面向深度學習的公平性研究綜述
2021-02-07 02:51:28陳晉音陳奕芃陳一鳴鄭海斌紀守領
計算機研究與發(fā)展 2021年2期
陳晉音 陳奕芃 陳一鳴 鄭海斌 紀守領 時 杰 程 瑤
1(浙江工業(yè)大學網絡空間安全研究院 杭州 310023)2(浙江工業(yè)大學信息工程學院 杭州 310023)3(浙江大學計算機科學與技術學院 杭州 310058)4(華為國際有限公司新加坡研究院 新加坡 138589)(chenjinyin@zjut.edu.cn)
目前,深度學習算法已經取得了巨大的進步,并且越來越多地用于影響個人生活的決策應用中,包括圖像分類[1]、欺詐檢測[2]、情緒分析[3]、面部識別[4]、語音理解[5]、自動駕駛[6]、醫(yī)學診斷[7]等,深度學習在這些復雜任務上的性能已經達到甚至超過了人類決策的水平,能夠實現比機器學習更高的準確率.然而,深度學習在基于種族、年齡、性別等敏感屬性上的應用仍然具有不公平性,這種基于數據的學習方法會過度關聯敏感屬性,可能會對受保護群體表現出歧視行為,從而對個人和社會產生潛在的負面影響.例如,美國法院使用COMPAS作為刑事司法系統(tǒng)中的風險評估工具,用來衡量每一個被告再次犯罪的概率.然而,對此工具的調查發(fā)現COMPAS對于種族這一敏感屬性存在不公平性,非裔美國人被告再次犯罪的風險估計平均高于白人被告[8].在醫(yī)學領域,年齡作為一種潛在的敏感屬性,會影響基于深度學習診斷系統(tǒng)的評估結果.例如,來自UCI機器學習知識庫的Heart Dataset包含了906名不同年齡段患者的14個處理過的特征[9].這個數據集的目標是準確地預測一個人是否患有心臟病,而研究發(fā)現系統(tǒng)對年齡的偏見可能會導致不必要的醫(yī)療護理.在某些簡歷篩選工具中,存在對性別這一敏感屬性產生歧視性行為的現象,導致男性在應聘過程中比女性更有優(yōu)勢.深度學習在應用過程中存在的不公平現象引起了業(yè)界和學術界的廣泛關注,Du[10]和Ross等人[11]使用局部解釋對深度模型進行正則化訓練從而實現模型的公平;Elazar[12]和Zhang等人[13]使用對抗性訓練從模型的隱層表示中去除敏感屬性的信息,從而得到一個公平的分類器.
與機器學習方法相同,深度學習存在的偏見也是來自于數據和模型.一方面,深度學習是基于數據驅動的學習范式,它使模型能夠自動從數據中學習有用的表示.但是這些數據在標注過程中會引入偏見,這些數據偏見被深度模型復制甚至放大.另一方面,深度模型的結構是基于經驗設計的,其訓練是一個黑盒過程,因此很難確定訓練好的模型是基于正確的理由做出的決定,還是受偏見影響做出的不公平判斷,這也使得模型去偏成為極具挑戰(zhàn)性的任務.
目前,面向深度學習的公平性研究領域還有很大的發(fā)展空間,針對來自數據、模型的偏見問題已經成為重點關注對象,仍需要不斷的探索.同時由于深度學習在高風險領域中的應用,對數據偏見的預處理去偏、對模型偏見的中處理去偏、以及后驗性去偏方法,正在引起業(yè)界和學術界的關注.
為了更好地探究深度學習的公平性與未來的發(fā)展方向,本文將綜述深度學習偏見的不同來源并分類,對預處理去偏方法、深度模型的公平性訓練方法以及后驗去偏方法進行介紹,并列舉目前主流的面向深度學習的去偏平臺及去偏方法的公平性評估指標,同時對未來可能的研究方向作出展望.
1 偏見的來源
由于訓練數據標注和深度模型結構設計本身存在偏見,會導致深度學習任務的預測結果存在不公平現象.根據偏見的來源不同,我們將偏見類型分為數據偏見和模型偏見.
1.1 數據偏見
訓練數據中可能存在由歷史社會原因產生的偏見,在有偏見的數據上學習的模型可能會導致預測結果的不公平性.數據的偏見會以多種形式存在,Suresh等人[14]討論了數據偏見的不同來源,以及這些偏見的產生方式;Olteanu等人[15]準備了一份完整的不同類型偏見的列表,并對由于數據偏見而產生的后果進行分析;Mehrabi等人[16]總結了以上2篇論文中引入的一些最普遍數據偏見的來源,但是缺少對偏見來源的細粒度分類.
在本文中,我們將介紹這些數據偏見的定義并進行詳細說明,此外還將按照發(fā)生的原因對這些數據偏見進行細粒度的分類.我們將其分為時間偏見、空間偏見、行為偏見、群體偏見、先驗偏見、后驗偏見.
1.1.1 時間偏見
時間偏見是指由于時間維度的差異引起的偏見.例如,在Twitter上可以觀察到一個例子,人們談論一個特定的話題時開始使用標簽來吸引注意力,然后不使用標簽繼續(xù)討論該事件[15,17],這是由不同時期人群和行為的差異產生的[15].另一個典型的時間偏見是縱向數據偏見,觀察性研究經常把橫斷面數據當作縱向的.例如,對大量Reddit數據的分析顯示,評論長度會隨著時間的推移而減少[18].
然而,大量的數據代表的是人口的橫截面快照,實際上包含了不同年份加入Reddit的不同群體.當數據按隊列分列時,發(fā)現每個隊列中的評論長度隨時間增加[18].時間偏見可能會導致數據缺失,對后續(xù)的分析統(tǒng)計帶來困難.
1.1.2 空間偏見
空間偏見主要指的是由數據空間維度產生的偏見,也就是常說的維數災難.Verleysen等人[19]指出基于學習原理的數據分析工具可從學習樣本中推斷出知識或信息.顯然,通過學習建立的模型僅在可獲得學習數據的空間范圍內有效.模型不可能對與所有學習點都不相同的數據進行概括.
因此,成功開發(fā)學習算法的關鍵要素之一就是要有足夠的數據進行學習,以便它們可以填充模型必須包含的空間.在保持其他所有約束不變的情況下,學習數據的數量應隨維度呈指數增長,例如,學習二維數據需要100個具有相同平滑度的模型;對于3維模型,則需1 000個.指數級增長是維數災難后果,這些數據通常會對算法的行為和性能產生不利影響.對于這類偏見,我們通常采用降維的方法進行偏見的減輕.
1.1.3 行為偏見
行為偏見可以分為社會行為偏見[20-21]和用戶行為偏見[21].其中社會行為偏見是由社會歷史固有的偏見或者他人的行為引起的偏見,可分為社會偏見[20]、緊急偏見[22]、歷史偏見[14]、資助偏見[16].社會偏見[18]的產生是由于他人的行為可能會影響我們的判斷,例如,用戶想要評價或回顧一個得分較低的項目,但當受到其他高評分的影響時,用戶可能認為自己太過苛刻,從而會改變自己的評分[20-21].緊急偏見[22]的發(fā)生由于人口、文化價值觀或社會知識的變化而產生的,這種偏見更可能在用戶界面中被觀察到,因為通過設計,界面傾向于反映未來用戶的能力、特征和習慣.歷史偏見[14]是指世界上已經存在的偏見和社會技術問題,即使給定一個完美的采樣和特征選擇,也會滲透到數據生成過程中.資助偏見[16]是指當公司為了滿足資助機構的要求而進行虛假報告,從而出現人為的偏見.例如,當公司的員工為了讓資助機構滿意而在他們的數據和統(tǒng)計中報告進行杜撰,使報告結果產生偏見.
用戶行為偏見[23]源于跨平臺、上下文或不同數據集的不同用戶行為.這類偏見的典型例子可在Miller等人[24]的研究中觀察到,其中作者展示了不同平臺之間的表情符號表達的差異如何導致人們的不同反應和行為,有時甚至導致交流錯誤.用戶行為偏見可以分為用戶交互偏見[23]、內容產生偏見[23]和流行偏見[23].用戶交互偏見[23]不僅可以在Web上觀察到,而且可以從2個來源觸發(fā)——用戶界面和通過用戶自己選擇的偏見行為[16].這種偏見可能會受到其他類型和子類型的影響,比如呈現偏見[20]和排名偏見[20].呈現偏見[20]是信息如何呈現的結果,例如,在Web上,用戶只能單擊他們看到的內容,因此其他內容不會被單擊,也可能是用戶沒有看到Web上的所有信息.排名偏見[20]是由于人們認為排名靠前的搜索結果是最相關、最重要的,這種想法會吸引更多的點擊量.這種偏見影響了搜索引擎[20]和眾包應用程序[25].內容產生偏見[15]源于用戶生成的內容在結構、詞匯、語義和句法上的差異.例如,Nguyen等人[26]討論了不同性別和年齡群體在使用語言方面的差異.流行偏見[27-28]是由于越受歡迎的物品越容易被曝光.這種偏見可以在搜索引擎或推薦系統(tǒng)中看到,在這些系統(tǒng)中,受歡迎的對象會更多地呈現給公眾.行為偏見會使用戶在決策過程中受到其他外界因素的影響,導致獲得的信息不足或者帶有偏見,從而產生歧視性行為.
1.1.4 群體偏見
群體偏見[15]產生于數據集或平臺中所表示的用戶群體中的統(tǒng)計數據、代表數據和用戶特征與原始目標群體不同的時候.典型的例子是對于不同社交平臺上不同用戶的統(tǒng)計數據,女性更傾向于使用Pinterest、Facebook、Instagram等社交平臺,而男性在Reddit或Twitter等在線論壇上更活躍.Huang等人[29]調查了根據性別、種族、民族和父母教育背景劃分的年輕人使用社交媒體的例子和數據.
群體偏見可分為聚集偏見[14]和Simpson悖論[30].聚集偏見[14]是由于人們觀察其他不同的子群體得出錯誤結論時或者對一個群體的錯誤假設影響模型的結果和定義時產生的.例如,在臨床輔助工具中用于糖尿病診斷和監(jiān)測的糖化血紅蛋白水平在不同性別和種族之間存在復雜的差異.由于這些因素以及它們在不同的子群體中的不同意義和重要性,單一的模型很可能不適合一個群體中的所有群體[14].
Simpson悖論[30]可能會對由不同行為的子群體或個體組成的異構性數據的分析產生偏見.這類悖論的一個比較著名的例子是對加州大學伯克利分校的性別歧視訴訟[31].在分析了研究生院的招生數據后,可以發(fā)現與男性相比,女性被錄取為研究生的比例更小.然而,當對各個院系的招生數據進行分析后發(fā)現女性申請者具有平等的地位,在某些情況下甚至比男性小有優(yōu)勢.Simpson悖論在許多領域都得到了觀察,包括生物學[32]、心理學[33]、天文學[34]和計算社會科學[35].群體偏見會導致用戶得到錯誤的數據,從而得到錯誤的結論.
1.1.5 先驗偏見
先驗偏見發(fā)生在我們選擇、利用和測量特定特征的方式上.先驗偏見可以分為抽樣偏見[16]、自我選擇偏見[16]、鏈接偏見[15]和遺漏變量偏見[16].抽樣偏見[16]是由于子組的非隨機抽樣而產生的,結果是對一個種群估計的趨勢可能不能推廣到從一個新種群收集的數據.自我選擇偏見[16]是抽樣偏見的一種亞型,它是指研究對象在這種調查研究中選擇自己.例如,在一項關于成功學生的調查研究中,一些不那么成功的學生可能會認為他們是成功的,這就會影響分析的結果.
鏈接偏見[15]是指當從用戶連接、活動或交互中獲得的網絡屬性不同并歪曲了用戶的真實行為的現象.Mehrabi等人[36]指出,僅考慮網絡中的鏈接,而不考慮網絡中用戶的內容和行為,社交網絡會偏向低度節(jié)點.Wilson等人[37]也表明,用戶交互與基于特征的社交鏈接模式有顯著差異.網絡中的差異可能是許多因素造成的,如網絡采樣,它可以改變網絡度量,導致不同類型的問題[38-39].
遺漏變量偏見[16]發(fā)生于當一個或多個重要的變量被排除在模型之外的時候.例如,當公司設計模型來預測老客戶繼續(xù)訂閱他們服務的占比,然而很快發(fā)現,多數的用戶會取消訂閱并不遵從設計模型.取消訂閱的原因可能是市場上出現了一個新的強有力的競爭對手,它提供同樣的解決方案,但價格減半.然而預測模型并沒有考慮到競爭者的出現,因此,它被認為是一個被忽略的變量.
1.1.6 后驗偏見
后驗偏見主要是由于研究人員或觀察者行為導致的偏見,可以分為評估偏見[14]、因果偏見[16]和觀察者偏見[16].評估偏見[14]發(fā)生在研究人員評估過程中,例如,在評價諸如Adience和IJB-A等應用時,使用不適當的基準,從而造成偏見.因果偏見[16]是由于觀察者認為相關性意味著因果關系這一謬論的結果.
例如,公司的數據分析師想要分析顧客的忠誠度有多成功,這位分析師認為,參加了忠誠度計劃的顧客比沒有參加的顧客在該公司的商店里花更多的錢.這是有問題的,參加忠誠度計劃的顧客與計劃在此商店花更多錢這一相關性并不意味著它們之間的因果關系.觀察者偏見[16]一般發(fā)生在研究人員下意識地將他們的期望投射到研究中的時候.當研究人員在采訪和調查中無意地影響參與者,或者當他們挑選對他們的研究有利的參與者或統(tǒng)計數據時,這種類型的偏見就會發(fā)生.由于觀察者的異常或者錯誤行為會導致后驗偏見,從而得到有歧視性的決策結果.
1.2 模型偏見
深度學習算法本身工作方式上存在細微差別,這些差別可能導致深度模型做出不公平的決策.Du等人[40]從計算的角度將深度模型的不公平性分為預測結果歧視和預測質量差異2類.
1.2.1 預測結果歧視的偏見
歧視[41]是指由于某些群體的成員身份,深度模型對這些群體成員產生不利決策結果的現象.深度學習是基于數據驅動的學習范式,它使模型能夠自動從數據中學習有用的表示.這些數據中有可能包含偏見,這會導致深度模型復制、甚至放大數據中存在的偏見.更糟糕的是,深度模型不僅依賴這些數據中的偏見來做決策,還會做出毫無根據的聯想,放大對某些敏感屬性的刻板印象[42-43],這最終會產生具有算法歧視的訓練模型.預測結果歧視[40]可以進一步分為輸入歧視和表征歧視2類.Du等人[40]對這2個子類別進行了詳細的描述.
輸入歧視是盡管深度模型沒有明確地將種族、性別、年齡等敏感屬性作為輸入,但仍可能導致預測結果的歧視[44].大多數深度模型直接使用原始數據作為輸入,因此在輸入數據中沒有對敏感屬性進行分類處理.雖然沒有明確敏感屬性,但深度模型仍可能表現出無意的歧視,主要是由于存在一些與類成員高度相關的特征[40].例如,郵政編碼和姓氏可以用來表示種族,文本輸入中的許多單詞可以用來推斷被預測成員的性別,模型預測過程可能與受保護群體高度相關.最終,模型可能對某些受保護的群體產生不公平的決策.例如,在就業(yè)系統(tǒng)中,簡歷篩選工具認為男性更有優(yōu)勢,對女性存在偏見;貸款批準制度對屬于特定郵政編碼的人給予負面評價,導致對特定地域的歧視;在刑事司法領域,再犯預測系統(tǒng)預測將黑人囚犯歸類為“高風險”的可能性是白人囚犯的3倍.
有的時候預測結果歧視需要從表征的角度進行診斷和減輕[40].在某些情況下,將偏見歸因于輸入幾乎是不可能的,例如在圖像輸入領域,卷積神經網絡可以通過視網膜圖像識別患者自我報告的性別,并有可能基于性別產生歧視.此外,在某些應用場景中如果輸入維度太大,那么查找輸入的敏感屬性就很困難[43].在這些情況下,某些受保護屬性的類成員關系可以在深度模型中表示,模型將根據這些信息做出決策,并產生歧視[40].例如在信用評分中,使用原始文本作為輸入,作者的人口統(tǒng)計信息被編碼在基于深度模型中間表示的信用評分分類器中.
1.2.2 預測質量差異的偏見
預測質量差異[40]的偏見是指不同受保護群體模型的預測質量差異較大.與其他群體相比,深度模型對某些群體的預測質量較低.預測結果歧視主要涉及高風險領域的應用,而預測質量差異涉及一般領域的應用.例如,在計算機視覺領域[45],對膚色較深的女性面部識別的表現較差;在自然語言處理中[46],語言識別系統(tǒng)在處理某些種族的人產生的文本時表現明顯較差;在醫(yī)療保健領域[47],重癥監(jiān)護病房死亡率和精神病30天再入院模型預測準確度在性別和保險類型之間存在顯著差異.這通常是由于訓練數據代表性不足導致的問題,在這種情況下,用戶對人口的某些方面收集的數據可能不夠充足或不夠可靠.因為深度模型訓練的典型目標是將總體誤差最小化,也就是說模型如果不能同時適合群體中的所有個體,它將以適合群體中的大多數個體為目標.雖然這可以最大限度地提高整體模型預測的準確性,但它可能因為缺乏代表性數據從而導致對少數類群體的預測表現出不公平性.
綜上所述,我們根據偏見的來源將其分為數據偏見和模型偏見,并進一步將數據偏見分為時間偏見、空間偏見、行為偏見等6個子類,將模型偏見分為預測結果歧視和預測質量差異2個子類,并且對這些偏見進行了詳細的介紹.在表1中我們對數據偏見和模型偏見進行列舉,如表1中的“偏見類型”;并表示出它們的子類型,見第2列的“子類型”;以及這些子類型的組成,見第3列的“組成”.這些偏見可能發(fā)生在不同的階段,例如,數據本身存在的偏見(表1中用“數據階段”表示)、由于用戶行為導致的偏見(表1中用“用戶行為”表示)以及由于算法細微的差別產生的偏見(表1中用“算法階段”表示),在表中用“√”表示偏見所發(fā)生的階段.此外,在表1最后一列“去偏方法”中介紹了上述偏見的常用去偏處理方法,去偏方法的具體內容將在第2~4節(jié)進行詳細介紹.
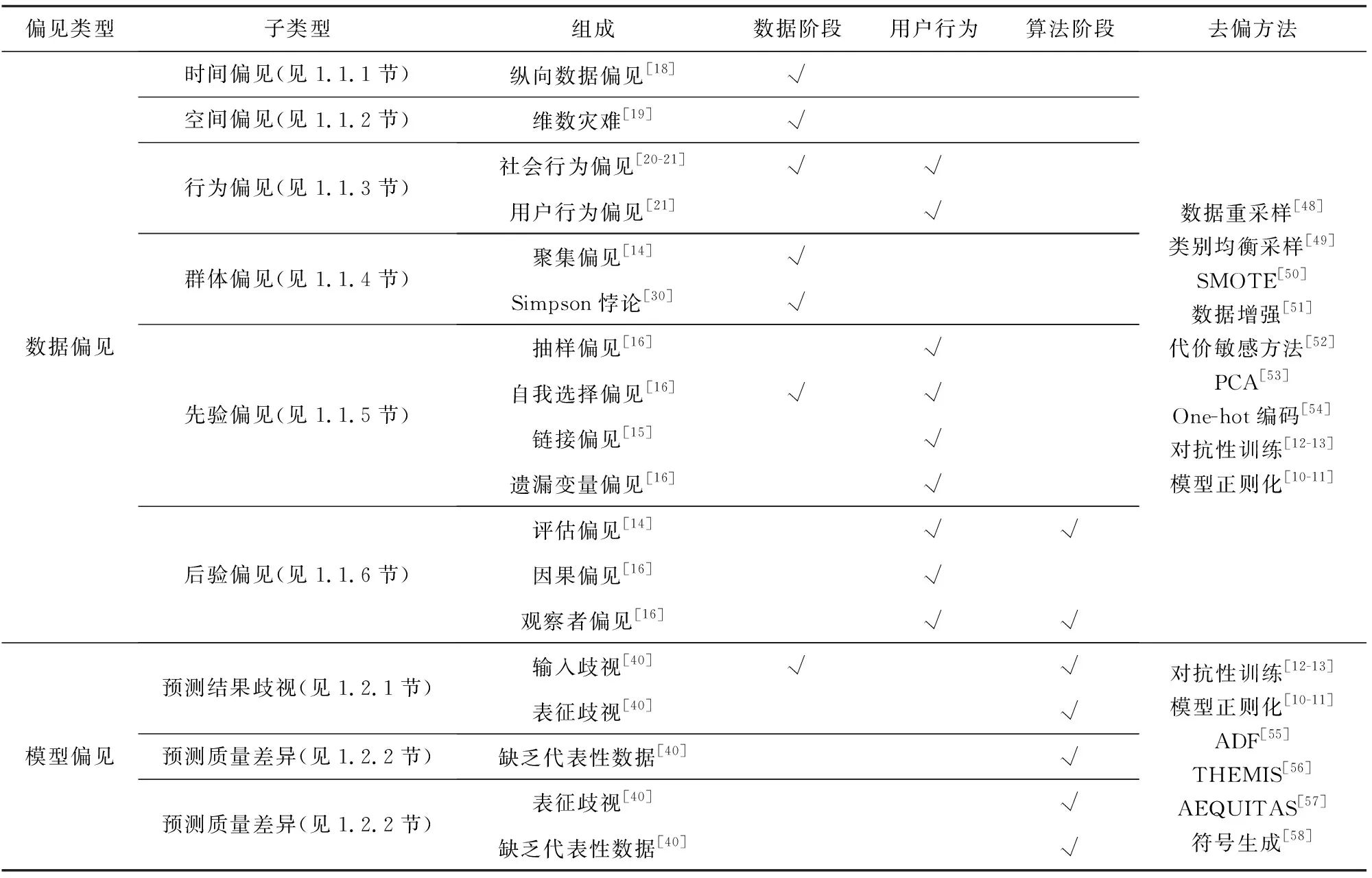
Table 1 Classification of Bias’s Sources表1 偏見來源的分類
2 基于預處理的數據去偏方法
預處理技術通過對數據進行處理,以減輕預測模型潛在的歧視.如果允許算法修改訓練數據,則可以使用預處理技術[59].例如,可以通過獲取更多數據來擴充數據集,對于代表性不強的數據集,更多的數據往往能得到更多的分布信息.數據預處理去偏可以分為數據層面處理方法和算法層面處理方法.
2.1 數據層面去偏處理方法
數據層面處理方法多借助數據采樣法等方法使整體訓練集樣本趨于平衡,從而達到去偏效果.常用的方法有數據重采樣、類別均衡采樣、數據合成、數據增強等.
2.1.1 基于數據重采樣的去偏方法

Burnaev等人[48]的實驗結果表明重采樣對數據集質量的影響在很大程度上取決于重采樣乘數,并且重采樣方法的性能取決于所使用的分類器,此方法在人工數據集上的去偏效果要好于真實數據集.如果正確選擇了方法,那么在大多數情況下,重采樣可以改善不平衡數據集的分類,從而達到去偏的效果.但是通過重采樣來對數據集進行去偏并不是總能達到預期效果,在某些情況下,數據重采樣可能會引入大量重復樣本,會減慢訓練速度,使模型在過采樣時容易過擬合,或者丟棄重要的重要示例.
2.1.2 基于類別均衡采樣的去偏方法
樣本類別分布不均衡也是導致深度模型不公平的一個原因,類別均衡采樣是解決這類問題一個方法.常用的類別均衡方法就是根據每個類別的觀察次數重新采樣和重新加權.Cui等人[49]認為隨著樣本數量的增加,新添加的數據點帶來的好處將減少.他們提出了一種新穎的理論框架,通過將每個樣本與其較小的鄰域相關聯來測量數據.有效樣本數通過簡單公式(1-βn)(1-β)來計算,其中n是樣本數,β∈[0,1)是超參數.Cui等人[49]設計了一種重新加權方案,該方案使用每個類的有效樣本數來重新平衡損失,從而產生類平衡的損失.
類別均衡采樣方法可以使不平衡樣本分布均衡,從而達到數據去偏的效果.但是,這種方法可能會破壞原屬性的線性關系,改變原樣本的某些特征值.此外,Shrivastava[60]等人提出了OHEM方法對樣本不平衡的問題進行處理.
2.1.3 基于合成數據的去偏方法
Chawla等人[50]提出了一種叫做Synthetic Minority Over-sampling Technique(SMOTE)的合成數據的方法.SMOTE通過創(chuàng)建“綜合”示例而不是通過替換來對少數群體進行過采樣.通過獲取每個少數種群樣本以及基于距離度量選擇類別下2個或者更多的相似樣本引入綜合示例,對少數種群進行過采樣.
合成數據是通過以下方式生成的:取所考慮的特征向量(樣本)與其最近鄰域之間的差,將該差乘以0到1之間的一個隨機數,并將其添加到所考慮的特征向量中.這將導致沿著2個特定特征之間的線段選擇一個隨機點,這樣就構造了許多新數據.Chawla等人[50]的實驗結果表明SMOTE方法可以提高少數群體分類器的準確性.SMOTE不僅提供了一種新的過采樣方法,并且SMOTE和欠采樣的組合比純欠采樣性能更好.合成數據這一去偏方法對數據量較少數據集的去偏效果較好,同時還能提高分類器的準確性,但是合成數據可能會引入重復樣本.
2.1.4 基于增強數據的去偏方法
數據增強[51](data augmentation)針對有限數據問題的數據空間提供解決方案,包含一套技術可用于加強深度學習所使用的數據集的大小和質量,從而給用戶提供更好的深度學習研究條件.
使用數據增強技術可以構建模型.例如,當輸入數據集是圖像時,可以應用圖像數據增強圖像方法.該增強方法包括幾何變換、色彩空間增強、抖動、混合圖像、隨機擦除、特征空間增強、對抗訓練、生成對抗網絡、神經樣式轉換和元學習等算法.數據增強旨在增加樣本數量,當數據量以及多樣性很少的情況下是非常有效的,但它無法克服小型數據集存在的所有偏差,例如,在犬種分類任務中,如果只有斗牛犬并且沒有金毛尋回犬,則數據增強方法不會創(chuàng)建金毛尋回犬.但是,使用數據增強可以避免或至少可以大大減少偏差的幾種形式,例如照明、遮擋、縮放等.數據增強的不足之處是可能引入重復樣本.
2.2 算法層面去偏處理方法
算法層面處理不平衡樣本問題的方法有代價敏感、主成分分析、One-hot編碼等.
2.2.1 基于代價敏感的去偏方法

為了能夠對少數類樣本進行比較準確的識別,可采用基于代價敏感學習的方法,將少數類視為重要類別,并令其錯分代價大于多數類的錯分代價.
2.2.2 基于主成分分析的去偏方法
主成分分析[53](principal component analysis, PCA)是一種線性、無監(jiān)督、生成和全局特征學習方法,可以對空間偏見進行減輕.它是通過創(chuàng)建新的不相關變量來實現的,從而連續(xù)地最大化方差.查找主成分變量的過程可以簡化為求解特征值以及特征向量的問題,并且新變量是通過現有的數據集定義的,而不是先驗的,因此PCA是自適應的數據去偏分析技術.從另一種意義上說,它也是自適應的,因為已經開發(fā)了針對各種不同數據類型和結構量身定制的技術變體.
2.2.3 One-hot編碼
One-hot編碼的操作十分簡單,從業(yè)人員經常將其用作更復雜技術的第一步.One-hot編碼[54]定義如下:令x為具有n個不同值x1,x2,…,xn的某個離散類別隨機變量.然后,特定值xi的One-hot編碼是向量v,其中v中第i個分量值為1,其余每個分量均為零.例如,假設我們有一些隨機變量x取自設置S={a,b,c}.令x1=a,x2=b和x3=c.x的一次編碼為:(1,0,0),(0,1,0)和(0,0,1).由于分類變量級別的One-hot編碼僅取決于級別的數量,因此One-hot編碼屬于確定的用于編碼分類變量的技術,可以用于神經網絡.對數據進行預處理去偏時,通常要確定2個相似個體特定特征之間的度量距離,One-hot編碼能更加合理的計算特征之間的距離,從而達到去偏的效果.Ruoss等人[61]使用One-hot編碼對數據進行預處理.
除了以上介紹的一般數據預處理的方法外,各類文獻中也提出了各種方法.為了減輕數據偏見對最終決策帶來的影響,Benjamin[62],Gebru[63]等人將數據表作為數據的支持文件來報告數據集創(chuàng)建方法、其特征、動機及其偏見.Holland等人[64]提出了標簽,就像食品上的營養(yǎng)標簽一樣,以便更好地對每個任務的每個數據進行分類.除了這些一般的技術,一些工作還針對更具體類型的偏見.例如,Alipourfard[65],Zhang等人[66]提出了自動發(fā)現數據中Simpson悖論的方法.在一些工作中,因果模型和圖表也被用于檢測數據中的直接歧視,以及對數據進行修改的預防技術,以使預測不存在直接歧視.Hajian等人[67]還致力于防止數據挖掘中的歧視,針對直接歧視、間接歧視和同時產生的影響.生成式對抗網絡可用于為少數生成合成數據,這可以提高少數群體的預測質量,同時又不影響未受保護群體的預測性能,從而避免對這些群體的歧視.
3 深度學習模型去偏
在介紹了數據預處理方法之后,我們在本節(jié)中將介紹深度學習模型去偏方法,確保深度學習模型的公平性.模型去偏方法通常可以分為模型正則化和對抗性訓練2類.前者通過在總體目標函數中添加輔助正則化項來實現,顯式或隱式地對某些公平性度量施加約束,后者可以從深度模型的中間表示中去除敏感屬性的信息,從而得到一個公平的分類器.
3.1 基于模型正則化的去偏方法
正則化是模型去偏的一種方法,具體來說,使用局部解釋對模型訓練進行正則化訓練[10-11].對于整個輸入x,除了真值y之外,這種正則化還需要特性方面的注釋r,指定輸入中的每個特性是否與受保護的屬性相關,r可以進一步融入到訓練過程中,目的是使深度模型更加公平.正則化的總損失函數如式(1)所示:
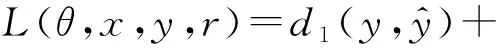
(1)
其中,d1為正態(tài)分類損失函數,R(θ)為正則化項.函數floc(x)是局部解釋方法,d2是距離度量函數.這3個術語分別用于指導深度模型進行正確的預測,超參數λ1和λ2用于平衡這3個術語.
例如,Du等人[10]采用一種名為CREX(CRedible EXplanation)的方法對深度模型進行正則化訓練,使用的損失函數如式(2)所示:
L(θ,x,y,r)=Lsup v+λ1Lrationale+λ2Lsparse,
(2)
其中,作者使用的正態(tài)分類損失函數為交叉式損失Lsup v.CREX的核心思想是深度模型應該依靠合理的證據來做出決定.CREX的示意圖如圖1所示.在圖1中,黑色實線表示向前的路徑,兩端帶箭頭的虛線是損失,一側帶有箭頭的虛線表示坡度流.xn,rn,yn三個向量從左到右分別是輸入、解釋和基本原理.
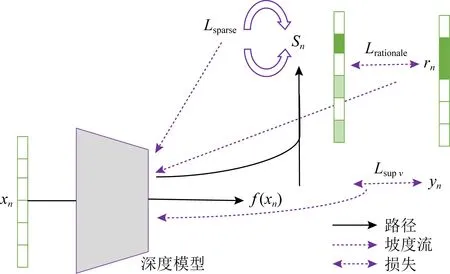
Fig. 1 Schematic of CREX[10]圖1 CREX示意圖[10]
3.2 基于對抗性訓練的去偏方法
從模型訓練的角度來看,對抗性訓練是一種典型的解決方案,可以從深度模型的中間表示中去除敏感屬性的信息,從而得到一個公平的分類器[12-13,68].其目標是學習一種高級輸入表征,該表征對主要預測任務具有最大信息量,同時對受保護屬性具有最小預測性.對抗性訓練過程可以表示為式(3):
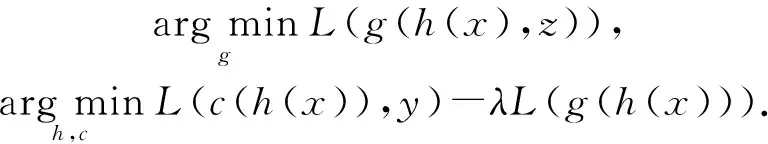
(3)
深度模型可以記為f(x)=c(h(x)),其中,h(x)是輸入x的中間表示,c(·)負責將中間表示映射到最終的模型預測.f(x)可以是通過反向傳播學習的任意深度模型.要檢查的受保護屬性使用z表示,主任務f(x)=c(h(x))本身并沒有與受保護的屬性z進行排序.構造了一個對抗性分類器g(h(x)),從表示h(x)中預測受保護屬性z.訓練是在f(x)和對抗性分類器g(h(x))之間迭代進行的.經過一定的迭代次數,我們可以得到去偏的深度模型.
圖2為對抗性訓練的示意圖,利用對抗性訓練,通過表示減少歧視.直覺上是通過加強深度表示來最大限度地預測主要任務標簽,同時最小限度地預測敏感屬性.

Fig. 2 Schematic of adversarial training[40]圖2 對抗性訓練示意圖[40]
對抗訓練廣泛適用于不同的深度模型架構和不同的輸入格式,包括帶有圖像數據的卷積神經網絡[69]、帶有文本數據的循環(huán)神經網絡[70]、以及帶有分類數據的多層神經網絡[71].Zhang等人[13]提出了一個模型用來減輕從關聯的數據中學習到的模型中的偏見.在這個模型中,他們試圖最大限度地提高y的預測精度,同時最小化對手預測受保護或敏感變量的能力.
3.3 其他模型去偏方法
除深度模型外,在傳統(tǒng)的機器學習中也有很多模型去偏的方法.Bolukbasi等人[41]注意到在詞類比測試中使用最新的詞嵌入時,“男人”將被映射為“計算機程序員”,而“女人”將被映射為“家庭主婦”.針對這種對女性的偏見,作者提出一種詞嵌入的方法,該方法通過遵循以下步驟對性別中性詞進行嵌入:首先識別性別子空間,然后確定捕獲偏見的嵌入方向[41],最后將性別子空間與性別中性詞分開,并確保在性別子空間中將所有性別中性詞都刪除并歸零[41].
Zhao等人[43]研究了語義角色標簽模型和數據集imSitu,并發(fā)現在imSitu中烹飪圖像中只有33%的代理角色是男人,其余67%的烹飪圖像中有女性代理角色.除了數據集中現有的偏見外,該模型還會放大偏見.因此,他們提出了一種稱為RBA(reducing bias amplification)的校準算法.RBA是一種通過在結構化預測中校準預測來消除模型偏見的技術,其思想是確保模型預測在訓練數據中遵循相同的分布.
在人工智能領域中已經提出了各種方法來消除偏見的影響,這些方法大多數都試圖避免敏感或受保護屬性對決策過程的影響.Lipton等人[72]提出通過在訓練階段允許使用受保護屬性,但避免在預測期間使用受保護屬性,他們認為通過這種方法可以減輕偏見.Louizos等人[73]使用變分編碼器對表示學習進行去偏.Mehrabi等人[36]提出了一種新的社區(qū)檢測方法,以減輕模型對在線社交社區(qū)中處境不利群體的損害.這些對其他模型去偏方法目前還沒有廣泛應用于深度模型.
4 深度學習的后驗去偏
深度學習模型后驗性去偏使用可解釋技術作為一種有效的工具,用戶可以利用可解釋技術生成特征重要度向量,然后對特征重要度向量進行分析,從而達到去偏的效果.在本節(jié)中,我們先介紹深度模型可解釋性的2種分類,然后對后驗性去偏方法進行介紹.
4.1 深度模型的可解釋性
可解釋性可以作為一種有效的調試工具,對模型進行分析,最終提高模型的透明度,保證模型的公平性.深度模型可解釋性一般可分為2類:局部解釋和全局解釋,這取決于目標是局部理解特定的預測,還是全局理解的預測[43].
4.1.1 深度模型的局部解釋技術

Fig. 3 Illustration of DNN local interpretation as well as global interpretation[40]圖3 DNN局部解釋和全局解釋的示意圖[40]
局部解釋可以說明模型是如何對特定輸入進行某種預測的(圖3(a)).它是通過對模型的輸入特征進行屬性預測來實現的,最后以特征重要度可視化的形式進行說明.以貸款預測為例,該模型的輸入是一個包含分類特征的向量,其中得分較高的特征表示與分類任務的相關度較高.局部解釋方法大致可分為4類:基于局部逼近的[41]、基于擾動的[41]、基于反向傳播的[70]以及基于分解的[70]方法,這些方法都可以被用來生成一個輸入的特征重要向量.
4.1.2 深度模型的全局解釋技術
全局解釋的目標是提供一個關于預先訓練的DNN所捕獲的知識,并以一種直觀的方式向人類說明所學的表示(圖3(b)).解釋可以看作是一個函數fglobal:Eh→Em,從中間表示Eh映射到人們可以理解的概念Em[74].在本例中,Eh是由特定層上的特定通道派生的表示,多個神經元的組合可以代表更抽象的概念[75].這里的Eh對應著不同通道甚至不同層的組合,特別是那些受保護的概念,它們通常基于多個基本的低級概念.例如,在人臉圖像識別應用中,可以通過多個局部線索來顯示性別和種族概念.因此,與單個神經元學習的概念相比,由多個神經元組合產生的概念與深度模型的公平性更相關.
4.2 模型的后驗去偏方法
深度學習模型后驗性去偏方法主要是搜索模型中的歧視實例,通過檢測偏見來進行模型再訓練,以減少歧視,達到模型的公平性.第1種方法采用自頂向下的方法,利用局部解釋生成特征重要度向量,然后對特征重要度向量進行分析.第2種解決方案以自底向上的方式實現.人們首先預先選擇他們懷疑與受保護屬性相關聯的特性,然后分析已識別的特性的重要性[76].這些對公平性敏感的特征被干擾,通過特征被直接刪除或特征被替代來實現.然后將擾動輸入到深度模型中,觀察模型預測的差異.如果這些被懷疑為公平敏感特征的擾動最終導致模型預測發(fā)生顯著變化,則可以斷言深度模型捕獲了偏見,并根據受保護的屬性進行決策.第3種方法利用全局解釋,首先,利用全局解釋來分析深度模型對受保護屬性相關概念的學習程度.這通常是通過指向深度模型中間層激活空間的一個方向來實現的[74-75,77].其次,在確認一個深度模型已經學習了一個受保護概念后,我們將進一步測試該概念對模型最終預測的貢獻.可以采用不同的策略來量化概念敏感度,包括自上而下計算深度模型預測對概念向量的方向導數[74],自下而上將該概念向量添加到不同輸入的中間激活中,觀察模型預測[78]的變化.最后,使用數值分數來描述受保護屬性的表示偏見水平.在2種方式中,數值敏感性得分越高,該概念對深度模型預測的貢獻越顯著.
Zhang等人[55]提出了一個基于梯度的可擴展的算法,稱為ADF(adversarial discrimination finder),用于生成個體歧視實例,它是專門為深度模型設計的.ADF的概述如圖4所示.
ADF由2部分組成,即全局生成(左邊的部分)和本地生成(右邊的部分).在全局生成過程中,對原始數據集中的樣本進行聚類,并以循環(huán)方式從每個聚類中選擇種子實例.全局生成的目標是增加所生成的個體歧視實例的多樣性.在全局生成中使用梯度通過最大化2個相似實例的深度模型輸出之間的差異來指導個體歧視實例的生成.如果成功生成了一定數量的個別歧視性實例或超時,則全局生成將停止.識別出的個別歧視實例然后作為本地生成的輸入.其思想是搜索個體歧視性實例的鄰域以尋找更多的歧視性實例.梯度在本地生成中以不同的方式使用作為引導,即我們利用代表每個屬性重要性的梯度的絕對值來識別與種子差異最小的個體歧視性實例,同時保持它們的模型預測[55].

Fig. 4 An overview of ADF[55]圖4 ADF概述圖[55]
除此之外,Galhotra等人[56]提出了THEMIS,通過在其域內隨機采樣每個屬性并識別出那些有偏見的實例來衡量歧視的發(fā)生頻率.Udeshi等人[57]開發(fā)了AEQUITAS,它包括一個全局搜索和一個本地搜索,即AEQUITAS首先搜索輸入空間的隨機抽樣(又名全局搜索),然后基于全局搜索的結果來進行本地搜索,通過將已識別的個體歧視實例與選定的屬性沿隨機方向進行干擾,以識別盡可能多的歧視的實例.Agarwal等人[58]提出了一種符號生成的方法,該方法首先使用現有的方法生成一個局部解釋決策樹來近似模型決策,然后根據決策樹進行符號執(zhí)行來生成測試用例[79].與AEQUITAS一樣,它還將基于決策樹的全局搜索與局部搜索相結合,前者的目標是最大化路徑覆蓋,后者的目標是最大化歧視性實例的數量.
對第2~4節(jié)介紹的基于數據預處理的去偏方法、模型去偏方法以及后驗去偏方法及其相關原理整理在表2中.表格的第1列“類型”為3類不同的去偏方法,分別為基于數據預處理的去偏方法、深度學習模型去偏方法以及模型的后驗去偏方法,根據這些去偏方法應用的階段不同,我們在表格中將它們表示為“數據預處理去偏、模型去偏、后驗去偏”.表格的第2列“方法”列舉了相應的算法,其中列舉了8種預處理方法、2類模型去偏方法以及4種后驗性去偏方法,并且在第3列“原理”表示出對應算法的原理,在第4列“貢獻”和第5列“不足”分別列舉出它們的貢獻和不足.
5 去偏實驗平臺和公平性指標
在本節(jié)中,我們列舉常用的去偏實驗平臺和公平性指標,方便之后的研究.近年來,隨著人工智能技術的快速發(fā)展,許多科技公司推出了對應的深度學習去偏實驗平臺.其中Microsoft的Fairlearn、IBM的AI Fairness 360以及Google的ML-fairness-gym具有功能較全、豐富的演示代碼以及持續(xù)迭代更新等顯著特點.本節(jié)將詳細介紹這3個去偏實驗平臺.

Table 2 List of Debiasing Methods for Different Sources of Bias表2 針對不同偏見來源的去偏方法列表
5.1 數據集
本文提到的去偏實驗平臺應用了Adult數據集、Bank marketing數據集、Boston房價數據集、COMPAS數據集、Greman credit數據集、醫(yī)療支出小組調查(Medical expenditure panel survey, MEPS)等6個數據集.
Adult數據集包括48 842個連續(xù)或者離散的實例,其中訓練集實例32 561個,測試集實例16 281個,該數據集可用于預測一個人的年收入是否多于5萬美元;該數據集包括年齡、工種、學歷、職業(yè)、性別、種族等14個特征,其中6個連續(xù)變量,8個名詞屬性變量,其中性別和種族是敏感屬性.
Bank marketing數據集與葡萄牙的銀行有直接關聯,根據相關信息進行電話推銷,與該數據集對應的任務是分類任務,目的是用于預測客戶是否會認購定期存款;該數據集包括年齡、工作類型、婚姻狀況、受教育背景、信用情況、個人貸款、最后聯系月份、最后一次接觸距離上一次接觸的時間,以前的活動中聯系的次數等一共50個特征以及41 188個實例,其中年齡和信用情況是敏感屬性.
Boston房價數據集包含美國人口普查局收集的美國Boston住房價格的有關信息,這個數據集的每一行數據都是對波士頓周邊或者城鎮(zhèn)的房價的描述數據統(tǒng)計于1978年,數據中包含14個特征,506個案例.特征例如城鎮(zhèn)人均犯罪率、住宅所占比例、城鎮(zhèn)中黑人比例、低收入人群數等,其中城鎮(zhèn)中黑人比例是敏感屬性.
COMPAS數據集使用一種算法來評估刑事被告再次犯罪可能性,開發(fā)者為一般累犯和暴力累犯以及審前不當行為制定了風險量表,這種風險量表是根據“與累犯和犯罪職業(yè)高度相關的”行為和心理結構設計的,目前已經在美國紐約州、威斯康星州、加利福尼亞州等地投入使用,其敏感屬性為種族屬性.
Greman credit數據集通過一組屬性描述將申請人員分類為良好或不良信用風險,該數據集是根據個人的銀行貸款信息和申請客戶貸款逾期發(fā)生情況來預測客戶貸款違約情況,數據集包含24個維度的共1 000條數據.該數據集包括年齡、借款持續(xù)時間、現有的信貸數量等特征,其中現有的信貸數量和年齡是敏感屬性.
MEPS數據集始于1996年,其收集內容包括對家庭和個人、醫(yī)療提供者和雇主的大規(guī)模調查,并提供有關受訪者使用的醫(yī)療服務、服務的成本和頻率、人口統(tǒng)計等數據.
5.2 Microsoft公司的Fairlearn去偏實驗平臺
Microsoft推出了Fairlearn(1)https://github.com/fairlearn/fairlearn(version 0.4.6)工具包,它能夠評定和改正人工智能技術系統(tǒng)軟件的公平性.可讓人工智能系統(tǒng)的開發(fā)人員評估其系統(tǒng)的公平性并減輕任何客觀存在但是不明顯的不公平問題.全世界四大會計師會計師事務所之一的安永,在用于全自動評定借款管理決策的機器學習模型中,運用Fairlearn工具包來減少與性別有關的不合理結果,其剖析數據顯示最初男士借款的成功率比女士高15.3個百分點.根據正模型,安永的開發(fā)設計工作組改善了計劃方案的精確度,將性別導致的差別降至了0.43個百分點.
Fairlearn去偏實驗平臺涵蓋閾值優(yōu)化器[80]、網格搜索[81]以及冪梯度[82]等去偏算法.其中,閾值優(yōu)化器算法基于監(jiān)督學習中機會均等原理,將現有分類器和敏感特征作為輸入,對深度模型進行后處理去偏.
該平臺還包含群體總結、平均預測以及選擇率等16種度量指標,用來衡量深度模型去偏效果.其中平均預測度量指標用于計算(加權)平均預測結果,選擇率計算與輸出“良好”結果相匹配的預測標簽的比例.
5.3 IBM公司的AI Fairness 360去偏實驗平臺
IBM公司發(fā)布的AI Fairness 360工具包(2)https://github.com/Trusted-AI/AIF360(version 0.3.0)是一種可擴展的開放源代碼庫,可幫助檢測和減輕整個AI應用程序生命周期中機器學習模型的偏見.
AI Fairness 360去偏實驗平臺涵蓋一共11種去偏算法,例如優(yōu)化預處理[83]、不同影響消除[84]、均等賠率后處理[80]、校準后的均等賠率后處理[85]、學習公平表示[86]、對抗性去偏[13]、公平分類的元算法[87]、重新加權[88]、基于拒絕選項的分類[89]、正則化去偏[90]等去偏算法.對抗性去偏是一種過程中去偏的技術,學習分類器通過對抗生成的方式以最大程度地提高預測準確性,同時降低對手根據預測確定受保護屬性的能力,因為預測結果不可以攜帶任何敵手可以利用的會造成歧視的信息,因此保證了公平性.
該平臺還包含超過30種公平性度量指標,所有的度量指標可以根據選擇率和錯誤率分為如下4類:全面的群體公平性度量標準、全面的樣本失真指標集、廣義熵指數[91]以及差異公平和偏見放大[92]等.在這4類度量中具有代表性的有群體總結、平均預測以及選擇率等度量指標,這些度量指標在5.2節(jié)已經介紹.
5.4 Google公司的ML-fairness-gym去偏實驗平臺
Google提出了ML-fairness-gym(3)https://github.com/google/ml-fairness-gym(version 0.1.0),用于評估機器學習系統(tǒng)的公平性以及評估靜態(tài)數據集上針對系統(tǒng)的各種輸入的誤差度量的差異.ML-fairness-gym是用于構建簡單模擬的一組組件,這些模擬探索了在社會環(huán)境中部署基于機器學習的決策系統(tǒng)的潛在長期影響.隨著機器學習公平性的重要性變得越來越明顯,最近的研究集中在最初在靜態(tài)環(huán)境中定義的執(zhí)行公平性度量的潛在的令人驚訝的長期行為.
ML-fairness-gym去偏實驗平臺包括注意力分配[93]去偏算法以及長期公平[94]去偏算法,注意力分配算法通過對深度模型動態(tài)分配不同的注意力權重以避免包含偏見較大的部分參與總體決策,從而實現公平性.該平臺也包括錯誤率指標、借貸指標以及價值追蹤指標等公平性度量指標.
我們在表3中對以上3種去偏實驗平臺所使用的數據集、度量標準以及平臺所支持的去偏算法進行分類整理.因篇幅有限,在這里僅列舉出部分具有代表性的度量標準.
6 未來研究方向
本文面向深度學習的公平性進行了盡可能全面的調研,對去偏實驗平臺以及公平性指標進行了介紹.本節(jié)我們針對深度學習中的公平性,探討其在未來的研究發(fā)展方向,從不同角度分析之后可發(fā)展的研究內容.
6.1 公平性的度量標準
我們在第5節(jié)中對國際主流去偏實驗平臺中的公平性度量標準進行了介紹,但是目前關于公平的度量方法仍然沒有形成共識.在某些情況下,一些度量可能與其他度量相沖突.一個模型可能在某一指標上是公平的,但可能導致其他類型的不公平,所以探討公平性的度量標準是有必要的.
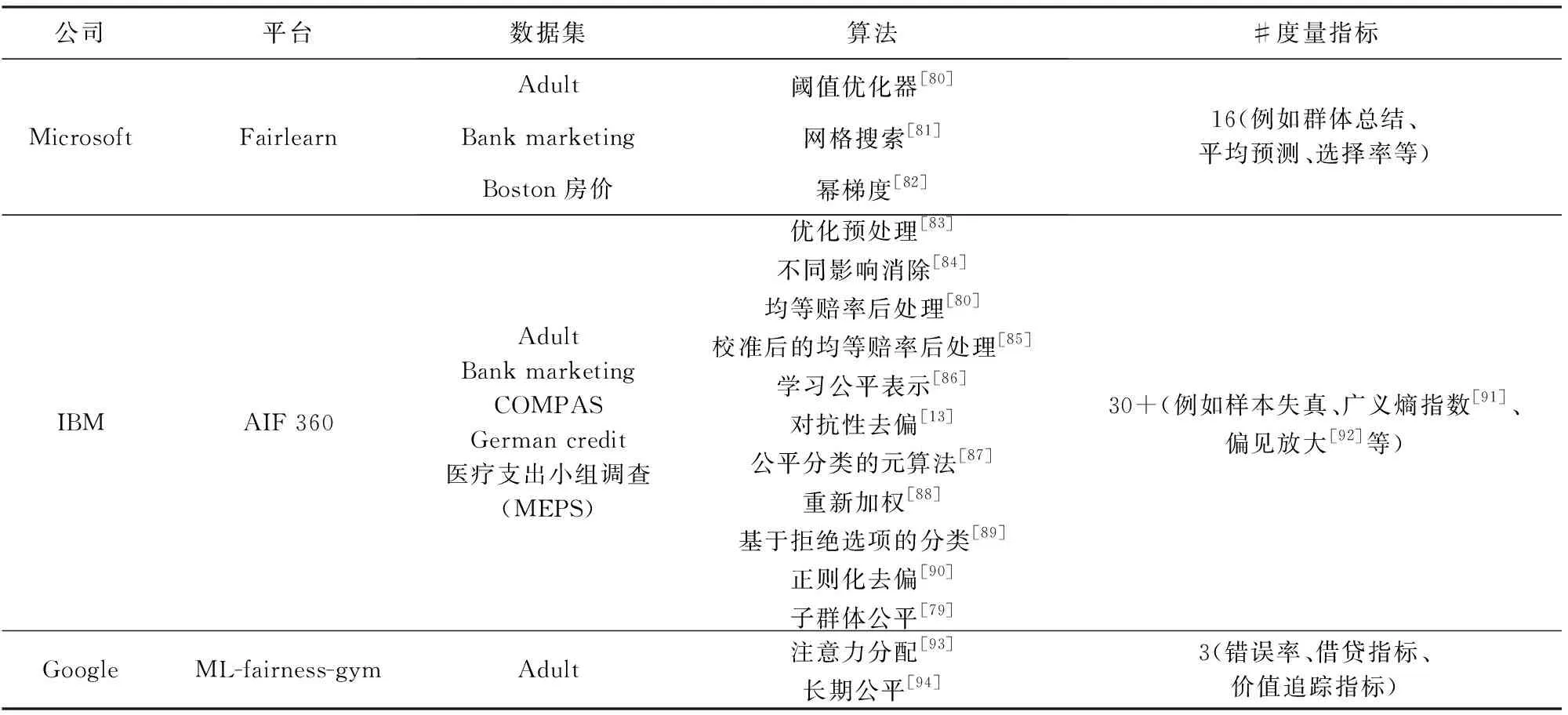
Table 3 Debiasing Experiment Platform表3 去偏實驗平臺
6.2 聯邦學習公平性問題
聯邦學習是一個機器學習框架,能有效幫助多個機構在滿足用戶隱私保護、數據安全和政府法規(guī)的要求下,進行數據使用和機器學習建模[95].在聯邦成員共享加密的模型參數或者中間計算結果的同時,也會共享各自存在的偏見,甚至是偏見疊加.對于聯邦學習的公平性,我們可以在聯邦環(huán)境下進行邊緣端偏見檢測,首先分析不同的聯邦成員在上傳加密的模型參數或者中間結果時,對其中攜帶的偏見信息進行檢測;然后,分析云端在下發(fā)共享參數信息時,檢測云端訓練的模型從成員中學到的疊加偏見.
6.3 遷移學習的公平性問題
遷移學習[96]是一種機器學習方法,就是把為任務A開發(fā)的模型作為初始點,重新使用在為任務B開發(fā)模型的過程中.遷移學習讓AI系統(tǒng)獲得“舉一反三”能力,但是從源域到目標域的遷移過程中,極大可能存在偏見的轉移.針對遷移學習中的公平性問題,可以從數據偏見轉移、算法偏見轉移、遷移的新增偏見3方面展開研究.在基于實例和基于特征的遷移中,研究數據的偏見轉移,對目標域的公平性影響.首先檢測源域中數據集存在的偏見,檢測目標域中數據集存在的偏見;對源域和目標域中的數據進行偏見對齊,得到偏見分布相似的數據集;使用偏見對齊的目標域中的數據進行遷移訓練,檢測目標模型與源模型的偏見差異,若偏見評價結果相等或更小,則有效消除數據偏見.
6.4 元學習的公平性問題
元學習利用以往的知識經驗來指導新任務的學習,具有學會學習的能力[97].在基于記憶的元學習中,網絡的輸入把上一次的y也作為輸入,并且添加了外部記憶存儲上一次的x輸入,這使得下一次輸入后進行反向傳播時,可以讓y和x建立聯系,使得之后的x能夠通過外部記憶獲取相關圖像進行比對來實現更好的預測[97].因此在歷史記憶中存在的偏見可能會不斷積累,對該偏見的消除十分重要.對于元學習的公平性,我們可以對記憶單元設計不同的權重分配策略,減弱歷史偏見的積累.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
