異構網絡中用戶關聯和功率控制的協同優化*
2021-07-28 10:08:30菅迎賓
電訊技術 2021年7期
樊 雯,陳 騰,菅迎賓
(石家莊鐵路職業技術學院 信息工程系,石家莊 050041)
0 引 言
當前數據信息傳輸網絡結構中,異構網絡可有效滿足移動數據流量需求的爆炸性增長,并兼具密集部署和異構特性[1]。與傳統同質網絡相比,異構網絡由宏基站、微基站、皮基站和飛基站等不同類型基站(Base Station,BS)組成,且各基站的發射功率、基站密度和數據傳輸速率均不同[2-3]。目前,隨著移動設備數量的不斷增加,由于上行鏈路異構網絡的頻譜共享策略,用戶設備(User Equipment,UE)間的干擾逐漸加重[4]。因此,當前主流無線通信標準均已采用基于正交頻分多址(Orthogonal Frequency Division Multiple Access,OFDMA)的異構網絡[5]。另外,隨著UE的增加,異構網絡的上行干擾也將逐漸明顯[6]。因此,為進一步提高網絡系統傳輸性能和用戶體驗,開展用戶關聯和功率控制的協同優化是異構網絡研究中的重要主題[7]。
針對異構網絡中用戶關聯和功率控制問題,眾多專家學者對此進行了大量研究。文獻[8]通過研究主要用戶和次要用戶間的上行通信鏈路能量效率,提出了一種基于凸優化理論的迭代算法,能夠有效提高用戶間的網絡通信平衡。文獻[9]基于非合作博弈理論,通過計算異構網絡系統的吞吐量,提出了一種適用于異構網絡的聯合BS關聯和功率控制算法,通過對長期速率加權的最大化處理來平衡網絡負載,并結合異構網絡的功率控制,可有效處理異構網絡延遲和上行鏈路用戶的關聯問題。但上述方法由于聯合用戶關聯和功率控制具有非凸和非線性特性,難以獲得全局最優解。同時,在實際應用中由于通信環境的不斷變化,上述方法無法獲取有效的網絡信息[10]。
因此,針對時變動態環境研究人員提出了基于人工智能的控制策略,通過不斷與環境互動、強化學習,解決長期決策的復雜計算問題。文獻[11]通過使用Q學習算法,提出了一種基于傳統單蜂窩網絡結構的設備到設備(Device to Device,D2D)的聯合信道分配和功率控制策略,可有效提高網絡學習性能。文獻[12]通過將Q學習和深度神經網絡(Deep Neural Network,DNN)相結合構成深度Q學習網絡(Deep Q-learning Network,DQN),提出了一種基于分布式用戶關聯算法的在線學習方法,能夠有效優化異構網絡的能量效率。文獻[13]提出了一種基于DQN框架的用戶關聯和信道分配深度強化學習算法,通過DQN方法對卸載決策和計算資源分配進行了優化。但上述方法所考慮的網絡行動空間相對較小,無法滿足異構網絡中聯合用戶關聯和功率控制問題中大狀態空間和大動作空間的需求,在實際運行中難以通過Q學習算法獲得良好性能。
綜上所述,上述研究主要集中于異構網絡中的聯合用戶群體和渠道分配問題,尚未考慮能量效率的綜合分析。目前,隨著各種新業務和應用場景的不斷涌現,UE的能耗也隨著密集型移動數據計算和應用程序的增長而上升,但當前的電池技術無法滿足移動UE的能源消耗。因此,異構網絡中UE的能量效率優化變得更加重要。基于以上分析,本文提出了一種多智能體DQN方法,對上行鏈路中的用戶關聯和功率控制進行優化處理,并基于能量消耗與UE電池容量的相互作用,將UE的能量效率重新定義為獎勵函數,實現對所有UE能量效率的最大化。仿真實驗驗證了所提算法的正確性和有效性。
1 系統模型構建
圖1所示為典型的異構網絡結構圖[14]。其中,在宏BS的覆蓋區域內,部署了一組小型BS,在不失一般性的情況下,將所有BS的集合表示為M={0,1,2,…,m}。
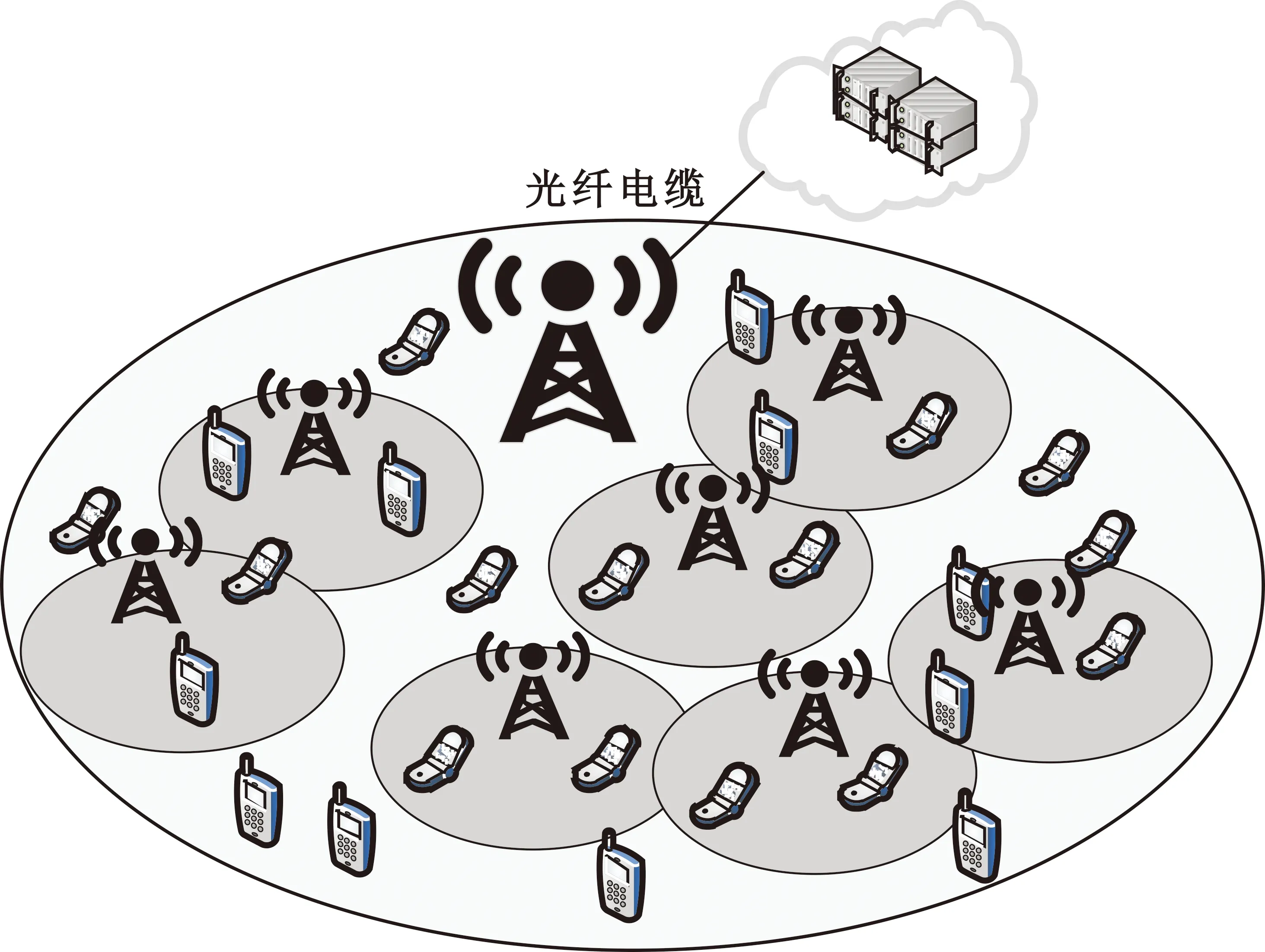
圖1 典型的異構網絡
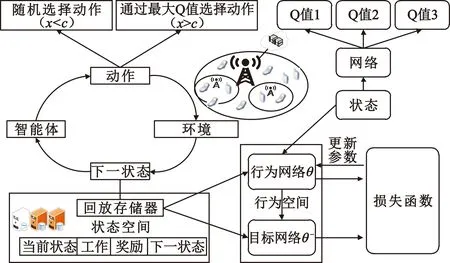
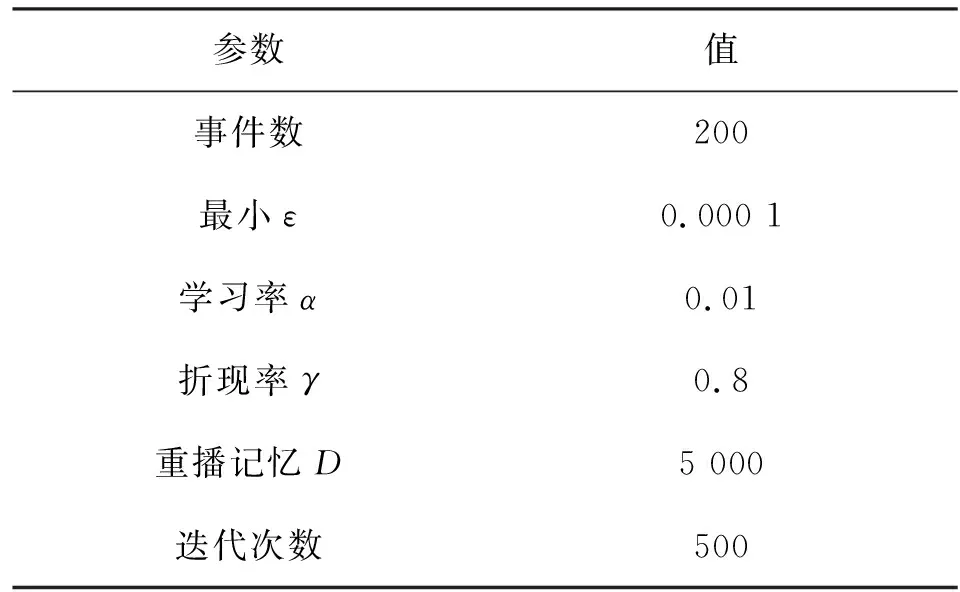
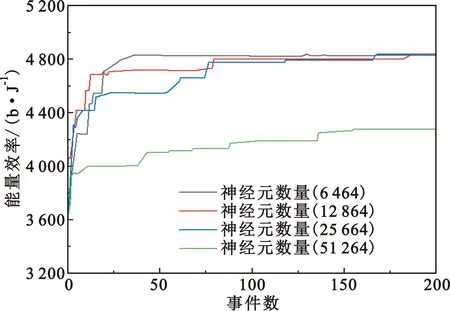
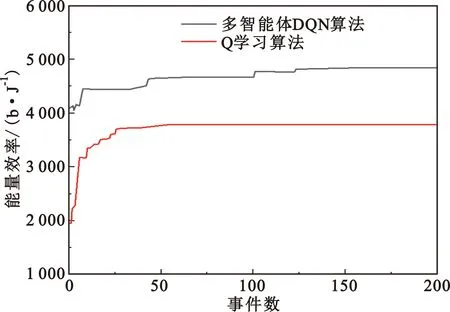
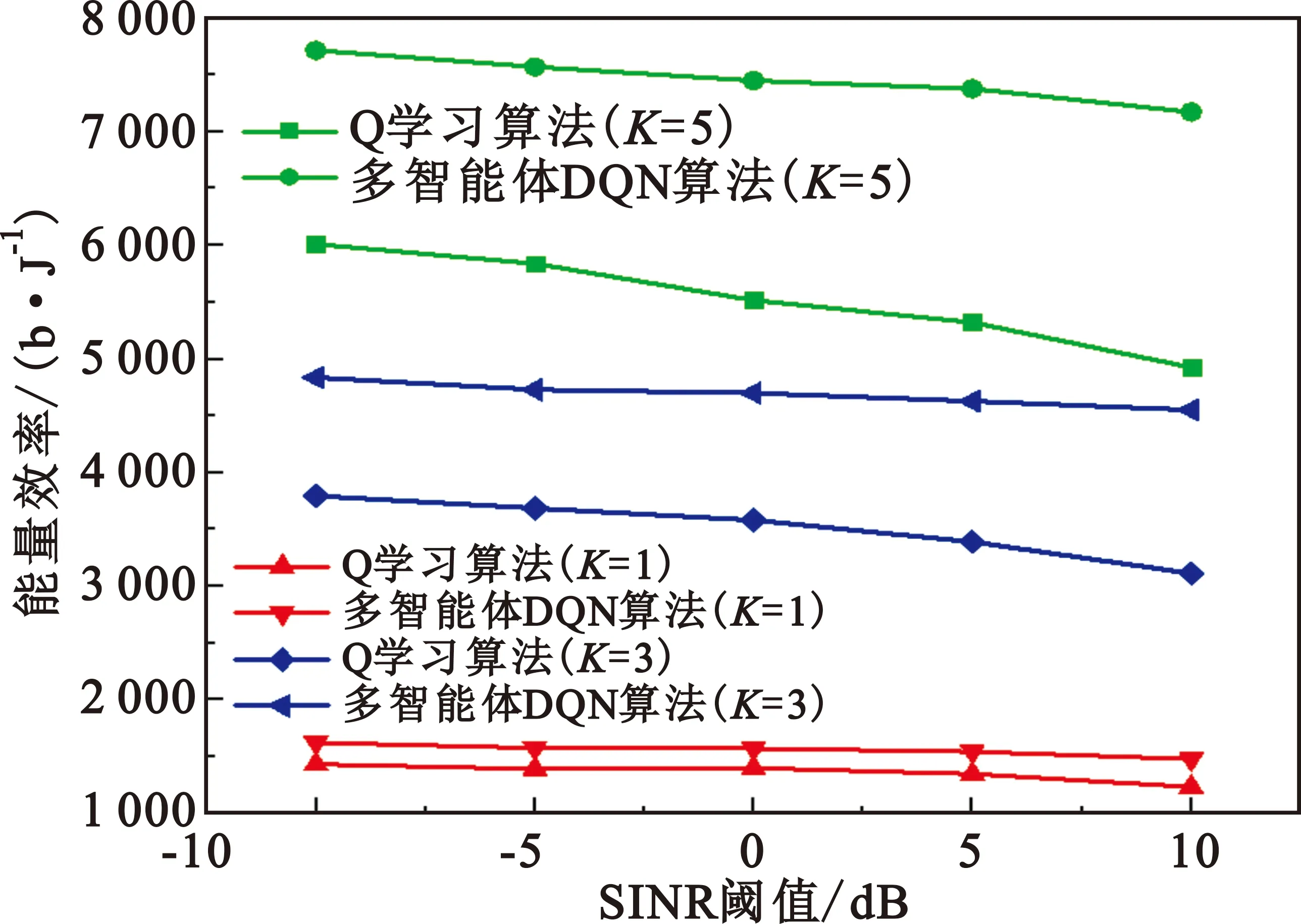
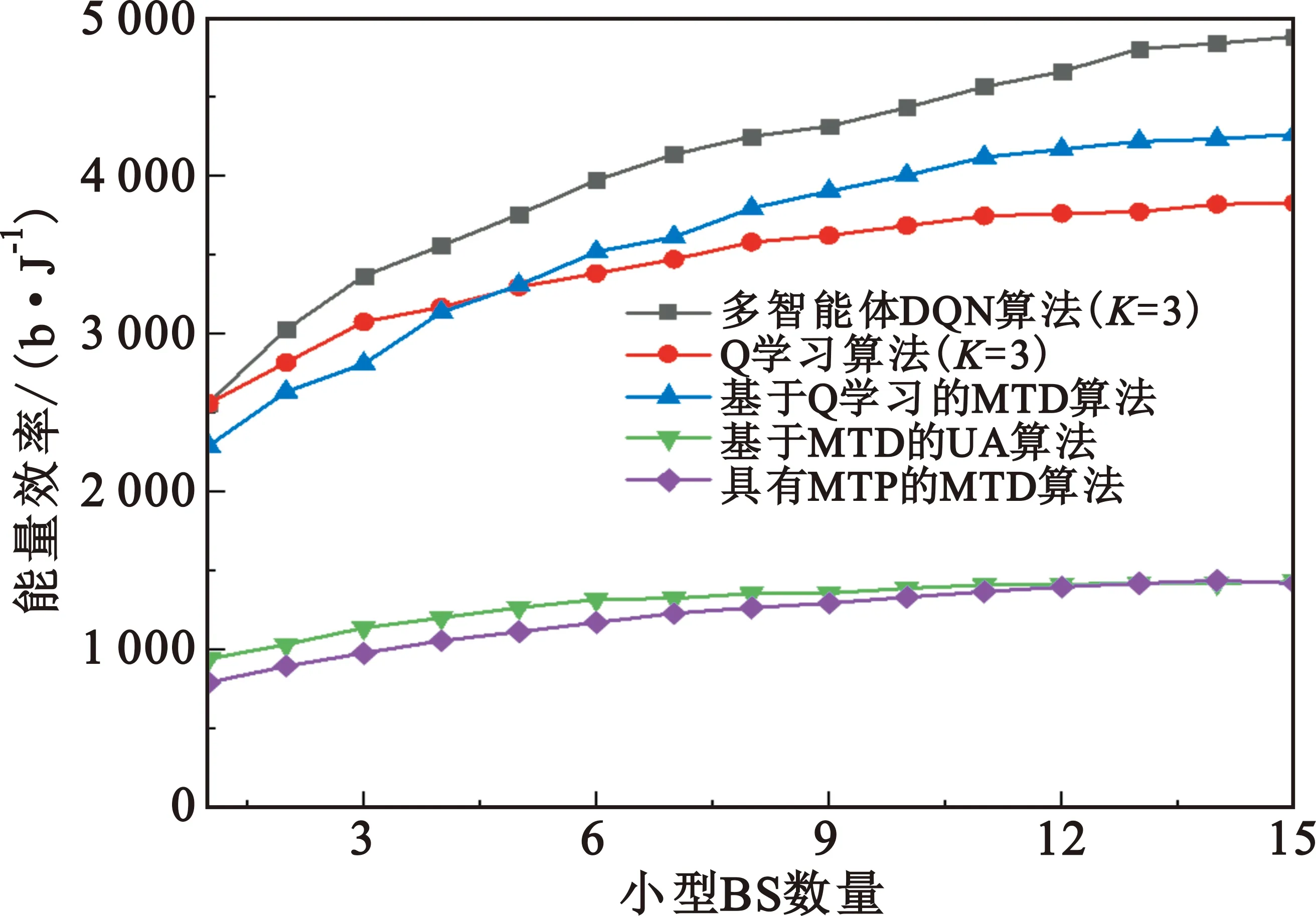
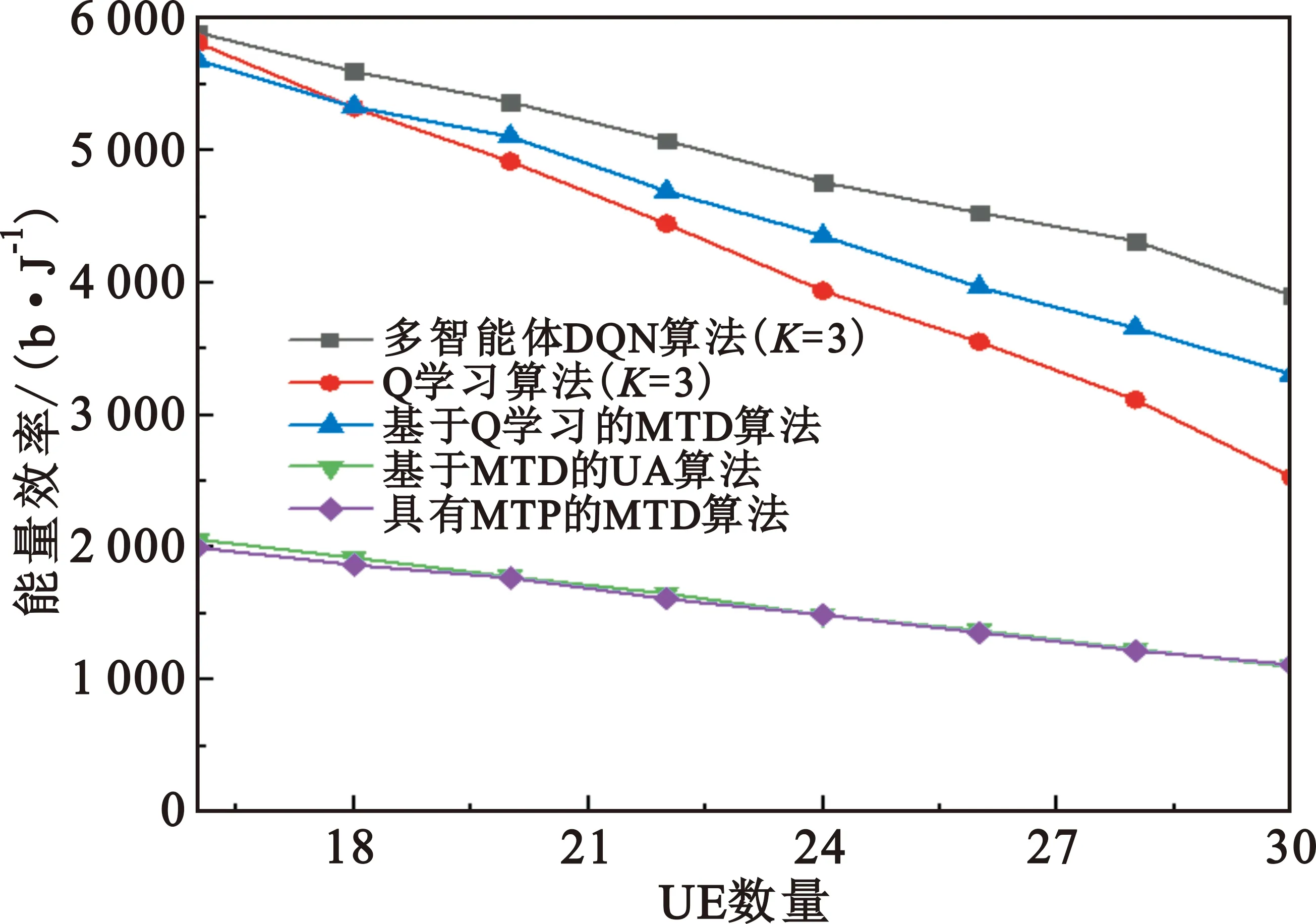
該模型的學習過程由云服務器完成,云服務器通過光纖電纜與宏BS或小型BS進行連接。UE隨機分布在網絡中,且UE的集合為U={1,2,…,u},其中u為UE的總數。通常,基于OFDMA的異構網絡系統具有n個子信道,分別表示為N={1,2,…,n},n 假設所有BS和UE均配備有獨立天線,信道增益主要受瑞利衰落gu,m、對數正態陰影LS和路徑損耗的影響,則將宏BS和小型BS的路徑損耗分別建模為PL1和PL2。因此,具有第m個BS的第n個子信道上的第n個用戶的信道增益的數學表達式如式(1)所示: (1) 為詳細闡明UE與BS間的關系,定義了一組整數二進制變量au,m來表示BS與UE間鏈路的有效性,其數學表達式如式(2)所示: (2) 此外,UE的功耗由靜態功耗和動態功耗兩部分組成。其中,靜態功耗是運行電路組件如轉換器、混頻器、濾波器等時消耗功率,而動態功耗被視為發射功耗。由于數字手機中的發射功率只能在離散水平上進行更新,因此實際應用中可以通過有限數量的值對發射功率進行設置。 (3) 因此,在第n個子信道上連接到第m個BS的第u個UE的信號干擾加噪聲比(Signal-to-Interference plus Noise Ratio,SINR)如式(4)所示[15]: (4) 根據香農公式,第u個UE的數據速率如式(5)所示: (5) 由此,在本文的系統模型中,結合用戶關聯和功率控制,提出了使異構網絡中所有UE的能量效率最大化的優化問題。將所有UE的能量效率定義為每個UE的能量效率之和,并將用戶在第n個子信道上選擇第m個BS的個人能效,定義為可實現的吞吐量與用戶的總功耗的比值,如式(6)所示: (6) 因此,本文異構網絡模型的總能效最大化問題可以表述為式(7)所示: C3:au,m∈{0,1}, (7) 式中:A表示用戶關聯矩陣,p表示所有UE的發射功率向量,γth為預定義的最小干擾加噪聲比;約束C1表示每個UE的發射功率與給定的最大發射功率的比值,C2可確保滿足每個UE的QoS要求,C3與C4能夠確保每個UE只能與一個BS相關聯。因此,通過解決混合整數非線性規劃問題P1,可以找到關于UE與BS的關聯以及傳輸功率,即A和p的最優控制策略。 從式(7)可知,用戶關聯和功率控制機制是相互關聯的。為有效解決異構網絡的混合整數和非凸性問題,以獎勵函數為基礎提出了基于強化學習的馬爾科夫決策過程。 在本文研究的場景中,主要是將協同優化問題P1轉換為馬爾科夫決策過程(S,A,R,Pss′)。其中,S為決策過程狀態空間,A為UE的動作空間,R為獎勵函數,Pss′為從狀態s過渡到狀態s′的概率。隨后,基于馬爾科夫決策過程,構建強化學習過程的系統狀態空間、動作空間和獎勵函數,具體如下: (1)狀態空間 在公式化問題P1中,智能體UE需選擇BS進行通信,確定發射功率,并將系統狀態空間定義為sstate={s1,s2,…,sj,…,s(M×K)U}。其中,sj=j表示所有UE與BS和功率控制相關聯的狀態。根據系統狀態空間公式可知,隨著U的逐漸增加,狀態數量呈指數增長。此外,由于每個UE僅可選擇一個子信道,選擇相同子信道的用戶將產生相互干擾。因此,從子信道角度出發,每個子信道的狀態空間可定義為sn={s1,s2,…,sj,…,s(M×K)Nn},其中Nn為第n個子信道服務中UE的數量。 (2)行動空間 在公式化問題P1中,需要控制UE與BS的關聯和發射功率,否則UE在時刻t的第n個子信道中的動作將出現發散。因此,對于第n個子通道中的所有動作,可定義時刻t的動作空間為an(t)={a1(t),a2(t),…,aj(t),…,a(M×N)Nn(t)}。系統N個子通道的所有動作如式(8)所示: a(t)={a1(t),a2(t),…,an(t),…,aN(t)}。 (8) (3)獎勵函數 通常,學習過程由強化學習框架中的獎勵函數驅動,在基于OFDMA的異構網絡下,將所有UE的總能量效率定義為系統獎勵函數,其數學表達式如式(9)所示: (9) 式中:rn(t)為第n個子通道的獎勵函數,通過與環境的相互作用最大化進行最優策略學習。 通過以上分析,可以將問題P1轉換為問題P2,其數學表達式如式(10)所示: (10) (11) 式中:γ∈[0,1]為折現因子,T為最大事件數。其中,當γ=0時,返回的獎勵為當前獎勵;當γ=1時,Rn(τ)等于獎勵的總和。 (12) (13) 因此,基于Bellman方程,異構網絡的最佳Q值函數如式(14)所示: (14) (15) 對式(14)和式(15)進行聯合求解,其結果如式(16)所示: (16) (17) 式中:α為學習率。 由于Q學習方法需選擇具有最佳值的動作,且對所選動作進行評估。另外,Q學習方法使用采樣方法進行狀態選擇,將使得采樣狀態過高,且采樣狀態和未采樣狀態之間的差距將會逐漸增大。通常,異構網絡的狀態和動作空間較大,使用Q學習方法獲得的最優解往往存在不足,即Q學習方法無法為大規模系統狀態空間采樣某些特殊狀態。因此,為了應對大規模的系統狀態空間問題,須采用深度強化學習方法。 (18) 由于數據樣本之間存在差異,系統難以獲得一個平滑的學習模型。因此,考慮具有權重參數θ的目標網絡作為系統智能體。通常,多智能體DQN方法有行為網絡和目標網絡兩種,通過使用目標網絡,計算目標值yi的學習模型,在一定時間內能夠保持權重參數恒定不變,減輕學習模型的波動性。此外,也可通過行為網絡獲得系統效率的估值。 通常,在強化學習過程中,經過一定數量的迭代之后,行為網絡的權重參數θ將與目標網絡同步,即θ→θ-。隨后,自動進入下一階段的學習。對于行為網絡,智能體將使用ε貪婪策略選擇動作an(τ),并使用最小損失函數為每次迭代更新的參數θ,其數學表達如式(19)所示: L(θ)=∑[(yj-Qπ(sn,an|θ))2] , (19) (20) DQN方法中,由于數據樣本之間的相關性,將導致學習不穩定。因此,可運用經驗回放技術進行DQN學習,其中主要包含存儲數據和采樣數據兩部分,經驗數據按迭代順序存儲到回放存儲器D中。在DQN學習過程中,智能體將選擇動作an(τ),獲得獎勵rn(τ)并轉到下一個狀態。隨后,將向量存儲到體驗存儲器中。如果內存D的存儲已滿,則新的體驗數據將覆蓋前一次迭代生成的數據。圖2所示為多智能體DQN策略圖,其中狀態空間和行為空間通過回放存儲器進行關聯。 圖2 多智能體DQN策略圖 在初始運行過程中,每個智能體分別為行為網絡和目標網絡的初始化內存D,以及權重參數的θ和θ-。隨后,智能體初始化開始進入狀態,并使用ε貪婪策略選擇動作an(τ)。最后,如果狀態約束條件滿足,則智能體將發送有關用戶關聯的信息,并將功率發送到環境條件中,通過獎勵函數rn(τ)和下一狀態獲得功率比值n;否則,智能體將不會回放任何內容。 向量Sn主要存儲在回放存儲器D中,通過將樣本隨機小批量寫入存儲器D,可通過初始化更新行為網絡的權重參數。當訓練一定數量的迭代次數時,行為網絡的參數將同步到目標網絡,并開始下一階段的學習。 選取具有一個宏BS和小型BS的兩層異構網絡進行多智能體DQN算法仿真實驗。其中,令25個UE隨機分散在宏BS的覆蓋范圍內,并設置其區間為200 m×200 m。此外,令小型BS也隨機分布在相關區域中。 其中,UE的最大發射功率為23 dBm,子信道總數為15,宏BS和小型BS的傳輸損耗為PL1=34+40 lg(d),PL2=37+30lg(d)。其中,d是從BS到UE的距離,對數法線陰影為8 dB,噪聲功率設置為σ2={-174 dBm}。 為估計Q函數計算結果,采用DNN算法在包含64個神經元的全連接神經網絡的兩個隱藏層以及一個輸出層模型中進行計算,表1所示為DQN的詳細參數。 表1 DQN詳細參數 首先,對具有不同學習參數,如學習率和神經元數量的DNN的性能進行仿真,分析具有不同學習率的訓練效率,其仿真結果如圖3所示。由圖3可知,隨著事件數的增加,所有UE的能量效率逐漸收斂。此外,隨著學習率α的變化,相較于α=0.1、α=0.001、α=0.000 1,當α=0.01時,所有UE的能效性能最佳。對α=0.01和α=0.1兩種情況進行比較分析可知,當學習率α較大時,算法計算結果難以達到最佳值;當學習率相對較小時,將可能導致局部最優。因此,考慮到算法的實際執行,將所提算法的學習率α設置為0.01。 圖3 不同學習率下的能量效率 圖4所示為DNN結構中不同數量神經元的性能。由圖4可知,隨著神經元數量的不斷增加,所有UE的能量效率都逐漸下降。由于數據樣本的稀疏性,當神經元數量過多時,優化問題可能會導致過度擬合,并增加更多的訓練時間。當神經元等于第一層的64和256時,兩條曲線的收斂性幾乎相同,而其他情況在收斂性上的表現則較差。因此,將兩個隱藏層的神經元均設置為64。 圖4 DNN結構的能量效率與神經元數目的關系 在SINR設置為γ=-10 dB的情況下,對多智能體DQN算法的收斂性能進行分析,并將其與經典Q學習框架進行對比分析。圖5所示為對比分析收斂性結果圖,由圖可知,Q學習的系統能效低于使用多智能體的DQN方法;且隨著事件數的增加,兩種方案的能量效率均會逐漸增加并趨于收斂,但多智能體DQN算法在學習速度上優于Q學習方法。對于Q學習方法及多智能體DQN算法,當事件數約等于180時,其系統能量效率改善較低;當事件約等于157時,其系統能量效率趨于穩定。由此可知,多智能體DQN算法雖開始呈現出發散性,但隨著事件數的增加,其不穩定程度會逐漸降低,并最終趨于收斂。因為智能體隨機選擇并將信息存儲到回放內存中,經過多次迭代,多智能體DQN算法開始從經驗中學習,從而提升其穩定程度。 圖5 收斂性能 此外,在不同SINR閾值下采用Q學習算法和多智能體DQN算法時,模擬所有UE的能量效率。圖6所示為不同K值下能量效率與SINR閾值的關系圖,由圖可知,隨著UE中SINR閾值的增加,所有UE的能量效率均逐漸降低。因為要實現較高的SINR,必然會消耗更多的功率,這將降低所有UE的能效。另外,隨著功率水平的增加,所有UE的能量效率也隨之提高。因為隨著功率水平的增加,智能體可以在固定的用戶關聯下選擇更合適的傳輸功率,從而提高能量效率。對于K=1的情況,UE的發射功率等于最大發射功率,即PMAX=23 dB。根據圖6可知,當UE的發射功率最大時,其能量效率最差。 圖6 不同K值下能量效率與SINR閾值的關系 此外,本文對不同數量小型BS的所有用戶設備的能量效率展開了仿真研究。設置γ=-10 dB,K=3,仿真結果如圖7所示。為了評估多智能體DQN算法的性能,除Q學習算法外,本文還選取了其他三種算法進行對比研究,即基于Q學習的MTD算法、基于信息傳遞部分(Message Transfer Part,MTP)的UA算法,以及具有MTP的動目標檢測(Moving Target Detection,MTD)算法。 圖7 能量效率與小型基站數量的關系 對于具有基于Q學習的MTD方案,用戶選擇最小傳輸距離用戶關聯方案,并采用基于Q學習的功率控制算法。對于具有MTP方案的UA,用戶采用基于Q學習的用戶關聯方案,并使用其最大發送功率進行發送。最后,對于帶有MTP方案的MTD,用戶選擇最小傳輸距離用戶關聯方案,并使用其最大發射功率進行發射。由仿真結果可知,隨著小型BS數量的增加,所有UE的能效將呈現出先增加,然后逐漸降低的現象。 對于基于Q學習的MTD算法,當小型BS的數量較少時,Q學習算法的性能表現更好。隨著小型BS數量的增加,Q學習算法的性能將逐漸下降。主要是由于狀態和動作的空間變大,部分狀態被高估,并且沒有被采樣。因此,在基于OFDMA的異構網絡模型中,小型BS的數量設計至關重要。 圖8所示為不同數量的UE下的所有UE的能量效率圖。由圖可知,相較于其他四種方案,多智能體DQN算法在所有UE的能量效率中均獲得了最佳性能。這是因為與基于Q學習的MTD算法、基于MTP的UA算法,以及具有MTP的MTD算法相比,多智能體DQN算法不僅優化了用戶關聯,還對發射功率進行了優化。通過使用DNN,多智能體DQN算法可以克服Q學習算法的缺點。因此,與Q學習算法相比,多智能體DQN算法具有更加優越的性能。這是因為系統狀態和動作空間將隨著UE數量的增加而增加。另外,隨著UE數量的逐漸增加,所有方案的UE能效性能均會逐漸下降,是因為越高的用戶數量將會引起越嚴重的干擾。 圖8 能量效率與用戶數量的關系 本文針對基于OFDMA異構網絡中的用戶關聯和功率控制協同優化問題,提出了一種多智能體DQN方法,通過仿真計算和分析得出以下結論: (1)相較于傳統的優化算法,多智能體DQN算法所需要的通信信息更少,計算時間更短,優化效率更高; (2)相較于傳統的Q學習算法,多智能體DQN算法具有更好的收斂性能; (3)所提方法能夠有效提升UE的服務質量與能效,并可獲得最大的長期總體網絡實用性。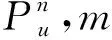
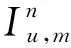
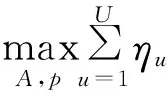
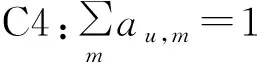
2 DQN強化學習過程構建
2.1 馬爾科夫決策轉換
2.2 強化學習

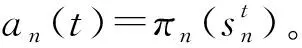
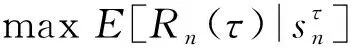
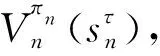
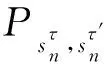
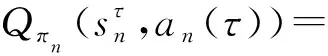
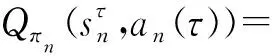
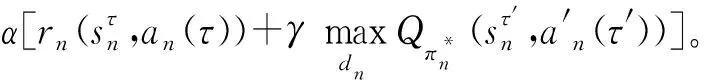
3 多智能體DQN框架
3.1 多智能體DQN方法
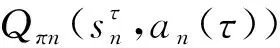

3.2 多智能體DQN模型構建
4 仿真結果與分析
4.1 仿真計算

4.2 能量效率仿真
5 結 論
猜你喜歡
當代陜西(2021年17期)2021-11-06 03:21:36
甘肅教育(2020年14期)2020-09-11 07:57:42
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
學苑創造·A版(2018年11期)2018-02-01 06:29:20
讀者(2017年5期)2017-02-15 18:04:18
時代英語·高二(2015年1期)2015-03-16 00:08:11
中國衛生(2014年11期)2014-11-12 13:11:32
