譚康裕 趙元成
摘 ?要:目的:直觀顯示新型冠狀病毒(2019-nCoV)肺炎疫情的發(fā)展趨勢,為復(fù)工復(fù)產(chǎn)的決策提供決策依據(jù)。方法:基于Python語言、使用requests庫下載網(wǎng)頁,使用re讀取目標數(shù)據(jù),使用csv存儲目標數(shù)據(jù)、使用pyecharts展示疫情地圖分布和疫情發(fā)展趨勢圖、使用Javascript腳本顯示趨勢圖,包括疫情的地圖分布,全國疫情新增趨勢,全國累計/疑似趨勢,全國累計治愈/死亡趨勢,全國各省疫情概覽表等。結(jié)果:得到疫情發(fā)展趨勢的可視化圖表,可以直觀顯示疫情的發(fā)展趨勢,全國各省疫情概覽表等。我們可以看到,疫情已經(jīng)趨于平穩(wěn)。結(jié)論:2019-nCoV肺炎疫情的防控措施是有效的,各地方政府嚴格執(zhí)行公共安全政策,保證了人民的生命安全,全力遏制了2019-nCoV的傳播,奪取了戰(zhàn)“疫”的最終勝利。
關(guān)鍵詞:新型冠狀病毒;Python;數(shù)據(jù)可視化;趨勢
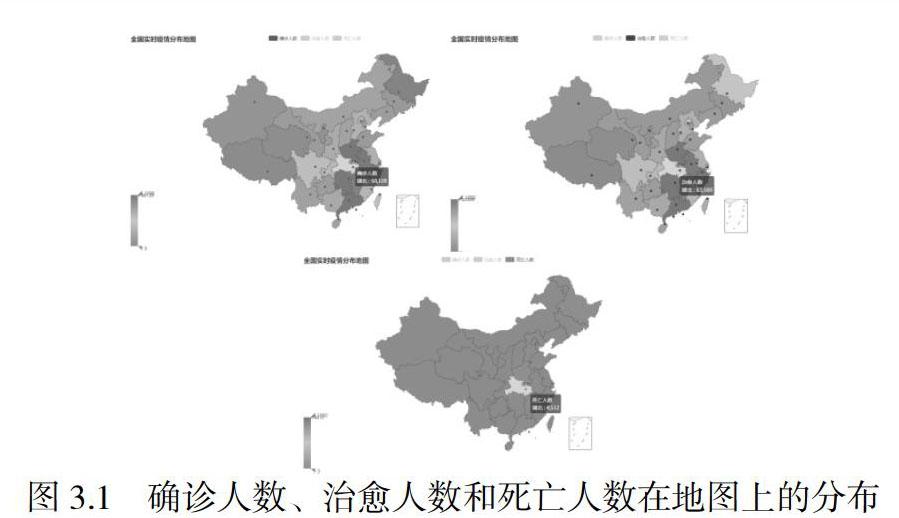
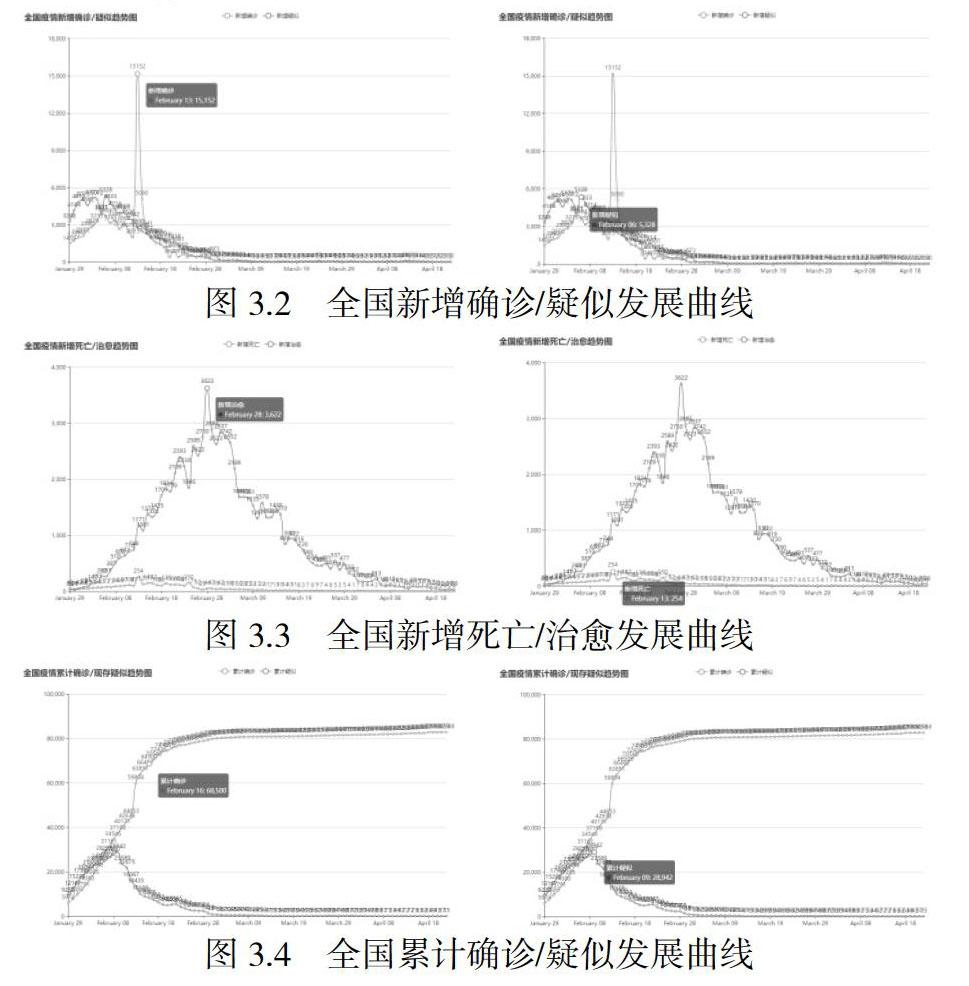
新型冠狀病毒(2019-nCoV)是一種β屬的冠狀病毒,自2019年12月在湖北省武漢市發(fā)現(xiàn) 2019-nCoV以來,疫情快速蔓延[1]。國家衛(wèi)生健康委員會疫情通報顯示,截至 2020年4月25日早上9點,累計確診人數(shù) 82816人,累計治愈出院病例77346例,累計死亡病例4632例[2]。為快速抑制病情蔓延,國家已出臺多種舉措,如延長春節(jié)假期、企業(yè)延遲復(fù)工、學(xué)校延期開學(xué)、限制出行、公共場所要佩戴口罩,居家隔離等。本文基于Python,通過網(wǎng)絡(luò)爬蟲技術(shù)收集2019-nCoV疫情數(shù)據(jù),通過數(shù)據(jù)可視化手段,給出疫情的地圖分布,全國疫情新增趨勢,全國累計/疑似趨勢,全國累計治愈/死亡趨勢,全國實時疫情概覽表等。
1 對象與方法
1.1 數(shù)據(jù)來源
本文疫情發(fā)展數(shù)據(jù)取自中國疾病預(yù)防控制中心周報(以下簡稱中國疾控中心周報)和丁香園,其地址參看“參考文獻”中的[2]和[3]。隨著2019-nCoV的快速傳播,自1月25日開始,各地紛紛啟動“重大突發(fā)公共衛(wèi)生事件Ⅰ級響應(yīng)”,因此我們認定從1月25 日開始,病毒即進入傳播狀態(tài)。由于數(shù)據(jù)是從中國疾病預(yù)防控制中心周報中讀取,比較完整的數(shù)據(jù)是從1月29日開始,因此,本次采集的數(shù)據(jù)就是從1月29日開始,直至4月25日零點。
1.2 疫情數(shù)據(jù)提取的需求
設(shè)計疫情數(shù)據(jù)提取的代碼要解決的以下幾個問題:
(1)下載網(wǎng)頁:根據(jù)給定的URL下載其HTML網(wǎng)頁。
(2)網(wǎng)頁解析:根據(jù)網(wǎng)頁結(jié)構(gòu)信息,提取網(wǎng)頁數(shù)據(jù)。
(3)數(shù)據(jù)存儲:把從網(wǎng)頁中解析出來的數(shù)據(jù)CSV文件中。
1.3 疫情數(shù)據(jù)提取的實現(xiàn)方法
(1)HTML下載器
本次設(shè)計使用requests庫和requests-html庫來下載網(wǎng)頁,分別使用requests來下載中國疾病預(yù)防控制中心周報的數(shù)據(jù),使用requests-html來下載丁香園的數(shù)據(jù)。使用requests-html下載網(wǎng)頁的核心代碼如下所示:
import requests
url = 'http://weekly.chinacdc.cn/news/TrackingtheEpidemic.htm'
r = requests.get(url) #下載網(wǎng)頁
使用requests-html下載網(wǎng)頁的核心代碼如下所示:
from requests_html import HTMLSession
dxyurl = 'https://3g.dxy.cn/newh5/view/pneumonia'
response = HTMLSession.get(dxyurl) ?#下載網(wǎng)頁
(2)HTML解析器
Python使用BeautifulSoup來進行HTML的解析,提取目標數(shù)據(jù)。在中國控制中心周報中,我們使用BeautifulSoup直接讀取其注釋部分,而不是按行讀取目標數(shù)據(jù)所在的XPath。在中國控制中心周報網(wǎng)頁中,目標文本是位于標簽
中的注釋文本。通過分析中國控制中心周報網(wǎng)頁數(shù)據(jù)結(jié)構(gòu),我們可以通過分割標簽,同時為了數(shù)據(jù)的提取,還要把標簽添加回原來的數(shù)據(jù)項中。提取數(shù)據(jù)的代碼如下:
soup = BeautifulSoup(page,'html.parser')
content = soup.find_all("div",'box-article-content') #數(shù)據(jù)返回為列表
content_to_string = str(content) #將列表轉(zhuǎn)換成字符串,使用正則表達式提取
pattern = re.compile(r"<!--(.*?)-->") # 抽取<!--(.*?)-->中間的文本
通過構(gòu)建正則表達式,提取網(wǎng)頁中的疫情數(shù)據(jù)。提取的疫情數(shù)據(jù)分別為日期、新增確診/疑似病例、累計確診/現(xiàn)存疑似病例、新增死亡/治愈人數(shù)、累計死亡/治愈人數(shù)。其正則表達式的構(gòu)建如下所示:
date_regex = r"(.*?)<" ?#提取日期的正則表達式
conf_suspe_data_regex = r"
Confirmed cases:(.*?)new,(.*?)total. Suspected cases:(.*?)new,(.*?)total.<" ?#提取新增確診/疑似病例、累計確診/現(xiàn)存疑似病例的正則表達式
