基于機器學習的UGC數據分析模型及應用實踐
2021-06-24 07:24:48王濤周藝雯
微型電腦應用 2021年6期
王濤, 周藝雯
(同濟大學浙江學院 電子與信息工程系, 浙江 嘉興 314000)
0 引言
科技技術的快速發展以及市場的快速擴張,使得企業間競爭愈發猛烈。以往,人們依靠路邊發傳單、電視放廣告等作為營銷策略,現如今,企業營銷策略不斷改進,精準營銷依靠分析受眾特征,優化產品策略贏得企業經營者的青睞。UGC(User Generated Content)在線評論,是新媒體平臺人們對商品數據的反饋心得。在線評論能反映用戶對當前購買商品質量的態度[1]。電商評論網頁上,購買過產品的消費者對產品進行評價,這些評價對產品口碑起決定性作用。在產品服務的過程中,用戶不僅僅是接受者,也是產品消費過程中的信息提供者。作為商品的銷售方,如何分析用戶產生的數據,例如用戶對產品的評論數據等,在此基礎上,商家可以修正不足,改進服務,提升用戶滿意度。故而,基于在線評論的文本挖掘吻合供需雙方需求,受到越來越多用戶的青睞。本文通過采集分析攜程網民宿數據,建立基于UGC數據分析模型。數據模型分為爬蟲模塊和分析模塊。爬蟲模塊采集房源數據和對應評論數據,分析模塊負責對評論數據集的數據清洗、分詞、特征提取、貝葉斯分類和情感分析。
1 爬蟲模塊
網絡爬蟲向目標網站發送請求的過程是爬蟲程序模擬瀏覽器發送請求的過程[2]。發送http請求過程[3]如下。
(1) 瀏覽器發送Request請求,獲取目標網址中的html文件數據代碼,服務器把Response發送給瀏覽器;
(2) 瀏覽器解析收到的數據,引用JS、CSS、Images源文件,瀏覽器再次發送請求,獲取過程中這些代碼用到的文件,完成渲染;
(3) 若請求失敗則對應欄目顯示錯誤;
(4) 當前數據接收成功后,瀏覽器會根據當前的HTML代碼,渲染前端頁面。
互聯網中,不是所有網頁都可任意爬取。Robots 協議是網絡爬蟲中網站限制爬蟲的協議[4]。協議允許下,為高效準確爬取數據,反爬蟲技術應運而生[5]:(1) 基于Headers字段。網站檢查Headers字段User-Agent,如圖1所示。

圖1 用戶字段
網站基于用戶瀏覽器版本、瀏覽器內核及操作系統版本渲染網頁。爬蟲過程,修改User-Agent字段,欺騙服務器,繞過檢查,完成響應。(2)基于模擬用戶行為。當前主流網站通過檢測用戶訪問網站的頻率來判斷訪問狀況。若某賬戶短時間頻繁訪問,會被網站要求驗證碼訪問,或頁面收到響應狀態碼“429 Too Many Requests”,甚至被網站拉入“黑名單”。為規避上述情況,一般通過RANDOM_DELAY函數設置隨機延時范圍,或使用IP代理。(3)基于動態頁面。一些網站的動態頁面通過AJAX或JS請求生成數據,不可直接爬取,這便需要基于動態頁面的反爬蟲策略。如果能找到AJAX請求,分析請求中的隱含信息,可以間接獲取目標數據。當出現無法直接獲取AJAX請求時,可嘗試使用框架selenium+ phantomjs[6]。
本文在比對了市面上同類型民宿租房網站,包括攜程、去哪兒、飛豬、途牛、愛彼迎等民宿租房網站后(alexa 網站2020年5月數據),選擇攜程網作為目標網站。本文的爬蟲程序步驟如下。
(1) URL獲取。依照行政區獲取房源列表界面的各個行政區下的房源URL。
(2) 房源頁面下載。獲取房源頁面的詳細信息和對應房源評論數據集。
(3) 網頁解析及結構化。解析網頁源碼得到結構化數據。
(4) URL管理。判斷URL是否爬取。
(5) 數據入庫。存儲結構化的房源數據。
本文最終采集房源數據10 767條,評論數據102 550條,其中房源數據項包括:名稱、尺寸、類型、分數、評論數目、房源戶型、床數、臨近地點以及熱門屬性,如圖2所示。

圖2 房源數據(部分)
通過初步分析發現,可能是受當前評分刷單風氣影響,評分不能較好反映該欄目對應房源的評分。房源數據綜合評分項評分中滿分占比高達85.23%,選擇評分數據作為參考意見時,容易出現偏離真相的情況[7]。針對這種情況,本文以評論數據為基礎,拆解評論數據,為評論數據重新打分。
2 數據分析模塊
文本數據挖掘(Text Mining)是指從文本數據中抽取有價值的信息和知識的計算機處理技術。文本數據挖掘通過高效獲取含有隱藏價值的信息,指導人們的理論基礎和社會實踐。本文文本挖掘過程如圖3所示。
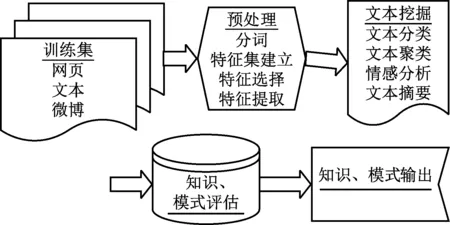
圖3 文本挖掘流程
(1) 訓練集獲取。訓練集一般由經過預先訓練的特征向量組成,每條文本有一個類別編號。本文訓練集的編號即為房源的評分分值。
(2) 數據預處理。文本數據往往不能直接進行文本挖掘,對臟數據進行清理、中文分詞、進行相似度度量并建立特征集并提取是正式進行文本挖掘前必不可少的步驟。
(3) 文本挖掘。本文通過評論數據進行房源數據重打分,打分區間位于0.0-1.0,精度為0.1。這實質上是一種文本聚類(Cluster)分析,在綜合比較后本文選擇樸素貝葉斯模型進行情感分析。
(4) 模式輸出。為便于直觀展現,本文選擇python的Matplotlib進行圖表可視化。
本文程序框圖如圖4所示。
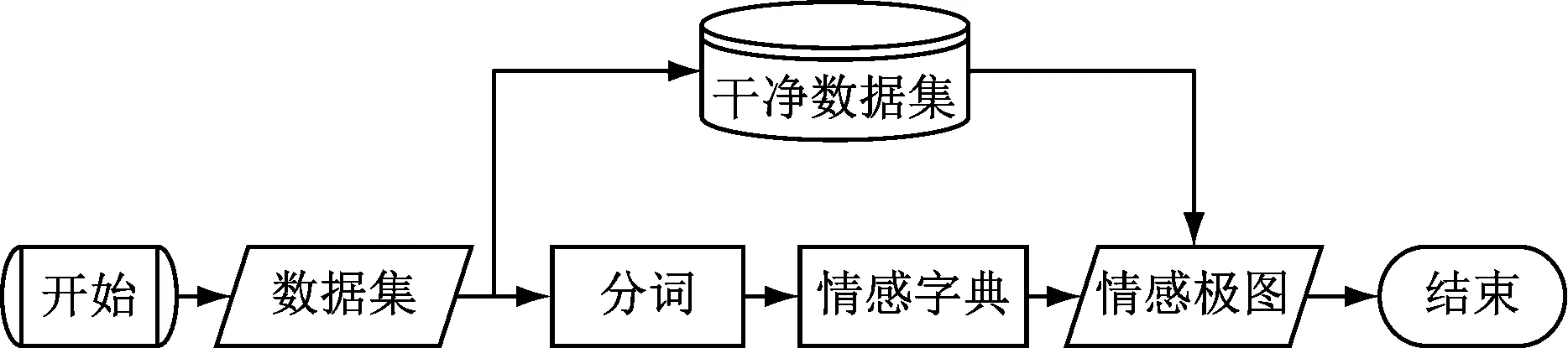
圖4 程序框圖
2.1 數據預處理
數據預處理是文本挖掘中承上啟下的環節,預處理清除網絡爬蟲過程中的臟數據,將文本分詞。預處理結果將直接影響后續特征提取及分類器分類結果。
2.1.1 數據清洗
電商評論的數據質量經常參差不齊,有些數據價值密度較低,有些刷單數據會影響統計結果,使最終分析結果不真實。數據清洗的目標:(1) 文本去重,減少刷單、用戶操作失誤、爬取重復評論的評論文本。(2) 壓縮去詞,刪除將評論中連續重復表達的詞匯。(3) 格式錯誤,如對房源尺寸數據“20 m2”,將其改成“20”。
2.1.2 中文分詞
對人類,根據語境判別句子含義是自然而然的,但對計算機十分困難。英文文本存在含獨立語義的最小語言單位[8],通過空格就可分隔,但對無空格分隔的中文分詞,將完整的中文句子分解成多個具有語義的詞匯,是中文自然語言處理中基礎但重要的環節。
自然語言建模是自然語言問題轉化成機器學習問題的關鍵,建模的目的是將單詞向量化,將詞語映射成實數向量[9]。2013年,谷歌研究團隊提出從大量文本語料庫中學習含有特定語義信息的低維度詞向量無監督學習方式語義模型[10],Word2vec詞向量研究模型。Word2vec利用神經網絡,將獨立詞語轉化為詞向量,統計計算向量與向量間空間距離,實現非結構型文本轉化為向量空間的向量運算。Word2vec模型包含兩種重要模型:CBOW(Continuous Bag-if-Words)模型和Skip-gram (Continuous Skip-gram)模型,這種方法訓練出來的模型,訓練步驟被相對簡化、合成方式被優化,同時詞向量質量較高,還降低了運算復雜度[11]。
假設已知輸入詞語W(t),預測輸入詞語W(t)周圍上下文2n個詞語的模型稱為Skip-gram 模型[12]。如果已知w(t)的上下文wct,存在未知詞語w(t),預測詞語w(t)的模型稱為 CBOW 模型,如圖5所示。

圖5 模型示例
分別為Skip-gram模型和CBOW模型的模型示例,此時n=2,模型包含三個層級:輸入層、投影層、輸出層。
上下文的定義如式(1)。
wt=wt-n,…,wt-1,wt+1,…,wt+n
(1)
式中,c表示詞語wt的前后詞語數量。Skip-gram模型和CBOW模型的優化目標函數分別為式(2)、式(3)。
(2)
(3)
式中,C表示包含所有詞語的語料庫;k表示當前詞語w(t)的窗口大小。
以Skip-gram模型為例,假設語料庫中句子“農業現代化受到限制”,選定詞語“受到”,上下文:農業、現代化、限制。要使得條件概率值達到最大,給定w(t)前提下,使得單詞t距離2n的上下文概率達到最大:P(農業|受到)、P(現代化|受到)、P(限制|受到)[13]。
當前的分詞工具一般基于Word2vec,目前較為成熟的開源中文分詞有LTP、Jieba、THULAC、NLPIR等[14]。本文通過LTP分詞工具實現分詞,LTP提供了以下模型文件,如表1所示。

表1 LTP模型文件
基于LTP分詞提供的cws.model模型文件,實現分句和詞性標注,部分LTP代碼如下。
for sentence in cont:
if sentence.strip() != ’’:
words= segmentor.segment(sentence)
for word in words:
f1.write(word+’ ’)
f1.write(’ ’)
word1=segmentor.segment(sentence)
postags = postagger.postag(word1)
for word,tag in zip(word1,postags):
if (tag == ’n’ ):
f.write(word+’ ’)
f.write(’ ’)
else:continue
2.2 基于貝葉斯分類的情感分析
貝葉斯分類是一類分類算法的總稱,這類算法均以貝葉斯定理為基礎,故統稱為貝葉斯分類。而樸素貝葉斯分類是貝葉斯分類中最簡單,也是常見的一種分類方法。樸素貝葉斯的思想基礎是這樣的:對于給出的待分類項,求解在此項出現的條件下各個類別出現的概率,哪個最大,就認為此待分類項屬于哪個類別。本文根據類別于詞之間的聯合概率在已知條件概率和先驗概率的基礎上,去計算其后驗概率的分類。樸素貝葉斯算法的前提條件是類別具有獨立性,一個類別的屬性值對于給定類別的影響應該獨立于該類別的其他屬性值。通過分類來計算一組給定樣本屬于特定類別的概率[15]。本文分類算法的具體過程描述如下。
(1) 對數據樣本進行標記;
(2) 對不同類別的樣本數據進行中文分詞和降噪;
(3) 將詞條組合成特征組并分析詞條頻率信息;
(4) 根據詞條頻率信息來計算其先驗概率;
(5) 對樣本數據進行中文分詞及降噪形成樣本特征組;
(6) 將詞條的先驗概率代入公式計算其后驗概率,所屬的文本類別就是其中最大的概率。
本文通過上述分類算法,將數據文本分成8個主題,價格、特色、體驗、餐飲、服務、環境、設施和交通,去掉無關的數據后,然后將此8個主題文本各分成五類(按照滿意度降序排列),總共四十個類別。“價格”主題評分如表2所示。
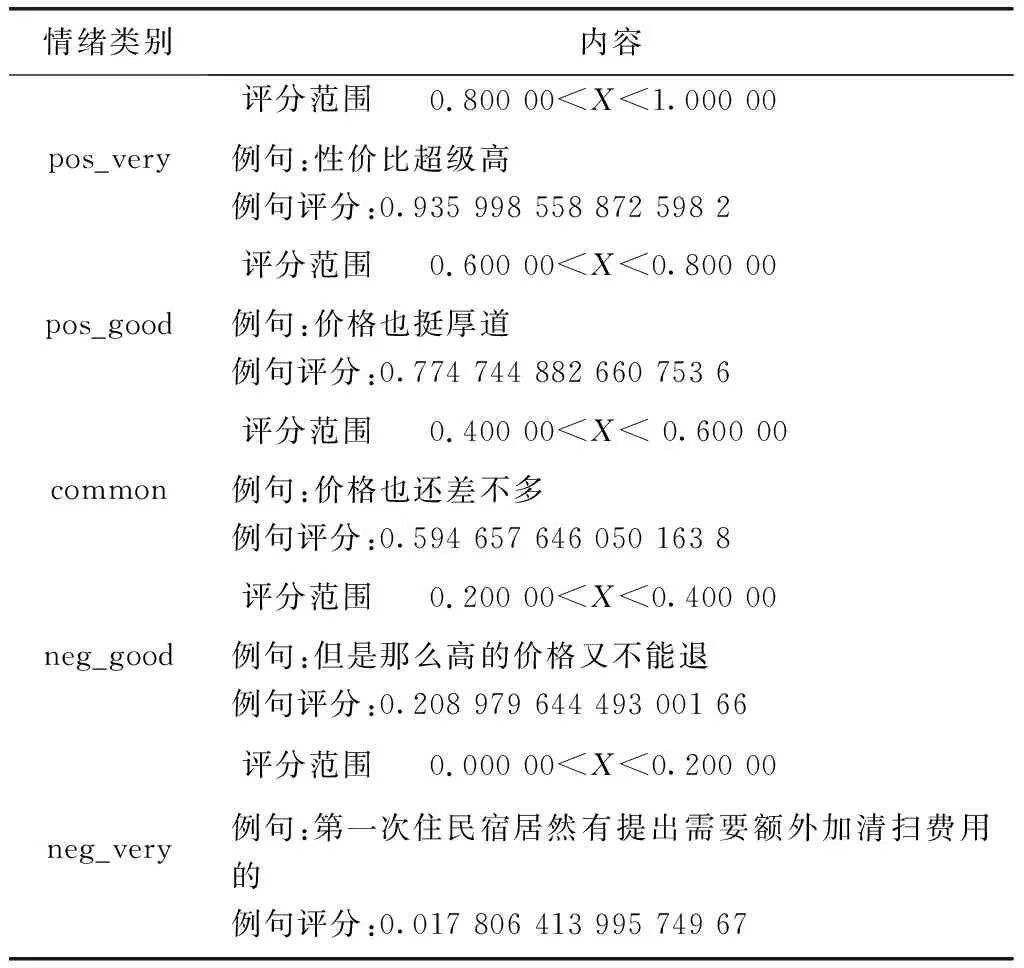
表2 模型評分“價格”主題
為便于理解情感趨勢,繪制基于評論評分的可視化圖表,將評論數據與初始房源評分數據進行對比就可以發現,初始房源評分數據以好評居多,很難從中得到更多有用信息,但是通過評論數據,綜合分析,就可以對當前地區的民宿經營狀況提出以下方面建議。
(1) 提高民宿的餐飲尤其是早餐的服務質量
餐飲-情感字典如圖6所示。
由圖6可知,排前五名的詞匯為:早餐、味道、菜、早飯、飯, 這表示住客對早餐的關注度較高,提示經營者如果提高早餐質量,可以調高服務評價。
(2) 提高民宿的硬件設施和日常維護
設施可視化如圖7所示。
圖7 設施可視化
總體來說,消費者對民宿的硬件設施滿意度不高,給出極低評價的不占少數。通過觀察情感詞典,提及頻率較高的硬件設施相關的詞語依次是房間、床、衛生間、空調等,民宿的經營者可以著重提高這些設施的檔次,同時做好即有基礎硬件設施的維護工作。
(3) 優化民宿的服務體系
服務可視化如圖8所示。

圖8 服務可視化
雖然有一部分用戶相當滿意民宿的服務,但多數顧客將評分置于0.6—0.8,這意味著民宿的服務勉強使其滿意,此外抱有消極態度的用戶不在少數。初步猜測這是有別于酒店擁有一套完整服務體系,民宿雖然具有自由神秘的特點,但也使得房東對于租客的態度比較自由隨性。酒店具有一套成熟的服務體系來提供基本的前臺接待及住房導引服務。而民宿經營者通過網絡來履行服務責任,大多不與用戶面對面聯系:交付費用、鑰匙告知、住房期間問題解決等。這意味著用戶一旦出現緊急問題而無法得到及時滿意的解決,如空調制冷、熱水器不熱等問題。這就需要經營者在基礎設施上下功夫,提高服務質量。
3 總結
隨著互聯網經濟和電子商務的急速發展,產生了越來越多的融合數據,更多的傳統行業將電子商務納入到其他業務體系中,雙十一的交易金額也在逐年增長。這些融合數據的價值挖掘將在未來的發展中具有廣大的前景和實用價值,為產品的發展和生產決策提供重要的參考依據。本文通過爬取了攜程網民宿房源數據和在線評論作為原始的數據集,應用傳統的文本分析方法,分析房源數據和評論數據的特點,應用貝葉斯分類完成了基于獨立主題的情感分析。根據爬取房源數據的特點,在以下方面展開了研究:(1) 房源數據爬蟲,通過分析房源網頁結構,分析待爬節點,解析網頁。(2) 中文文本預處理,中文文本降噪、去重和分詞。(3) 8類主題評論文本劃分,通過Word2vec原理,建立8類主題情感字典,基于8類情感字典完成評論文本劃分。(4) 對房源數據進行樸素貝葉斯模型情感分析,通過數據可視化得出直觀結果。
針對本文研究,只使用了樸素貝葉斯算法對評論語料進行分類分析,如果可以通過比較更多其他模型算法對其進行分析,可能會有更好的結論。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
