基于持久化內存的索引設計重新思考與優化
2021-02-07 02:51:32韓書楷熊子威蔣德鈞
計算機研究與發展 2021年2期
關鍵詞:優化
韓書楷 熊子威 蔣德鈞 熊 勁
(計算機體系結構國家重點實驗室(中國科學院計算技術研究所) 北京 100190)(中國科學院大學 北京 100049)(hanshukai@ict.ac.cn)
非易失性內存(non-volatile memory, NVM)是近幾年來出現的一類存儲介質的統稱,例如:PCM[1],ReRAM[2],STT-RAM[3]等.一方面,這些存儲介質同DRAM(dynamic RAM)一樣有著低訪問延遲、可字節尋址的特性;另一方面,與DRAM不同的是,它們具有非易失性、較低的能耗和較高的存儲密度.這使得基于NVM技術的非易失性內存有著更大的單片存儲容量,同時能夠作為存儲設備保存數據.若利用基于非易失性內存構建存儲系統,一方面,相對于傳統基于內存的存儲系統而言,可以受益于非易失性內存的非易失、大容量、低能耗特點[4];另一方面,相對于傳統基于磁盤的存儲系統而言,可以受益于更低的訪問延遲以及更細粒度尋址方式.因此,NVM技術有望被大規模的應用在存儲系統的研發與構建中,成為存儲系統進一步發展的新機遇.
鍵值存儲系統是數據中心中一類重要的基礎性存儲設施,例如內存鍵值存儲系統Memcached[5],Redis[6]和磁盤鍵值存儲系統LevelDB[7],RocksDB[8]等.無論是內存鍵值存儲系統還是磁盤鍵值存儲系統,索引結構都是這些存儲系統中非常重要的基礎技術,一直以來便是存儲領域的熱點研究問題.在之前的研究工作中,索引結構大多構建在DRAM中.隨著低訪問延遲、可字節尋址、可持久化數據的NVM的出現,這使得基于NVM構建持久化的高性能索引成為可能.近年來,很多面向NVM的索引研究工作[9-16]認為NVM有著同DRAM近似的讀延遲以及高于DRAM數倍的寫延遲的特性.因此,大部分研究工作提出通過降低NVM寫開銷從而構建不同的高效持久化索引.這些工作基本可以分成2類:一類是針對單一索引結構的設計優化.例如:Level Hashing[10]是面向NVM設計的Hash索引,它使用2層的Hash表結構以降低表拓展時搬運的數據總量.NV-Tree[12]是針對B+樹索引的優化,它不對同一葉子節點內的數據進行排序,從而減少了插入數據時的寫開銷,此外NV-Tree還將內部節點放在DRAM以降低樹分裂時對NVM的寫開銷.另一類是面向DRAM-NVM混合內存結構的混合索引,例如,HiKV[15]是基于DRAM-NVM構建的混合索引鍵值存儲系統,它對同一份數據同時維護Hash表和B+樹2種索引去保證高效的讀性能,為了HiKV將寫開銷較低的Hash表放在的NVM而將寫開銷較高的B+樹放在DRAM中,從而降低對NVM寫負擔.
從2009年開始,NVM便被計算機系統領域廣泛研究.然而,研究早期NVM技術還未成熟,尚未有成熟的NVM設備可供使用,上述大部分研究工作都是基于對非易失性內存器件的性能假設并使用模擬器進行實驗評測[4-5].2019年4月,英特爾公司正式發布了基于3D-XPoint技術[17]的NVM硬件產品apache pass(AEP)[18],這為研究人員基于真實的NVM硬件進行研究提供了基礎.目前,已有一些針對真實NVM硬件的評測工作顯示,現有的NVM硬件有著接近DRAM的寫延遲以及高于其數倍的讀延遲.而之前研究工作所采用了如下性能假設:1)NVM有著同DRAM近似的讀延遲,2)NVM有著高于DRAM數倍的寫延遲.這些假設和現有真實NVM硬件性能評測結果并不完全相符.這使得我們需要重新審視之前基于NVM性能假設的索引研究工作,并基于實際的NVM硬件特性開展有效的優化工作.
本文的主要貢獻有3個方面:
1) 對最新的AEP硬件進行了評測,我們評測了AEP硬件的不同訪問線程、不同訪問粒度下的讀寫延遲、帶寬,以及讀寫混合下AEP的性能變化趨勢.
2) 基于真實AEP硬件評測結果,我們分別重新審視了之前研究工作并針對混合索引結構和單一索引結構進行了優化.針對混合索引結構,本文基于AEP硬件真實性能,重點關注索引放置的優化.本文探索了不同索引放置方式對混合索引結構的影響,當面臨讀密集的負載時,通過將主索引放置在DRAM,輔助索引放置在AEP上,從而可以有效提升索引的讀性能.本文針對不同應用場景,提出索引放置相應的設計原則考慮.我們針對混合索引(HybridIndex)提出了讀優化的改善方案Hybrid-Index+,該方案下HybridIndex最多可提升80%的讀性能.
3) 針對單一索引結構,本文基于AEP讀延遲較高的特性,提出基于DRAM的異步緩存方法,將位于NVM中持久化索引通過高速Hash索引的方式緩存在DRAM中,從而獲得高效的訪問性能.此外,本文還針對FP-Tree[13]、FAST-FAIR[11]和持久化跳表[14]實現了異步緩存,評測結果顯示經過我們的優化,最多可以降低持久化索引20%~50%的讀延遲.
1 非易失性內存簡介
在實際的NVM硬件投放市場之前,學界對持久化內存的訪存特性具有一些基本假設,比如:NVM有著數倍于DRAM的寫延遲及相近的讀延遲.該假設是否成立尚需物理器件的驗證.此外,非易失性內存的具體特性尚處于未知,如訪問粒度對延遲帶寬的影響、多線程對延遲帶寬的影響、混合訪存對延遲帶寬的影響等.對AEP進行詳細的測試可以為我們揭示一類非易失性內存的物理特性,為研究者和開發者在后續基于非易失性內存的工作中提供參考,也可為系統工作者構建包含非易失性內存的新型存儲系統提供參考.本節主要介紹了非易失性內存的特性,并對當今最新的NVM硬件在各個維度進行了詳細的評測.
1.1 非易失性內存技術
NVM與傳統DRAM一樣,可以被掛載在CPU地址總線上按字節進行尋址.如表1所示,目前已有多種可用于生產持久化內存的存儲介質.這些介質有著接近DRAM的納秒級讀寫延遲以及更高的集成密度.此外,相比DRAM需要頻繁的刷新去記錄數據,非易失性內存介質不需要頻繁的刷新去保證數據的有效性,這使其能耗相比DRAM更低.

Table 1 Comparison of the Properties of Different Storage Media[19]
需要注意的是,表1僅為不同存儲介質的性能對比而非實際的存儲硬件性能.NVM設備的復雜性要求我們進行細致的評測和分析以獲得硬件的實際性能和詳細特性.
1.2 Apache Pass
英特爾公司在2019年4月公布了第1代基于3D-XPoint技術[17]的商用持久化內存硬件AEP[18],當前發布的AEP分別為128GB256GB512GB容量.這標志著持久化內存正式進入了實際可用的階段.
2 AEP硬件性能評測
目前存在著如MLC(memory latency checker)[20]等內存檢查的工具,但這些工具的高度定制化和閉源特性不符合我們對AEP進行細粒度測試的需求,因此我們編寫了一系列測試代碼(1)已開源:https://github.com/KinderRiven/AEP_TEST,這些測試代碼主要完成對AEP硬件的延遲、帶寬等基本性能的評測,探索AEP的物理特性,以揭示其帶寬延遲特性,最佳訪問模式等信息,為后續設計工作在AEP上的系統提供指導.
2.1 測試環境和方法
AEP有著接近傳統易失性內存的訪問延遲,此外還有著傳統持久化設備的持久化特性,因此它在傳統存儲層次架構中可以擔任不同的角色.一方面作為內存而言,它可以作為DRAM的下層大容量存儲介質;另一方面作為可持久化設備,它可以作為存儲層中的高速上層存儲介質,位于傳統的高速SSD之上.
基于這2種使用方法,AEP提供了Memory Mode和App Direct Mode這2種配置使用方法[21].若采用Memory Mode進行配置,AEP將被當作大塊內存而非持久化存儲設備使用,因此對應用程序不可見;如果采用App Direct Mode進行配置,AEP則被當作一塊持久化設備使用,可以被應用程序直接看到并訪問.需要注意的是.由于我們的研究工作主要將AEP作為高性能且持久化的存儲設備而使用,因此本文所進行的評測都基于Direct Mode進行配置和使用,該模式可以有效反映AEP作為有效存儲設備的性能.而對于Memory Mode模式下的性能評測,我們暫時沒有進行.
表2展示了進行評測的物理環境.對于每組評測,我們均進行5次評測并在每組波動不超過5%的基礎上取平均值.另外,為了避免CPU預取對測試結果造成影響,我們在測試中關閉了CPU預取.
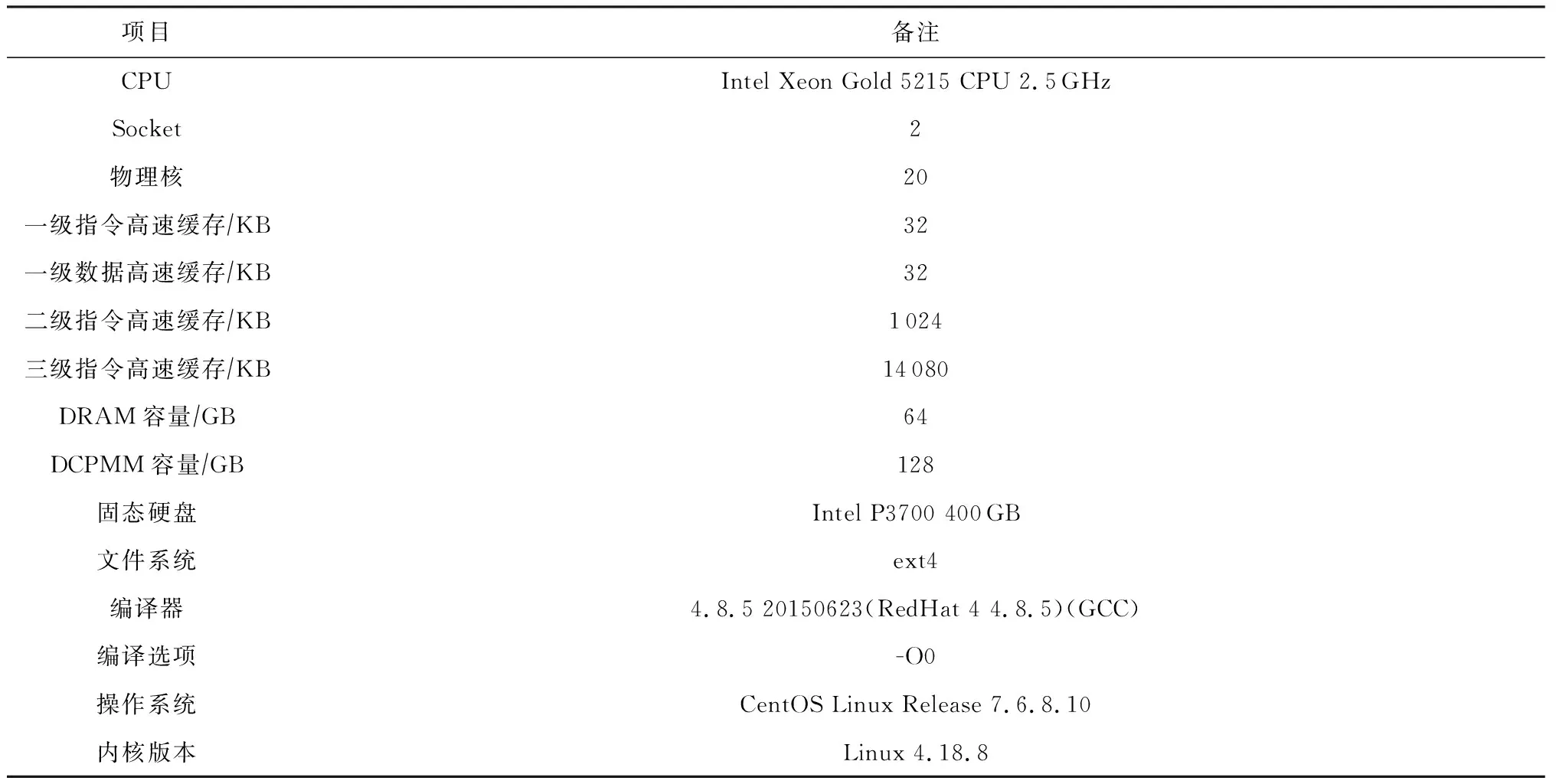
Table 2 Experimental Environment
2.2 測試結果
2.2.1 延遲
表3展示了使用單線程對AEP進行小粒度隨機和順序讀寫時的延遲對比情況.可以看到,小于256 B的隨機讀延遲基本接近256 B的隨機讀延遲,這是由于AEP的訪問粒度為256 B.當訪問粒度小于256 B時,順序讀相比隨機讀延遲要低很多,這是由于AEP的內部存在緩存機制,使得對同一訪問單元(256 B大小的物理塊)進行連續訪問時的性能得到提升.
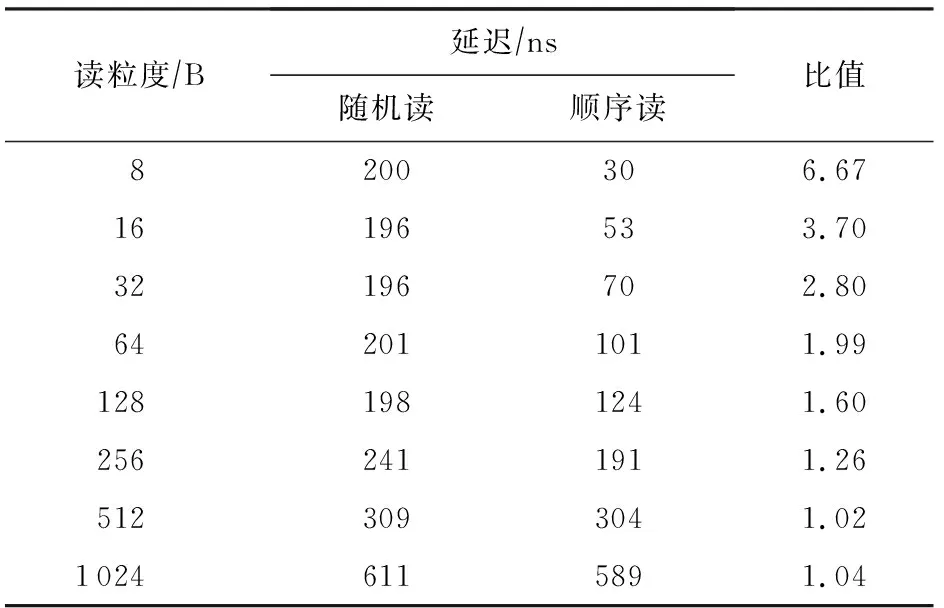
Table 3 Comparison of Random and Sequential Read Latency of Small Access Granularity for AEP
表4展示了使用單線程對AEP進行大粒度隨機和順序讀時的延遲對比情況.可以看到,AEP的隨機和順序讀延遲基本一樣,結合表3來看,在不考慮訪問小粒度數據時內部緩存機制的影響,AEP的隨機和順序讀延遲基本一樣.
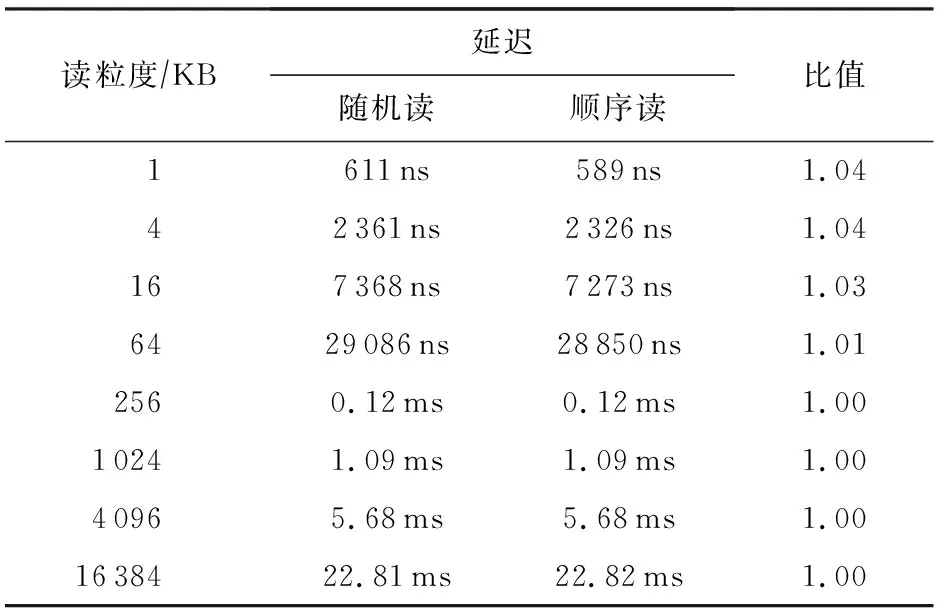
Table 4 Comparison of Random and Sequential Read Latency of Large Access Granularity for AEP
表5和表6展示使用單線程對不同粒度數據進行隨機和順序寫的延遲對比,可以看到,不論在大小粒度下,AEP的隨機和順序寫延遲都是一樣的.同讀訪問一樣,AEP有著較好的隨機訪問特性.需要注意的是,在進行小于64 B數據的訪問時,出現了延遲上升的情況,這主要是由于我們使用了NTStore指令進行寫操作,該類指令可以不經CPU cache而將數據直接寫入內中,而NTStore指令在處理小于64 B的數據時存在延遲升高的問題.
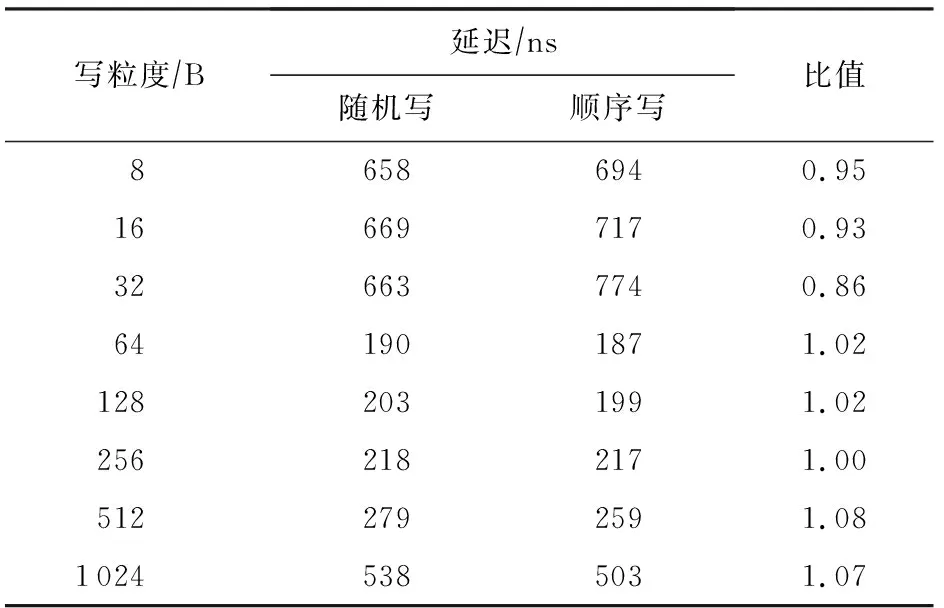
Table 5 Comparison of Random and Sequential Write Latency of Small Access Granularity for AEP
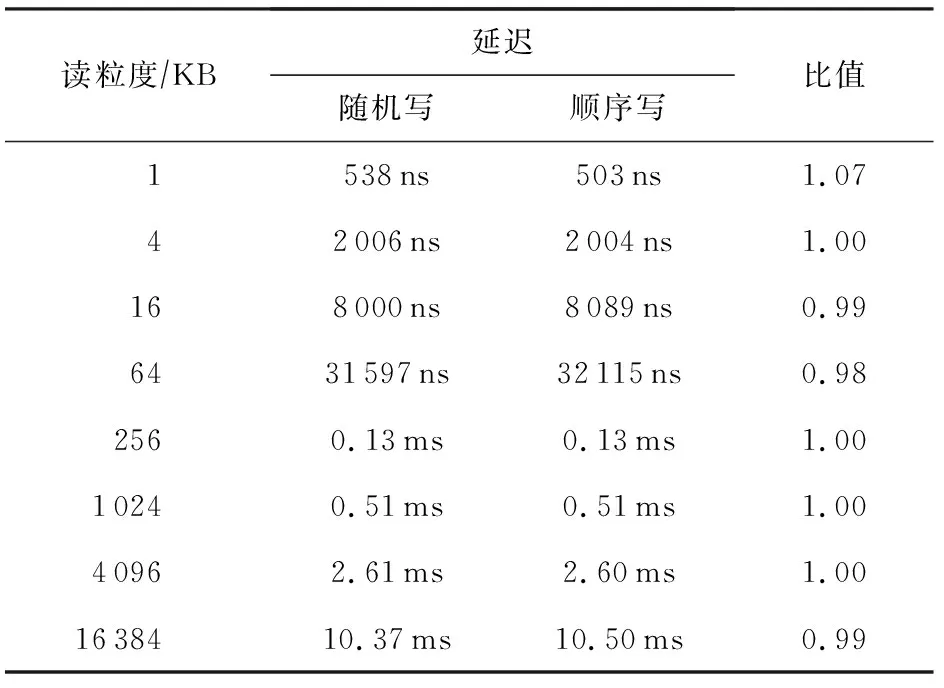
Table 6 Comparison of Random and Sequential Write Latency of Large Access Granularity for AEP
綜上所述,AEP有著良好的隨機訪問特性,最佳訪問粒度為256 B.在處理1 KB及以下的數據時,AEP可以保證納秒級別的訪問延遲.
圖1為AEP的在不同線程、不同粒度隨機讀延遲變化趨勢圖.

Fig. 1 Trend of random read latency of AEP over access granularity圖1 AEP的隨機讀延遲隨訪問粒度增加的變化趨勢
我們注意到,在256 B以內的隨機讀延遲并不顯著受到線程數的影響.但可以看出線程數的增加導致了延遲的升高,這個趨勢在讀粒度較大、延遲較高的情況下更為明顯.在順序讀的測試中,AEP也具有相似的趨勢,讀粒度小于256 B時延遲受線程數影響較小,且讀延遲隨線程數增加而升高.總結如下:
1) 多線程寫操作會導致AEP讀延遲的升高;
2) 為了維持較低的讀延遲,小于等于256 B的讀粒度是較優的讀粒度.
圖2是AEP的隨機寫延遲變化趨勢圖.與讀延遲類似的是,寫粒度小于256 B時AEP維持較低的延遲,且對線程數的增加更為敏感.且當寫延遲在訪問粒度接近256 B時取得最小值.總結如下:
1) 多線程讀操作會導致AEP寫延遲的急劇升高;
2) 接近256 B的寫粒度是較優的寫粒度;
3) 從延遲的角度來看,讀寫的最佳粒度是256 B,且訪問線程數不應太多.

Fig. 2 Trend of random write latency of AEP over access granularity圖2 AEP的隨機寫延遲隨訪問粒度增加的變化趨勢

Fig. 3 Trend of random read bandwidth of AEP over access granularity圖3 AEP隨機讀帶寬隨訪問粒度增加變化趨勢
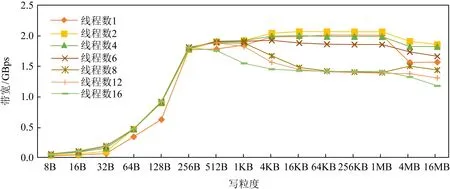
Fig. 4 Trend of random write bandwidth of AEP over access granularity圖4 AEP隨機寫帶寬隨訪問粒度增加變化趨勢
2.2.2 帶寬
圖3和圖4展示了多線程下不同粒度下隨機讀寫帶寬變化情況,可以看出,AEP最大讀帶寬為7 GBps左右,最大寫帶寬為2 GBps.且在多線程下,256 B的訪問粒度下讀寫帶寬基本可以達到最大帶寬上限.這主要是由于AEP的訪問粒度為256 B所導致的,小于256 B的訪問會造成讀寫放大從而降低有效帶寬.
此外,我們從圖3和圖4中發現,若訪問粒度超過一定閾值,AEP的讀寫帶寬反而出現了下降.這是由于對于讀帶寬,cache的頻繁替換造成了性能的損失.而對于寫帶寬,我們認為是CPU亂序導致寫操作被拆分為64 B粒度,由于AEP寫帶寬較低并受256 B寫粒度的影響,當數據被拆分成64 B的隨機寫后亂序寫回,這造成了數據的寫放大從而引起帶寬下降.為了驗證我們的判斷,將一個數據塊寫回時,每隔256 B添加一次內存屏障(sfence),確保數據的有序寫回.如圖5所示,添加內存屏障后AEP的寫帶寬沒有出現下降的情況.
圖6和圖7展示了多線程下不同粒度下順序讀寫帶寬變化情況.可以看出,相比隨機訪問需要在256 B達到最大讀寫帶寬,順序訪問在64 B的訪問粒度時即可達到最大讀寫帶寬.對于讀操作而言,這是由于AEP內部的緩存機制使得小于256 B的順序訪問可以有效命中緩存,從而降低讀放大減少帶寬浪費;對于寫而言,這主要是由于AEP內部會對連續地址的請求進行合并,這使得AEP在順序寫入64 B的數據時能夠將其合并成一個256 B單位的數據寫入硬件中,從而避免了寫放大問題.此外,我們依然可以看出,在大粒度的順序訪問時讀寫帶寬依然出現了退化的情況.
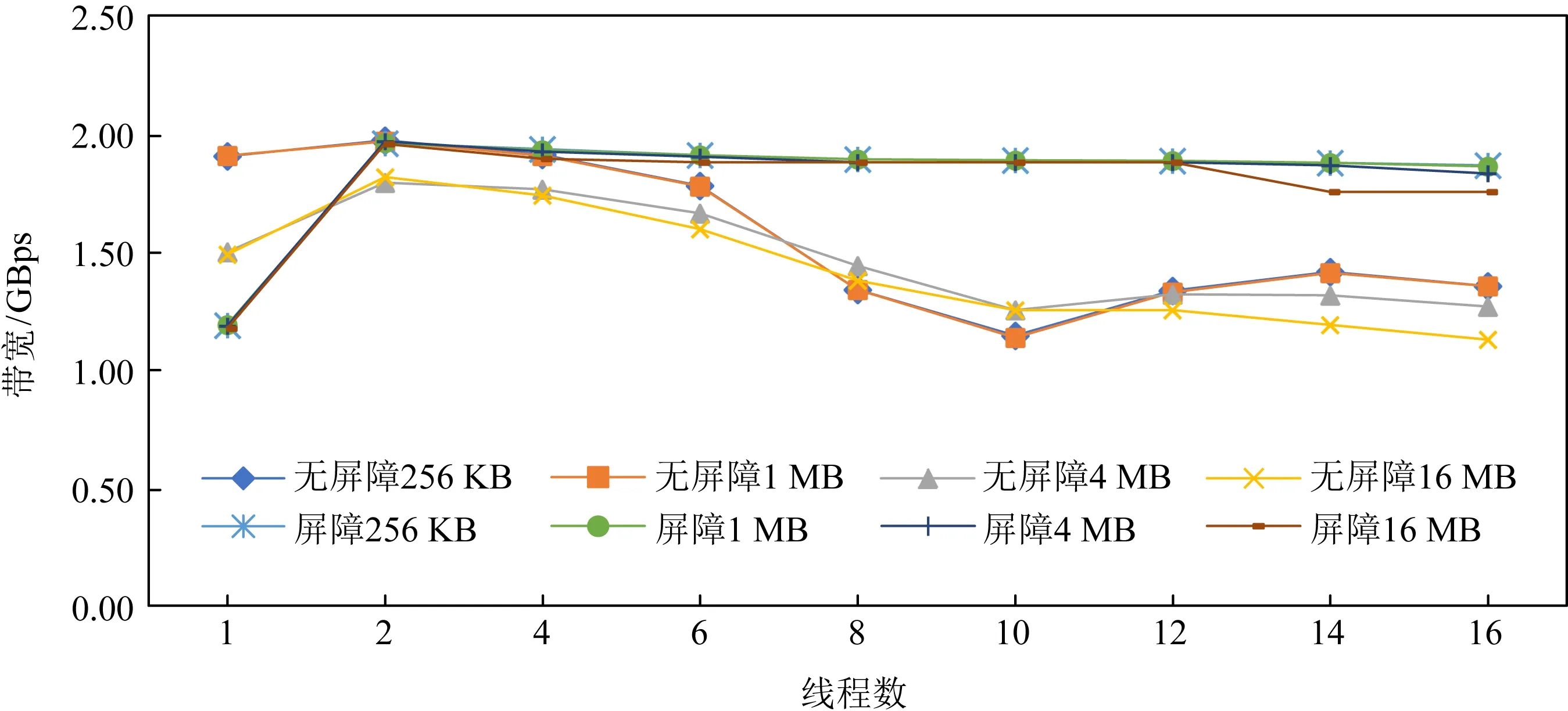
Fig. 5 Impact of using memory barriers on write bandwidth degradation圖5 內存屏障對寫帶寬退化的影響
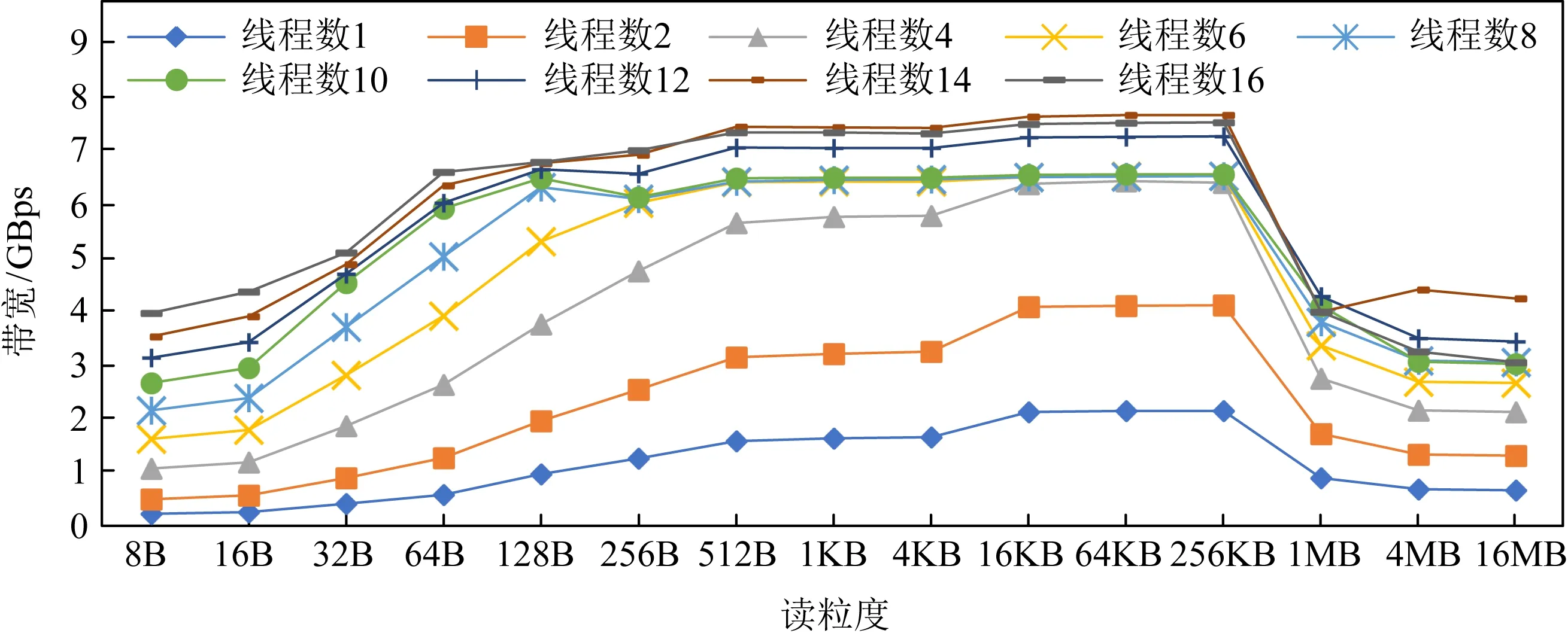
Fig. 6 Trend of sequential read bandwidth of AEP over access granularity圖6 AEP順序讀帶寬隨訪問粒度增加變化趨勢
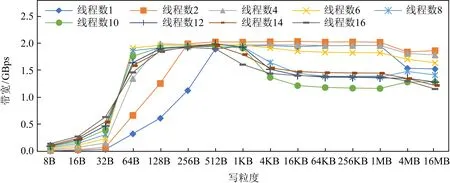
Fig. 7 Trend of sequential write bandwidth of AEP over access granularity圖7 AEP順序寫帶寬隨訪問粒度增加變化趨勢
經過評測有如下結論:
1) 當AEP進行大粒度數據訪問時,會出現帶寬退化的現象,對于讀帶寬的帶寬,可以利用內存屏障進行寫序控制從而防止退化.
2) AEP更加適合處理小粒度數據,考慮到其訪問粒度為256 B,因此處理更小粒度的數據時可能會造成讀寫放大,從而浪費帶寬.
3) 盡管受制于256 B的訪問粒度,但AEP內部仍存在某些順序訪問的優化機制.
2.2.3 與DRAM和SSD的比較
在延遲方面,與DRAM的讀延遲對比如表7所示,寫延遲對比如表8所示.
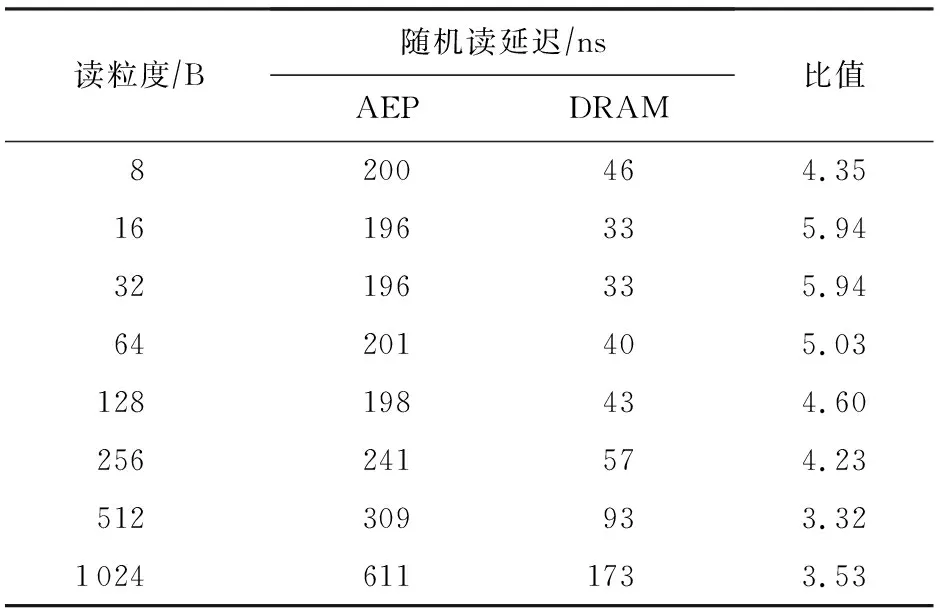
Table 7 Latencies of AEP and DRAM Random Read with Single Thread for Small Access Granularity
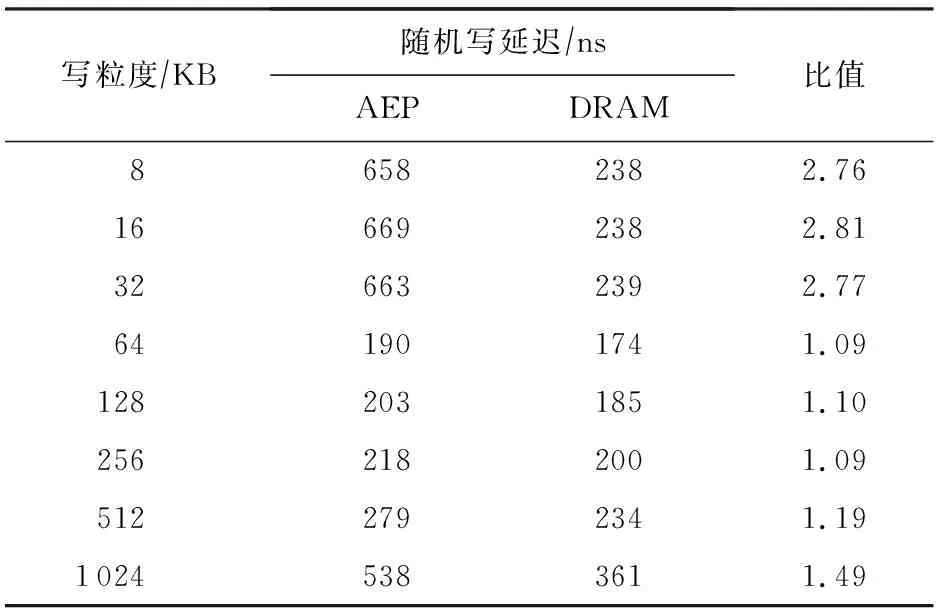
Table 8 Latencies of AEP and DRAM Random Write with Single Thread for Small Access Granularity
從表7~8中可以看出,讀延遲上AEP為DRAM的4~5倍,之前關于“NVM比DRAM有著更高的寫延遲和一樣的讀延遲”的假設與實際器件是不符合的.而寫延遲,DRAM和AEP都表現出了非對稱的寫延遲,但AEP的寫延遲在寫粒度接近256 B時與DRAM相差不大.因此對非易失性內存的假設應當修正為:對于采用與AEP相似技術的NVM,其整體具有比DRAM更高的讀延遲以及與DRAM相近的寫延遲.此外,在帶寬方面,DRAM具有高達10 GBps以上的讀寫帶寬,而AEP讀帶寬為7 GBps,寫帶寬僅2 GBps.因此AEP目前還不具備完全代替DRAM的潛力.
盡管表現遜色于DRAM,AEP的性能遠遠優于目前已有的SSD產品.我們使用fio測試了傳統NVMe SSD的性能,可以發現系統內SSD的峰值讀帶寬為870 MBps,遠遠低于AEP.盡管目前已有較高端的SSD產品達到了2 GBps的讀帶寬,但對比AEP高達7 GBps的讀帶寬,仍舊顯得遜色.而寫帶寬上系統內SSD的峰值寫帶寬僅680 MBps,也遠低于AEP高達2 GBps的帶寬.因此我們有如下觀察:
1) AEP在256 B訪問下具有較優異的讀寫帶寬和延遲表現;
2) AEP并不是一個高并發友好的器件,訪問AEP的線程數應控制在較低的數量;
3) AEP目前暫不具備完全代替DRAM的潛力;
4) AEP的性能表現遠遠好于SSD,在現有的存儲層次中,可作為DRAM于SSD甚至HDD之間的新層級.
如2.2.2節所述,訪問粒度和線程數對AEP的性能表現存在較大影響,接下來將分別說明粒度和線程數對AEP性能表現的具體影響.
2.2.4 訪問粒度的影響
2.2.2節已粗略展示了隨著訪問粒度的升高,AEP出現帶寬下降、延遲升高的性能退化問題,本節將以單線程的結果,更詳細分析訪問粒度對AEP性能的影響.由于帶寬的下降是有限的,因此本節不討論AEP帶寬的變化.
從圖8和圖9中可以看出,盡管較小粒度(小于512 B)時AEP展現了百納秒級別的優秀表現,但當訪問粒度上升至KB級別,AEP延遲開始上升到了微秒級別,而如果采用MB基本的訪問,AEP的延遲飆升至毫秒級別,逼近了SSD的延遲.隨機寫具有類似的現象.因此可見,AEP是一個小粒度友好的設備,在設計工作在AEP上的系統時,應當盡量避免過大粒度的訪問.
2.2.5 訪問線程數的影響
本節同樣聚焦于線程數對隨機讀延遲的影響.如圖10所示,在小粒度的情況下(小于256 B),AEP的延遲上升不明顯.線程數從1增加15倍到16之后,延遲并未上升15倍,而僅升高了2倍左右.但在大粒度的情況下,延遲基本隨線程數線性增長.這進一步說明在并發的情景下,AEP也仍然是一個小粒度訪問友好的設備.較小的訪問粒度可以避免高并發下延遲陡增的情況.隨機寫也具有類似的現象.

Fig. 8 The impact caused by small access granularity to the read latency of AEP with single thread圖8 單線程下小粒度訪問對AEP隨機讀延遲的影響
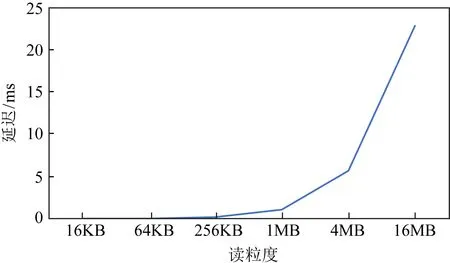
Fig.9 The impact caused by large access granularity to the read latency of AEP with single thread圖9 單線程下大粒度訪問對AEP隨機讀延遲的影響
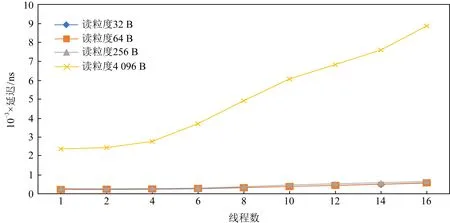
Fig. 10 The impact caused by number of thread to the read latency of AEP圖10 不同線程數對AEP讀延遲的影響
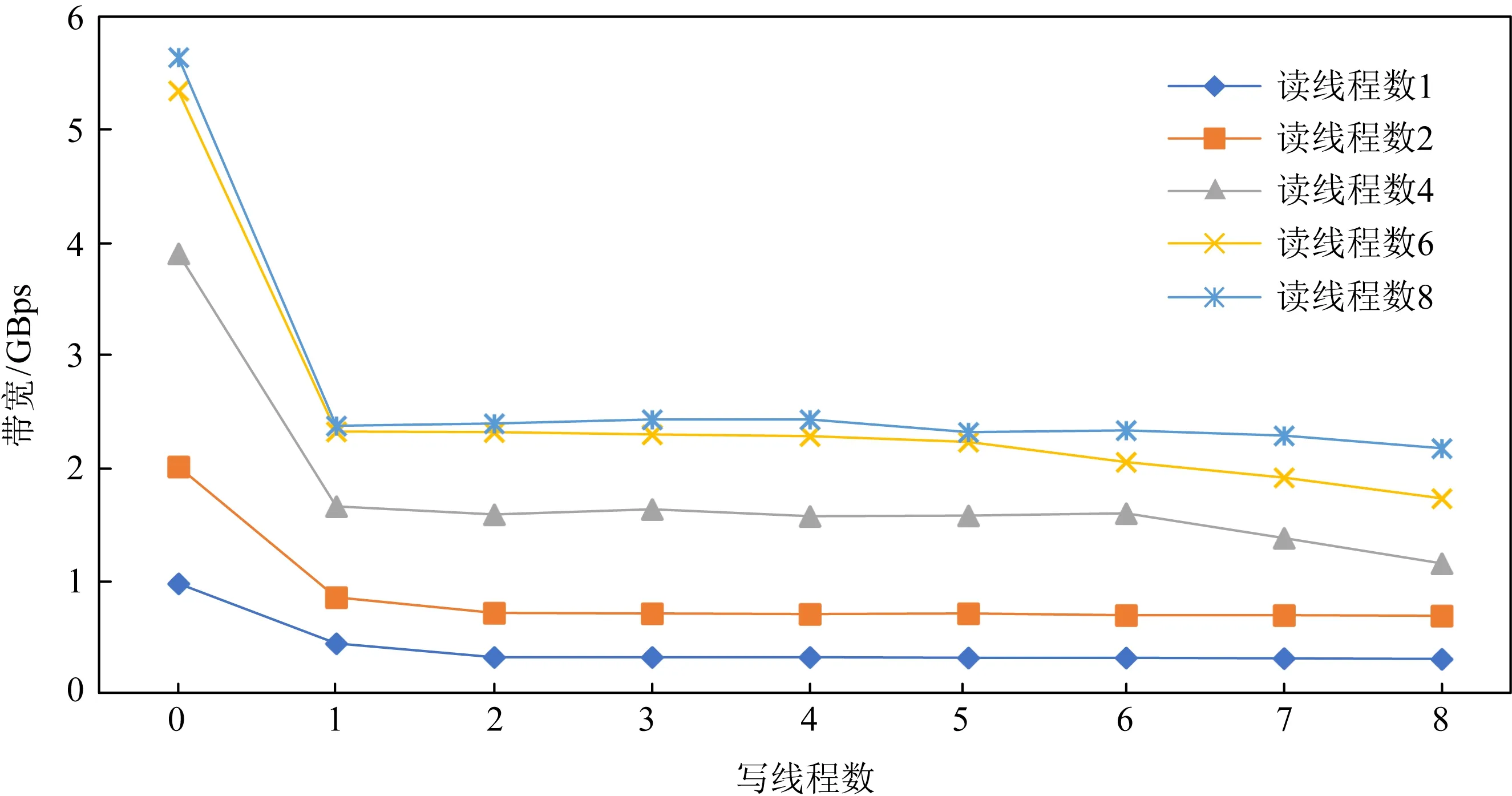
Fig. 11 Read bandwidth variation of AEP under mixed read-write at granularity 256 B圖11 256 B粒度混合讀寫下的AEP讀帶寬變化情況
2.2.6 混合讀寫的影響
我們評測了讀寫混合下AEP硬件帶寬和延遲的變化趨勢,如圖11所示.我們注意到若固定讀線程數,一旦出現寫線程,則讀取帶寬出現急劇下降的情況,但這種下降不是無限制的,隨著寫線程的不斷增加,讀帶寬下降變得不再明顯.這表明AEP內部存在一定的讀保護機制,阻止讀帶寬受到寫帶寬的過度影響.如圖12所示,反之若固定寫線程,增加讀線程數,寫帶寬也同樣出現下降的情況,但最終也逐漸趨于平緩不再下降,.綜上表現來看,AEP內部對于讀寫帶寬的控制存在一定的“保底”,從而避免了高并發情況下出現讀寫帶寬不平衡的情況.
在延遲方面,AEP也呈現出類似的趨勢,從圖13和圖14中可以看出,AEP內部的讀保護機制也阻止了讀寫延遲受線程影響也發生過大的升高,保證了讀寫延遲穩定在1 μs左右.
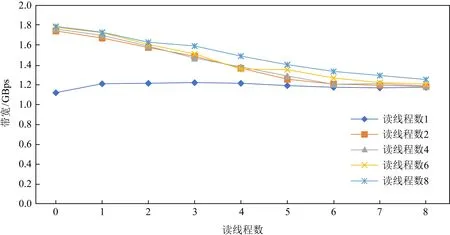
Fig. 12 Write bandwidth variation of AEP under mixed read-write at granularity 256 B圖12 256 B粒度混合讀寫下的AEP寫帶寬變化情況
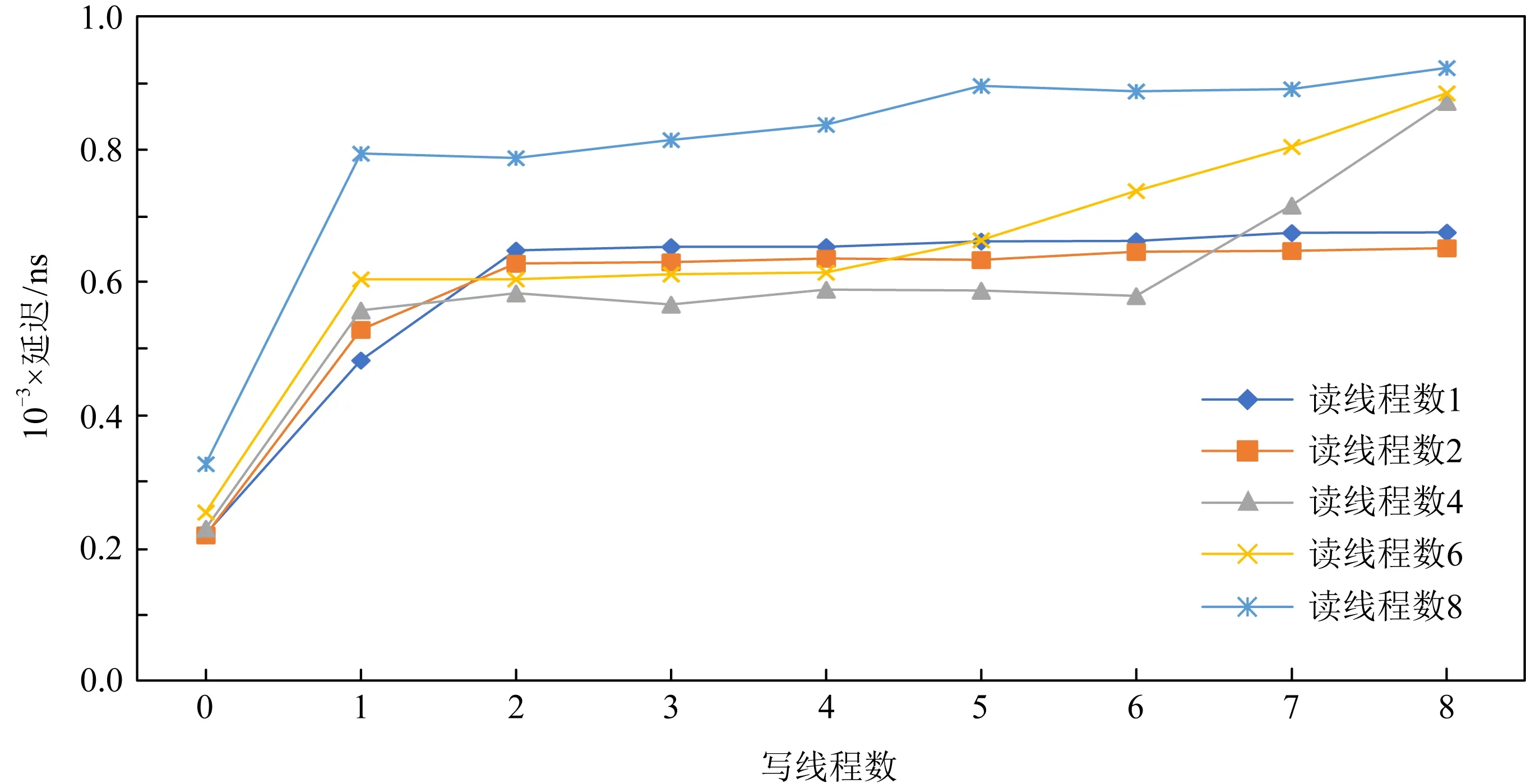
Fig. 13 Read latency variation of AEP under mixed read-write at granularity 256 B圖13 256 B粒度混合讀寫下AEP讀延遲的變化情況
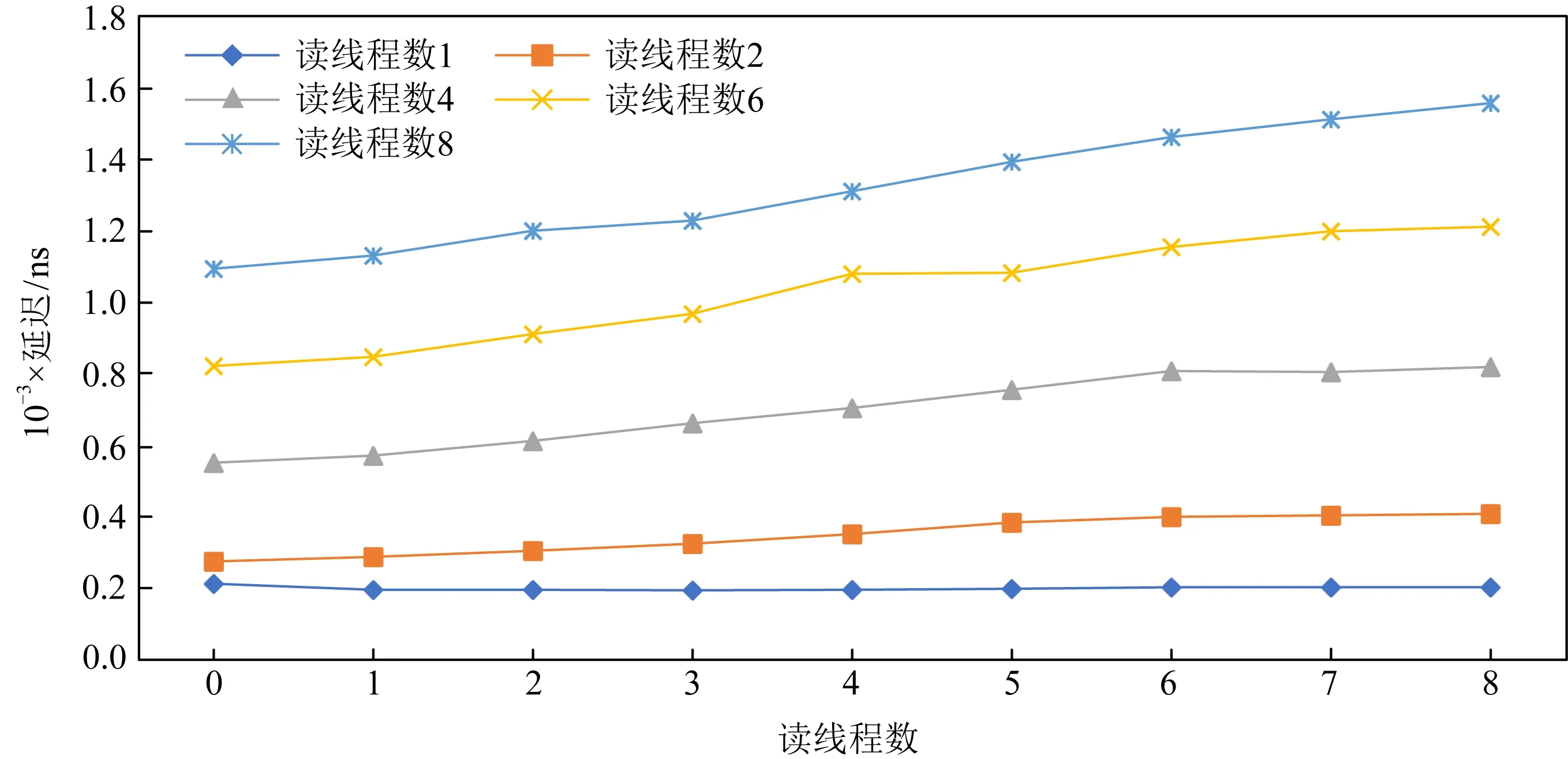
Fig. 14 Write latency variation of AEP under mixed read-write at granularity 256 B圖14 256 B粒度混合讀寫下的AEP寫延遲變化情況
2.3 評測總結
針對AEP的評測可總結出以下的結論:
1) AEP訪問粒度為256 B,其內部存在緩存機制,從而可對于小粒度的順序訪問進行優化.但對小粒度的隨機訪問該優化通常不奏效,因而對AEP的小粒度隨機訪問會造成讀寫放大問題.在進行大粒度數據訪問時,AEP存在帶寬退化的問題且性能較差.綜上所述,AEP更加適合用于存儲小粒度的數據,特別是256 B到4 KB之間大小的數據.
2) 在帶寬方面,AEP讀寫帶寬較低且不平衡.AEP的讀帶寬大約為7 GBps,僅為DRAM的13左右;而寫帶寬更低約為2 GBps,僅為DRAM的16左右.
3) 在延遲方面,AEP順序隨機訪問性能持平,作為一種隨機存儲設備是合格的.它的寫延遲接近DRAM,而讀延遲為DRAM的3~5倍.
4) 相比其較低的帶寬,AEP的延遲顯得更為優秀.因而AEP更適合作為低延遲的響應設備,用于存儲對延遲需求較高且需要持久化的數據,比如索引、日志等重要的元數據.此外,同之前工作主要聚焦于NVM高寫延遲上不同的是,經評測由于AEP的讀延遲高于DRAM,面向AEP的設計更應該關注高讀延遲所帶來的問題并進行優化.
3 基于非易失性內存的索引設計
近幾年來,關于如何使用NVM一直是存儲系統領域的熱點研究問題.一方面,NVM有著接近易失性內存的納秒級訪問延遲,以及可字節尋址的特性;另一方面,NVM相比易失性內存有著更大的容量以及非易失性的特性,此外盡管NVM有著較低的訪問延遲,但受制于介質特性,其擁有的帶寬相比DRAM而言并不高.因此有很多工作考慮在NVM中構建高效的持久化索引[9-16].
然而,在過去幾年里由于NVM硬件尚未商業化,很多工作都是基于模擬環境進行;此外,過去的針對NVM性能的假設也存在一些偏差,比如過去的很多模擬器大多模擬NVM比易失性內存寫延遲高5倍,而讀延遲同易失性內存一樣,這同我們對AEP實際硬件的評測結果并不一致.因此,上述原因使得過去的很多工作的設計和評測存在一些局限性.
在本節,我們針對實際的AEP硬件重新優化并評測了過去針對NVM模擬器進行設計的索引,通過2個實例分析證明我們工作的有效性.
3.1 案例分析:面向混合索引的性能優化
混合索引鍵值存儲系統(hybrid index key-value store, HiKV)[15]是面向混合內存架構的一種高性能鍵值存儲系統.由于不支持范圍查詢的Hash索引的查詢復雜度為O(1),而B+樹等支持范圍查詢的數據結構查詢復雜度為O(logn),因此,該系統中提出了面向DRAM-NVM混合內存架構的混合索引(HybridIndex)機制.具體而言,HybridIndex采用Hash表和B+樹組成的混合索引機制來支持高效的查詢.
如圖15所示,HybridIndex對同一份數據維護2個索引,HybridIndex使用Hash索引進行單點查詢,使用B+樹進行范圍查詢.為了保證索引的持久化,HybridIndex將Hash索引放在NVM而將B+樹索引放在易失性內存,宕機之后根據NVM中的持久化Hash索引重建易失性內存中的B+樹.此外,為了降低寫延遲,HybridIndex只對NVM中的Hash索引進行持久化更新,這種設計主要是針對當時NVM普遍被認為寫延遲高于DRAM而讀延遲和DRAM近似的情況,而隨著實際的NVM硬件出現,這種設計不再合理.經過實際評測,NVM的寫延遲同易失性內存近似,而NVM的讀延遲會比易失性內存高3倍.因此,受制于NVM的高讀延遲,這使得置于NVM的Hash索引無法提供高效的單點查詢.由于在很多實際負載中的查詢操作大部分為單點查詢,且查詢操作在很多負載中為主要的負載占比,因此主要面向查詢優化而設計的HybridIndex無法再提供高效的系統吞吐量.
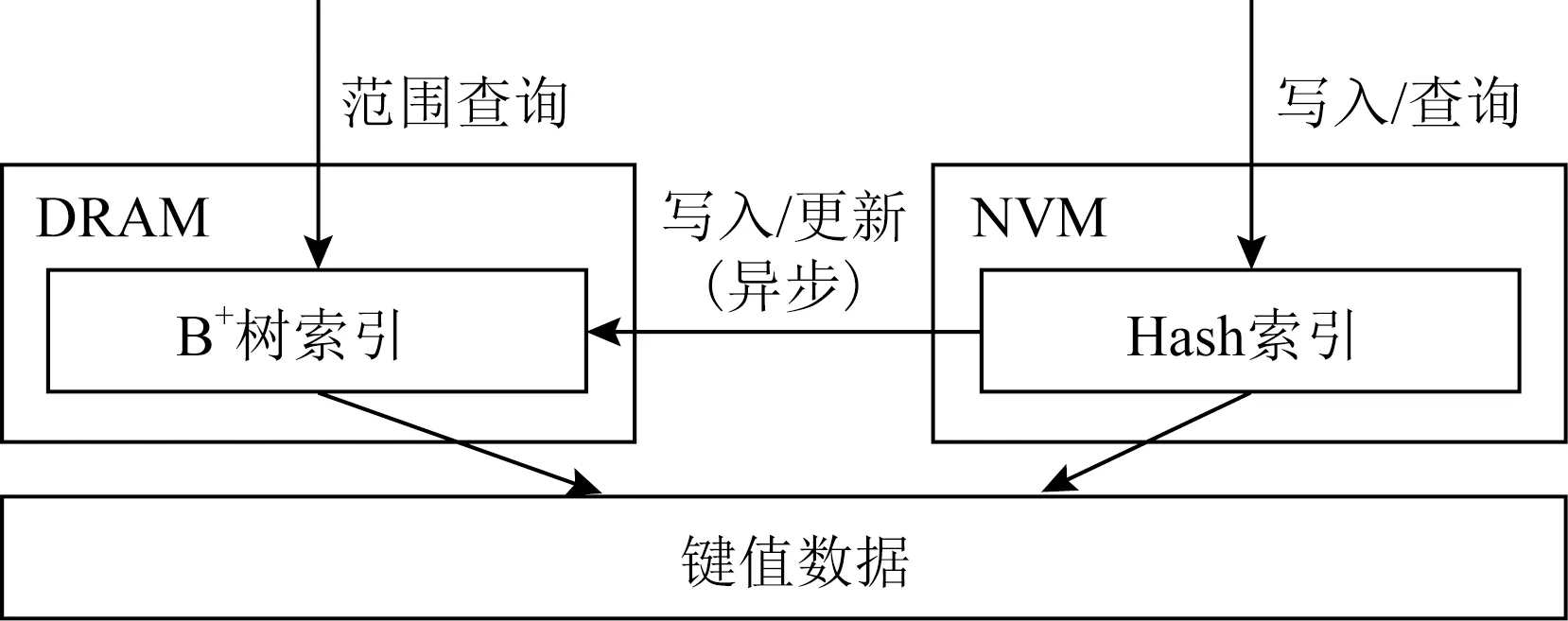
Fig. 15 HybridIndex system architecture圖15 HybridIndex系統架構
本文對HybridIndex面向實際的NVM硬件進行了優化并提出了HybridIndex+.如圖16所示,HybridIndex+對換了Hash索引和B+樹索引的位置,將Hash索引放在了易失性內存,將B+樹索引放在了NVM,并采用同步更新的方法同時更新2個索引.HybridIndex+采用了FAST-FAIR[11]作為持久化B+樹,在進行宕機恢復時,可以瞬間恢復B+樹,之后異步地重建DRAM中的Hash索引.HybridIndex+的設計優勢為:1)將Hash索引放在讀延遲更低的易失性內存有利于降低讀開銷,而B+樹由于只提供范圍查詢服務,因此在查詢B+樹通常會查詢整個葉子節點,可以有效地利用NVM較大讀粒度的特點,不會造成讀放大問題;2)在進行宕機恢復時,HybridIndex+在恢復完B+樹后,HybridIndex+便可以正常提供服務,而易失性內存中Hash索引的恢復會放在后臺異步進行.在這個過程中,B+樹即可提供單點查詢又可提供范圍查詢,當Hash索引恢復完成后,Hash索引便可提供更高效的單點查詢服務.相比HybridIndex需要等待B+樹全部恢復完成才可提供完整的查詢服務,HybridIndex+有著更低的宕機恢復時間.

Fig. 16 HybridIndex+ system architecture圖16 HybridIndex+系統架構
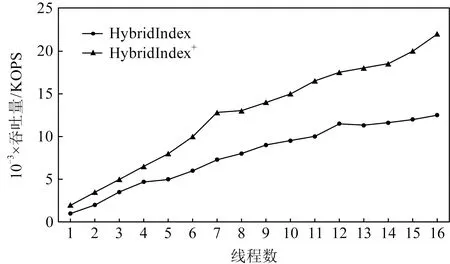
Fig. 17 Read performance comparison of HybridIndex and HybridIndex+圖17 HybridIndex和HybridIndex+讀性能對比
評測結果如圖17所示,經過優化后,Hybrid-Index+的讀性能最多可提升至HybridIndex的1.8倍.但是由于采用了同步更新方法,HybridIndex+的寫性能相比HybridIndex降低了30%.此外,由于HybridIndex+大部分讀發生在DRAM中,而HybridIndex的讀均發生在NVM中,由于NVM的讀帶寬相比DRAM較差,因此隨著線程的不斷增加,HybridIndex的性能與HybridIndex+的性能差距逐漸增大.
討論:在上述評測中,HybridIndex+考慮采用同步方式修改Hash表,這是因為若采用異步方式修改,可能存在查詢Hash表時該更新還在異步隊列中,這使得該查詢需要等待隊列中的更新完成后才能得到有效的數據,這將增加讀請求的延遲.因此,對于寫占比較大的負載場景,更加適合使用HybridIndex來降低寫延遲,而對于讀傾斜較高的負載場景,使用HybridIndex+能獲得更低的讀取延遲.此外,也可以根據實時的負載壓力動態調節混合索引的同步異步更新方式.比如,可以在寫負載較高而讀負載較低時采用異步寫的方法去降低寫延遲,而當讀負載較高寫負載較低時可以采用同步寫的方式去降低讀延遲.
3.2 案例分析:基于持久化內存的異步緩存方法
在過去的幾年里,很多研究普遍認為NVM的寫延遲較高的問題[9-16],很多工作針對NVM設計了各種寫優化索引,它們大多針對NVM設計了精細的數據結構從而減少了在索引持久化過程中的寫開銷.這些優化在現在看來依然是有效的,但過去的工作大多沒有針對NVM硬件高讀延遲的問題進行優化,因此,我們提出了一種基于持久化索引的異步緩存方法(asynchronous cache scheme, ACS)去優化現有持久化索引.
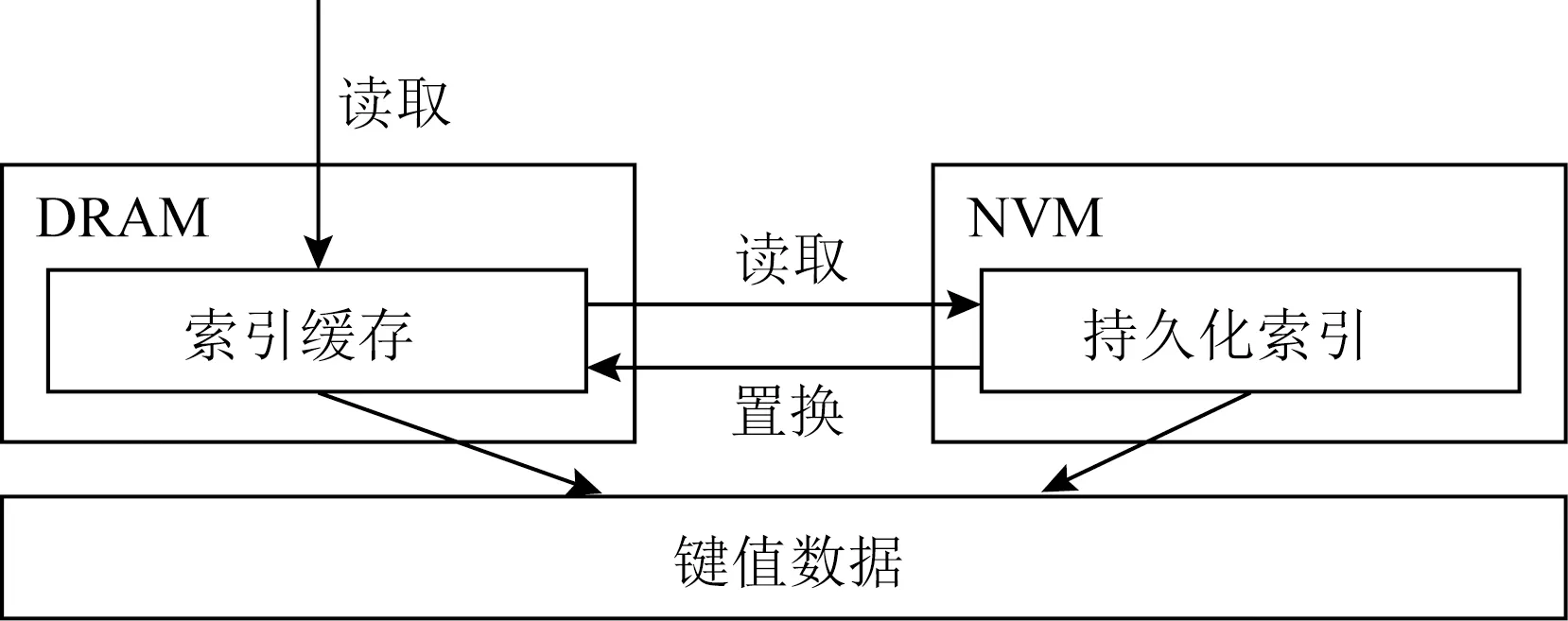
Fig. 18 Asynchronous cache scheme based on NVM圖18 基于持久化內存的異步緩存方法
ACS的設計思路是在不改變現有的持久化工作基礎上,在易失性內存中緩存部分索引去提高NVM中索引的讀性能.如圖18所示,ACS在易失性內存中維護了一個Hash索引去提供高效的單點查詢.當進行一次查詢時,首先需要搜索易失性內存中的Hash表,若該查詢命中,則返回結果;若該查詢未命中,則繼續搜索NVM中的持久化索引,若命中持久化索引則返回結果,并將該索引異步更新到易失性內存中的讀緩存中.需要注意的是,易失性內存中的Hash索引僅僅是NVM中索引的部分緩存,用戶可以根據自身需求配置其大小,當它可緩存的索引項飽和從而無法再進行寫入時,根據替換策略替換其中的索引項,在我們的實現中采用了LRU算法.此外,為了保證易失性內存和NVM中索引的同步,對于更新刪除操作,ACS采用了同步更新策略,對易失性內存和NVM同時存在的索引項進行同步更新,從而避免了數據不一致性的問題.
為了驗證有效性,我們使用該方法對一些過去的持久化索引的研究工作進行了優化.在這里我們選擇了基于B+樹實現的持久化索引FAST-FAIR[11]、FP-Tree[13]以及持久化跳表[14]作為優化對象.FAST-FAIR是在FAST會議上發表的基于B+樹的持久化索引工作,它利用FAST(failure-atomic shift) 和 FAIR(failure-atomic in-place reba-lance)算法去實現索引的持久化并保證高性能.FP-Tree也是基于B+樹的持久化索引工作,為了降低B+樹分裂時的寫開銷,FP-Tree只將葉子節點保存在NVM并將內部節點保存在DRAM,為了降低數據插入葉子節點的開銷,FP-Tree不對同一葉子節點內的數據進行排序.跳表作為一種簡單且高效的索引結構被廣泛應用在各種鍵值數據庫中,如LevelDB[7]和RocksDB[8]都將跳表作為內部數據的索引結構,自NVM出現以來也有工作討論基于NVM的持久化跳表實現.
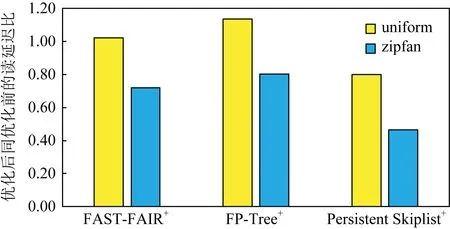
Fig. 19 Index read latency comparison after using ACS optimization圖19 經過ACS優化后的索引讀延遲對比
在為索引加載了5 000萬個索引項后,我們分別使用YCSB[22]中的均勻負載以及非均勻負載(負載分布為zipfan)進行了讀評測.在評測中,將緩存的容量設置為最多可容納總數據量10%的容量,評測結果如圖19所示.在均勻的負載情況下,由于緩存命中率較低從而導致一次搜索需要同時搜索緩存以及持久化索引,這使得ACS優化下的索引讀性能并沒有的提升;而在zipfan的負載情況下,緩存的命中率較高,因此一次搜索只會搜索緩存而不會搜索索引,因此經過ACS優化后的索引最多可以降低40%的讀延遲.可以看到,被優化索引的性能越差,通過ACS優化后所取得的收益越高.需要注意的是,對于插入操作,ACS不會影響索引的性能,但對于更新操作,ACS為了保證緩存和實際索引的一致性,需要在更新時對緩存進行修改,因此使用了ACS優化后的索引更新性能會下降20%~30%.
討論:ACS可以在zipfan負載下取得較高的緩存命中率,因此可以獲得較好的讀性能,然而在面向uniform的負載傾斜時面臨著讀延遲升高的情況.這主要是由于ACS的搜索為串行執行,當搜索DRAM中緩存不成功時,還需要繼續搜索位于NVM的持久化索引.為了解決該問題,我們可以使用并行搜索方法去降低請求延遲.如圖20所示,當進行一次搜索時,可以在搜索DRAM中緩存的同時讓后臺線程搜索位于NVM的持久化索引,從而避免當緩存未命中時而導致的高讀延遲.對于更新操作同樣可以使用該方法進行優化.
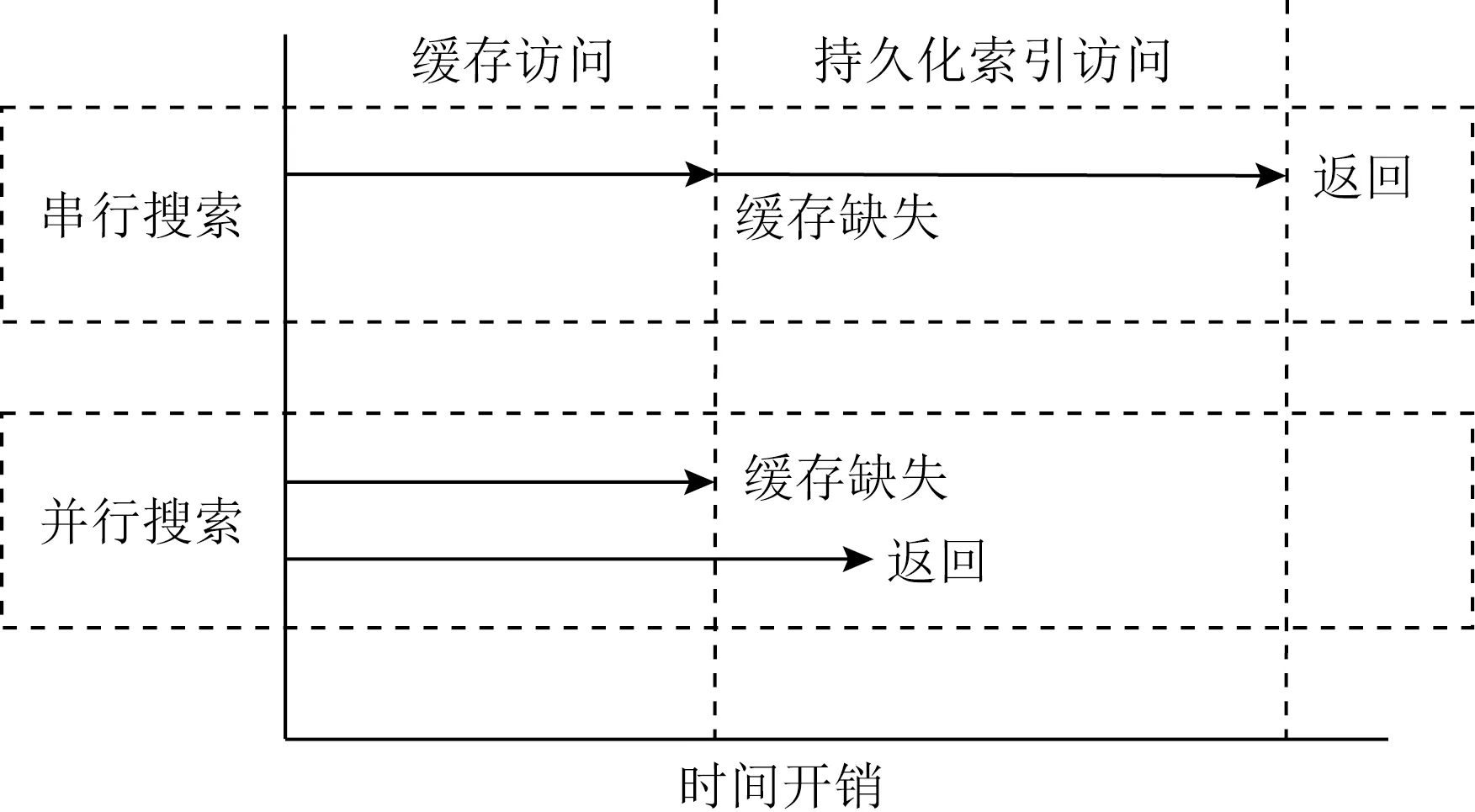
Fig. 20 Comparison of parallel/serial access time process based on ACS圖20 基于ACS的并行/串行訪問時間過程對比
實驗表明,經過并行搜索優化后的ACS,在緩存未命中情況下其讀性能和更新性能不會下降.然而,進行并發搜索會消耗額外的CPU和帶寬資源,因此在設計系統時可以根據緩存命中率決定是否啟用并行執行,當緩存命中率較低時可以開啟并行訪問模式,反之當緩存命中率較高時可以只開啟串行模式避免額外的系統資源消耗.
4 相關工作
目前已有其他AEP的測試工作,在文獻[23]中,作者測試了AEP的帶寬和延遲數據和AEP在若干系統中的表現(如Memcached, RocksDB).但該工作主要聚焦于AEP在系統內的表現,忽視了AEP本身的物理特性,未能挖掘出AEP的詳細訪問特性.而在文獻[24]中,除AEP的帶寬延遲信息外,作者進一步探索了AEP的尾延遲特性和多線程下的表現,分析了AEP的多線程訪問中性能下降的問題,但并發提及混合讀寫下AEP的讀寫保護機制.
在過去的幾年里,有許多工作基于NVM去設計高性能索引.Level Hashing[10]采用了2層Hash結構設計,在Hash表拓展時只進行一層結構的重構,從而減少了Hash拓展時的寫開銷;CCEH[9]采用段結構來降低Hash表拓展時的寫開銷;NV-Tree[12]針對B+樹進行優化,它將內部節點保存在易失性內存中,將葉子節點保存在NVM中,從而減少了樹分裂時對NVM設備被造成高昂寫開銷;FP-Tree[13]基于NV-Tree基礎上設計了簡單高效的并發算法并利用signature槽優化了訪問葉子節點時開銷;FAST-FAIR[11]設計了一種高效的持久化B+樹算法;WORT[16]針對字典樹在NVM中進行了寫優化.
這些工作大多面向NVM高昂的持久化開銷來進行優化,本文的工作主要面向非易失性的高讀延遲進行優化,在保留過去研究設計的基礎上設計了面向混合內存架構的異步緩存方法,在高傾斜的讀負載情況,我們的優化能降低不同索引20%~40%的讀延遲.
5 總 結
本文對實際的非易失性內存器件AEP進行了評測.基于評測結果發現,AEP的硬件性能同之前的假設有所不同:AEP同DRAM相比有著更高的寫延遲以及更低的讀延遲.為此,本文重新審視了之前的工作.一方面,針對過去的混合索引研究工作,本文提出對換索引位置提高索引的搜索性能,實驗表明,HybridIndex+相比HybridIndex可提升80%的讀性能;另一方面,不改變原索引結構的基礎上,本文提出了在DRAM中建立高速緩存的方法去加速AEP中的持久化索引搜索.實驗表明,本文提出的優化方法最多可以降低50%的讀延遲.在本文中主要討論了在不改變原索引設計的基礎上如何基于混合內存架構去提升原索引性能.然而,根據硬件評測結果顯示,AEP作為可字節尋址設備依然與DRAM有著不小的區別,比如AEP有著更低的讀寫帶寬以及更大的訪問粒度,這也為日后的持久化索引研究工作提供了更多挑戰.
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
