基于GIS滑坡地質(zhì)災(zāi)害易發(fā)性評價(jià)方法綜述
2021-01-24 07:57:32陶偉,孫岳
世界有色金屬 2020年21期
陶 偉,孫 岳
(東華理工大學(xué)地球科學(xué)學(xué)院,江西 南昌 330013)
滑坡作為最常見的地質(zhì)災(zāi)害,危害性大、破壞力強(qiáng),給人民的生命財(cái)產(chǎn)安全造成巨大威脅。據(jù)全國地質(zhì)災(zāi)害通報(bào),2019年全國共發(fā)生地質(zhì)災(zāi)害6181起,共造成211人死亡、13人失蹤、75人受傷,直接經(jīng)濟(jì)損失27.7億元,其中滑坡4220起,占地質(zhì)災(zāi)害總數(shù)的68.27%,造成嚴(yán)重的環(huán)境破壞和經(jīng)濟(jì)損失,具有自然和社會(huì)雙重屬性[1,2]。我國幅員遼闊,地質(zhì)環(huán)境復(fù)雜多樣的特殊性決定了滑坡地質(zhì)災(zāi)害多樣性和區(qū)域變異性,滑坡同時(shí)受多種外界因素耦合誘發(fā),亟待提高滑坡災(zāi)害監(jiān)測預(yù)警的時(shí)效性與準(zhǔn)確性[3]。科學(xué)地進(jìn)行滑坡災(zāi)害預(yù)測和評價(jià)對防災(zāi)減災(zāi)和保護(hù)人民生命、財(cái)產(chǎn)安全意義重大,選定合適的評價(jià)方法、建立分析模型,劃分研究區(qū)滑坡地質(zhì)災(zāi)害易發(fā)性等級(jí),從而為防災(zāi)減災(zāi)和區(qū)域規(guī)劃的制定提供可靠的決策依據(jù),為滑坡災(zāi)害防治和預(yù)警提供指導(dǎo)[4]。
地理信息系統(tǒng)(geographic information system,GIS)作為數(shù)據(jù)管理、空間分析和圖像輸出的強(qiáng)有力技術(shù)手段,能使得分析結(jié)果更加精細(xì)化,被廣泛應(yīng)用于滑坡地質(zhì)災(zāi)害的早期識(shí)別和定量分析領(lǐng)域。將地形地貌特征、地質(zhì)信息以及與滑坡有關(guān)的降水量和歷史災(zāi)害等數(shù)據(jù)導(dǎo)入GIS平臺(tái),建立相應(yīng)的預(yù)測模型,能有效對滑坡災(zāi)害進(jìn)行評價(jià)和預(yù)測。GIS高效率、高精度、定量化的模擬與分析,對滑坡災(zāi)害的易發(fā)性區(qū)劃研究及預(yù)警有重要的現(xiàn)實(shí)意義,為滑坡災(zāi)害的研究開創(chuàng)了新局面。
本文通過總結(jié)前人基于GIS滑坡災(zāi)害易發(fā)性評價(jià)的研究方法和模型,歸納幾種常用的滑坡災(zāi)害評價(jià)方法,分析了其適用范圍及在應(yīng)用中的優(yōu)勢和局限性。在此基礎(chǔ)上,總結(jié)出基于GIS滑坡易發(fā)性評價(jià)思路,以期對今后的不同形成機(jī)理的滑坡災(zāi)害研究提供借鑒。
1 常見滑坡災(zāi)害易發(fā)性評價(jià)方法分析
滑坡災(zāi)害的易發(fā)性評價(jià)研究起始于20世紀(jì)60年代,九十年代開始伴隨著數(shù)理統(tǒng)計(jì)、概率論及信息量理論、模糊數(shù)學(xué)理論等學(xué)科不斷被引入地質(zhì)災(zāi)害研究領(lǐng)域,傳統(tǒng)定性研究逐步向定量研究發(fā)展,即以數(shù)據(jù)資料為基礎(chǔ)和依據(jù),能夠更加客觀和科學(xué)的反映滑坡地質(zhì)災(zāi)害的真實(shí)狀況[5]。當(dāng)前,基于GIS應(yīng)用于滑坡地質(zhì)災(zāi)害評價(jià)的方法大致可以分為統(tǒng)計(jì)分析方法和數(shù)學(xué)模型法兩類。統(tǒng)計(jì)分析法中比較常見的方法有層次分析法、頻率比法、證據(jù)權(quán)法和邏輯回歸等;數(shù)學(xué)模型法中比較常用的有神經(jīng)網(wǎng)絡(luò)模型法、模糊綜合評判法、信息量模型、支持向量機(jī)模型法等[6,7]。
1.1 統(tǒng)計(jì)分析法
(1)層次分析法(Analytic Hierarchy Process,AHP):20世紀(jì)90年代由T.L.Saaty提出層次分析理論的“1~9標(biāo)度法”,用于解決層次結(jié)構(gòu)或網(wǎng)絡(luò)結(jié)構(gòu)的多指標(biāo)決策分析的方法[8]。將評價(jià)因子大致分為目標(biāo)層、準(zhǔn)則層和方案層三個(gè)層次,分析思路是確定研究區(qū)域的方案層要素因子,照各因子相互之間的內(nèi)在關(guān)系,建立層次結(jié)構(gòu)模型,通過各因子的兩兩對比,建立判斷矩陣,進(jìn)行層次分析排序,確定單個(gè)因子的相對重要性。運(yùn)用層次分析法進(jìn)行滑坡災(zāi)害易發(fā)性分區(qū)與評價(jià)基本流程為:分析地質(zhì)條件,選定評價(jià)因子和評價(jià)單元→建立遞階層次結(jié)構(gòu)模型→構(gòu)造判斷矩陣并計(jì)算各因子權(quán)重,計(jì)算權(quán)向量,一致性檢驗(yàn)→因子加權(quán)疊加,分級(jí)擬合后進(jìn)行分區(qū)[2]。
層次分析法的優(yōu)勢是根據(jù)判斷矩陣定量計(jì)算出各因子的權(quán)重,雖然判斷矩陣是人為確定,但是矩陣需要通過一致性檢驗(yàn)判斷權(quán)重是否科學(xué),一致性檢驗(yàn)合格后,確定各個(gè)評價(jià)因子的權(quán)重值,大大減少了人為確定的主觀性和錯(cuò)誤可能性,確保AHP法在研滑坡易發(fā)性評價(jià)上的運(yùn)用是科學(xué)合理的[9]。缺點(diǎn)是在構(gòu)建判斷矩陣時(shí),評價(jià)指標(biāo)過多,統(tǒng)計(jì)量大,指標(biāo)間可能存在很強(qiáng)的相關(guān)性導(dǎo)致模型失真,且由于決策者很難掌握標(biāo)度的標(biāo)準(zhǔn),因此往往做出的判斷不能滿足一致性檢驗(yàn)。這會(huì)導(dǎo)致計(jì)算收斂較慢,迭代次數(shù)較多,從而增加計(jì)算量[10,11]。
(2)頻率比法(Frequency Ratio,F(xiàn)R):基于已知的滑坡分布與各滑坡災(zāi)害影響因子間的關(guān)系,通過數(shù)學(xué)方法計(jì)算滑坡災(zāi)害與評價(jià)因子間的關(guān)系得到頻率比值(FR)表示滑坡地質(zhì)災(zāi)害位置和評價(jià)因子間的相關(guān)程度。FR值為1代表平均值,當(dāng)FR小于1時(shí),表明評價(jià)因子與滑坡災(zāi)害相關(guān)性低;當(dāng)FR大于1時(shí),說明評價(jià)因子與滑坡災(zāi)害間的相關(guān)性高。頻率比法類似于專家打分和層次分析法的確定權(quán)重步驟,僅僅是純數(shù)理統(tǒng)計(jì),而對滑坡發(fā)育機(jī)理和各因子協(xié)同耦合關(guān)系缺少深入研究。
(3)證據(jù)加權(quán)分析法(Weights of Evidence Model,WEM):是加拿大數(shù)學(xué)地質(zhì)學(xué)家Agterberg提出的一種地質(zhì)學(xué)統(tǒng)計(jì)方法,它基于貝葉斯理論,統(tǒng)計(jì)分析計(jì)算滑坡災(zāi)害評價(jià)因子的權(quán)重值。證據(jù)加權(quán)分析法成立有兩個(gè)前提條件,一是評價(jià)因子通過獨(dú)立性檢驗(yàn)去除相關(guān)性大的因素,二是滑坡災(zāi)害所有的致災(zāi)因子均是長期保持不變的[12]。對滑坡災(zāi)害和滑坡災(zāi)害的致災(zāi)因子進(jìn)行空間分析,計(jì)算致災(zāi)因子的權(quán)重值,求取滑坡災(zāi)害危險(xiǎn)性指數(shù)。這種方法成立的前提條件要求致災(zāi)因子相對穩(wěn)定,但是近年來極端氣候頻發(fā),降水和溫度的變化較大,會(huì)間接影響一些其他因子,不能有效避免評價(jià)因子之間的相互依賴,因此使用該方法有很大局限性。
(4)邏輯回歸(Logistic Regression,LR):從統(tǒng)計(jì)學(xué)角度出發(fā),各因子數(shù)據(jù)可以作為自變量,而災(zāi)害的發(fā)生與否可以作為分類因變量。由于不是連續(xù)變量,線性回歸不適用于推導(dǎo)自變量和因變量之間的關(guān)系。這種情況下,通常采用對數(shù)線性模型,而Logistic回歸模型就是對數(shù)線性模型的一種特殊形式,被引入到地質(zhì)災(zāi)害評價(jià)中,展現(xiàn)了較好的評價(jià)效果[13]。邏輯回歸模型有操作方法簡單、計(jì)算過程不受主觀因素影響,評價(jià)結(jié)果的物理意義明確等突出優(yōu)點(diǎn)。其缺點(diǎn)是基于大樣本統(tǒng)計(jì)規(guī)律的,需要大量數(shù)據(jù)的支持,且對于研究區(qū)特征如植被覆蓋度高的容易造成數(shù)據(jù)本身的不確定性導(dǎo)致回歸模型的結(jié)果不可靠[4]。
1.2 數(shù)學(xué)模型法
(1)人工神經(jīng)網(wǎng)絡(luò)模型法(Artificial Neural Networks Model,ANNM):是模擬人腦結(jié)構(gòu)和神經(jīng)元網(wǎng)絡(luò)進(jìn)行信息處理的數(shù)學(xué)模型,由大量處理單元互聯(lián)而成,具有獨(dú)特的學(xué)習(xí)和適應(yīng)特性,收斂速度快,容錯(cuò)率高,被廣泛應(yīng)用于災(zāi)害預(yù)測等各個(gè)方面,取得了令人滿意的效果[13,14]。其中BP(Back-Propagation Network)神經(jīng)網(wǎng)絡(luò)模型是應(yīng)用最成熟廣泛的一種,于1986年被提出的,采用反推學(xué)習(xí)規(guī)則,又稱為反向傳播神經(jīng)網(wǎng)絡(luò),是一種按誤差逆向傳播算法訓(xùn)練的多層前饋網(wǎng)絡(luò)。BP網(wǎng)絡(luò)是一種有監(jiān)督的學(xué)習(xí)算法,具有很強(qiáng)的自適應(yīng)、自學(xué)習(xí)、非線性映射能力,能較好地解決數(shù)據(jù)少、信息貧、不確定性問題,且不受非線性模型的限制。一個(gè)典型的BP網(wǎng)絡(luò)包括三層:輸入層、隱含層和輸出層,輸入層為滑坡災(zāi)害評價(jià)因子,輸出層主要是輸出滑坡災(zāi)害易發(fā)性的評價(jià)結(jié)果,而隱含層主要是用于修正誤差。但是由于人工神經(jīng)網(wǎng)絡(luò)對輸入層和輸出層有著嚴(yán)格的要求,而在地質(zhì)災(zāi)害評價(jià)中輸出層(危險(xiǎn)性等級(jí))很難和實(shí)際數(shù)據(jù)(災(zāi)害是否發(fā)生)一致,使得在地質(zhì)災(zāi)害中應(yīng)用人工神經(jīng)網(wǎng)絡(luò)技術(shù)的難點(diǎn)集中在訓(xùn)練樣本的選擇上。雖然BP神經(jīng)網(wǎng)絡(luò)具有高度非線性和較強(qiáng)的泛化能力,但也存在收斂速度慢、迭代步數(shù)多、易陷入局部極小和全局搜索能力差等缺點(diǎn)。
(2)模糊綜合評判(Fuzzy Comprehensive Evaluation,F(xiàn)CE):是以模糊數(shù)學(xué)為基礎(chǔ),將定性評價(jià)轉(zhuǎn)化為定量評價(jià)的綜合評判方法。可以對確定性或不確定性因素基于給予綜合評價(jià),將邊界不清,復(fù)雜模糊和不易定量的因素進(jìn)行量化[15]。滑坡地質(zhì)災(zāi)害的影響因子十分復(fù)雜,存在很多不確定性因素,而模糊綜合評判能夠?qū)ζ渲械牟淮_定因素建立分析模型,綜合考慮多因素、多層次的影響,直觀的描述各風(fēng)險(xiǎn)因素間的關(guān)系,利用概率推理中的先驗(yàn)概率及后驗(yàn)概率進(jìn)行計(jì)算,確定不同區(qū)域的災(zāi)害發(fā)生風(fēng)險(xiǎn),對相似的地區(qū)進(jìn)行類比分析,再結(jié)合研究區(qū)實(shí)際地質(zhì)條件進(jìn)行綜合評判,使評價(jià)結(jié)果更加科學(xué)。但應(yīng)用模糊數(shù)學(xué)理論時(shí),其隸屬度函數(shù)的選取更多的是依靠專家經(jīng)驗(yàn),評價(jià)結(jié)果具有很大的主觀性,而且由于模型的限制,在區(qū)劃中網(wǎng)格通常較大,致使評價(jià)結(jié)果不夠精確,本方法更適合單體滑坡的評價(jià),在大范圍、區(qū)域性的滑坡空間預(yù)測上有很大的局限性。
(3)信息量模型(Information Model,IM):是以已知災(zāi)害區(qū)的滑坡致災(zāi)因素為依據(jù),推算出貢獻(xiàn)大小的信息量,建立評價(jià)預(yù)測模型。依照類比原則外推到相鄰地區(qū),從而對整個(gè)地區(qū)的危險(xiǎn)性做出評價(jià)。信息量模型相對于其他預(yù)測方法在單元?jiǎng)澐謹(jǐn)?shù)量較大的災(zāi)害區(qū)劃中更具優(yōu)勢。但信息量模型所統(tǒng)計(jì)的信息只能反映不同影響因子在特定組合情況下災(zāi)害出現(xiàn)的可能性,各因子的影響程度的差異不能體現(xiàn),可能出現(xiàn)某種條件對災(zāi)害發(fā)生具有抑制作用,與自然規(guī)律相悖,影響準(zhǔn)確性[16,17]。為了解決這一問題,應(yīng)對評價(jià)因子進(jìn)行加權(quán),使其反映出不同因素對滑坡影響的差異性,采用加權(quán)信息量評價(jià)模型,提高評價(jià)的準(zhǔn)確性[18]。信息量模型常用來與其他模型的計(jì)算評價(jià)結(jié)果交叉檢驗(yàn),效果較好。理論上信息量模型對參與危險(xiǎn)性評價(jià)因子的標(biāo)志狀態(tài)的劃分沒有特殊要求,但研究發(fā)現(xiàn)[10],因子選取及其標(biāo)志狀態(tài)劃分的合理性影響著計(jì)算評價(jià)的結(jié)果。所以,因子選擇要有代表性,能夠反映災(zāi)害活動(dòng)的特征。在預(yù)測單元?jiǎng)澐稚希辣壤叩牟煌銐蛐。@樣才能減少誤差,從而提高預(yù)測的準(zhǔn)確性[19,20]。地質(zhì)災(zāi)害有一定的隨機(jī)性,只從歷史災(zāi)害因素去分析和預(yù)測,缺少災(zāi)害形成機(jī)制的分析判斷,那么進(jìn)行分析的準(zhǔn)確性將取決于收集的數(shù)據(jù)量的大小,具有一定局限性。
(4)支持向量機(jī)模型(Support Vector Machine,SVM):由Vapnik提出,是一種基于統(tǒng)計(jì)學(xué)原理的分類預(yù)測模型,通過引入核函數(shù),將特征空間內(nèi)線性不可分的數(shù)據(jù)轉(zhuǎn)換為多維空間線性可分?jǐn)?shù)據(jù)的算法[17]。核函數(shù)是SVM的核心,核函數(shù)的選擇直接影響到運(yùn)算結(jié)果的精度和時(shí)間。常見的SVM模型可以分為單類支持和兩類支持兩種。與其他統(tǒng)計(jì)預(yù)測模型或?qū)W習(xí)算法相比,支持向量機(jī)模型具有兩個(gè)突出優(yōu)點(diǎn):①易于使用而不需要對輸入?yún)?shù)進(jìn)行較大的調(diào)整;②結(jié)合了最優(yōu)理論、統(tǒng)計(jì)和函數(shù)分析,計(jì)算效率高、預(yù)測能力強(qiáng),在解決小樣本、高緯度和非線性問題方面更具優(yōu)勢,避免了人為因素的干擾[13,14]。在研究區(qū)資料不夠豐富時(shí),可利用易于獲得的資料,如地形圖、遙感影像,加上已知滑坡點(diǎn)和不穩(wěn)定斜坡的位置,建立滑坡的預(yù)測評價(jià)模型,快速完成滑坡災(zāi)害的區(qū)劃評價(jià)。但這種方法需要選定合適的核函數(shù),對數(shù)理分析及計(jì)算機(jī)能力要求較高。兩種類型中,由于單類支持向量機(jī)沒有未發(fā)生滑坡樣本的約束,因此在相同的預(yù)測精度下可能導(dǎo)致高危險(xiǎn)區(qū)域偏大。
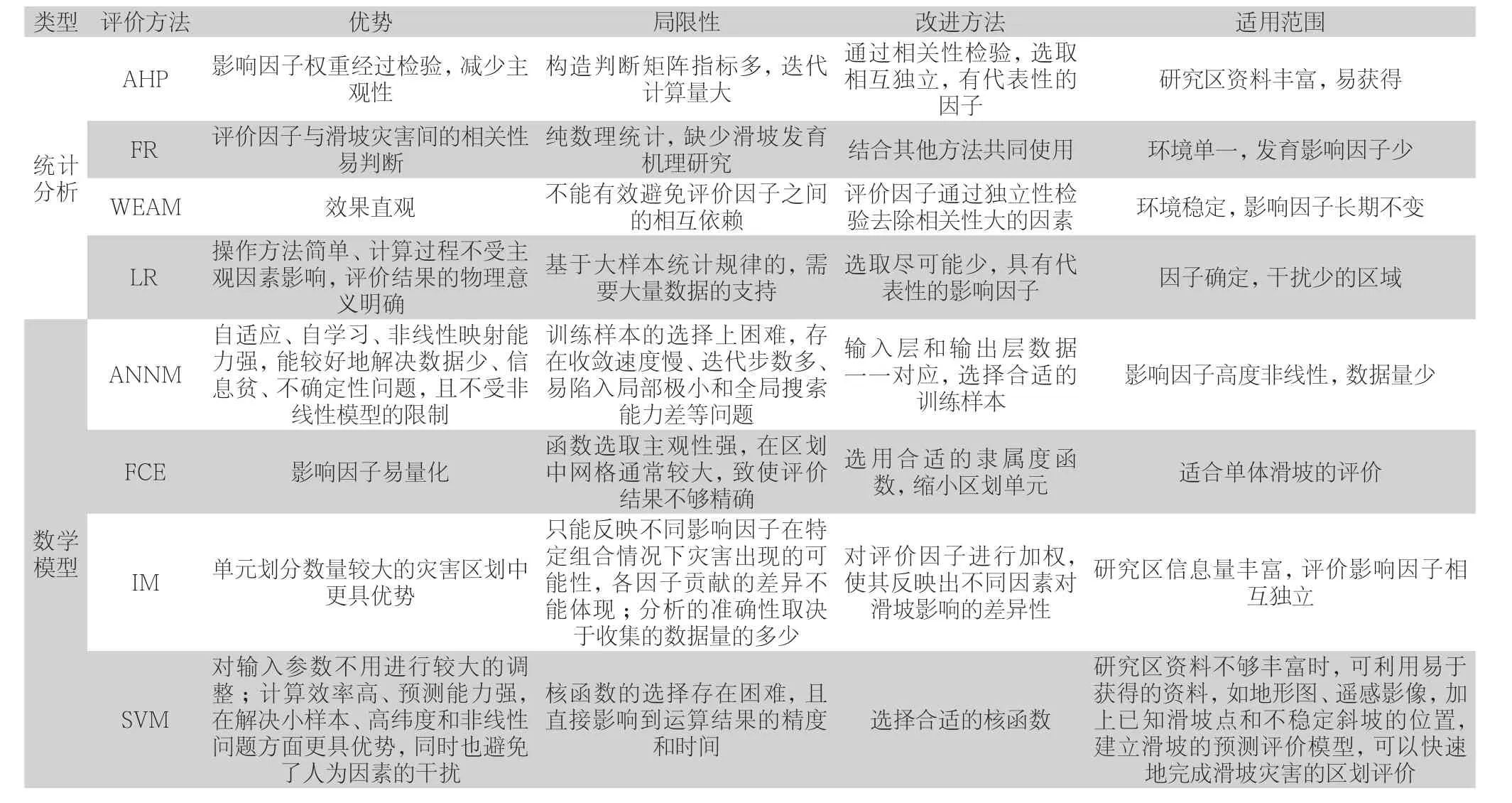
表1 常用滑坡易發(fā)性評價(jià)方法對比
2 常用滑坡評價(jià)方法對比
通過上述統(tǒng)計(jì)分析法和數(shù)字模型法的分析總結(jié),不同方法的優(yōu)勢和局限性如表1所示。
由表1可知,不同方法都具有一定的局限性和適用范圍。在研究某一地區(qū)滑坡災(zāi)害時(shí),由于影響滑坡發(fā)育的因素眾多,所有對滑坡的產(chǎn)生有貢獻(xiàn)的因素也很難被全部收集到,因此在研究區(qū)資料不夠充足時(shí),可用已獲得的各種來源的數(shù)據(jù)結(jié)合現(xiàn)有的滑坡的詳細(xì)位置資料等,應(yīng)用一定的數(shù)據(jù)挖掘模型來建立適合目標(biāo)研究區(qū)的滑坡評價(jià)模型,實(shí)現(xiàn)滑坡災(zāi)害評價(jià)。本文針對不同形成機(jī)理的滑坡災(zāi)害,歸納出基于GIS滑坡易發(fā)性評價(jià)基本思路。首先依據(jù)已發(fā)生滑坡災(zāi)害的規(guī)模、大小、地形特征、坡度、巖石性質(zhì)、斷裂等信息進(jìn)行統(tǒng)計(jì)分析,確定評價(jià)因子,并進(jìn)行相應(yīng)賦值,然后根據(jù)滑坡易發(fā)性評價(jià)因子選擇合適的一種或幾種評價(jià)方法及模型,最后劃分易發(fā)性等級(jí),完成滑坡災(zāi)害易發(fā)性評價(jià)和預(yù)測。
3 結(jié)語
對比基于GIS評價(jià)滑坡災(zāi)害的不同方法可知,針對不同區(qū)域的滑坡災(zāi)害,需要分析滑坡災(zāi)害的形成機(jī)理,選擇合適的易發(fā)性評價(jià)方法。此外,往往還需要綜合多種方法加以交叉驗(yàn)證,才能達(dá)到科學(xué)合理的評價(jià)和預(yù)測結(jié)果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
石油瀝青(2021年4期)2021-10-14 08:50:44
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
意林原創(chuàng)版(2016年10期)2016-11-25 10:28:30
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中國教育技術(shù)裝備(2015年19期)2015-03-01 02:43:07
