數據庫測試用例虛擬仿真系統的研究與設計
2021-05-10 02:53:39楊愛民吳志磊劉潔
中國信息技術教育 2021年8期
關鍵詞:數據庫
楊愛民 吳志磊 劉潔


摘要:本文介紹了數據庫測試用例虛擬仿真系統的研究方法與設計思路,提出了以語義知識庫推理法則為代表的三種計算機數據庫用例生成仿真數據方式,為高等院校數據庫類課程實驗以及企業應用軟件測試提供了相應的仿真數據與實驗環境。
關鍵詞:數據庫;測試用例;仿真實驗
中圖分類號:G434? 文獻標識碼:A? 論文編號:1674-2117(2021)08-0105-04
● 研究背景及意義
隨著大數據時代的來臨,越來越多的應用軟件(如電子商務、網上售票、醫療、超市等)在設計數據庫時都需要運用海量的真實數據進行性能、功能以及壓力測試,以保證軟件上線后的正常運行。但是,要想得到海量的真實數據,對大多數測試者而言都不太現實,這一方面是因為渠道問題無法大批量獲取原始數據,另一方面如果采用人工錄入,需要耗費的巨大的人力、物力,如北京某商廈百貨業管理系統,在上線前由4個計算機專業錄入員花了近20天的時間才完成了10萬條記錄的數據錄入的初級測試,而離系統飽和測試(100萬條)還相差很遠。而對于其他大型的軟件如12306售票系統等,需要的測試數據會高達上億條,這對于一般手工錄入來說是無法完成的。為此,本項目研究的是一個“數據庫測試用例自動生成虛擬仿真系統”,該仿真系統可以借助語義知識庫、智能算法,并通過接口程序為主流數據庫提供用例自動生成仿真數據,以檢驗數據庫的承載力,以及應用軟件的可靠性,從而為數據庫課程實驗以及企業應用軟件提供相應的仿真測試數據。
● 國內外研究現狀和發展動態
國外研究創立了一套相對成熟的理論,創造了一批比較優秀的自動化測試工具。其中,典型自動化測試框架比較有名的有Automated Testing Specialists Inc提出的基于數據驅動的自動化測試方法以及GUI測試方法、Mercury Interavtive Inc提出的關鍵字驅動自動化測試方法及錄制/回放式的自動化測試方法。
從國內學者對自動化測試領域的研究現狀來看,基于智能優化算法的軟件測試用例自動生成技術已經取得了不錯的進展。國防科技大學的單錦輝(2002)博士將迭代松弛法改進之后再用于測試用例自動生成,并開發了完整的系統原型[1];賀瀅(2015)首次提出了應用粒子群算法自動生成測試用例,并且在智能尋優算法的基礎上對TC自動生成方法進行了系統的研究[2];劉慰(2018)等人提出一種以遺傳算法為核心的測試數據生成方法,自動生成測試數據并且使用XML文件來記錄測試結果[3];侯俊(2018)等人針對現在Web測試主要依賴人工測試的問題,在Web測試生成單個測試用例的基礎上提出了一種基于WSDL文檔和形式化模型樹Web服務操作測試用例的自動生成方法,該方法大幅度提高了Web測試用例生成的效率,節省了測試消耗的時間。[4]
但國內目前數據庫用例測試的地位不高,大多數的公司還只是停留在軟件單元測試、集成測試和功能(軟件交付前的功能、性能)測試上,沒有一套完整的數據庫用例測試標準化準則,也缺乏完全商業化的操作機構,其主要原因是數據庫用例測試需要大量的人力及時間成本。但在大數據發展趨勢下,數據庫管理系統不斷被應用于企業管理中,幫助企業更好地管理大量數據。因此,就國內現狀而言,測試用例自動生成技術使用價值大,應用前景廣,但研究普遍相對較少,目前還沒有成熟的主流數據庫的測試用例系統的相關報道,同歐美國家軟件測試行業的差距較大。
● 系統的設計思路及方法
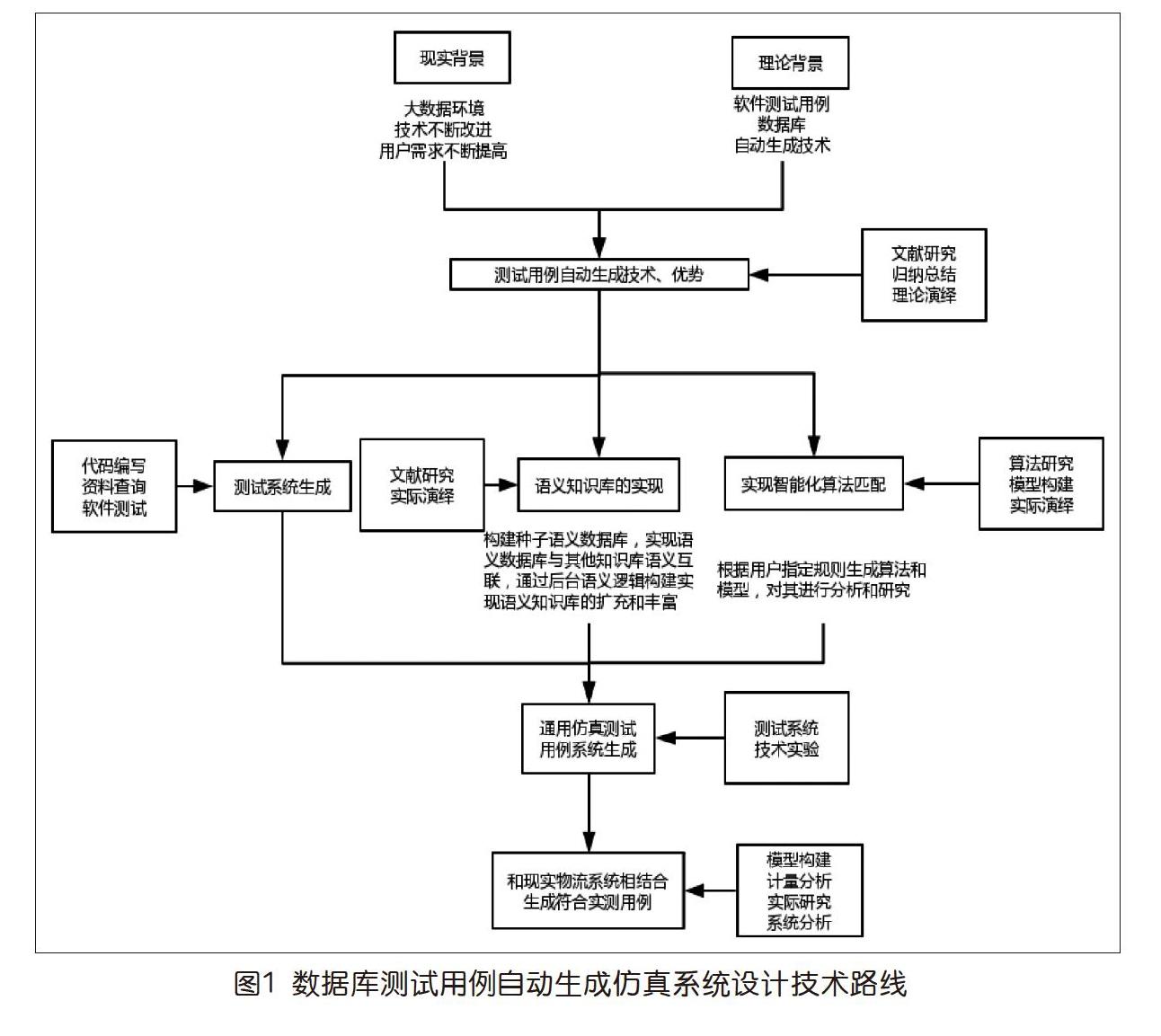
本實驗方案的設計思路是在大數據測試用例上,不去關心具體應用軟件的數據庫怎么設計,而是根據現有流行數據庫的通用字段結構,按字段類型設計出一個通用的數據結構模型,然后再定義語義知識庫、關聯條件庫、語義種子庫,以及原始字庫等,并以此作為支撐,提供應用軟件數據接口。這樣,在遇到不同的應用軟件時,只要捕捉到應用軟件數據庫表的結構(或人工提供),然后通過接口程序匹配,給出生成條件,即可開始生成海量數據。系統設計技術路線如圖1所示。數據庫測試用例生成,實際上是結合了智能算法、語義知識庫、文獻研究演繹等相關智能化知識體系加上程序設計而完成的一套比較復雜的虛擬仿真實驗系統。
本系統的設計原理是由測試用例自動生成工具自動捕獲數據庫應用系統表,從而獲得數據庫中的表、表結構及其屬性信息等。在為其生成測試用例的時候,既能判斷出表參照關系是否存在循環關系,也能顯示生成表測試用例的先后順序,同時為了能讓用戶直接明了地看到數據庫之間的直接參照關系,自動生成工具也能將表之間的參照關系可視化。[5]
目前,本系統可以通過三種方式生成測試用例,如下頁圖2所示。
一是基于已有的語義知識庫讓計算機按照一定的語義規則推理自動生成測試用例。
這種方法主要針對含語義類型的字段內容,如姓名、地名、商品名等,通過構建相關類字段的語義知識庫以及普通字庫,生成時由用戶按需要輸入相關語義種子,構建用戶自定義的語義種子庫,然后結合遺傳算法調用字庫,生成符合語義規則的數據內容。
二是從已有的同種或異種關系數據庫中直接導入生成。
有時在生成某一數據字段時,需要用同種數據庫或異種數據庫的另一數據表數據來生成,如學生成績管理系統中學生表包含學號、姓名、性別、系部、出生日期,課程表包含課程號、課程名、學分,選課表包含學號、課程號、成績,其中選課表中的學號及課程號分別需要從學生表和課程表的數據中生成,這就需要在生成選課表時,調用學生表和課程表的數據進行導入,這是同種數據庫的導入生成。有時同類系統如船務管理系統、貨物管理系統,用的不是同類數據庫,但某些數據類型內容相似,引用時,則需要異種數據庫數據的導入。這種導入方式,在導入前提供通常用的數據庫的接口程序,需要引用哪種數據庫,通過設置接口程序實現對接,然后再由用戶設定一些導入規則,如生成數量、時間范圍等,即可實現同種或異種數據庫數據的導入生成。
三是根據表的結構和屬性以及用戶指定的約束規則隨機自動生成。
此類數據一般是針對時間類、數字類和非語義字符類數據,可以通過用戶給定約束條件,如生成數量、數值/時間范圍等約束條件,按一定算法自動生成,為了靈活高效管理字段實例引擎,引入“時間、非語義類字符、數字(含整數和實數)、邏輯”四種類型引擎接入插件。整個系統對自動生成的表測試用例可以進行維護。數據庫用例仿真實驗系統的功能實現如圖3所示。
● 系統的仿真實驗結果分析
本系統設計完成后,筆者對所在學校設置了數據庫、軟件工程等課程的班級開設的60多個實驗案例及軟件作品進行了測試用例實驗,實驗結果表明,學生實驗的數據表中80%的數據可以直接利用本系統生成,剩余的數據通過重新定義語義規則也基本上可以全部實現,同時本系統還針對地方企業進行了應用軟件用例測試分析,如某船務代理有限公司的船務代理系統,生成了100多萬條數據進行壓力測試,還有山東工商學院、浙江大學寧波理工學院、寧波財經學院、浙江萬里學院的全國大學生體質上報系統,也是采用該仿真系統瞬間生成數萬條仿真數據來進行壓力測試,如圖4所示。
本系統主要體現出以下兩個特色:
(1)通用性。本仿真系統設計完成后,可以通過數據庫接口程序,與目前市場上流行的主流數據庫對接,實現了主流數據庫的測試用例自動生成,具備了數據庫用例的通用性。
(2)智能化。通過運用算法模型,設計語義知識庫及表與字段的模型庫,智能化地與應用案例數據庫進行匹配,實時生成海量仿真數據。
● 結論
數據庫用例測試仿真系統是按照用戶需求,為應用軟件特別是數據處理量非常大的應用軟件瞬間智能化地生成海量仿真測試數據,以檢驗軟件的可靠性及數據處理壓力的最大臨界值,為企業數據的備份轉儲或數據庫的升級提供預警,減輕了測試人員繁重的手工勞動。
目前,本系統主要實現了ACCESS、MYSQL、SQL-SERVER幾種數據庫之間的對接以及常規數據的自動生成,但對一些特殊字段類數據,如圖像、聲音、二進制等數據格式,還無法自動生成,課題組將在后期繼續研究針對大型數據庫以及特殊字段的自動測試生成,并將研究成果向社會推廣。
參考文獻:
[1]單錦輝,高仲儀.面向路徑的測試數據自動生成工具及其圖形界面Tcl/TK設計[J].計算機工程與應用,2002(01):74-77.
[2]賀瀅,徐蔚鴻,李楊林.基于RACPSO的測試用例自動生成方法[J].計算機工程,2016(05):67-70.
[3]劉慰,應新洋.基于遺傳算法與XML的測試用例自動生成執行系統研究與實現[J].計算機時代,2018(02):44-47.
[4]候俊,周紅,馬春燕,等.面向WEB服務的測試用例自動化生成方法[J].西北工業大學學報,2018(02):14-15.
[5]張文祥.關系數據庫測試用例自動生成研究[M].北京:科學出版社,2004.
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
