汽車關門聲品質預測的MSA-SVR方法研究
2021-06-16 02:15:06黃澤好陳華語鄒艾宏陳寶
噪聲與振動控制 2021年3期
黃澤好,陳華語,鄒艾宏,3,陳寶
(1.重慶理工大學 汽車零部件先進制造技術教育部重點實驗室,重慶 400054;2.重慶理工大學 車輛工程學院,重慶 400054;3.重慶金康賽力斯新能源汽車設計院有限公司,重慶 401120)
隨著汽車常規性能的提高,其關門聲品質也逐漸受到人們重視。汽車關門聲品質的優劣直接影響著消費者購車時的決策,因此研究汽車關門聲品質具有現實意義。汽車關門聲品質研究內容一般包括3個方面:(1)新的關門聲品質預測模型研究,加強主觀評價與客觀評價的相關性,為汽車開發前期提供有效的預測手段[1-2];劉寧寧等[3]建立了基于小波包分解(WPD)和經驗模態分解(EMD)的聲品質評價模型,并驗證了該模型可以準確地預測響度和尖銳度等客觀參數。(2)聲品質新客觀評價參數研究,使客觀評價更加真實有效[4]。趙麗路等[5]基于Hilbert-Huang變換,研究提出新的聲品質評價參數—SMHHT,并證明該參數與主觀評價結果相關性較高,能更準確地評價汽車關門聲品質。藺磊等[6]通過分析汽車關門時尖銳度隨時間的變化曲線,提出了與主觀偏好值相關性更高的尖銳度溢值作為關門聲品質的客觀評價參數。(3)汽車關門聲品質主觀評價體系研究,分析主觀評價值與客觀參量間的相關性,以提高評價效率[7-8]。其中對于預測模型的研究主要是分析客觀參量與主觀參量的相關性,而忽略了各客觀參量間的相關性。因此,本文針對這一問題提出建立基于多元統計分析-支持向量回歸方法的汽車關門聲品質主觀偏好性預測模型。首先利用因子分析與聚類分析方法得出各客觀參量間的相關關系,再根據主觀偏好值與客觀參量的相關性提取出主要客觀參量,運用支持向量回歸方法對汽車關門聲品質偏好值進行預測,驗證該方法對汽車關門聲品質預測的有效性。
1 關門聲樣本采集
在半消聲室內,利用人工頭、速度傳感器、聲級校準器等設備,對14輛不同等級乘用車進行等速關門工況下的聲樣本采集。為保證采樣數據的一致性,設置采樣頻率為44 100 Hz,采樣時長為10 s,每組聲樣本重復采集3次,如圖1所示。并將時域采集信號導入HEAD-Artemis軟件,剔除聲樣本中受干擾或采樣工況不穩定的信號。根據樣本聲時長一致性原則,將保留下的聲樣本長度剪輯為3 s。

圖1 試驗數據采集
2 主觀評價試驗
2.1 試驗準備及評價過程
根據流程圖2進行主觀評價試驗,主觀評價試驗選擇對評價者無需經驗要求的成對比較法。主觀評價者為20名(評價者P1~P20)車輛工程專業在讀研究生,平均年齡25歲,無聽力障礙,且均具有相關噪聲與振動知識基礎。在聽音前對評價主體進行培訓,使其了解相關評價內容及方法。

圖2 關門聲品質主觀評價流程
2.2 試驗數據處理
為提高試驗數據可靠性和有效性,采用交換樣本對順序誤判法、相同聲樣本評價誤判法和三角循環誤判法對結果進行誤判分析。計權一致性系數計算公式如式(1)所示:

式中:ζ為計權一致性系數,Ci為第i種誤判方法實際產生的誤判率,Ei為第i種誤判分析方法可能產生的誤判次數。
由式(1)計算得出各評價主體計權一致性系數如表1。

表1 計權一致性系數
根據計權一致性原則,ζ在0.7以上時認為評價結果一致性較好,且最后約10%的評價結果應予以剔除[9]。因此,剔除表1中評價主體P8和P11的評價結果,以確保試驗數據的可靠性和有效性。
2.3 主觀評價試驗結果
以評價主體對樣本的選擇次數表征主觀偏好性得分,并對18名合格評價主體總分值進行算術平均得到14個聲樣本最終偏好性分值如表2所示。
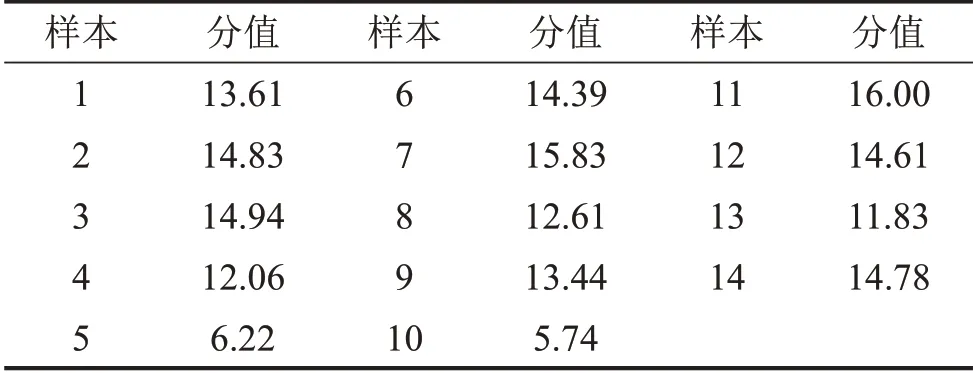
表2 樣本主觀偏好性得分值
以直方圖表示各聲樣本主觀偏好性得分如圖3所示。其中,樣本11得分最高,樣本10得分最低,且由圖4、圖5兩個樣本時頻圖對比可知,樣本11在高頻時能量較小且能量衰減相對較快,持續時間較短。

圖3 各聲樣本主觀偏好性得分對比
3 客觀參量計算
心理聲學參數可以定量分析不同評價主體聽覺感受的差異。應用ArtemiS軟件計算得到14個聲樣本的響度、粗糙度、尖銳度、A計權聲壓級、抖動度以及語言清晰度,如表3所示。可以看出,各樣本客觀參量值均有不同,無法預知各客觀參量間內在聯系且單一客觀量無法準確表征樣本聲品質。
4 客觀參量多元統計分析
利用多元統計方法對客觀參量進行分析提取[10-11]。首先采用因子分析法與聚類分析法對各客觀參量間相關性進行分析,再通過相關性分析得出主觀偏好值與客觀參量間相關系數,從而提取出與主觀偏好性相關系數最高的客觀參量。
4.1 因子分析
因子分析可以從多參量中提取出少數客觀參量來表征與主觀偏好性之間的關系,且這幾個參量能夠反映主觀偏好性的大部分信息。在因子分析法中,原始數據可用矩陣X表示:

則因子模型可表示為X=AF+B,即(3)式:

模型中,n≤m,向量X表示原始觀測向量,向量F(f1,f2,f3,…,fn)是X的公共因子,即各個原始觀測變量表達式中共同出現的因子,是相互獨立的理論變量。公共因子的具體含義應結合實際研究問題來界定。αmn稱為因子載荷,是xm與fn的協方差,表示第m個原有變量在第n個因子上的負荷或權重;βm為特殊因子,表示原始變量無法被公共因子解釋的部分。采用SPSS數據分析軟件對客觀參量進行因子分析,分析結果如表4所示。

表3 客觀參量計算結果

表4 因子分析結果
表4的因子分析結果表明,前3個成分對于6個客觀參量(響度、尖銳度、粗糙度、A計權聲壓級、抖動度、語言清晰度)的解釋率已高達92.910%,符合累積貢獻率高于85%時可以代表原始信息量的原則[12],說明3個因子可很好體現原始參量的大部分特征,可只提取3個因子用于汽車關門聲品質偏好性預測。

圖4 樣本10時頻圖

圖5 樣本11時頻圖
4.2 聚類分析
聚類分析主要根據數據間的相似性對數據進行分類。本文采用層次聚類法中的最短距離聚類法對客觀參量進行聚類分析。設有i個樣本,每個樣本有j個參量值,原始數據可用如式(4)矩陣Y表示。

其中:yij表示第i個樣本的第j個參量的觀測值。
將原矩陣元素上下非對角元素中找出,分別定義為Gp和Gq并歸為一新類Gr,然后按式(5)和式(6)計算原來各類Gr與任一新類Gk之間的距離:

這樣就得到一個新的(m-1)階的距離矩陣;再從新的距離矩陣中選出最小者dij,把Gi和Gj歸并成新類,計算各類與新類的距離,直至各分類對象被歸為一類[12]。利用SPSS軟件對客觀參量進行聚類分析,結果如圖6所示。

圖6 聚類分析結果
圖6中橫坐標為各類間距離。結合因子分析和聚類分析結果可將客觀參量分為三類:第一類包含粗糙度、抖動度和尖銳度;第二類包含響度;第三類包含A計權聲壓級與語言清晰度。
4.3 相關性分析
將表2中主觀偏好性試驗值與表3中各客觀參量進行Pearson相關性分析,結果如表5所示。相關性系數高于0.7時說明該客觀參量與主觀偏好值間具有較強相關[12]。
綜合因子分析、聚類分析以及相關性分析結果可知,客觀參量可分為三類,且各類中與主觀偏好性相關系數最高的客觀參量分別為響度(0.787)、尖銳度(-0.823)以及A計權聲壓級(0.863)。因此,提取該3個客觀參量作為聲品質偏好性建模及預測分析的客觀參量。

表5 主觀偏好值與客觀參量的相關性系數
5 聲品質預測模型的建立與檢驗
5.1 預測模型的建立
找出主觀偏好性與客觀參量間的影響關系是建立汽車關門聲品質預測模型的關鍵。相關研究表明主客觀參量間的關系實質為回歸分析[13],因而本文采用支持向量回歸機建立預測模型,回歸問題擬合函數為

支持向量回歸最優化問題數學表達式為

其中:c為懲罰因子,b為偏置;ξi和為松弛變量,且ξi≥0,≥0;ε為不敏感誤差損失函數。引入拉格朗日乘子αi和以及核函數可得SVR的決策函數:

式中:且αi≠0,≠0;(x,xi)為訓練樣本集;K(x,xi)為核函數,本文選用適用性最廣的高斯徑向基核函數。
至此,建立了3個預測模型優化參數:懲罰因子c,徑向基核函數中的σ以及損失函數中的ε。定義g=1/2σ2,p=ε,并引入遺傳算法(Genetic Algorithm,GA)對SVR的決定參數進行尋優,該方法能高效尋求全局最優解[14]。
5.2 預測模型的檢驗
將主觀偏好性試驗分值與本文多元統計分析后提取出的客觀參量響度、尖銳度和A計權聲級代入GA-SVR模型中進行訓練,得到如圖7所示適應度線。
由圖7可知,當種群進化到10代左右,最佳適應度值快速收斂并趨于穩定,訓練后得到的最優參數為:c=104.792 8,g=2.894 4,p=0.016 506。將最優參數代入支持向量機即得一個初步預測模型,再將測試集代入初步模型驗證模型精度,直至模型精度滿足要求。

圖7 適應度曲線圖
由MATLAB可得最終模型結構體為

由模型結構體參數可知預測模型共有10個支持向量,則模型數學表達式為11項的和(包括常數項),表達式較為冗長復雜。此處以提取第一項決策函數為例,將模型結構體內參數代入式(9)、式(10),得到預測模型其中一項數學表達式為
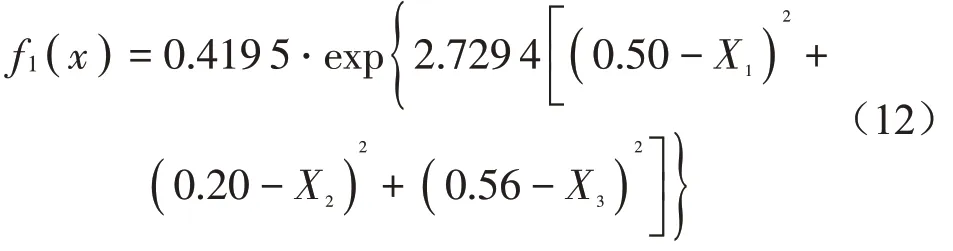
其中:x=(X1X2X3);X1——響度;X2——尖銳度;X3——A計權聲壓級。
由圖8至圖11及表6可知,對訓練樣本集和測試樣本集,應用MSA-SVR模型得到的預測偏好性值與試驗主觀偏好性值的平方相關系數分別為R2=0.998 7和R2=0.972 9,均大于85%,高于未經多元統計分析時SVR模型的平方相關系數R2=0.948 3和R2=0.707 1,且預測均方誤差mse都低于0.001,比未經多元統計分析SVR模型的預測均方誤差mse值0.004 0和0.068 4要小很多,說明不管是從相關性系數還是從預測均方誤差看,MSA-SVR模型預測偏好性值比無多元統計分析的SVR模型預測偏好性值更優。

圖8 MSA-SVR模型訓練集樣本預測結果對比

圖9 MSA-SVR模型測試集樣本預測結果對比
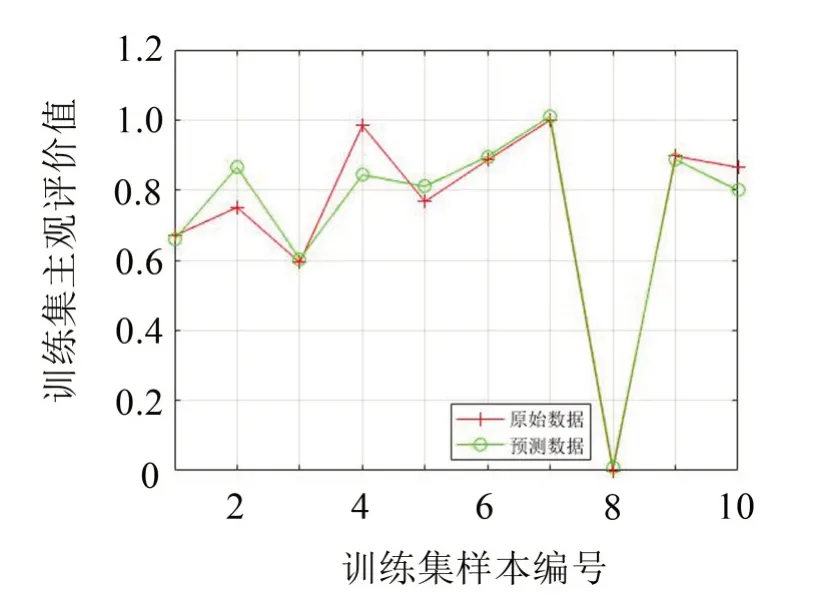
圖10 SVR模型訓練集樣本預測結果對比
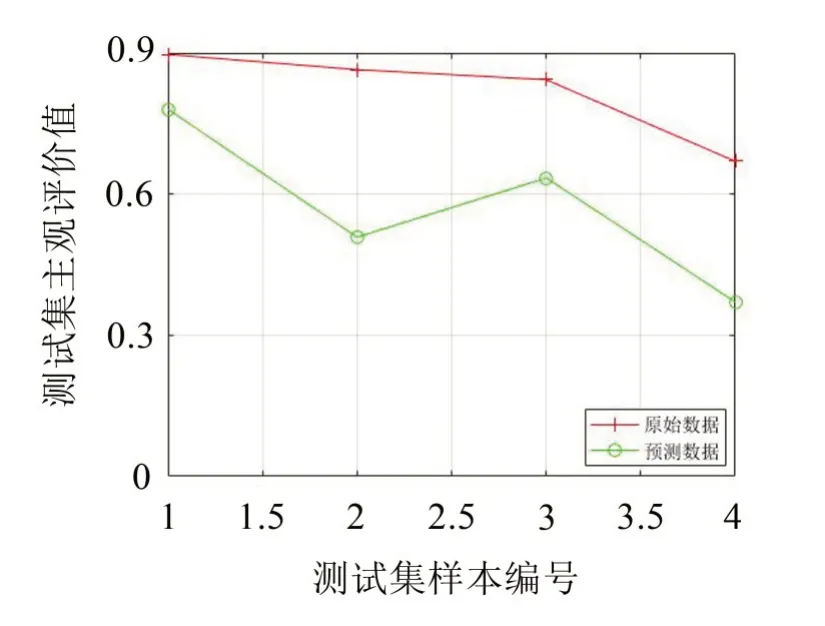
圖11 SVR模型測試集樣本預測結果對比

表6 預測模型預測結果對比
6 結語
計算得出了汽車關門聲的主觀偏好值及客觀參量,通過因子分析與聚類分析找出各客觀參量間相關性,并在此基礎上,利用相關性分析得出主觀偏好性與客觀參量間的相關性系數,提取出了最能表征主觀偏好性的客觀參量:響度、尖銳度和A計權聲壓級。利用遺傳算法對支持向量回歸機主要參數進行尋優,得到了基于多元統計分析-支持向量回歸的預測模型。MSA-SVR模型的主觀偏好預測值與主觀偏好試驗值相關系數高于未經多元統計分析的SVR模型且其均方誤差明顯低于未經多元統計分析的SVR模型,說明MSA-SVR模型的預測能力顯著提高,驗證了多元統計-支持向量回歸方法用于汽車關門聲品質偏好性的預測是可行和高效的。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
石油瀝青(2021年4期)2021-10-14 08:50:44
世界科學技術-中醫藥現代化(2021年10期)2021-03-02 05:52:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
中國工程咨詢(2015年2期)2015-02-14 02:59:26
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
