基于語義分割的紅外和可見光圖像融合
2021-02-06 09:27:38周華兵侯積磊張彥鐸吳云韜馬佳義
計算機研究與發展 2021年2期
周華兵 侯積磊 吳 偉 張彥鐸 吳云韜 馬佳義
1(武漢工程大學計算機科學與工程學院 武漢 430205)2(智能機器人湖北省重點實驗室(武漢工程大學) 武漢 430205)3(武漢大學電子信息學院 武漢 430072)(zhouhuabing@gmail.com)
圖像融合是一種增強技術,其目的是將不同類型傳感器獲取的圖像結合起來,生成一幅信息豐富的圖像,以便于后續處理[1].通過不同類型傳感器獲取的圖像一般并不是對齊的,會有一定的偏移,需要配準后才能融合[2-4].本文主要解決精確配準條件下的圖像融合問題,其在語義上具有逐像素(per pixel)的對應關系.
紅外和可見光圖像融合是圖像融合的重要分支,紅外圖像可以根據輻射信息來突出目標,并且不受天氣和光線的影響,可見光圖像擁有較高的分辨率,圖像更清晰,符合人類視覺習慣[5-8].紅外和可見光圖像融合既可以保留紅外圖像的對比度信息,又可以保留可見光圖像的高分辨率.
傳統的圖像融合方法多是基于多尺度分解的思路.包括拉普拉斯金字塔變換(Laplacian pyramid transform, LP)[9]、雙樹復小波變換(dual-tree complex wavelet transform, DTCWT)[10]、非下采樣輪廓波變換(nonsubsampled contourlet transform, NSCT)[11]等方法.隨著視覺顯著性相關研究的深入,出現越來越多基于視覺顯著性的圖像融合方法.Zhang等人[12]提出一種基于顯著性區域提取的紅外和可見光圖像融合方法.首先基于顯著性分析和自適應閾值算法提取出紅外圖像的目標區域,然后采用非下采樣剪切波變換得到背景區域融合系數,完成融合任務.但這種方法得到的融合圖像中目標區域直接使用了紅外圖像中的目標區域,丟失了可見光圖像中相應區域的信息.
隨著深度學習的火爆,近年來,基于深度學習的紅外和可見光圖像融合方法越來越多.如:Ma等人[13]的FusionGAN使用生成式對抗神經網絡來完成融合任務,通過生成器和鑒別器的對抗,來使融合圖像保留更豐富的信息.Zhang等人[14]的PMGI從圖像梯度和對比度2條路徑來提取圖像信息,并且在同一條路徑上使用特征重用,以避免由于卷積而丟失圖像信息.同時,在2條路徑之間引入了路徑傳遞塊,實現了不同路徑間的信息交換,保證了融合圖像有更豐富的信息.但這些融合方法都是將紅外和可見光圖像整體放進同一個網絡框架下,對源圖像中的目標和背景采用同一種處理方式,沒有針對性,不可避免地損失了源圖像的部分信息.
紅外和可見光圖像具有豐富的語義信息,語義信息可以用來提取圖像中的目標區域,也可以遮擋圖像中的干擾區域.語義分割可以將圖像轉換為具有語義信息的掩膜,是計算機視覺研究的熱門方向[15].一般的分類卷積神經網絡(convolutional neural network, CNN),會在網絡的最后加入一些全連接層,經過softmax后就可以獲得類別概率信息.但是這個概率信息是1維的,即只能標識整個圖像的類別,不能標識每個像素點的類別.Long等人[16]提出的全卷積網絡(fully convolutional network, FCN)將CNN的全連接層替換成卷積層,這樣就可以獲得一幅2維特征圖,從而成功解決了語義分割問題.Chen等人[17]提出的Deeplabv3+采用了編碼解碼網絡結構,逐步重構圖像空間信息來更好的捕捉物體邊界.并在網絡結構中引入了空間金字塔池化模塊(spatial pyramid pooling, SPP),利用多種比例感受野的不同分辨率特征來挖掘圖像多尺度的上下文內容信息.
為了在融合任務中更具有針對性地保留源圖像目標和背景區域的信息,本文基于語義分割和生成式對抗神經網絡提出了一種新的紅外和可見光圖像融合方法,在融合任務中引入語義分割,實現了圖像融合時對目標區域和背景區域采用不同的融合策略,解決了現有融合方法對源圖像不同區域針對性不足的問題.本文的融合結果在目標區域保留了紅外圖像的對比度,在背景區域保留了可見光圖像的紋理細節,圖像信息更豐富,視覺效果更好.
1 融合方法
為了實現對目標和背景區域融合時的不同偏好,本文提出一種基于語義分割的紅外和可見光圖像融合方法,流程圖如圖1所示,步驟如下:
1) 通過語義分割,得到帶有紅外圖像目標區域語義信息的掩膜Im.
2) 使用掩膜Im帶有的語義信息來處理紅外圖像Ir和可見光圖像Iv,得到紅外圖像的目標區域Ir1和背景區域Ir2,以及可光圖像的目標區域Iv1和背景區域Iv2.
3) 將紅外圖像的目標區域Ir1和可見光圖像的目標區域Iv1融合得到融合圖像If1.
4) 將紅外圖像的背景區域Ir2和可見光圖像的背景區域Iv2融合得到融合圖像If2.
5) 將If1和If2融合得到最終融合圖像If.

Fig. 1 Schematic of infrared and visual image fusion based on semantic segmentation圖1 基于語義分割的紅外和可見光融合
2 語義分割
紅外和可見光圖像融合是為了融合圖像目標區域保留更多的紅外圖像信息,背景區域保留更豐富的可見光圖像信息[18].為了達到這個目的,本文將語義分割引入圖像融合,用帶有語義信息的掩膜提取紅外和可見光圖像的目標和背景區域.
我們將紅外圖像和與之對應的標注圖作為輸入,訓練語義分割網絡,這里采用Deeplabv3+網絡結構.通過此網絡,可以得到帶有紅外圖像語義信息的掩膜Im,然后使用掩膜Im提取出紅外圖像目標區域Ir1和可見光圖像目標區域Iv1,如式(1)所示:
Ir1=Im⊙Ir,Iv1=Im⊙Iv.
(1)
接著,再使用掩膜Im將源圖像中的目標區域遮擋起來,得到紅外圖像背景區域Ir2和可見光圖像背景區域Iv2,如式(2)所示:
Ir2=(1-Im)⊙Ir,Iv2=(1-Im)⊙Iv,
(2)
其中,⊙為Hadamard乘積.
3 圖像融合
3.1 分割圖融合
由于融合圖像中目標區域和背景區域需要保留的信息差別較大.本文提出的融合方法對目標區域Ir1和Iv1以及背景區域Ir2和Iv2采用不同的融合策略,以便在融合圖像不同區域能更具有針對性的保留所需要的信息.
目標區域Ir1和Iv1是為了保留更多紅外圖像的對比度,要讓融合圖像If1更接近紅外圖像目標區域Ir1,網絡框架如圖2所示.生成器G1的目標是生成融合圖像If1去騙過鑒別器D1,鑒別器D1的目標就是將生成融合圖像If1和可見光圖像目標區域Iv1區分開來,通過這種對抗過程,網絡最終能得到信息豐富的融合圖像If1.

Fig. 2 Schematic of target area fusion圖2 目標區域融合網絡結構圖
首先將源圖像目標區域Ir1和Iv1在通道維度上連接起來,一起輸入到生成器G1得到融合圖像If1,通過損失函數讓融合圖像If1保留更多紅外圖像目標區域Ir1的信息,生成器G1損失函數如式(3)所示:
LG1=Ladv1+λ1L1,
(3)
其中,LG1代表生成器G1整體的損失,λ1是常數,用于平衡2項損失函數L1和Ladv1.Ladv1代表生成器G1和鑒別器D1之間的對抗損失,如式(4)所示:
(4)
其中,N代表融合圖像的數量,c代表生成器G1希望鑒別器D1相信的融合圖像的值.
生成器G1損失函數中的第2項L1代表目標區域內容損失,如式(5)所示:

(5)
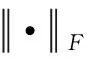
生成器G1在沒有鑒別器D1時生成的融合圖像會損失大量可見光圖像目標區域Iv1的信息.通過生成器G1和鑒別器D1對抗過程,融合圖像If1中能加入更多可見光圖像目標區域Iv1的信息,鑒別器D1的損失函數如式(6)所示:

(6)
其中,a和b分別代表Iv1和If1的標簽,D1(Iv1)和D1(If1)分別代表Iv1和If1的鑒別結果.
對于背景區域Ir2和Iv2,整體網絡框架和目標區域融合網絡框架一樣采用了生成式對抗神經網絡,如圖3所示.為了要讓融合圖像If2更接近可見光圖像的背景區域Iv2,我們重新設計了生成器G2和鑒別器D2的損失函數,生成器G2的損失函數如式(7)所示:
(7)
其中,LG2代表生成器G2整體的損失,λ2是常數,用于平衡2項損失函數L2和Ladv2.Ladv2代表生成器G2和鑒別器D2之間的對抗損失,如式(8)所示:
(8)
其中d代表生成器G2希望鑒別器D2相信的融合圖像的值.
生成器G2損失函數中的第2項L2代表背景區域內容損失,如式(9)所示:

(9)
其中ξ2是常數,用于平衡括號內的左右2項.
生成器G2在沒有鑒別器D2時生成的融合圖像會損失大量紅外圖像背景區域Ir2的信息.通過生成器G2和鑒別器D2對抗過程,融合圖像If2中能加入更多紅外圖像背景區域Ir2的信息,鑒別器D2的損失函數如式(10)所示:
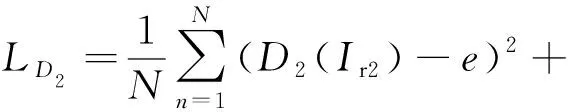
(10)
其中,e和f分別代表Ir2和If2的標簽,D2(Ir2)和D2(If2)分別代表Ir2和If2的鑒別結果.
3.2 目標和背景的融合
語義分割后的圖像有很多像素為0的區域,這些區域雖然不帶信息,對生成器讀取圖像信息沒有影響,但在生成融合圖像時,生成器并不能完美識別這些區域,會在這些區域根據學習到的風格生成像素值.為了避免這些像素影響最終融合圖像,我們先通過掩膜Im帶有的語義信息將融合圖像If1中的目標部分提取出來,同時將融合圖像If2中的背景部分提取出來,如式(11)(12)所示:
I1=Im⊙If1,
(11)
I2=(1-Im)⊙If2.
(12)
經過處理后的圖像I1在目標區域以外區域像素值都為0,I2在背景區域以外區域像素值都為0,我們直接通過簡單的像素相加得到最終融合圖像If,如式(13)所示:
If=I1+I2.
(13)
3.3 訓練過程
本文從公開的對齊數據集TNO(1)https://github.com/Jilei-Hou/FusionDataset中選取了45對不同場景的紅外和可見光圖像作為訓練數據,通過掩膜的語義信息將45對訓練數據都分為紅外圖像目標區域、紅外圖像背景區域、可見光圖像目標區域、可見光圖像背景區域4部分.由于45對紅外和可見光圖像不足以訓練一個好的模型,所以本文將stride設置為14來裁剪每一幅圖像,裁剪后每個圖像塊的尺寸都是120×120.這樣,我們可以得到23 805對紅外和可見光圖像塊.
對于目標區域Ir1和Iv1,我們從訓練數據中選擇32對目標區域的紅外和可見光圖像塊,將它們的尺寸填充到132×132作為生成器G1的輸入.生成器G1輸出的融合圖像塊尺寸為120×120.然后,將32對目標區域的可見光圖像塊和融合圖像塊作為鑒別器D1的輸入.我們首先訓練鑒別器k次,優化器的求解器是Adam,然后訓練生成器,直到達到最大訓練迭代次數.在測試過程中,我們不重疊地裁剪測試數據,并將它們批量輸入到生成器G1中.然后根據裁剪的先后順序將生成器G1的結果進行拼接,得到最終的融合圖像.
對于背景區域Ir2和Iv2,訓練過程中對訓練數據裁剪的尺寸與目標區域相同,生成器G2的輸入為32對背景區域的紅外和可見光圖像塊,鑒別器D2的輸入為32對背景區域的紅外圖像塊和融合圖像塊.在測試過程中,同樣根據裁剪先后順序將生成器G2的結果進行拼接,得到最終的融合圖像.
4 實驗與結果分析
本文提出的方法在融合任務中引入了語義分割,為此,我們首先需要構建基于語義分割的紅外和可見光圖像融合數據集.其次,為了評估本文融合方法的性能,本文選取了FusionGAN,PMGI作為對比實驗,通過主觀和客觀2方面對融合圖像進行比較,所有對比實驗代碼都是公開的源代碼,參數均是默認的參數.
4.1 數據集
本文實驗所使用的紅外和可見光圖像來源于公開的對齊數據集TNO.我們首先將圖像尺寸統一為450×450,然后挑選出紅外圖像的目標區域,使用labelme工具對目標區域進行標注,得到紅外圖像目標區域的標注圖(2)https://figshare.com/articles/dataset/TNO_Image_Fusion_Dataset/1008029,再使用Deeplabv3+網絡得到帶有紅外圖像語義信息的掩膜,通過掩膜的語義信息將紅外和可見光圖像分為紅外圖像目標區域、紅外圖像背景區域、可見光圖像目標區域、可見光圖像背景區域4部分.論文發表之后,我們會公開基于語義分割的紅外和可見光圖像融合數據集.對比實驗FusionGAN和PMGI所使用數據與本文實驗數據相同,且都將圖像尺寸統一為450×450.
4.2 主觀評估
主觀性能評估是基于人眼視覺系統來評價融合圖像質量,因為可見光圖像符合人類視覺習慣,所以紅外和可見光融合圖像應該在一定程度上符合人類視覺習慣.
為了驗證本文融合方法的主觀性能,選取了幾幅圖像作為評估數據,如圖4所示,前2行分別是紅外圖像和可見光圖像,第3行是掩膜,第4行是FusionGAN的融合結果,第5行是PMGI的融合結果,第6行是本文的融合結果.

Fig. 4 Fusion results of different methods圖4 不同方法融合結果
本文的融合方法通過引入語義分割,實現了對目標和背景區域采用不同的融合策略,與FusionGAN和PMGI相比,3組融合圖像中,本文方法的融合結果目標區域保留的對比度信息更豐富,能更好地突出目標,有利于目標檢測.背景區域本文的融合結果紋理細節保留的更好,第1組融合結果中,方框內樹干的邊界清晰,顏色保留的也更接近可見光圖像,其他2組結果也是這樣,特別是在第3組融合結果中表現最明顯,相比與FusionGAN和PMGI,我們的融合結果在樹梢的細節和天空的顏色上視覺效果都更好.這說明在融合任務中引入語義信息的方法是可行的,融合圖像視覺效果明顯優于現有的方法.
4.3 客觀評估
主觀性能評估雖然能根據人類視覺系統來評估融合圖像的質量,但是會受人類主觀情緒的影響,為了更全面地評估融合圖像的質量,本文還采用了客觀性能評估.客觀性能評估是依賴于數學模型的評估指標,不受人類視覺系統和主觀情緒的干擾,是評價融合圖像質量的重要手段,但單一的客觀評估指標不能充分反映融合圖像的質量,因此,本文采用了3種典型的客觀評估指標,分別是熵(EN)、標準差(SD)和互信息(MI).
1) 熵
熵(EN)是統計圖像特征的一種常用方法,融合圖像的熵反映了圖像從紅外和可見光圖像中獲取的信息的多少[19],數學定義如式(14)所示:
(14)
其中,L表示圖像灰度級,pl是融合圖像中灰度值為l的標準化直方圖.熵的值越大,說明融合圖像中保留的源圖像的信息越豐富,融合方法的性能越好.
2) 標準差
標準差(SD)反映了圖像灰度值相對于灰度平均值的離散情況[20],定義如式(15)所示:
(15)
其中,F(i,j)表示融合圖像F在(i,j)處的像素值,融合圖像F的尺寸為M×N,μ表示融合圖像的像素平均值.由于人類視覺系統對對比度信息很敏感,人類的注意力會被高對比度區域所吸引.因此,融合圖像的標準差越大表明融合圖像對比度越高,意味著融合圖像的視覺效果更好.
3) 互信息
互信息(MI)是信息論中的基本概念,可以度量2個隨機變量之間的相關性.在圖像融合中互信息用來度量源圖像和融合圖像的相關性[21].紅外和可見光圖像融合互信息定義如式(16)所示:
MI=MIr,f+MIv,f,
(16)
其中MIr,f和MIv,f分別表示紅外圖像和可見圖像與融合圖像的相關性.任意一幅源圖像和融合圖像之間的互信息可用定義如式(17)所示:

(17)
其中,pX(x)和pF(f)分別表示源圖像X和融合圖像F的邊緣直方圖.pX,F(x,f)表示源圖像X和融合圖像F的聯合直方圖,互信息越大意味著融合圖像與紅外和可見光圖像相關性越大,融合性能越好.
使用熵、標準差和互信息對5組圖像進行客觀性能評估,實驗結果如表1所示:

Table 1 Objective Evaluation of Fusion Results表1 融合結果客觀評估
通過實驗表明,相比FusinGAN和PMGI,本文提出的基于語義分割的紅外和可見光圖像融合方法在3個客觀評估指標上表現均為最佳.
熵和互信息有最優的值表明,本文的融合結果從紅外和可見光圖像中獲得的總信息量最多,說明本文的融合方法確實是有效的融合方法,能保留豐富的源圖像信息.標準差有最優的值表明,本文的融合圖像對比度更高,證明通過引入語義信息,針對性的對目標區域和背景區域采用不同融合方法是有效的,實現了融合圖像在目標區域保留更多紅外圖像信息,背景區域保留更多可見光圖像信息.
FusionGAN,PMGI和本文方法的平均運行時間分別為0.058 6 s,0.032 2 s,0.111 8 s.因為本文提出的方法需要目標區域融合網絡和背景區域融合網絡2個不同的網絡,所以本文方法的平均運行時間相比FusionGAN和PMGI有一定增長,但本文方法的融合結果在主客觀上相比現有方法提升更為明顯.
5 結 論
本文在原有的基于深度學習的紅外和可見光圖像融合方法基礎上,通過語義分割引入圖像語義信息,對源圖像目標區域和背景區域采用不同的融合方法,以求得到質量更高的融合圖像.實驗表明,相比現有方法,本文提出的方法達到了預期的效果,融合圖像目標區域保留了大量的對比度信息,背景區域保留豐富的紋理細節信息,在主觀和客觀上都有更好的融合效果.
猜你喜歡
汽車工程師(2021年12期)2022-01-17 02:29:54
當代陜西(2020年14期)2021-01-08 09:30:42
開放教育研究(2020年2期)2020-03-31 01:54:14
貴州師范學院學報(2016年4期)2016-12-01 03:54:07
現代語文(2016年21期)2016-05-25 13:13:44
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
大連民族大學學報(2015年2期)2015-02-27 08:28:11
民生周刊(2012年10期)2012-10-14 09:06:46
