基于SURF特征的汽車輪轂型號識別
2021-08-26 10:51:52侯永濤黎良臣顧寄南冒文彥
機械設計與制造 2021年8期
關鍵詞:特征
侯永濤,黎良臣,顧寄南,冒文彥
(1.江蘇大學機械工程學院,江蘇 鎮江 212000;2.江蘇大學機械工程學院,江蘇 鎮江 212000)
1 引言
隨著工業4.0和中國制造2025的相繼提出,智能制造成為了制造業領域的熱門話題。如何將近年來涌現出的一大批智能算法運用到傳統的制造業中,并使其發揮出超越常規方法的能力,成為了越來越多學者的研究課題。機器視覺技術作為自動化、智能化生產的一項關鍵技術,是未來實現無人化工廠的重要基礎。
物體識別,在傳統機器視覺技術中都是通過模板匹配的方法來實現的。而模板匹配又大致可分為:基于灰度值的模板匹配,基于邊緣的模板匹配,基于形狀的模板匹配以及基于角點、特征點的匹配[1]。這些方法共同的特點就是對圖像的質量要求高,易受環境噪聲的影響。
輪轂是汽車的重要零配件,隨著汽車產量的擴大,輪轂的需求量也日益增加。在自動化生產線上要實現多品種輪轂的混流生產,首先要完成的就是輪轂型號的識別[2]。文獻[2]通過檢測輪轂的三個物理量并構造了四個位置、旋轉不變量,以此作為圖像識別的特征,最后利用投票分類器來識別輪轂型號。文獻[3]選取了輪轂七個旋轉不變的物理量,以此作為圖像識別的特征。以上兩種方法相似,都需要嚴格的應用環境來保證圖像質量,以便于圖像處理獲得特征。另外,當兩種輪轂物理量相似時,會對識別產生干擾。文獻[4]利用輪輻的邊緣作為模板進行匹配,并增加了輪轂圖像紋理對比的步驟,從而減少了誤識別的幾率。但是邊緣匹配只能適應小范圍的光照變化,此外,該方法的實時性也是一個問題。文獻[5]提出一種在遮擋、雜波和不同光照下具有不變性的通用匹配算法。該算法對應用環境有很強的適應性,但是面對體型較大、形狀各異的輪轂時,制作模板、處理圖像都會變得十分復雜。
綜上所述,用傳統的方法來識別輪轂型號是十分復雜的,且易受環境影響,可靠性不佳。針對輪轂自身的特點,這里的將采用輪轂圖像的SURF特征與神經網絡相結合的方式來識別輪轂型號。該方法既具有SURF算法的優良特性,又具有神經網絡容錯能力和學習能力強的特點。
2 圖像SURF特征的提取
文獻[6]提出了一種提取圖像尺度不變特征點的算法即SIFT(Scale Invariant Features Transform)算法。SIFT特征對旋轉、尺度縮放具有不變性,對光照變化也不敏感。文獻[7]進一步改進了SIFT算法,形成了SURF算法。SURF特征(Speeded-Up Robust Features)在保持了SIFT特征優良特性的基礎上,解決了SIFT算法計算復雜度高、耗時長的缺點。這就為實時識別提供了有力的支撐。
SURF特征是一種典型的局部特征,提取圖像的SURF特征主要分為五個步驟。
(1)計算圖像中每個像素的Hessian矩陣行列式的近似值。公式為:

其中,D xx、D yy、D x y是將高斯二階導數模板用盒子濾波器代替后與原圖像卷積得到的結果。以9×9模板為例,如圖1所示。圖中灰色像素代表0,上圖是y方向高斯二階求導的近似表示,下圖是高斯二階混合偏導的近似表示。另外,Bay H還引入了積分圖像的概念,進一步提高了計算效率。
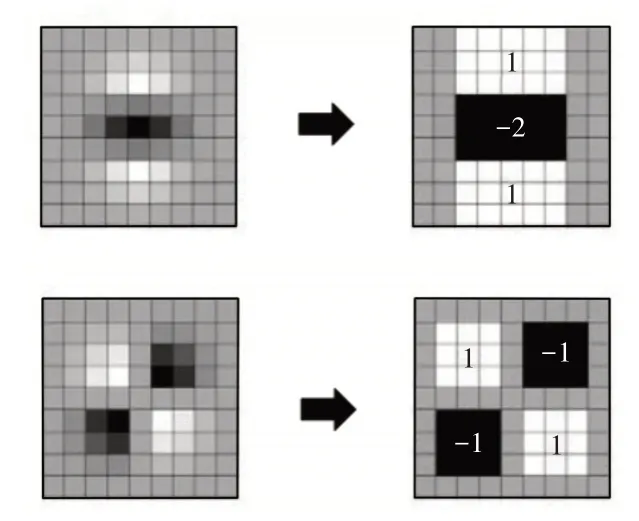
圖1 將高斯二階導數模板用盒子濾波器代替Fig.1 Replaces Gaussian Second Derivative Template with A Box Filter
(2)構造尺度金字塔。相比于SIFT算法,SURF算法沒有降采樣過程,圖像的大小保持不變,改變的是高斯模糊模板的尺寸和尺度。
(3)定位特征點。如圖2所示,將經過式(1)處理過的每個像素點與其3維鄰域的26個點進行比較,如果該點為極值點,則作為初步的特征點。然后,采用3維線性插值法得到精確的特征點。

圖2 特征點的初定位Fig.2 Initial Positioning of Feature Points
(4)確定特征點的主方向。特征點主方向的確定是使SURF特征具有旋轉不變性的關鍵。以特征點為中心,半徑6S(S為特征點所在的尺度值)劃定一個圓形區域,每60°統計扇形內所有點在x和y方向上的Haar小波響應值(Haar小波邊長取4S),再給這些響應值乘以高斯權重系數,使得越靠近特征點的權重越大,然后將這些響應值相加得到一個矢量,最后取所有扇形區域得到的矢量長度最長的作為該特征點的主方向。
(5)構造特征描述子。在特征點的周圍劃定一個邊長為20S的正方形區域,該正方形的一邊與特征點的主方向垂直。如圖3所示,將正方形區域劃分為16個子區域,然后計算每個子區域中所有像素點在x和y方向的Haar小波響應,再將x、y方向的響應值以及響應值的絕對值分別相加獲得4個值,公式為:

圖3 特征描述子的構造Fig.3 Structure of Feature Descriptor

因此,特征點即可用一個4×16=64維的向量來表示。
3 搭建神經網絡
由于輪轂型號有多種,采用的分類算法必須具備多類別的分類能力。而神經網絡作為常用的分類算法,具有容錯能力、學習能力強的特點,適合多類別分類的問題。神經網絡的本質是使用大量的基本非線性計算單元(稱為神經元),這些單元以網絡的形式進行組織,就像大腦中神經元的互連那樣[8]。神經網絡一般分為輸入層、隱含層和輸出層。一般情況下,一個三層的神經網絡就能訓練出一個合適的分類器來解決分類問題。如圖4所示,這里的將提取出的輪轂圖像的SURF特征作為神經網絡的輸入,將輪轂型號作為輸出,經過一定量樣本圖像的訓練,從而訓練出一個合適的分類模型。

圖4 神經網絡的搭建Fig.4 Construction of Neural Network
針對如何用提取出的輪轂圖像的SURF特征作為圖像的表征,從而用于神經網絡的訓練。這里的將提取出的SURF特征點按照每個特征點的強度值即由式(1)得到的值,從大到小進行排序。假設每張圖像提取m個SURF特征點,則每張圖像可表示為:

因為每個特征點是由一個64維的向量來表示的,所以將每個特征點的描述向量按照式(3)的順序連接成一個向量,就可以以此來表征圖像。因此,輸入層的神經元數就是64m個;輸出層的神經元數就是所需分類的類別數n;而隱含層的神經元數由經驗式(4)確定。

4 實驗與分析
這里的以三種型號的輪轂為例,采集了強光、正常光、弱光下輪轂在傳送帶上的圖像。A、B、C三種型號輪轂的灰度圖,如圖5所示。圖像大小為756×756。實驗方案,如圖6所示。識別算法基于MATLAB R2016a平臺實現。實驗所用的計算機配置:In?tel Core i3-2310M處理器,頻率:2.1GHz;NVIDIA GeForce GT 520M顯卡;4G運行內存。

圖5 三種型號輪轂的灰度圖像Fig.5 Gray Image of Three Types of Hub

圖6 實驗方案流程圖Fig.6 Experimental Scheme Flow Chart
實驗中,每種型號輪轂各采集了90張圖像。根據文獻[9]提取SIFT特征點來識別汽車標識時,每張圖像所提取的特征點數,對每張輪轂圖像提取了100個SURF特征點,這些特征點也基本能夠覆蓋輪轂的關鍵部位,能夠充分表達各型號輪轂圖像的特點。因此,神經網絡輸入層的神經元數即為:6400;輸出層的神經元數即為:3;由式(4)可知隱含層的神經元數即為:85(β取5)。另外,A型輪轂在輸出層以[1 0 0]表示,B型輪轂以[0 1 0]表示,C型輪轂以[0 0 1]表示。
實驗中,將所有樣本分成了訓練集、驗證集和測試集,每個集合依次占70%、15%、15%,結合總的圖像數即訓練集:188張、驗證集:41張、測試集:41張,且都是隨機抽取。其中驗證集是用來衡量網絡的泛化能力,在泛化能力無法繼續改善時停止訓練,防止過擬合。神經網絡采用量化共軛梯度反向傳播法[10]來更新網絡的權值和偏差值;采用交叉熵來衡量網絡的性能。
經過訓練、驗證和測試,得到了一個最佳的識別模型,該模型的性能隨訓練過程的變化,如圖7所示。模型在第47代時獲得最佳驗證性能,交叉熵值約為:0.0044。利用該識別模型對更多A、B、C三種型號的輪轂圖像進行了識別,得到了三種型號輪轂的平均識別準確率和一次識別所需要的時間,并與其它方法進行了比較結果,如表1所示。其中,多參數匹配方法和形狀匹配及紋理篩選方法的識別準確率和識別時間分別由文獻[2]和文獻[4]得到。

圖7 模型的性能隨訓練過程的變化Fig.7 Model Performance Changes with Training Process

表1 識別的準確率和時間消耗Tab.1 Identification Accuracy and Time Consumption
5 結論
(1)這里的利用SURF特征對光照不敏感、抗干擾性強以及神經網絡容錯能力、多類別分類能力強的特點,實現了對多種型號汽車輪轂的識別。(2)工業環境中,比如在傳送帶、輥道等這些單一背景下,這里的的識別方法具有很高的準確率;并且能夠容忍輪轂表面的金屬反光和背景中的噪聲;另外,從每次識別所需的時間來看,完全能滿足實時性的要求。(3)但是這里的的識別方法十分依賴神經網絡對數據信息的學習,即沒有經過訓練的型號是無法識別的。這與傳統模板匹配必須事先制作某一型號輪轂的模板才能識別該型號輪轂一樣。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
