基于LDA-FCM方法的Web服務發現聚類性能分析
2020-10-20 05:34:01冉冉徐立波曲睿婷夏雨
計算技術與自動化 2020年3期
冉冉 徐立波 曲睿婷 夏雨

摘? ?要:為提高Web服務發現能力,需要進行Web數據的優化聚類處理,提出了基于LDA-FCM方法的Web服務發現聚類方法。利用LDA模型進行Web服務發現資源數據的重組和自適應調度,以提取Web服務發現的數據資源特征。依據數據特征確定其相似度,在FCM算法中,通過相似度計算隸屬度,從而確定聚類中心,多次迭代后,實現Web服務發現聚類。實驗結果表明,所提方法復雜度較低,具有較好的聚類精度,聚類執行時間較少,其查全率與查準率均較高。
關鍵詞:LDA模型;Web服務;聚類;模糊C均值算法;隸屬度;數據相似度;服務發現
中圖分類號:TM7659? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?文獻標識碼:A
Performance Analysis of Web Service Discovery
clustering Based on LDA-FCM Method
RAN Ran?,XU Li-bo,QU Rui-ting,XIA Yu
( State Grid Liaoning Information and Communication Company,Shenyang,Liaoning 110006,China)
Abstract:In order to improve the ability of Web service discovery,it is necessary to optimize the clustering of Web data,and a clustering method of Web service discovery based on LDA-FCM method is proposed. The LDA model is used for the reorganization and adaptive scheduling of Web service discovery resource data in order to extract the data resource characteristics of Web service discovery. According to the data characteristics,the similarity is determined. In the FCM algorithm,the membership degree is calculated by similarity,so as to determine the clustering center. After many iterations,the Web service discovery clustering is realized. The experimental results show that the proposed method has low complexity,good clustering accuracy and less clustering execution time. The recall rate and precision rate are high.
Key words:Latent Dirichlet Allocation model;Web service;clustering;fuzzy C-means algorithm;degree of membership;data similarity;service discovery
為進一步提高Web資源的自動調度能力,需要進行Web服務發現聚類處理,構建Web服務資源數據的自適應分類和調度模型,進行Web數據的優化分類,滿足人們的個性化服務需求[1]。在大數據環境下,進行Web資源數據的聚類處理。根據Web資源的圖片、聲音、數據和文本信息等屬性,進行Web資源的聚類分析[2],研究Web服務發現聚類方法,在提高Web資源優化調度和服務能力方面具有重要意義,相關的Web數據發現方法研究受到人們的極大關注[3]。
其中,黃媛提出一種基于標簽推薦的服務聚類方法[4],利用標簽推薦形式分析API服務聚類集合,以Web2.0為研究對象,在API服務數據集進行操作實驗,以此為基礎,提出服務聚類方法。肖巧翔等[5]提出基于Word2Vec和LDA主題模型的Web服務聚類方法,將Wikipedia語料庫實行擴展,利用Word2Vec進行信息收集,將收集的結果按LDA主題模型實施文檔描述,完成Web服務聚類。
針對上述情況,提出了基于LDA(Latent Dirichlet Allocation)-FCM(Fuzzy C-Means)的Web服務發現聚類方法,實現Web服務發現聚類優化。
1? ?基于LDA模型的Web服務資源數據特
征提取
LDA(Latent Dirichlet Allocation)模型可推斷出Web服務中的不同資源數據、文檔的主題狀況,預測資源數據的分布狀況,而Web服務中使用到的資源數據、項目文檔等均可以用來Web服務發現聚類,為用戶的提供搜索功能。為了實現在大數據環境下的分布式Web服務資源數據聚類,實現Web服務發現聚類分析,提出運用LDA結合FCM方法進行聚類研究。
1.1? ?LDA模型構建
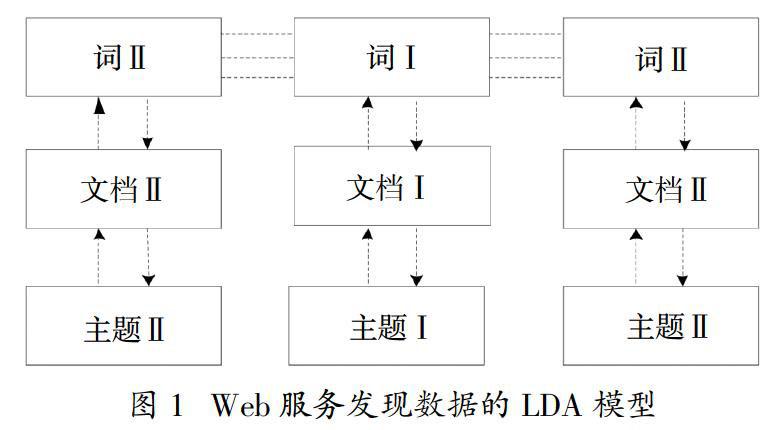
首先構建Web服務發現數據的LDA模型,其為一種非監督的機器學習算法,該種算法可以將Web服務發現數據的主要內容分為三類[6],分別為:詞、文檔、主題,可用來識別海量Web服務中的隱含數據信息。這種運用LDA模型分類處理Web服務資源數據,有效地過濾與用戶搜索目標無關的Web服務,減少Web服務匹配次數,縮短Web服務發現的執行時間。主要方法為:
設分布式Web服務發現資源數據信息為Pi∈P(i = 1,2,…,m),根據上述分析,構建Web服務發現數據的LDA模型,如圖1所示。
目前,用戶搜索Web服務時,往往是輸入用戶自身需要的功能名稱,搜索引擎根據用戶鍵入的請求,給出滿足用戶要求的Web服務。其中,搜索引擎主要依靠標簽對Web的搜索服務進行功能劃分,這種劃分下,極易造成資源浪費。如若一個資源可以用做不同的功能,但其只劃分到最常用功能中,則導致該資源的其他功能浪費,還有一些隱蔽資源,如該項資源數據具有某項功能,用戶只搜索該功能,但該項資源數據的篇名或文件名并非該項功能,導致目前的搜索方法很難查詢到。而本文構建使用的Web服務發現數據LDA模型,將Web服務的數據資源劃分為三類,分別為:詞、文檔、主題,這種劃分不論用戶在搜索關鍵詞、功能、模糊主題甚至固定的文檔題目等,均可以高效搜索到目標內容,擴大了可搜索到資源的數目,避免資源浪費,提高檢索效率。同時,將Web服務資源進行有效分類后,可以提高其重組精度,對資源重組,如將具有共同含義的詞或具有共同研究方向的文檔歸為一個組合,提供“打包”服務,可為Web服務搜索提供新嘗試,為融合調度服務資源數據提供基礎。
1.2? ?Web服務資源數據的調度模型設計
在1.1節中構建LDA模型實現Web服務數據資源的分類后,還需提取不同類別數據資源的特征,以實現最終的聚類目的。其中,考慮到不同資源具有相同功能,即不同的詞、文檔、主題可能均滿足同一個用戶搜索請求,為提高資源利用效率,利用關聯屬性對資源數據進行重組,依據重組結果實現最終的調度模型設計。
假設分布式Web服務資源數據信息存儲的節點的屬性集為X = {x1,x2,…,xn},Web服務資源數據的關聯屬性集:
在分布式Web服務資源數據的不同類別層中,采用異構信息庫重組方法[7-8],可得分布式Web服務資源數據動態重組的約束參量θ:
其中,β代表數據離散估計參量。根據Web服務發現數據的屬性特征以及重組約束參數,對其進行資源數據重組,得到資源數據重組結果為:
對Web服務資源數據進行重組可為數據的自適應調度提供基礎[9-10],得到分布式Web服務資源數據自適應調度模型為:
由此完成了自適應調度模型的構建。在海量Web服務資源數據中,若直接提取資源數據的特征,易造成資源數據過多,未歸類而導致特征過多,不利于后續應用。故需要先對海量資源數據進行一定的處理,對重組后數據進行自適應調度,可確保在此之后的融合處理及特征提取過程更為簡單,降低方法的復雜度,并提高特征提取的準確度。
1.3? ?Web服務資源數據特征提取
在提取資源數據特征之前,還需要融合處理調度結果,這是由于將數據進行互信息融合,可以提高數據的聚集度,使其具有更優的分類效果,保證不同類別數據特征提取的精度。
將Web服務資源數據調度模型映射到高維空間中,在高維相空間中進行分布式Web服務資源數據的互信息融合性調度,得到融合結果為:
其中,t為當前Web服務資源數據的統計量。數據融合處理實際上是一項信息處理技術,其主要是對數據進行自動的分析、組合或篩選,以實現最終的決策。由Web服務資源數據融合處理結果,得到分布式Web服務資源數據不同類別的特征表示為[12]:
其中,μi、Vi 、Oi 分別代表Web服務發現資源數據中詞、文檔、主題的特征值;μk代表Web服務資源的動態服務特征分布模糊值。
以上實現了不同類別數據的特征提取,依據這些特征,可計算FCM算法的隸屬度。
2? ?基于FCM算法的Web服務發現聚類
FCM(Fuzzy C-Means)算法是監督機器學習的一種,由于FCM算法的數據集均處于同一個向量空間,而Web服務無法映射到一個向量空間,只能計算它們之間的相似度,然后通過相似度來計算隸屬度,從而確定聚類中心。
2.1? ?隸屬度的計算
在1.3節獲取Web服務資源數據的特征后,確定分布式Web服務資源數據的相似度為:
根據語義 Web 服務的相似度特點,計算分布式Web服務資源數據指向性特征量:
其中,di代表兩個數據之間的歐式距離。由此得到其隸屬度函數為:
2.2? ?聚類中心的確定
在Web服務發現性數據的信息覆蓋區域,假設m個Web服務發現的傳輸數據,分布式Web服務資源數據動態特征分布集在t中的聚類簇為ci,第i個Web服務發現性數據的散亂點集為Ri = (ri1,ri2,…,riD),得到數據關聯特征量為:
其中,P(d|t,ci)為ci類分布式Web服務資源發現聚類的分布概率,在統計特征分布模型中[12-14],分布式Web服務資源數據發現聚類的融合特征量為z = {zf 1,zf 2,…,zf r},得到分布式Web服務資源數據發現聚類的目標函數為:
構建分布式Web服務資源發現聚類的關聯性決策函數為:
進行模糊C均值聚類的自適應尋優控制,構建Web服務數據的空間聚類模型[15],計算分布式Web服務資源數據指向性特征量vi,vj = ((w1,t1),(w2,t2),…,(wj,tj)),分布式Web服務資源聚類的模糊集為:
其中vi為Web服務發現資源數據的關聯系數值。對Web服務發現資源數據的屬性進行動態評估,計算公式為:
根據Web服務發現的屬性集進行向量量化分解[16-18],得到Web服務發現資源數據聚類的模糊相似度為:
其中:pi,j(t)為分布式Web服務資源數據共享的模糊相關性特征分布集,Δp(t)為分布式Web服務資源數據的模糊決策增量值。用4元組(Ei,Ej,d,t)來表示分布式Web服務資源數據的決策樹[19-20],得到的Ei是分布式Web服務資源數據在聚類分岔節點,分布式Web服務資源發現聚類的差異化融合特征量:
式中,m為分布式Web服務資源數據分布的有限數據集,(Yik)2為相似度分布映射,采用模糊C均值聚類,得到優化聚類中心為:
2.3? ?基于FCM算法的Web語義服務發現聚類
步驟
FCM算法的核心即為隸屬度以及聚類中心的確定。算法的具體步驟為:
(1)給定聚類數目、初始化設置隸屬度值和聚類中心,確定迭代誤差。
(2)對第i次迭代,重新計算隸屬度函數,以得到更新后的隸屬度函數值。同時,重新優化更新聚類中心。
(3)計算目標函數,并保存結果。
(4)若目標函數結果滿足條件,則算法停止;否則,返回步驟(2)。
3? ?仿真實驗實驗結果分析
為了驗證本方法在實現Web服務發現性聚類的性能,采用Matlab進行實驗分析,對Web服務數據采樣來自于Pearson Database數據庫,調查對象主要包括11個領域內的數據,分別為:Tools,Financial,Enterprise,Messaging,Payments,Government,Science,Social,Commerce,Mapping和Education等11個領域。主要針對Tools領域里的Web服務進行研究。結合分組控制單元(PCU,Packet Control Unit)進行分布式Web服務資源調度,訓練樣本規模為80,分布式Web服務資源數據的關聯維度為5,迭代次數N = 1 000,延遲為13 ms,采樣頻率為120 kHz,根據上述仿真環境和參數設定,進行了100次模糊聚類實驗,以降低初始點選取對聚類結果的影響。將本方法與K-means聚類方法和FCM聚類方法進行對比,對比指標包括執行時間、查全率和查準率。原始的Web服務資源數據時域分布如圖2所示。
分析圖3得知,采用本方法進行Web服務發現資源數據聚類的特征歸集能力較好。
將本方法與K-means算法和單一的FCM聚類算法進行對比,測試聚類時間,得到對比結果見表1。
由表1可以看出,使用本方法的聚類耗時最少。一方面是由于FCM聚類方法本身聚類耗時較短(可由單一的FCM方法耗時較K-means方法耗時少看出),另一方面,在聚類之前首先使用LDA模型對海量資源數據進行分類與重組,這種處理后,過濾掉了與用戶搜索目標無關的資源數據,使同時各個類別的數據量明顯降低,對各個類別的資源數據進行同時特征提取和聚類,使得提取數據特征更為簡單,算法復雜度低,從而縮短了整體的聚類耗時。
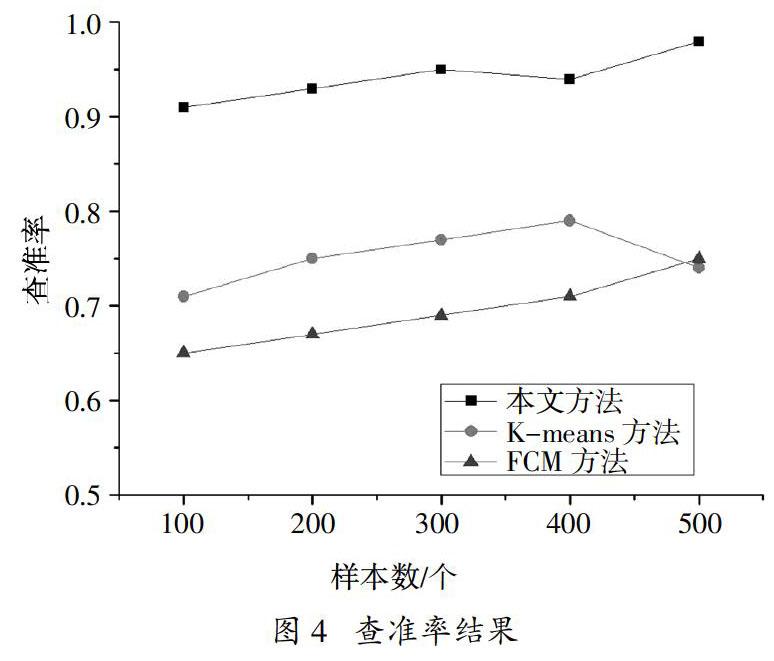
測試不同方法的查準率和查全率,查準率是評價檢索出的資源數據是否正確的指標,即為檢索出的正確資源數據量與檢索出的所有資源數據量的比值。查全率是評價檢索方法在整體資源數據中查詢是否成功的指標,即為檢索出相關的資源數據量與總量的比值。具體的查準率和查全率計算公式如公式(21)和公式(22)所示,得到實驗結果如圖4~圖5所示。
由圖4和圖5可以看出,本方法進行Web服務資源數據的聚類后,其查準率較高。查全率始終高于其他兩種方法,證明了使用LDA與FCM結合后的算法可提高Web服務發現聚類性能。這主要是由于,使用LDA模型對資源數據進行有效分類,按照詞、篇名和主題將資源數據分為三類,有利于隱蔽數據的利用和后續資源數據特征的高精度提取,從而求得聚類所需的相似度更為準確,提高最終的Web服務資源數據查準率。而其他兩種方法不具有搜索隱蔽性數據的功能,故其查全率較低。但在未來的研究中,可進一步重點研究如何提高Web服務資源數據的查全率。
4? ?結? ?論
Web服務聚類是Web服務發現的基礎,用戶對Web服務資源數據進行查找,能夠提高資源數據的利用率和Web服務發現效率。為此,提出了基于LDA-FCM方法的Web服務發現聚類方法。在利用FCM聚類之前,使用LDA方法對Web服務資源數據進行分類處理,以過濾掉不滿足要求的數據,同時挖掘發現隱含數據,保證Web服務發現的即時性和準確度。并提取Web服務發現的數據資源特征,解決Web服務無法映射到一個向量空間而導致無法有效求得隸屬度的問題,實現Web發現服務聚類。實驗發現,運用LDA-FCM方法可以有效提高聚類性能,其具有較單一FCM算法更高的查準率和查全率,且耗時相對較少,說明所提出的算法具有更高的效率和實用性。在未來的研究中,將致力于添加合適的約束參數,以進一步提高查全率。
參考文獻
[1]? ? 張祥平,劉建勛,肖巧翔,等. 基于LDA和模糊C均值的Web服務多功能聚類[J]. 中南大學學報(自然科學版),2018,49(12):92-98.
[2]? ? 趙一,李昭,陳鵬,等. 一種面向領域的Web服務語義聚類方法[J]. 小型微型計算機系統,2019,40(1):83-90.
[3]? ? 杜勝浩,錢曉捷. 基于刻面與本體標識的語義Web服務發現方法[J]. 計算機工程,2018,44(8):230-235.
[4]? ? 黃媛. 一種基于標簽推薦的服務聚類方法[J]. 計算機與數字工程,2017,45(06):133-136.
[5]? ? 肖巧翔,曹步清,張祥平,等. 基于Word2Vec和LDA主題模型的Web服務聚類方法[J]. 中南大學學報(自然科學版),2018,49(12):85-91.
[6]? ?CAO B,LIU X,LIU J,et al. Domain-aware mashup service custering based on LDA topic model from multiple data sources[J]. Information & Software Technology,2017,90:40-54.
[7]? ? 陸佳煒,馬俊,陳烘,等. 一種面向全局社交服務網的Web服務聚類方法[J]. 計算機科學,2018,45(3):204-212.
[8]? ? WU Qing-qiang,KUANG Yi-chen,HONG Qing-qi,et al. Frontier knowledge discovery and visualization in cancer field based on KOS and LDA[J]. Scientometrics,2019,118(3):979-1010.
[9]? ? 黃蓉. 基于聚類分析的數據挖掘方法研究[J]. 山東農業大學學報(自然科學版),2017,48(1):100-103.
[10]? BUKHARI A,LIU Xu-min. A Web service search engine for large-scale Web service discovery based on the probabilistic topic modeling and clustering[J]. Service Oriented Computing & Applications,2018,42(3):1-14.
[11]? 劉一松,朱丹. 基于聚類與二分圖匹配的語義Web服務發現[J]. 計算機工程,2016,42(2):157-163.
[12]? 田浩,樊紅,杜武. 基于用戶社群關系的Web服務發現研究[J]. 通信學報,2015,36(10):28-36.
[13]? ILAHI R,ADMODISASTRO N,ALI N M,et al. Dynamic reconfiguration of Web service in service-oriented architecture[J]. Advanced Science Letters,2017,23(11):11553-11557.
[14]? 唐妮,熊慶宇,王喜賓,等. 基于位置聚類和張量分解的Web服務推薦算法[J]. 計算機工程與應用,2016,52(15):65-72.
[15]? 閆莉莉,程剛. 基于共詞聚類分析的國外知識密集服務研究熱點分析[J]. 現代情報,2015,35(8):22-27.
[16]? 姚瑤,王戰紅,石磊. 一種基于頁面聚類的 We b概念化建模新方法[J]. 微電子學與計算機,2015,14(1):156-160.
[17]? CHEN F,LI M,WU H,et al. Web service discovery among large service pools utilising semantic similarity and clustering[J]. Enterprise Information Systems,2015,11(3):452-469.
[18]? RAMASAMY R K,CHUA F F,HAW S C,et al. Web Service discovery for cloud-based mobile application using multi-level clustering and QoS-based ranking[J]. International Journal of Software Engineering & Knowledge Engineering,2016,26(07):1077-1097.
[19]? 申利民,陳真,李峰. 考慮數據變化范圍的Web服務服務質量協同預測方法[J]. 計算機集成制造系統,2017,23(1):215-224.
[20]? 陳婷,劉建勛,曹步清,等. 基于BTM主題模型的Web服務聚類方法研究[J]. 計算機工程與科學,2018,40(10):1737-1745.
