基于連體段的印刷維吾爾文特征提取
2020-11-10 07:52:34賈鈺峰章蓬偉賈園園邵小青劉茂霞
智能計(jì)算機(jī)與應(yīng)用 2020年5期
賈鈺峰,章蓬偉,賈園園,邵小青,劉茂霞
(新疆科技學(xué)院 工商管理系,新疆 庫爾勒841300)
0 引 言
關(guān)于維吾爾文印刷識(shí)別方面,相關(guān)的研究文獻(xiàn)資料較少。 但維吾爾文與阿拉伯文很相似,參考了阿拉伯文及相關(guān)印刷識(shí)別方法[1-2]:典型的識(shí)別系統(tǒng)模塊是由預(yù)處理、特征提取、訓(xùn)練模型、識(shí)別器組成的,如圖1。 由維吾爾文的特點(diǎn)得知:印刷的文字切分不論以筆劃,字母還是詞,切分都是相當(dāng)困難的[3-5]。 同時(shí)還有圖像文本躁點(diǎn)等因素影響,如:粘連,斷裂,偽字母切分等。 基于連體段(WordPart)[3]的段切分是一個(gè)很好的解決方案。 它能夠保留出整體的完備信息,從而為提取良好的特征做準(zhǔn)備。 本文在已經(jīng)預(yù)處理的基礎(chǔ)上,對(duì)連體段提取各類特征。
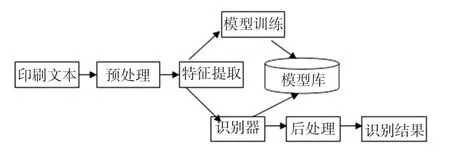
圖1 印刷維吾爾文識(shí)別系統(tǒng)框架Fig. 1 Printed Uighur recognition system framework
1 維吾爾文的特點(diǎn)
維吾爾族的語言屬于阿爾泰語系突厥語族。1938 年形成現(xiàn)行文字,有32 個(gè)字母拼音自右向左橫寫,且有120 多個(gè)字符形式,以詞的形式表達(dá)[6]。其部分特點(diǎn)如下:
(1)維吾爾文字母包括主體部分和附加部分,其中20個(gè)字母有附加部分,它的形式為一“”、兩“”、多“”、以及“”、“”等。附加部分在主體筆劃的內(nèi)部、下面或上面。如:、、、、、等。
(2)維吾爾文的單詞是由多個(gè)或者單個(gè)字母組合而成。 根據(jù)書寫規(guī)則這些字母的組合形成一個(gè)或幾個(gè)前后相連接的音節(jié)或稱連體段。 連體段中的字母,在印刷的時(shí)候總是沿著水平線的,這條水平線被稱為基線。 維吾爾文的結(jié)構(gòu)詳情見圖2。
2 特征提取
特征提取的過程就是將圖像文本映射到文字獨(dú)有的特征空間,以便壓縮信息量,方便后續(xù)的分類、訓(xùn)練和識(shí)別。 本文根據(jù)維吾爾文的特點(diǎn),基于連體段提取出一系列常用特征,并最終建立一個(gè)特征庫以備使用,現(xiàn)將方法介紹如下:
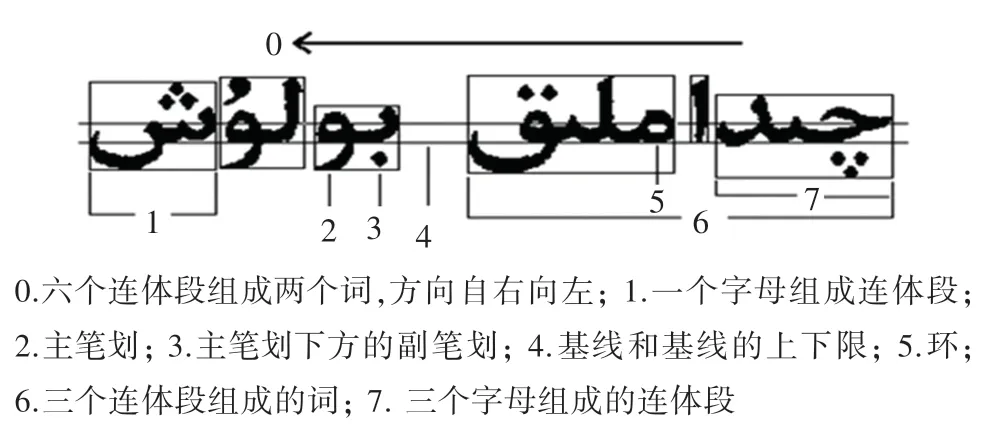
圖2 維吾爾文結(jié)構(gòu)特點(diǎn)說明Fig. 2 Structural features of Uighur
2.1 筆劃位置特征
維吾爾文中連體段由主體部分和附加部分組成。 由圖2 可知附加筆劃在主筆劃的下面、上面或內(nèi)部。 筆劃位置特征就是求出主筆劃,副筆劃個(gè)數(shù),副筆劃與主筆劃的相對(duì)位置關(guān)系。 副筆劃的位置特征可以通過與基線的相對(duì)位置來識(shí)別。 但有些特殊情況無法完美判斷,如與。故介紹一種基于聯(lián)通域的更細(xì)致的判別方法:
選定一點(diǎn)作為一個(gè)種子,由圖像的區(qū)域生長法[7-8]可以求得一個(gè)相同像素相互聯(lián)通的區(qū)域(即筆劃)。 因此根據(jù)種子點(diǎn)就可以知道聯(lián)通域,根據(jù)聯(lián)通域就知道連體段筆劃的數(shù)量。 根據(jù)圖像像素點(diǎn)讀取的順序,位圖行內(nèi)是由左往右,行間由下往上。將二值圖像掃描時(shí)第一個(gè)碰到的黑色像素作為種子,再由區(qū)域生長法生長蔓延出一個(gè)筆劃區(qū)域,得到一個(gè)筆劃。 為了防止重復(fù)計(jì)算筆劃,將已經(jīng)蔓延過的筆劃反色(使筆劃和背景同色)后繼續(xù)循環(huán)尋找下一個(gè)種子點(diǎn),繼續(xù)生長蔓延找到下一個(gè)筆劃,直至圖循環(huán)完畢。 該算法主要步驟:
(1)為了不破壞原圖,復(fù)制初始化為連體段圖像的緩沖區(qū)兩個(gè)(設(shè)為A 和B)。
(2)對(duì)A 圖像域按由左往右,由下往上的方式依次掃描像素點(diǎn)。 碰到黑色像素點(diǎn)就作為種子點(diǎn)記錄下來。
(3)由區(qū)域生長法得出此聯(lián)通域。 在區(qū)域生長同時(shí)統(tǒng)計(jì)黑點(diǎn)的個(gè)數(shù)并記錄黑點(diǎn)的坐標(biāo)(黑點(diǎn)總個(gè)數(shù)為連體段的面積;坐標(biāo)的平均值可以用來判斷筆劃的位置關(guān)系)。
(4)根據(jù)記錄的黑點(diǎn)坐標(biāo),把B 圖像域相同坐標(biāo)處像素值反色(白色)。 此時(shí)B 域就是除去聯(lián)通域剩下的部分。
(5)將B 域的像素值覆蓋掉A 域。
(6)重復(fù)步驟(2),(3),(4),直至循環(huán)完畢。
由此算法可統(tǒng)計(jì)出連體段的聯(lián)通域個(gè)數(shù),即筆劃數(shù);其中面積最大的為主筆劃。 其它筆劃的平均縱坐標(biāo)與主筆劃比較,就可以判斷出副筆劃的上下位置特征。 同理副筆劃之間的平均橫坐標(biāo)可以判斷出副筆劃之間的左右位置特征,而這些特征都是全局精確特征,可以顯著提高識(shí)別分類效果。 連體段筆劃位置特征提取步驟如圖3 所示。

圖3 連體段筆劃位置特征提取步驟Fig. 3 Stroke position feature extraction steps of wordpart
其特征結(jié)果如下:
(1)筆劃數(shù)為8 個(gè)。 面積分別為:15,16,16,815,14,82,14,16。 最大面積即主筆劃面積為:815。
(2)位置特征由下往上依次為:-16,-11,-11,0,-11,13,13,15。 其中0 代表主筆劃;小于0 的共4 個(gè),代表在主筆劃下方;大于0 的共3 個(gè),代表在主筆劃上方。
(3)同時(shí)還可以知道副筆畫之間的位置關(guān)系。
2.2 孔洞數(shù)
連體段孔洞數(shù)也是基于聯(lián)通域個(gè)數(shù)的[7]。 為保證孔洞數(shù)目準(zhǔn)確性,將圖像黑白像素調(diào)換后繼續(xù)遞歸循環(huán)算法對(duì)不是筆劃的區(qū)域進(jìn)行聯(lián)通域個(gè)數(shù)計(jì)算,如圖4 所示,可得到總的不是筆劃的連通區(qū)域個(gè)數(shù),減去和邊界相交的背景區(qū)域,就可以得到連體段孔洞數(shù)數(shù)量這一特征。 這也是全局精確特征。 此特征在后續(xù)使用中發(fā)現(xiàn)非常高效。

圖4 黑色聯(lián)通域共有3 塊 孔洞數(shù)共有2 個(gè)Fig. 4 There are 3 holes in the black connecting area and 2 holes in total figure
2.3 方向碼
方向碼特征是字符識(shí)別中非常經(jīng)典有效的特征,方向碼就是把平面分成八個(gè)方向[9-10],如圖5 所示。 取出主筆劃的輪廓,在輪廓上選取一個(gè)開始點(diǎn)和一個(gè)結(jié)束點(diǎn)作為一個(gè)線段,并判斷這個(gè)線段歸屬于那個(gè)方向,然后用方向序號(hào)標(biāo)識(shí)。 繼續(xù)重復(fù)直至循環(huán)輪廓一周后得到一組方向特征向量,這組向量就是主筆劃的方向碼。 它具有較高穩(wěn)的定性和抗干擾能力,代表主筆劃的形狀特征。 方向碼特征提取過程為:求連體段輪廓,點(diǎn)聚類,直線逼近,得出方向碼。
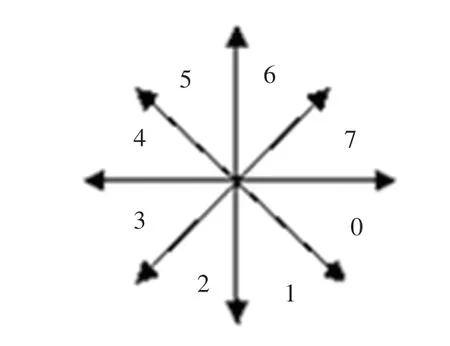
圖5 八方向示意圖Fig. 5 Eight direction schematic diagram
(1)取輪廓。 取輪廓使用邊界跟蹤法,從圖6 得到主筆劃,從主筆劃選取種子點(diǎn),順時(shí)針環(huán)繞主筆劃邊界一周后得到連體段的輪廓[7-11]。

圖6 連體段原始圖像Fig. 6 Original image of wordpart
主筆劃輪廓選取算法如下:
定義初始搜索方向?yàn)樽笊戏?搜索到的第一個(gè)黑色像素作為輪廓種子點(diǎn),找到下一個(gè)黑色像素,記錄邊界點(diǎn)坐標(biāo)和個(gè)數(shù)。 找不到就順時(shí)針旋轉(zhuǎn)45°繼續(xù)尋找直至找到下一個(gè)點(diǎn)。 重復(fù)以上方法直到返回最初起始種子點(diǎn)為止。 輪廓像素點(diǎn)個(gè)數(shù)就是周長特征,坐標(biāo)點(diǎn)就是主筆劃的離散形式。 用此方法取得的輪廓如圖7 所示。

圖7 取出輪廓的連體段Fig. 7 Take out the wordpart of the contour
(2)點(diǎn)聚類。 如隔幾個(gè)像素點(diǎn)取一個(gè)點(diǎn),使輪廓點(diǎn)稀疏。 但點(diǎn)聚類依然不夠簡化。
(3)直線逼近。 在盡量保留拐點(diǎn)、關(guān)鍵點(diǎn)的情況下,仍對(duì)輪廓進(jìn)行進(jìn)一步的簡化采樣,將輪廓變?yōu)楸3衷行螤畹恼劬€,如圖8 所示。
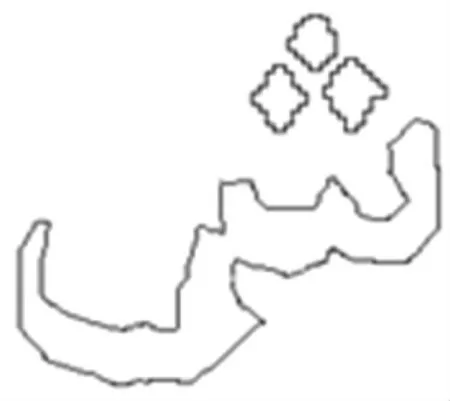
圖8 直線逼近后的連體段Fig. 8 The wordpart after the straight line approximation
在這里我選用了經(jīng)典的Douglas-Peucker 算法[12]實(shí)現(xiàn)直線逼近功能,其算法描述如如圖9 所示。
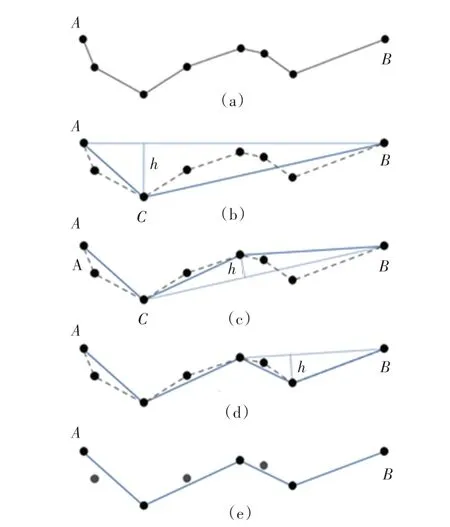
圖9 Douglas-Peucker 算法描述過程Fig. 9 Douglas Peucker algorithm description process
①在曲線AB 之間連接一條線段AB,線段AB 為曲線的弦,如圖9(b)所示。
②求出曲線上離線段AB 距離最遠(yuǎn)的點(diǎn)C,計(jì)算其與線段AB 的距離h。
③若h 小于預(yù)定閾值,則該直線段AB 作為曲線的近似,該段曲線AB 處理完畢。
④若h 大于預(yù)定閾值則,利用距離最遠(yuǎn)的C 點(diǎn)將曲線AB 分為兩段AC 和BC,線段AC 和BC 重復(fù)步驟1 到3,直至處理完畢,如圖9(c)和圖9(d)。
⑤依次連接各個(gè)最終確定的逼近點(diǎn)作為連體段的近似輪廓,完成簡化采樣,如圖9(e)。
(4)得出方向碼。 根據(jù)筆劃骨架中每一段線段歸屬的方向得出方向碼特征向量。
圖8 的方向碼特征向量為(假設(shè)閾值為3,具體根據(jù)字體大小判斷):4,5,5,6,1,0,0,0,7,5,5,6,0,1,0,6,1,7,5,6,0,1,2,3,3,4,2,3,3。 若將每個(gè)方向的個(gè)數(shù)求和,則方向碼向量降維為:6,4,1,3,5,4,2。
2.4 尾點(diǎn)、交叉點(diǎn)
尾點(diǎn)與交交叉點(diǎn)作為細(xì)化后字符識(shí)別提取的常用特征已被廣泛使用[13]。 前人已經(jīng)研究了各種經(jīng)典的細(xì)化算法,經(jīng)過論證,本文采用細(xì)化算法提取此特征,得到了較好的效果[7]。 在細(xì)化后的連體段圖像中,交叉點(diǎn)一般都是在當(dāng)前點(diǎn)的8 鄰域模板中,即以當(dāng)前點(diǎn)p 為中心選擇一個(gè)3×3 的模板來判別其尾點(diǎn)、交叉特征屬性。 計(jì)算P 點(diǎn)的交點(diǎn)數(shù)的公式(1):
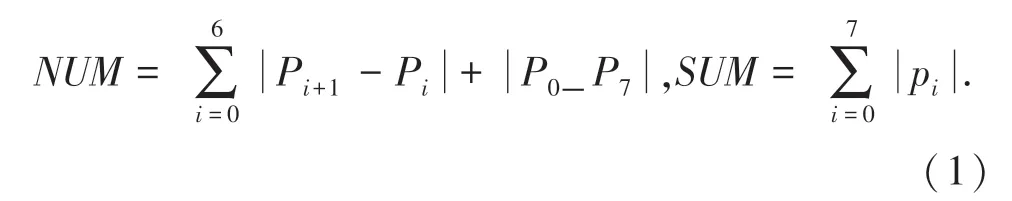
模板如圖10 所示。
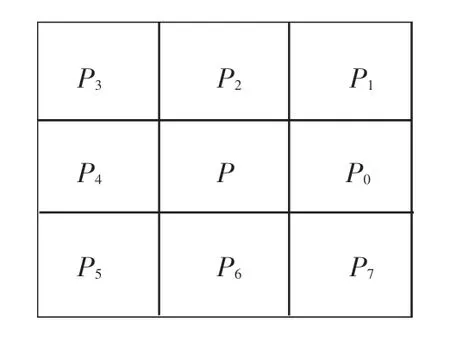
圖10 8 鄰域模板Fig. 10 8 Neighborhood templates
其中, SUM 表示當(dāng)前點(diǎn)8 領(lǐng)域中像素點(diǎn)的個(gè)數(shù)。 NUM 表示當(dāng)前點(diǎn)P 的8 領(lǐng)域模板中像素值的0,1 變化次數(shù)。 由算法可以判定出:
(1) 當(dāng)NUM = 2,SUM = 1 時(shí),P 為尾點(diǎn);
(2) 當(dāng)SUM >3 時(shí)為交叉點(diǎn)。 其中,NUM =6,SUM =3 時(shí),P 為三叉點(diǎn);NUM =8,SUM =4 時(shí),P 為四叉點(diǎn)。
圖11 為圖3 的主筆劃細(xì)化后的情況,共有尾點(diǎn)、三叉以上點(diǎn)各6 個(gè)。
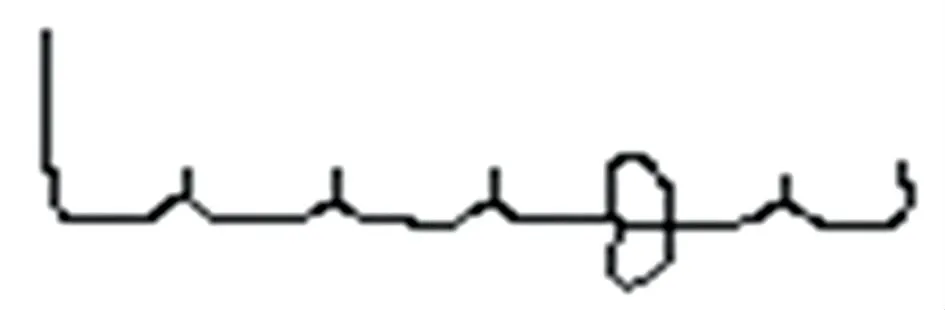
圖11 細(xì)化后的主筆劃Fig. 11 Main stroke after thinning
2.5 前后景比值
前后景比值特征是基于統(tǒng)計(jì),計(jì)算出連體段矩形框中黑像素和與白像素的比值[14]。 這樣提取特征的優(yōu)點(diǎn)在于計(jì)算簡單,不受字符大小的影響,只要字形固定,對(duì)于印刷體就可以作為特征,如圖12 的前后景比值為0.25。 另外,印刷體維吾爾文連體段具有一定的高度和寬度,計(jì)算連體段高寬比特征值,如圖12 寬為60,高為56,寬高比:1.071。 前后景色比值結(jié)合連體段寬高比,可以作為聯(lián)合特征,針對(duì)部分連體段可獲得較高的穩(wěn)定性和抗干擾性。

圖12 連體段的像素模型Fig. 12 Pixel model of wordpart
3 結(jié)束語
本文重點(diǎn)表述了維吾爾文連體段常用特征提取方法。 在分析維吾爾文書寫特點(diǎn)的基礎(chǔ)上提取了如下特征:寬高比,前后景比值,孔洞數(shù),尾點(diǎn),交叉點(diǎn),方向碼,筆劃位置特征。 基于以上方法通過對(duì)四十多對(duì)樣張進(jìn)行批處理,建立起了基于連體段的特征庫圖14 為對(duì)圖13 從右往左提取連體段相關(guān)特征的截圖。

圖13 原始樣張部分截取Fig. 13 Part of the original sample
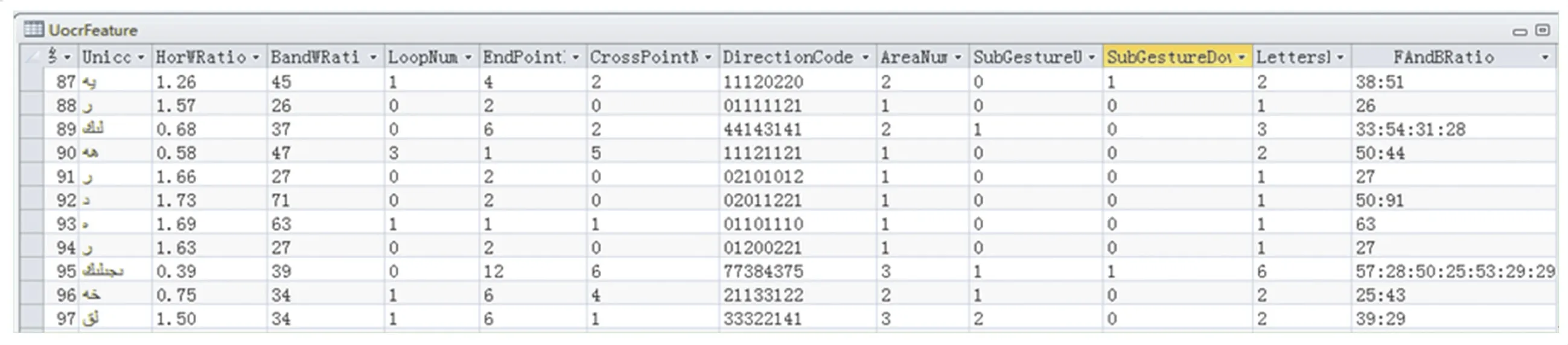
圖14 特征庫截圖Fig. 14 Screenshot of feature library
圖14 為特征庫的截圖:從左往右每一列的特征分別為:連體段Unicode 碼,高寬比,孔洞數(shù),尾點(diǎn)數(shù),交叉點(diǎn)數(shù),壓縮后的8 方向碼,筆劃數(shù),基線上方副筆劃數(shù),基線下方副筆劃數(shù),連體段字母個(gè)數(shù),前后景比值等。
將特征應(yīng)用于維吾爾文字印刷識(shí)別系統(tǒng),由識(shí)別器識(shí)別后證明所采用的算法思想和特征維度是有效的。 但還需要進(jìn)一步完備連體段的有效特征,以便抽取出那些對(duì)不同類別最為重要的特征,組合成良好且優(yōu)秀的特征組合。 后續(xù)還需要研究局部特征和全局特征合并訓(xùn)練的方法,完備字符特征集合,改進(jìn)特征選取準(zhǔn)則函數(shù),結(jié)合分類器的改進(jìn),盡可能的提高識(shí)別率[15]。
猜你喜歡
計(jì)算機(jī)應(yīng)用(2022年2期)2022-03-01 12:33:42
計(jì)算機(jī)應(yīng)用(2021年4期)2021-04-20 14:06:36
計(jì)算機(jī)應(yīng)用(2021年1期)2021-01-21 03:22:38
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
中國生物醫(yī)學(xué)工程學(xué)報(bào)(2017年6期)2017-02-10 05:11:45
小天使·一年級(jí)語數(shù)英綜合(2015年2期)2015-01-14 06:35:05
噪聲與振動(dòng)控制(2015年4期)2015-01-01 07:08:21
