豆瓣大連電影票信息爬取與存儲
2021-07-04 13:10:25孫愛婷
科學與財富 2021年11期
關鍵詞:分析


摘 要:針對爬取工作量較重,分析內容繁雜的網站而言,利用正則表達式的re模塊實現爬蟲是較困難的,此時需要更高效的BeautifulSoup分析工具來解決這一問題。爬取豆瓣電影票-大連城市網站中的全部電影列表,首先進行網頁源代碼分析,采用python自帶的html.parser解析器解析網頁,爬取所需電影信息,然后采用5種不同方式進行存儲,方便進行不同需求的數據挖掘和分析。
關鍵詞:網頁爬取;BeautifulSoup;解析器
一、BeautifulSoup
BeautifulSoup是網絡爬蟲必學的技能之一,是一個可以從HTML或XML文件中爬取數據的python庫。BeautifulSoup主要功能是從復雜的網頁解析和爬取HTML或XML內容,哪怕此時使用BeautifulSoup實現的是海量的網站源碼的分析工作,我們會發現,它的實現過程也非常簡單,極大地提高了分析源碼的效率。
同時,BeautifulSoup支持Python標準庫中的HTML解析器,還支持一些第三方庫的解析,如果不進行特殊的解析器安裝,Python則會使用默認的解析器。基于以上特性,BeautifulSoup已成為和Lxml一樣出色的Python解析器,為用戶靈活提供不同的網站數據爬取和解析策略。
二、基于BeautifulSoup的獨立數據爬取
1.實例分析
本實例的爬取目標是豆瓣電影票-大連城市網站中的全部電影列表,網站內容見圖1,網站地址如下:https://movie.douban.com/cinema/nowplaying/dalian/,部分網頁源代碼如圖2所示,需要說明的是,由于網站內容不斷地動態更新,因此每次運行得到的結果可能會有差異。
2.源代碼分析
我們的目標是電影列表,首先從圖2中搜索到目標位置,然后通過“soup.find_all(‘li’,class_=’list-item’)”,找到全部class_屬性為“list-item”的<li>標簽,爬取需要的電影信息。例如,item[‘data-title’]獲取<li>標簽中的指定屬性data-title(電影名)對應的value值,item[‘id’]對應屬性id(電影ID)的value值等,最后依次爬取需要的內容即可。
3.具體代碼實現
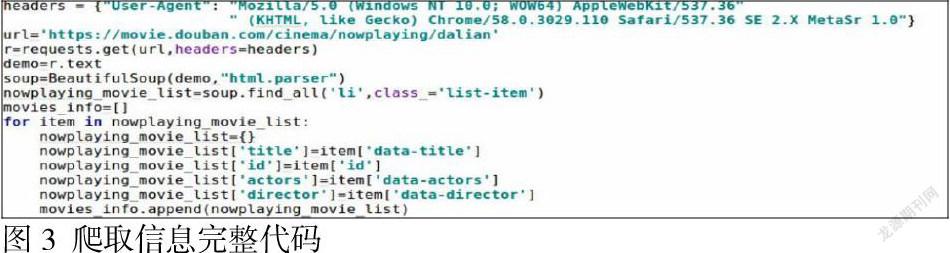
本實例實現了爬取豆瓣電影票-大連城市網站中的全部電影列表,爬取信息完整代碼如圖3所示。
4.爬取信息存儲
通過以上程序可以得到所有大連城市電影信息,緊接著可以采用不同存儲方式進行存取,以下列出了5種存儲方式:
(1)存儲于.txt文檔
使用python讀寫文本數據,需要使用open()方法,用于打開一個文件,將爬取內容寫入當前打開的文件中。注意,open()方法打開文件后,一定不要忘記關閉文件對象,即結束文件的使用時調用close()方法。具體代碼見圖4所示。
(2)存儲于.csv文件
CSV文件以純文本形式存儲表格數據(數字和文本)。純文本意味著該文件是一個字符序列,不包含二進制數字。CSV文件由任意數量的記錄組成,記錄之間以某種換行符分隔;每條記錄由字段組成,字段間的分隔符是其他字符或字符串,最常見的是逗號或制表符。使用該存儲方式之前需要import csv,實現過程具體代碼見圖5所示。
(3)存儲于.xls表格
在python中,xlwt是讀取Excel文件的一個常用擴展模塊,可以實現創建表單、寫入指定單元格、指定單元格樣式等常見功能,人為使用Excel實現的絕大部分寫入功能,都可以使用這個擴展包實現。xlwt模塊同樣需要用戶單獨安裝:pip install xlwt,使用前導入xlwt包:import xlwt,實現過程如圖6所示。
(4)存儲于.json文件
JSON作為一種輕量級的數據交換格式,可作為讀寫數據的對象使用,通常使用JSON模塊,首先需要導入JSON庫:import json。在JSON模塊中,主要涉及json.dumps()、json.load()和json.loads()方法,實現過程如圖7所示。
(5)存儲于MongoDB數據庫
MongoDB是一個介于關系數據庫和非關系數據庫之間的產品,是非關系數據庫中功能最豐富的、與關系數據庫最相近的NoSQL數據庫。使用前需要安裝MongoDB服務器端,然后安裝PyMongo模塊,該模塊是Python對Mongodb操作的接口包,它能夠實現對MongoDB的增、刪、改、查及排序等操作。由于PyMongo模塊來源于第三方,因此未包含在Python的標準庫中,需要自行安裝:pip install PyMongo,然后導入PyMongo包:import pymongo,實現過程如圖8所示。
參考文獻:
[1]奚增輝等.應用主題爬蟲的電力網絡輿情數據采集[J].西安工程大學學報, 202003).
[2]高雅婷,劉雅舉. 基于Python的網上購物數據爬取[J].現代信息科技,2020(5):16.
[3]王彥雅. 基于Python的廊坊市二手房數據爬取及分析[J].電腦知識與技術,2020(29).
[4]于學斗,柏曉鈺.基于Python的城市天氣數據爬蟲程序分析[J].辦公自動化. 2020,27(07).
作者簡介:孫愛婷(1984-),女,漢族,遼寧大連人,講師,碩士,遼寧輕工職業學院,信息工程系大數據技術專業主任,主要研究方向:大數據技術。
猜你喜歡
現代畜牧科技(2021年9期)2021-10-13 06:39:14
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
當代經濟研究(2016年5期)2016-12-01 03:12:05
現代農業(2016年5期)2016-02-28 18:42:46
出版與印刷(2016年3期)2016-02-02 01:20:11
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
華北水利水電大學學報(社會科學版)(2014年3期)2014-04-16 04:38:31
終身教育研究(2014年5期)2014-02-28 01:23:06
