XML文檔分類中特征表達(dá)方法的研究
2020-10-20 05:34:01魏東平馬弋惠
計(jì)算技術(shù)與自動(dòng)化 2020年3期
關(guān)鍵詞:分類
魏東平 馬弋惠


摘? ?要:XML文檔分類技術(shù)可以高效地管理海量存在的數(shù)據(jù),XML文檔同時(shí)擁有結(jié)構(gòu)信息和文本信息。為充分利用XML特點(diǎn),優(yōu)化分類效果,在結(jié)構(gòu)鏈接表達(dá)模型(structured link vector model,簡(jiǎn)稱SLVM)的基礎(chǔ)上,提出了一種新的特征表達(dá)方法,即P-SLVM表達(dá)模型。該模型在傳統(tǒng)的tf*idf的權(quán)重設(shè)置方式基礎(chǔ)上,根據(jù)特征詞在類中的分布情況,對(duì)特征詞權(quán)重設(shè)置進(jìn)行改進(jìn),同時(shí)利用泊松分布理論、特征詞所在位置等對(duì)結(jié)構(gòu)單元進(jìn)行加權(quán),以更為有效地表達(dá)結(jié)構(gòu)信息和內(nèi)容信息。實(shí)驗(yàn)結(jié)果表明,在P-SLVM表達(dá)模型下進(jìn)行的XML文檔的分類,有更好的分類效果。
關(guān)鍵詞:XML文檔;分類;結(jié)構(gòu)鏈接模型;tf*idf;泊松分布
中圖分類號(hào):TP311? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 文獻(xiàn)標(biāo)識(shí)碼:A
Research on Feature Expression Methods
in XML Document Classification
WEI Dong-ping,MA Yi-hui?
(Collage of Computer Science and Technology,China University of Petroleum(East China),Qingdao,Shandong 266580,China)
Abstract:XML document classification technology can efficiently manage massive data,XML documents have both structural and textual information. In order to make full use of the characteristics of XML and optimize the classification effect,this paper proposes a new feature expression method based on structured link vector model (SLVM),namely P-SLVM expression model. Based on the traditional tf*idf weight setting method,the model improves the feature word weight setting according to the distribution of feature words in the class,and uses the Poisson distribution theory and the location of the feature words to weight the structural units. To more effectively express structural information and content information. The experimental results show that the classification of XML documents under the P-SLVM expression model has a better classification effect.
Key words:XML document;classification; structure link model;tf*idf;Poisson distribution
在大數(shù)據(jù)時(shí)代的今天,對(duì)用作數(shù)據(jù)交換和傳輸標(biāo)準(zhǔn)的XML文檔進(jìn)行分析、歸納、整理,以提高數(shù)
據(jù)的利用率是非常必要的。分類技術(shù)是數(shù)據(jù)挖掘下的重要技術(shù),能夠提取文檔特征,根據(jù)文檔特征將
文檔分到不同類別中,以提高數(shù)據(jù)管理的效率。其中的特征表達(dá)過(guò)程是用數(shù)字的形式提取文檔文字信息的過(guò)程,是影響分類效果的關(guān)鍵的環(huán)節(jié)。
XML文檔同時(shí)具有文本信息和結(jié)構(gòu)信息,所以對(duì)XML文檔特征表達(dá)不同于普通文本的表達(dá),它需要同時(shí)表達(dá)內(nèi)容信息以及結(jié)構(gòu)信息。M.Zaki等人提出的XRules是挖掘各類文檔的頻繁子樹形成規(guī)則分類[1]; Nierman等人提出的基于樹結(jié)構(gòu)進(jìn)行
編輯距離[2],用最小的編輯距離來(lái)衡量?jī)蓚€(gè)文檔之間的相似度。這些都是提取結(jié)構(gòu)特征進(jìn)行分類,造成內(nèi)容信息的丟失。當(dāng)前廣泛使用的向量空間特征表達(dá)模型[3](Vector Space Model,VSM)是表達(dá)文檔中每個(gè)開始標(biāo)記和結(jié)束標(biāo)記之間的文本內(nèi)容特征,無(wú)法表達(dá)XML文檔的結(jié)構(gòu)特征。Yang等人提出
的結(jié)構(gòu)鏈接模型[4]是在經(jīng)典的只考慮內(nèi)容信息的
VSM表達(dá)模型的基礎(chǔ)上進(jìn)行擴(kuò)展,將原本僅僅只能表達(dá)內(nèi)容信息的向量表示轉(zhuǎn)化為矩陣表示,以綜合表達(dá)XML文檔的結(jié)構(gòu)信息和文本內(nèi)容信息,這個(gè)特征表達(dá)模型解決了VSM模型只包含內(nèi)容信息,不包含文檔結(jié)構(gòu)信息的問(wèn)題。然而,這個(gè)模型并沒(méi)有考慮不同的結(jié)構(gòu)單元對(duì)文檔的分類貢獻(xiàn)度不同的問(wèn)題,模型中使用的傳統(tǒng)tf*idf并沒(méi)有考慮特征詞類別分布情況對(duì)分類結(jié)果的影響。
在結(jié)構(gòu)鏈接表達(dá)模型的基礎(chǔ)上,提出了一種新的特征表達(dá)模型P-SLVM,它對(duì)傳統(tǒng)的tf*idf的特征詞權(quán)重進(jìn)行設(shè)置時(shí),考慮特征詞的類別分布情況,同時(shí)采用XML文檔樹的路徑作為結(jié)構(gòu)單元,根據(jù)不同的結(jié)構(gòu)單元的位置,引入泊松分布進(jìn)行權(quán)重的設(shè)置[5]。
1? ?有關(guān)概念
1.1? ?XML文檔樹
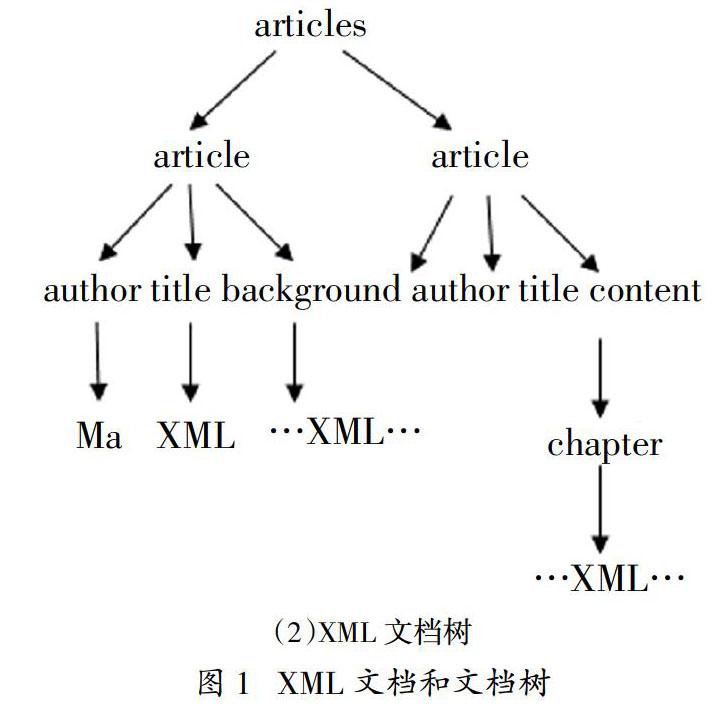
XML文檔有結(jié)構(gòu)層次信息,可以轉(zhuǎn)化為一個(gè)文檔樹的形式。圖1是一個(gè)XML文檔的片段及它的文檔樹形式。
現(xiàn)在對(duì)XML文檔的分類普遍采用的方法是僅僅提取文檔樹中葉子節(jié)點(diǎn)上的內(nèi)容特征信息,舍棄了XML文檔的結(jié)構(gòu)信息,造成信息的丟失。
(1)XML文檔
(2)XML文檔樹
1.2? ?XML文檔特征表達(dá)
XML文檔無(wú)法直接被現(xiàn)有的分類算法識(shí)別,通常需要將XML文檔的特征提取轉(zhuǎn)化為分類算法能識(shí)別的數(shù)字形式,這個(gè)過(guò)程叫做文檔特征表達(dá)。特征表達(dá)模型的建立直接關(guān)系文檔信息的提取,是影響分類效果的關(guān)鍵的環(huán)節(jié)。
1.2.1? ?經(jīng)典的VSM表達(dá)模型
向量空間模型[3](Vector Space Model,VSM)是現(xiàn)在使用最廣泛的文本表達(dá)模型,它將一個(gè)XML文檔表示成特征向量的形式,特征向量中的每一維表示從文檔中選取的特征詞的特征屬性值,也表示這個(gè)特征詞在分類過(guò)程中的權(quán)重,表達(dá)公式如下:
其中,表示Dx文檔x的特征向量,n表示這個(gè)文檔特征詞的數(shù)量。D
x(i)表示x文檔中第i個(gè)特征詞的特征屬性值,特征值一般由公式TF*IDF來(lái)計(jì)算:
其中n
(i,j)是在文檔Dj中特征詞wi出現(xiàn)的次數(shù);n
(k,j)是在文檔Dj中所有特征詞出現(xiàn)的總次數(shù);D是文檔集的文檔數(shù)目;DF(wi)表示有特征詞 的文檔的數(shù)目。從公式看出,一個(gè)特征詞在某個(gè)文檔中出現(xiàn)的頻率越高,在總文檔中出現(xiàn)的次數(shù)越少,這個(gè)特征詞的特征向量值越大,也就是權(quán)重越大,越能區(qū)分文檔類別。
1.2.2? ?擴(kuò)展VSM的SLVM表達(dá)模型
VSM表達(dá)模型僅僅表達(dá)文檔的內(nèi)容信息,對(duì)普通文本分類有很好的分類效果。但是,對(duì)于XML文檔,如果直接使用VSM模型,則會(huì)丟失XML文檔結(jié)構(gòu)信息,表達(dá)不充分。在VSM模型基礎(chǔ)上提出了SLVM表達(dá)模型(Structured Link Vector Model)[4]。SLVM引入了結(jié)構(gòu)信息,能夠同時(shí)表示文檔的結(jié)構(gòu)信息以及內(nèi)容信息。SLVM表達(dá)模型將XML文檔分成一個(gè)個(gè)結(jié)構(gòu)單元(標(biāo)簽、路徑等),再把每個(gè)結(jié)構(gòu)單元都表示成一維向量,對(duì)應(yīng)VSM模型中的一個(gè)文檔。這樣,每個(gè)XML文檔都用一組向量表示,形成矩陣形式。該矩陣綜合體現(xiàn)了XML文檔的結(jié)構(gòu)與文本內(nèi)容。
SLVM模型中結(jié)構(gòu)鏈接向量[5]由三部分組成,分別是結(jié)構(gòu)向量、鏈出向量和鏈入向量。鏈接向量用于表示不同文檔之間的互相鏈入和鏈出關(guān)系,為文本挖掘算法提供更多的文檔關(guān)系信息。由于本文的研究重點(diǎn)是改進(jìn)XML文檔的特征表示模型,所以我們僅考慮SLVM的結(jié)構(gòu)向量。SLVM的結(jié)構(gòu)向量由以下模型表示:
其中表示一個(gè)XML文檔,Dj表示XML文檔D的第j個(gè)結(jié)構(gòu)單元,D
(j,i)是表示文檔D中第 個(gè)結(jié)構(gòu)下的第j個(gè)特征詞的權(quán)重,TF(wi,Dx .ej)表示特征詞wi在Dx文檔中的結(jié)構(gòu)單元ej下的出現(xiàn)頻率。
每個(gè)結(jié)構(gòu)單元包含的特征詞數(shù)量是不同的,為了消除其影響,將結(jié)構(gòu)單元進(jìn)行單位化,其公式如下:
1.3? ?分類算法
用特征模型表達(dá)的文檔可以直接被分類算法識(shí)別。當(dāng)前,有很多分類算法可用于XML文檔分類,決策樹[6]、 貝葉斯[7]、人工神經(jīng)網(wǎng)絡(luò)[8]、支持向量機(jī)[9]、極限學(xué)習(xí)機(jī)[10-11]等,其中神經(jīng)網(wǎng)絡(luò)是分類效果較好的算法之一。 因?yàn)榉诸愃惴ú⒉皇潜疚难芯康闹攸c(diǎn),所以我們選擇了BP神經(jīng)網(wǎng)絡(luò)作為分類器。這里,對(duì)其原理進(jìn)行簡(jiǎn)單分析。
BP神經(jīng)網(wǎng)絡(luò)模型如圖2所示,模型分為三層結(jié)構(gòu):輸入層、隱藏層和輸出層。其分類過(guò)程分為兩個(gè)階段,第一個(gè)階段是數(shù)據(jù)的前向傳播,指的是數(shù)據(jù)從輸入層到隱藏層再到輸出層的過(guò)程;第二個(gè)階段是誤差的反向傳播,指的是根據(jù)實(shí)際和期望的偏差值經(jīng)輸出層到隱藏層再到輸入層不斷期間的權(quán)重和偏置的過(guò)程。
前向傳播過(guò)程比較簡(jiǎn)單,上一層節(jié)點(diǎn)用 表示下一層的節(jié)點(diǎn)則用yj表示,wij表示節(jié)點(diǎn)xi和節(jié)點(diǎn)yj之間的權(quán)重,bj是節(jié)點(diǎn)yj的閾值,f()是激活函數(shù),通常是Sigmoid函數(shù)。下一層節(jié)點(diǎn)yj的值為:
這是前向傳播過(guò)程。反向傳播過(guò)程是通過(guò)實(shí)際結(jié)果和期望結(jié)果的差值,不斷反饋調(diào)節(jié)權(quán)重和閾值,以達(dá)到最小的誤差值。期望結(jié)果用dj表示,實(shí)際結(jié)果是yj,誤差函數(shù)E為:
BP神經(jīng)網(wǎng)絡(luò)是基于梯度下降的,以目標(biāo)的負(fù)梯度方向進(jìn)行調(diào)整。根據(jù)誤差函數(shù),wij和bij的修正值為:
其中,η是動(dòng)力因子。類似地,也可推出bij,此處從略。
2? ?改進(jìn)的文檔特征表達(dá)方法P-SLVM
2.1? ?賦予結(jié)構(gòu)單元權(quán)重
SLVM特征表達(dá)模型將XML文檔的文本內(nèi)容和結(jié)構(gòu)內(nèi)容都引入了分類中。但是,單純以節(jié)點(diǎn)為結(jié)構(gòu)單元并沒(méi)有考慮節(jié)點(diǎn)位置的作用,已經(jīng)證明了使用路徑作為結(jié)構(gòu)單元的分類效果比使用節(jié)點(diǎn)作為結(jié)構(gòu)單元的分類效果要好[12]。這里,我們選擇了效果更好的路徑作為結(jié)構(gòu)單元,進(jìn)行我們的改進(jìn)實(shí)驗(yàn)。
基本思路有二。一是作為結(jié)構(gòu)單元的路徑長(zhǎng)度應(yīng)該是影響該結(jié)構(gòu)單元的權(quán)重。XML文檔文本內(nèi)容信息只出現(xiàn)在文檔樹的葉子節(jié)點(diǎn)中,也就是說(shuō),特征詞只存在于文檔樹的葉子節(jié)點(diǎn),因而路徑長(zhǎng)度代表了特征詞所在文檔樹的深度。同一特征詞的深度不同,對(duì)于文檔的表達(dá)能力也就不同。路徑越長(zhǎng),包含的文本內(nèi)容離根節(jié)點(diǎn)越遠(yuǎn),對(duì)文檔的描述能力越弱,對(duì)分類的貢獻(xiàn)度越小。例如圖1中,在articles/article/title和articles/article/content/chapter兩個(gè)路徑都有同一個(gè)特征詞XML,但顯然article1更可能是XML的類別。二是不同的路徑本身對(duì)分類的貢獻(xiàn)程度也是不一樣的。比如,某XML文檔中出現(xiàn)了“賽制”一類的路徑,很可能該文檔屬于體育類新聞。通過(guò)下面公式給不同的結(jié)構(gòu)單元賦予不同的權(quán)重,來(lái)充分利用XML文檔的結(jié)構(gòu)信息。
其中l(wèi)p
(i)表示路徑p
(i)長(zhǎng)度,k是一個(gè)小于1的調(diào)節(jié)因子[13]。特征詞所經(jīng)過(guò)的路徑越短,其結(jié)構(gòu)單元權(quán)重越大,結(jié)構(gòu)單元內(nèi)的特征詞越接近根節(jié)點(diǎn),越能代表文檔分類。由于每個(gè)XML文檔樹深度都可能是不同的,為防止異常情況,比如文檔樹T1深度為3,T2深度為10,但在T1中路徑長(zhǎng)度為3的特征詞比在T2中路徑長(zhǎng)度為4的權(quán)重大,可對(duì)lp
(i)進(jìn)行規(guī)范化[14]:
其中TreeDepth是樹的深度。
公式(10)中的w
p(i)表示路徑本身的權(quán)重。不同的路徑對(duì)分類的作用也不同,這里我們引入泊松分布[15]來(lái)計(jì)算。
在信息檢索領(lǐng)域,泊松分布用于選擇有效的查詢?cè)~語(yǔ)。這里,我們用來(lái)衡量路徑對(duì)于文檔分類的作用。根據(jù)泊松分布,如果一個(gè)路徑被設(shè)置較大的權(quán)重應(yīng)具備兩點(diǎn)特征:第一個(gè)是該路徑所攜帶的信息與這個(gè)文檔所屬類別應(yīng)該存在很大的關(guān)聯(lián)度,即該路徑的出現(xiàn)和文檔屬于某個(gè)類別并不是獨(dú)立的。因?yàn)椴此煞植碱A(yù)測(cè)獨(dú)立事件發(fā)生的概率,所以該路徑在這個(gè)類別的文檔中的分布就應(yīng)該偏離泊松分布,偏離程度越大,路徑與文檔所屬類別的關(guān)聯(lián)度就越大,權(quán)重設(shè)置應(yīng)該越大;另一個(gè)特征是該路徑在非這個(gè)類中應(yīng)該服從泊松分布。這是因?yàn)檫@個(gè)路徑與非這個(gè)類的文檔之間不應(yīng)該存在依賴關(guān)系,該路徑的出現(xiàn)是隨機(jī)獨(dú)立事件,應(yīng)該被泊松分布所預(yù)測(cè)。根據(jù)以上分析,可使用以下公式為路徑賦予權(quán)重:
其中N是文檔總數(shù),F(xiàn)i是路徑在文檔中出現(xiàn)的頻率,N
(cj)是指文檔中cj類的文檔總數(shù),N
(cj)是指不屬于cj類的文檔總數(shù)。
這里,aij是包含路徑pi同時(shí)屬于類別cj的文檔數(shù)目,bij是不包含路徑pi同時(shí)屬于類別bij的文檔數(shù)目,cij是包含路徑pi同時(shí)但不屬于類別cj的文檔數(shù)目,dij是不包含路徑pi同時(shí)不屬于類別cj的文檔數(shù)目。
p(pi,cj)能夠反映一個(gè)特征詞偏離泊松分布的程度,可用其數(shù)值表示該路徑跟一個(gè)類的依賴程度。
p(i)即為利用泊松分布計(jì)算出的路徑的權(quán)重。
2.2? ?改進(jìn)的TF*IDF值
根據(jù)公式(2),特征詞在文檔中出現(xiàn)的頻率越高,tf越大;特征詞在總文檔中出現(xiàn)的文檔數(shù)越多,則idf越小。但這個(gè)公式存在不完善的地方,下面進(jìn)行詳細(xì)的分析。表1給出了兩個(gè)類、四個(gè)文檔中特征詞a、b、c的分布情況。
首先,特征詞a均勻分布在一個(gè)類中,特征詞b則分散在兩個(gè)類中,顯然,特征詞a更能區(qū)分文檔的類別,但是,根據(jù)公式(2.b),idf(a)和idf(b)相等,并不合理。再者,特征詞c集中分布在一個(gè)文檔中,idf(a)小于idf(c),因而特征詞c的權(quán)重比特征詞a的大,這同樣不合理。可見(jiàn),并不是一個(gè)特征詞在總文檔中出現(xiàn)的頻率越高,這個(gè)特征詞對(duì)文檔分類的貢獻(xiàn)度越大小,而應(yīng)該是在非這個(gè)類中出現(xiàn)的頻率越高,對(duì)這個(gè)類的分類貢獻(xiàn)越小。同時(shí),還應(yīng)該考慮特征詞在類中分布是否均勻。改進(jìn)的TF*IDF公式為:
其中,IDF(wi,cj)表示在類cj中出現(xiàn)特征詞 wi的文檔數(shù)量,D(cj)表示測(cè)試集中類cj的文檔數(shù)量,D(wi,cj)是特征詞wi在類cj中出現(xiàn)文檔數(shù)量。是特征詞在類中分布的均勻程度,如果是均勻分布則數(shù)值越大,表明這個(gè)特征詞越能代表這個(gè)類。是特征詞wi在一個(gè)非cj類中的出現(xiàn)情況,如果關(guān)鍵詞wi在非cj類中出現(xiàn)的次數(shù)多,數(shù)值越小,則權(quán)重越小。改進(jìn)后的TF*IDF值引入了特征詞在類中分布情況使特征詞的權(quán)重設(shè)置更加合理。
3? ?實(shí)? ?驗(yàn)
用分類算法對(duì)表達(dá)模型的效果進(jìn)行了驗(yàn)證。文檔的預(yù)處理是在MyEclipse環(huán)境下進(jìn)行的。分別采用SLVM和P-SLVM表達(dá)模型,經(jīng)過(guò)預(yù)處理生成不同的輸入數(shù)據(jù)。分類過(guò)程則是在Matlab環(huán)境下進(jìn)行的。測(cè)試用的數(shù)據(jù)集有兩組,分別來(lái)自維基百科[17]和Reuters-21578。在兩個(gè)數(shù)據(jù)集中,分別挑取10個(gè)類別,每個(gè)類別隨機(jī)挑選500個(gè)XML文檔,按照4:1的比例分別劃分訓(xùn)練集和測(cè)試集。
實(shí)驗(yàn)中,首先對(duì)數(shù)據(jù)進(jìn)行清洗,包括分詞、去停用詞、同義詞轉(zhuǎn)化等。其次是文本特征選擇。原始數(shù)據(jù)維數(shù)很高,有些特征詞對(duì)于分類作用很小,需要選擇出對(duì)文檔分類貢獻(xiàn)度大的特征詞。特征選擇的方法有很多[17-18],選擇了效果比較好的卡方統(tǒng)計(jì)。再者,分別使用SLVM和P-SLVM表達(dá)模型將處理好的數(shù)據(jù)集轉(zhuǎn)換為分類算法能識(shí)別的形式。最后,用bp神經(jīng)網(wǎng)絡(luò)分類算法進(jìn)行測(cè)試。測(cè)試時(shí),激活函數(shù)采用Sigmoid函數(shù),調(diào)節(jié)因子k為0.8。
分類效果的評(píng)價(jià)采用了準(zhǔn)確率(precision)、召回率(recall)及F1[19],其計(jì)算方式是:
其中,TP表示一個(gè)類中分類正確的文檔數(shù),F(xiàn)P是錯(cuò)誤將其它類的文檔分到這個(gè)類中的文檔數(shù),F(xiàn)N是這個(gè)類中被錯(cuò)誤分到其它類的總數(shù)。圖3、圖4分別是在測(cè)試集1和2上的分類準(zhǔn)確率的測(cè)試結(jié)果。
百科數(shù)據(jù)集或者Reuters-21578數(shù)據(jù)集上,無(wú)論隱藏層的節(jié)點(diǎn)數(shù)為多少,改進(jìn)后的P-SLVM表達(dá)模型的分類準(zhǔn)確度都高于SLVM表達(dá)模型。
表2和表3是選取75個(gè)隱藏層節(jié)點(diǎn)測(cè)得的實(shí)驗(yàn)數(shù)據(jù)。
可以看出,采用改進(jìn)的P-SLVM表達(dá)模型進(jìn)行XML文檔分類,準(zhǔn)確率、召回率和F1指標(biāo)都優(yōu)于SLVM表達(dá)模型。
4? ?結(jié)? 論
針對(duì)XML文檔同時(shí)包含結(jié)構(gòu)和內(nèi)容的特點(diǎn),提出了一種新的特征表達(dá)模型,在SLVM的基礎(chǔ)上,引入了特征詞在類中的分布情況,使tf*idf權(quán)重設(shè)置更合理。同時(shí),用路徑作為結(jié)構(gòu)單元,引入了泊松分布、特征詞在文檔樹的深度等對(duì)結(jié)構(gòu)單元進(jìn)行權(quán)重的設(shè)置。實(shí)驗(yàn)表明,改進(jìn)的表達(dá)模型在準(zhǔn)確率、召回率以及F1等指數(shù)上比之前都有所提高,有更好的分類效果。
參考文獻(xiàn)
[1]? ? ZAKI M,AGGARWAL C.Xrules:an effective stucturan classifier for XML data[C]//Proc of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:ACM Press,2003.
[2]? ? NIERMAN A,JAGADISH H V. Evaluating structural similarity in XML documents[C] // Proceedings? of the ACM SIGMOD International Workshop on the Web and? Databases,2002,2:61-66.
[3]? ? SALTON,G M J,MICHAEL J.Introduction to modern infornation retrieval[M]. New York:McGraw-Hill Inc,1983.
[4]? ? YANG J W,CHEN X O .A semistructured document model for text mining .Journal of Computer Science and T echnology,2002,17(5):603-61.
[5]? ? BI X,ZHAO X,WANG G,et al. Distributed extreme learning machine with kernels based on mapReduce[J]. Neurocomputing,2015,149:456-463.
[6]? ? RUGGIERI? S. Efficient? C4.5[J]. IEEE? ?Computer? Society,2000,14(2):438-444.
[7]? ? JIANG L,LI C Q,WANG S S,et al. Deep feature weighting for naiveBayes and its application to text classification[J]. Engineering Applications of Artificial Intelligence,2016,52 :26-39.
[8] RAMASUNDARAM S, V S P. Text categotization by backpropagtions neragations netword[J]. International Journal of Computer Application,2010,8(3-4):1-5.
[9]? ? RAMESH B,SATHIASEELAN J G R. An advanced multiClass instance selection based support vector machine for text classification[J] Procedia Computer Science,2015,57:1124-1130.
[10]? HUANG G B,ZHU Q Y,SIEW C K. Extreme learning machine:theory and applications[J]. Neurocomputing,2006,70(1):489-501.
[11]? HUANG G B.An insight into extreme learning machines:random neurons,random features and kernels[J] Cognitive Computation,2014,6 (3) :376-390.
[12]? 基于核方法的XML文檔自動(dòng)分類[J].計(jì)算機(jī)學(xué)報(bào),2011,34(2):353-359.
[13]? ZHANG L J,LI Z H,CHEN Q,et al. Classifying XML documents based on term semantics[J]. Journal of Jilin University:Engineering and Technology Edition,2012,42(6):1510-1514.
[14]? GAO N,DENG Z H,JIANG J J,et al. Combining strategics for XML retrieval[C]//Proceedings of INEX Conference,Berlin:Springer-Verlag,2011:319-331.
[15]? HIROSHI O,HIROMI A,MASATO M. Feature selection with ameasure of deviations? from? Poisson? in Applications,2009,36(6826-6832).
[16]? DENOYER L,GALLINARI P. The Wikipedia XML corpus [J]. ACM SIGIR Forum,2006,40(1):64-69.
[17]? CANTU-PAZ E,NEWSAM S,KAMATH C. Feature selection in scientific application[C]. In Proceedings of the tenth? ACM? SIGKDD? International Conference on Knowledge Discovery and Data Mining,2004:788-793.
[18] CHEN X,WASIKOWSKI M. FAST:a ROC-based feature selection metric for small samples and imbalanced data classification problems[C]. KDD'08,2008,124-132.
[19]? SEBASTIANI F.Machine learning in automated text categorization[J]. ACM Computing Surveys,2002,34(1):1-47.
猜你喜歡
西北民族大學(xué)學(xué)報(bào)(自然科學(xué)版)(2021年4期)2021-12-29 02:54:24
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學(xué)生天地(2019年32期)2019-08-25 08:55:22
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級(jí)語(yǔ)數(shù)英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
