基于持久性內存和SSD的后端存儲MixStore
2021-02-06 09:27:32屠要峰陳正華韓銀俊關東海
計算機研究與發展 2021年2期
關鍵詞:一致性
屠要峰 陳正華 韓銀俊 陳 兵 關東海
1(南京航空航天大學計算機科學與技術學院 南京 211106)2(中興通訊股份有限公司 南京 210012)(tu.yaofeng@zte.com.cn)
近年來,隨著移動通信和物聯網技術的快速發展,數據的規模呈爆發式增長,傳統的存儲系統已經無法滿足不斷增長的海量數據存儲的需要.為解決數據存儲規模、數據備份、數據安全、服務質量、軟件定義等問題,分布式存儲系統應運而生.分布式存儲是通過軟件的方法把若干節點的存儲資源,如磁盤、內存等組織起來,對外提供虛擬的統一的塊、文件或對象接口的按需存儲服務.
本地文件系統如XFS(extents file system),EXT4(fourth extended file system),btrfs(B-tree file system)等,具有成熟、穩定的優勢,成為分布式存儲系統訪問本地存儲資源的主要方法.應用廣泛的分布式存儲系統Ceph的后端存儲FileStore也是基于XFS進行存儲訪問.這樣做的優勢是利用了文件和對象天然的映射關系,利用操作系統頁緩存機制緩存數據,利用索引節點(inode)緩存機制緩存元數據,同時從操作系統層面保證了磁盤的隔離性.但是這種架構也有明顯的缺陷[1],主要是事務一致性難以保證,元數據管理低效,以及缺乏對新型硬件的支持.鑒于此,Ceph在Jewel版本引入了BlueStore作為后端存儲.BlueStore將對象數據的存放方式改為直接對裸設備進行指定地址和長度的讀寫操作,不再依賴本地文件系統提供的POSIX(portable oper-ating system interface of Unix)接口.同時,BlueStore引入了RocksDB數據庫保存元數據和屬性信息,包括對象的集合、對象、存儲池的omap信息和磁盤空間分配記錄等,BlueStore有效避免了數據的雙寫,提升了元數據的操作效率,同時借助RocksDB解決了事務一致性問題.
BlueStore雖然改善了元數據效率和事務一致性,但在實際使用中存在一些明顯的問題[1],主要包括:
1) RocksDB使用預寫式日志(write ahead logging, WAL)技術保證一致性,存在寫放大.RocksDB本身的LSM-Tree(log-structured merge tree)[2]機制也會帶來寫放大.LSM-Tree的數據壓緊(compaction)機制還會帶來業務的性能抖動.
2) BlueStore的元數據信息、屬性信息和小數據被存儲到RocksDB中,并在其中多次復制和序列化,帶來較大的CPU開銷.
3) 為了保證事務一致性,對小數據的更新需要先從磁盤讀取更新后保存到RocksDB中,同時RocksDB有自己的WAL日志,導致Journal of Journal的寫放大問題.
上述3個問題和對應的系統開銷,在固態硬盤(solid state disk, SSD)和機械盤場景下,相對系統整體性能提升帶來的收益來說是值得的,但在持久性內存場景下則成為了不必要的負擔.
PMEM(persistent memory)[3]也稱為非易失內存(non-volatile memory, NVM)或存儲級內存(storage class memory, SCM),在本文統稱為PMEM.PMEM因其非易失、字節尋址和原地更新等特性,成為工業界和學術界研究的熱點.
BlueStore沒有很好利用PMEM內存式高速處理和外存式持久化的雙重能力.PMEM具有非易失、字節尋址特性[4],可以通過簡化日志的方式保證事務一致性,減少日志結構引起的數據整理和寫放大,以及由此帶來的額外系統開銷和性能瓶頸.與傳統基于塊的存儲設備相比,PMEM提供了更高的吞吐和更低的延遲.但是,PMEM比SSD容量小且單位存儲成本更高,而且目前商用的PMEM讀寫具有不對稱性,例如通過Intel MLC[5]測得的Intel Optane DC Persistent Memory讀帶寬最高約為6 GBps,而寫帶寬則約為2 GBps.因此,PMEM更適合用來存儲元數據和小數據,而SSD更適合存儲大塊的數據對象.充分發揮PMEM和SSD存儲介質的優勢特性,設計高性能的后端存儲,將為解決傳統存儲的不足帶來了新的機遇.
本文提出了一種基于PMEM和SSD的分布式后端存儲MixStore,通過針對PMEM和SSD特性的組合優化設計,構建性能更優的本地存儲系統,解決了Ceph現有后端存儲BlueStore的寫放大以及compaction等問題.
1 相關工作
Ceph現有的BlueStore被設計為一個面向SSD和HDD(hard disk drive)的存儲引擎,致力于提供快速的元數據操作、避免對象(Object)寫入時的一致性開銷,同時解決日志雙寫問題.BlueStore通過將元數據保存到RocksDB來實現快速的元數據操作.通過Space Allocator進行磁盤空間管理,將Object直接寫入塊設備,去除對文件系統的依賴.同時,BlueStore實現了寫時復制機制(copy-on-write, CoW)方式的Object更新,從而避免在日志中包含完整的Object數據,解決雙寫問題.但是基于RocksDB管理元數據存在寫放大問題,RocksDB的compaction操作也會導致性能抖動,影響系統吞吐率.另一方面,在數據規模較大以及EC(erasure code)等應用場景中,基于RocksDB的元數據管理仍然難以滿足性能要求.即使更換持久性內存等更高性能的硬件,所獲得的提升也有限.
以LevelDB[6]和RocksDB[7]為代表的LSM-Tree存儲引擎憑借其優異的寫性能成為眾多分布式組件的存儲基石.在大型生產環境中,例如BigTable[8],Cassandra[9],HBase[10]等廣泛部署了各種基于LSM-Tree的本地存儲.LSM-Tree把小的隨機寫通過合并操作變成連續的順序寫,因此對HDD硬盤的寫入性能有很好的優化.相比HDD來說,SSD的順序寫入和隨機寫入性能差別較小,所以LSM-Tree對SSD的寫入性能提升有限.為此,WiscKey[11]提出一種基于SSD優化的鍵值(key-value, KV)存儲,核心思想是把key和value分離,只有key被保存在LSM-Tree中,而value單獨存儲在日志中.這樣就顯著減小了LSM-Tree的大小,使得查找期間數據讀取量減少,并減輕了索引樹合并時不必要的數據移動而引起的寫放大.WiscKey保留了LSM-Tree的優勢,減少了寫放大,但數據訪問時需要進行多次MAP映射,且依然存在LSM-Tree固有的compaction過程.SLM-DB[12]基于PMEM和磁盤對LSM-Tree進行改進,將磁盤上的數據從多級樹減少到1級,在PMEM上構建B樹加速對磁盤數據的訪問,具有低寫入放大和近乎最優的讀取放大特性.但在磁盤上數據依然需要做compaction操作,同時因為數據存放在磁盤,小數據的訪問性能較差.NoveLSM[13]是一款基于PMEM的LSM-Tree存儲結構的KV系統,旨在利用PMEM為應用提供高吞吐、低延遲的KV存儲,在WAL日志滿的時候,或在compaction受阻時,引入PMEM進行加速,是一種改良的LSM-Tree,但沒有完全解決寫放大和compaction的問題.
針對PMEM,NOVA[14]把DRAM和PMEM相結合,索引存放在DRAM中,日志放在PMEM中,每個inode都有自己的日志,日志通過鏈表進行組織,這樣的設計充分發揮了PMEM的字節尋址特性,但因為單位存儲成本較高不適合作為大容量后端存儲.Ziggurat[15]提供了一個分層文件系統,將PMEM和慢速磁盤結合在一起,通過在線預測應用的訪問模型,把同步的、小的數據寫入PMEM,把異步的、大的數據寫入磁盤,這種分層放置的策略對有多樣性的訪問模型有效,但對于單一數據類型的應用將不能充分發揮PMEM和磁盤的各自的特性.NV-Booster[16]提出了一種基于PMEM的文件系統來加速存儲節點的對象訪問,通過PMEM中的高效命名空間管理,實現了快速的對象搜索以及對象ID和磁盤位置之間的映射,其優化是針對Ceph的FileStore,未解決BlueStore所面臨的問題.此外,以上這些工作都提供基于內核態的本地文件系統,由于系統調用、內存拷貝和中斷而導致較大的性能開銷,并不適合作為分布式存儲的后端.Octopus[17]提出了一種基于PMEM和RDMA(remote direct memory access)的分布式持久存儲文件系統,利用了RDMA可以直接讀寫PMEM的特性,將文件數據設置為全局可見,直接執行遠程讀寫,提高性能;而文件元數據則設置為私有,對應的操作由服務端來執行,從而保證安全性和系統數據一致性.但該系統缺少對大容量SSD的集成,不適合作為分布式存儲的后端.
KVell[18]是基于NVMe SSD設計的高效KV存儲,核心設計思想是簡化CPU的使用,數據在SSD上不排序,每個分區的索引在內存中是有序的.這種設計在每次啟動時需要進行索引的重構,無法滿足快速重啟動的工程需求.KVell使用頁緩存和LRU(least recently used)算法負責磁盤上的空閑空間申請和釋放,省去了磁盤上空閑空間回收和整理的過程.但是當磁盤容量快被用完,特別是被覆蓋寫時,大概率觸發SSD的擦除→拷貝→修改→寫入過程,實際IO性能會大幅下降.Pmemkv[19]是針對持久性內存優化的本地鍵值數據存儲,其底層包含了cmap、csmap、tree3、stree等多種存儲引擎,其中csmap引擎基于SkipList實現,put、get、count等操作的性能隨線程數擴展,但其remove操作使用了全局鎖,限制了并發性.
在并發訪問控制和事務一致性方面,Harris等人[20]利用指針標記的方法解決了DRAM上CAS(compare-and-swap)算法在并發執行節點插入和刪除操作時,刪除前置節點會導致插入節點丟失的問題.David等人[21]基于此研究提出一種無鎖數據結構,實現了適用于PMEM的CAS算法,當使用CAS指令更新前置節點的next指針時,同步為該指針添加未持久化標記,并在完成持久化后去除此標記.其他并發的更新操作在檢測到未持久化標記時,則首先執行持久化,以保證更新的線性執行.但上述方法中,保存在PMEM中的指針包含了未持久化標記,后續的標記移除操作則可能因故障而未被持久化,導致故障恢復后新的插入操作重復執行指針持久化,產生不必要的性能開銷.PMwCAS[22]通過無鎖持久高效的多字段CAS技術,解決了多字段更新的原子性問題,大大降低了構建無鎖索引的復雜性,但未提供節點刪除時資源回收的解決方案.TLPTM[23]通過分配感知和基于壓縮算法的日志優化策略設計了一種基于微日志的持久性事務內存系統,雖然減少了日志的寫入量,但本質上還是一種基于日志的事務系統,沒有解決前述的數據雙寫問題.
肖仁智等人[24]從持久索引層面、文件系統層面和持久性事務等方面對面向PMEM的數據一致性相關工作進行了綜述和總結,并指出在開發新的一致性的持久內存索引方面,未來更多的工作將集中在LSM-Tree和SkipList上.
綜上,現有后端存儲BlueStore固有的寫放大和compaction問題在PMEM上更加突出,業界針對SSD和PMEM下的LSM-Tree提出了許多改進,但仍然避免不了compaction帶來的性能抖動.在構建基于持久性內存的存儲系統方面業界提供了一些解決方案,但大多是內核態的實現,存在較多的上下文切換和數據拷貝的開銷,并且基于本地文件系統的后端存儲在事務一致性保證和高效元數據訪問方面并不友好,同時PMEM本身由于容量和成本原因并不適合單獨構建大規模分布式存儲系統,因此基于PMEM和SSD的特性聯合設計后端存儲存在切實的需求.
2 MixStore架構設計
針對PMEM和SSD的硬件場景,本文設計了MixStore替換原有的BlueStore,作為Ceph的后端本地存儲.其最大的挑戰是事務一致性處理和充分發揮新型硬件的性能,事務一致性要求一次IO更新操作要么全部成功,要么什么也沒做,確保系統異常崩潰時數據的正確性.通常基于本地文件系統實現后端存儲時,需要先寫WAL日志,再更新數據,但這樣存在嚴重的寫放大而影響到系統的性能.與此同時,由于本地文件系統在管理文件時使用了多層級inode來管理文件數據和元數據的存放,但后端存儲也有自己的元數據,會導致后端存儲元數據到本地文件系統多級元數據和數據的映射的開銷,所以直接基于裸盤設計后端存儲更具有性能優勢.
MixStore利用PMEM的字節尋址和持久性特性,把元數據和小塊數據存放在PMEM中,基于SSD裸盤,把對齊的大塊數據對象存儲在SSD上.PMDK(persistent memory development kit)[25]是Intel提供的適用于持久性內存的開源庫,專門針對PMEM進行了優化.基于PMDK事務機制可以確保在節點故障后,所有內存操作都回滾到最后提交的狀態,PMDK實現了線程內的原子性,但沒有提供隔離性.MixStore提出了一種基于PMEM的Concurrent SkipList索引管理機制,基于PMDK事務、區段標志位以及待刪除列表的方式保證節點修改的事務一致性、原子性和并發性.同時提出了一種高效的數據對象更新管理方法.針對PMEM和SSD各自的特性,優化數據對象的訪問性能.
MixStore的系統架構如圖1所示.作為用戶態后端存儲,MixStore對外提供ObjectStore接口,內部分為元數據管理和數據對象的管理.MixStore的核心創新是在PMEM上實現了基于Concurrent SkipList的索引替換原有RocksDB所實現的元數據管理功能,去除了對RocksDB的依賴;通過直接管理Object元數據,避免了WAL和LSM-Tree機制帶來的寫放大和compaction時的性能抖動;同時避免了序列化和反序列化帶來的CPU開銷;小塊的數據存放于PMEM中,并優化了小IO的事務一致性處理方法,避免了BlueStore的Journal of Journal的問題,對于大塊的數據對象,首尾非最小可分配大小(minimal allocate size, MAS)對齊的部分存放在PMEM中,中間MAS對齊部分使用CoW機制存儲到SSD中.得益于PMEM的字節尋址特性,對于非對齊寫和小IO有更好的優化.
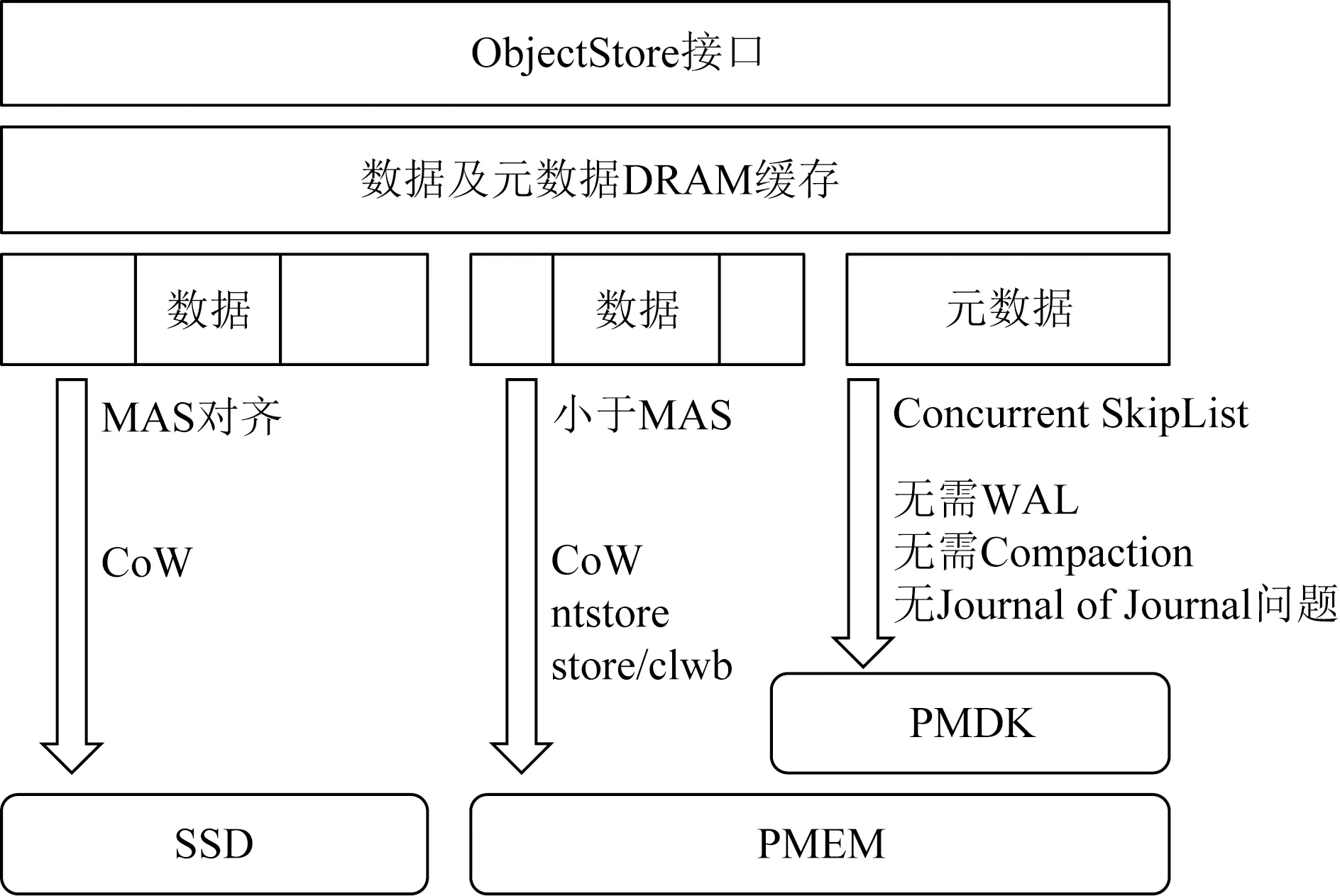
Fig. 1 System architecture of MixStore圖1 MixStore系統架構圖
在索引結構的選擇上,現有的LSM-Tree在WAL日志更新,多層級查找及序列化方面開銷巨大[13],且無法利用PMEM的字節尋址和低延遲特性,顯然不適用于PMEM.有序鏈表因為O(N)的較高時間復雜度消耗亦不適合用作索引結構.對于樹形結構,數據量的變化通常需要對樹結構重新平衡,重新平衡操作可能會影響樹結構的較大范圍,這將需要在較多樹節點上使用互斥鎖.相比樹結構,SkipList具有更好的局部性,更適合并發訪問修改[26-27].對SkipList的操作只會影響到節點本身以及前后插入的節點,在更改SkipList結構時不需要鎖住和同步整個SkipList數據,具有更好的并發性.MixStore選擇SkipList作為索引結構,同時基于PMEM實現了事務一致性和并發性.
在寫放大方面,PebblesDB[28]顯示,插入5億個鍵值對時,平均鍵值大小100 B,共寫入45 GB數據,RocksDB實際寫入了1 868 GB數據,寫放大率達42倍.對于SkipList來說,只需要額外一個指針,加上中間層次節點,平均一個鍵值對額外增加16 B,寫放大為0.16倍,遠遠少于RocksDB的寫放大.對于每個100 B鍵值加上SkipList管理開銷16 B,可以管理NVMe SSD上的4 KB的數據塊,實際元數據最多消耗僅為數據量的2.8%.
在時間效率方面,SkipList通過維護一個多層次的鏈表,且與下面一層鏈表元素的數量相比,每一層鏈表中的元素的數量更少.算法首先在最稀疏的層次進行搜索,直至需要查找的元素在該層2個相鄰的元素中間.這時,算法將跳轉到下一個層次,重復剛才的搜索,直到找到需要查找的元素為止[29].SkipList與平衡二叉樹一樣可提供時間復雜度為O(logN)查找、插入和刪除操作[30],而無需像B樹、紅黑樹或AVL樹所要求的那樣,進行復雜的樹平衡或頁面拆分,并且實現起來更加簡單和簡潔.
在數據布局方面,根據DRAM,PMEM,SSD各自特性和優勢,合理搭配使用以充分挖掘系統的性能.SSD容量最大,用于存儲具體的數據內容,PMEM隨機讀寫性能好,且具有持久性,用于存儲元數據信息、磁盤空間分配信息、屬性信息等,同時還存儲非MAS對齊的臨時的數據內容.而對于DRAM,性能相比PMEM更好,用作熱點數據和元數據的緩存.對于MAS對齊的數據首先寫入DRAM,然后持久化到SSD中,但在DRAM中仍然保留,直至后續被LRU淘汰.
在事務一致性方面,PMDK libpmemobj庫實現了事務機制,提供更新原子性,以及崩潰一致性保證.通過Concurrent SkipList設計,基于PMDK實現了強一致的元數據管理,而不必額外使用日志機制,從而避免了Journal of Journal問題.但是PMDK未提供足夠的隔離性,當多個線程并發執行事務操作時,對共享資源的訪問仍然需要額外的隔離機制.MixStore通過區段標志位方式進行并發控制訪問,解決了多線程隔離性問題.對于PMEM中非MAS對齊的小數據更新使用ntstore或clwb指令通過CoW方式直接寫入.因為大塊數據使用ntstore指令具有更好的性能表現[31],所以MixStore對于大于等于256 B的數據采用ntstore的方式進行存儲,而對于小于256 B的數據采用clwb的方式進行存儲.
3 關鍵技術
本節詳細描述MixStore在元數據管理和數據對象管理方面的關鍵技術.
3.1 基于Concurrent SkipList的元數據管理
MixStore的元數據通過基于PMEM的SkipList進行管理,內存結構的SkipList可以基于CAS指令實現數據的并發更新機制,但在PMEM上應用CAS算法面臨新的挑戰.
現有的Cache Coherency模型是針對DRAM的,當CAS操作完成時,數據在CPU Cache間保持一致,但對于PMEM,仍然需要額外的clflush操作,才能完成持久化.因此,操作原子性被破壞,如果在斷電時僅完成了指針的更新,而沒有持久化到PMEM,則在多線程并發更新訪問時,會導致數據結構的損壞,產生內存泄漏和一致性問題.
3.1.1 元數據插入機制
與David等人[21]提出的無鎖數據結構不同,MixStore使用一種易失區段標記來解決并發操作一致性問題,即將SkipList分為多個區段,并在DRAM中保存每個區段的更新標記.更新操作在完成前置節點查找后,通過CAS指令將對應區段設置為更新中,以與同區段的其他更新操作互斥.更新標記保存在DRAM而不是PMEM中,以提升訪問效率,并簡化故障恢復處理.區段級而不是節點級的更新標記則可以縮減內存使用量,并有助于解決插入和刪除并發時的節點丟失問題.為了解決跨區段更新的問題,在SkipList中引入dummy節點作為區段邊界,以保證前置節點和待插入節點總是在一個區段中.此時,僅同區段的更新操作需要互斥,不同區段的更新操作可以并發執行,而查找操作不需要互斥,完全是并發執行的.
以一個2區段的SkipList為例,新元素的插入操作如圖2所示,首先根據待插入元素d所屬區段設置對應的更新標記,并開啟PMDK事務,然后將待插入元素d的next指針指向x(x為區段中第1個元素時,則指向該區段的起始dummy節點),通過CAS操作將元素c的指針指向元素d.此時,CPU cache中的插入操作完成,元素d對查找操作可見.接下來,提交PMDK事務將更新操作持久化到PMEM中,并復位SkipList的區段更新標記.此時,CPU cache和PM中的數據視圖達成一致,整個插入操作完成.對于待插入元素的高度超過1的情況,由于上層list在故障恢復時可以通過底層的數據進行重建,因此可以僅通過CAS操作進行更新,無需主動執行持久化操作.

Fig. 2 Metadata insertion mechanism圖2 元數據插入機制
為了進一步減少同區段的并發沖突,插入時的查找操作可以使用二次確認(double check)的方式,即首先遍歷SkipList確定新元素的插入位置,然后設置區段更新標記,并再次檢查前置節點的next指針,確定是否需要重新執行查找操作.完整的節點插入流程描述如算法1.
在節點插入時需要同時更新本節點的next指針和前一節點的next指針,把這2個指針更新放在同一PMDK事務中執行,確保系統的崩潰一致性,避免斷電導致的各類異常,例如數據部分持久化導致的內存區域泄漏、SkipList鏈表斷裂等情況.
算法1.插入節點Insert(node).
①pre←SearchPrevious(node.key);
②MarkRange(node.key);
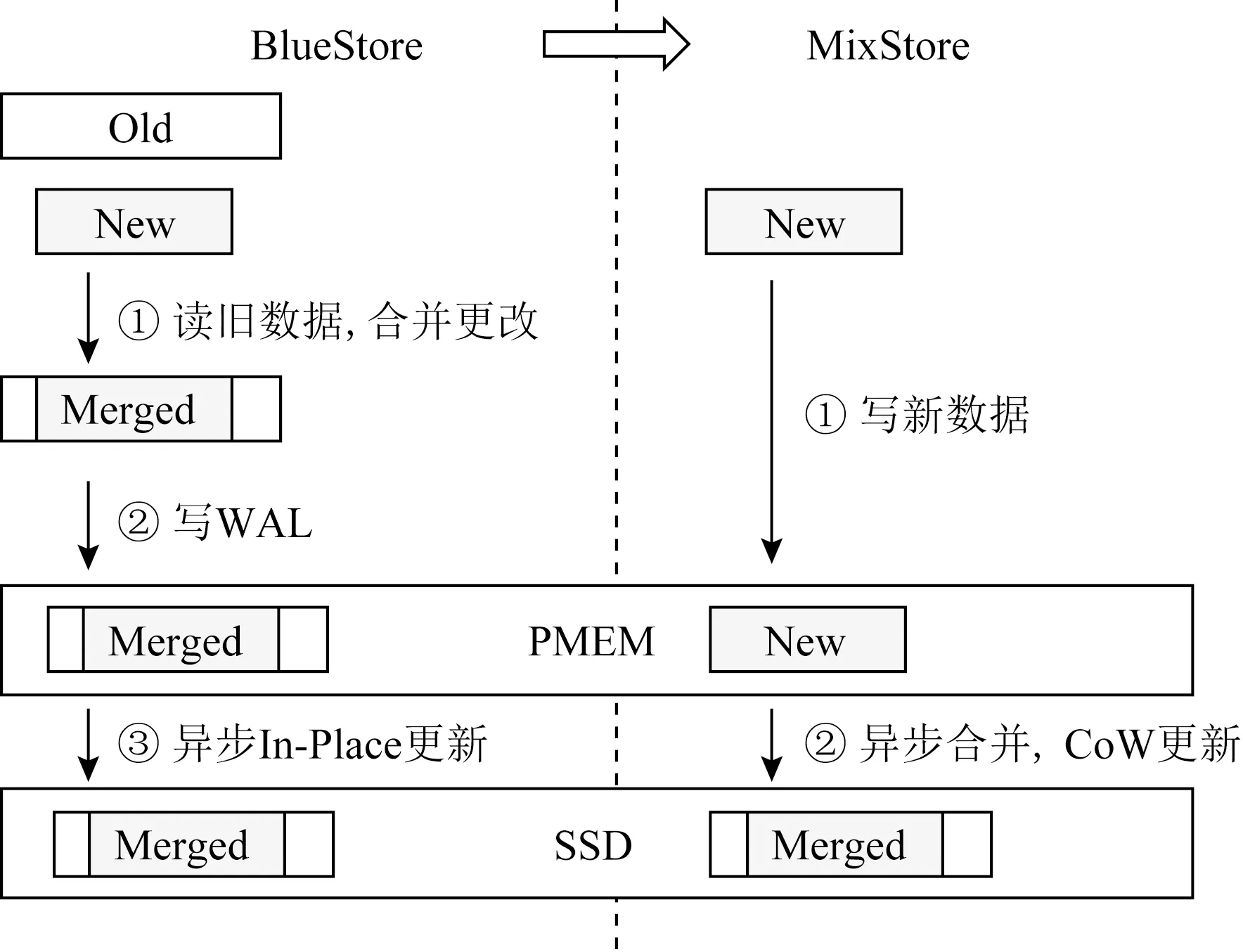
③ ifpre.next.key ④pre←SearchPrevious(node.key); ⑤ end if ⑦node.next←pre.next; ⑧pre.next←node; ⑩UnmarkRange(node.key). 3.1.2 元數據刪除及查詢機制 元素刪除操作與插入操作類似,需要通過區段更新標記進行互斥.與插入操作不同的是,元素從SkipList移除后,由于可能有其他線程正在執行查找操作,其內存區域不能立即釋放.同時,在等待釋放期間,為了避免異常斷電導致持久內存泄漏,待刪除的元素需要進行妥善的跟蹤管理. MixStore使用待刪除列表解決上述問題.如圖3所示,首先為每個線程維護一個SkipList訪問事件時戳,線程每次完成SkipList的訪問后,時戳加1.同時,每個線程有一個保持在持久內存中的待刪除元素列表,該列表實際由2個數組和對應的2個時戳向量組成,在當前數組滿時互相交換,并在符合特定條件時清空備用數組.時戳向量中記錄了特定時刻所有線程的時戳值,線程時戳和時戳向量均無需持久化,在啟動時初始化為0即可.元素從SkipList中刪除時,會被暫存到待刪除列表,同時更新此刻的時戳向量. Fig. 3 Metadata deletion mechanism圖3 元數據刪除機制 以刪除元素c為例,首先設置區段更新標記,并開啟PMDK事務,然后使用CAS操作將元素b的next指針指向元素x.此時,元素c對后續的查找操作不可見,但仍然可能有查找過程正在訪問元素c.然后,元素c被加入待刪除列表,提交PMDK事務完成持久化,同時復位區段更新標記.接下來,更新時戳向量,記錄當前時刻所有線程的時戳值.顯然,刪除操作發生在此時戳向量之前,當后續某一時刻的時戳向量嚴格大于該值時,即每個線程的時戳都大于舊值時,元素c的內存可以被釋放.具體而言,在更新當前時戳向量后,將當前時戳向量與備用數組的時戳向量進行比較,并確定是否清空備用數組.完整的節點刪除流程描述如算法2所示. 算法2.刪除節點Remove(key). ①pre←SearchPrevious(key); ②MarkRange(key); ③ ifpre.next.key≠keythen ④pre←SearchPrevious(key); ⑤ end if ⑥curr←pre.next; ⑧pre.next←curr.next; ⑨AddToSwaplist(curr); 在進程重啟后的故障恢復階段,由于待刪除列表中的元素仍然可能會被其他線程的恢復過程訪問,故保留待刪除列表中的元素,并將2個時戳向量重置為0.此時,待刪除列表中的元素被延遲到后續刪除操作中進行清理. 與插入和刪除不同,查詢操作不需要關注區段標記.節點插入時,鏈表指針的更新通過原子操作完成,從鏈表中刪除的節點則首先保存在額外的待刪除列表中,直到查詢操作完成后相關內存才被釋放.因此,查詢操作是完全并發的,不存在等待時間,故而具備較高的性能和延遲一致性表現. MixStore充分利用PMEM的字節尋址特性,來優化Object的寫入性能.一方面,Object的元數據使用存儲在PMEM中的SkipList進行管理,另一方面,對于非對齊IO和隨機小IO,也利用PMEM,通過不同的寫入策略進行優化. 雖然SSD有較好的隨機讀寫性能,但相比于順序讀寫仍有所降低.為此,設定SSD的最小分配大小MAS,對于普通的SATA SSD來說,MAS=16 KB.對于NVMe SSD來說,因為有更好的隨機讀寫性能,我們設定MAS=4 KB.通過數據寫入策略的設定,有效減少了SSD的隨機讀寫,進一步優化系統的性能. Object更新時,小于MAS的數據被直接寫入PMEM,后續小IO寫入也直接在PMEM中進行追加更新和合并,從而有效減少了SSD的磨損和閃存轉換層(flash translation layer, FTL)頻繁垃圾回收(garbage collection, GC)導致的性能抖動.對于此類數據,如圖4左側部分所示,BlueStore采用DeferredWrite策略,即首先從SSD讀取舊數據與新數據進行合并,獲得block對齊的待更新數據塊,然后將待更新數據塊和元數據作為WAL寫入RocksDB.最后,異步執行數據的In-Place更新,并在完成數據寫入后刪除WAL.這種方式導致在構建WAL時即需要執行SSD數據讀取,且增加了PMEM的寫入數據量.與BlueStore不同,MixStore對異步寫入的數據不使用In-Place更新策略,如圖4右側部分所示,MixStore將非對齊小IO直接寫入PMEM,然后異步執行SSD讀取操作并進行CoW異地更新.MixStore面向更高性能的PMEM和SSD設計,由于數據的不連續分布對SSD設備的讀性能影響要遠小于HDD,因此選擇CoW異地更新而不是In-Place更新,從而避免了構建WAL,降低了PMEM寫入數據量;此外,PMEM的高性能也可以更好的支撐不連續的讀取操作,使得MixStore可以使用更惰性的數據回寫策略,從而提升非對齊小IO的合并概率,減少最終的SSD寫入次數和數據的碎片化. Fig. 4 Comparison of unaligned IO processing圖4 小IO數據更新流程對比 對于大于MAS的更新操作,則首先進行MAS對齊,將其切分為3個部分,即首尾非MAS對齊的部分和中間MAS對齊的部分.對于首尾非對齊部分使用與小IO相似的方式處理,對齊部分則使用CoW策略,在寫入SSD后更新元數據信息.具體而言,整個更新操作分為2個階段,即首先將中間MAS對齊部分異地寫入SSD,首尾非對齊部分寫入PMEM,然后將所有的元數據修改在一個PMDK事務中完成. Object讀取時,通過訪問SkipList獲取數據存放位置信息,首選從SSD中讀取本次IO涉及的數據區域,然后從PMEM中讀取非對齊的小IO增量,并進行必要的合并即可.得益于PMEM的隨機訪問性能,對數據的碎片化有更高的容忍度,讀性能仍然可以保持較高的水平. MixStore根據PMEM的可用容量和數據的碎片化情況決定是否執行合并操作,PMEM讀取4 KB數據的延遲通常不超過5 μs,而NVMe SSD的4 KB讀延遲通常在100 μs左右.MixStore在讀操作中檢查數據的碎片化情況,當碎片數量超過閾值以后,觸發合并操作,合并后的數據使用CoW的形式進行更新,以避免In-Place更新可能的一致性問題.碎片閾值是動態的,在PMEM容量充足時,碎片閾值較高,并隨著可用容量的減少而逐步降低. 本實驗采用的硬件配置信息如表1所示,實驗在一個由40 GbE以太網交換機連接的4節點集群上完成,測試使用的持久內存為Intel最新推出的Optane DC持久性內存,單條容量為256 GB,NVMe SSD為Intel的P4610,單盤容量為1.6 TB.PMEM可以配置為App-Direct或Memory這2種工作模式,由于本實驗都是把PMEM作為持久存儲來使用,所以采用App-Direct模式.本實驗對比BlueStore和MixStore測試時所采用的硬件環境相同. Table 1 Experiment Configuration表1 實驗環境配置 所有主機均安裝Fedora release 29,內核版本升級到4.18.16-300,以提供對PMEM的支持.測試基于Ceph Luminous 12.2.12或其修改版本完成,使用FIO 3.10進行負載模擬. Ceph集群部署在其中3臺安裝了PMEM和NVMe的主機上,PMEM配置為fsdax模式.另一臺主機作為客戶端運行FIO程序,該主機上實際未安裝PMEM和NVMe設備. 測試BlueStore時,PMEM作為塊設備使用,用于存儲WAL和DB數據,SSD用于保存對象數據.測試MixStore時,PMEM格式化為ext4-dax,然后通過MMAP轉換為持久內存使用,PMEM用于存儲索引和小塊數據,大塊對象數據保存在SSD上. 本次測試使用FIO工具的rbd ioengine訪問Ceph RBD接口,后端為2副本存儲池.為了更接近真實負載,FIO的隊列深度被設置為32,而不是更大的值.每次測試使用20個FIO客戶端分別對20個大小為50 GB的RBD Image進行讀寫,測試過程持續5 min. 4.2.1 寫性能 本次測試覆蓋了小IO隨機寫入和大IO順序寫入2類場景.對于隨機寫入,為了進一步確認BlueStore和MixStore針對不同數據大小的寫入策略差異,分別測試了2 KB,4 KB,16 KB的數據寫入.對于順序寫入,分別測試了64 KB,128 KB,256 KB的數據寫入. 每組數據測試完成后,重啟全部OSD(object storage daemon)節點,以排除緩存等因素的干擾. 小IO隨機寫入的性能如圖5所示,可以看到,對于所有隨機寫入場景MixStore均有優于BlueStore的表現,其中4 KB寫入高出約59%,這顯然得益于MixStore的高效原數據管理和事務日志的消除.對于2 KB隨機寫,BlueStore和MixStore均使用PMEM進行數據暫存,不同的是,BlueStore需要執行read-merge-write操作,因此最終寫入PMEM的為包含4 KB數據塊的事務日志,而MixStore則直接將2 KB的數據以及相關元數據寫入PMEM.測試過程中,通過iostat或pcm-memory.x可以觀察到MixStore消除了NVMe讀操作,PMEM寫帶寬約為BlueStore的一半.但由于NVMe磁盤實際負載較小,最終MixStore測試結果僅表現出與4 KB類似的優勢,領先BlueStore約56%.對于16 KB的隨機IO,MixStore領先約34%,一方面,MixStore更高效的元數據操作釋放了NVMe的性能,另一方面,對于16 KB的數據,NVMe寫操作在整個請求處理開銷中的占比上升,導致最終的性能優勢不如4 KB數據明顯.MixStore的平均延遲和尾延遲也呈現出和IOPS相同的優勢,平均延遲約為BlueStore的63%~75%,尾延遲約為BlueStore的72%~84%. Fig. 5 Comparison of random write圖5 隨機寫測試對比 如圖6所示,對于大IO順序寫入,MixStore和BlueStore基本表現出相同的性能,平均延遲也基本相同.這是因為對于64 KB以上的寫請求,2個系統的處理策略基本相同.較大的數據尺寸也導致請求處理的主要開銷來自于SSD寫入操作,軟件棧的差異被進一步削弱.即便如此,由于具備更好的元數據操作并發性,MixStore仍然表現出了更好的尾延遲,約為BlueStore的54%~91%. Fig. 6 Comparison of sequential write圖6 順序寫測試對比 4.2.2 讀性能 對于讀操作,本次測試選擇了與寫操作相同的數據特征,即針對2 KB,4 KB,16 KB的隨機讀取,以及64 KB,128 KB,256 K的順序讀取場景進行測試.同樣,每組測試完成后重啟所有OSD,以消除緩存的干擾. 對于小IO隨機讀,如圖7所示,MixStore和BlueStore有基本相同的IOPS和平均延遲,這是因為在排除緩存干擾后,讀操作的開銷主要來自于磁盤數據讀取.而較大的寫入總量也導致讀操作更多的是從SSD而不是PMEM讀取數據,因此不同數據大小的測試之間并未體現出差異.但得益于MixStore元數據訪問的高并發性,在16 KB讀取測試中,MixStore的尾延遲表現出了23%的降低. Fig. 7 Comparison of random read圖7 隨機讀測試對比 對于大IO順序讀,如圖8所示,受限于本次測試的網絡環境,BlueStore和MixStore未能體現出差別,僅64 KB順序讀MixStore體現出約21%的尾延遲降低.128 KB及256 KB的性能制約則更多來自于網絡傳輸. Fig. 8 Comparison of sequential read圖8 順序讀測試對比 現有的分布式存儲的后端存儲存在著明顯的寫放大和compaction消耗.持久內存具備字節尋址,接近DRAM性能,掉電不丟數據等特性.但持久內存容量較小,更適合存放數據的元數據或小的數據的緩存,相反SSD容量較大,順序讀寫性能更優,更適合存放大塊的數據.MixStore充分利用持久內存和磁盤各自的特性,把兩者結合起來,通過構建Concurrent SkipList進行精細的索引元數據組織,以及通過惰性的CoW的數據存放機制,提供了高性能的后端存儲,有效減少了寫放大和避免了compaction帶來的消耗.實驗顯示,相比BlueStore,MixStore的寫吞吐提升59%,寫時延降低了37%,有效地提升了系統的性能,并且具有更好的讀寫尾時延表現.展望未來,隨著新型器件的發展和持久內存產業化水平的提升,計算、存儲和網絡能力都將顯著提升,可能會出現基于持久內存等新型器件構筑的全新存儲環境.我們需要重新審視現有的設計和優化機制,并設計新的算法來適配新的硬件環境.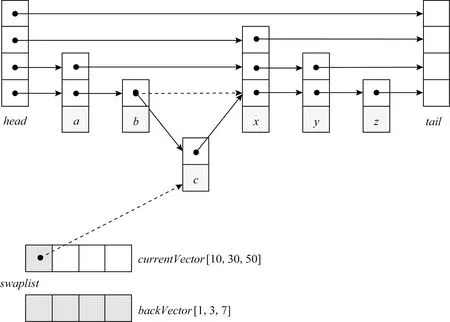
3.2 數據對象管理
4 實驗及分析
4.1 實驗環境

4.2 性能對比




5 結 論
猜你喜歡
遼寧教育(2022年19期)2022-11-18 07:20:42
公民與法治(2022年5期)2022-07-29 00:47:28
汽車實用技術(2022年9期)2022-05-20 05:51:26
教學考試(高考物理)(2021年5期)2021-11-08 10:31:22
歷史教學問題(2021年4期)2021-11-05 07:02:34
中醫眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
裝備制造技術(2020年11期)2021-01-26 00:39:12
中國公共安全(2017年11期)2017-02-06 05:28:08
電測與儀表(2016年7期)2016-04-12 00:22:18
燕山大學學報(2015年4期)2015-12-25 02:19:49
