嵌入用戶評分偏好置信度的社會化推薦算法
2020-12-24 07:52:16郝潤芳張光明程永強
重慶理工大學學報(自然科學) 2020年11期
郝潤芳,張光明,程永強
(太原理工大學信息與計算機學院,山西晉中 030600)
隨著5G網絡的問世,信息傳輸的速度得到極大提升,使得移動通信網絡與計算機網絡的融合變得更加緊密。只要打開客戶端,琳瑯滿目的物品就會沖擊著用戶的眼睛,因此,如何快速尋找到需要的、滿意的物品困擾著許多用戶。這種情況下推薦系統顯得尤為重要,它能夠從用戶相關數據中挖掘出用戶潛在興趣愛好,為用戶決策提供幫助[1-2]。推薦系統已經在各大電商平臺[3-4],如淘寶、京東、亞馬遜,以及音樂、電影和新聞[5-8]等諸多領域廣泛應用。
推薦系統中傳統的推薦算法通常根據用戶顯式評分作為推薦的主要依據,如傳統的協同過濾算法[9]、KNN(k-Nearest Neighbor)計算相似用戶推薦算法[10-11]等。由于網絡技術的飛速發展,除了直接獲取用戶對物品顯式的評分外,通過社交網絡服務獲取用戶的社會信息也更加容易[12]。用戶通常通過朋友、同事或伙伴之類的熟人來獲取和傳播信息,這就意味著用戶潛在的社交網絡能為用戶選擇提供幫助。信任關系是社會信息中最重要的一種,因為用戶更愿意接受信任用戶的觀點[13]。
基于此,研究者提出以下基于社會信任關系的推薦算法:Ma和Zhou等[14]提出的社會關系規范化的矩陣分解推薦算法(explicit matrix factorization,EMF),通過社會正則化對推薦系統進行社會約束,詳細闡述了社會網絡信息在推薦系統中的應用。Ma等[15]提出的基于評分相似隱含社會信任信息正則化的矩陣分解推薦算法(implicit matrix factorization,IMF),通過用戶評分計算隱含社會信任信息對推薦結果的影響。Yang等[12]提出的基于社會信任關系的協同過濾矩陣分解推薦算法(trust matrix factorization,TMF),通過將信任關系映射到低維特征空間來提高推薦的質量。Zhang等[16]提出的嵌入用戶網絡的社交推薦算法(collaborative user network embedding,CUNE),通過提取可靠的社交信任信息推導相關的前幾個信任朋友納入矩陣分解(MF)框架,從而提高推薦的質量。上述基于社會關系的推薦算法大都依靠明確的社會信任關系。然而明確的社會信任關系非常稀疏[12],缺乏信任傳播,即只是利用直接相關朋友的信任值,未能將信任關系進一步延伸,把朋友的朋友聯系在一起。利用明確的信任關系挖掘非直接信任朋友之間的聯系,既能緩解數據稀疏的問題,又能進一步提高預測評分準確度。
此外,與用戶有過交互的物品,不一定是用戶偏好的物品。例如,用戶現在聽的音樂可能僅僅只是播放器順序播放的音樂。或者,用戶購買某物品作為禮物送給其他用戶,而用戶本身卻不一定喜歡這個物品。因此,在指示用戶與有交互的物品之間應具有不同的置信度。Yang[17]依據目標用戶與其他用戶評分相似來設置置信度的值,進而結合其他相似度計算公式來整體計算相似用戶。Hu等[18]依據與用戶有交互物品的評分值大小設置置信度,進而確定用戶對物品的偏好程度。但上述方法在設置置信度的值時忽略了不同用戶偏好和習慣的差異。
為此,本文中采用一種新的用戶評分偏好置信度計算方法,并且融合拓展后社會信任關系,將朋友的朋友以及更多的相似朋友(即隱語義朋友)聯系起來,提出了嵌入用戶評分偏好置信度的社會化推薦算法(socialized matrix factorization recommendation algorithm with user rating preference confidence,Conf-SMF)。
1 Conf-SMF算法
Hu等[18]提出的 CFI(collaborative filtering for implicit feedback datasets)推薦算法較好地將用戶評分置信度融入矩陣分解算法中,考慮了用戶在給出物品評分大小的置信度,相比于一般的矩陣分解推薦算法能更有效地判斷用戶偏好。本文中提出的Conf-SMF算法主要在CFI算法基礎上進行改進,一是根據用戶評分信息構造出一種新的用戶評分偏好置信度的計算方法;二是引入拓展的社會信任信息隱語義朋友正則化項,約束預測評分,使得到的損失函數值更小。算法流程如圖1所示。
本文中涉及的主要符號及其含義如表1所示。

表1 主要符號及其含義
1.1 用戶評分偏好置信度
用戶對于偏好的物品通常給更高的評分,即在用戶與物品有交互的情況下,評分高的物品就是用戶更加偏好的物品。由此Hu等[18]提出了用戶評分置信度,在用戶與物品有交互的情況下根據用戶不同的評分給予不同的權重,從而預測用戶評分。最小損失函數定義如下:
式(1)分為2部分,第1部分控制著模型的偏差,第2部分為正則化項,控制著模型的方差,以防止過擬合。在第1部分中將Cui賦予統一權重1,再引入1個參數a來確保每個用戶-物品對的置信度隨用戶評分值增大而增大,表示為:
bui為二值函數,將用戶與物品交互信息進行分類,形式如下:
該方法對于推斷用戶偏好有一定的幫助,但是Cui統一設置權值,忽略了用戶之間的差異性。參照加權平均的思想[20],通過對用戶的多次評分取平均可以得到不同用戶的不同評分基準,然后根據不同用戶對同一物品評分比用戶本身評分基準比較不同用戶對該物品的偏好程度,本文中對置信度進行優化。比如用戶A對于物品i較為偏好,評分為4;用戶B同樣偏好物品i,評分卻為5,雖然用戶A與用戶B有著相同的偏好,但是給出的評分不同。然而以用戶A對物品i評分比用戶A的平均評分結果,卻近似等于以用戶B對物品i評分比用戶B的平均評分結果,這樣更有利于推斷不同用戶的評分偏好,便于評分預測。鑒于這種思想,改進后的置信度公式如下:
通過取不同a值對比實驗,發現當a=12時效果最佳,因此在與其他算法進行比較時a的值取12。本文中置信度的計算方法不僅考慮了用戶做出評分的可信度,而且考慮了用戶評分之間的差異,可以比較不同用戶對于同一物品的偏好程度。接下來通過拓展社會信任關系,將目標用戶朋友的朋友聯系在一起,推導出與目標用戶相關的社會隱語義朋友。
1.2 社會隱語義朋友
在生活、工作中,用戶通常通過朋友、同事、伙伴來獲取、傳播消息。明確信任的朋友在較大程度上能夠影響用戶做出選擇[12],而明確的信任關系數據稀疏[14]阻礙了社會化信息在推薦算法中的應用。為拓展社會信任關系,通過Deepwalk[20]深度學習網絡將網絡中的拓撲結構嵌入到一個低維向量中,即在原始網絡中關系緊密節點對應的向量在其空間中距離更近,從而將用戶信任朋友的朋友以及更多的朋友聯系起來,從中挑選出與用戶偏好更相似的Top-k個朋友(即隱語義朋友),其計算流程如圖2所示。
圖2 中 U-I-Net(user item bipartite network)為用戶-物品交互網絡,C-U-Net(collaborative user network)為協作用戶網絡[16]。社會隱語義朋友推導過程為:
首先,獲取協作用戶網絡。如圖3所示,先由用戶-物品交互矩陣映射得到U-I-Net,然后通過單模投影壓縮將 U-I-Net映射到 C-U-Net。U-I-Net是由用戶和物品兩組節點來表示的,兩組節點間的連線表示用戶與物品之間存在交互,即一種用戶-物品反饋,通過這種不同用戶與某一相同物品反饋信息將U-I-Net映射到C-U-Net。在C-U-Net網絡中不僅將相鄰用戶聯系起來,通過傳遞性將非相鄰用戶也聯系在一起。
其次,帶有偏置的隨機游走[21],獲取用戶節點序列生成社會語料庫。隨機游走的用戶節點類似于文本語料庫中單詞頻率的分布,因此將隨機游走中的用戶節點稱為社會語料庫[16],每一次隨機游走都生成一組社會語料庫的節點序列,例如圖4中W1∶1→4→3→2。在C-U-Net上進行帶有偏置的隨機游走是通過對結構信息進行深入的挖掘,使相同節點對于不同的鄰居節點有著不同的嵌入。如圖4所示,使每個變量的選取是從其前任的鄰居節點中加入注意力后選擇的節點。
最后,計算 Top-k個隱語義朋友。Skip-Gram[22]是Word2Vec模型中的一種,原為給定輸入詞向量而預測其上下文出現詞向量的概率。本文中將用戶序列類比為詞向量進而對目標用戶序列進行計算。如圖5所示,通過Skip-Gram模型計算最大化出現在語料庫中特定用戶序列的平均對數概率。Skip-Gram模型學習l嵌入得到E社會語料庫的特征自由參數(v是C-U-Net中所有節點的集合,l是步長),E的每一行表示特定用戶的特征向量。在得到社會語料庫E后,通過余弦相似度公式計算E中每一行與目標用戶特征向量的相似度,提取Top-k個隱語義朋友。
通過Top-k個相似用戶構建相似用戶矩陣,用于目標用戶的評分預測。
1.3 最小損失函數
通過對用戶評分置信度的改進,考慮不同用戶對于同一物品的偏好程度。通過對社會信任關系的拓展得到隱語義朋友,解決明確信任關系稀疏的問題。但是某些用戶與不同偏好的用戶建立社交聯系,直接利用社交關系可能會誤導推薦。例如,用戶1信任用戶3,原因是他們在流行音樂方面有相似偏好,但是他們在其他類型的音樂可能會有不同的偏好。筆者在Hu等[18]算法的基礎上,進一步對式(1)進行改進,首先將原先統一分配權值的置信度改進為能夠計算每個用戶評分偏好的置信度;其次為了減少目標用戶與相似用戶特征項之間的距離(較小的距離表示更相近的偏好),引入了拓展社會信任關系后計算得到的隱語義朋友,作為正則化對預測評分進行約束;最終得到最小損失函數公式:
式中:pf表示用戶 u一個隱語義信任朋友因子向量。
本文中最小損失函數通過Cui歸一化不同用戶評分偏好以及在用戶給出評分時的置信度,對于預測評分的修正不單以用戶、物品正則化還以拓展社會化信任關系的隱語義朋友作為正則化進行修正,使得誤差波動更小,最終得到的損失函數值也更小。
pu、qi數據更新,采用動量梯度隨機下降[19]。當數據量非常大時,每次梯度下降遍歷整個數據集會耗費大量的計算能力,而小批量梯度下降法通過從數據集抽取小批量的數據進行梯度下降解決了這一問題,但是使用小批量梯度法下降過程中會產生左右振蕩的現象,動量梯度下降法通過減小振蕩對算法進行優化。更新過程如下:
式中:ˉH(u)表示其Top-k語義朋友集包含用戶u本身的用戶集;β控制著指數加權平均數,Zhang等[19]通過取不同β值進行實驗,結果顯示當值為0.9時效果最好,結果更加穩定,因此本文中β=0.9;Vdw和 Vdb分別為?C/?pu和?C/?qi加權平均指數,可以將之前梯度下降聯系在一起,目的是使每次的梯度下降不再是獨立的,而是與之前的梯度下降方向有關。本文中采用動量梯度下降法的原因是減少下降過程中因梯度下降折返所損耗的時間,因而使損失函數能夠更快地達到最小值點。
2 實驗與分析
2.1 實驗數據及評估指標
選取3個公開數據集,分別是Film Trust數據集、CiaoDVD數據集以及 Epinions數據集。Film Trust數據集是2011年從Film Trust電影網站抓取下的公開數據集;CiaoDVD數據集是2013年12月從dvd.ciao.co.uk網站上抓取的DVD類別的公開數據集;Epinions數據集是由Paolo Massa 2013年11月在Epinions.com網站上收集的數據集。3個數據集的組成如表2所示。

表2 3個數據集的組成
算法的評價指標采用均方誤差值RMSE(root mean squared error)。均方誤差是一種較常見且較流行的算法評價指標,定義如下:
當預測評分^rui越接近用戶真實評分rui,RMSE值越小。因此,RMSE值越小時就表示算法的預測性能越好。
2.2 用戶評分偏好置信度參數a對實驗結果的影響
式(2)中參數a是對用戶評分偏好的一個加強。當a設置較小時,一方面用戶評分偏好體現度甚微,另一方面對于數據更新、誤差修正影響較小。當a設置較大值時,用戶評分偏好在數據更新中權重太大,因而導致誤差修正步長較大,即難以達到最小誤差點。因此,在Film Trust數據集上進行實驗時,觀察選取訓練數據train=70%、維度d=10時不同a值對RMSE值的影響。實驗時,當a值超過20時誤差較大,因此a值分別取2、4、6、8、10、12、14、16、18、20。實驗結果如圖6所示。
從圖6中可以看出,取不同a值對RMSE的影響關系。當a取值較小時,對計算結果有一定的修正作用,隨著a值的增大,修正結果更加明顯,當a=12時,所得到的RMSE值最小,但當a取更大時函數更新步長增大,因而產生的誤差值增大。根據圖中結果可知,在其他條件不變的情況下,對于不同的取值產生不同誤差結果,只有取到合適的值才能使誤差值取到更小。
2.3 社會隱語義朋友個數k對預測精度的影響
在改進算法中參數k起著重要作用,當k取值較大時,所生成的隱語義朋友關聯程度太低,因此會為模型的訓練引入噪聲;當k取值較小時,由于引入較少的隱語義朋友,所以提取到的信息較少或是有可能提取不到足夠的信息來塑造目標用戶的潛在特征。為了研究參數k對實驗結果的影響,在Film Trust數據集上,選取train=70%,且d=10時不同k值對RMSE值的影響進行實驗,k值分別取 5、10、15、20、25、30。實驗結果如圖 7所示。
由圖7中取不同k值時RMSE的走勢可以看出,最初由于k值較小,所以從隱語義朋友中提取到較少的信息來塑造目標用戶的特征,得到的誤差較大。隨著k值的不斷增大,提取到較多的信息,能夠更好地塑造目標用戶特征,所以產生的誤差越來越小。當k=10時,RMSE最小,但是隨著k值的不斷增大,此時通過算法得到的隱語義朋友與目標用戶相關性降低,從而導致提取到的信息塑造的目標用戶特征產生較大偏差,所以導致RMSE值增大。
2.4 性能對比實驗
比較 Conf-SMF算法與 EMF、IMF、TrustMF、以及CUNE-MF幾種基于社會信任關系的算法。為了能夠進行完整的實驗,根據參考文獻[12,16]中的經驗設置算法中的一些參數。具體參數設置如下:在Skip-Gram中的參數設置為l=20,T=30和τ=5。為了能夠對比實驗的有效性,對于所有的模型潛在特征維度d=5或10。其他參數設置:EMF、IMF、TrustMF、CUNE-MF和 Conf-SMF的正則化參數λ=0.01。社會化約束權重 α,EMF、IMF為0.001,TrustMF、CUNE-MF、Conf-SMF為 0.01。另外,Conf-SMF中用戶評分偏好置信度常數a為12,社會隱語義朋友Top-k為10。實驗中將數據劃分為70%的訓練集和30%的測試集,以及50%的訓練集和50%的測試集。實驗結果如表3所示。
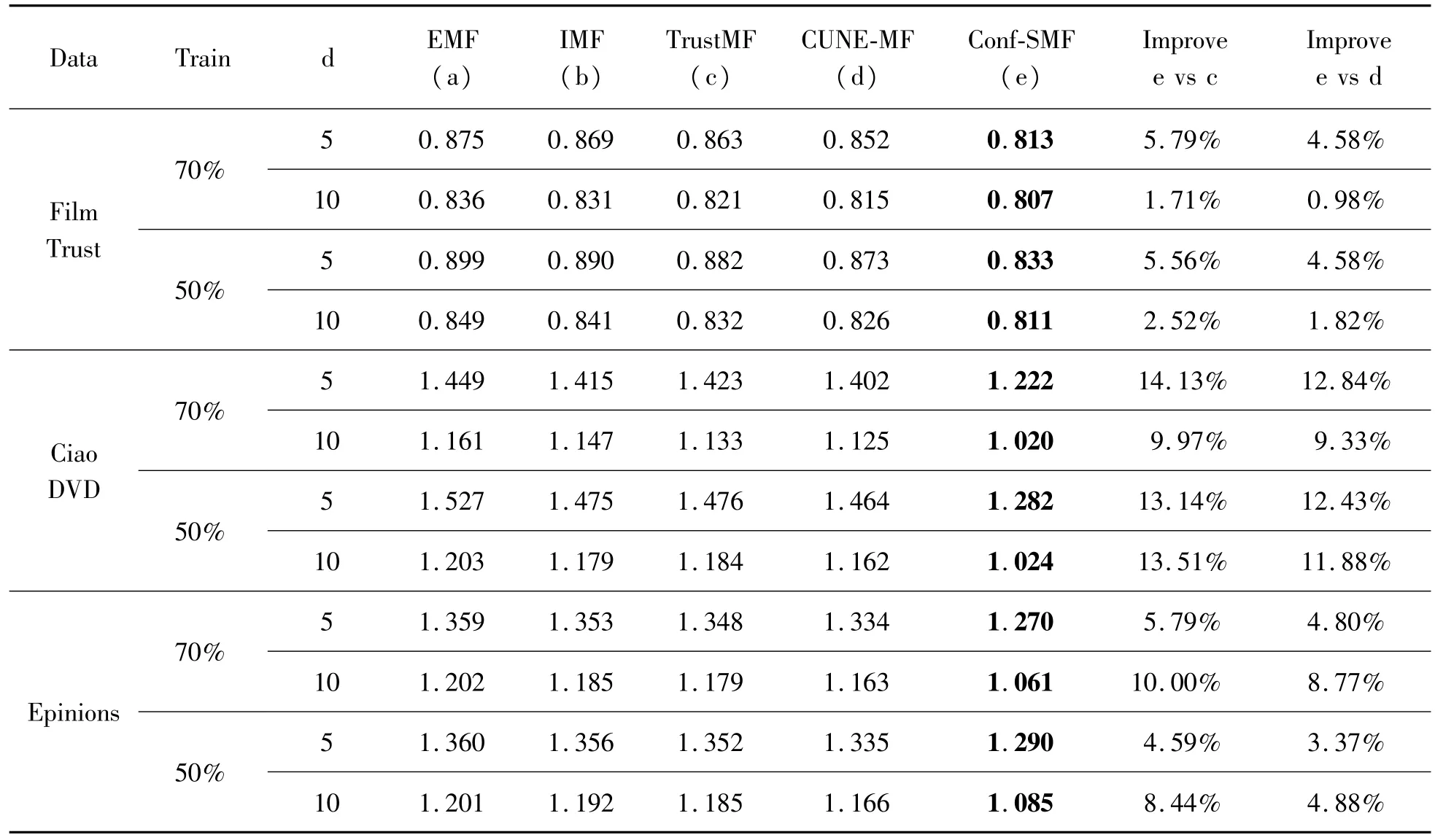
表3 實驗結果
從表3中數據可以看出,Conf-SMF算法預測用戶評分性能表現最佳。在數據集Film Trust、CiaoDVD以及Epinions上,當d=5時的預測平均RMSE得分分別為 0.823、1.252、1.280;當 d=10時的預測平均RMSE得分分別為0.809、1.022、1.073。Conf-SMF的性能優于 EMF、IMF、TrustMF,證明通過帶有用戶評分偏好置信度的社會隱語義朋友正則化擴展矩陣分解的有效性。同時Conf-SMF算法優于CUNE-MF,也驗證加入改進用戶評分偏好置信度以及在該算法生成的用戶的Top-k隱語義朋友能更有效地幫助MF中建立用戶的潛在信任關系。另外,在數據集 Film Trust上將算法Conf-SMF與改進前算法CFI損失函數收斂速度與最低值進行比較,結果如圖8所示。
從圖8中可以觀察到,改進后的Conf-SMF比改進前的CFI損失函數最小值小,并且損失函數達到收斂時所需迭代次數更少,說明改進后算法的有效性。
2.5 Conf-SMF對“冷啟動”及“活躍”用戶預測評分準確性的影響
“冷啟動”用戶即新用戶或有較少反饋信息的用戶[16,23],本文中“冷啟動”主要指反饋數目少于10條的用戶,“活躍用戶”為反饋數目大于40條以上的用戶。明確的社交關系提供的對于解決“冷啟動”用戶推薦幫助信息有限,另外反饋信息多的活躍用戶可能只是與目標用戶部分偏好相似,容易引入潛在的噪音。為驗證改進后的方法對于“冷啟動”用戶推薦和應對活躍用戶建議的有效性,對 Conf-SMF與 EMF、IMF、TrustMF、CUNEMF在不同用戶反饋等級中RMSE的值進行了比較。根據用戶反饋信息數目將維數d為10、訓練數據為70%的Film Trust數據集分為5個等級,分別為:0~10,11~20,21~30,31~40以及40條以上。實驗結果如圖9所示。
由圖9中可以看出,在不同反饋條件下,Conf-SMF算法的均方誤差值均為最小。值得注意的是,改進后的算法在用戶反饋數目為0~10條和40條以上時相比其他算法均方誤差有較大提升。因此,Conf-SMF在解決“冷啟動”和對待“活躍用戶”的建議方面有很大的幫助。
3 結論
1)改進了用戶評分偏好置信度。利用用戶對某一物品評分比該用戶的平均評分,緩減因用戶評分偏好不同而造成的預測誤差,并引入一個參數,使用戶偏好體現更加明顯,從而保證了對不同用戶評分預測的穩定性。
2)引入社會隱語義朋友作為最小損失函數正則項。通過拓展社會信任關系得到隱語義朋友,采用動量隨機梯度下降法進行數據更新,有效降低了評分預測誤差,使損失函數達到最小值。
3)使用公開數據集Film Trust,CiaoDVD以及Epinions分別實驗驗證算法的有效性,實驗結果表明:Conf-SMF算法預測誤差遠小于其他基于社會信任的推薦算法,并且對“冷啟動”用戶和“活躍”用戶預測評分準確度均有提高。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
現代語文(2016年21期)2016-05-25 13:13:44
商用汽車(2016年4期)2016-05-09 01:23:12
大連民族大學學報(2015年2期)2015-02-27 08:28:11
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
創業家(2015年5期)2015-02-27 07:53:25
當代修辭學(2011年6期)2011-01-29 02:49:50
