面向新浪微博的情感社區檢測算法
2021-01-15 09:30:08韓東紅張宏亮朱帥偉齊孝龍
東北大學學報(自然科學版) 2021年1期
韓東紅, 張宏亮, 朱帥偉, 齊孝龍
(東北大學 計算機科學與工程學院, 遼寧 沈陽 110169)
隨著Web 2.0的出現和普及,互聯網用戶迅速從信息的消費者轉變成了信息的生產者.借助微博為代表的社交網絡平臺,用戶可以自由表達情感、互動交流,使得跨越地理位置而具有相同喜好的用戶聚集成一個社區成為可能.因此通過挖掘分析海量社交網絡數據,發現其中潛在社區已經成為近年來的熱點研究問題.
社交網絡中的社區發現概念最早由Newman等[1]提出,即發現社交網絡中的內聚子群,其中節點與節點之間的聯系非常緊密,而子群之間的聯系相對稀疏.社區發現有助于進一步認識、理解復雜網絡,可用于社會網絡演變[2]、個性化推薦[3]、市場營銷[4]等應用研究.情感社區的概念則由Xu等[5]首次提出,旨在發現社交網絡中對某商品質量或服務有相同情感或觀點的聯系緊密的用戶群,以幫助企業改進生產、設計營銷策略.
作為最大的中文社交網絡平臺,截至2017年5月份,新浪微博用戶數已超過Twitter,達到3.4億.可見,在線社交網絡已成為連接網絡虛擬空間和人類物理世界不可或缺的橋梁.如果能通過微博用戶的文本及網絡交互信息,分析在某一話題下具有情感傾向一致性的用戶群體,對于微博情感分析、輿情監測及心理學研究等領域都具有重要意義.例如在網絡輿情分析方面,通過挖掘微博熱點事件中的情感社區,可以幫助政府了解網絡輿情以及不同情感社區的構成;在心理健康分析領域,對微博用戶進行情感社區劃分,便于進一步對其中的高壓力人群實施針對性的心理疏導和專業干預.
基于此,本文對面向新浪微博的情感社區檢測算法進行了深入研究.作為首個面向中文微博進行情感社區發現的研究項目,本文首先在構建情感社區檢測框架的基礎上,融合微博情感表情建立情感詞典,提出基于樸素貝葉斯半詞典半表情(SL-SE-NB)算法進行文本情感傾向預測;并提出一種基于潛在狄利克雷分配(latent Dirichlet allocation,LDA)話題模型的用戶-超話題-關鍵詞(UTK)模型,使之能準確挖掘用戶話題,同時解決微博網絡稀疏性問題;最后由于傳統社區劃分算法大多基于網絡結構而忽略用戶產生的文本內容,本文在標簽傳播算法(label propagation algorithm,LPA)基礎上加入話題概念,并抽取帶有情感傾向的用戶作為種子集進行標簽傳遞,提出SMB-LPA算法以發現情感社區.
1 相關研究工作
情感分析和社區發現是社交網絡挖掘中重要的兩個研究領域,本研究融合了兩個領域中的相關技術,下面分別介紹它們的研究成果.
1.1 社交網絡中的情感分析
情感分析亦稱觀點挖掘,由Nasukawa等在2003年提出,旨在通過文本分析進行情感計算,從而提取用戶的情感傾向(極性)及所持觀點[6].有研究將情感分析劃分為篇章級、句子級和詞及屬性級三種層次[7].其中詞語級情感傾向研究是核心,即發現文檔中的主觀詞或用戶在實體及屬性上表達的觀點詞并分析其情感傾向.情感極性包括粗粒度和細粒度兩種,前者將情感分為正、中、負三類,而后者則給出“喜怒哀樂驚惡恐”等復雜情緒傾向.目前,社交網絡情感分析方法分為基于情感詞典(無監督)和基于機器學習(有監督)兩類[8].
基于詞典和規則的方法一般不需要訓練數據,通過構造文檔或句子中的情感函數,計算出情感極性[9].Fersini等[10]綜合考慮形容詞、表情符號、擬聲詞等作為微博情感分析中的表達符號,并證明了該方法能夠豐富特征空間及提高情感分類的性能.楊佳能等[11]基于情感詞典對微博文本進行依存句法分析并且構建情感表達樹,再根據制定的規則計算微博文本情感強度并判斷文本的情感傾向類別.Saif等[12]提出了一種不同于典型情感詞典的方法,即對Twitter文本進行情感分析時,考慮了在不同語境中詞的共生模式以便捕捉其語義,并相應更新其在情感詞典中的極性.
基于機器學習的方法則使用含大量標注的訓練數據,選擇不同的監督學習方法如樸素貝葉斯、最大熵、SVM等構造分類器,實現對微博文本的情感極性預測[13].Wang提出了一種融合情感詞典和機器學習的方法對旅游評論進行情感極性分析[14],即采用向量空間模型并通過情感詞典降低特征空間維度,通過TF-IDF計算權重,再利用SVM分類器對旅游評論的情感極性分類.一種深度信任網絡DBN模型和多模態特征抽取方法對中文短文本進行情感分類亦被提出[15],多模態特征結合傳統文本特征作為DBN模型的輸入向量,RBM層利用輸入數據的概率分布抽樣來學習隱藏的語義結構,最后RBM分類層完成對中文短文本的情感分類.
1.2 社區發現
社區發現又稱社群監測,用以發現社交網絡中的社區結構,相關算法主要分為3類,即基于網絡拓撲結構的社區發現、基于語義的社區發現及融合拓撲結構和語義的社區發現[16].
基于網絡拓撲結構的算法分為非重疊社區劃分和重疊社區劃分,前者主要包括譜聚類方法(如最小割算法[17])、模塊度優化方法(如GN算法[18])、基于標簽傳遞策略(如LPA)[19],而重疊社區劃分算法的代表包括基于團滲透改進的CPM算法[20]、基于種子集傳遞的LMF算法等[21].用戶的文本內容是衡量其情感、興趣傾向等的重要載體,此類方法的特點是僅考慮用戶之間的拓撲關系,用戶間的相似度度量并不全面.
基于語義的社區發現算法則通過文本內容的相似性進行聚類,并根據文本相似性劃分社區.話題模型是典型的文本聚類方法.Blei等[22]提出的LDA模型將“話題”概率化,認為模擬文章的生成過程,可以先從文檔-主題分布中抽取一個主題,再從主題-詞分布上抽取一個詞,抽取概率均由狄利克雷分布模擬生成.針對社交網絡中出現的短文本數據,Yang等提出了TS-LDA模型[23],從文本內容中抽取出隨時間變化的潛在動態話題.Song等[24]提出PTM模型,將成對的用戶關系融入到話題模型中,以發現潛在話題和轉移話題.A-LDA模型[25]為了能夠抽取出某段時間內的微博熱點話題,在LDA的基礎上加入了時間屬性和標簽屬性.Li等進一步提出PAM模型[26],用一個有向無環圖(DAG)表示語義結構,不僅可以 描述詞之間的相關性,而且可以靈活描述主題之間的相關性,較LDA具有更強的文本表示能力.
融合拓撲結構和語義的社區發現算法是結合網絡拓撲結構和文本信息建立模型,旨在挖掘有共同興趣的群體.Zhang等提出了一個聯合框架,即挖掘興趣社區時融合了話題模型和用戶的關注關系網[27].Yang等[28]在CESNA算法的基礎上,提出融合網絡結構和節點屬性的重疊社區發現算法.
1.3 情感社區發現
與傳統社區發現不同,情感社區檢測是指挖掘社交網絡中有相似情感傾向或持相似觀點的社群.盡管社區發現的研究成果已經頻頻問世,情感社區挖掘的研究才剛剛開始.Xu等[5]首先給出“情感社區”定義,同時提出兩種情感社區發現算法,目標是使社區內用戶情感的一致性最大化.通過Epinions網站API獲取的數據建立用戶信任關系網,將用戶對產品的評論分為“積極”、“中性”、“消極”三種極性,并基于所提出的算法將社區劃分為對應的三種情感社區.Wang等[29]提出了兩種情感社區檢測方法,目標分別是模塊度最大化和最小化情感差異.通過爬取電影評論網站Flixster獲取數據集并根據彼此分享影評以建立朋友關系網,利用提出的情感社區發現算法區分具有不同情感極性的社區.Deitrick等[30]則首先利用隨機游走策略劃分社區,并在全局社區內及某話題下社區內進行不同層次的情感分析,最后通過@technet社交網絡數據驗證所提出算法的有效性.文獻[31]利用情感分析強化社區發現,即在社區檢測考慮評論、轉發、回復等文本內容作為Twitter特征.
以上成果均面向英文社交網絡,目前尚無針對中文社交媒體的情感社區發現研究,而該研究對網絡輿情、公共心理健康、個性化推薦等領域均有重要意義和應用價值.
2 情感社區檢測算法
2.1 相關定義
定義1微博用戶集合U:U={u1,u2,…,uN},其中ui表示第i個用戶,ui∈U,N為微博總用戶數.
定義2微博博文集合B:用戶ui發表的微博集合為Bi={bi1,bi2,…,biM},其中M表示用戶ui發表的博文總數,Bi∈B.
定義3博文詞集合W:對于用戶ui發表的博文bij可表示為詞的集合Wij={wij1,wij2,…,wijK},K表示bij中包含詞的總個數,wijK表示博文bij中第K個詞.
定義4博文表情集合E:對于用戶ui發表了微博bij,在該篇博文bij中使用的表情集合為Eij={eij1,eij2,…,eijP},其中P為ui在博文bij中使用表情的個數,eijP表示博文bij中第P個表情.
定義5情感詞典集合:本文一共涉及4種詞典,分別是積極情感詞典(用PWD表示)、消極情感詞典(用NWD表示)、積極表情詞典(用PED表示)和消極表情詞典(用NED表示).
定義6博文情感傾向:先分別計算積極情感詞、消極情感詞、積極表情、消極表情在博文中出現的后驗概率Ppw,Pnw,Ppe和Pne,情感傾向計算如式(1)~式(3)所示.
Aw=Pnw-Ppw.
(1)
Ae=Pne-Ppe.
(2)
A=aAw+bAe.
(3)
其中:Aw為博文考慮情感詞后的情感傾向;Ae為博文考慮表情后的情感傾向;A為二者綜合考慮后博文最終的情感傾向.若A>0,判定該博文的情感傾向為負向;若A<0,判定博文的情感傾向為正向;若A=0,則判定該博文情感傾向為中性,其中a和b為參數,a+b=1.
定義7超話題:微博話題主要是指#號與#號之間的內容,如#魏則西百度推廣事件#,所謂超話題就是進一步抽取話題,如上述話題可拆分成#魏則西#和#百度#等超話題.
定義8子話題:本文所提出的UTK模型是基于LDA模型改進的,主要是對用戶-超話題-子話題-關鍵詞模型建模,在本模型中的子話題相當于LDA模型中的話題角色,是基于用戶微博內容進行抽樣得到的類別分布結果.
定義9情感社區:在特定的話題下,微博用戶對該話題具有相同情感傾向的社交網絡群體,稱為一個情感社區.
2.2 處理框架
面向新浪微博情感社區發現的總體框架如圖1所示.首先爬取微博文本和用戶關系;在數據預處理階段,數據經三輪清洗后,利用構建的情感詞典對文本進行分詞處理;對用戶博文進行情感詞和表情詞統計,利用SL-SE-NB算法進行情感傾向計算;接著使用UTK模型進行話題抽取,最后抽取帶有情感傾向的用戶作為種子集進行標簽傳遞,利用SMB-LPA算法發現情感社區.

圖1 情感社區檢測處理框架
2.3 情感檢測SL-SE-NB算法
構建情感詞典時本文借助了目前所有較權威的情感詞典,其中有褒貶詞及其近義詞詞典、博森實驗室網絡情感詞典、清華大學李軍中文褒貶義詞典、大連理工大學中文情感詞匯、臺灣大學NTUSD簡體中文情感詞典和知網Hownet情感詞典.去除一些不常用的詞或者短語,最后獲得68 432個正向情感詞,41 382個負向情感詞.再從微博中提取表情文字并進行詞頻統計,過濾不常用的表情符號后進行人工標注,共獲得573個正向情感表情,343個負向情感表情.最后,得到由情感詞詞典和情感表情詞典構成的情感詞典集合.為預測微博文本的情感極性,本文提出了基于情感詞詞典集合和樸素貝葉斯的SL-SE-NB算法,其偽代碼如下.
輸入:情感詞典集合,訓練集, 未標注的微博數據集
輸出:有標注的微博數據集
1. For eachbijin 訓練集
2. 統計消極訓練數據集中情感詞及情感表情的權重;
3. 統計積極訓練數據集中情感詞及情感表情的權重;
4. 統計中性訓練數據集中情感詞及情感表情的權重;
5. End for
6. For eachbijin 未標注的微博數據集
7. For eachwijK∈Wij‖eijP∈Eij
8. If (wijK∈NegativeWordDic‖wijK∈
Positive WordDic) then
9. 統計當前微博中的情感詞wijK的詞頻;
10. For eachwijKin 當前詞的權重
11. 計算wijK出現在消極微博中的后驗概率;
12. 計算wijK出現在積極微博中的后驗概率;
13. End for
14. End if
15. If (eijP∈NegativeEmojiDic‖eijP∈
PositiveEmojiDic) then
16. 統計當前微博中情感表情eijP的詞頻;
17. For eacheijPin 當前表情的權重
18. 計算eijP出現在消極微博中的后驗概率;
19. 計算eijP出現在積極微博中的后驗概率;
20. End for
21. End if
22. If(A>0) then
23. 極性=-1;
24. Else if (A<0) then
25. 極性=1;
26. else
27. 極性=0
28. End if
29. End if
30. End for
31. End for
SL-SE-NB算法是先訓練分類器模型再對測試數據進行情感極性預測的過程.其中第1~5行是統計情感詞和情感表情在消極訓練數據集、積極訓練數據集和中性訓練數據集中出現的權重,至此分類模型訓練完畢.第6~7行開始遍歷實驗數據集中每篇博文的每個單詞和每個表情;如果這些情感詞出現在情感詞典(積極情感詞典或者消極情感詞典)中,分別計算該詞在消極微博中的后驗概率和在積極微博中的后驗概率,代碼如8~14行所示,NegativeWordDic與PositiveWordDic分別為消極情感詞典與積極情感詞典;同理可以計算出每篇博文中每個表情出現在消極微博中的后驗概率和每個表情出現在積極微博中的后驗概率,代碼如15~21行,NegativeEmojiDic與PositiveEmojiDic分別為消極表情詞典與積極表情詞典;第22~29行是根據式(1)~式(3)判斷博文情感極性,但為了使算法達到最優還需進行調參.
2.4 話題UTK模型
LDA是一個文檔-話題-詞的三層貝葉斯框架模型,可以發現主題和詞之間的相關性,卻忽略話題之間的相關性.本文提出了基于LDA的UTK模型,即利用微博#與#之間的話題,將其加入到LDA模型中,將原LDA模型修改為用戶-超話題-子話題-關鍵詞的4層模型,旨在準確地挖掘出用戶主題,同時解決了微博網絡稀疏性問題.
UTK模型如圖 2所示.
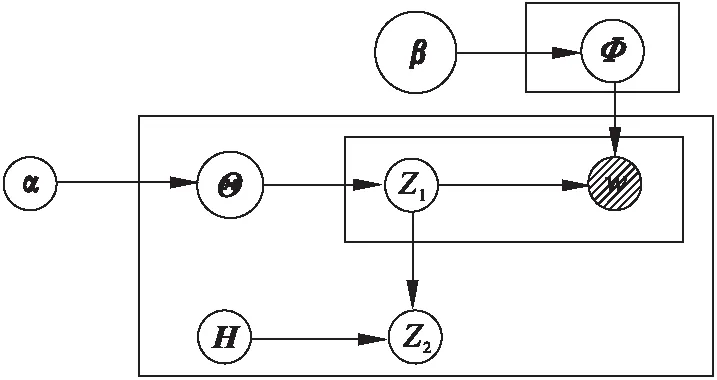
圖2 UTK模型
文檔生成的超話題分布Z1、子話題分布Z2和關鍵詞分布參數矩陣為Θ的聯合概率如式(4)所示.其中w為關鍵詞的多項式分布,H為超話題多項式分布的先驗均勻分布的參數矩陣,α和β分別是參數矩陣為Θ和Φ的狄利克雷分布的超參數.
P(w,Z1,Z2|α,β)=P(w|Φ,Z1)·
P(Z1|Θ)P(Z2|H).
(4)
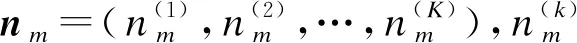
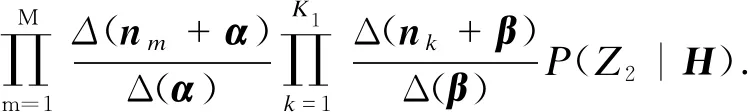
(5)
式中,Δ(·)為狄利克雷分布的歸一化因子.
基于式(5),本文用吉布斯抽樣法對博文中每個詞的主題進行抽樣,得到UTK模型算法的偽代碼如表1所示.

UTK模型算法中第1~2行分別對訓練集中每篇博文抽取關鍵詞并加載語料庫.第3~5行是為了保證讓訓練的主題個數至少為1,第6行計算詞匯表中關鍵詞對的超話題的概率,第7行進行吉布斯采樣,通過計算文檔-主題矩陣和主題-詞矩陣以獲取Θ和Φ概率矩陣.第8行獲取最大概率的前10個關鍵詞對應的超話題,第9~11行是保存每個主題出現概率最高的10個詞,至此UTK模型訓練完成.第12行是抽取每篇新博文中的關鍵詞,第13行是結合新博文和UTK模型中的詞匯表,構建一個新詞匯表.第14行利用Φ矩陣計算重新采樣每個詞的話題,第15~17行輸出新文檔中話題概率最高的10個話題,并把結果寫入到UserTopics文件中.
2.5 SMB-LPA算法
社區發現的經典算法包括LPA和GN算法.LPA優點是收斂速度快,但遇到多個標簽時,LPA的隨機選擇會帶來算法的不穩定,即算法每次執行后的結果都會不同.GN算法考慮了全網結構,找到的社區準確率較高,但計算最短路徑時時間復雜度較高.并且二者均利用網絡結構進行社區檢測,未考慮帶有情感傾向的文本信息,故不能直接用于情感社區發現.
本文對上述兩個算法進行優化,提出了用于情感社區挖掘的SMB-LPA算法.在標簽初始化部分采用了SL-SE-NB算法的情感傾向計算結果,通過從微博中提取具有代表性的種子集,將其情感極性作為該用戶節點的標簽,這樣就可以基于某個話題,將其劃分為積極、消極和中性社區.SMB-LPA算法見表2.

第1行加載邊關系和根據種子集初始化標簽,第2行初始化記錄迭代次數iter_time.第3~20行是進行標簽傳遞的過程,若can_stop()為true且迭代次數小于最大迭代次數max_iter,則進行標簽傳遞.第6~8行若標簽為種子集中的標簽,則不進行標簽更新.第9~12行若只有一個最大標簽,直接選取最大標簽為新標簽.第13~18行若遇到多個最大標簽,則采用最小邊介數進行標簽傳遞;第19行將迭代次數加1進入下次標簽傳遞.
3 實驗與結果分析
3.1 實驗環境與數據集
本文的實驗所需數據主要包括了微博用戶內容、微博用戶關系和數據清洗完以后的數據以及用戶關系等.本文通過搭建分布式爬蟲框架,爬取了2016年5月2日到2016年5月16日發布的微博數據,共搜集9 028 632篇微博,539 564個用戶.這些微博原數據經過3輪數據清洗后,清洗掉一些轉發微博、回復微博、廣告、新聞等內容,同時過濾了一些中英、中日、中韓混用的微博,并且把繁體微博轉化成簡體微博,大約剩下1 471 234篇微博可供實驗選擇.
因為本文主要研究的是計算原創微博的情感傾向,并且主要針對的是大眾用戶和活躍用戶,鑒于此,本文根據微博用戶信息又進行了一次篩選,最后符合本實驗的微博用戶有以下幾個特點:① 在2016年5月2日到2016年5月16日期間發表微博篇數在25到35之間,且沒有被新浪微博屏蔽的用戶,本文稱這些用戶為活躍用戶; ② 用戶必須有粉絲或者關注;③ 有認證信息的用戶不作為研究對象,因為有認證的大多數微博用戶發表的博文是積極的.基于上述要求,本文最后選取了98 250篇微博,3 323個微博用戶作為實驗數據集.最后又爬取了這3 323個微博的關注或者粉絲關系,一共獲得479 543條邊關系.
本文采用的軟、硬件參數如表3所示.
3.2 情感傾向計算實驗結果分析
首先需要確定式(3)中的兩個參數值,其中a為情感詞特征的權重,b為情感表情特征的權重.為了使分類準確率最高,本文對a和b進行了參數設置.進行參數設置的數據集選取了已經標注的2 000條數據進行召回率對比實驗.如圖3所示,當a=0.8或者b=0.2,召回率最大.本文選取了基于情感詞典的情感分類算法(Senti-Lexicon)[32]、樸素貝葉斯分類算法(Naive Bayes) 進行性能對比.本文采用召回率和F1值作為實驗評價指標,結果見圖4和圖5.
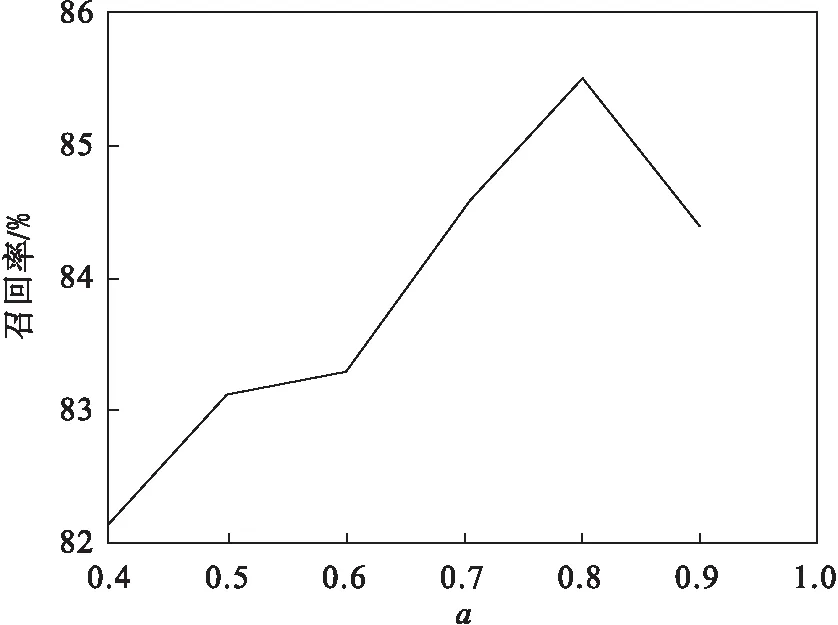
圖3 a取值對召回率的影響
從圖4中可以看出SL-SE-NB算法比其他兩種算法(Senti-Lexicon和Naive Bayes)的召回率都要高,但是隨著數據集樣本量增加,三種算法的召回率都呈遞減趨勢.這主要是因為測試數據集存在一定噪聲數據,隨著樣本量增加,噪聲數據也越來越多,從而導致了召回率下降.
從圖5中可以看到,本文所提出的SL-SE-NB算法的F1值高于其他兩種算法,但隨著實驗數據集樣本量增加,F1值均呈下降趨勢.原因是實驗數據集由本實驗室人工標注,故存在個人標注差異,數據量較小時,這種差異不明顯,隨著數據量的增加,差異性就會顯現.
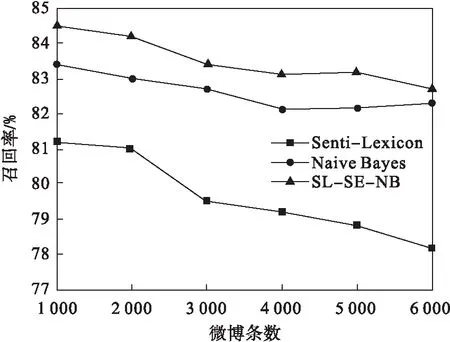
圖4 不同算法的召回率對比

圖5 不同算法的F1值對比
3.3 UTK模型結果分析
在UTK模型中有3個參數需要設置,分別是話題數K、狄利克雷分布的超參數α和β,以及迭代次數.在評價話題抽取模型的性能時,采用召回率、困惑度作為評價指標;對比算法選取了LDA模型和PAM模型.
關于最優話題數K的設置, Blei等[22]提出了一種根據設置不同的topic數量畫出話題數-困惑度曲線圖,然后來確定最佳的話題K.本文采用該方法設置話題數K如圖6所示.可以看出,隨著話題數增加,困惑度趨于減小;當話題數達到100以后,困惑度值基本趨于收斂,所以本文取話題數K=100.此結果與訓練數據集比較吻合,訓練數據集的超話題數共有102個.這也從側面說明本文所提出的UTK模型可以找出與訓練數據集中話題個數相等的話題.其他參數如狄利克雷分布的超參數α和β,及迭代次數,最后又經驗調優得到α=0.1和β=0.1(向量的每一維都相同,為0.1),而最大迭代次數為1 000.
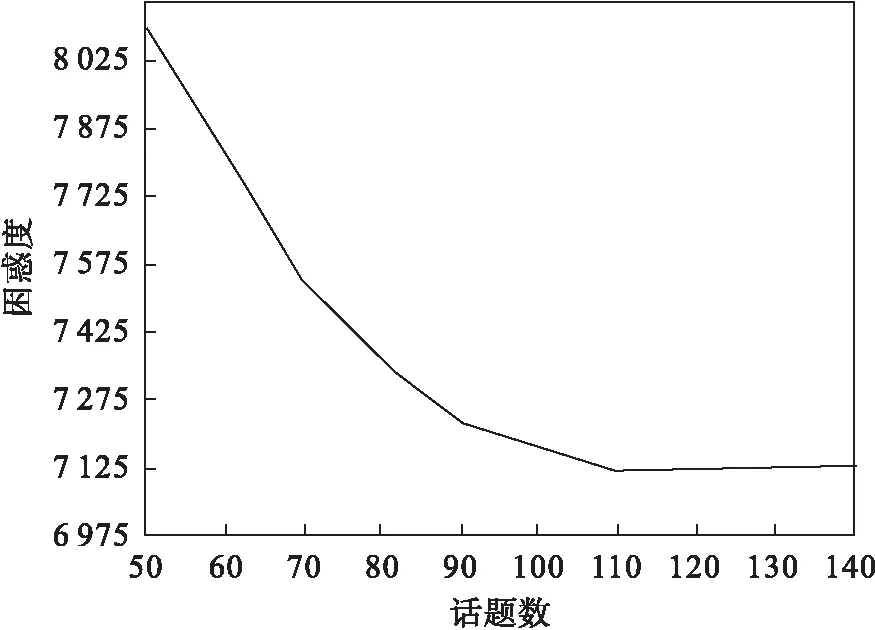
圖6 話題-困惑度關系
測試數據集的超話題編號集合為{1,12,28,35,42,56,63,71,85,97,101},從圖7中可以看出,UTK話題模型的召回率均高于傳統LDA模型和PAM模型.在1號超話題和63號超話題的測試數據集上,UTK模型的召回率可以達到83.20%和82.56%.但在56號超話題上UTK的召回率降到了70.45%,原因是它是關于#戛納電影節#的一個超話題,其中涉及到的明星名字非常多,會導致在話題抽取的時候把其中關于某個明星的內容歸類到其他超話題中,從而出現召回率降低的情況.相對于LDA模型,PAM模型融入了層次化思想,不僅可以對子節點進行聚類,而且可以抽取更有代表性的父節點層,所以PAM模型得到的實驗結果雖不如UTK模型,但是比LDA模型有優勢.
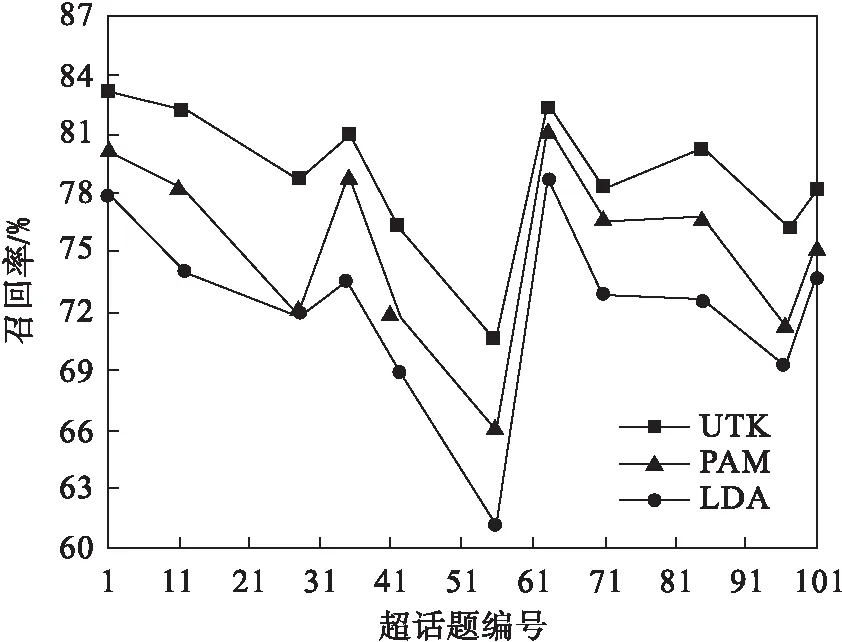
圖7 主題質量圖
在相同參數下,分別計算UTK模型、PAM模型和LDA模型的困惑度,結果如圖8所示.可以看出,隨著迭代次數的增加,困惑度趨于收斂,UTK模型的困惑度要比其他模型的困惑度小.這也說明UTK模型可以用于真實數據集建模和預測.同時也可以看到當迭代次數超過1 000時,困惑度基本不再變化,所以本文在真實數據集上進行話題抽取的時候,選取的迭代次數為1 000.

圖8 迭代次數-困惑度關系
3.4 SMB-LPA算法實驗結果分析
本文采用模塊度、規范化互信息和算法的運行時間等評價指標,對比算法是LPA,GN,SCD[33],GEMSEC[34]和Edmot[35].使用開源框架Karate Club[36]來實現SCD,GEMSEC以及Edmot算法,并且在實現的過程中,將用戶作為節點,將用戶所發的經過分詞后的微博作為該節點的特征.
模塊度是指給定一個由n個節點和m條邊組成的網絡,在任意兩個節點vi和vj之間,邊的期望值為(didj)/(2m),其中di和dj分別是兩個節點vi和vj的度.考慮一條邊從節點vi出發,隨機連接網絡中的任意節點,那么它以di/(2m)的概率連接節點vj.由于節點vi的度為di,也就是說,這個節點有di條邊,所以在兩個節點vi和vj之間,邊的期望值為(didj)/(2m).結合上述解釋,模塊度的計算公式為
(6)
為了計算方便常常引入參數1/(2m),讓模塊度值歸一化到-1~1之間.模塊度越大證明社區劃分的質量越好.
規范化互信息是用來度量兩個聚類結果的相似度的,計算公式為
NMI(πa;πb)=
(7)
實驗抽取了兩個比較活躍的話題進行了模塊度計算,最后的模塊度值是對5次結果求平均值取得的.結果如表4所示,可以看出SMB-LPA算法是6個算法中模塊度值最大的,同時每次計算的模塊度值差別不大,這也說明SMB-LPA算法具有很好的穩定性.LPA的模塊度值差異較大,這是由標簽傳播算法的隨機性造成的.SCD與GEMSEC算法的模塊度值較小,這是由于聚類算法沒有種子集作為起始標簽,僅由節點的特征來進行聚類,而且節點的特征矩陣又較為稀疏,所以聚類的結果中很多社區只有單一一個節點,這樣的原因也導致了算法檢測出的社區數量非常多,算法的模塊度與規范化互信息都很低.而Edmot算法通過邊增強的方法,增強了輸入網絡的原始連接結構以生成重新連接的網絡,從重新連接的網絡中獲得的社區數量較少,所以其模塊度較高.雖然Edmot算法的模塊度高,但是其規范化互信息較低,原因是雖然其劃分出的社區數量少,但是劃分的準確度低,與標注值的差異依然很大,所以其模塊度高但是規范化互信息低.且由圖9可知,SMB-LPA算法的規范化互信息高于其他的算法.

表4 模塊度值比較
本文對平均運行時間也進行了對比,即將每個算法分別運行30次求平均值,結果如表5所示.可以看出LPA的運行時間最短,而SMB-LPA次之,然后就是GN算法,其余算法的運行時間較長,尤其是GEMSEC算法的運行時間特別長.LPA運行時間短的原因是其執行時只需要根據標簽進行隨機傳遞,不需要計算其他額外變量;而SMB-LPA算法在LPA的基礎上,需要計算最小邊介數,所以運行速度不及LPA; GN算法需計算全部的邊介數,SMB-LPA算法在最大標簽個數不唯一時才需要計算邊介數,所以SMB-LPA算法要比GN算法的運行速度快.SCD,GEMSEC以及Edmot算法由于其在聚類過程中需要將節點及其鄰接節點的特征值納入計算過程中,而且沒有種子集作為起始標簽進行傳遞,所以計算過程較長.
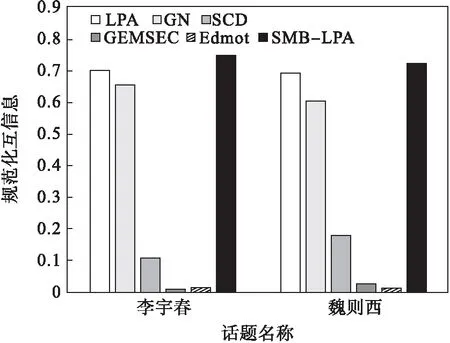
圖9 規范化互信息值比較

表5 運行時間比較
4 結 語
本文針對新浪微博平臺構建情感社區檢測框架,融合微博情感表情建立情感詞典,并基于樸素貝葉斯算法提出SL-SE-NB分類模型計算文本情感傾向;為更準確地挖掘出用戶主題,加入了超話題的概念,提出一種基于LDA話題模型的用戶-超話題-關鍵詞UTK模型;在LPA基礎上加入話題概念,并抽取帶有情感傾向的用戶作為種子集進行標簽傳遞,提出SMB-LPA算法以檢測情感社區;最后通過實驗驗證了本文算法在召回率、模塊度值、F1值、規范化信息等指標優于其他算法.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中國生殖健康(2020年5期)2021-01-18 02:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
中國生殖健康(2018年5期)2018-11-06 07:15:40
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
