基于問題生成的知識圖譜問答方法
2020-11-10 07:51:30喬振浩車萬翔
智能計算機與應用 2020年5期
喬振浩, 車萬翔, 劉 挺
(哈爾濱工業(yè)大學 計算機科學與技術學院, 哈爾濱150001)
0 引 言
問答系統(tǒng)是自然語言處理的明日之星,已獲得了人工智能及其相關產業(yè)的廣泛關注,并已經在互聯(lián)網、醫(yī)療、金融等領域進行了應用嘗試。 與目前主流資訊檢索技術相比,問答系統(tǒng)有兩點不同:首先,查詢方式為口語化的問句,使用者不需要思考該使用什么樣的問法才能得到理想的答案;其次,查詢結果為高精度的網頁或明確的答案字符串。
問答系統(tǒng)依賴于優(yōu)質的知識。 依據(jù)知識的形式,問答系統(tǒng)可以分為基于文本的問答和基于知識圖譜的問答。 基于文本的問答,知識通常來源于純文本,如百科文本、社區(qū)問答以及網絡文檔等;基于知識圖譜的問答,知識來自以RDF 三元組格式存儲的知識。相比于文本知識,對于事實型問題(when、who、where、which、what),知識圖譜問答較文本問答更為精確和高效,同時也要求知識圖譜規(guī)模足夠大。 語義網絡技術和自動信息處理系統(tǒng)的發(fā)展進步催生了大規(guī)模知識圖譜。 近些年涌現(xiàn)出了大批十億甚至更大規(guī)模的知識圖譜,包括Freebase、DBpedia 等,這些知識圖譜的出現(xiàn)使基于知識圖譜的問答系統(tǒng)變得可行。
由于深度學習技術在自然語言處理領域的大放異彩,目前很多知識圖譜問答系統(tǒng)都是基于各種深度學習模型進行構建,訓練深度學習模型需要大量的標注數(shù)據(jù)[1]。 然而在實際應用中,往往只能獲取到知識圖譜而缺乏標注數(shù)據(jù),造成這種困境的原因是相比于構建知識圖譜,構造標注數(shù)據(jù)的成本更高。知識圖譜以三元組形式組織,其構建過程并不需要數(shù)據(jù)庫專業(yè)知識,當應用場景明確且規(guī)模適當時,針對特定應用場景抽取三元組即可完成知識圖譜的構建。 標注數(shù)據(jù)由自然語言問句與對應邏輯表達式構成。 自然語言問句需要覆蓋大部分的知識庫三元組,并且要兼顧表達多樣性的需求。 問句對應的邏輯表達式則需要具有專業(yè)知識才能寫出,需要專業(yè)人士的參與,獲取成本較高。
針對上述問題,本文提出一種基于問句生成的知識圖譜問答方法。 該方法通過模版將知識圖譜三元組轉換為問句形式,并為生成的問句建立全文索引。 當用戶查詢時,系統(tǒng)首先通過全文檢索引擎檢索出候選集合,然后通過語義匹配模型為候選集合打分,挑選出得分最高的候選項,最后把候選項對應的三元組作為答案返回給用戶,完成問答操作。 通過這種方式,可以在缺少標注數(shù)據(jù)集的情況下,快速開發(fā)出可用的知識庫問答系統(tǒng)。 經過實驗分析,在無標注數(shù)據(jù)的情況下,本文的提出的模型相比于深度模型有更好的可用性,有助于知識圖譜問答系統(tǒng)的推廣應用。
1 模版定義
模版是將知識庫三元組轉換為自然語言表達的工具。 給定由三元組(實體1,關系,實體2)組成的知識圖譜,為一個關系或語義相近的一組關系編寫一套模版,模版中包含預留實體槽位的自然語言問句。 問句生成時,處理程序依次讀入三元組,將三元組解析為(實體1、關系、實體2)的形式,從模版庫中選取該關系下的全部模版,使用相應實體替換問句中的實體槽位,生成出自然語言形式的句子,生成出的自然語言語句與三元組保持一一對應的關系。以哈爾濱工業(yè)大學信息問答為例,以下為JSON 格式模版的實例:"創(chuàng)辦時間": {
"alias": ["創(chuàng)辦時間"],
"templates": [
" $1 是什么時候創(chuàng)辦的?",
" $1 建校時間",
" $1 成立于哪一年?",
" $1 創(chuàng)辦時間?",
" $1 建校于哪一年?",
]
}
該JSON 格式的文本中,JSON 鍵值“創(chuàng)辦時間”對應了知識圖譜三元組中的關系。 JSON 值域中,“alias”代表共享該模版的三元組關系名,凡是包含此類關系的三元組都會通過這條模版進行擴展。“templates”為具體的模版。 模版中$1、 $2 分別代表了實體1 和實體2。 擴展時,程序依次讀入的三元組,將三元組解析為實體1、關系、實體2 的形式。程序從模版庫中選取該關系下的全部模版,使用相應實體替換$1、$2 符號,生成問句。 例如:對于三元組“<哈爾濱工業(yè)大學><創(chuàng)辦時間><1920 年>”將被擴展為“哈爾濱工業(yè)大學是什么時候創(chuàng)辦的?”、“哈爾濱工業(yè)大學建校時間”、“ 哈爾濱工業(yè)大學成立于哪一年?”、“哈爾濱工業(yè)大學創(chuàng)辦時間?”、“哈爾濱工業(yè)大學建校于哪一年?”五句語義信息完整的句子。
下面介紹兩種模版構造的方法:
(1)從數(shù)據(jù)集中抽取模版。 公開的開放域知識庫數(shù)據(jù)集中包含了豐富的自然語言表達和對應的邏輯表達式。 通過替換自然語言問句中的實體為特殊標簽$1,并根據(jù)關系名稱進行聚類,就可以獲得豐富的模版表達。
(2)手工構造模版。 開放域知識庫問答數(shù)據(jù)集覆蓋的范圍較廣,但對具體的場景無法全面覆蓋。因此,除了從數(shù)據(jù)集中抽取模版外,還需通過手工構造模版的方式,來提高模版精度,保證大部分的三元組數(shù)據(jù)都有較好的覆蓋,并滿足問句多樣性的要求。若知識庫問答的場景比較新穎,例如:高校信息問答、新冠肺炎知識問答,則主要依賴這種方法。
2 候選集檢索與語義匹配
將三元組轉換為自然語言問句形式后,當用戶輸入查詢時,只需從生成的句子中選擇出最相關的句子并返回對應的三元組即可完成問答操作。 通過這種方式,實際上是將知識庫問答問題轉換為了FAQ 問題。 由于使用模版生成問句時存在排列組合問題,生成的自然語言問句規(guī)模比較龐大。 為了有效地檢索出與用戶問句相關的句子,首先采用基于全文檢索的檢索方法進行粗匹配,縮小候選答案的范圍,然后使用基于語義匹配的方式進行細匹配,在語義層面挑選出最佳答案。
2.1 基于全文檢索的檢索算法
本方法首先使用基于全文檢索的檢索方式來檢索得到候選關系集。 在信息檢索系統(tǒng)中,文本數(shù)據(jù)按照存儲方式可以分為結構化數(shù)據(jù)和非結構數(shù)據(jù)。結構化數(shù)據(jù)是指具有明確格式,定義清晰的有限長度數(shù)據(jù),如數(shù)據(jù)庫、XML 數(shù)據(jù)。 對結構化數(shù)據(jù)檢索時,由于其數(shù)據(jù)格式定義明確,可以使用規(guī)范的查詢語句,如SQL 語句進行查詢。 非結構數(shù)據(jù)又稱為全文數(shù)據(jù),通常具有長度不固定,格式不統(tǒng)一的特點。對此類數(shù)據(jù)檢索最樸素的方式是順序掃描法,查找時將關鍵詞與全部文本逐個進行對照,直至遍歷完全部文檔。 當處理小數(shù)據(jù)量文本時,這種方法簡單而有效。 對于大量的文本順序掃描的時間復雜度非常高,需要采用更加高效的方法。 全文檢索的基本原理是從非結構的文本中提取出關鍵信息,并按照一定規(guī)則重新排列為結構化的形式存儲,這些提取出的結構化信息稱之為索引。 檢索時根據(jù)這些結構化的索引進行檢索,從而達到加速的目的。 這種先建立結構化信息索引,再通過索引加速搜索的過程就稱為全文檢索。 全文檢索應用時分為建立索引和查找索引兩個部分:建立索引負責預處理待檢索的文本,根據(jù)詞法知識對待檢索文本進行解析后創(chuàng)建索引;查找索引將用戶查詢文本進行同樣的詞法預處理后,檢索已創(chuàng)建的索引并返回給用戶查詢結果。
建立索引時第一步是通過分詞組件將文本處理為有意義的獨立詞元(Token)。 這個過程需要將文檔分為一個個單詞的形式。 由于中文文本中字與字之間沒有分割符,需要借助外部分詞工具進行處理,常用的中文分詞工具有LTP 平臺,THULAC 分詞等。 而對于英文文本,直接使用空格符號進行分割即可,然后去除分詞結果中的標點符號,通常使用正則匹配的方法即可完成,最后去除停用詞,停用詞在文本中會大量出現(xiàn)并且沒有實際的含義,會干擾正常的搜索。
第二步處理中,通過語言處理組件將第一步得到的詞元進行自然語言相關處理。 以英文為例,處理包括:1)大小寫轉換;2)單詞縮減為詞根形式,例如:將“games”改寫為“game”;3)單詞替換為詞根形式,如:將“played”替換為“play”。 處理后得到的結果稱為詞(Term)。 經過分詞組件處理后,使用得到的Term 創(chuàng)建倒排索引。 倒排索引由全部不重復的詞構成,每一個詞都對應了一個包含該詞的全部文檔列表。
使用倒排索引技術檢索出的結果從眾多文檔中篩選出了與用戶查詢有相同詞匯的候選文檔,然而這些候選項只能保證與查詢句是相關的,而無法定量地確定與問句的相關程度。 為了準確地反應出候選文檔與問句的相關程度,使用TF-IDF(Term Frequency-Inverse Document Frequency,詞頻-逆文檔頻率)對檢索出的結果項進行相關度排序。 TF-IDF 是用來估計單詞在文檔庫中的重要程度的指標,單詞的重要程度與它在文檔中出現(xiàn)的次數(shù)成正比,但同時又會與它在整個文檔庫中出現(xiàn)的頻率成反比[2]。
詞頻代表了一個詞在某篇文檔中出現(xiàn)的頻率。在一篇文檔中,一個詞出現(xiàn)的次數(shù)越多,說明這個詞對于這篇文檔的重要程度越高,越能代表這篇文檔。然而僅憑詞數(shù)來衡量重要程度會出現(xiàn)不相關的長文檔得分遠高于精煉的短文檔得分的問題。 詞頻是詞數(shù)進行歸一化后得到指標,能夠無偏地反映詞的重要程度。 對于某一文檔m 中的詞語i, 其詞頻計算方式如式(1):
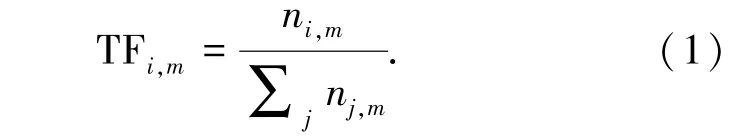
其中,ni,m是詞i 在文檔m 中出現(xiàn)的次數(shù),分母是文檔m 中全部單詞計數(shù)之和。 逆文檔頻率代表了詞的普遍性程度。 越多的文檔包含該詞,說明這個詞越普遍,不足以區(qū)分這些文檔。 對某一特定詞語i,其IDF 值由文檔總數(shù)除以包含該詞的文檔數(shù)目,再將結果取對數(shù)得到式(2):


由該公式可以看到,TF-IDF 值平衡了一個單詞在某一特定文檔和全部文檔出現(xiàn)頻率的關系,使重要的詞語得分高于常見的詞語。 計算出句子中每個詞的TF-IDF 值后,按順序排列,得到了該句子的向量。 通過計算查詢向量Vq與候選項向量Vd的余弦相似度,就可以判斷查詢與候選句之間的相似性,公式(4):

本方法在開源的全文檢索軟件庫Lucene 上進行二次開發(fā)。 Lucene 是由Apache 軟件基金會支持的一套用于全文檢索的開源程序庫,提供了強大且易用的應用程序接口。 Lucene 是目前最廣泛使用的免費全文檢索程序庫。
2.2 語義匹配方法
通過檢索模塊召回的候選問句只保證了字符級別的重合,為了保證問答效果,需要進一步進行語義級別的匹配,使用預訓練模型BERT 進行語義匹配。預訓練語言模型是近年來NLP 領域最激動人心的進展,包括ELMo、ULMFiT 及BERT 等。 這些預訓練模型可以顯著改善下游任務的表現(xiàn),讓NLP 領域進入了預訓練模型的“新時代”。 可以從海量無標注數(shù)據(jù)中學習到潛在的深層語義信息,并且可以通過微調的方式將這些知識遷移到下游任務中,不再需要大量單獨標注額外的訓練數(shù)據(jù)。 下面介紹BERT的原理及其在語義匹配任務上的微調方法。
BERT(Biderectional Encoder Representations)是基于多層雙向Transformer 的深度雙向語言模型[3]。相較于傳統(tǒng)的RNN 類循環(huán)神經網絡,Transformer 有更好的并行運算性能。 BERT 使用掩碼語言模型進行訓練,這種雙向預訓練方式相比于ELMo 等使用單向的模型,可以更好地學習上下文信息。 同時,BERT 還使用了下一句預測任務,模型需要根據(jù)上下文信息預測兩句是否為連續(xù)的,該任務使模型具有處理句子的能力。
具體來說,在MLM 掩碼語言模型中,BERT 會隨機將15%Token 替換為[MASK]標簽。 模型需要根據(jù)被替換位置的隱層向量來預測該詞。 盡管這種方法可以完成雙向預訓練模型的訓練,然而這種方法有兩個缺點。 第一是預訓練過程和微調過程不匹配。 在微調時,[MASK]標簽并不會出現(xiàn)。 為了緩解這種情況,在挑選出15%Token 后,80%的情況下用[MASK]進行替換,10%的情況隨機替換為其他詞,10%的情況下保持不變。 這樣做的目的是使模型適應微調階段的情況;第二是在預訓練過程中,輸入模型的一個Batch 中只預測15%的Token,會導致訓練效率降低,耗費更多時間。 不過BERT 在眾多任務上出色的指標提升說明了雖然模型的收斂速度不如傳統(tǒng)的從左到右的語言模型,但模型帶來的性能提升遠遠大于增加的時間成本。
此外BERT 的訓練還包括下句預測的二分類任務,從而賦予模型處理句子級別輸入的能力。 下句分類的目標是判斷輸入模型的兩個句子是否連續(xù),即判斷兩句是否具有相同或相近的語義表達。 該任務的輸入可以從任意的單語語料庫中生成,具體來說,挑選出句子A 后,預處理程序以50%的概率選擇句子A的下一句話作為句子B,50%的情況下從預料庫中隨機選取任意一句話作為句子B。 本文的語義匹配步驟正是依賴于BERT 模型的句對分類的能力。
由上述兩個任務可以很自然地推測出BERT 的輸入為單個句子或是句子對。 對于文本中的每一個詞,其輸入表示為詞嵌入、段嵌入和位置向量的和。詞嵌入使用了WordPiece 技術,將一個單詞拆分為更小的單位,這樣同一詞根不同形式(如時態(tài)變化)的單詞將共享部分相同的表示,縮小了詞表大小,有益于模型收斂。 段嵌入向量中只包含0、1 兩個值,該向量是為了區(qū)分句對而設置的。 由于Transformer編碼器在輸入文本上并行計算,遺失了單詞的位置信息,故使用位置向量來補充位置信息。 此外,BERT 模型的輸入中還定義了兩個特殊符號[CLS]與[SEP]。 [CLS]符號位于輸入的起始位置,在進行句子級別的分類任務時,可以使用該符號對應的向量進行預測。 [SEP]符號用于分隔輸入的兩個句子,與位置向量配合使用。
Google 提供的預訓練模型與本文要完成的語義匹配任務仍有一些差距,需要經過微調操作把BERT從海量數(shù)據(jù)中學習到知識遷移到目標領域。 對于句子級別的匹配任務,微調時將輸入“[CLS]”所對應的最后一層隱層向量V ∈RH,經過一層線性變換后送入 softmax 函 數(shù), 計 算 類 別 得 分 即: P =softmax ( V*WT) ,式中W ∈RK×H,P ∈RK,K 為分類器標簽數(shù)目。 在語義匹配任務中,K 取2。 使用LCQMC 數(shù)據(jù)集與生成的問句進行微調。 LCQMC 是中文口語話描述的語義匹配數(shù)據(jù)集,該數(shù)據(jù)集定位與本文的任務比較相符。 但是該數(shù)據(jù)集面向領域為開放域問答,問句類型與限定領域問答仍有一定差距。因此本文使用模版生成的問句做了一組微調數(shù)據(jù):將生成的問句兩兩拼接為句對,由同一關系生成的句子標注為正例,不同關系生成的句子標注為負例。 語義匹配模型在這兩個數(shù)據(jù)集上進行微調,微調網絡結構如圖1 所示。

圖1 BERT 微調Fig. 1 BERT fine-tuning
本文提出了一種無標注數(shù)據(jù)下快速構建知識圖譜問答系統(tǒng)的方法。 該方法首先針對知識圖譜的應用場景編寫模版文件。 模版文件結構簡單,不需要編寫者掌握專業(yè)的知識。 模版以自然語言形式組織,只需標注者具有應用場景的基本常識即可,標注成本極低。 經程序使用知識圖譜三元組填充模版后,可以得到具有完整語義信息的問句表達,使用檢索工具包Lucene 為生成的問句建立全文索引。 當用戶輸入查詢時,系統(tǒng)首先使用全文檢索引擎檢索出相關的問句,然后使用預訓練模型為候選項打分。這樣既保證了檢索的速度,又保證了檢索結果與查詢句語義層面相匹配。 最后,系統(tǒng)返回語義匹配模塊得分最高項對應的三元組就完成了整個問答操作。 本文所提出的方法最大的優(yōu)點就是不需要標注數(shù)據(jù),編寫模版的人工成本很低,并且充分發(fā)揮了預訓練模型的語義匹配能力,有效地提升問答效果。系統(tǒng)流程示意圖如圖2 所示。
3 評價指標與實驗結果
3.1 實驗數(shù)據(jù)集的構造
本文提出了一種限定領域下無標注數(shù)據(jù)的知識圖譜問答方法。 對于無標注數(shù)據(jù)場景下的系統(tǒng)評價采用自行構建測試數(shù)據(jù)的方法進行。 首先,人工構建了面向哈爾濱工業(yè)大學百年校慶知識問答的知識圖譜數(shù)據(jù),該知識圖譜包含哈爾濱工業(yè)大學基本信息、院系專業(yè)、長江學者等4 個領域,共2922 組三元組數(shù)據(jù)。 然后通過在線文檔的方式收集并標注了250 組標注數(shù)據(jù),標注數(shù)據(jù)包含問句與對應的答案。

圖2 系統(tǒng)流程示意圖Fig. 2 System flow diagram
3.2 評價指標
基于知識圖譜的問答系統(tǒng)使用宏觀準確率P(Macro Precision)與宏觀召回率R(Macro Recall)以及Averaged F1 值對模型性能進行評價。 設Q 為問題集合,Ai為問答系統(tǒng)對第i 個問題給出的答案集合,Gi為第i 個問題的標注答案集合,這3 個指標的定義如公式(5)~公式(7):

3.3 實驗結果與分析
使用基于語義圖的深度學習模型作為實驗的baseline。 該模型通過建模語義圖的方式將自然語言問句映射為SPARQL 語句。 實驗結果如表1 所示。表1 顯示了本文提出的方法與深度模型在此數(shù)據(jù)集上的效果的對比情況。 從F1 值上可以看到基于問句生成的知識圖譜問答方法相比于深度學習模型有顯著的提高。 這是由于深度模型需要大量的訓練樣本,在無標注、少量標注數(shù)據(jù)情況下很難奏效,而本文提出的方法克服了這一缺點,無需標注數(shù)據(jù)也可以取得較好的效果。 進一步補充了消融實驗,消融實驗的結果顯示了兩種微調數(shù)據(jù)給模型帶來的效果提升。 在LCQMC 數(shù)據(jù)集上進行微調給模型帶來了小幅度的提升,而使用生成的問句進行微調對模型影響較大。 這說明了兩個問題:預訓練模型確實有助于下游任務的表現(xiàn);微調時,需要選擇與下游任務緊密結合的數(shù)據(jù)。

表1 實驗結果Tab. 1 Experimental results %
4 結束語
基于知識圖譜的問答系統(tǒng)由于其準確、便捷的知識獲取能力受到了學術界和工業(yè)界的關注和重視。然而目前主流的深度學習技術需要成本昂貴的人工標注數(shù)據(jù)驅動,妨礙了知識圖譜問答系統(tǒng)的應用。 針對這一問題,本文提出了基于問句生成的知識圖譜問答方法,該方法充分利用了文本檢索技術與預訓練語義匹配模型,只需針對知識圖譜編寫簡單的模板文件即可構造問答系統(tǒng)。 實驗結果表明,該方法在無標注數(shù)據(jù)的限定領域內具有良好的問答效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
