一種基于語義分割的機場跑道檢測算法
2021-04-16 13:07:38王旒軍蔣海濤劉崇亮裴新凱邱宏波
導航定位與授時 2021年2期
關鍵詞:特征
王旒軍,蔣海濤, 劉崇亮,裴新凱,邱宏波
(1.北京自動化控制設備研究所,北京 100074; 2.海裝駐北京地區第三軍事代表室, 北京 100074)
0 引言
在軍事領域,無人機(Unmanned Aerial Vehicles, UAVs)可以替代有人作戰飛機執行戰場管理、空中和海上監視、戰場巡邏與制圖、戰時安全通信、目標跟蹤和作戰打擊等多種任務。隨著各項技術的成熟,各型軍用無人機,如美國RQ-4全球鷹和中國彩虹無人機等越來越多地參與到實際作戰中,變得越來越流行。
固定翼無人機在實際使用中面臨的一大挑戰是如何確保無人機在執行完任務后能安全著陸。目前常用的無人機著陸導航系統為衛星/慣性等多源信息融合的組合導航系統。但是,面對越來越復雜的電磁作戰環境,嚴重依賴外界定位信息的著陸系統的安全性難以保證。相對于依賴外界定位信息的著陸方案,使用視覺信息輔助的全自主著陸系統在自主性、安全性和價格方面展現出優勢[1]。
機場跑道檢測(Airport Runway Detection)是視覺著陸導航系統的重要一環。Vezinet等[1]基于跑道的參考圖像執行圖像配準,以檢測點特征進行著陸引導。Gibert等[2]使用機場跑道邊界和中線作為特征進行跑道檢測。Khaled等[3]結合區域競爭分割和最小化能量函數的方法,構建了實時跑道檢測和跟蹤系統。在之前的團隊工作中,劉暢等[4]提出了一種視覺/慣性組合導航算法,采用Kalman 濾波分別完成位置和姿態匹配,實現了視覺測量與慣導信息的融合。劉崇亮等[5]提出了一種著陸視覺導航P3P問題唯一解的求解方法,實現了無人機與跑道之間的六自由度位姿解算。文獻[6]利用可見光相機、紅外相機和雷達高度計等傳感器,通過提取跑道直線和輪廓特征,實現了跑道檢測和位姿計算。
人工智能(Artificial Intelligence, AI)技術的崛起給機場跑道檢測算法研究帶來了新的契機。本文研究基于圖像語義分割的機場跑道檢測算法,在特征提取部分,利用注意力模型(Attention Model)設計構建了自注意力模塊,融合了特征圖空間維度和通道維度的全局相似性信息,以捕獲特征圖中大范圍全局特征,可以提高跑道檢測網絡的全局特征提取能力。主干網絡選用輕量高效的ShuffleNet V2[7],并使用空洞卷積對網絡進行改造,從而獲取更高分辨率的稠密特征圖。最后,設計了簡潔高效的解碼器模塊,使用跳躍連接將網絡淺層特征圖引入頂層,使淺層豐富的細節、空間位置信息與頂層粗略、抽象的語義分割信息相融合,以獲得精細的跑道檢測輸出結果。
1 自注意力模型
注意力模型可以對特征圖中全局特征之間的關系進行建模,在圖像、視頻和音頻處理等工作中廣泛使用[8-13]。兩個向量點積的幾何意義是計算其相似程度,點積結果越大,表明兩個向量越相似。自注意力機制(Self-attention Mechanism)利用這個原理進行特征圖中關系權值的學習,不需要外部輔助,通過特征圖之間的特征變換獲取特征圖空間、通道或者時序的全局關系。
本節利用自注意力機制,設計構建了自注意力模塊(Self-attention Module)。首先介紹了位置注意力模塊(Position Attention Module)和通道注意力模塊(Channel Attention Module)的網絡結構,然后闡述了融合這兩種注意力模塊的自注意力模塊網絡設計。
1.1 位置注意力模塊
圖像語義分割任務對網絡的特征抽象能力要求比較高。理論上,網絡中深層的卷積核具有很大的感受野,更容易提取抽象出高級語義特征,但是深層網絡的實際感受野要遠小于理論值[14],導致全局特征缺失。位置注意力模塊通過特征圖之間的特征變換,計算每個像素與其他像素的全局相似性關系,可以增加網絡的感受野,通過建模特征圖中局部特征的全局上下文信息,從而增強網絡的全局特征表達能力。
位置注意力模塊的網絡結構如圖1所示。首先對尺寸為[H,W,C]的輸入特征圖使用1×1卷積壓縮特征圖的通道維度,對于用于特征變換的第一路分支,通道壓縮比為8,得到尺寸為[H,W,C/8]的特征圖f;第二路分支的通道壓縮比為2,保留了較多的原始信息,得到尺寸為[H,W,C/2]的特征圖g。然后再分兩路對f特征圖進行特征變換:一路進行維度變換和轉置操作,合并高度和寬度維度,將通道變換為第一維度,得到[C/8,H*W]的特征圖f1;另一路對f特征圖只進行維度變換操作,合并高度和寬度維度,得到[C/8,H*W]的特征圖f2。接著對f1和f2特征進行矩陣乘法,消去通道維度C/8,再使用Softmax函數歸一化,獲得尺寸為[H*W,H*W]的注意力圖。注意力圖描述了特征圖中每個像素的全局相關性信息,特征圖中兩個位置的特征相似度越高,注意力圖中相應的值越大。同時,對第二路分支的特征圖g進行維度變換,得到[H*W,C/2]的特征圖g1。最后,使用注意力圖與g1特征圖進行矩陣乘法,將獲取的全局相關性權值信息重新分布到原始特征圖中,并使用維度變換操作恢復特征圖的高度和寬度,輸出通道壓縮后[H,W,C/2]的特征圖。
1.2 通道注意力模塊
一般情況下,深度卷積神經網絡中頂層不同的通道會關注不同的分割類別。位置注意力模塊可以提取特征圖中不同像素的全局相似性關系,而通道注意力模塊利用相似的特征變換操作,在計算特征圖矩陣乘法時,將相乘順序調換了一下,保留通道維度,使網絡具有全局通道相關性表達能力[15]。
通道注意力模塊的網絡結構如圖2所示。首先使用1×1卷積壓縮特征表達得到特征圖h,h∈RH×W×(C/2)。然后分成三路對特征圖進行特征變換,使用維度變換或轉置操作,分別得到尺寸為[C/2,H*W]的特征圖h1,尺寸為[H*W,C/2]的特征圖h2和h3。接著,對特征圖h1和h2進行矩陣乘法,不同于位置注意力模塊,這里消去H*W維度,保留通道維度。為了防止訓練期間的損失值不收斂[12],這里將特征圖中每個位置去除最大值,設得到的特征圖為G,其中一個像素點Gi,j為
Gi,j=max(G)-Gi,j
(1)
其中,max(G)表示特征圖中像素的最大值;i、j分別表示像素點坐標,i,j∈[1,C/2]。
隨后對特征圖G使用Softmax函數歸一化,獲得尺寸為[C/2,C/2]的注意力圖,注意力圖描述了特征圖中所有通道之間的相關性信息。特征圖中兩個通道的特征相似度越高,注意力圖中相應的權值越大。
最后,將注意力圖與特征圖h3進行矩陣乘法,消去H*W維度,并恢復特征圖高度和寬度維度。使用注意力圖更新通道關系權值,有選擇性地強調所有通道中相關聯的通道,并將全局通道相關性信息分布到原始特征圖中,獲得尺寸為[H*W,C/2]的輸出特征圖。
1.3 自注意力模塊
自注意力模塊整合了位置注意力模塊和通道注意力模塊,可以融合特征圖空間維度和通道維度的全局相似性信息,從而獲得更好的語義分割效果。
自注意力模塊如圖3所示,首先使用位置注意力模塊和通道注意力模塊對輸入特征圖進行操作,分別提取特征圖全局像素相似性和通道相關性信息。然后,使用3×3卷積進一步提取兩個模塊輸出的特征圖特征,獲得兩路尺寸為[H,W,C/2]的特征圖。接著融合位置注意力和通道注意力輸出特征圖。不同于文獻[12] 使用兩個可訓練參數分別對兩路特征圖進行加權后再和原始特征圖逐像素求和的方法,本文設計的自注意力模塊將兩個注意力模塊輸出的特征圖直接與原始特征圖在通道維度進行拼接,再使用1×1卷積對拼接的特征圖進行特征整合,在達到相同特征融合目的的情況下可以使特征的融合更加自由。最后,添加失活概率為0.1的隨機失活層,隨機失活一些特征,以避免網絡對某些特定特征的過度依賴,從而增強模塊的魯棒性。自注意力模塊中每層卷積操作后,使用批量歸一化和ReLU激活函數來減少梯度消失等現象,以加快收斂速度。

圖3 自注意力模塊Fig.3 Self-attention module
自注意力模塊原理簡單、結構清晰,融合了位置注意力模塊的空間相似性特征提取能力和通道注意力模塊的全局通道關系提取能力,在不需要外界信息輔助的情況下,通過特征圖之間的特征變換就可以捕獲特征圖中大范圍全局相似性信息,在沒有增加很多參數的情況下增加了網絡感受野,提高了網絡全局特征提取能力。
2 跑道檢測網絡
在語義分割領域,多數學者的研究工作致力于提升圖像分割的精度,相對忽略了網絡推理的實時性。本文著眼于構建實用跑道檢測網絡,結合學術界最新的研究成果和理念,在網絡設計時兼顧精度和實時性。以下小節分別闡述了主干網絡構建、解碼器設計和整個跑道檢測網絡的結構。
2.1 主干網絡構建
分類網絡作為語義分割網絡的主干,承擔了特征提取器的重要角色,在很大程度上決定了整個語義分割網絡的性能。
ShuffleNet V2輕量級分類網絡遵循高效設計理念:網絡模塊的輸入和輸出特征圖通道數應當一致,以減小內存訪問耗時(Memory Access Cost,MAC);避免使用過多的分組卷積(Group Convolution);減少網絡分支結構,以提高并行計算效率;逐像素操作如ReLU和1×1卷積等,雖然具有較小的計算量(FLoat point OPerations,FLOPs),但是內存訪問消耗較高。
深度可分離卷積(Depthwise Separable Convolution)首先使用3×3卷積核在輸入特征圖上逐通道分別進行卷積運算,然后使用1×1卷積進行通道關系映射。通常,逐通道計算的3×3卷積被稱為“Depthwise Convolution”,1×1卷積被稱為“Pointwise Convolution”。深度可分離卷積的使用可以大幅減少網絡的計算量。
設深度可分離卷積模塊輸入特征圖尺寸(高×寬×通道)為h×w×ci,輸出特征圖尺寸為h×w×co。則常規卷積卷積核尺寸為k×k×ci×co,co為卷積核個數,深度可分離卷積中逐通道卷積核尺寸為k×k×ci,1×1卷積核尺寸為1×1×ci×co。深度可分離卷積與常規卷積的計算量之比為
(2)
由于通常卷積核尺寸遠小于輸出通道數,所以深度可分離卷積與常規卷積的計算量之比約為1/k2,當Depthwise Convolution卷積核設置為3×3時,深度可分離卷積比常規卷積可使計算量僅為原來的1/8~1/9。
網絡模塊的輸入和輸出特征圖通道數相同可以減少內存訪問。簡便起見,設卷積核的大小k=1,則卷積計算量FLOPs=F=hwcico,內存訪問次數MAC=hw(ci+co)+cico,由均值不等式可得
MAC=hw(ci+co)+cico
(3)
由式(3)可知,當FLOPs確定時,ci=co時模型MAC最小。
ShuffleNet V2舍棄了ShuffleNet V1[16]中1×1分組卷積,引入了通道分離(Channel Split)操作,將輸入c通道數的特征圖分為c-c′和c′(實現時c′=c/2)兩部分,一路分支使用恒等連接,另一路分支使用輸入和輸出通道數相等的1×1 Conv+3×3 DWConv+1×1 Conv三個卷積層(DWConv: Depthwise Convolution),最后將兩路結果在通道維度進行拼接(Concatenate)。為了使兩路分支(組)的特征相互交流,對拼接后的特征進行通道洗牌(Channel Shuffle)操作。接著進入到下一個網絡模塊,這樣拼接、通道洗牌和下一個模塊的通道分離操作就合并成了一個逐像素運算的模塊,從而減少了內存訪問。
實驗表明,ShuffleNet V2與ShuffleNet V1、MobileNet[17-18]和modified Xception[19]等網絡相比,在推理速度大為提升的同時具有最佳分類精度[7]。因此,本文選用ShuffleNet V2 “1×”版本構建主干網絡。
首先,將ShuffleNet V2網絡Stage4網絡塊后的池化層和全連接層等去除,構建為全卷積網絡(Fully Convolutional Networks,FCN)。這樣,網絡的Output Stride(網絡輸入圖像與輸出特征圖的尺寸比值)為32。而圖像分割任務希望網絡輸出特征圖相對稠密,以獲得精細的語義分割結果,并且為了提取抽象的語義信息,在輸出較大分辨率特征圖的情況下,頂層網絡的感受野不能太小。空洞卷積(Atrous Convolution or Dilated Convolutions)可以解決這個問題。
如圖4所示,空洞卷積引入膨脹比率(Dilation Rate)r,在原有卷積核的中間插入空洞構造成為空洞卷積。常規卷積(圖4(a))可以認為是空洞卷積在rate=1時的特例。設常規卷積核尺寸為k×k,則空洞卷積的卷積核大小等效于
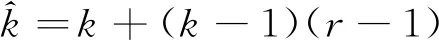
(4)
由式(4)可知,空洞卷積在不增加卷積核參數量和卷積計算量的情況下,可以增加卷積核的感受野,進而提升網絡的特征提取能力。

(a) rate=1×1

(b) rate=2×2

(c) rate=3×2
設卷積層的輸入圖像或者特征圖的尺寸為h×w,每次滑動的步長(Stride)為s,在邊緣填充(Padding)零像素的圈數為p,輸出特征圖的尺寸為m×n,則使用常規卷積核時輸出特征圖的尺寸為
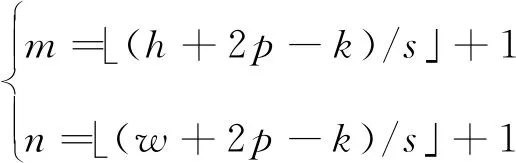
(5)
使用空洞卷積核時輸出特征圖的尺寸為
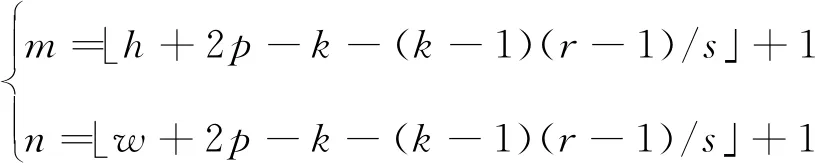
(6)
由式(6)可知,通過設置相應的膨脹比率和步長,空洞卷積使主干網絡輸出的特征圖尺寸可控,可以根據分割任務調整特征圖尺寸,對語義分割任務非常有利。
將Stage4網絡塊中第一層步長設為1,并將隨后的三個網絡層改造為膨脹比率為2的空洞卷積,使得卷積層感受野繼續增大的同時,特征圖尺寸不再減小。最終選用Stage4網絡塊輸出464通道Output Stride為16的特征圖作為主干網絡的輸出。
本文構建的主干網絡如圖5所示。主干網絡中使用了通道分離、通道洗牌、深度可分離卷積和空洞卷積等技術,在有效降低參數量、計算量和內存訪問量的同時,具備很強的特征提取能力。
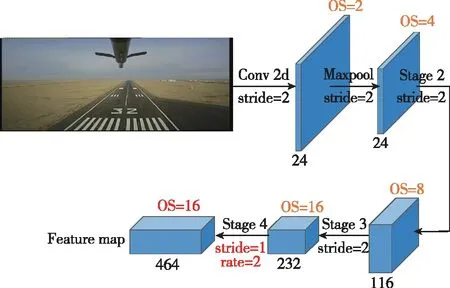
圖5 主干網絡Fig.5 Backbone network
2.2 解碼器設計
主干網絡和自注意力模塊編碼了圖像中豐富的語義信息,但是輸出特征圖分辨率低,丟失了部分空間位置信息。解碼器使用上采樣逐步增大特征圖的尺寸,并使用跳躍連接融合淺層豐富的細節和空間位置信息,可以恢復清晰的物體邊緣,從而獲得更加稠密、精細的語義分割結果。
本文設計的簡單高效的解碼器模塊如圖6所示。圖6中,DSConv表示深度可分離卷積(Depthwise Separable Convolution),OS表示Output Stride。對輸入OS=16的特征圖首先進行雙線性
插值2倍上采樣,獲得OS=8的特征圖,然后引入主干網絡中相同空間分辨率的Stage2網絡輸出特征圖,并使用1×1卷積降維1/3得到38通道淺層特征。隨后將兩路特征圖拼接后,使用兩層3×3的深度可分離卷積進一步整合細化深層和淺層特征,最后輸出256通道OS=8的整合了深層網絡豐富語義信息和淺層網絡豐富細節及空間位置信息的精細化分割特征圖。
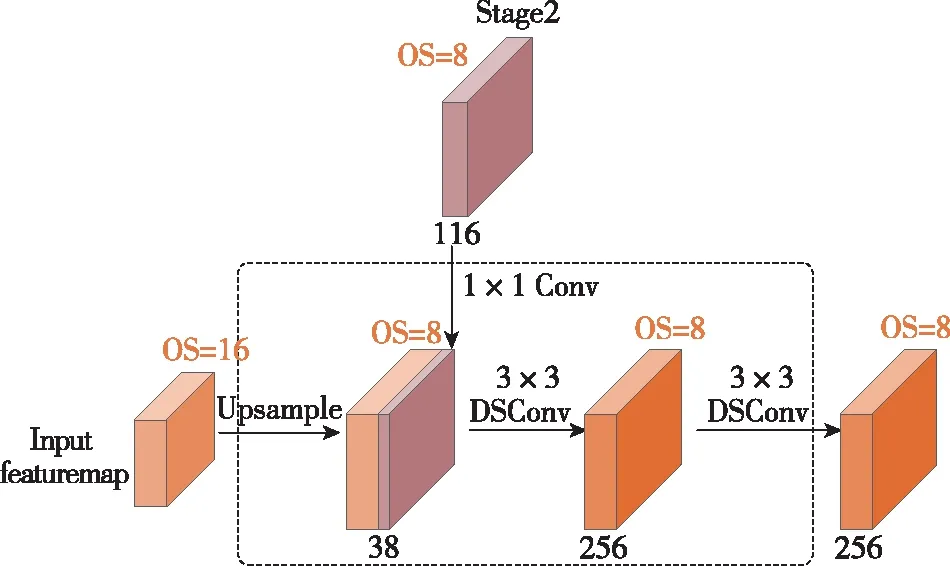
圖6 解碼器模塊Fig.6 Decoder module
2.3 跑道檢測網絡設計
整個跑道檢測網絡(命名為RunwayNet)可分為編碼器和解碼器兩部分,網絡結構如圖7所示。編碼器部分包括主干網絡和自注意力模塊:主干網絡對輸入的三通道圖像逐步提取抽象語義特征,最終輸出464通道OS=16的特征圖;自注意力模塊進一步對主干網絡輸出特征圖進行特征變換,捕獲特征圖空間維度和通道維度的全局相似性信息,提高了編碼器的全局特征提取能力。編碼器輸出的256通道特征圖隨機進入解碼器,經過跳躍連接和雙線性插值上采樣融合淺層特征,輸出OS=8更加稠密、精細的的特征圖。最后,使用1×1卷積將特征圖映射為兩通道(分類類別數)的分割圖,將分割圖上采樣8倍并在通道維度取最大值(ArgMax)操作,從而獲得最終的分割結果。

圖7 RunwayNet網絡結構圖Fig.7 RunwayNet network architecture
3 實驗
3.1 數據集介紹
實驗部分使用某型國產固定翼無人機進行跑道圖像數據采集,收集了數個跑道不同季節、不同時刻、不同天氣下的機場跑道圖像序列,使跑道數據具有多樣性。采集的跑道圖像序列經過降采樣和人工篩選得到1753張跑道圖像。此外,為了豐富實際采集的跑道數據,在互聯網上搜集并篩選得到948張著陸跑道圖像。最后共收集了2701張圖像。
隨后使用labelme標注工具對跑道圖像進行精細標注工作。設置“跑道”和“背景”兩個類別語義標簽:跑道區域定義為左右跑道邊線、起始斑馬線和終止斑馬線之間的區域,其他圖像區域劃分為背景。接著將數據劃分為2124張訓練集和557張測試集,命名為Runway數據集。Runway數據集數據統計如表1所示,表中以序列為單位統計了圖片數、劃分為訓練集或測試集的數據集、季節、時刻、天氣和數據來源等詳細信息。Runway數據集關注真實機場場景下跑道的分割能力,貼近機場跑道檢測的實際應用需求,任務難度相對較高。
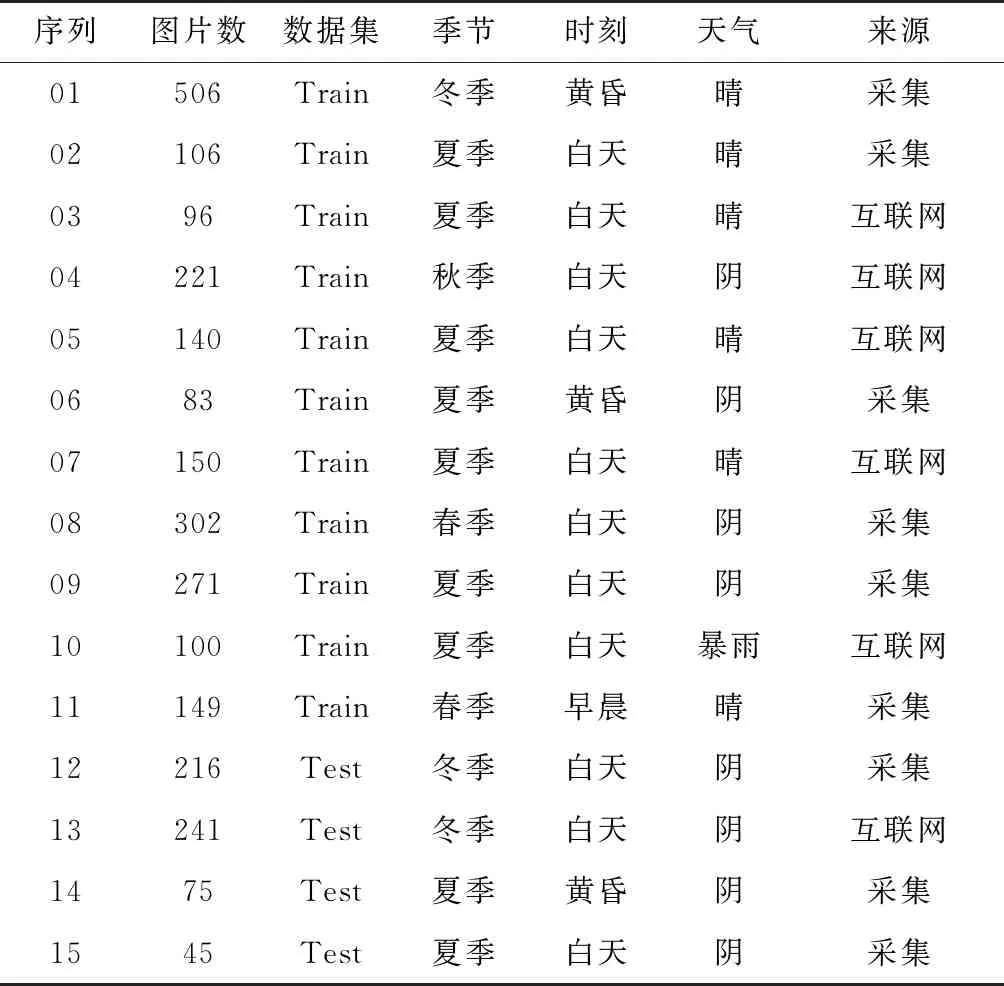
表1 Runway數據集統計
3.2 訓練細節
訓練平臺為搭載兩塊Nvidia GTX 1080Ti GPU的服務器,CPU型號為I7-8700K,擁有32GB機身內存,運行Ubuntu 16.04操作系統。軟件代碼基于TensorFlow[20]開源框架實現。
網絡訓練時首先使用在ImageNet數據集[21]上預訓練的ShuffleNet V2來初始化主干網絡權重,然后將整個網絡在MS COCO數據集[22]上進行端到端預訓練,最后在Runway數據集上進行最終的訓練。
數據增強方面,首先使用縮放因子為[0.5,2.0],步長為0.25的隨機縮放操作。然后對訓練輸入圖像進行1242×375尺寸的隨機裁剪。最后對訓練圖像使用概率為0.5的隨機左右翻轉操作。
網絡使用Softmax函數計算每個像素的分類概率,并使用交叉熵函數計算總損失值。權值正則化系數設為4×10-5,批量歸一化的Batch Sizes設置為16,在反向傳播和網絡參數更新時使用Adam優化器[23],學習速率使用ploy策略,初始學習率設置為1×10-3, power設置為0.9,最大迭代次數設置為60K。
3.3 實驗結果
本節首先進行RunwayNet各個模塊的消融實驗(Ablation Experiments),然后對自注意力模塊中間結果進行可視化,最后給出RunwayNet在英偉達Jetson AGX Xavier嵌入式平臺上的跑道檢測效果圖。
首先在Runway數據集上進行RunwayNet各個模塊的消融實驗,以驗證各個模塊及其組合的性能、參數量和計算量。跑道分割精度用平均交并比[24](Mean Intersection over Union,MIoU)來評價,參數量的單位為MB(兆字節),網絡計算量用GFLOPs表示,GFLOPs=1×109FLOPs,GFLOPs在網絡輸入為1242×375×3分辨率下測得。
實驗結果如表2所示,表中SAM和Decoder分別表示自注意力模塊和解碼器模塊,Our-Basic方法表示只使用主干網絡進行語義分割,推理速度fps在英偉達Jetson Xavier平臺上測得,MIoU得分由Runway測試集計算得出。
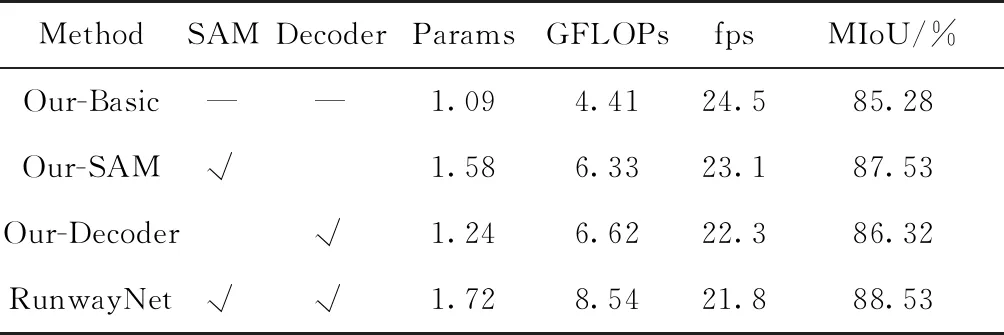
表2 RunwayNet各模塊消融實驗
由表2中數據可知:Our-Basic網絡配置在參數量僅1.09MB、計算量僅4.41GFLOPs的情況下,MIoU得分可達到85.28%,在Xavier上推理速度達到24.5fps,可見本文構建的主干網絡在極少參數量和計算量的條件下具有很強的特征提取能力;Our-SAM網絡配置在主干網絡的基礎上添加了自注意力模塊,MIoU評分提升了2.25%達到87.53%,參數量略微增加0.49MB,計算量增加1.92GFLOPs,推理速度也略微下降到23.1fps,可見自注意力模塊在沒有增加很多參數量和計算量的情況下,分割精度提升明顯;Our-Decoder網絡配置在主干網絡的基礎上添加了解碼器模塊,MIoU評分相比Our-Basic網絡提升了1.04%,參數量略微增加0.15MB,計算量增加2.21GFLOPs,推理速度稍微下降,可見解碼器模塊融合了淺層細節和空間位置信息后能夠獲得更好的跑道檢測結果。RunwayNet網絡整合了自注意力模塊和解碼器模塊的優點,參數量為1.72MB,計算量為8.54GFLOPs,在Xavier上推理速度為21.8fps,最終MIoU評分達到88.53%,相比于Our-Basic網絡評分提高了3.25%,驗證了本文設計的自注意力模塊、解碼器模塊和RunwayNet跑道檢測網絡的優異性能。
為了更好地理解注意力模型的原理并驗證本文構建的自注意力模塊的有效性,將網絡中間結果:圖像標簽、網絡預測結果、位置注意力圖和通道注意力圖進行可視化。
由1.1節的分析可知,對于H×W×C的輸入特征圖,每一個像素位置都對應一幅H×W分辨率的位置注意力圖,該注意力圖描述了當前像素與特征圖中所有像素的相似性信息。由1.2節可知,通道注意力圖的尺寸為[C/2,C/2],為了使通道注意力特征可視化,對融合了原始特征圖和通道相關性信息的通道注意力模塊輸出特征圖進行可視化,其尺寸為H×W×C/2。需要說明的是,由于原圖和標簽尺寸為1242×375,網絡預測結果OS=8,所以網絡預測原始分辨率為47×156;而自注意力模塊輸入和輸出特征圖OS=16,所以注意力圖實際分辨率為24×78,為了可視化方便,將各圖像縮放至統一尺寸。此外,實際訓練時標簽圖像和預測輸出的像素值為其對應的類別,所以其像素取值為(0,1)。可視化時將標簽圖像和預測結果進行了[255/2]因子的加權,方便區分不同的類別標簽。
自注意力模塊可視化結果如圖8所示。圖8中,每一列對應一張圖的可視化結果,第一行為輸入原圖,第二行為真值標簽,第三行為網絡預測結果。PAM表示位置注意力圖,其標號對應圖中像素位置(x,y); CAM表示通道注意力圖,其標號對應通道號。由第四行第一列可見,紅色坐標點(14,7)對應的位置注意力圖提取了整個圖中“背景”類別的信息,分類準確,邊界清晰。第四行第二列綠色坐標(38,15)像素點對應跑道區域,其位置注意力圖對整個標簽真值定義“跑道”區域響應明顯,對非標簽定義但是人類認知上的跑道區域有所響應且有較強的抑制作用,對“背景”類別沒有任何響應。由最后一行可見,通道注意力圖同樣提取了不同類別清晰的分割區域,如第一列第五列中通道109提取了“跑道”類別,第一列第五列中通道50對“背景”類別響應強烈。

圖8 自注意力模塊中間層可視化結果Fig.8 Visualization of self-attention module intermediate layer
由以上可視化結果分析可知,自注意力模塊如預期的一樣提取了特征圖中各像素位置之間的全局相似性關系和通道之間的全局相關性信息。
為了使評測得分結果更加直觀,可視化理解本文設計的RunwayNet的有效性,給出了RunwayNet在Runway測試集上的分割結果,并做出分析。
分割結果如圖9所示,跑道區域用紫色標記,前四行圖像為機載實驗采集所得,后兩行圖像由互聯網搜集所得。由圖中第一列結果可見,RunwayNet網絡在距離跑道很遠(大于3km)時就對跑道區域正確感知,人眼隱約看見跑道的時候,網絡就能大致識別出跑道區域。由最后一列結果圖可見,從無人機即將著陸到完全降落到跑道上滑行, 網絡都準確地分割出了跑道區域。結合圖中第一列、第二列和第三行結果可見,網絡對由遠及近著陸過程中各個階段的跑道圖像都能精準的分割識別,并且對不同時刻、不同季節、不同背景、不同鋪設條件的跑道都能準確進行分割檢測。綜合以上實驗結果和分析可知,相比于其他方法[1,6],RunwayNet網絡具有媲美于人眼的檢測精度和作用距離,通過大量數據的訓練具備對陌生機場跑道的檢測識別能力,并且對無人機著陸全過程成像尺度變化劇烈的跑道區域進行了精準的分割識別,具有很強的多尺度全局特征提取能力。

圖9 Runway測試集分割結果Fig.9 Segmentation results of Runway test set
4 總結
本文針對無人機自主著陸應用場景,研究了基于圖像語義分割的機場跑道檢測算法,構建了輕量高效的RunwayNet跑道檢測網絡。在編碼器部分,設計構建了自注意力模塊,選用ShuffleNet V2構建了主干網絡。在解碼部分設計了簡潔高效的解碼器以獲得更加精細的跑道分割結果。實驗部分使用無人機進行跑道圖像數據采集,收集了豐富多樣的機場跑道圖像,形成Runway跑道數據集。實驗結果顯示,本文設計的自注意力模塊和RunwayNet跑道檢測網絡具有優異性的能。最終RunwayNet網絡在Runway測試集上取得了88.53%的MIoU評分,1242×375圖像分辨率下在英偉達Jetson Xavier平臺上能達到21.8 fps的處理速度,且無人機著陸全過程都可以對跑道區域進行精準的分割識別,具有很強的實用價值。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
