基于中間表示規則替換的二進制翻譯中間代碼優化方法
2021-08-24 03:17:44龐建民
國防科技大學學報 2021年4期
李 男,龐建民
(1. 戰略支援部隊信息工程大學, 河南 鄭州 450001;2. 數學工程與先進計算國家重點實驗室, 河南 鄭州 450002)
二進制翻譯技術[1-2]是作為程序等價變換工具產生并發展起來的,被定義為一種機器上的指令序列到另一種機器上指令序列的等價轉換過程。它在豐富國產平臺軟件生態的過程中,發揮了重要作用。
二進制翻譯按照實現方式主要包含靜態翻譯和動態翻譯[3]。靜態翻譯采用的是一種先翻譯后執行的“離線翻譯”方式,實現了“一次翻譯,多次執行”,其翻譯過程與執行過程彼此獨立,翻譯時間不計入系統時間。動態翻譯采用的是一種邊翻譯、邊執行的“捆綁式”工作方式,可以實現多源到多目標的程序翻譯,由于可以獲得運行時信息,因此動態翻譯能夠解決靜態翻譯難以解決的動態地址發現和自修改代碼的問題。但是,動態翻譯本身需要占用部分系統時間。翻譯優化問題一直是動態翻譯的研究熱點[4-6]。本文在不引起歧義的情況下,將待翻譯二進制文件的生成平臺稱為源平臺,將動態二進制翻譯器運行的平臺稱本地平臺或目標平臺。
1 問題的提出
動態二進制翻譯在實現多源到多目標的程序翻譯過程中,為了屏蔽不同源平臺間的硬件差異,引入了中間代碼,可以將任何源平臺的指令先轉化成中間代碼,再轉化成目標平臺指令。在中間代碼生成過程中,動態二進制翻譯采用了內存虛擬機制,借助臨時變量和環境變量,將對源平臺特定寄存器的訪問操作轉化為與寄存器無關的內存訪問操作。臨時變量用來暫存變量,一般使用tempX的形式來表示,例如temp0,temp1等;環境變量是一種全局變量,用來模擬源平臺的CPU環境,負責將臨時變量存儲到本地內存,一般使用env的形式來表示。env有多種實現形式,例如X86平臺對應的env數據結構如圖1中的CPUX86State所示,其成員變量regs[CPU_NB_REGS]用來模擬X86平臺的寄存器,此時常量CPU_NB_REGS=9。
圖1 X86平臺下的env結構
Fig.1 env structure on X86 platform
利用內存虛擬機制,二進制翻譯器在處理與源平臺寄存器有關的指令時,借助env將其轉化成對本地內存空間的操作。圖 2展示了X86平臺的立即數加法被翻譯到中間代碼的過程。源平臺第1條movl匯編指令是立即數傳送指令,使用了通用寄存器eax,經過內存虛擬機制,被翻譯為2條中間代碼:第1條中間代碼是movi_i32 temp0,S|0x1,表示將立即數0x1暫存于臨時變量temp0中;第2條中間代碼是st_i32 temp0 env,S|0x0,表示將temp0存儲于由環境變量env和偏移量0指定的本地內存位置。由環境變量env與偏移量構成的虛擬內存位置等價表示了源平臺的位置,實現了去源平臺化,這就是內存虛擬的含義。
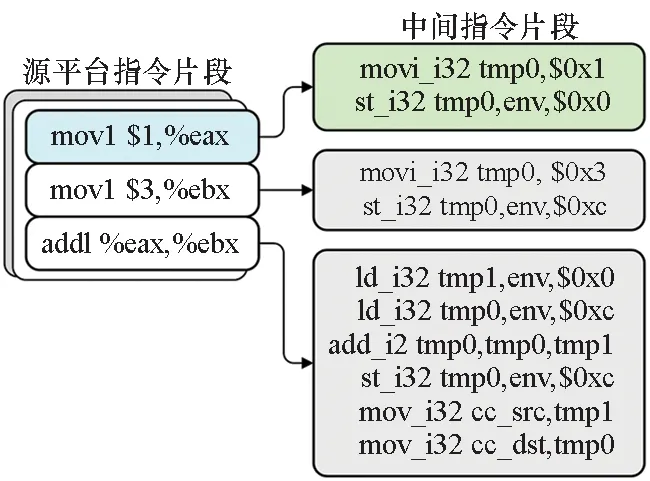
圖2 立即數加法的翻譯過程Fig.2 Translation process of immediate addition instruction
內存虛擬策略在屏蔽源平臺硬件差異的同時,會帶來中間代碼的膨脹問題。在圖 2的示例中,源平臺的前2條指令被分別翻譯為2條中間代碼,第3條指令被翻譯為6條中間代碼。總的代碼膨脹達到3.3倍。造成中間代碼膨脹的原因在于中間代碼生成機制依賴于頻繁的內存模擬操作。
在針對中間代碼優化的相關研究中,主要采用的方法有兩類:第一類與后端冗余指令相關,文獻[7]提出了線性掃描冗余ldM和stM指令的匹配刪除算法來刪除冗余指令;文獻[8]引用活性分析技術對快速模擬器(Quick EMUlator, QEMU)[9]后端無內部互鎖流水級的微處理器(Microprocessor without Interlocked Piped Stages, MIPS)冗余MOVE指令提出了刪除算法。另一類方法與寄存器分配策略相關,文獻[10]詳細分析了QEMU下的寄存器管理機制,但并未提出自己的優化方案;文獻[11]實現了X86平臺到龍芯平臺的寄存器映射,映射的寄存器范圍限于源平臺的eax、esp、ebp三個寄存器和龍芯平臺的S4、S5、S6三個寄存器;文獻[12]提出了一種在寄存器映射過程中進行裁剪的方法,借助裁剪函數實現了PowerPC平臺到ALPHA平臺的寄存器映射;文獻[13]實現了X86平臺下的8個通用寄存器向MIPS平臺的映射;文獻[14]提出一種基于優先級的動靜結合寄存器映射優化算法,首先根據源平臺寄存器的統計特征進行靜態全局寄存器映射,然后通過獲取基本塊中間指令需求確定寄存器分配的優先級,進行動態寄存器分配。
基于上述研究,本文將特殊指令匹配與寄存器直接映射思想應用在二進制翻譯中間代碼的優化過程中,對造成中間代碼膨脹的典型場景進行分析歸納,找出特定指令動作的組合,通過建立相應的映射規則,將內存虛擬表示轉化為對本地寄存器的直接操作,從而提高翻譯效率。
2 優化方法
2.1 中間表示函數
動態二進制翻譯使用內存虛擬策略時,中間代碼的生成是通過調用中間表示函數(序列)實現的,一次內存模擬操作需要調用一個中間表示函數序列,由多個中間表示函數的組合進行實現。例如,對于x86平臺下的數據傳送指令MOVIm,reg,內存虛擬機制會調用兩條中間表示函數gen_op_movl_T0_im()和gen_op_movl_reg_T0()生成中間代碼。表1給出了這兩條中間表示函數的功能描述和定義。

表1 中間表示函數示例
中間表示函數gen_op_movl_T0_im()用來實現將立即數暫存于臨時變量CPU_T[0]中,中間表示函數gen_op_movl_reg_T0()用來實現將立即數存入對應于源寄存器的本地內存區域。類似于這樣的中間表示函數還有很多,它們的函數名稱都以gen_op_作為前綴,以特定的指令動作名稱作為后綴。基于中間表示函數,可以進一步對相關機器指令操作,特別是造成中間代碼膨脹的寄存器操作進行描述。
2.2 基于中間表示函數的特定指令動作描述
在圖2的示例中,源平臺的代碼翻譯到中間代碼后,反復出現了立即數提取指令movi_i32,加載指令ld_i32,以及存儲指令st_i32等。通過大量的代碼分析得出,中間代碼膨脹主要與四種寄存器操作相關,包括立即數提取操作、加載操作、存儲操作和臨時變量操作,本文將上述四種造成中間代碼膨脹的特殊指令操作稱為特定指令動作。
使用中間表示函數可以對這四種特定指令動作進行描述,并進一步抽象,方便后續的優化工作。例如,立即數提取操作可以使用中間表示函數類gen_op_movl_A_im表示,并可進一步簡化表示為op_mov_im(A,Im)。
四種特定指令動作的描述如下:
1)立即數提取操作:op_mov_im(A,Im)∈{gen_op_movl_A_im}。
2)加載操作:op_ld(A,α)∈{gen_op_movl_A_reg(α)}。
3)存儲操作:op_st(α,A)∈{gen_op_movl_reg(α)_A}。
4)臨時變量操作:op(A),op(A,B)。第一個參數A用于存儲運算后的結果。
其中,A,B∈{T0,T1,A0}。
以此為基礎,分析造成中間代碼膨脹的典型場景,找到與其相關的特定指令動作組合,然后運用寄存器直接映射思想,使用少量的本地寄存器操作進行等價替換,從而降低中間代碼膨脹。
3 優化方法的實現
在實現將內存虛擬操作映射到本地寄存器的過程中,需要解決好兩個問題:一是要保證寄存器在映射過程中的一致性。二是要建立等價的中間表示替換規則。
針對第一個問題,首先需要構建合適的映射公式,同時,還要保證源平臺每一個待映射的寄存器都能夠映射到本地平臺的某個寄存器上。當本地平臺的寄存器數量遠大于或等于源平臺的寄存器數量時,可以選擇本地平臺的部分寄存器進行映射。當本地平臺的寄存器數量小于源平臺的寄存器數量時,可以采用活性分析技術加以解決。3.1節給出了實現過程。
針對第二個問題,需要找到與中間代碼膨脹相關的特定指令動作的組合,通過構建相應的映射規則,實現將原有的內存虛擬操作轉化為對本地平臺的寄存器操作。3.2節給出了實現過程。
3.1 映射公式的構建
本文研究的源平臺為X86平臺,目標平臺是國產申威平臺,源平臺包含9個通用寄存器,目標平臺包含32個通用寄存器。目標平臺寄存器的數量遠多于源平臺寄存器的數量,滿足映射的前提條件,因此,適用于本文的優化方法。
原有的內存虛擬策略是借助環境變量env通過調用使用env→regs[α]實現的,本文在實現內存虛擬操作到本地寄存器映射時,引入臨時變量數組reg[i],建立了式(1)和表2所示的映射關系。
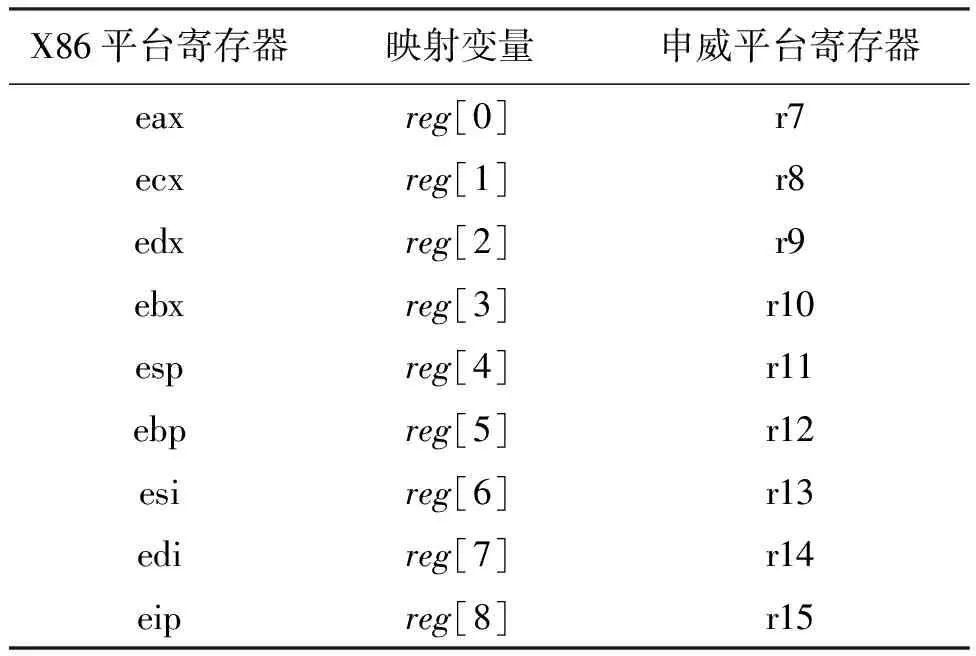
env→regs[α]→reg[i] (1)
在式(1)中,臨時變量數組reg[i]的自變量取值范圍由源平臺寄存器的數量決定,例如,源平臺X86平臺包含9個通用寄存器,則reg[i]中i的取值為0≤i≤8。而目標申威平臺包含32個通用寄存器,僅需要選用其中的部分寄存器進行本地映射即可。本文選用申威平臺下的r7到r15作為本地寄存器進行映射,表2顯示了具體的映射關系。
3.2 中間表示替換規則的建立
2.2節中已經提到中間代碼的膨脹往往和一些特定指令動作的組合相關,針對中間代碼膨脹呈現出的幾種典型場景,應用式(1),可以建立以下4條基本替換規則:
替換規則C1:如果存在相鄰的特定指令動作op_mov_im(A,Im)和op_st(reg(α),A)其中A∈{T0,T1,A0},則可以使用op_mov_im(reg[α],Im))替代op_mov_im(A,Im)和op_st(reg(α),A)。
C1的典型應用場景:將立即數移動到虛擬內存。
分析:將立即數Im提取到中間變量A,然后將中間變量A存儲到虛擬內存reg(α)的操作序列,這與將立即數Im存儲到寄存器reg(α)的操作功能等價。
替換規則C2:如果存在相鄰的特定指令動作op(A)、op_ld(B,reg(α))、op(B,A)和op_st(reg(α),B),其中A、B∈{T0,T1,A0},則可以使用op(reg[α],A)替代op_ld(B,reg(α))、op(B,A)和op_st(reg(α),B)。
C2的典型應用場景:虛擬內存與立即數的計算結果存入同一虛擬內存。
分析:將虛擬內存reg(α)提取到中間變量B,然后將中間變量B和A的計算結果臨時存儲到B中,再將B存儲到虛擬內存reg(α)的操作序列,這與將虛擬內存reg(α)和中間變量A的計算結果存儲到虛擬內存reg(α)的操作功能等價。
替換規則C3:如果存在相鄰的特定指令動作op_ld(A,reg(α))、op(A)和op_st(reg(α),A),其中A∈{T0,T1,A0},則可以使用op(reg[α])替代op_ld(A,reg(α))、op(A)和op_st(reg(α),A)。
C3的典型應用場景:僅操作同一虛擬內存數據。
分析:將虛擬內存reg(α)提取到中間變量A,然后對A進行相關計算并保存計算結果到A,再將A寫回虛擬內存reg(α)的操作序列,這與將虛擬內存reg(α)計算后存儲到自身的操作功能等價。
替換規則C4:如果存在相鄰的特定指令動作op(A)、op_ld(A,reg(α))和op_st(reg(β),A),其中A∈{T0,T1,A0},則可以使用mov_reg_reg(reg[β],reg[α])替代op(A)、op_ld(A,reg(α))和op_st(reg(β),A)。
C4的典型應用場景:僅涉及不同虛擬內存間的數據移動。
分析:將虛擬內存reg(α)提取到中間變量A,然后將A的值存儲到虛擬內存reg(β)的操作,這與將虛擬內存reg(α)存儲到虛擬內存reg(β)的操作功能等價。
在上述4條基本替換規則基礎上,還可以衍生出以下2條擴展的替換規則:
替換規則C5:如果存在相鄰的特定指令動作op_ld(A,reg(α))、op(B,A)和op_st(reg(β),B),則可以使用op(reg[β],reg[α])替代op_ld(A,reg(α))、op(B,A)和op_st(reg(β),B)。
替換規則C6:如果存在相鄰的特定指令動作op_ld(A,reg(α)),op_ld(B,reg(β)),op(B,A)和op_st(reg(β),B),其中A,B∈{T0,T1,A0},則可以使用op(reg[β],reg[α])替代op_ld(A,reg(α))、op_ld(B,reg(β))、op(B,A)和op_st(reg(β),B)。
上述規則提到的相鄰特定指令動作并不要求位置連續,但必須存在于同一基本塊,這是由語義環境一致性要求決定的。通過以上6條替換規則,可以實現功能等價條件下的寄存器直接映射策略,將原有內存模擬操作替換為本地寄存器操作。
4 優化方法的應用
下面分別以翻譯源平臺X86下的立即數加法指令和棧操作指令為例,闡述中間表示替換規則的運用。
圖3展示了應用替換規則后,X86平臺的立即數加法指令被翻譯到中間代碼的優化過程。源平臺中第一條movl指令應用替換規則C1后,將立即數0x1直接存入eax寄存器對應的本地寄存器reg[0]中;類似地,源平臺第二條movl指令應用替換規則C1后,將立即數0x3存入ebx寄存器對應的本地寄存器reg[3]中;源平臺第三條addl指令應用替換規則C6后,使用本地寄存器reg[0]和reg[3]完成相應操作。最終,中間代碼由優化前的10條指令簡化為優化后的5條,中間代碼規模縮減為原來的50%。
同樣,圖4展示了應用替換規則后,X86平臺的棧操作被翻譯到中間代碼的優化過程。應用替換規則后,中間代碼數量由優化前的29條指令簡化為優化后的16條,規模減少了44.8%。
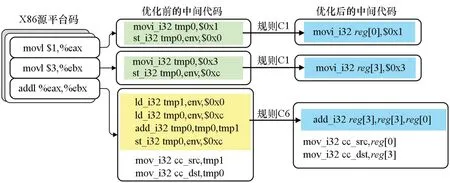
圖3 立即數加法指令的中間代碼優化示例Fig.3 Example of intermediate code optimization for immediate addition instruction
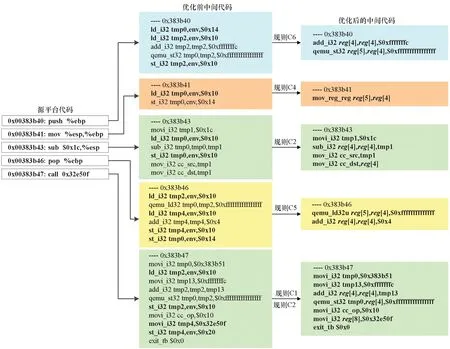
圖4 棧操作指令的中間代碼優化示例Fig.4 Example of intermediate code optimization for stack operation instruction
5 實驗部分
將提出的中間代碼優化方法在開源二進制翻譯器QEMU1.7.2[15]進行了實現。使用如表3所示的實驗環境,源平臺采用的是X86-64架構處理器,本地平臺采用的是國產申威411[16]處理器。

表3 實驗環境
采用了正確性測試和性能測試兩種方法來驗證優化方法的正確性和有效性。正確性測試通過對比優化前和優化后的執行結果是否一致來進行驗證,性能測試通過計算優化后的中間代碼指令數量相對于優化前的中間代碼指令數量的壓縮率來進行驗證,壓縮率越高優化效果越好。測試用例選取了SPEC CPU2006[17]中的CINT2006的測試用例,如表4所示。
5.1 正確性測試
實驗使用SPEC CPU2006進行了正確性測試,采用的測試方法是比較優化前后測試用例的執行結果是否一致。表 5顯示了選取的測試用例和測試結果,測試結果表明優化方法的正確性達到100%。
5.2 性能測試
實驗借助QEMU翻譯SPEC CPU2006測試用例過程中產生的中間代碼日志文件,通過對比優化前后日志文件中的中間指令數量,測試中間代碼優化的效果。為了更清楚地說明測試效果,引入了代碼縮減率R,如式(2)中所示:
R=1-Nopt/Nori×100%
(2)
式(2)中,Nori代表優化前的中間指令數量,Nopt代表優化后的中間指令數量,R值越高表明中間代碼優化效果越好。
實驗記錄了每個測試用例的R值,測試結果見圖5。結果表明,中間表示規則的建立對于中間代碼的優化效果作用明顯,各用例的代碼縮減率R平均達到32.59%。可以看出,不同用例的加速效果差別較大,優化效果最好的用例是xalancbmk,其R值達到了37.31%;優化效果最差的用例是gcc,其R值為30.68%。通過分析用例源代碼發現,xalancbmk用例中包含了大量的寄存器操作,使得中間表示替換規則可以被充分使用,所以優化效果明顯;gcc用例只包含少量的寄存器移位操作,替換規則應用較少,所以優化作用有限。

表4 測試用例說明
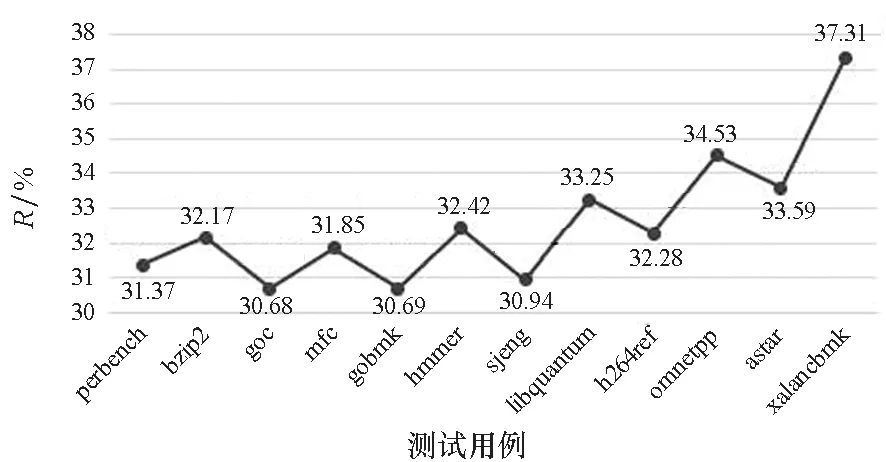
圖5 中間代碼優化性能測試Fig.5 Performance test of intermediate code optimization
6 結論
針對動態二進制翻譯過程中的中間代碼膨脹問題,本文對內存虛擬策略的實現機制進行了深入分析,提出了一種基于中間表示規則替換的二進制翻譯中間代碼優化方法,在對中間表示函數進行分類歸納的基礎上,建立了針對特定指令函數匹配的中間表示替換規則,對于能夠匹配規則的特定指令動作,應用建立的映射公式,使用少量的本地寄存器操作替代原有的內存虛擬操作,進而達到優化中間代碼的目的。
另外,本文研究的基礎平臺是QEMU,具備多源到多目標的二進制翻譯功能,因此,本文提出的方法具有一定的泛化能力。同時,需要進一步完善等價替換規則,從而取得更好的翻譯效果。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
房地產導刊(2022年5期)2022-06-01 06:20:14
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
Coco薇(2017年11期)2018-01-03 20:59:57
