基于深度學習的中長期風電發電量預測方法
2021-07-02 07:44:40朱尤成王金榮徐堅
廣東電力 2021年6期
朱尤成,王金榮,徐堅
(國電電力云南新能源開發有限公司,云南 昆明 650051)
風電的開發利用可減少溫室氣體排放,減輕環境污染,緩解當前的能源危機[1-2]。由于風電具有強隨機性和間歇性[3],風速等影響風電功率的因素隨時間呈現無規律的變化,導致風電功率難以預測[4]。而對風電功率的準確預測不僅是解決風電消納的重要手段,也會增強風電在電力市場中的競爭力。因此,準確的風電預測對于確定合理的調度計劃和確保電網安全經濟運行具有重要意義。
針對此類問題,國內外已有大量研究。從時間尺度上,可以分為超短期預測(以小時為單位,預測接下來0~4 h的發電功率),短期預測(以日為單位,預測72 h內的電力輸出),中長期預測(以月或年為單位)。其中超短期預測主要用于風電系統的實時調度,短期預測主要用于制訂電網的發電計劃,中長期預測用于安排大型檢修,而長期預測的主要作用是風電場選址評估。對于超短期預測的工作,文獻[5]提出了一種結合卷積神經網絡(convolutional neural network,CNN)和門控循環單元(gated recurrent units,GRU)網絡的超短期風電預測模型,針對時間序列進行動態時序建模,完成對風電功率的超短期預測;文獻[6]建立了一個基于離散馬爾可夫鏈的超短期風電預測模型。對于短期預測的工作[7-9],文獻[9]利用宜昌市歷史氣象數據、電力負荷數據以及日期類型數據等建立長短期記憶(long short term memories,LSTM)網絡模型,通過逐步調優試驗評估,提出適用于宜昌電力負荷預測的LSTM網絡模型方案。目前,很少有針對中長期時間尺度上的研究,一方面由于中長期風電預測應用場景偏少,僅在少量研究文獻中有所提及[10-11],另一方面我國風電場的發電量、氣象等數據通常只可追溯至前5~7年[7-9],這將導致中長期預測缺少充足的樣本[10,12-14]。文獻[15]建立了基于自適應小波神經網絡的長期風力發電預測模型。
針對目前中長期風電預測中樣本稀疏、缺乏通用特征表達框架、無法解決長期依賴時間序列的問題,本文工作如下:①使用來自不同地區4個風電場的特征數據,在研究適用于云貴高原地區風力發電預測模型的背景下,最大限度擴充模型數據集,為更好的訓練模型、增強模型魯棒性打下基礎;②提出一種基于關聯結構函數與神經網絡的特征表示與融合方法,以有效表達風電場氣象因素、地理位置等特征;③提出一種基于LSTM的中長期發電量預測模型,以有效解決模型對風電場時間序列數據反向傳播時,早期月度數據信息缺失的問題;④最后對提出的多維特征提取(feature extraction,FE)-關聯函數(copula,CO)-LSTM(FE-CO-LSTM)融合模型進行驗證。
1 風電預測模型介紹
1.1 氣象特征分析
影響風力發電量的氣象因素眾多且復雜,影響因素也各不相同。提高風電預測精度的關鍵之一便是有效提取氣象主要特征,風電預測中氣象特征主要包括:風力、氣壓、溫度、濕度。已有的氣象特征分析可以在一定程度上量化氣象因素和風力發電之間的相關性,但這些基于線性相關系數的方法在實際情況下效果不佳,因為大多數氣象因素以非線性方式與風力發電相關。我們使用基于關聯結構的方法來表示氣象變量與風力發電之間的非線性關系,以提取關鍵的氣象因素,進行后續的中長期預測建模。
令連續隨機變量X和Y分別表示氣象數據與歷史風電功率,其邊際分布為F(x)和G(y),并且相應的關聯結構函數為C(u,v),其中u代表邊際分布F(x),v代表邊際分布G(y)。Kendall等級相關系數τ的定義為
(1)
根據Spearman等級相關系數ρs的定義[16],使用Copula理論來計算ρs,
(2)
式中Ι=[0,1] 。上尾部相關系數λup與下尾部相關系數λlo的定義如下:
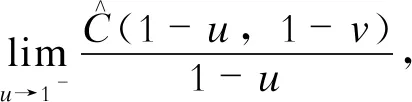
(3)
(4)
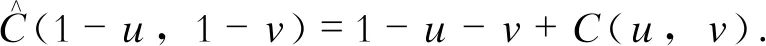
(5)
Kendall等級相關系數和Spearman等級相關系數反映了隨機變量X和Y的一致性程度,并且在嚴格單調變換之后保持不變。它們的大小與X和Y的邊際分布無關,這表明與線性相關系數相比,非線性相關系數的應用范圍將會更廣。尾部相關系數測量隨機變量X和Y同時增加或減少的概率。
在氣象特征分析模型中,使用核密度估計(kernel density estimation)方法評估氣象數據與歷史風電功率的邊際分布〔對應上文中的F(x)和G(y)〕,使用關聯結構函數分別計算上述4種氣象數據與歷史風電功率的相關性,將其結果作為各氣象特征在神經網絡特征融合模型中的初始權重。具體步驟為:①使用關聯結構函數建立風速和風電功率的聯合分布模型,并采用最大似然估計法(maximum likelihood estimation,MLE)來估計模型的參數;②計算關聯結構函數的Kendall和Spearman等級相關系數;③計算風速與風電功率的尾部相關特征,根據4種氣象特征分別和風電功率的尾部相關系數,確定特征在神經網絡模型中的初始權重。
1.2 基于多層感知機的多特征的融合表示
影響風電發電量的因素是多方向性的,機組在正常運行狀態由于受到天氣和人為因素的影響,會使得實際發電量與理論相比存在差別,因此本文將具體分析影響機組發電量的主要因素,包括風能潛力、氣溫、氣壓信息、空氣濕度、日期和海拔。其中使用有效風能密度、風能大小和空氣密度ρ表示風能潛力特征,定義有效風能密度
(6)
式中:N為各等級風速出現的總次數;vi為i等級的風速;Ni為等級風速vi出現的次數。
空氣的濕度可以用空氣中所含水蒸汽的密度,即單位體積的空氣中所含水蒸汽的質量來表示。由于直接測量空氣中水蒸汽的密度比較困難,而水蒸汽的壓強隨水蒸汽密度的增大而增大,所以通常用空氣中水蒸汽的壓強來表示空氣的濕度。令E為水氣壓,定義相對濕度
(7)
式中Ew為純水平液面飽和水氣壓。Ew的計算公式為
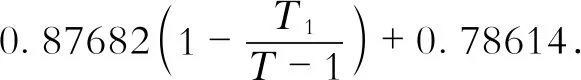
(8)
式中:T為絕對溫度;T1為水的三相點絕對溫度。
氣溫為風電場全年的氣溫統計數據,海拔數據是風電場建設處海拔高度,二者均為統計數據。
模型的核心思想是使用每日的風力信息、氣溫信息、氣壓信息、空氣濕度和風電場的海拔信息,預測月度和年度發電量。模型具體實現步驟為:
a)將采集自氣象站和風電場區域的氣象信息等多維日度數據進行嵌入表示,構造日度特征向量。
b)通過神經網絡以月為單位將日度特征向量表示為月度特征向量,融合網絡對日度特征集融合過程為
(9)
式中:ci,P為特征P的月度向量表示,i表示月份;wj,P為特征P的日度向量表示,j為當月日期數;D為當月的總天數;αij為神經網絡中日度特征向量的權重向量,其中4種氣象特征初始權重由1.1節計算得到的相關系數表示。
c)對多維月度特征進行向量表示,表示過程如圖1所示。其中:風能潛力特征由有效風能密度、風能大小和空氣密度表示;空氣濕度特征由空氣絕對濕度表示;月度氣壓特征、氣溫與海拔特征則使用當地當時的統計信息。多種月度特征長度不一、形式差異較大,因此首先將其表示為可變長度的低維向量。
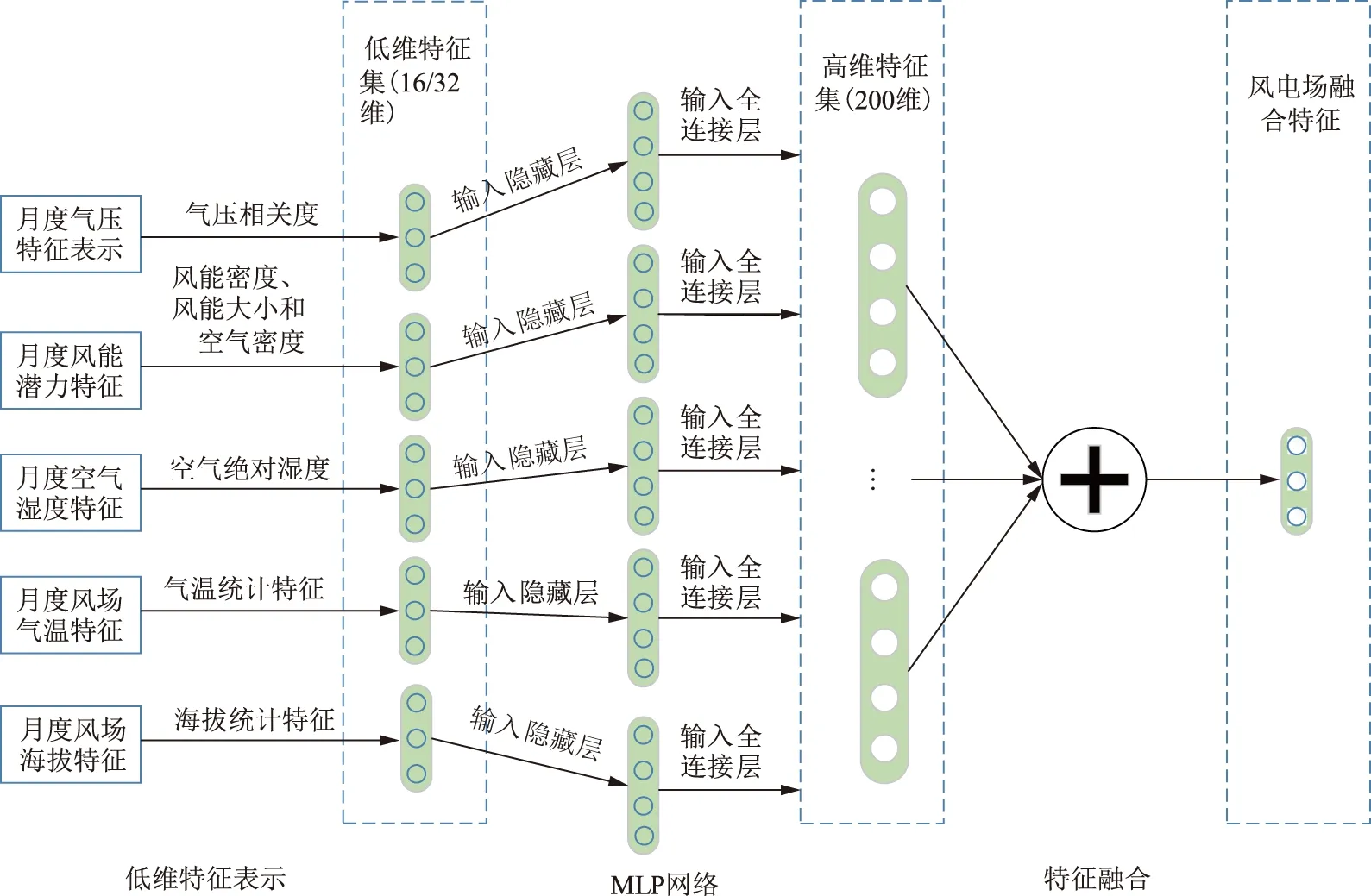
圖1 風電場特征融合模型圖Fig.1 The framework of wind farm feature fusion model
d)初始化多層感知機(multilayer perceptron,MLP)網絡,包含1個輸入層、1個隱藏層和1個輸出層,均為全連接網絡。MLP網絡接受低維月度特征向量,輸出結構統一的高維特征向量。然后將各類高維月度特征向量進行拼接,構成風電場當月融合特征向量表達,為后續LSTM模型的中長期發電量預測做準備。
1.2 基于LSTM的預測模型
LSTM神經網絡具有長期記憶功能,可以有效利用有限數據樣本的長期依賴性[17-18]。它還可以解決遞歸神經網絡(recurrent neural network,RNN)訓練過程中梯度消失導致失去感知遠距離網絡單元能力的問題。主要思想是使用特殊的神經元長時間存儲和傳輸信息,以獲得永久性記憶、捕獲長期依賴性、減緩時間序列中信息損失的速度以及增加深度計算的優勢。LSTM神經網絡可以深入評估有限數據樣本中的長期依存關系和趨勢關系,適用于數據樣本有限的中長期風力發電預測。
LSTM網絡結構圖如圖2所示。
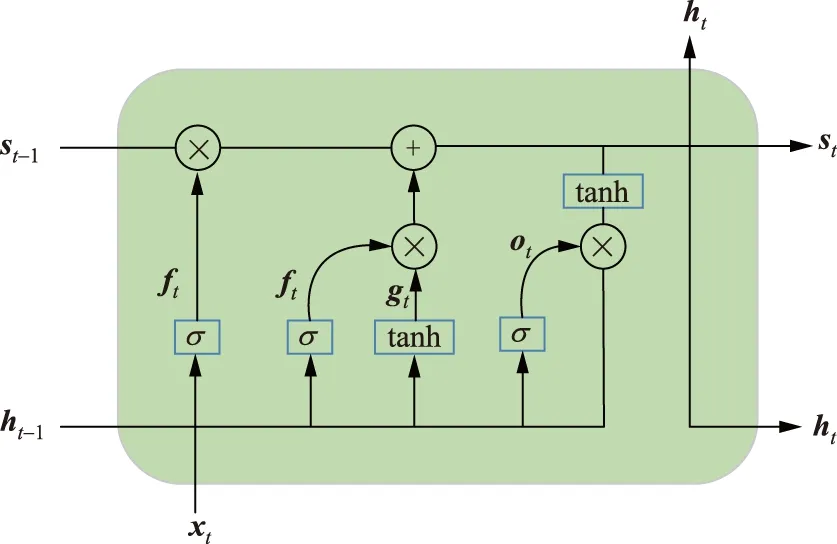
圖2 LSTM網絡模型Fig.2 Long and short term memory network model
圖2中:
(10)
LSTM預測模型基于風電月度特征融合向量,進行月度風電發電量預測。這一過程可以表示為
[h(t+1)h(t+2) …h(t+12)]=FLSTM(h(t),
h(t-1),…,h(t-n),x(t),
x(t-1),…,x(t-n)).
(11)
式中:h(t+1)為當前時刻的預測結果;[h(t+1)h(t+2) …h(t+12)]為當前12個月發電量的預測向量;h(t),h(t-1),…,h(t-n)為先前時刻的月度發電量預測結果;x(t),x(t-1),…,x(t-n)為先前時刻的輸入,即月度特征融合向量;n為當前已輸入的網絡節點數。
2 實驗與結果分析
本文首先對風電場原始數據進行日度特征提取,進而對整個網絡模型(包括風電場月度特征融合模型和發電量預測模型)進行訓練,最終得到訓練好的預測模型。具體流程如圖3所示。
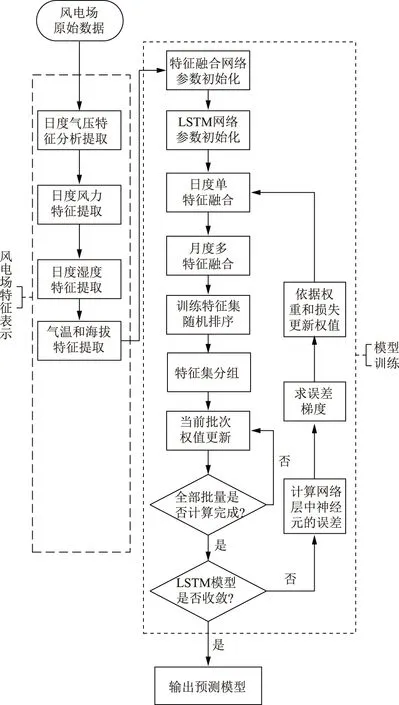
圖3 FE-CO-LSTM模型流程Fig.3 Flow chart of the FE-CO-LSTM model
2.1 數據集與對比模型
考慮到中長期風電預測問題缺乏大樣本集,從而導致模型預測精度較低,本文收集了我國云南和貴州共計4個風電場5~7年的發電歷史記錄,以及相應時間段內該地區的風力、氣壓、濕度、氣溫和海拔信息,數據集具體統計情況見表1。其中,將數據中的月度信息作為網絡中時間序列的一個節點輸入,由表1可見,數據集中收集的風電場數據的時間跨度不同,因此各數據集下網絡的長度并不相同。云南風電場1與貴州風電場1為高原地區風電場,其數據集具有完整風力、氣壓、氣溫、濕度、海拔數據。云南風場2和貴州風場2數據集分別有濕度數據和風力數據的缺失,在模型特征融合時仍使用相同方法。
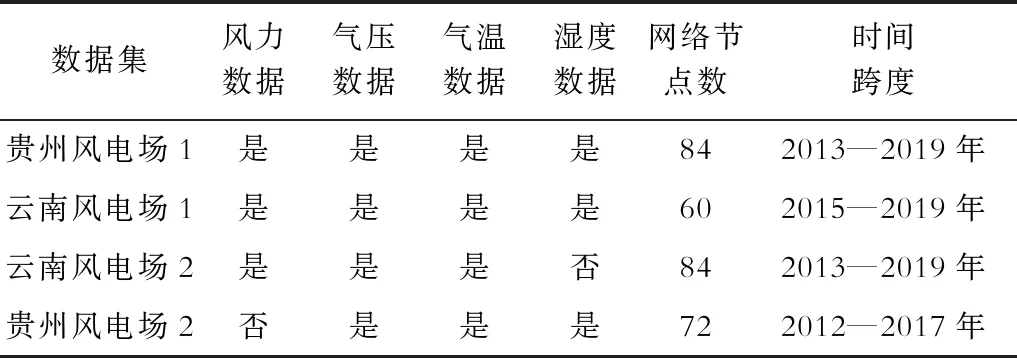
表1 4個風電場數據集信息Tab.1 Data set information of four wind farms
為驗證模型的有效性,本文選取了基于支持向量機(support vector machines,SVM)風電預測方法[19]、基于CNN的風電預測方法[20]、LSTM(CO)方法(僅使用氣象特征分析和LSTM的網絡模型)與LSTM(FE)方法[21](基于特征融合方法與LSTM的網絡模型)作為對比。
2.2 實驗與結果分析
為評估中長期風電發電量預測模型的準確性,使用2個指標作為評估標準:一是平均絕對百分比誤差(mean absolute percentage error,MAPE)KMAPE用于評估實時誤差,另一個是均方根百分比誤差(root mean squared percentage error,RMSPE)KRMSPE用于評估預測期間的總體誤差。2個指標的計算式為:
(12)
(13)
式(12)、(13)中:W′i為每月發電量的預測值;Wi為每月的真實發電量;m為預測的總月份數。
在4個風電場的數據集中,將最后一年的數據作為測試集,其余作為訓練集。模型對測試集的預測結果如圖4所示,預測誤差統計見表2。
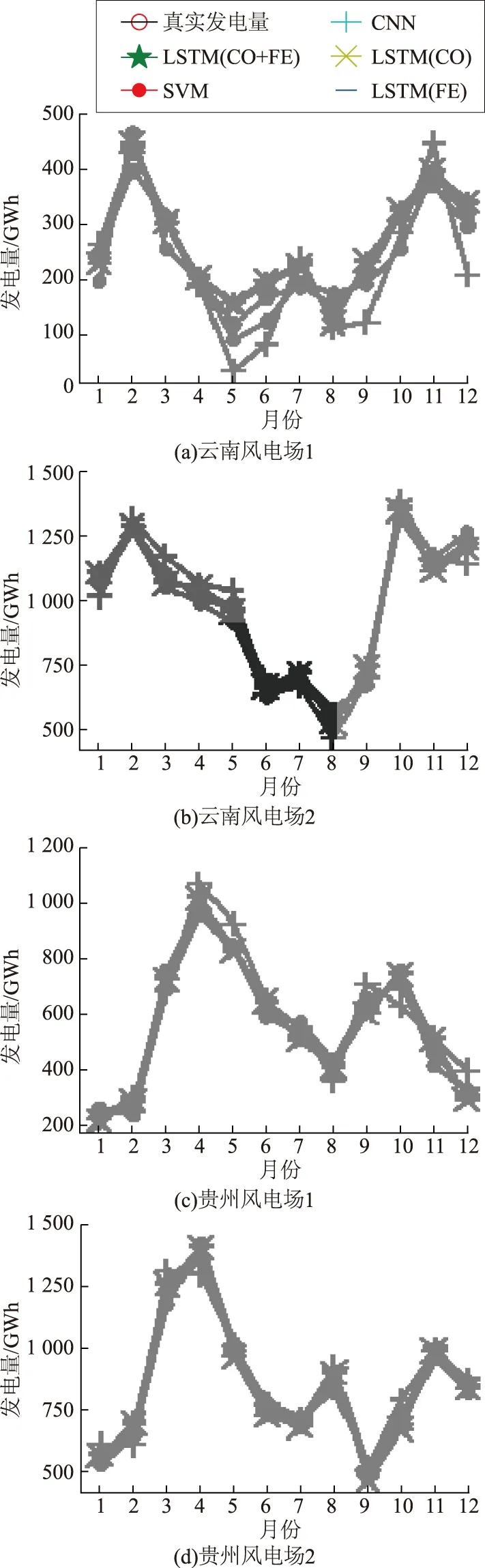
圖4 5種預測模型的實驗對比Fig.4 Experimental comparisons of 5 prediction models
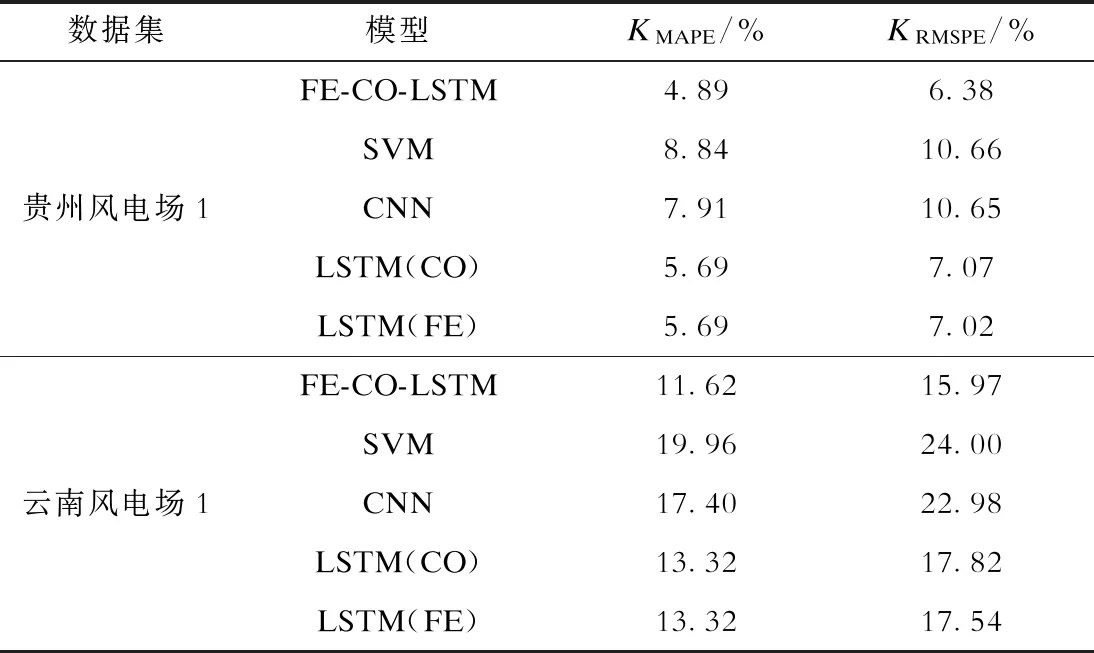
表2 FE-CO-LSTM模型與其他模型預測誤差統計Tab.2 Prediction error statistics of the FE-CO-LSTM model and other models
表2列出了貴州風電場1、云南風電場1的實驗結果,進一步證明了本文方法的有效性。通過觀察可知:①FE-CO-LSTM、LSTM(CO)和LSTM(FE)這3種基于LSTM的方法相比SVM、CNN方法大幅減小了誤差;②CNN模型在云南更高海拔地區的風電場1數據集上表現出比SVM模型更小的誤差,說明對于高原地區高海拔、低氣壓、風密度低且風向變化頻繁的復雜數據,神經網絡模型可以學習到更好的特征表達;③LSTM(CO)、LSTM(FE)方法的誤差與FE-CO-LSTM方法相比均有所上升,這說明氣壓-發電量相關度表示與多維度特征融合在LSTM模型中起到提高模型精度的作用。
3 結論
本文對云貴高原地區風力發電量的中長期預測問題進行了研究,提出了一種基于LSTM的結合多維特征模型與關聯結構函數的風電發電量預測模型,并且在4個風電場數據集上進行了驗證,結論如下:
a)基于LSTM的方法在所有驗證方法中表現最好,說明LSTM模型更適用于中長期風電預測,可以有效解決長時依賴,其中本文提出的FE-CO-LSTM模型體現出了最好的預測性能。
b)在處理高原地區高海拔、低氣壓、風密度低且風向變化頻繁的復雜風電數據時,基于深度學習的方法表現出比SVM模型更強的學習能力。
c)對于稀疏的風電數據,進行氣壓-發電相關度分析與特征融合工作可以有效提升模型預測性能。
因此,后續工作可以進一步探索云貴高原地區的氣象數據與風力發電的相關性,挖掘更多數據特征,研究風電特征融合表示。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
