一種基于RDMA多播機制的分布式持久性內存文件系統
2021-02-07 02:51:34陳茂棠鄭圣安游理通王晶鈺屠要峰韓銀俊黃林鵬
計算機研究與發展 2021年2期
關鍵詞:機制
陳茂棠 鄭圣安 游理通 王晶鈺 閆 田 屠要峰 韓銀俊 黃林鵬
1(上海交通大學計算機科學與工程系 上海 200240)2(清華大學計算機科學與技術系 北京 100084)3(中興通訊股份有限公司 南京 210012)(chenmaotang@sjtu.edu.cn)
新型的非易失性內存(non-volatile memory, NVM)[1-5]技術的出現為傳統的計算機存儲結構帶來變革,其中通過內存總線連接CPU的NVM形態也被稱為持久性內存(persistent memory, PM).與DRAM相比,持久性內存擁有相接近的傳輸帶寬與訪問延遲,但兼具了DRAM不具備的持久性.隨著持久性內存的逐漸應用,許多研究針對持久性內存設計特異性的文件系統,其中大多數文件系統基于單臺機器設計[6-10].但是目前大容量的持久性內存價格昂貴,單機存儲容量難以提高.同時,持久性內存運行帶來較高的CPU負載,單機大規模部署持久性內存會使CPU成為存儲性能的瓶頸.這些原因使得單機持久性內存文件系統難以滿足日益增長的大規模數據存儲需求,必須開發基于持久性內存的分布式文件系統.
多播技術同樣在分布式系統中發揮著重要的作用.多播技術的應用范圍很廣,從多媒體數據的直播分發,到數據中心的分布式文件系統,均需要多播技術的支持.尤其是在數據中心中,數據傳輸通常是從源節點到2個甚至多個目標節點,文件數據需要被復制到多個存儲服務器[15].這個過程造成的延遲往往占數據中心負載的主要部分,并最終決定了系統的總體IO性能[16].
盡管多播技術在系統中起到重要的作用,但是在現有的基于RDMA的分布式文件系統中,往往沒有提供多播傳輸的支持[13-14].在需要1對多傳輸的場景下,這些系統通常使用每次傳輸到1個節點的方法,將數據依次推送到所有的目標節點[17].為了解決該問題,康奈爾大學的RDMC基于RDMA的1對1傳輸開發了多播通信框架[18].但是,由于這種框架的底層依然是基于1對1的連接進行通信,當多播操作的目標節點較多時,需要占用大量的網卡資源,導致系統難以基于框架進行有效的擴展.另外,基于框架的編程較為復雜,不利于分布式系統的應用與維護.其他解決方案在獲得可擴展性的同時,往往為傳輸過程引入了額外的復制與延遲,同樣沒有辦法很好地解決分布式系統中的多拷貝文件數據傳輸問題[19].
本文提出了一種基于RDMA多播傳輸機制的分布式持久性內存文件系統(RDMA multicast trans-mission based distributed persistent memory file system, MTFS).通過使用RDMA多播通信語句,實現元數據節點與數據節點之間的1對多通信,提升數據傳輸效率.具體地,MTFS實現了低延遲多播通信機制,基于RDMA多播通信語句搭建內核態RDMA通信模塊,將文件系統中1對多的傳輸請求使用多播通信機制發送,并添加無通知機制與擁塞控制來優化RDMA傳輸,從而避免了傳統1對1傳輸機制帶來的冗余傳輸開銷.為提升傳輸的靈活性,對分布式文件系統各項功能提供支持,MTFS基于多播通信機制設計多模式遠程過程調用(remote procedure call, RPC)框架,發送端將請求相關信息寫入RPC頭部,接收端通過接收處理程序解析相關信息,從而定位要執行的操作地址與操作類型,保證相應文件系統功能得到執行.為保證多播傳輸機制的一致性,MTFS引入輕量級一致性保障機制,利用持久性內存字節尋址的特性實現錯位的快速糾正,并支持在數據無法恢復時請求重傳.節點發生故障時,MTFS為元數據節點與數據節點均提供了故障恢復機制,保證文件數據的一致性與可靠性.
本文的主要貢獻有3個方面:
1) 提出基于RDMA多播機制的分布式持久性內存文件系統MTFS,實現了內核態RDMA通信模塊,通過將文件系統中1對多請求使用RDMA多播語句發送,避免了額外的開銷.
2) 提出基于多播傳輸機制的多模式RPC設計,提升數據傳輸的靈活性,為分布式文件系統各項功能提供支持.
3) 引入輕量級一致性保障機制,使用冗余校驗機制保證數據傳輸過程的可靠性,利用持久性內存字節尋址的特性實現錯位的快速糾正,并為系統中的各個節點提供故障恢復功能,從而保證數據的可靠性與一致性.
1 背景介紹
本節主要介紹了持久性內存技術與遠程內存直接訪問技術的基本特征,同時簡要介紹與MTFS相關的NOVA文件系統實現細節.
1.1 持久性內存
持久性內存是一種新興的硬件技術,主要包括相變存儲器(phase-change memory, PCM)、憶阻器、自旋矩存儲器(spin-torque transfer ram, STT-RAM)和3D XPoint等技術[1-4],其中基于3D XPoint的英特爾傲騰持久內存目前已經投入市場使用[5].
持久性內存的出現打破了內外存之間的界限,顛覆了傳統的存儲體系結構.一方面,持久性內存作為一種內存,擁有內存的種種特性.持久性內存可直接連接于高帶寬的內存總線上,傳輸帶寬和訪問延遲均與DRAM相接近,并支持字節尋址訪問.同時,與DRAM相比,持久性內存具有更高的存儲密度和更低的能耗,這為搭建大規模內存文件系統提供了基礎.另一方面,持久性內存作為一種持久性存儲介質,與傳統的硬盤和SSD相比,具有更高的帶寬和更低的訪問延遲.同時,由于CPU可以直接對持久性內存上的數據進行訪問,數據可以繞過DRAM,無需在內存和存儲之間進行遷移,數據訪問的整體性能得到了大幅的提升.
持久性內存為文件系統的設計提出了新的要求.基于持久性內存的文件系統可以直接通過loadstore指令讀寫持久性內存.一些文件系統專為持久性內存進行特異性設計[6-9,20],另一些文件系統則基于現有文件系統進行改動[10,21],通過添加直接訪問能力,允許應用程序繞過頁緩存直接訪問持久性內存,從而實現了文件系統對持久性內存的適配.
1.2 遠程直接內存訪問
近年來,RDMA技術在業界受到越來越廣泛的關注[11,22-24].RDMA技術允許應用程序在不告知遠端CPU情況下,繞過內核直接訪問遠端內存,實現零拷貝的數據傳輸,從而實現高帶寬且低延遲的遠端內存訪問[25].目前,RDMA傳輸性能已遠優于現有的固態硬盤和機械硬盤的讀寫性能,如果仍使用固態硬盤或者機械硬盤搭配RDMA網絡實現分布式文件系統,存儲介質的高延遲將使系統無法充分發揮RDMA網絡的性能優勢,同時文件系統也無法繞過DRAM直接寫入存儲介質.而持久性內存低延遲內存訪問的特性,使其能有效適配RDMA技術,實現高效的遠程存儲訪問.
RDMA主要提供單邊語句和雙邊語句2種傳輸語句支持.表1展示了每種傳輸語句對應的類型.單邊語句主要包括READ和WRITE語句,這些語句可以繞過遠端節點的CPU,直接對遠端內存進行讀寫操作.此外,RDMA單邊語句還包括compare_and_swap 和fetch_and_add等原子性語句,使RDMA能夠對遠端內存進行原子性訪問.雙邊語句主要包括SEND和RECV語句,采用類似于socket編程的方式,發送端和接收端均需要CPU參與.在發送端進行SEND操作之前,接收端需要提前準備1個RECV請求并放入網卡,該請求中包含待接收數據的地址.

Table 1 Verbs Type of Each Transport Verb表1 每種傳輸語句對應的語句類型
RDMA通過隊列對(queue pair, QP)進行傳輸操作.每個隊列對包括1個發送隊列(send queue, SQ)和1個接收隊列(receive queue, RQ).當進行傳輸時,使用RDMA的程序首先根據其傳輸的內容填充1個工作請求(work request, WR),并將其發布到發送隊列上.RDMA網卡會依次處理隊列上的WR,執行對應的傳輸操作.當傳輸完成時,網卡會在完成隊列(completed queue, CQ)上發布1個工作完成(work completion, WC)信息,通知CPU進行相應處理.如果是雙邊操作,接收端在傳輸進行之前還需要提交1個RECV WR并放入其接收隊列.
RDMA包括有連接和無連接2種形式.有連接的傳輸提供2個QP之間的1對1通信,若需要與多個節點進行通信,則需要創建多個QP分別與多個節點進行1對1通信.而無連接的傳輸基于數據報實現,通信節點之間不需要創建連接,每個QP可以和多個QP進行通信.用戶可以選擇可靠或不可靠的RDMA傳輸類型.可靠的傳輸可以按照順序交付信息,并在傳輸失敗時返回錯誤信息.不可靠的傳輸則無法提供可靠性保證,但是其通過避免發送確認信息獲取更高的性能.使用不可靠傳輸,RDMA通過數據鏈路層提供的一致性保障機制仍可以在很大程度上保證數據傳輸的可靠性[22].
基于傳輸是否有連接與是否可靠,RDMA提供了3種主要的傳輸方式:可靠連接(reliable connec-tion, RC),不可靠連接(unreliable connection, UC)和不可靠數據報(unreliable datagram, UD).表2展示了每種傳輸方式可以支持的傳輸語句.可以看到,不同的傳輸方式所支持的傳輸語句不同,RDMA單邊操作只在有連接的傳輸方式下支持,而RDMA多播傳輸只在UD模式下支持,因此用戶需要根據傳輸需求選擇對應的傳輸方式.
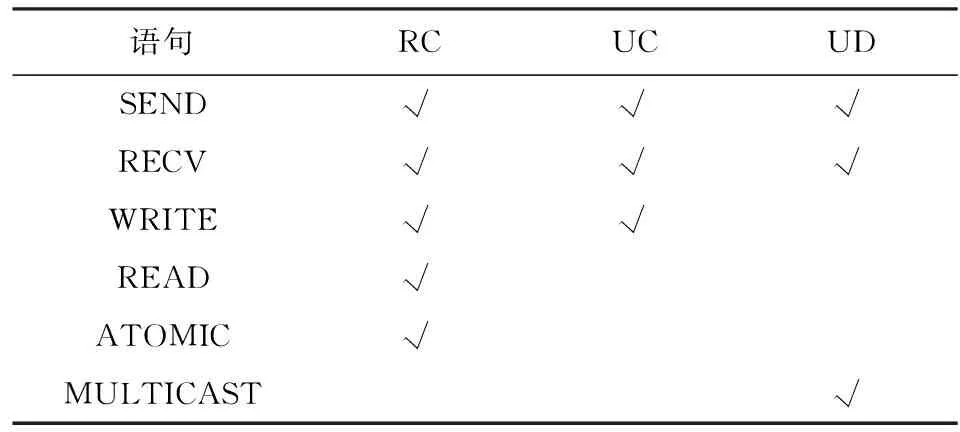
Table 2 Verbs Supported by Each Transport Type表2 每種傳輸方式支持的傳輸語句
RDMA提供了多播語句支持[26].多播語句是UD模式下雙邊語句的一種特殊形式.用戶使用多播語句進行RDMA通信時,首先將所有需要通信的節點加入同一個多播組.發送信息時,目標地址設定為多播組的地址,發送端僅需要1次發送操作,發送成功后,所發送的信息通過交換機被分發到多播組中的各個節點.多播語句為1對多的傳輸場景提供了合適的解決方案,降低了多節點數據傳輸的開銷,為解決基于RDMA的分布式系統中的多拷貝文件數據傳輸問題提供了有效的支持.
1.3 NOVA文件系統
MTFS是基于NOVA實現的.NOVA是加州大學圣地亞哥分校開發的一種持久性內存文件系統[6].為更好地利用持久性內存的諸多優秀特性,NOVA做了許多特異性的設計,使其在保證一致性的基礎上提升文件系統的性能.本節討論與MTFS相關的一些NOVA設計.
NOVA為每個索引節點維護1個單獨的日志鏈表,每塊日志中存儲1次寫入的基本信息與指向寫入數據頁的指針,同時在DRAM中維護基數樹索引以加速對文件數據的查找.寫入操作使用寫時復制機制實現,每次寫入時會申請新的日志塊與數據頁,在日志中記錄操作相關信息與指向新寫入數據的指針.當數據成功寫入持久性存儲介質后,NOVA更新文件日志的尾指針以及其對應的基數樹索引.當讀取數據時,NOVA通過基數樹索引找到對應的日志塊,從日志中讀取數據地址,并通過地址找到數據頁并讀取數據.
NOVA使用可利用空間表管理持久性內存空間.NOVA將可用的數據空間均分給每個CPU進行管理以提升并發文件訪問的性能,每個CPU使用紅黑樹結構管理數據空間中的空閑塊,以提升連續數據塊查找的性能.通過這種方式,NOVA提升了持久性內存空間分配操作的并行性,減少了空間分配的爭用.
NOVA提供了故障恢復機制.當系統從故障中恢復時,首先,NOVA需要檢查崩潰前寫入的日志,通過日志將未提交的事務回滾.然后,NOVA并行掃描每個索引節點,通過日志鏈表恢復數據組織結構.通過日志設計,NOVA保證系統可以從故障中恢復數據.
2 MTFS設計
本節將詳細介紹MTFS的系統設計.首先整體描述MTFS的系統架構,然后分別對MTFS中的低延遲多播通信機制、多模式多播RPC機制和輕量級一致性保障機制進行介紹.
2.1 系統架構
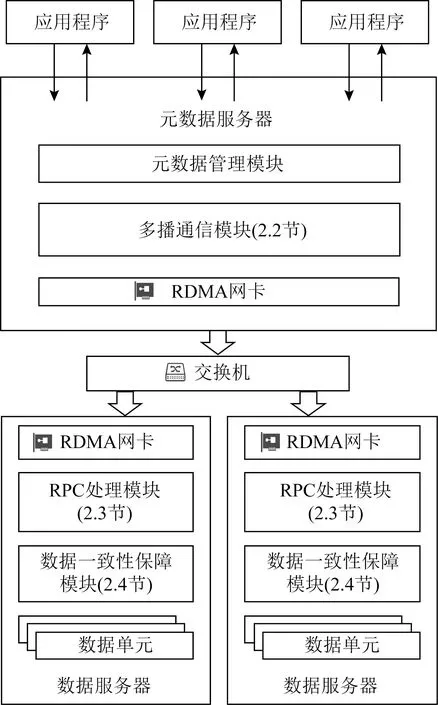
Fig. 1 Overall architecture of MTFS圖1 MTFS系統整體架構
圖1展示了MTFS的系統整體架構.系統由1個元數據節點和多個數據節點組成.其中元數據節點存儲系統的元數據信息,包括文件的元數據信息和系統的基本配置與空間管理信息,數據節點中僅存儲文件的數據.元數據節點與數據節點之間通過RDMA網絡互連.MTFS采用主從式架構,將數據存儲在多個數據節點上,提升了數據訪問的并行性.
應用程序通過可移植操作系統接口(portable operating system interface of UNIX, POSIX)對文件系統進行訪問.以數據寫入為例,當應用程序發起數據寫入請求時,MTFS通過訪問元數據節點在各目標數據節點分配持久性內存空間,然后將數據寫入到各數據節點中.待寫入的數據通過多播通信模塊(2.2節)以RDMA數據報的形式由網卡發出.網絡交換機收到多播數據報時,會進行分發操作,將數據報發送到多播組中的每個數據節點.數據節點通過RPC處理模塊(2.3節)識別數據報請求體,并通過數據一致性保障模塊(2.4節)將數據持久化到持久性內存.與此同時,元數據節點會提交該次數據寫入操作并返回用戶.文件系統的元數據訪問則僅通過元數據節點進行,無需對數據節點進行遠程訪問.
2.2 低延遲多播通信機制
在分布式文件系統中,節點間的網絡傳輸的開銷非常高昂.數據節點間等待傳輸完成與確認需要耗費大量的時間,從而產生較高的延遲.而在1對多的分發場景下,傳統的文件系統會發起多次網絡傳輸請求,將相同的數據逐一發送到各個節點,增加了網卡的負載(圖2(a)).多播通信機制旨在將多個傳輸相同數據的請求合并為多播請求,避免網卡數據重復發送的冗余開銷,從而大幅提升發送數據的效率.
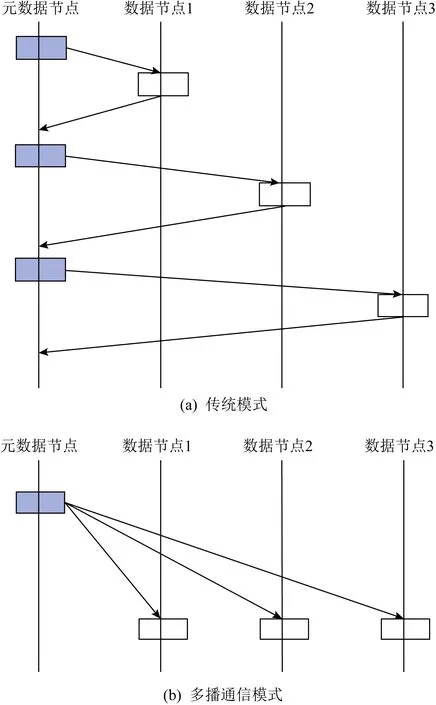
Fig. 2 Comparison of traditional and multicast schemes圖2 傳統模式與多播通信機制對比
當MTFS的元數據節點發起寫請求時,數據將被同時寫入所有的目標數據節點:首先多播傳輸模塊會申請1塊發送結構體,并根據寫請求對應的數據地址、數據大小等元數據信息填寫結構體的頭部字段,同時將數據放入發送結構體的數據字段.然后多播傳輸模塊會將RDMA傳輸信息添加到填寫完畢的發送結構體中,并將其打包成工作請求放入發送隊列進行傳輸;網卡依次對工作請求進行處理,將數據以RDMA數據報的形式發送到各個目標數據節點,由數據節點中的接收處理程序進行處理并寫入持久內存.當發送操作完成之后,元數據節點會觸發中斷通知發送完成處理程序,將工作完成從完成隊列中移出,從中獲取已完成的發送結構體地址并將對應空間釋放回收.執行過程如圖3所示.
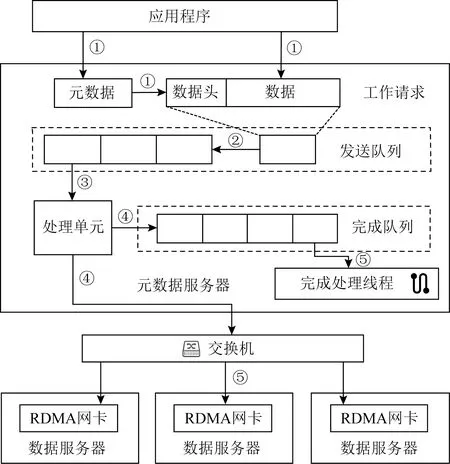
Fig. 3 Multicast transmission execution圖3 多播通信運行過程
為提升系統可擴展性,MTFS將數據節點劃分為存儲單元進行管理.MTFS將數據節點每2~3個一組劃分為存儲單元,單元內的數據節點存儲相同的數據,并和MTFS的元數據節點加入同一個多播組.多播信息僅在組內傳遞,由于不同存儲單元間存儲的數據互不相同,存儲單元之間不需要進行多播通信.當元數據節點發起寫入請求時,MTFS會選擇剩余空間最多的存儲單元,并將單元內的數據節點作為存儲的目標數據節點;當元數據節點發起讀取請求時,MTFS會根據對應存儲單元內各數據節點正在請求的線程數量,從中選擇負載最低的數據節點讀取數據.通過存儲單元管理,MTFS避免了數據冗余存儲,提升了系統的可擴展性.
為減少元數據節點CPU的開銷,MTFS通過RDMA無通知機制優化多播發送流程.由于RDMA的多播能力由UD模式提供,而UD模式基于無連接數據報實現,不需要處理接收端的確認信息.因此,當多播請求發送完畢后,多播傳輸模塊不會立即通知CPU進行處理,而是將工作完成暫存在完成隊列上.當完成一定數量的工作請求之后,為了防止工作完成的堆積,下一次發送的工作請求會被設置為完成后通知.當該工作請求發送完成后,網卡會觸發CPU中斷并轉入發送完成處理程序,對先前放入的工作完成進行批量處理.通過無通知發送的優化,MTFS減少了CPU中斷處理的次數,極大地降低了CPU的負擔.
為了避免網絡堵塞引起的發送隊列擁擠,MTFS實現了擁塞控制系統.RDMA的發送隊列長度固定,當網卡處理速率小于工作請求的增加速率時,發送隊列會被填滿,導致之后的工作請求無法放入發送隊列.MTFS多播傳輸模塊會對發送隊列中待發送的多播請求數目進行實時統計,并據此控制RDMA多播請求的發送速率.當網絡擁塞時,發送隊列中待發送的請求數目超過了預先設定的閾值.此時發送隊列將暫緩接受工作請求直到待發送的請求數量低于閾值,從而避免了發送隊列溢出造成的傳輸問題.
通過上述多播通信機制,MTFS減少了文件操作過程中RDMA的通信次數,并充分利用UD模式數據報通信的優勢降低了數據的傳輸延遲(圖2(b)).盡管RDMA的UD模式具有一定的可靠性[22],MTFS依然通過發送端的擁塞控制機制與接收端的一致性保障機制(2.4節),在不顯著增加延遲的情況下盡可能地保證數據的可靠性與一致性.
2.3 多模式多播RPC機制
MTFS使用RPC實現元數據節點與數據節點間通信.如圖4所示,RPC采用服務端主動的方式,元數據節點通過多播通信機制將RPC請求分發到數據節點的網卡上,并由網卡放入接收隊列等待處理.接收端處理程序按到達順序依次處理接收隊列中的RPC請求,對參數進行解析并執行相應的操作.
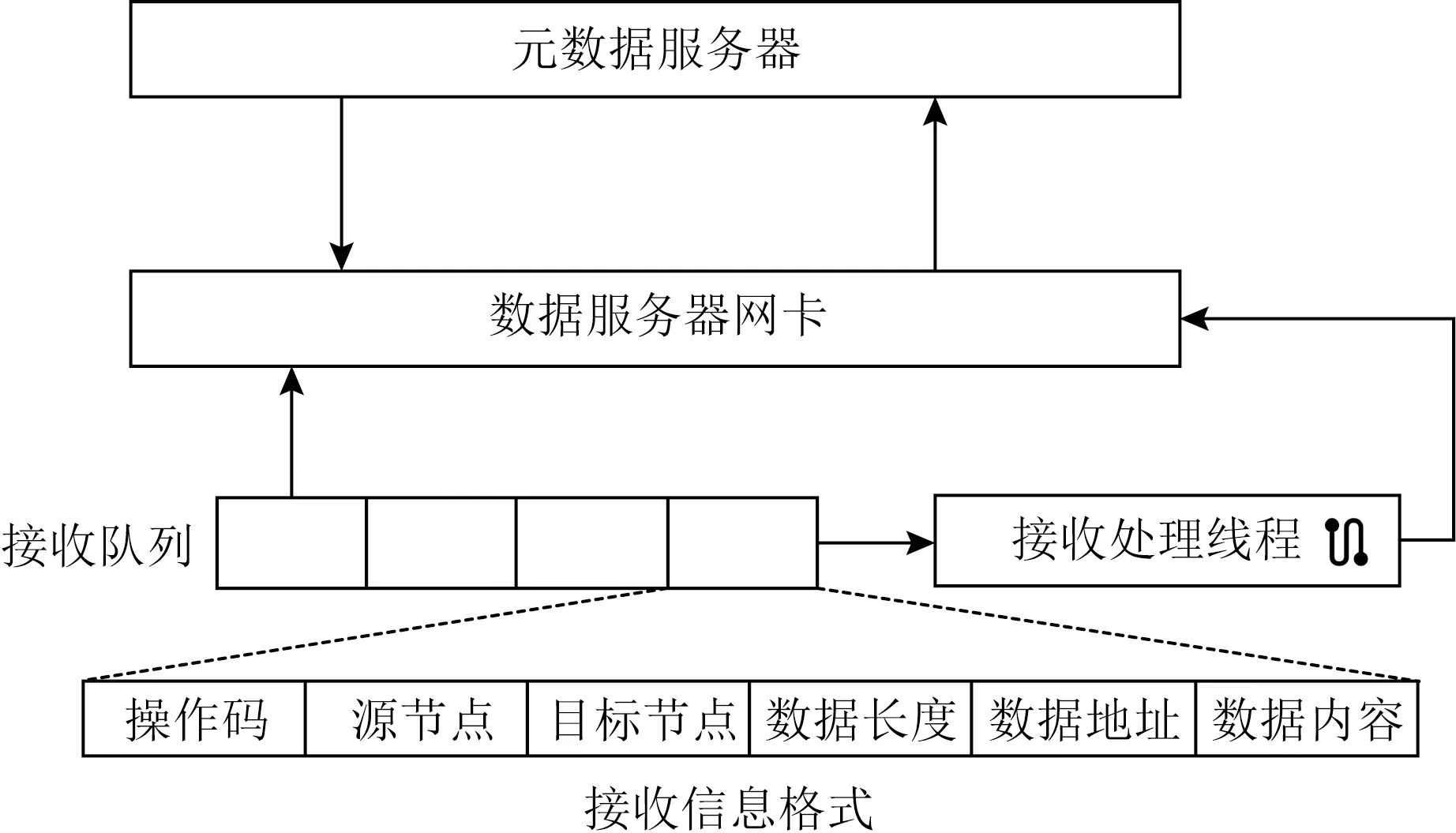
Fig. 4 RPC module design圖4 RPC模塊設計
RPC通過源節點字段和目標節點字段進行請求識別,從而判斷該節點是否需要進行處理.由于RPC采用多播通信機制實現,多播組中的所有數據節點均可以接收到元數據節點的請求.為增強RPC的靈活性,請求頭部標識了源節點與目標節點,數據節點收到請求后首先判斷該節點是否需要執行操作,從而避免冗余的請求對數據節點資源的占用.
RPC通過優化返回機制降低執行延遲.接收端根據其接收到的操作碼對請求進行分類:對于不需要返回信息的請求如數據寫,數據節點會直接執行相應操作,不發送返回信息;對于時效性要求較高的請求如數據讀,數據節點會立即進行處理并返回完成信息;對于時效性要求較低的請求如數據遷移,元數據節點采用異步處理機制,發送RPC請求之后繼續執行其他操作,不阻塞等待結果,當收到返回信息后再進行結果處理操作.而數據節點收到請求之后,會在優先處理其他請求之后進行處理并返回完成信息.通過RPC多模式分類,MTFS減少了部分操作的傳輸次數,并將部分傳輸操作從關鍵路徑移除,有效提升了文件操作的整體效率.
考慮到RPC基于多播通信機制,MTFS的寫請求使用RPC實現,保證寫請求通過多播語句1對多地發送到所有的數據節點.但鑒于讀請求針對單一客戶端的特性,MTFS在實現了基于RPC的讀方法的同時,采用基于RC模式的RDMA讀操作實現了對文件數據的讀取操作,避免了集群規模過大時使用多播通信機制讀數據造成的額外開銷.用戶掛載文件系統時,可以根據集群配置選擇合適的讀方法.
2.4 輕量級一致性保障機制
MTFS開發了故障恢復機制以有效應對各節點上可能發生的系統崩潰.MTFS檢測到數據節點崩潰后,會將該數據節點標記成為故障節點,讀請求將被分流到其他數據節點執行,不會影響系統正常運行.該數據節點中的數據可以通過元數據節點與其他數據節點進行恢復.當元數據節點崩潰時,系統停止提供服務,等待元數據節點重啟,并通過文件的元數據與數據日志,將系統恢復到崩潰前的狀態.通過故障恢復機制,MTFS保障了數據的高可靠性.
MTFS使用冗余校驗機制保證了數據傳輸的容錯性(圖5).發送端打包傳輸數據時,會將數據分為2部分并分別計算循環冗余校驗(cyclic redun-dancy check 32, CRC32),校驗結果存入發送請求的固定區域.同時,MTFS對2部分數據計算奇偶校驗結果并放入發送結構體.接收處理程序收到數據后會首先計算2部分數據的CRC32校驗和,與收到數據中存儲的校驗和進行比對.若2份數據校驗和與存儲的校驗和均相同,則說明本次數據傳輸沒有發生錯誤;若僅有1份數據校驗和與存儲的校驗和相同,說明另1份數據發生了傳輸錯誤.接收處理程序會通過奇偶校驗結果查找錯誤發生的位置,計算出正確的結果并寫入;若2份數據校驗和與存儲的校驗和均不相同,則該次傳輸可能出現了大面積無法恢復的錯誤,接收處理程序會激活重傳機制,發送1個重傳請求到發送端,請求重新發送該數據.通過冗余校驗機制,MTFS在不顯著影響性能的情況下保證了數據傳輸的正確性.
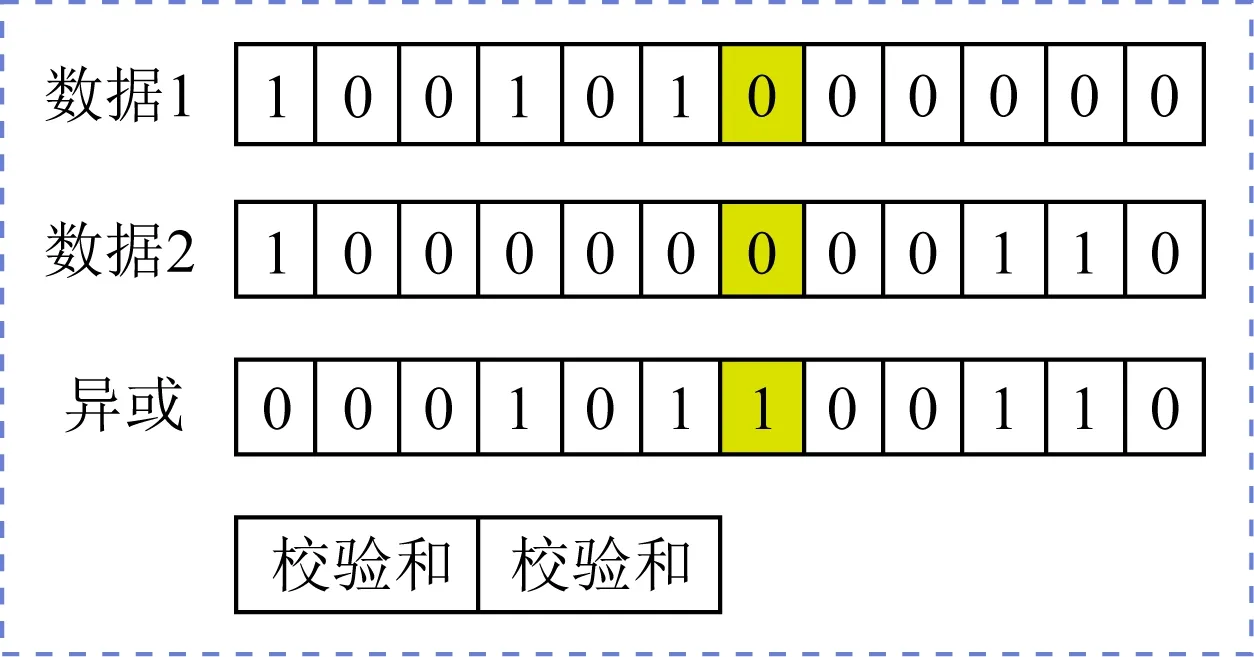
Fig. 5 Data verification mechanism圖5 數據冗余校驗機制
MTFS使用重傳機制保證文件數據的持久性.發送端申請工作請求時會指定全局唯一的WR_ID,并附在RDMA發送的立即數字段一同發送.接收處理程序會記錄來自同一個節點的最近1個請求的WR_ID,并在新的請求到達時讀取立即數字段進行比較.若新接收的請求出現亂序,接收處理程序會發送重傳請求到發送端,要求重傳缺失的工作請求.對于傳輸數據出現大面積錯誤的情況,接收處理程序會通過最新記錄的WR_ID計算出錯誤的WR_ID并發送重傳請求到發送端.發送端收到重傳請求時,會通過WR_ID查找相應的發送數據進行重新打包發送.
MTFS通過窗口確認機制保證了數據一致性.元數據節點記錄了每個索引節點最后1次寫入操作的WR_ID.各數據節點每隔一段時間會向元數據節點報告TAIL_WR_ID(即節點已成功接收在該WR_ID之前的所有請求).當元數據節點發起讀請求時,會檢查索引節點最后1次寫入的WR_ID和目標節點報告的TAIL_WR_ID,確認目標節點是否已經收到該索引節點的所有寫請求.若未收到,則說明還有寫請求正處于傳輸的過程中,系統會對讀請求進行阻塞,直到數據節點確認已收到所有的寫請求;若已收到,則元數據節點可以執行讀操作.通過窗口確認機制,MTFS避免了文件讀寫出現不一致,保證了數據一致性.
MTFS避免了RDMA網卡的數據一致性問題.當使用RDMA網卡對遠端地址進行數據寫入時,數據可能會暫時駐留在RDMA網卡的易失緩存中,由網卡決定寫入內存地址的時機,這可能導致數據不一致的問題[27].MTFS采用多播發送語句,遠端網卡接收到數據之后,會通知接收處理程序將數據寫入持久性介質,避免數據在RDMA網卡緩存中駐留,保證數據的一致性.
3 系統實現
本節主要講述了MTFS各項設計的實現方式與細節.雖然本文在NOVA的基礎上實現MTFS的各項功能設計,但MTFS的設計可以基于現有的單機持久性內存文件系統實現,不局限于某個系統的設計.
3.1 文件系統相關實現
MTFS基于NOVA的元數據組織實現元數據節點組織,并沿用了NOVA的元數據相關設計.由于MTFS元數據節點與數據節點分離的架構,MTFS優化了數據日志的格式,將各目標數據節點中對應的數據地址存入日志之中.同時,MTFS對所有的數據節點進行統一編址,使用NOVA的可利用空間表數據結構進行管理.每個CPU在每個數據節點上對應1個可利用空間表,并通過可利用空間表管理1塊持久性內存空間.當執行數據寫入操作時,元數據節點會從每個目標數據節點對應的區域中各分配1段空間,并通過RPC將數據遠程寫入.當執行數據讀取操作時,系統會按照日志塊中記錄的遠端數據的地址從遠端數據節點讀出數據.
3.2 RDMA通信模塊
MTFS實現了高效的內核態RDMA通信模塊.為了提升通用性,更好地與主流的基于POSIX接口的內核態文件系統適配,MTFS在內核態實現了RDMA通信.同時MTFS將RDMA服務以模塊的形式呈現,封裝RDMA的相關操作,將復雜的RDMA操作抽象為通信建立、通信關閉和操作執行等若干類函數,對文件系統屏蔽了RDMA通信的相關細節,方便相關代碼的移植與維護.
為了方便管理RDMA,MTFS使用RDMA_CM庫管理通信.RDMA_CM可以在RDMA傳輸建立之前,使用基于RDMA網絡的TCP傳輸在各節點間傳遞RDMA網絡參數,并據此建立RDMA傳輸.RDMA_CM將RDMA通信建立流程封裝成為類似于socket的接口,并在整個通信階段對通信進行管理.建立多播通信時,需首先對約定好的多播地址進行解析,當確認解析無誤后將解析到的設備綁定到CM_ID,然后各節點加入該多播組并注冊到子網管理器,從而完成多播通信的建立.對于多播傳輸請求,所有加入該多播組的節點均可以接收.通過使用RDMA_CM庫,MTFS簡化了RDMA編程操作.
MTFS實現了RDMA發送與接收請求的統一管理,從而支持了RDMA多播傳輸的各項優化.為了方便對網絡請求進行統一管理,MTFS在各節點上分別為RDMA發送與接收請求維護全局的工作請求鏈表.正常情況下,當有新的請求需要發送時,MTFS申請1個新的工作請求,相關信息填寫完畢后,會將工作請求放入鏈表,并生成全局唯一的WR_ID,WR_ID在發送時被放入數據報一起發送.當發送完成時,發送完成處理程序通過工作完成找到WR_ID,進而找到該次工作請求并回收相關數據結構.接收請求的情況與之類似.當無通知優化功能被啟用時,MTFS會記錄發送請求的數量,工作請求通知標志的默認值為0,當一定數量的數據發送完成后,下一個工作請求的通知標志會被置為signaled,發送完成之后通知處理程序對所有早先產生的工作完成統一進行處理.啟用擁塞控制時,MTFS使用原子變量記錄發送隊列上的待發送工作請求數量,通過該原子變量判斷是否暫緩接受發送請求.通過對RDMA請求的統一管理,MTFS實現了請求的添加、存儲、刪除與查找,為RDMA多播傳輸的各項優化提供了有效的支持.
3.3 RPC與一致性保障實現
MTFS為RPC傳輸設計了發送結構體.結構體中包含了該次操作的詳細信息,包括操作碼、源節點與目標節點、數據長度、數據地址和數據內容等,整個結構體經過冗余和校驗處理之后,會統一作為RDMA傳輸的數據進行發送.而工作請求的控制信息會根據請求類型和待發送數據進行填寫,其中立即數字段填寫全局唯一的WR_ID,填寫完畢之后放入發送隊列進行發送.接收端收到RPC請求之后,會讀取數據并對各字段進行解析,執行相應操作.
4 實 驗
本節將MTFS與其他文件系統對比,對各項性能進行評估.首先介紹實驗環境配置,然后從微觀測試、Filebench測試、Redis測試3個方面對比MTFS與現有的分布式和單機持久性內存文件系統,詳細比較并分析相關性能差異.
4.1 實驗配置
實驗所使用的實驗平臺環境配置信息如表3所示.各節點均部署4塊Intel Optane DC 128 GB持久性內存,并采用APP-Direct模式.各節點通過一塊Mellanox ConnectX-5 RDMA網卡與其他節點通信,網卡配置為Infiniband模式運行,并連接到Infiniband交換機.

Table 3 Platform Configuration表3 實驗平臺配置
MTFS使用NOVA的代碼作為基礎,在Linux 4.13內核上實現.MTFS基于Mellanox OFED實現了內核態RDMA通信模塊,并整合入文件系統.MTFS最大可支持同一廣播域內的所有節點組成的集群,本實驗中MTFS默認在3個節點組成的集群上部署,包括1個元數據節點與2個數據節點,其中2個數據節點屬于同一個存儲單元.各節點采用128 GB持久性內存作為存儲介質.
本實驗主要將MTFS與同樣運行在持久性內存與RDMA上的分布式文件系統GlusterFS進行比較[28],對各項性能進行評估.鑒于MTFS基于單機文件系統NOVA實現,本實驗同樣將與NOVA進行性能比較.由于NOVA部署在單臺機器上,公平起見,MTFS在實驗中數據吞吐量均表示集群中單個節點的吞吐量.
4.2 微觀測試
實驗使用Fio進行微觀測試,展示MTFS在1對多的場景下進行寫操作的吞吐量[29].在測試過程中采用隨機讀寫,分別通過IO大小變化和文件大小變化,測試Fio的總體吞吐量.
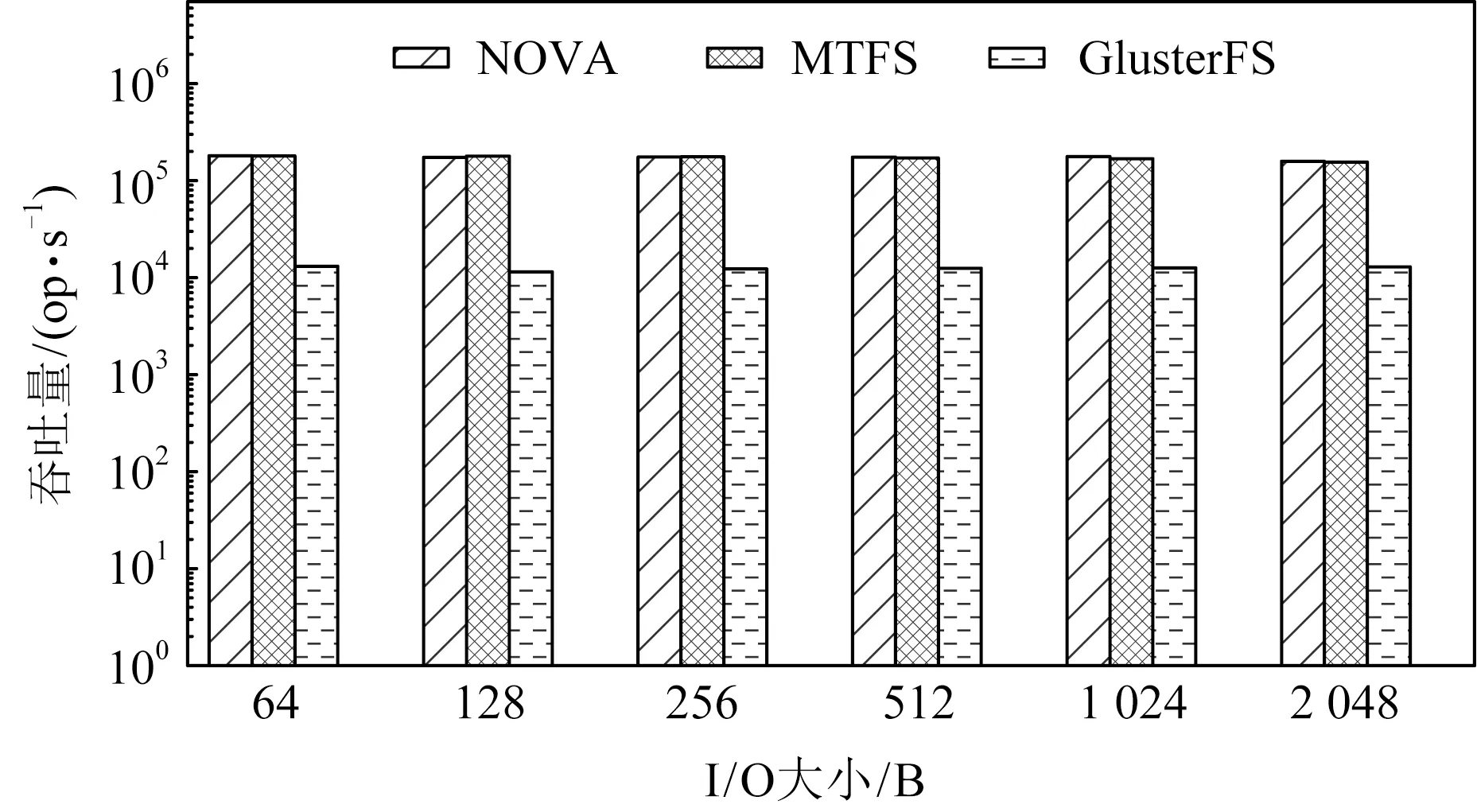
Fig. 6 Throughput of write syscall with varying I/O sizes圖6 寫系統調用在不同I/O大小下的吞吐量
圖7展示了MTFS與其他對比系統在不同的文件大小下的寫系統調用吞吐量,其中IO大小為2 KB.從圖7中可以看到,與GlusterFS相比,在文件大小為2 KB時,MTFS性能相比GlusterFS提升了145倍,而在文件大小為2 GB時,MTFS對比GlusterFS仍然有10.2倍的提升.同時,隨著文件大小增長,MTFS和NOVA性能均未出現明顯下降.這是因為MTFS與NOVA雖然采用日志結構,但相應的在DRAM中維護了作為數據索引的基數樹,當文件大小增長時,文件數據訪問延遲并不會出現明顯增大.
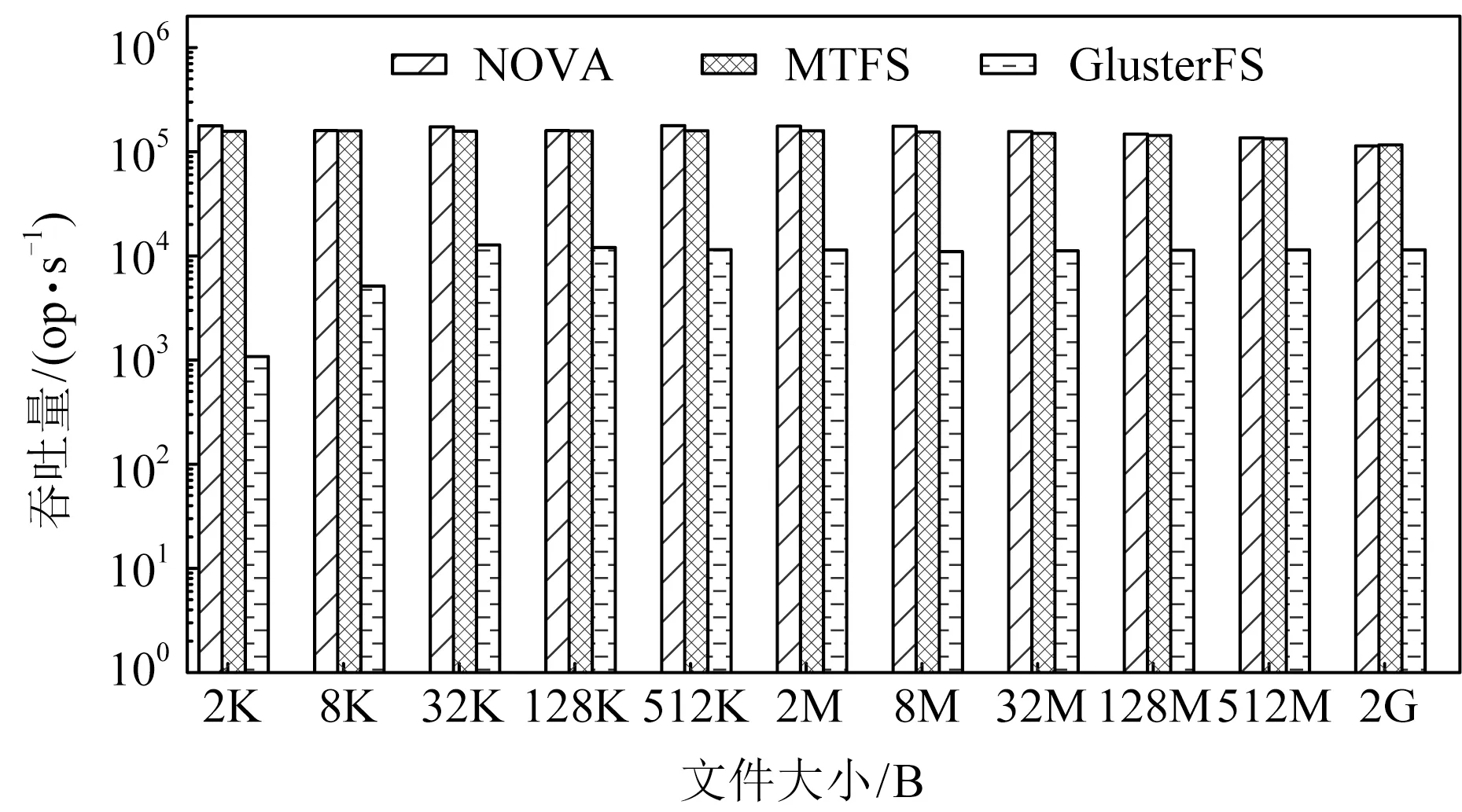
Fig. 7 Throughput of write syscall with varying file sizes圖7 寫系統調用在不同文件大小下的吞吐量
為了檢驗MTFS在集群中的可擴展性,實驗測試了MTFS在不同規模集群中的性能表現,結果如圖8所示.可以得知,隨著集群中節點數量增加,在不同的IO大小下,MTFS吞吐量都能夠基本保持不變,展現出良好的可擴展性.
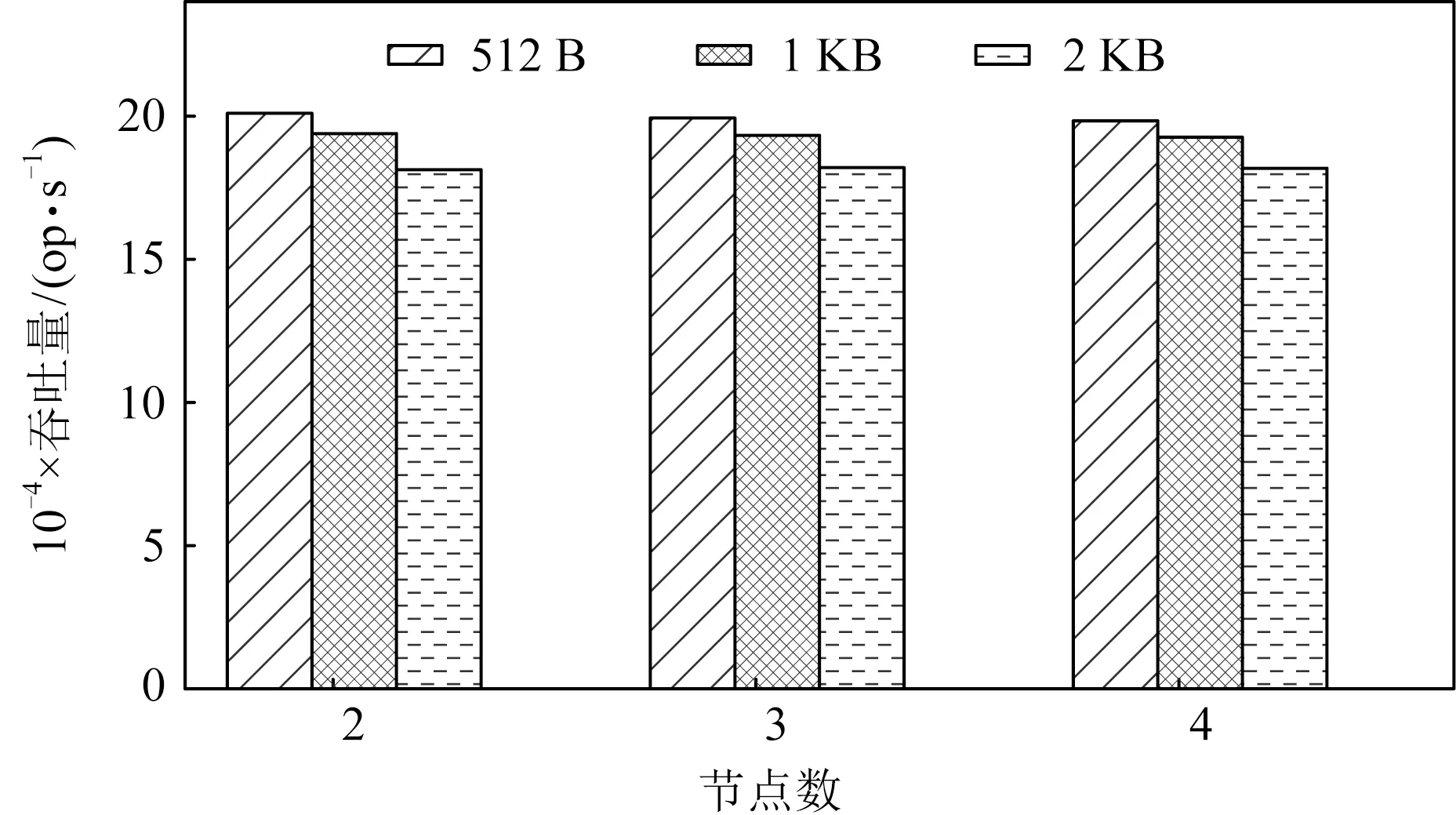
Fig. 8 Throughput of write syscall in clusters with varying sizes圖8 寫系統調用在不同規模集群中的吞吐量
4.3 Filebench
MTFS使用Filebench[30]測試評估真實負載下的表現.實驗選擇Filebench的工作負載Randomwrite來評估MTFS的性能.實驗采用以下參數進行測試:負載平均文件大小2 KB,數據操作的平均IO大小從64 B~2 KB不等.
圖9展示了各文件系統在Filebench的Random-write工作負載上的性能表現.可以得知,MTFS與NOVA性能相接近,在IO大小為2 KB時,MTFS相比NOVA性能有11%的提升.主要原因是當IO大小增大時,NOVA進行持久化相關操作的延遲隨之增大,而MTFS將持久化相關操作放在遠端數據節點進行處理,從關鍵路徑移除,減小了數據操作的延遲.與GlusterFS相比,MTFS性能仍然有13.7~219倍的提升.
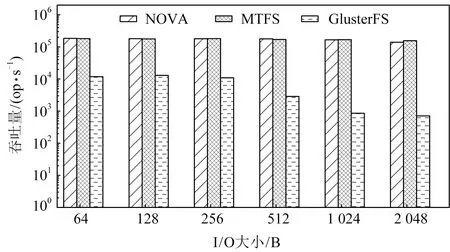
Fig. 9 Throughput of Randomwrite with varying I/O sizes圖9 Randomwrite在不同I/O大小下的吞吐量
4.4 Redis
為進一步測試MTFS在真實負載環境下的表現,實驗采用Redis[31]作為負載測試各文件系統的表現.Redis 是一個高性能的key-value數據庫,在企業級應用中被廣泛使用.實驗采用Redis的AOF機制實現數據持久化,持久化策略使用每修改同步策略,數據大小從默認2 B~2 KB不等.實驗比較Redis在不同文件系統下的每秒請求數.

Fig. 10 Performance of Redis with varying data sizes圖10 Redis在不同數據大小下的性能
圖10展示了各文件系統運行Redis時的性能表現.與上述微觀測試和Filebench測試采用IO密集型負載不同,Redis包含大量的計算操作,這導致GlusterFS數據操作上的性能缺陷在一定程度上被掩蓋,但MTFS與GlusterFS相比仍取得了25.5~42.1倍的性能提升.與NOVA相比,MTFS在Redis負載上取得了更優異的性能表現,主要原因是Redis操作中IO密集度下降減輕了網卡的負載,使得RDMA多播操作發送延遲下降,進而提升了數據傳輸效率.
實驗在Redis負載上對各文件系統進行了線程擴展能力測試,結果如圖11所示.可以看到,MTFS隨線程數量增加,表現出良好的線程可擴展性.
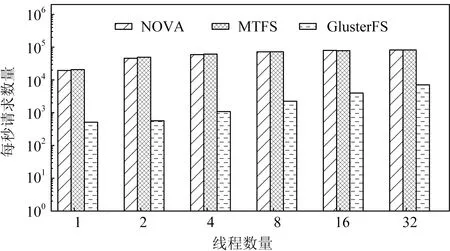
Fig. 11 Performance of Redis with varying thread numbers圖11 Redis在不同線程數下的性能
5 相關工作
新興的持久性內存技術與RDMA技術分別為本地內存訪問與遠程網絡通信訪問提供了優化的可能,現有的一些工作基于這2種技術提出了針對性設計.
5.1 RDMA相關優化
文獻[11]提出了一個基于RDMA的分布式共享內存系統FaRM.FaRM使用單邊RDMA語句實現了無鎖讀取和RPC操作,避免了雙邊RDMA操作帶來的通信延遲與CPU開銷.與基于TCP的系統相比,它的設計使其在RDMA網絡上獲得了巨大的性能提升.但是,FaRM使用了RC模式的單邊RDMA操作,對于每組連接都需要創建至少1對QP,而過多的QP會帶來RDMA網卡緩存不足和處理器爭用的問題,這限制了系統在大規模集群中的表現.MTFS基于多播語句實現,每對QP都可以發送信息到所有的節點,從而大幅減少了對RDMA網卡相關資源的需求.
文獻[22]通過實驗證明了在UD模式中,RDMA傳輸依然具有非常高的可靠性,并基于該結論提出了FaSST.FaSST使用UD模式的雙邊RDMA操作開發了RPC系統,利用UD模式數據報傳輸的優勢,通過降低發送端延遲提高系統性能,并取得了良好的可擴展性.然而FaSST只能通過QP進行1對1數據發送,當需要將相同的數據傳輸到不同的目的地時,需要進行多次發送操作.盡管MTFS同樣基于UD模式的雙邊RDMA操作,但是在上述情況下,MTFS使用多播語句可以將發送操作降低到1次,從而有效降低了發送端的延遲與資源占用.
文獻[23]提出了一種基于混合RDMA語句的分布式事務系統DrTM+H.該系統使用了樂觀并發控制實現事務,按照樂觀并發控制中的特性比較不同RDMA語句的表現,并在事務執行的每個階段選擇最適合的語句進行操作,取得了良好的性能表現.MTFS也使用了混合RDMA語句,選擇了多種RDMA語句分別進行讀取和寫入操作,但是與DrTM+H相比,MTFS將元數據操作放在本地執行,僅將數據放在遠端存儲,通過減少RDMA操作次數降低了事務執行延遲.
5.2 基于持久性內存的分布式文件系統
文獻[17]提出一個分布式文件系統NVFS,在現有的HDFS基礎上進行了改進,使系統可以更好地利用持久性內存技術和RDMA技術的特性.盡管HDFS表現良好,但HDFS設計的復雜性增大了改進的難度,導致NVFS無法充分利用硬件的性能.而其他類似的工作只是簡單地用RDMA替換了現有系統中的網絡,同樣無法充分地利用新技術的特性[28].
文獻[13]同樣將持久性內存與RDMA功能進行了緊密結合,開發出分布式文件系統Octopus.Octopus基于RDMA的write_with_imm語句構建RPC,該語句可以在進行單邊寫操作的同時攜帶32 b立即數字段,通過在該字段中編碼RPC相關信息,為接收端的相關處理提供了一定的靈活性與便利.但是在該語句中,當遠端節點的網卡接收到立即數字段時,需要觸發中斷來通知CPU處理立即字段,從而失去了RDMA單邊寫操作無需CPU處理的優勢,而僅32 b的字段大小也無法充分實現靈活性.為了滿足靈活性的需求,MTFS采用了UD模式的雙邊操作語句,并設計了大小可調整的頭部字段來實現RPC操作.
上述系統雖然均表現良好,但由于缺少對RDMA多播通信支持,導致難以解決分布式系統中的多拷貝數據傳輸問題,造成一定的性能損失.MTFS充分利用RDMA多播通信能力,通過多播傳輸解決了多拷貝數據傳輸問題,有效提升了系統數據傳輸效率.
6 總 結
持久性內存與RDMA技術的出現,為分布式系統的設計提供了新的思路.現有的基于RDMA的分布式系統未能充分利用RDMA的多播能力,難以解決多拷貝文件數據的傳輸問題.本文提出一種基于RDMA多播機制的分布式持久性內存文件系統MTFS,通過低延遲多播通信機制將數據高效傳輸到多個數據節點,從而避免了多拷貝傳輸操作.為提升傳輸操作的靈活性,MTFS設計了多模式多播RPC機制,并通過優化返回機制將部分操作移出關鍵路徑,進一步降低傳輸延遲.同時MTFS提供了輕量級一致性保障機制,保證了數據的可靠性和一致性.實驗結果表明,MTFS在各測試集上性能比GlusterFS高10.2~219倍,并在Redis負載上相比于NOVA取得了最高10.7%的性能提升.MTFS在大規模數據存儲場景中有著廣闊的應用前景.
猜你喜歡
四川勞動保障(2021年9期)2022-01-18 05:11:08
文苑(2018年21期)2018-11-09 01:23:06
當代陜西(2018年9期)2018-08-29 01:21:00
當代陜西(2017年12期)2018-01-19 01:42:33
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:00
中國衛生(2016年9期)2016-11-12 13:28:08
中國衛生(2015年9期)2015-11-10 03:11:12
醫學研究雜志(2015年12期)2015-06-10 06:57:46
中國衛生(2014年3期)2014-11-12 13:18:12
中國火炬(2014年4期)2014-07-24 14:22:19
