淺談人工智能技術在音樂創作中的應用
2020-12-28 06:49:46陳世哲
音樂探索 2020年1期
關鍵詞:人工智能
陳世哲

關鍵詞:人工智能;電子音樂;算法作曲
引言
人工智能(Artificial Intelligence)并不是一個新名詞。早在20 世紀50 年代,計算機領域就引起了第一次科技熱潮, 中間也歷經了多次低谷,但隨著谷歌DeepMind 團隊的AlphaGo 擊敗人類圍棋冠軍, 一個計算機學科中的人工智能技術迅速引發人類下一個科技浪潮, 并在各行業產生新的機遇。
在傳統意義上, 機器的優勢在于能夠幫助人類完成機械而重復性的勞動, 對于創造性的工作則參與較少。但隨著人工智能技術的發展,它正逐漸應用于音樂的創作、制作、分析和教育等領域。其中,利用AI 作曲或者輔助作曲變成關注度最高的應用方向之一, 很多疑問也就此產生。如AI 作曲技術能否在一定程度上代替人類作曲家? AI 作曲技術會如何影響傳統作曲的思維? 這些將變成一個個有趣而又嚴肅的課題。
在人工智能于各行業應用的實際過程中,機器學習① 可以說是AI 最重要的子集之一,它深刻影響著AI 中的其他領域。用AI 技術自動作曲并不是一個新的課題, 相關的研究很多年前就已經開始,但是一直受技術所限。人工智能作曲的主要原理同下圍棋的原理類似, 主要運用遺傳算法② 、神經網絡、馬爾可夫鏈③ 和混合型算法等,利用音樂規律給計算機制定規則、建立海量數據庫,繼而進行深度學習① ,分析作曲規則、結構等各項信息,然后重新生成音樂。目前, 有多家國內外機構和公司開始了該領域的研究。傳統的方案是完全建立在用規則構建智能系統的基礎上, 而新的方案是更多地使用神經網絡的方式,即使用“學習”的方式來實現。
本文主要討論將AI 技術應用在音樂創作領域所主要使用的技術方案和策略算法, 并分析目前所碰到的問題以及與算法作曲的關系,討論其應用方式, 以促進此技術能更好地為音樂服務。
二、相關技術手段分析
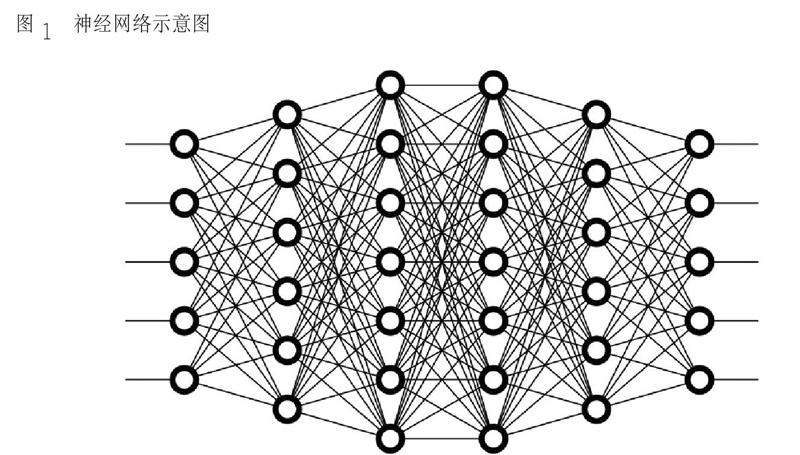
(一)神經網絡(NN)
人工智能的傳統方式是利用規則, 即以一種自上而下的思路來解決問題; 而神經網絡(Neural Network,簡稱NN)則是以一種自下而上的思路來解決問題, 它的基本特點是模仿人類大腦的神經元② 之間的信息傳遞和模式。
神經網絡有兩個特性,一是每個神經元通過對應的輸出函數,計算和處理來自相鄰神經元的加權輸入值;二是通過加權值來定義神經元之間信息傳遞的關系,算法在處理過程中不斷地自我學習、不斷地優化和調整這個加權值。此外,神經網絡的處理過程需要依靠大量的數據來訓練。所以,神經網絡的處理過程具有非線性、分布式、并行計算、自適應和自組織的特點。
以人類學習創作音樂的過程為例, 一般要經歷音樂感知(欣賞),音樂模仿寫作,最后達到獨立創作。在創作過程中,也包含對作曲技法、和聲理論等的學習,學習者在不斷地練習中,通過教師地批改引導, 不斷完善自己的創作思路等。這些學習過程基本可以通過神經網絡的架構模擬出來, 這也是這項技術得以應用的一個基礎。
神經網絡的運作過程需要有輸入與輸出,權重和閾值以及多層的感知器③ 的結構(圖1)。神經網絡可以看成是一個“黑盒子”,給定足夠多的訓練集,即可以在輸入端給定X 后,得到預期的Y。具體來說,神經網絡的運作過程需要確定輸入和輸出,然后找到一種或多種算法,可以從輸入得到輸出, 再找到一組已知答案的數據集,用來訓練模型,此后,重復這個過程,輸入模型,就可以得到結果,不斷修正這個模型④。
音樂是時間的藝術, 許多信息是基于時間軸建立的。而神經網絡實現的機制有很多種,其中能夠較好地處理時間軸信息的一種技術就是遞歸神經網絡(Recursive Neural Network,簡稱RNN)。RNN 是一種(前饋)神經網絡,通過新增表示時間維度信息的參數以及相關機制, 使神經網絡不僅可以基于當前數據而且可以基于先前數據來學習。和之前的模式不同,RNN 系統中,前一個輸入和后一個輸入是有關聯的,RNN是一個在時間上傳遞的神經網絡, 時間作為其深度的度量。循環網絡通常具有相同的輸入層和輸出層, 因為循環網絡預測下一個項目是以迭代的方式用作下一個輸入,以便產生序列,因此RNN 是音樂創作中一項重要的實現方式。
(二)LSTM 長短期記憶單元
LSTM(全稱Long Short-Term Memory)是一種特殊的RNN 結構,為RNN 的變種結構,屬于反饋神經網絡的范疇。LSTM 是為了克服RNN循環神經網絡的梯度消失① 或爆炸而產生的神經網絡,它除了繼承RNN 模型的特性外還具備了自身的優點。RNN 雖然可以兼顧時間維度信息的處理,但是若時間間隔拉長后,長期保存信息并在其中開展學習得到的結果并不理想,這對于音樂信息處理是一個致命的問題, 而解決該問題的一個重要方向便是增大網絡存儲。因此,采用特殊隱式單元的LSTM 被首先提出,其自然行為是長期的保存輸入。LSTM 主要的改變是增加了3 個門,分別是輸入門、輸出門和忘記門。在實踐中,LSTM 被證明比傳統的RNN 更加有效,它最先應用于機器翻譯領域、對話生成以及編解碼領域②。LSTM 能夠表征更復雜的人類的邏輯發展和認知過程, 所以也是音樂生成目前最值得研究的方向。
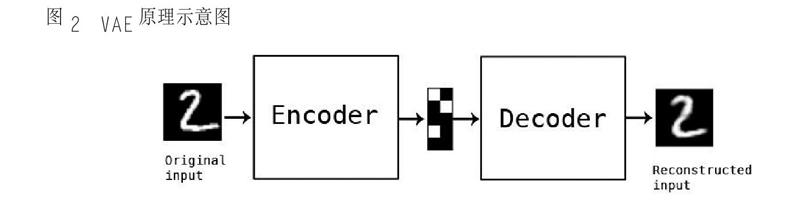
(三)VAE
Autoencoder 是通過對特征數據進行壓縮和解壓來實現非監督學習的過程③ , 它本身既是一個多層神經網絡, 也是一個對數據的非監督學習④ 的模型。⑤ 音樂數據沒有明確的優與劣之分,所以更適合于非監督的模式。而其中的變分自動編碼器(Variational Autoencoder, 簡稱VAE)是自動編碼器的升級版本,結構與自動編碼器相似,其原理是在編碼過程中增加一些限制(圖2)。這種處理原理同作曲的思維過程有相似之處,作曲在某種意義上是一個創作和規則并存的過程,而VAE 的機制可以很好地與之相符合。
在實踐過程中,VAE 已經可以在對多聲部音樂的音高動態和樂器等信息分析與生成中得到很好的應用,尤其在古典音樂和爵士樂方面。它甚至可以用爵士風格演繹莫扎特的作品,產生新的混搭方式。
變分自動編碼器是目前生成內容最優的方法之一,它可以成功生成各種形式的數據,特別是在多聲部音樂的生成工作過程方面。但是,當數據是多模式時,VAE 并不能提供明確的機制,它不能對離散值潛在變量進行推理, 所以這是制約其發展的一個重要因素。比如在C 大調與c 小調的處理過程中,對音階中各種音的使用傾向是不同的, 特別是擴展到24 音及以上時,VAE 處理起來就比較困難。所以現在還有一些研究思路是設計一種VAE+LSTM 方式,這種方式可以避免部分問題。此外,在和弦問題上還可以用受限玻爾茲曼機(Restricted BoltzmannMachine,簡稱RBM) ① 建模等等。
三、深度學習與算法作曲的關系
算法作曲(Algorithmic Composition)是電腦作曲的一種重要方式, 也可稱為自動作曲(Automatic Composition), 主要利用算法減少音樂創作時的人類干預。在傳統意義上, 作曲可以從多個維度來理解,比如旋律、節奏、和聲、編曲或者配器等等,雖然這些維度不能完全表征音樂,但可以作為數據化的起點,計算機可通過相應的語言和技術來表征這些,即計算機輔助作曲。但本文討論的AI 作曲比之已有的方式更縮減了人類干預,并不屬于傳統意義上的計算機輔助作曲。
傳統算法作曲領域的技術實現方案,除了前文提到的神經網絡方式,還包括以下幾種模式②。
1. 翻譯模式(Translational Models)
這一類模式主要是將一些其他媒介的信息轉換成音樂的相關信息,可以是因一定規則生成的,也可以是隨機產生的。例如將圖片的色彩和明暗對應到音色的色彩和明暗,但這種直接、簡單的對應,其成果和表現形式往往過于牽強。
2. 數學模型方式(Mathematical Models)
這種方式主要通過數學模型來產生音樂,在此模型下, 很多音樂的元素是通過非確定性的方法構成的。這種隨機的方式在很多傳統音樂家的創作過程中都有所應用, 而這里的隨機是完全基于數學方式的。在創作過程中,作曲家可以參與算法相關的參數配置。數學模型方式主要運用馬爾可夫鏈、高斯分布③ 及分形理論④ 等實現。這種方式存在的問題是:其算法完全基于規則的設定, 對于創作音樂這項復雜的工作,公式化實現只能完成其中一個過程,完全由數學模型方式實現的創作結果很難完美。
3. 語法模式(Grammars)
這種研究方式認為音樂中存在著語法,如同語言中的語法。這種方式借鑒語言學的概念,將音樂當作一種特殊的語音對待, 其研究方向在于如何以這種思路從音樂中提煉出算法,目前有一定的研究成果, 也可以借鑒其他學科的相關成果。這種方式的問題是:第一,語法是存在層次結構的, 或者說語言的規則是相對固定的, 但音樂的表達是存在一定的即興性或是模糊性的;第二,在語法分析和規則較多時,尤其存在模糊性的情況下,計算量要求比較高。
4. 演化模式(Evolutionary Methods)
這種方式可以通過一定的方法對信息做篩選,利用算法把好的方案篩選出來并不斷優化,得到相應的結果。該方式主要利用遺傳算法來模擬生物進化的過程, 因為遺傳算法已被證明是解決大規模搜索空間的有效解決方式, 可以找到多個解法, 這些邏輯很符合音樂創作的某些邏輯①。這種方式的問題是:遺傳算法并不能完全模擬作曲的思路, 特別是在實際操作過程中,為了節約資源通常會采用簡化的方式,而一旦簡化就會大大影響最終的結果。
5. 混合模式(Hybrid Systems)
混合模式就是混合以上方式甚至更多方式,一起來生成音樂。從理論上來說,這種方式有其合理性,研究十分復雜。但在實際應用中,傳統基于規則和其他相關信息生成音樂的實現方法相對簡單,對算法本身的要求太高,整個的運作模式并不存在“智能”和“學習”的成分②。神經網絡的方式從運作模式上來說是最接近人類思維的,傳統算法作曲的思路則各有各的特點,目前的各種主要技術方案還有一定的問題,所以結合規則和神經網絡的方案在相當長一段時間里都是最優的一種解決方案。
四、應用實例與分析比較
人工智能應用于音樂創作時, 要確定處理的音樂信號種類的問題, 通常使用信號類信息或符號類信息。但在深度學習的過程中,使用符號信息的方式相對更加普遍。
信號類信息中的第一種是音頻信號, 它可以是波形文件, 也可以是通過傅里葉變換處理后的音頻頻譜信息。符號類信息主要是用MIDI信息。MIDI 已經是一種成熟的并被廣泛應用的格式, 主要使用音符信息中的Note On 信息和Note Off 信息,利用二者在0~127 之間的取值來表示主要的音樂信息。符號類信息另一個使用的信息就是MIDI 里面衡量時間點的Tick 值。
在深度學習過程中, 還有一種和計算機交換信息的方式,是直接用文本信息來表示音樂,當然它的規則也有很多。此外,還有以和弦、節奏或者總譜的方式用于深度學習。
就目前的研究水平來看,首先,絕大多數的研究不考慮自動作曲的音樂表情問題, 也就是說,生產出來的音樂基本是比較機械的,或者說是多種音頻采樣的組合。其次,由于音色采樣和聲音合成目前在商業應用領域發展的比較完整,并沒有相關的AI 研究去關注這些方面。再次,游戲音樂因其結構完全取決于游戲場景,所以大部分研究也沒有涉及到此類型。
實際上,以“AI為音樂服務”為宗旨的相關產品已經開始為音樂服務。
例如,人工智能作曲系統DeepBach 用于復調音樂特別是圣詠類作品的創作。為保證最終效果,該系統主要圍繞四聲部合唱來工作,并專注于巴赫的四聲部合唱類作品的創作。系統采用靈活高效的采樣抽樣方法, 除了通過機器學習的方式生成, 使用者還可以在過程中添加音符生成,稱為增加一元約束,通過節奏或相關信息對模型進行控制。這種讓用戶干預過程的方式, 是在音樂概率模型中經常被忽略的一種方式。與基于RNN 的模型相反,DeepBach 不從左到右進行采樣。在考慮單個時間方向的情況下,DeepBach 架構會考慮時間上向前和向后的兩個方向,使用兩個循環網絡:一個用于總結過去的信息,另一個用于匯總來自未來的信息,以及用于同時發生的音符的非遞歸神經網絡。DeepBach 能夠生成連貫的音樂短語,并提供各種旋律的重新調和,而不會出現重復。這個系統的工作困難來自于和聲與旋律之間錯綜復雜的相互作用。此外,每個聲音都有自己的“風格”和自己的連貫性。找到一種像巴赫式的和聲進行,并與音樂上有趣的旋律運動相結合, 最終生成類似合唱的音樂是這個系統的目標。對此,我們通過網上調查問卷的方式,對1200 多人(包括音樂專業人士和業余人士)進行作品聽辨測試,結果顯示幾乎所有人都難以區分這些作品是巴赫創作的還是DeepBach 創作的。譜例1 為AI生成的作品中的一個片段。
猜你喜歡
西安航空學院學報(2022年2期)2022-07-04 07:45:42
汽車零部件(2020年3期)2020-03-27 05:30:20
表面工程與再制造(2019年1期)2019-05-11 08:52:04
商界(2019年12期)2019-01-03 06:59:05
家庭影院技術(2018年9期)2018-11-02 05:31:34
IT經理世界(2018年20期)2018-10-24 02:38:24
通信電源技術(2018年3期)2018-06-26 06:33:30
軍營文化天地(2018年1期)2018-02-10 05:19:25
小康(2017年16期)2017-06-07 09:00:59
學與玩(2017年12期)2017-02-16 06:51:12
