據特征(meta information)是關于數據的結構化數據,描述數字音頻的元數據也被作為熱門音頻預測的特征選擇。Pham 等[17]使用詞袋的方法對歌曲名稱、藝術家id 和藝術家經常關聯的術語(類型)等元數據特征進行表示,并取得了比深淺層音頻特征更好的熱門音樂預測效果。Yang 和Yu 等人[15-16]利用JYnet 模型[30]生成的音樂標簽,作為卷積神經網絡進行熱門音樂預測的特征輸入之一,提高了預測準確率。Tsagkias 等[19]使用PodCred 框架[27]中基于播客元數據的相關特征完成了對iTunes 上的熱門播客的排名預測。Zangerle 等[6]使用音頻的發布時間元數據作為熱門音頻預測的特征輸入之一并取得了良好的預測效果。
3 預測模型算法
3.1 預測算法性能評價指標
大多數情況下的熱門數字音頻預測問題是一個二分類問題,因此樣本有正負兩個類別,即熱門/非熱門音頻。那么模型預測的結果和真實標簽的組合就有4 種:TP(True Positive),FP(False Positive),FN(False Negative),TN(True Negative),如表二所示。這4 個分別表示:實際為熱門音頻預測結果為熱門音頻,實際為非熱門音頻預測為熱門音頻,實際為熱門音頻預測為非熱門音頻,實際為非熱門音頻預測為非熱門音頻。

表2 熱門音頻二分類預測模型結果組合Table2 Results of the two-class popular audio prediction model
在使用模型對熱門數字音頻進行二分類預測時,傳統的模型評價指標包括:(1)準確率(Accuracy)、(2)精確率(Precision)、(3)召回率(Recall)、(4)F1 值(F1 Score)。由于許多機器學習的模型對分類問題的預測結果都是概率,而以上四種評價指標的結果依賴于模型中的閾值設定的合理性,所以也有部分學者采用AUC 指標(Area Under Curve,曲線下面積)衡量模型效果。同時,在測試集中的正負樣本的分布變化的時候,曲線能夠保持不變。由于在實際的數據集中經常會出現類不平衡(class imbalance)現象,即可用來實驗的熱門音頻的數量總是遠遠少于非熱門音頻,使用AUC 指標能夠很好的描述模型整體性能的高低。各個評價指標的解釋以及意義如表3所示。

表3 熱門音頻預測模型常用評價指標Table3 Commonly used evaluation indicators of the popular audio prediction models
除了將熱門數字音頻預測看作一個二分類問題外,還有研究者對熱門音頻在排行榜上的排名進行預測,衡量其模型性能的評價指標包括描述預測值誤差的均方根誤差RMSE(Root Mean Square Error)和平均絕對誤差MAE(Mean Absolute Error)[6],以及描述真實排名與預測排名相關性的歸一化折損累計增益NDCG(Normalized Discounted Cumulative Gain),Kendall 相關系數以及Spearman 相關系數等[20,31]。
3.2 基于機器學習的預測算法
機器學習是一個快速發展的領域,它能解決許多傳統方法所無法有效解決的復雜問題[32]。基于不同機器學習方法的預測算法被應用于熱門數字音頻預測領域的研究,其中支持向量機法與邏輯回歸法因其較好的預測效果應用最為廣泛。
3.2.1 支持向量機
使用支持向量機對熱門音頻進行預測,雖然不是在該研究領域被被最廣泛應用的機器學習方法,但是被學者最早應用到該領域的算法。支持向量機的原理是試圖從最近的數據點找到一個邊界盡可能大的分離超平面,實現簡單,因而會最早被學者用來做熱門音樂領域的探索。
早在2005年,Dhanaraj 和Logan[12]首次使用基于聲學和歌詞的特征來構建支持向量機,并使用增強分類器來區分不同風格的歌曲中排名前1 的歌曲。盡管只有91 首歌曲的原聲和歌詞數據,他們的結果很樂觀,并認為熱門音樂可以預測。在2011年,Borg 和Hokkanen[14]使用the Echo Nest 的音頻數據特征構建了支持向量機模型預測熱門音樂,但獲得的結果卻非常有限:無論選取任何特征以及設定任何參數,他們的預測精確率都從未超過樣本偏差1%。因此他們認為,一首歌曲是否能成為熱門歌曲很可能是由社會力量驅動的。2013年,Fan 和Casey[8]對英文熱門歌曲和中文熱門歌曲進行了預測和比較研究。英文的歌曲數據是從英國專輯排行榜收集的,中文歌曲數據從中國歌曲排行榜收集而來。同樣從the Echo Nest 獲得音樂音頻特征,他們使用了時間加權的線性回歸和支持向量機算法進行熱門音樂預測。當將熱門歌曲定義為出現在前40 位排行榜前5 名中的歌曲、將非熱門歌曲定義為同一列表中的最后5 首時,使用支持向量機方法預測中文歌曲的錯誤率約為29%,而英文歌曲的預測錯誤率約為44%,其預測效果好于線性回歸模型。其研究結果還表明,中文流行歌曲預測比英文流行歌曲預測結果更準確。斯坦福大學Pham[17]等人于2016年進行的另一項最新研究評估了不同的機器學習算法預測熱門音樂的能力。他們使用了支持向量機、邏輯回歸、線性判別分析、二次判別分析和多層感知器等方法,其所選取的特征包括音頻深淺層特征以及元數據特征。在他們的研究中,所有模型獲得了大致相似的預測準確率,取值范圍為0.75 至0.80,其中支持向量機模型的綜合預測效果最佳。2018年,Lee 等人[24]使用描述音樂復雜性的音頻深層特征以及其他傳統聲學淺層特征建立了支持向量機、邏輯回歸、決策樹和神經網絡模型對熱門音樂進行預測。其結果表明,雖然仍有改進的空間,但基于歌曲的音頻信號預測歌曲的熱門指標是可行的,預測結果明顯優于隨機概率,特別是同時使用歌曲的復雜性特征和MFCC 特征,其中預測準確率最高的也是支持向量機模型。
使用支持向量機對熱門歌曲進行預測有如下優勢:首先,它們不需要任何復雜的參數調優。其次,在一個小的訓練語料庫中,他們表現出很強的概括能力。最后,它們特別適用于高維空間的學習。但當訓練樣本過大時,則不能使用支持向量機對熱門音樂進行預測,因為它使用二次規劃法來求解支持向量,而求解二次規劃將涉及N 階矩陣的計算(N為樣本的個數),當N 數目很大時,該矩陣的存儲和計算將耗費大量的機器內存和運算時間。由于其模型的預測效果極度依賴小型訓練數據的質量,因此使用支持向量機預測熱門歌曲的效果也會隨著特征選取的成功與否表現出不同的預測成功率。
3.2.2 邏輯回歸
邏輯回歸是一種數學模型,可用于描述一個或多個自變量和一個因變量之間的關系[33]。因此,該模型可用于像熱門音頻預測這樣的二分類問題。當將訓練好的邏輯回歸模型應用到測試數據的特征時,會輸出是否為熱門音頻的置信概率,這個概率是0到1 之間的一個數字。邏輯回歸通常使用0.5 作為分類閾值。對于熱門音頻預測,邏輯回歸法是可以優化精度的理想方法,因為可以通過提高熱門音頻的分類閾值,從而在熱門音頻的定義上形成一個“更嚴格的”標準。并可以通過加入正則化系數λ,迭代減小過擬合。
2014年,Herremans 等人[9]對熱門舞曲的預測進行了研究。他們創建了從2009年到2013年的熱門舞曲數據集,并在其中使用了決策樹、樸素貝葉斯、邏輯回歸和支持向量機等機器學習算法進行預測模型的訓練。他們的研究結果表明,通過分析音頻特征來預測舞曲的流行程度是可行的,其中預測效果最好的算法是邏輯回歸,AUC 為0.65,準確率為83%。同年,Wang[10]從MIDI 音樂文件中提取樂器、旋律和節拍特征對熱門音樂進行預測,并取得了令人驚訝的好結果。他們使用n 元語言模型將原始音頻淺層特征轉換為詞-文檔頻率矩陣(word-document frequency matrices),將邏輯回歸作為分類器,并使用概率系數來優化精度。 同時使用樂器、旋律和節拍等特征進行預測,其預測準確率峰值為0.882,對應召回率為0.279。Herremans 和Bergmans[11]在實驗中既使用音頻特征和元數據特征,又使用了一種基于社交媒體傾聽行為的新特征,建立了邏輯回歸和支持向量機等機器學習模型對熱門音樂進行預測。其結果表明,基于早期聽眾行為分析特征的邏輯回歸模型在預測排名前20 的熱門舞曲時表現最好,能夠達到0.79 的AUC 值。2019年,Yang 等人[20]對播客的非文本特征進行建模,提出了一種基于逆向學習的播客表示方法ALPR。其評價結果表明,同樣使用邏輯回歸的預測方法,相比于僅基于文本特征或先前研究中的音頻特征表示,ALPR 特征帶來了顯著的性能提升。同年,Georgieva 等人[5]將美國熱門歌曲排行榜Billboard年度排名前100 名的歌曲看作熱門歌曲,并整理了大約4000 首熱門和非熱門歌曲的數據集,從Spotify Web API 中提取了每首歌曲的音頻深淺層特征對熱門歌曲進行預測。通過五種機器學習算法,他們在驗證集上以大約75%的準確率預測了一首歌曲是否可以成為熱門歌曲。其中最成功的算法是邏輯回歸模型和帶有一個隱含層的神經網絡方法。
邏輯回歸是一種被人們廣泛使用的算法,使用邏輯回歸對熱門音頻進行預測的優勢除了上文提到的分類標準的嚴格程度可通過設置不同閾值而自由調節外,還具有高效、不需要太大計算量和縮放輸入特征、通俗易懂并且可以輸出校準好的預測概率等優勢。但它最大的劣勢就是不能用來解決非線性問題,因為它的決策面是線性的。當去掉與輸出變量無關的特征以及相似度較高的特征時,邏輯回歸效果確實會更好。因此在熱門音頻預測中,特征工程質量的好壞亦在該算法的性能方面起著重要的作用。
3.2.3 其他機器學習方法
除了應用較為廣泛并取得了較好的預測效果的支持向量機和邏輯回歸法外,貝葉斯網絡、移動感知器、隨機森林和XG-Boost 方法也曾被應用于熱門數字音頻的預測。
2009年,Singhi 和Brown[4]使用歌曲的歌詞信息進行了熱門歌曲預測的探索。他們使用31 種韻律和音節特征開發了一個熱門音樂檢測模型,對在2008年至2013年間進入Billboard年終熱門100 首單曲的歌曲進行訓練。他們使用492 首熱門歌曲和6 323 首非熱門歌曲訓練了貝葉斯網絡,得到了0.451的召回率和0.214 的預測準確率,結果優于隨機結果。在他們的實驗中,隨著歌詞長度的增加,預測效果也會隨之提高。同年,Tsagkias等人[19]通過實驗證明,根據對比分析iTunes 上流行和非流行播客的指標特征,并使用PodCred 評估模型[27]中的一組基于人工分析的淺層特征指標可以用來預測播客的聽眾偏好。這些特征更多的涉及元數據的完整性、一致性以及播客的完成質量等相關特性。他們成功在iTunes 上的一組播客數據上進行了熱門播客預測實驗。使用多種機器學習方法,他們能夠將iTunes 上流行的播客與不流行的播客分類,并對播客進行排名,使iTunes 上最流行的播客名列前茅。其中預測熱門播客效果最好的是隨機森林法,通過使用所有維度的所有特征,可以取得0.83 的F1 值。2019年,Joshi等人[21]研究了播客的文本內容特征,以探索在不同的熱門播客和非熱門播客中,文本線索的輔助作用。盡管一些文本內容的極性和主觀性非常相似,但它們所包含的詞匯線索卻存在顯著差異。因此,他們采用了一種基于三元組的訓練方法,學習一個基于文本的播客表示,然后使用XG-Boost 算法用于熱門播客預測任務。其最佳模型的F1 值為0.82,比對照組的最佳水平提高了12.3%。
不同的機器學習算法可能會在不同的數據集上產生不同的預測效果,但可以肯定的是,在避免過擬合的情況下,選取恰當而更具表示性的特征輸入都會有助于提高各自算法的預測性能。
3.3 基于深度學習的預測算法
深度學習是人工智能的重要研究方向,也是人工智能技術發展迅速的領域之一,幫助計算機理解大量圖像、聲音和文本形式的數據。[34]人工神經網絡,通常稱為神經網絡,是一種基于實際生物神經元功能的計算模型。它是一種非線性的統計工具,在模式識別領域廣泛應用,同時也是深度學習的核心方法。神經網絡是一種自適應系統,它根據訓練數據在學習階段自動進行參數的調整。
第一次使用神經網絡對熱門音頻進行預測的是Monterola 等人[25],他們在從2004年至2006年發行的380 首菲律賓語原創音樂(OPM,Original Pilipino Music)歌曲(其中有190 首熱門歌曲)中提取了56個單值音樂特征(如音高和速度),并定義了一個評價標準來衡量每一個特征的表示能力,將排名最高的20 個音樂特征輸入神經網絡,使用梯度下降反向傳播方法進行訓練,最后得到了81%的平均預測準確率,比使用此相同的數據集和特征建立的其他機器學習方法高出了約20%的預測準確率。其實驗結果顯示了使用神經網絡方法對熱門音樂進行預測的樂觀前景與可觀優勢,并在之后深度學習的發展歷程中得到了許多學者的實驗佐證。
隨著深度學習領域如火如荼的發展,對于熱門音頻預測領域的研究,學者們紛紛開始使用卷積神經網絡方法進行模型的建立。不同的是模型的結構有所不同,但都取得了較好的預測效果。同時,深層結構和多種類特征輸入的模型預測效果往往優于淺層結構和單一特征輸入模型的預測效果。
2017年,Yang 等人[15]將熱門歌曲預測問題表示為一個回歸問題,并以原始的MFCC 特征作為特征輸入,訓練了一個簡單卷積神經網絡模型、一個更高級的JYnet 模型[30]和這兩種模型的融合模型。其實驗表明,在預測中文歌曲或西方歌曲在中國臺灣地區的熱門程度時,深層結構模型的預測效果比淺層結構模型更準確。對西方歌曲的預測更依賴于模型的深層結構,他們認為簡單的淺層模型可能無法捕捉西方流行歌曲中豐富的聲學特征和流派多樣性。
同年,Yu 等人[16]擴展了上述研究成果。他們建立了Siamese-CNN 模型,以歌曲對為輸入,然后聯合優化兩首歌曲在預測熱門歌曲得分時的平均平方誤差和判斷兩首歌曲得分高低的成對排名損失。使用普通的卷積神經網絡模型通常將熱門音頻預測作為一個回歸問題,而Siamese-CNN 模型可以同時學習音頻的流行性分數和相對排名。作者根據KKBOX 提供的商業數據對歌曲的每日播放次數進行評估,證實了Siamese-CNN 模型結構在區分熱門歌曲和非熱門歌曲方面比其他基本算法更有效。
2019年,Zangerle 等人[6]采用了一個寬而深的神經網絡模型,聯合利用音頻淺層特征、音頻深層特征以及元數據特征(音頻發行年份)預測美國Billboard 歌曲排行榜中年度前100 名的熱門音樂,使用多種類特征的聯合訓練模型效果顯著高于使用單一種類特征的預測模型,最高可達75.04%的準確率。
使用深度學習的方法對熱門數字音頻進行預測具有如下優勢:他們在實踐中往往表現出比普通機器學習更好的預測精準度,同時可以學習訓練數據中非常復雜的底層特征,因為網絡隱藏層的存在減少了對特征工程的需求。此外深度學習法特別適用于大型數據集和高維度數據集。但其劣勢也相應表現在訓練速度較慢、需要消耗巨大的計算資源以及對于較為少量的訓練數據不能學習到效果較好的預測參數等方面。
3.4 預測算法小結
對上述熱門音頻預測算法進行性能分析總結,如表四所示。我們從預測類型、特征選擇、方法復雜度、預測效果及方法優劣等幾個角度進行了總結。
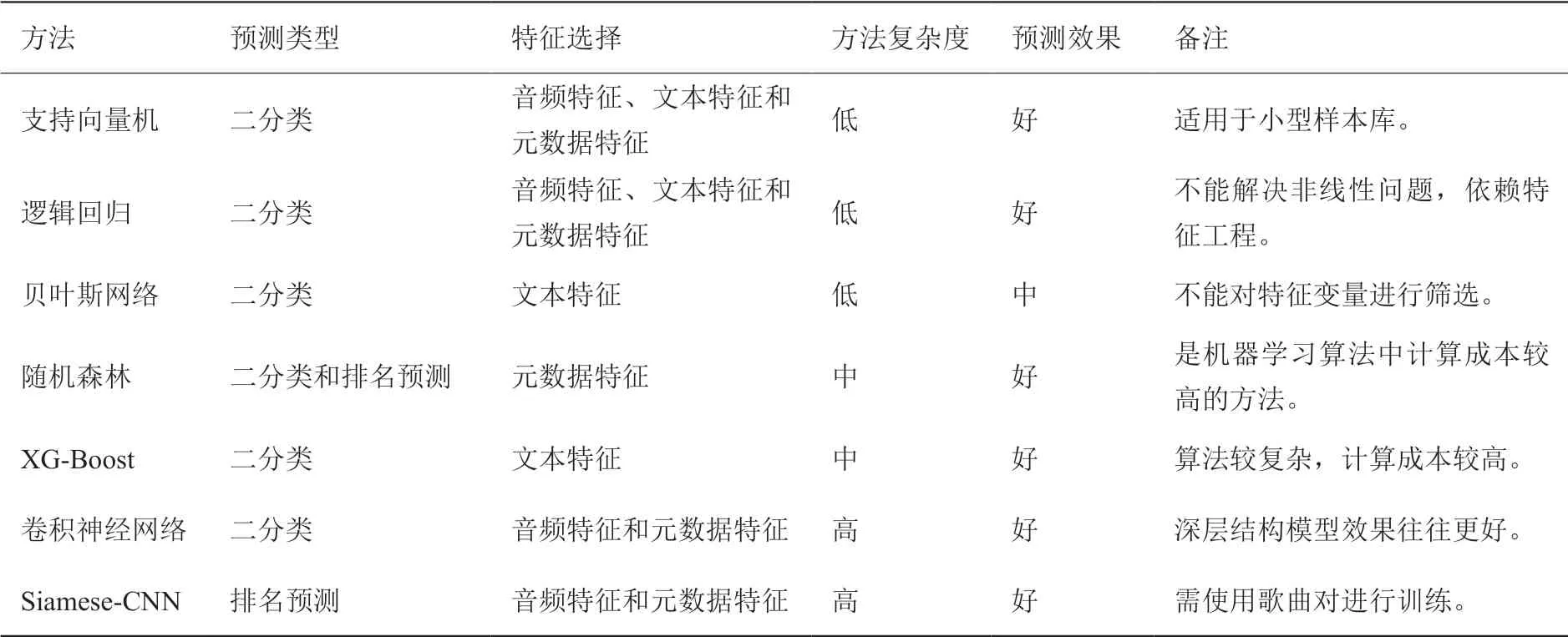
表4 熱門音頻預測算法性能分析Table4 Performance analysis of popular audio prediction algorithms
4 總結與展望
如上文所述,熱門音頻預測領域自發展以來,大多數研究學者在熱門音樂或熱門播客預測領域都取得了較為樂觀的實驗結果。通過建立不同的預測模型,選取不同的特征數據,從而取得了各不相同的預測效果,其中使用深度學習方法的預測效果最令人滿意。但熱門數字音頻預測領域的研究并不是一帆風順的,Salganik 等人[35]曾在2006年提出過文化市場不可預測性的主張,Pachet 和Roy[36]在2008年通過不成功的熱門音樂預測實驗檢驗了這一主張在音樂市場上的有效性,Borg 和Hokkanen[14]以及Reiman 和?rnell[37]同樣認為,一首歌曲是否能成為熱門歌曲很可能是由社會力量驅動的,而音頻本身的內部特征不足以支撐成功的熱門音頻預測實驗。
對于這些質疑,筆者認為其實驗失敗的原因可能在于直接使用了第三方API 獲得特征進行訓練,在實驗中缺少了選取關鍵或者是有效特征的過程。此外,對音樂數據集“熱門”這一指標的不同定義方法也會在一定程度上影響預測效果。同時,訓練模型的維數災難和過擬合現象可能也是導致預測失敗的原因。
筆者對于熱門音頻預測領域未來的發展仍是看好的。科學研究活動必然借助于先進的數據與計算平臺,先進的數據與計算平臺也將因應用需求驅動演進出更新的技術,驅動當代科學研究的螺旋式上升[38]。隨著深度學習、大數據和云計算技術的深入發展,會有更大量的可用實驗音頻數據集,對于“熱門”指標的衡量也可以通過加入更多維度的數據計算過程來使其更加客觀和準確。同時,計算機的數據計算和處理能力也會不斷加強,各種改進的深度學習算法層出不窮,熱門音頻預測領域仍會有很大的探索空間,具體可歸納為以下三點:
(1)優化特征選取過程:特征選擇的好壞與模型的預測效果息息相關,除了本文中介紹的學者常用的特征外,選取表示性更強的音頻淺層特征、發明更具針對性的音頻深層特征、合理利用文本特征和元數據特征可能會取得更好的預測效果。
(2)優化“熱門”指標的衡量方法:由于問題定義本身固有的類別不平衡,熱門播客或歌曲在語料庫中總是占少數,這會導致訓練數據集的不平衡。此外目前大多數文獻都是通過使用播放量或者是熱門排行榜中的排名這種單維第三方數據來衡量音頻的“熱門”程度,因此該指標可能并不科學或客觀。更多的社會影響要素如推廣宣傳、時事熱點等狀況未被考慮進去。這一領域更是需要更深入的跨學科研究過程。
(3)從預測模型算法方面進行優化:可以利用多層音頻特征、文本特征以及元數據特征來構建改進的多模態模型或融合模型,使算法更具對熱門數字音頻預測領域的問題針對性。
此外,由上文可知,目前國內科研界對熱門數字音頻預測領域的研究內容較為欠缺,筆者在搜集文獻時可查閱的中文文獻相對較少。而在世界范圍內,熱門音樂預測領域的研究成果也遠遠多于熱門播客預測領域的研究成果。但值得一提的是,目前我國移動網絡電臺發展迅速,根據前瞻產業研究院的報告顯示,喜馬拉雅FM 在2020年5月的平臺月活用戶數已超過9937.39 萬人,因此對我國熱門播客預測領域進行研究具備深遠意義。
利益沖突聲明
所有作者聲明不存在利益沖突關系。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
