不同數據預處理對雷達點跡分類的影響
2020-11-27 07:54:34劉鑄華齊永梅劉正成
艦船電子對抗 2020年5期
劉鑄華,齊永梅,劉正成
(中國船舶重工集團公司第七二三研究所,江蘇 揚州 225101)
0 引 言
雷達利用目標回波來獲得目標的信息,從而發現和測定目標。在雷達目標環境中,目標以外的其他散射體的回波稱為雷達雜波。在雷達探測目標時,目標的回波強度可能遠低于這些不期望得到的回波強度,因此當目標處于特別強的雜波環境中時,雷達對目標的檢測難度大大增加[1]。在作戰指揮時,如果態勢中存在大量的虛假航跡,必然會給指揮員的作戰決策帶來嚴重的干擾[2-3]。由于雜波是不可避免的,信號處理和數據處理的一個重要任務就是盡可能地對雜波和雜波產生的疑似點跡進行過濾[4-5]。
人工神經網絡是模擬生物的神經網絡處理信息的系統,其原理為:利用大量的歷史數據,逐層提取數據的特征,尋找數據與標簽的關系,按照舊數據得出的規律提取新數據的特征并進行合理的推斷、分類、預測[6]。2006年,Hinton教授提出,有多個隱層的深度學習神經網絡具有更強的學習能力,這引起了學術界、工業界對深度學習神經網絡的再次探索[7]。深度學習的快速發展,給雷達目標檢測提供了一些新的啟發。在雷達海量大數據背景下,研究基于深度學習的雷達點跡分類方法,輔助過濾雜波點跡,對虛假航跡抑制具有重要意義。
在訓練神經網絡的過程中,通常需要對原始數據進行預處理。在一些實際問題中,我們得到的樣本數據都是多個維度的,即一個樣本是用多個特征來表征的[8]。這些特征的量綱和數值的量級都是不一樣的,如果直接使用原始的數據值,那么每個特征的影響程度將是不一樣的,而通過數據預處理,可以使得不同的特征具有相同的尺度[9]。全連接神經網絡的訓練需要大量的雷達點跡數據,數據預處理在算法中起著重要作用。本文以TensorFlow作為深度學習的基礎框架,搭建全連接神經網絡用于雷達點跡的分類,研究不同數據預處理方法對模型效果的影響。
1 基于全連接神經網絡的雷達點跡分類模型搭建
1.1 數據說明
使用的數據全部采用雷達實測點跡數據,根據劇情對數據中的每個點跡進行標注,雜波標簽為0,目標標簽為1。利用其中大部分數據對模型進行訓練,再留一部分數據用于驗證模型。用于模型訓練的數據集稱為訓練集數據,用于模型驗證的數據稱為驗證集數據。
1.2 雷達點跡數據信息
通過整理,針對點跡數據,本文提取如下幾種信息(包括位置信息、特征信息),具體如表1所示。
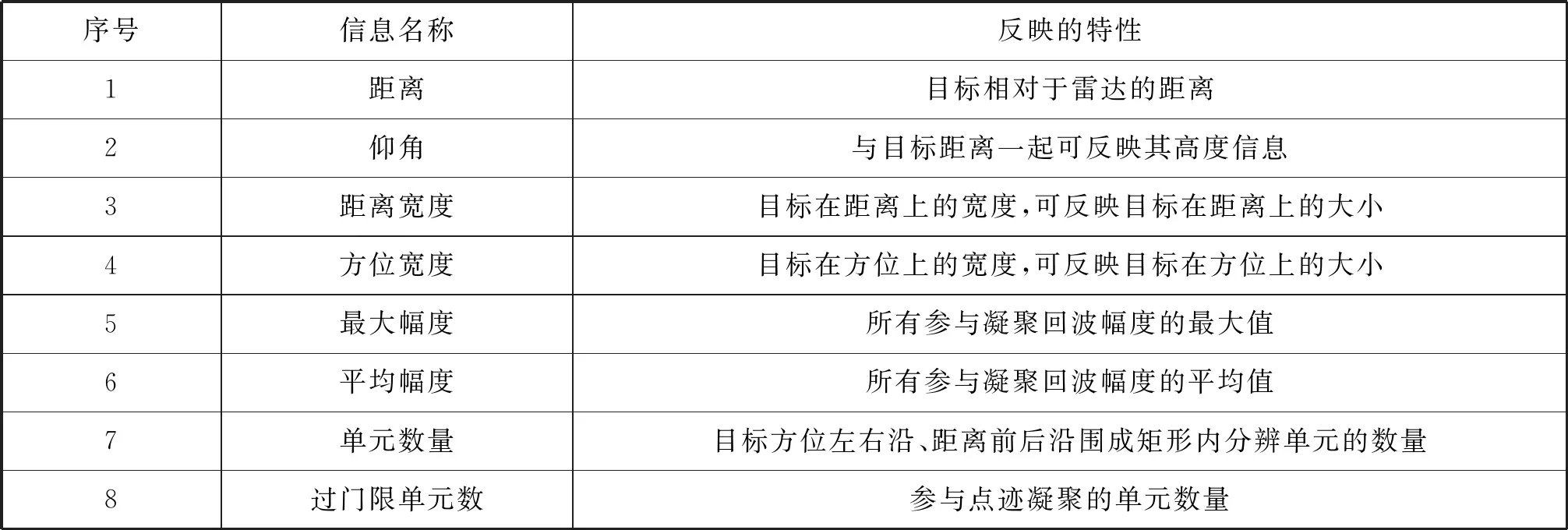
表1 點跡數據信息
1.3 訓練步驟
本文搭建的全連接神經網絡結構如圖1所示。
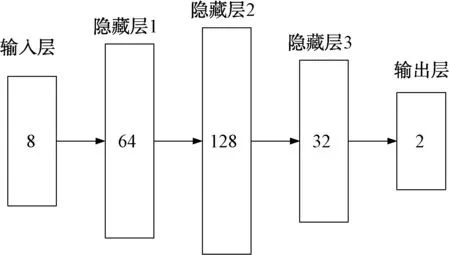
圖1 全連接神經網絡結構
網絡層數為4層,隱藏層節點數分別為64,128,32。作為神經網絡輸入的特征向量直接從點跡文件中獲取,激活函數為ReLU函數,損失函數則為期望輸出與真實輸出的加權交叉熵,加權的目的是盡量降低目標損失率。
網絡訓練步驟如下:
(1) 初始化。初始化訓練次數為0,初始化權重為截斷的正態分布噪聲,標準差設為0.1,初始化偏置為0.1,初始學習速率為0.001,每訓練10輪后學習率乘以衰減系數0.99。
(2) 前向傳播。從訓練數據集中隨機抽取512個特征數據輸入網絡,逐層計算各層網絡的輸出,獲得預測值。
(3) 反向傳播。得到輸出層的真實值后,根據優化損失函數計算真實值與數據標簽的誤差,更新網絡連接權值和偏置量。
(4) 迭代訓練。通過步驟(2)、(3),完成一次訓練,訓練數加1。然后使用當前狀態的網絡對驗證數據集進行分類,得到分類準確率、目標損失率和雜波濾除率。若訓練數大于5 000,停止訓練,否則轉至步驟(2)繼續。
1.4 模型效果評估指標
本文將綜合利用準確率、目標損失率和雜波濾除率對比采用不同數據預處理的全連接神經網絡模型效果。下面對3個模型效果對比指標進行說明。
準確率是一個用于評估分類模型的指標,是指模型預測正確的結果所占的比例,公式如下:
(1)
式中:A為準確率;TP為目標分類正確數;TN為雜波分類正確數;N為樣本總數。
在本文雷達雜波和真實目標分類問題研究中,漏警可能造成很嚴重的損失,也就是說將目標判為雜波的代價要遠高于將雜波判為目標的代價。因此對比模型效果時,目標損失率也是一個重要指標,公式如下:
(2)
式中:γt為目標損失率;FN為目標判為雜波數;TP為目標分類正確數。
在降低目標損失率的同時,要盡量濾除雜波,其公式如下:
(3)
式中:γc為雜波濾除率;TN為雜波分類正確數;FP為雜波判為目標數。
2 常用數據預處理方法
數據預處理是指在構建模型前對原始數據進行的處理。由于不同原始生成的點跡數據之間的數值跨度比較大,為得到高質量的模型學習效果,需要對原始數據進行預處理。最常用的方法有最小值處理、最大最小值處理、0-1標準化以及零均值化方法,處理公式如下:
(1) 最小值處理
X=X/Xmin
(4)
(2) 最大最小值處理
X=(X-Xmin)/(Xmax-Xmin)
(5)
(3) 0-1標準化
(6)
(4) 零均值化
X=X-μ
(7)
式中:X表示所有樣本;Xmax為樣本數據的最大值;Xmin為樣本數據的最小值;μ為樣本數據的均值;σ為樣本數據的標準差。
這些方法都是分別歸一化輸入信息向量的每一個特征值向量,也就是說對輸入樣本空間的每組列向量進行歸一化。
3 最大最小值聯合處理方法
常用數據預處理方法,沒有考慮不同特征參量之間的聯系[10],所以本文提出的最大最小值聯合處理方法,同時對樣本空間的行和列向量都進行最大最小值處理,具體處理公式如下:
(8)
(9)
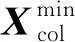
本文雷達點跡分類問題中選擇系數n=2,將輸入點跡特征參數全部歸一化到-1~1。
4 不同數據預處理的實驗對比
本文進行了5種數據預處理的性能對比,在相同的模型參數設置下,得到的實驗結果如表2所示。
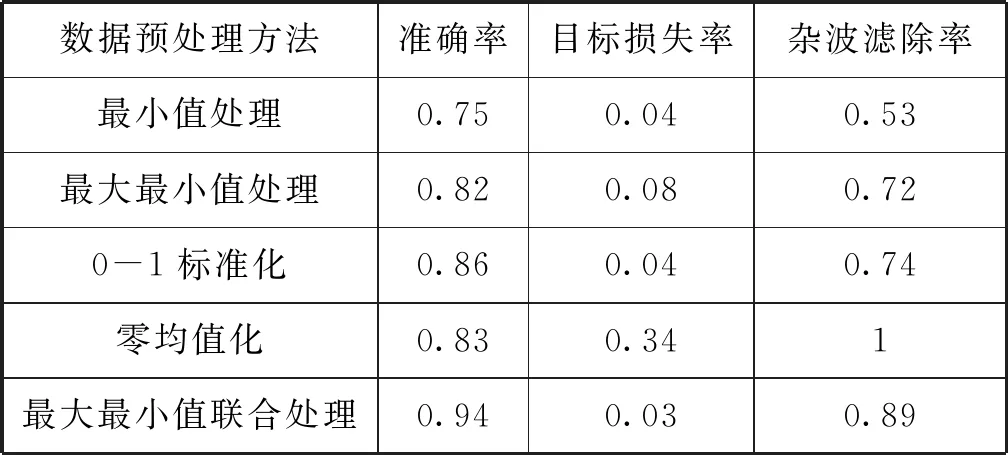
表2 不同數據處理方式對比表
每100次迭代記錄訓練準確率和目標損失率,不同數據處理方式下,準確率和目標損失率隨迭代次數變化對比圖如圖2、圖3所示。
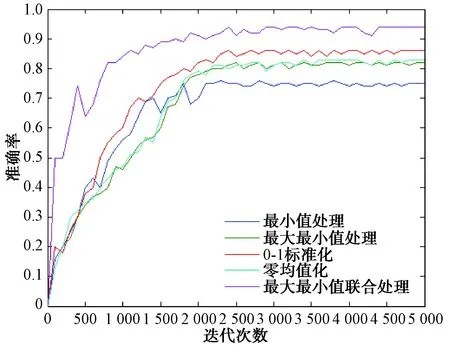
圖2 不同數據處理方式準確率對比圖
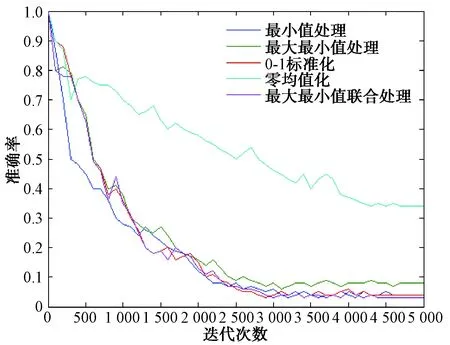
圖3 不同數據處理方式_目標損失率對比圖
結果表明,數據預處理方式不同,產生的訓練效果有明顯的差距,綜合考慮在降低目標損失率的情況下,盡量使準確率和雜波濾除率提高,本文所使用的數據預處理方法使模型分類精度達到94%,相對于常用數據預處理方法分類準確率分別提高19%、12%、8%和11%,同時目標損失率和雜波濾除率相較常用數據預處理方法也達到最小,模型的收斂速度更快。不同于常用數據預處理方法的單一性,本文方法不僅消除了不同特征的量綱和數值差異影響,同時也增加了不同特征參量之間的聯系,使模型有更好的訓練效果,更好地模擬了雷達點跡的數據特性。
5 總結與展望
本文搭建了基于全連接神經網絡的雷達點跡分類模型,選擇合適的模型效果評估指標,研究不同數據預處理方式對模型效果的影響。通過實驗結果可知,不同的預處理方式對模型效果的影響有所不同,本文所用方法相較于常用方法,不僅加快了模型收斂速度,同時也提高了模型分類精度,得出的結論對后續的研究具有很好的指導意義。數據預處理只是模型訓練的第一步,我們還可以研究如何優化、調整模型超參數,使模型最終效果達到最佳。總之,還有很多方面值得去探索。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
